
Time-Lag Selection for Time-Series Forecasting Using Neural Network and Heuristic Algorithm

 , , , ,
, , , ,  , and
, and
Abstract
:1. Introduction
- (i)
- Statistical analysis was conducted on the hourly data using autocorrelation function to find time-lag value.
- (ii)
- An LSTM model was developed for time-series forecasting.
- (iii)
- A heuristic algorithm, e.g., Genetic Algorithm (GA), was run over LSTM to search for the optimal value of the time-lag.
- (iv)
- A parallel implementation was performed to find the time-lag value dynamically.
- (v)
- A comparison between these methods was made for the selection of time-lag value.
2. Related Works
3. Materials and Methods
3.1. Dateset Handling and Per-Processing
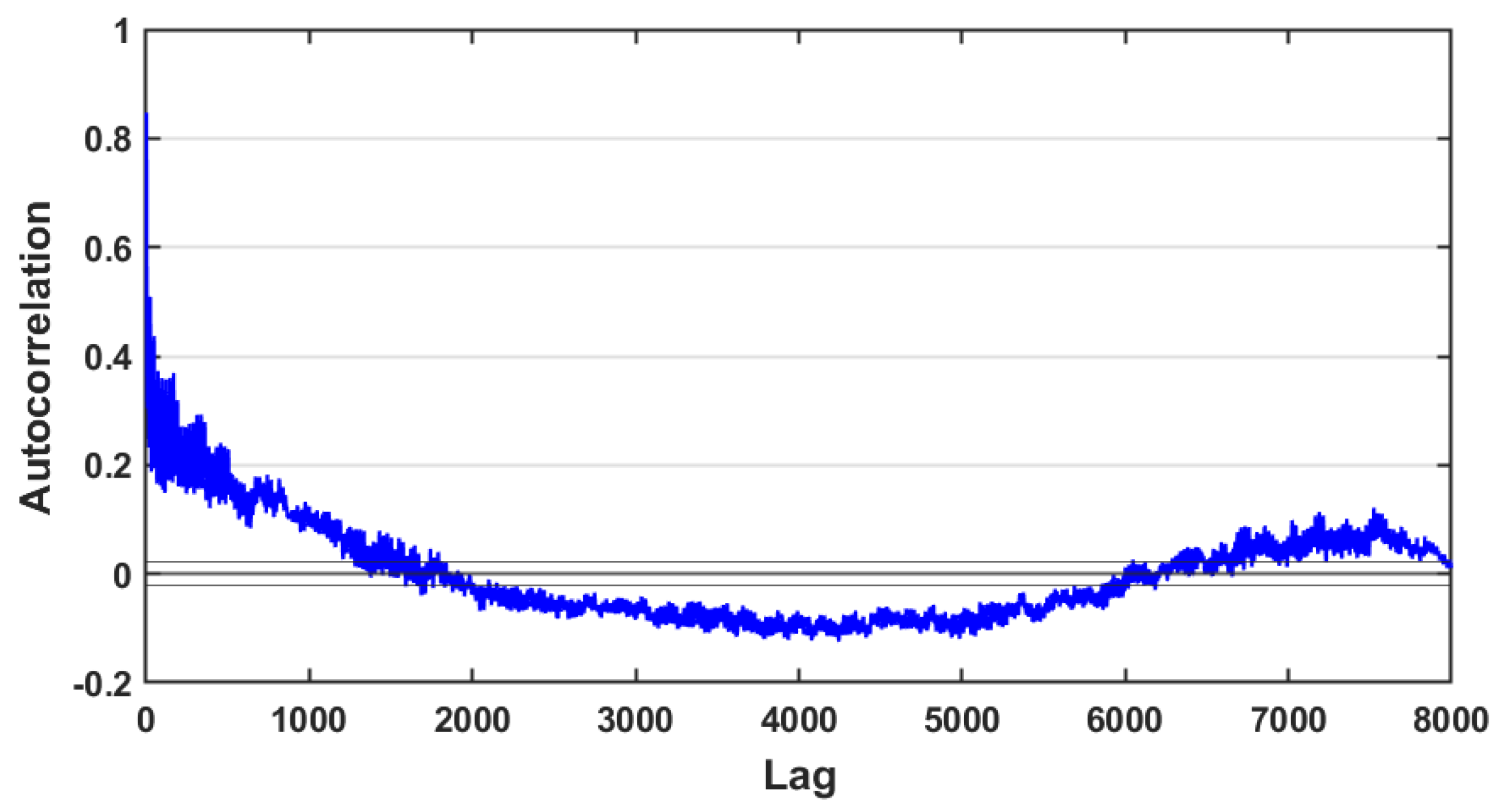
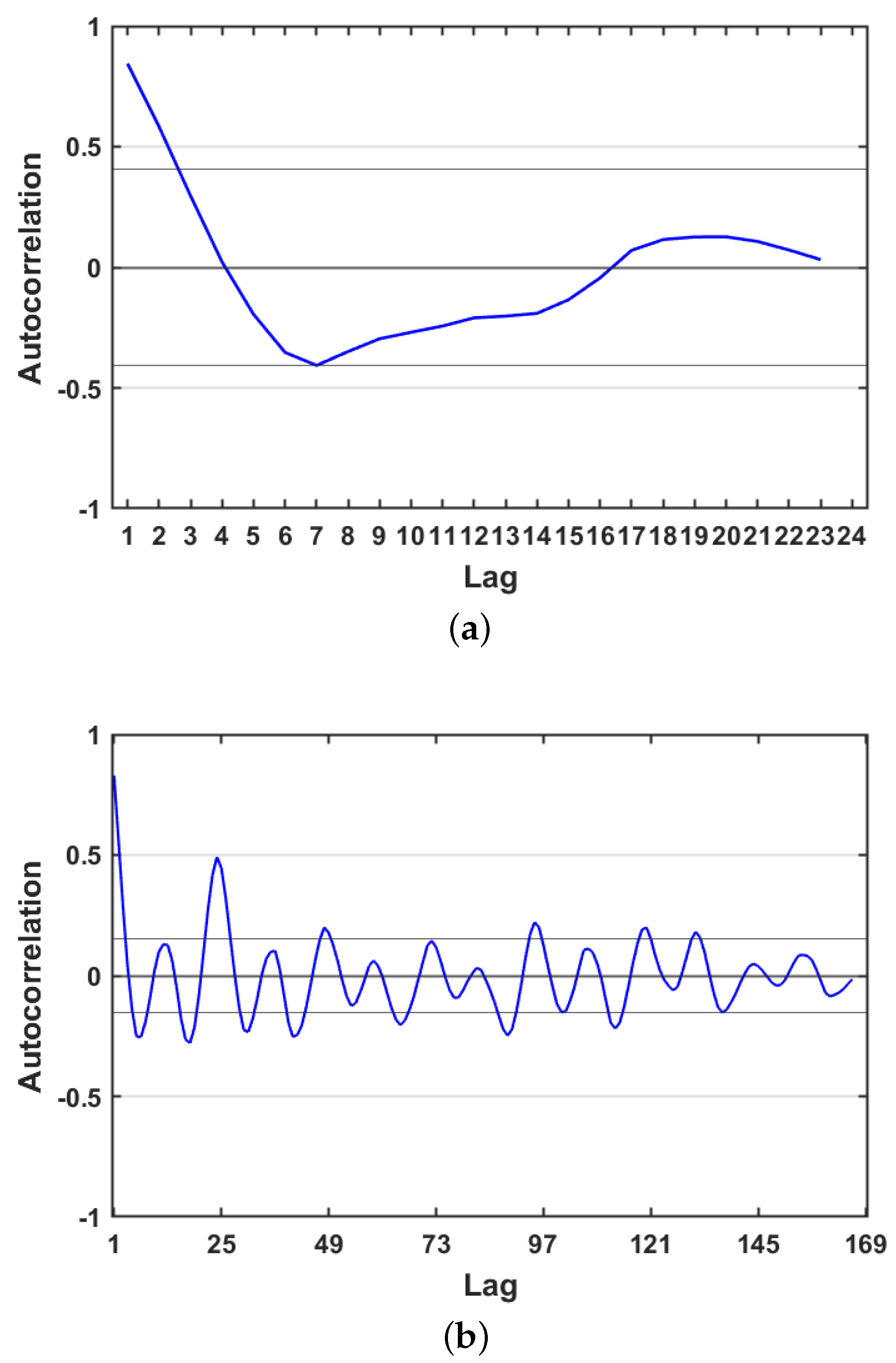
3.2. Data Statistical Analysis
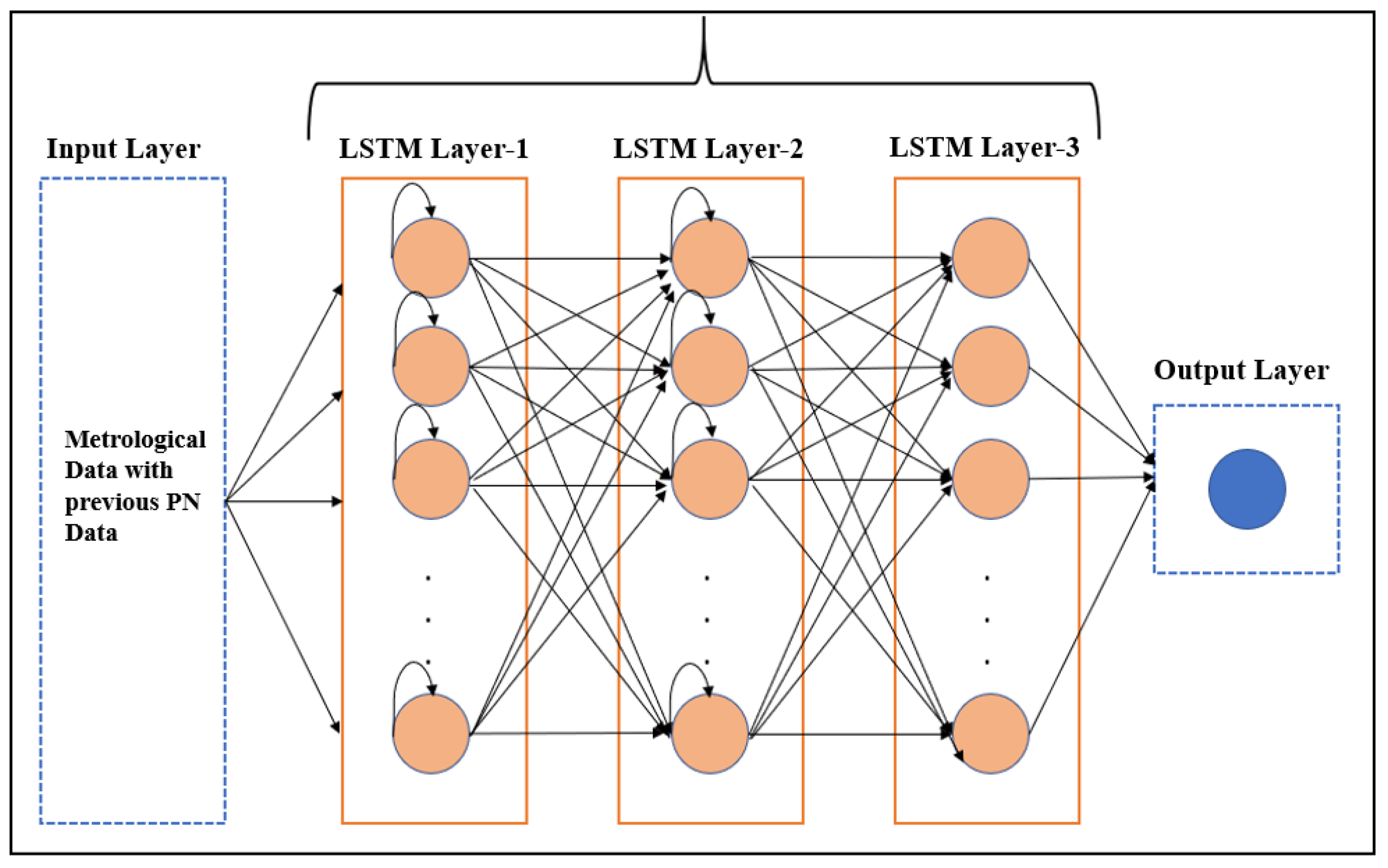
3.3. LSTM Model Setup
