
Blind Image Super Resolution Using Deep Unsupervised Learning



Abstract
:1. Introduction
- (1)
- A novel blind SR method with deep unsupervised learning, i.e., BSR-DUL, is proposed for simultaneously learning the latent HR image and the degradation operations without any external training samples and prior knowledge.
- (2)
- We leverage an encoder–decoder-based generative network for modeling the prior of the latent HR image, and a learnable depth-shared convolutional layer for automatic estimation of the degradation operation. Moreover, via combining these two components, we obtain an approximated LR image for formulating the loss function of the proposed unsupervised network with the LR observation only.
- (3)
- We investigate a joint optimization strategy to solve the BSR-DUL model for simultaneously generating the latent HR image, learning blur kernel and implementing the degradation operation, and thus establish an end-to-end blind SR learning framework, which can be adapted to super resolve the diverse LR observation captured under arbitrary imaging conditions.
2. Related Work
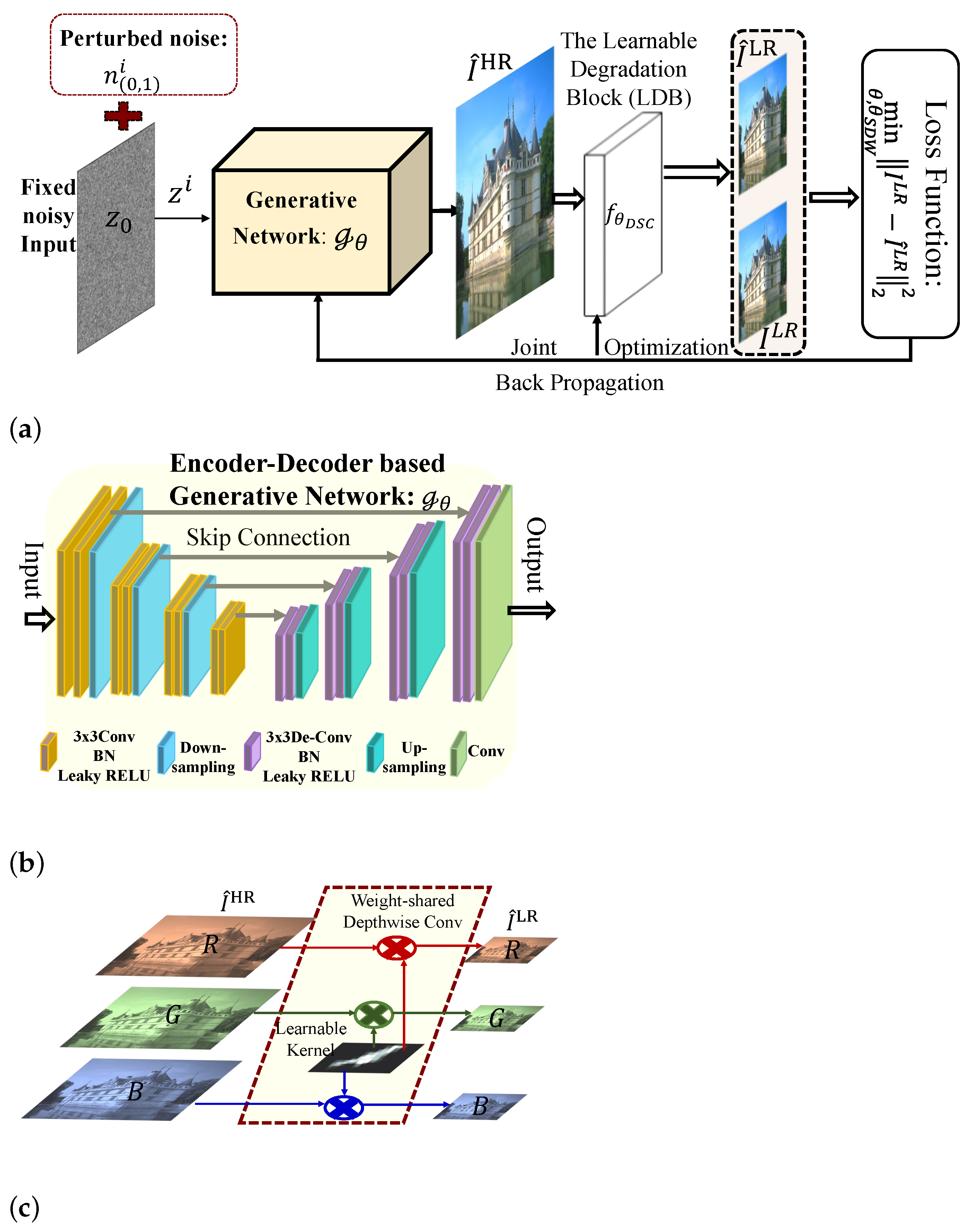
3. Blind Image SR Framework with Deep Unsupervised Learning
3.1. Problem Formulation
3.2. Motivation of the Proposed BSR-DUL
3.3. The Detailed Implementation of the Proposed BSR-DUL
| Algorithm 1 Joint Optimization for BSR-DUL. |
Input: the LR observation Output: the latent HR image Sample the base noise from uniform distribution for to max. iter. (T) do Sample the noise from uniform distribution Perturb with : Loss function of Equation (6): Compute the gradients w.r.t and Update and using the ADAM algorithm [59] end for |
4. Experimental Results
4.1. Experimental Settings
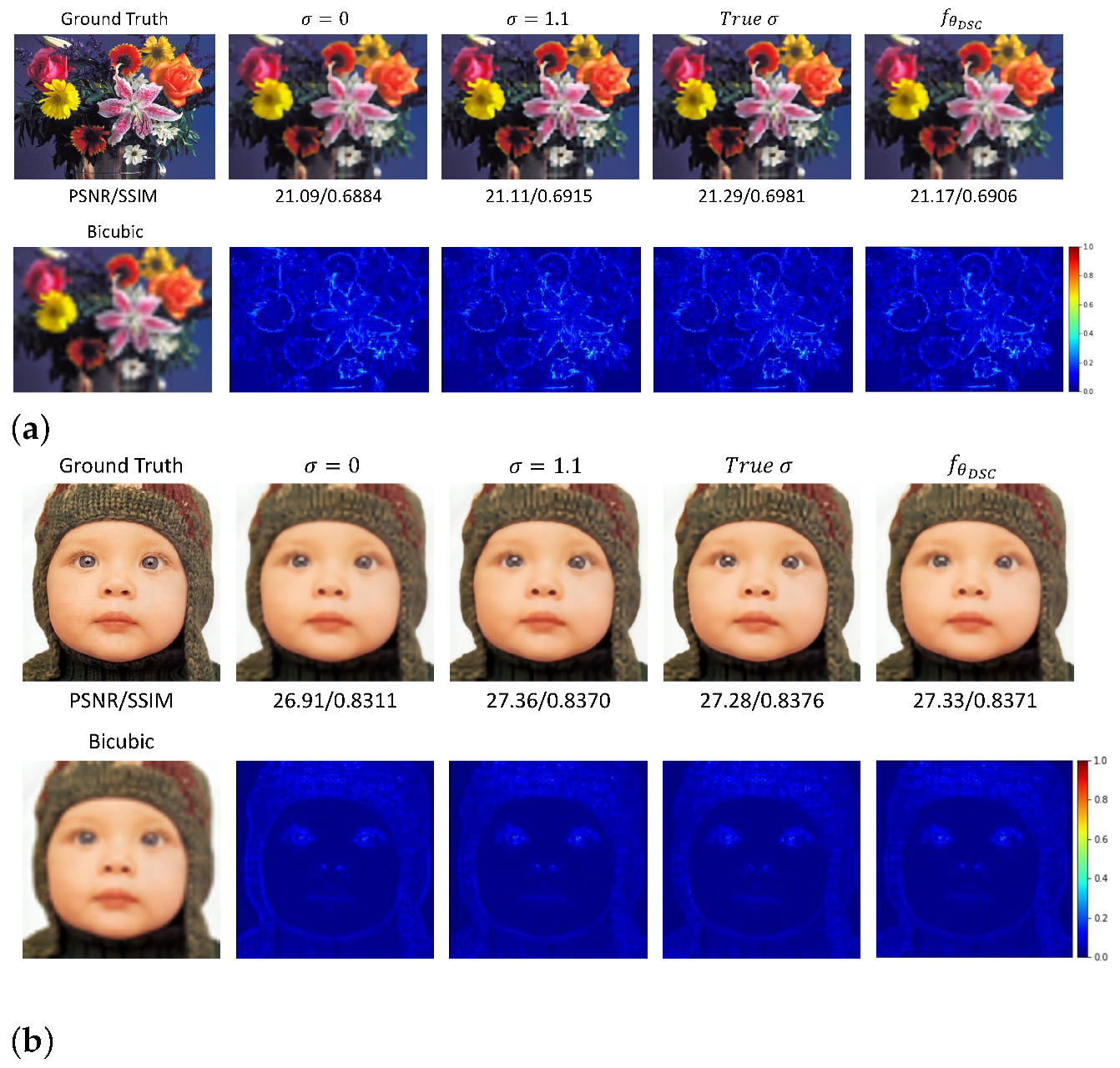
4.2. Compared Results on Different Degraded LR Images