3.4. LSTM with Heuristic Algorithm
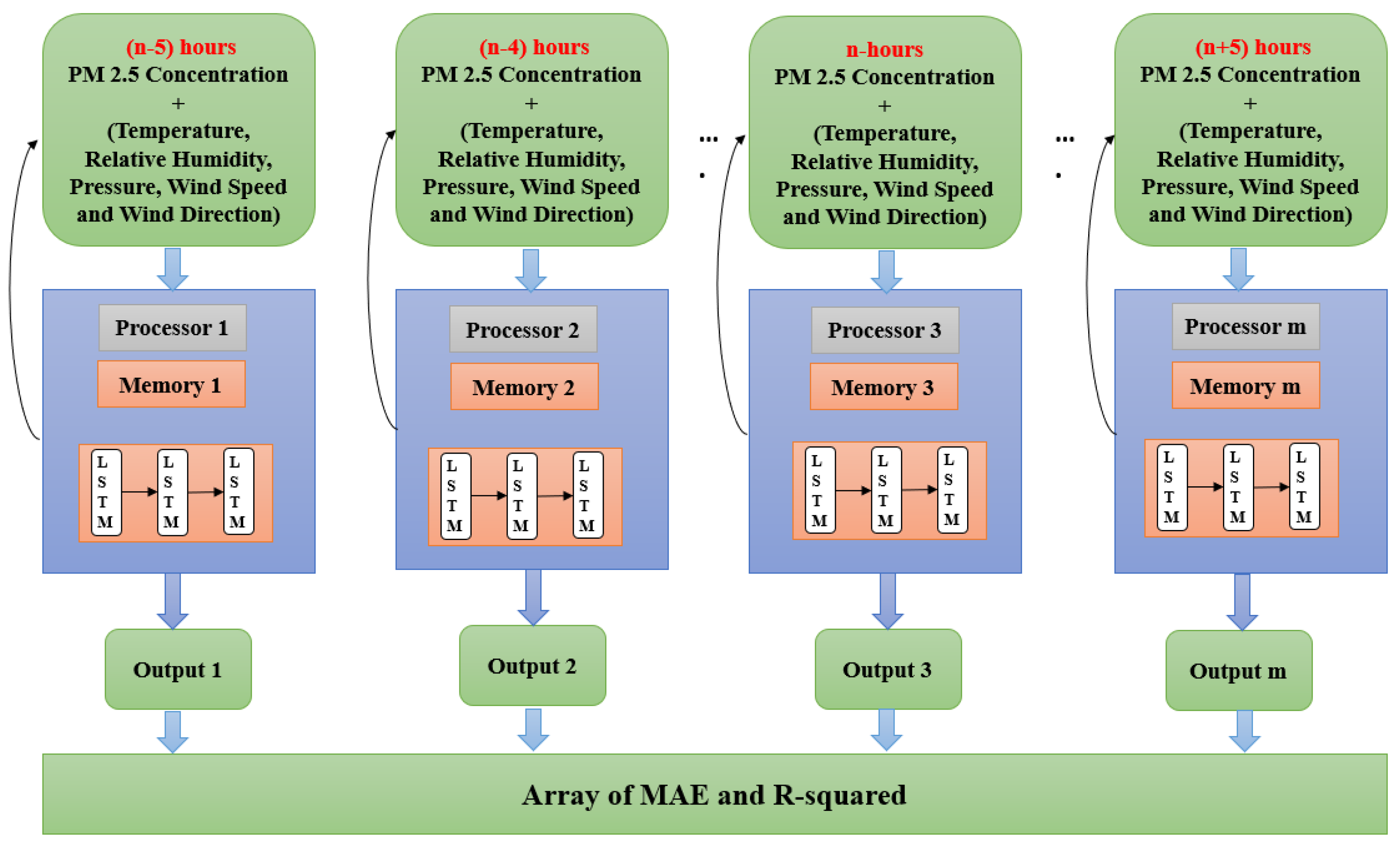
3.5. Parallel Model
4. Empirical Results and Discussion
- (i)
- The statistical method that are based on autocorrelation coefficient function. This method will suggest the value of time-lag based on correlation that is shown by the autocorrelation function
- (ii)
- The LSTM with GA. GA will search for the best time-lag value to be used for the prediction. The solution with lowest MAE (fitness function) will be considered to be an optimal solution.
- (iii)
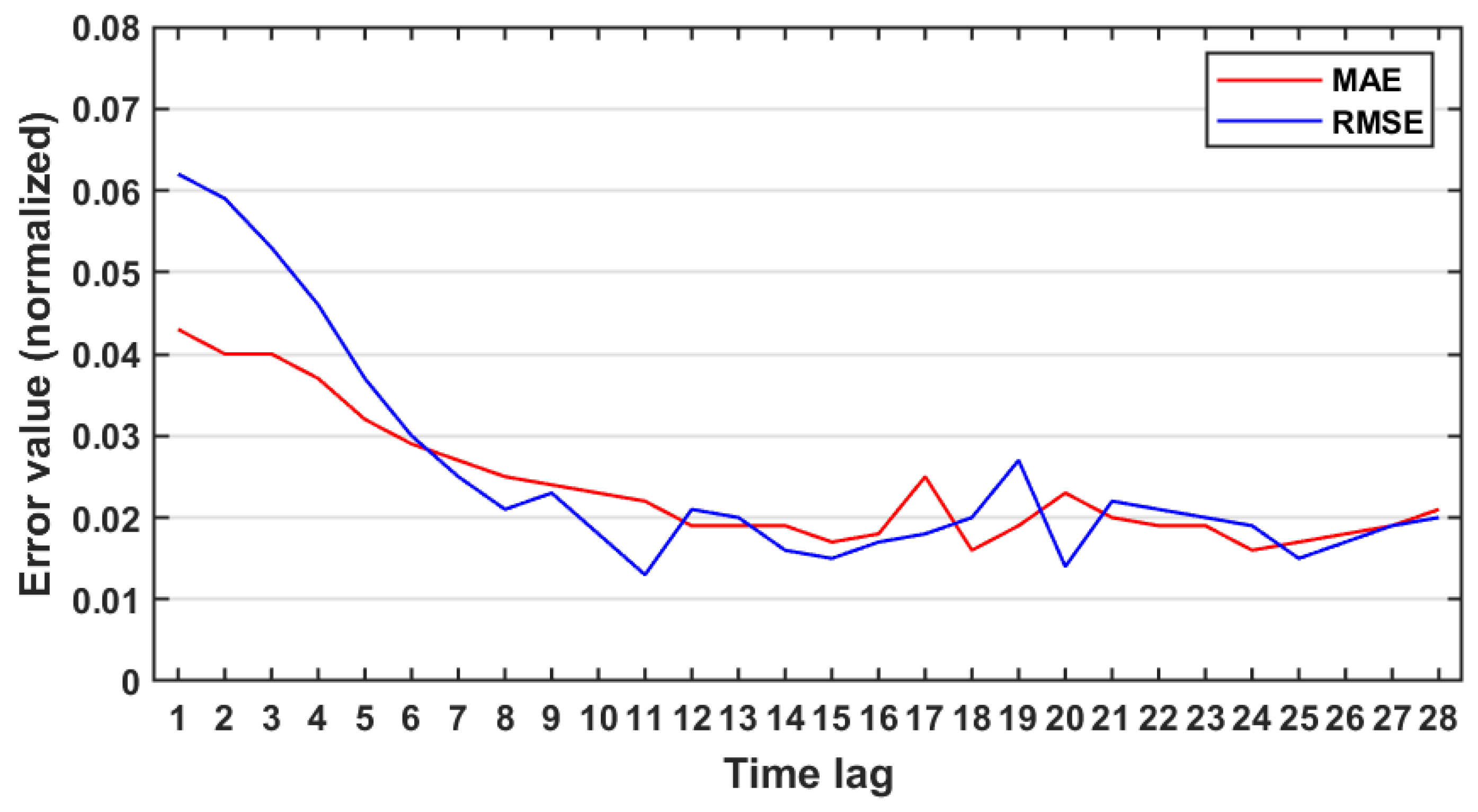
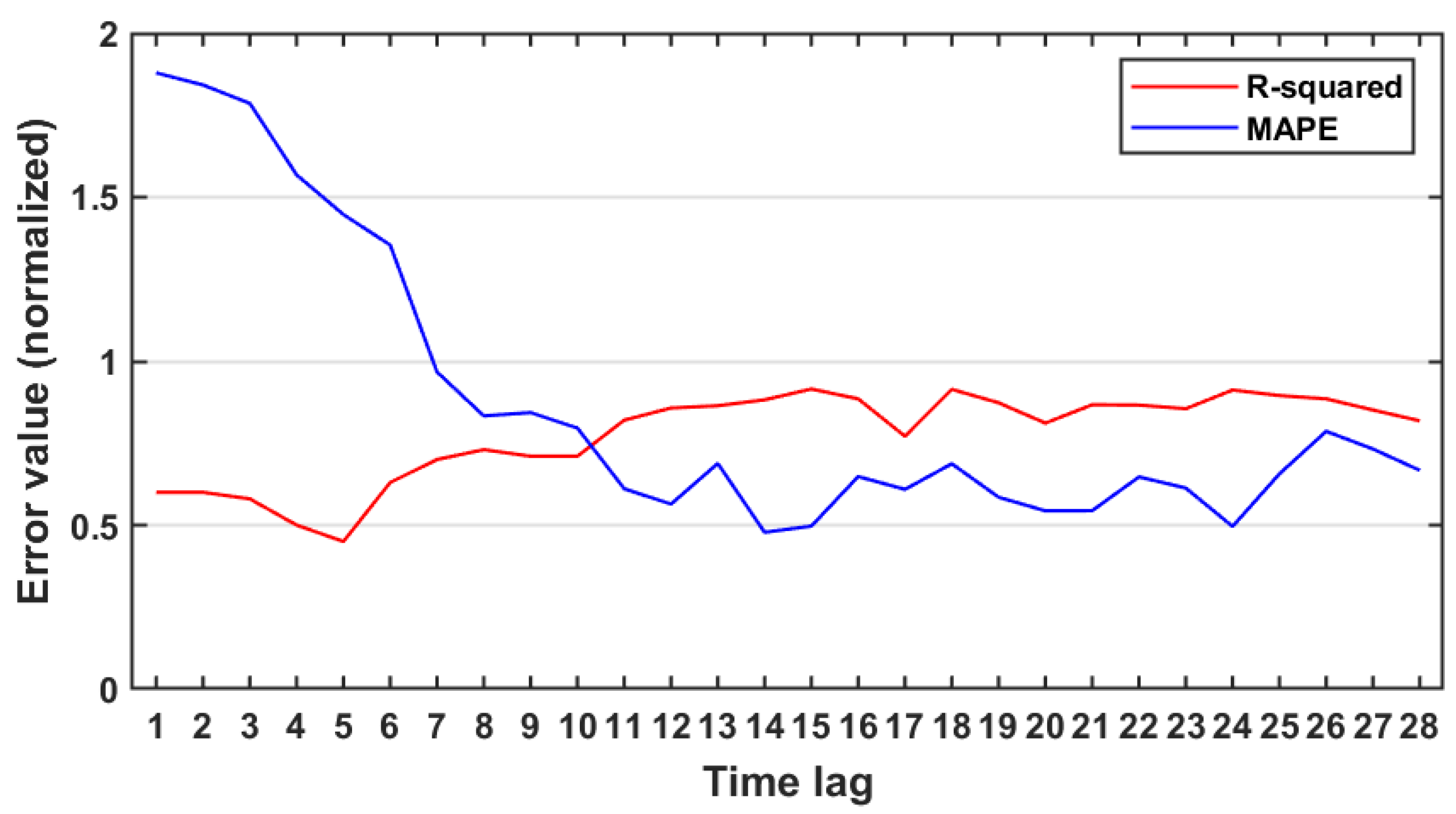
- The parallel LSTM. The LSTM model will run in parallel over different processors with different time lag. The MAE, RMSE, MAPE and R-squared are taken for the performance evaluations among them. The processor with lowest MAE, RMSE, MAPE and highest R-squared will be considered to be the best prediction result where the time-lag used by it will be the best lag value.
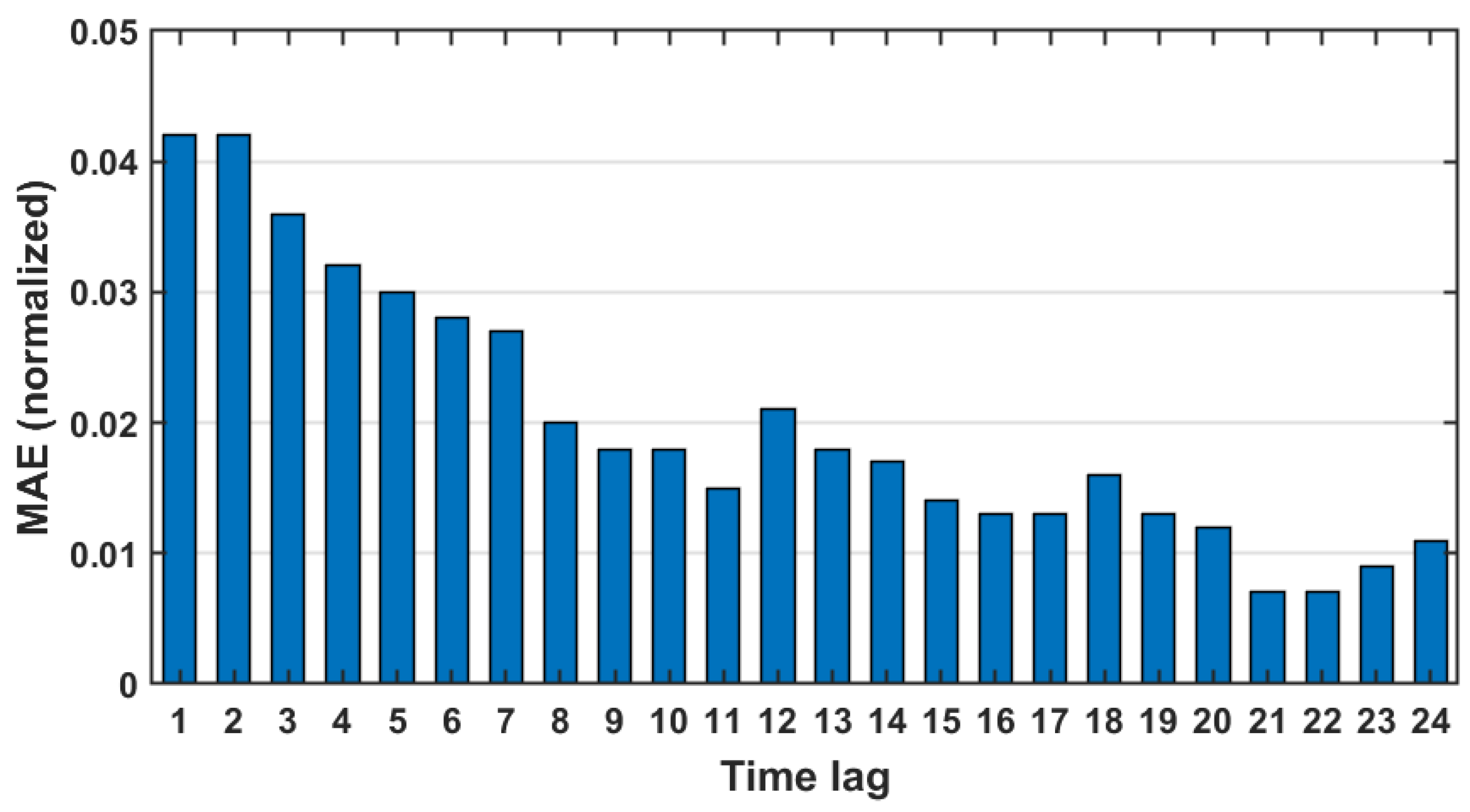
4.1. Statistical Results
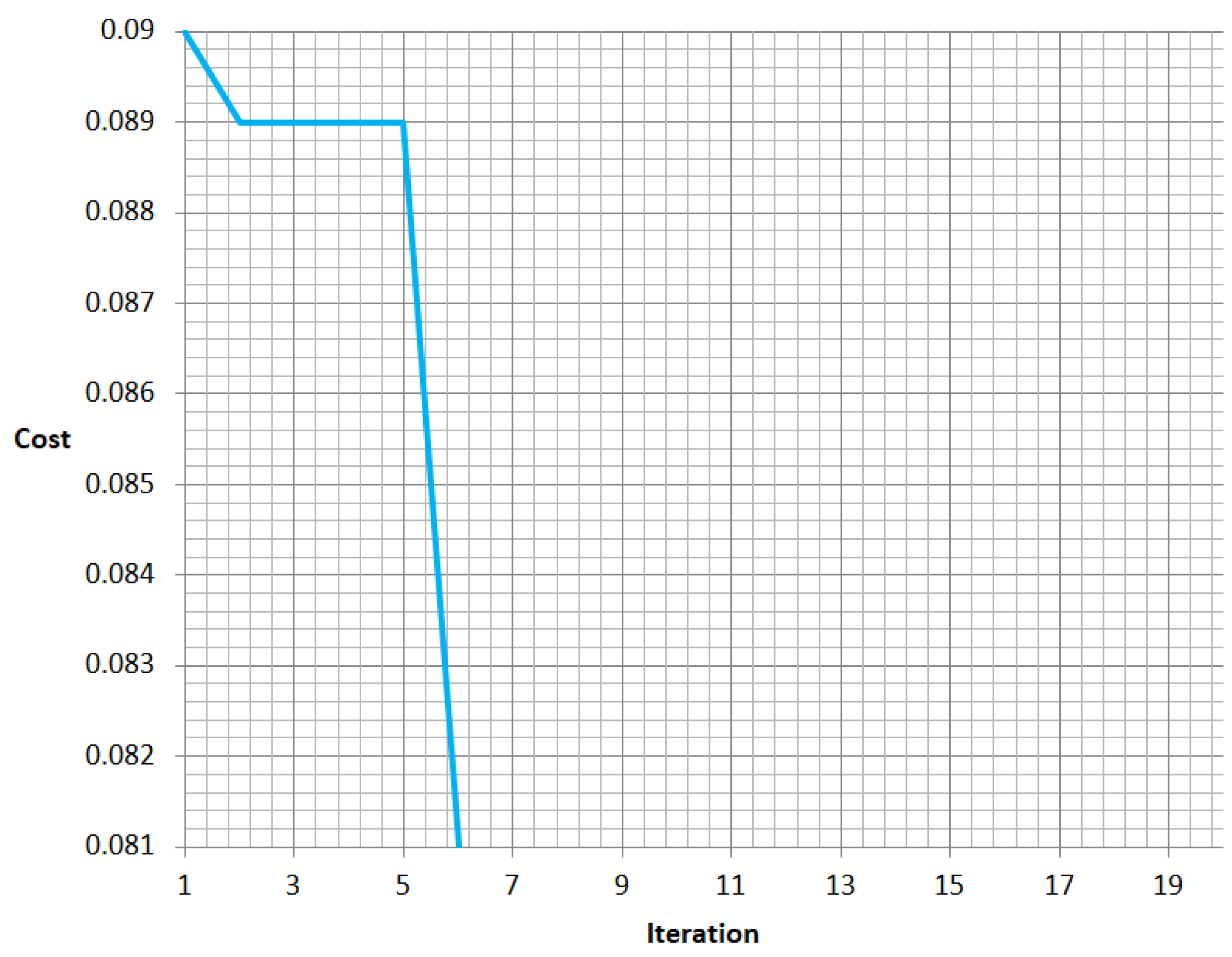
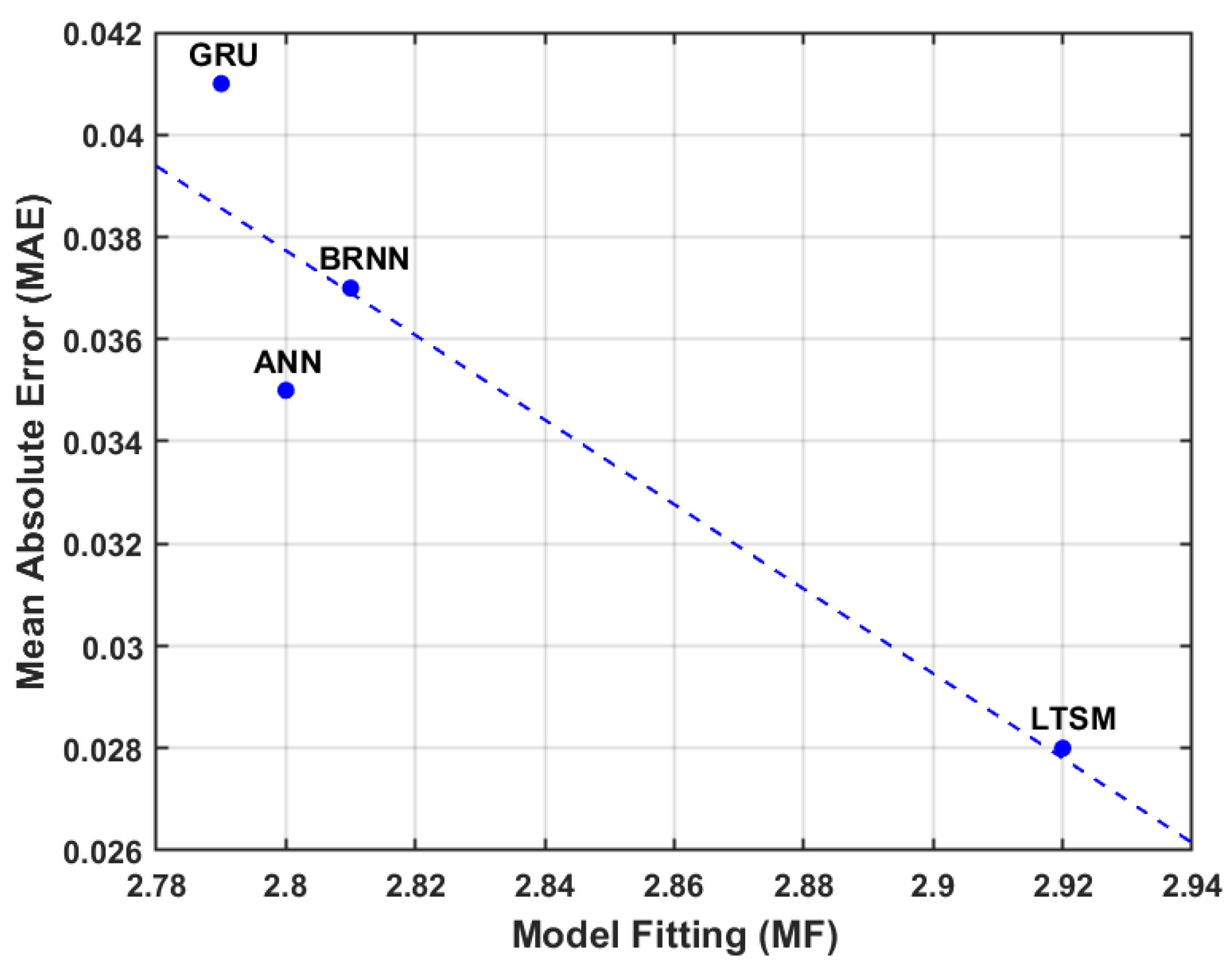
4.2. LSTM and GA Results
- Initial population: The range of time-lag to be tested is from 1 to 24. A binary vector randomly initializes using uniform distribution defined initial solution. The population is set to have 50 possible solutions.
- Selection: Select the best fitness values of two individuals from the population (parents).
- Crossover: Trade the variables between chosen parents to generate new off springs. One-point crossover is used for that.
- Mutation: A binary bit flip with probability of 0.1 is connected with the solution pool by arbitrarily swapping bits to realize differing qualities on the solutions.
- Fitness function: MAE is used to evaluate solution.
4.3. Parallel LSTM Results
4.4. Discussion
- (i)
- The statistical method depends on using mathematical function, autocorrelation function. It requires a prior knowledge about the data domain in order to select the proper parameter. It is good to capture the linear relationship between observations at time t and at previous time t − 1 and gives an obvious result about correlation between observations.
- (ii)
- GA is a heuristic algorithm that searches for optimal solution for a given problem by repeatedly applying specific operations on the population of the problem. The heuristic algorithm guarantees the generation of satisfactory solution, but it could not be the best. It is recommended to use it if the dataset of the given problem is not too big. The running time of GA is large, and it increases as the search space of the algorithm increases.
- (iii)
- The parallel implementation that searches for optimal time-lag dynamically is recommended if the parallel resources become available. It gives the best result from a given input range, and a high forecasting accuracy can be obtained from this method. For large dataset and big data problem, it is recommended to run such model on high-performance computers, such as super computers.
- (iv)
- Comparing methods in terms of processing time shows that LSTM with GA needs more time to generate accurate results. This is because GA is a search optimized algorithm, which searches for the optimal solution depends on the dataset size. For larger datasets, more time will be needed to guarantee the generation of optimal solution.
- (v)
- The experimental results show that heuristic algorithm could find the optimal time-lag value and it could be applied to LSTM, resulting the best prediction accuracy with lowest prediction error. This method can be applied to any time-series applications and complex data.
- (vi)
- Deciding which category (statistical or machine learning) of methods to be used for choosing time lag value depends on the dataset and linearity in the relationship between inputs and outputs. There are thousands of works in the literature that apply neural networks on the time-series forecasting. Few of these works investigate the effect of parameter selection on the forecasting accuracy and model performance. Recent studies such as [50] proposed the use of LSTM to analyze the changes in Air Quality Index and time-series data of Nanjing were used. The study in [51] combined Semi-Supervised Classification and Semi-Supervised Clustering machine learning methods for air pollutants prediction and showed how it can be used successfully for time-series prediction problem. The work in [52] compared statistical and deep learning methods in time-series forecasting. However, both statistical and deep learning methods (such as LSTM) are useful to be used in the time-series applications, a comparison between these methods can be investigated with respect to more than one consideration such as time-lag parameter selection. This is exactly what is investigated in this work.
- (vii)
- In the time-series applications, the default time-lag value used is usually one. Few studies aimed to find the optimal lag value to be used in the forecasting model where the model observations are highly correlated. Finding this value can be done using different methods as mentioned before. The aim of this research is to set up a vector between the determination strategies to contextualize which one is the best and for which setting.
- (viii)
- This study differs from other similar studies in the following aspects: (1) Dataset, the type of the data being used is PN concentrations in Amman, Jordan. (2) The setting of LSTM model which is used for the comparative analysis.
- (ix)
- The method used in this paper may be less efficient if the amount of dataset were massive. Additional experiments would be done by including more variables that may have impacts on the estimation of PN concentrations in Jordan and other different locations.
- (x)
- Despite differences between this study and other similar studies in the literature, the proposed results can be extended to be used into wider scientific areas especially in time-series forecasting applications.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fattah, J.; Ezzine, L.; Aman, Z.; El Moussami, H.; Lachhab, A. Forecasting of demand using ARIMA model. Int. J. Eng. Bus. Manag. 2018, 10, 1847979018808673. [Google Scholar] [CrossRef] [Green Version]
- Tealab, A.; Hefny, H.; Badr, A. Forecasting of nonlinear time series using ANN. Future Comput. Inform. J. 2017, 2, 39–47. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Precup, R.E.; Teban, T.A.; Albu, A.; Borlea, A.B.; Zamfirache, I.A.; Petriu, E.M. Evolving fuzzy models for prosthetic hand myoelectric-based control. IEEE Trans. Instrum. Meas. 2020, 69, 4625–4636. [Google Scholar] [CrossRef]
- Bengio, Y.; Boulanger-Lewandowski, N.; Pascanu, R. Advances in optimizing recurrent networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8624–8628. [Google Scholar]
- Amberkar, A.; Awasarmol, P.; Deshmukh, G.; Dave, P. Speech recognition using recurrent neural networks. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; pp. 1–4. [Google Scholar]
- Zaidan, M.A.; Motlagh, N.H.; Fung, P.L.; Lu, D.; Timonen, H.; Kuula, J.; Niemi, J.V.; Tarkoma, S.; Petäjä, T.; Kulmala, M.; et al. Intelligent calibration and virtual sensing for integrated low-cost air quality sensors. IEEE Sens. J. 2020, 20, 13638–13652. [Google Scholar] [CrossRef]
- Motlagh, N.H.; Lagerspetz, E.; Nurmi, P.; Li, X.; Varjonen, S.; Mineraud, J.; Siekkinen, M.; Rebeiro-Hargrave, A.; Hussein, T.; Petaja, T.; et al. Toward massive scale air quality monitoring. IEEE Commun. Mag. 2020, 58, 54–59. [Google Scholar] [CrossRef]
- Mahata, S.K.; Das, D.; Bandyopadhyay, S. Mtil2017: Machine translation using recurrent neural network on statistical machine translation. J. Intell. Syst. 2019, 28, 447–453. [Google Scholar] [CrossRef] [Green Version]
- Nabavi, S.A.; Motlagh, N.H.; Zaidan, M.A.; Aslani, A.; Zakeri, B. Deep Learning in Energy Modeling: Application in Smart Buildings with Distributed Energy Generation. IEEE Access 2021, 9, 125439–125461. [Google Scholar] [CrossRef]
- Nabavi, S.A.; Aslani, A.; Zaidan, M.A.; Zandi, M.; Mohammadi, S.; Hossein Motlagh, N. Machine learning modeling for energy consumption of residential and commercial sectors. Energies 2020, 13, 5171. [Google Scholar] [CrossRef]
- Belavadi, S.V.; Rajagopal, S.; Ranjani, R.; Mohan, R. Air quality forecasting using LSTM RNN and wireless sensor networks. Procedia Comput. Sci. 2020, 170, 241–248. [Google Scholar] [CrossRef]
- Moghar, A.; Hamiche, M. Stock market prediction using LSTM recurrent neural network. Procedia Comput. Sci. 2020, 170, 1168–1173. [Google Scholar] [CrossRef]
- Jammalamadaka, S.R.; Qiu, J.; Ning, N. Predicting a stock portfolio with the multivariate Bayesian structural time series model: Do news or emotions matter? Int. J. Artif. Intell. 2019, 17, 81–104. [Google Scholar]
- Nguyen, H.P.; Baraldi, P.; Zio, E. Ensemble empirical mode decomposition and long short-term memory neural network for multi-step predictions of time series signals in nuclear power plants. Appl. Energy 2021, 283, 116346. [Google Scholar] [CrossRef]
- Ghoniem, R.M.; Shaalan, K. FCSR-fuzzy continuous speech recognition approach for identifying laryngeal pathologies using new weighted spectrum features. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 9–11 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 384–395. [Google Scholar]
- Peng, L.; Liu, S.; Liu, R.; Wang, L. Effective long short-term memory with differential evolution algorithm for electricity price prediction. Energy 2018, 162, 1301–1314. [Google Scholar] [CrossRef]
- Feurer, M.; Hutter, F. Hyperparameter optimization. In Automated Machine Learning; Springer: Cham, Switzerland, 2019; pp. 3–33. [Google Scholar]
- Velliangiri, S.; Karthikeyan, P.; Xavier, V.A.; Baswaraj, D. Hybrid electro search with genetic algorithm for task scheduling in cloud computing. Ain Shams Eng. J. 2021, 12, 631–639. [Google Scholar] [CrossRef]
- Kan, X.; Fan, Y.; Fang, Z.; Cao, L.; Xiong, N.N.; Yang, D.; Li, X. A novel IoT network intrusion detection approach based on Adaptive Particle Swarm Optimization Convolutional Neural Network. Inf. Sci. 2021, 568, 147–162. [Google Scholar] [CrossRef]
- Wu, T.; Feng, F.; Lin, Q.; Bai, H. Advanced Method to Capture the Time-Lag Effects between Annual NDVI and Precipitation Variation Using RNN in the Arid and Semi-Arid Grasslands. Water 2019, 11, 1789. [Google Scholar] [CrossRef] [Green Version]
- Surakhi, O.M.; Zaidan, M.A.; Serhan, S.; Salah, I.; Hussein, T. An Optimal Stacked Ensemble Deep Learning Model for Predicting Time-Series Data Using a Genetic Algorithm—An Application for Aerosol Particle Number Concentrations. Computers 2020, 9, 89. [Google Scholar] [CrossRef]
- Zaidan, M.A.; Mills, A.R.; Harrison, R.F.; Fleming, P.J. Gas turbine engine prognostics using Bayesian hierarchical models: A variational approach. Mech. Syst. Signal Process. 2016, 70, 120–140. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Optimal deep learning lstm model for electric load forecasting using feature selection and genetic algorithm: Comparison with machine learning approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Lin, K.; Qi, Y.; Lian, Q.; Feng, S.; Wu, Z.; Pan, G. Estimating brain connectivity with varying-length time lags using a recurrent neural network. IEEE Trans. Biomed. Eng. 2018, 65, 1953–1963. [Google Scholar] [CrossRef]
- Lim, Y.B.; Aliyu, I.; Lim, C.G. Air Pollution Matter Prediction Using Recurrent Neural Networks with Sequential Data. In Proceedings of the 2019 3rd International Conference on Intelligent Systems, Metaheuristics & Swarm Intelligence, Male, Maldives, 23–24 March 2019; pp. 40–44. [Google Scholar]
- Zaidan, M.A.; Surakhi, O.; Fung, P.L.; Hussein, T. Sensitivity Analysis for Predicting Sub-Micron Aerosol Concentrations Based on Meteorological Parameters. Sensors 2020, 20, 2876. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef]
- Ribeiro, G.H.; Neto, P.S.d.M.; Cavalcanti, G.D.; Tsang, R. Lag selection for time series forecasting using particle swarm optimization. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 2437–2444. [Google Scholar]
- Reddy, D.M. Implication of ARIMA Time Series Model on COVID-19 Outbreaks in India. IJMH 2020, 4, 41–45. [Google Scholar] [CrossRef]
- Cortez, P. Sensitivity analysis for time lag selection to forecast seasonal time series using neural networks and support vector machines. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Xiao, Q.; Chaoqin, C.; Li, Z. Time series prediction using dynamic Bayesian network. Optik 2017, 135, 98–103. [Google Scholar] [CrossRef]
- Widodo, A.; Budi, I.; Widjaja, B. Automatic lag selection in time series forecasting using multiple kernel learning. Int. J. Mach. Learn. Cybern. 2016, 7, 95–110. [Google Scholar] [CrossRef]
- Fung, P.L.; Zaidan, M.A.; Surakhi, O.; Tarkoma, S.; Petäjä, T.; Hussein, T. Data imputation in in situ-measured particle size distributions by means of neural networks. Atmos. Meas. Tech. 2021, 14, 5535–5554. [Google Scholar] [CrossRef]
- Samanta, S.; Pratama, M.; Sundaram, S.; Srikanth, N. A Dual Network Solution (DNS) for Lag-Free Time Series Forecasting. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Hussein, T.; Atashi, N.; Sogacheva, L.; Hakala, S.; Dada, L.; Petäjä, T.; Kulmala, M. Characterization of urban new particle formation in Amman—Jordan. Atmosphere 2020, 11, 79. [Google Scholar] [CrossRef] [Green Version]
- Hussein, T.; Dada, L.; Hakala, S.; Petäjä, T.; Kulmala, M. Urban aerosol particle size characterization in Eastern Mediterranean conditions. Atmosphere 2019, 10, 710. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, D.E. Genetic Algorithms; Pearson Education India: London, UK, 2006. [Google Scholar]
- Slowik, A.; Kwasnicka, H. Evolutionary algorithms and their applications to engineering problems. Neural Comput. Appl. 2020, 32, 12363–12379. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Alnuweiri, H.; Wu, Y.; Li, H. Acceleration of back propagation through initial weight pre-training with delta rule. In Proceedings of the IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993; pp. 580–585. [Google Scholar]
- Idrissi, M.A.J.; Ramchoun, H.; Ghanou, Y.; Ettaouil, M. Genetic algorithm for neural network architecture optimization. In Proceedings of the 2016 3rd International Conference on Logistics Operations Management (GOL), Fez, Morocco, 23–25 May 2016; pp. 1–4. [Google Scholar]
- Lim, S.P.; Haron, H. Performance comparison of genetic algorithm, differential evolution and particle swarm optimization towards benchmark functions. In Proceedings of the 2013 IEEE Conference on Open Systems (ICOS), Kuching, Malaysia, 2–4 December 2013; pp. 41–46. [Google Scholar]
- Ashari, I.A.; Muslim, M.A.; Alamsyah, A. Comparison Performance of Genetic Algorithm and Ant Colony Optimization in Course Scheduling Optimizing. Sci. J. Inform. 2016, 3, 149–158. [Google Scholar] [CrossRef] [Green Version]
- Tarafdar, A.; Shahi, N.C. Application and comparison of genetic and mathematical optimizers for freeze-drying of mushrooms. J. Food Sci. Technol. 2018, 55, 2945–2954. [Google Scholar] [CrossRef]
- Song, M.; Chen, D. A comparison of three heuristic optimization algorithms for solving the multi-objective land allocation (MOLA) problem. Ann. GIS 2018, 24, 19–31. [Google Scholar] [CrossRef] [Green Version]
- Sachdeva, J.; Kumar, V.; Gupta, I.; Khandelwal, N.; Ahuja, C.K. Multiclass brain tumor classification using GA-SVM. In Proceedings of the 2011 Developments in E-systems Engineering, Dubai, United Arab Emirates, 6–8 December 2011; pp. 182–187. [Google Scholar]
- Swathy, M.; Saruladha, K. A comparative study of classification and prediction of Cardio-Vascular Diseases (CVD) using Machine Learning and Deep Learning techniques. ICT Express 2021. [Google Scholar] [CrossRef]
- Rashid, T.A.; Fattah, P.; Awla, D.K. Using accuracy measure for improving the training of LSTM with metaheuristic algorithms. Procedia Comput. Sci. 2018, 140, 324–333. [Google Scholar] [CrossRef]
- Zhoul, L.; Chenl, M.; Ni, Q. A hybrid Prophet-LSTM Model for Prediction of Air Quality Index. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 595–601. [Google Scholar]
- Bougoudis, I.; Demertzis, K.; Iliadis, L.; Anezakis, V.D.; Papaleonidas, A. Semi-supervised hybrid modeling of atmospheric pollution in urban centers. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2–5 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 51–63. [Google Scholar]
- Cecaj, A.; Lippi, M.; Mamei, M.; Zambonelli, F. Comparing deep learning and statistical methods in forecasting crowd distribution from aggregated mobile phone data. Appl. Sci. 2020, 10, 6580. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | Neural Network Model | Time-Lag Method | Application Domain |
|---|---|---|---|
| Surakhi, et al. [23] | Ensemble of three RNN variants | Heuristic algorithm | Air quality prediction |
| Zaidan, et al. [24] | Bayesian | Bayes’s rule | Aerospace gas turbine engines |
| Bouktif, et al. [25] | LSTM | Heuristic algorithm | Electric load forecasting |
| Wang, et al. [26] | LSTM | By experiment | Brain connectivity |
| Lim, et al. [27] | RNN | By experiment | Air pollution prediction |
| Zaidan, et al. [28] | ANN | Sensitive analysis | Air pollution prediction |
| Li, et al. [29] | LSTM | Autocorrelation Function | Air pollution prediction |
| Ribeiro, et al. [30] | MLP and SVM | Heuristic algorithm | Time-series forecasting |
| Reddy [31] | ARIMA | Autocorrelation function | COVID-19 cases prediction |
| Cortez [32] | NN and SVM | Backward selection search algorithm | Seasonal time-series |
| Xiao, et al. [33] | NN and Bayesian inference | Combination of KFM and ESN | Time-series data |
| Widodo, et al. [34] | SVM | Multiple kernel learning | Time-series data |
| Fung, et al. [35] | Feed-forward NN | By experiment | Air pollution prediction |
| Samanta, et al. [36] | Dual Network Solution | Moving Average Method | Wind Speed Prediction |
| PN | T | RH | P | WS | WD | |
|---|---|---|---|---|---|---|
| PN | 1 | −0.2475 | 0.0078 | 0.3389 | −0.3113 | −0.3320 |
| T | −0.2475 | 1 | −0.6909 | −0.4463 | 0.3105 | 0.2836 |
| RH | 0.0078 | −0.6909 | 1 | 0.1385 | −0.0094 | 0.0718 |
| P | 0.3389 | −0.4463 | 0.1385 | 1 | −0.3481 | −0.3323 |
| WS | −0.3113 | 0.3105 | −0.0094 | −0.3481 | 1 | 0.6794 |
| WD | −0.3320 | 0.2836 | 0.0718 | −0.3323 | 0.6794 | 1 |
| Network Parameter | Configuration |
|---|---|
| Number of hidden layers | 3 |
| Number of neurons at each hidden layer | 50, 50, 10 |
| Number of epochs | 500 |
| Optimizer | Adam |
| Batch size | 32 |
| Learning rate | 0.001 |
| Activation function | ReLU |
| Weight initialization | Normal distribution |
| Loss function | Mean square error |
| MAE | RMSE | MAPE | R-Sqaured |
|---|---|---|---|
| 0.020 | 0.022 | 0.053 | 0.90 |
| Time lag value | 22 | 23 | 24 |
| LSTM with GA (MAE) | 0.009 | 0.012 | 0.013 |
| Parallel LSTM (MAE) | 0.019 | 0.019 | 0.016 |
| LSTM with GA/Processing time | 19.423 | 23.604 | 29.183 |
| Parallel LSTM/Processing time | 24.745 | 25.254 | 29.678 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Surakhi, O.; Zaidan, M.A.; Fung, P.L.; Hossein Motlagh, N.; Serhan, S.; AlKhanafseh, M.; Ghoniem, R.M.; Hussein, T. Time-Lag Selection for Time-Series Forecasting Using Neural Network and Heuristic Algorithm. Electronics 2021, 10, 2518. https://doi.org/10.3390/electronics10202518
Surakhi O, Zaidan MA, Fung PL, Hossein Motlagh N, Serhan S, AlKhanafseh M, Ghoniem RM, Hussein T. Time-Lag Selection for Time-Series Forecasting Using Neural Network and Heuristic Algorithm. Electronics. 2021; 10(20):2518. https://doi.org/10.3390/electronics10202518
Chicago/Turabian StyleSurakhi, Ola, Martha A. Zaidan, Pak Lun Fung, Naser Hossein Motlagh, Sami Serhan, Mohammad AlKhanafseh, Rania M. Ghoniem, and Tareq Hussein. 2021. "Time-Lag Selection for Time-Series Forecasting Using Neural Network and Heuristic Algorithm" Electronics 10, no. 20: 2518. https://doi.org/10.3390/electronics10202518
APA StyleSurakhi, O., Zaidan, M. A., Fung, P. L., Hossein Motlagh, N., Serhan, S., AlKhanafseh, M., Ghoniem, R. M., & Hussein, T. (2021). Time-Lag Selection for Time-Series Forecasting Using Neural Network and Heuristic Algorithm. Electronics, 10(20), 2518. https://doi.org/10.3390/electronics10202518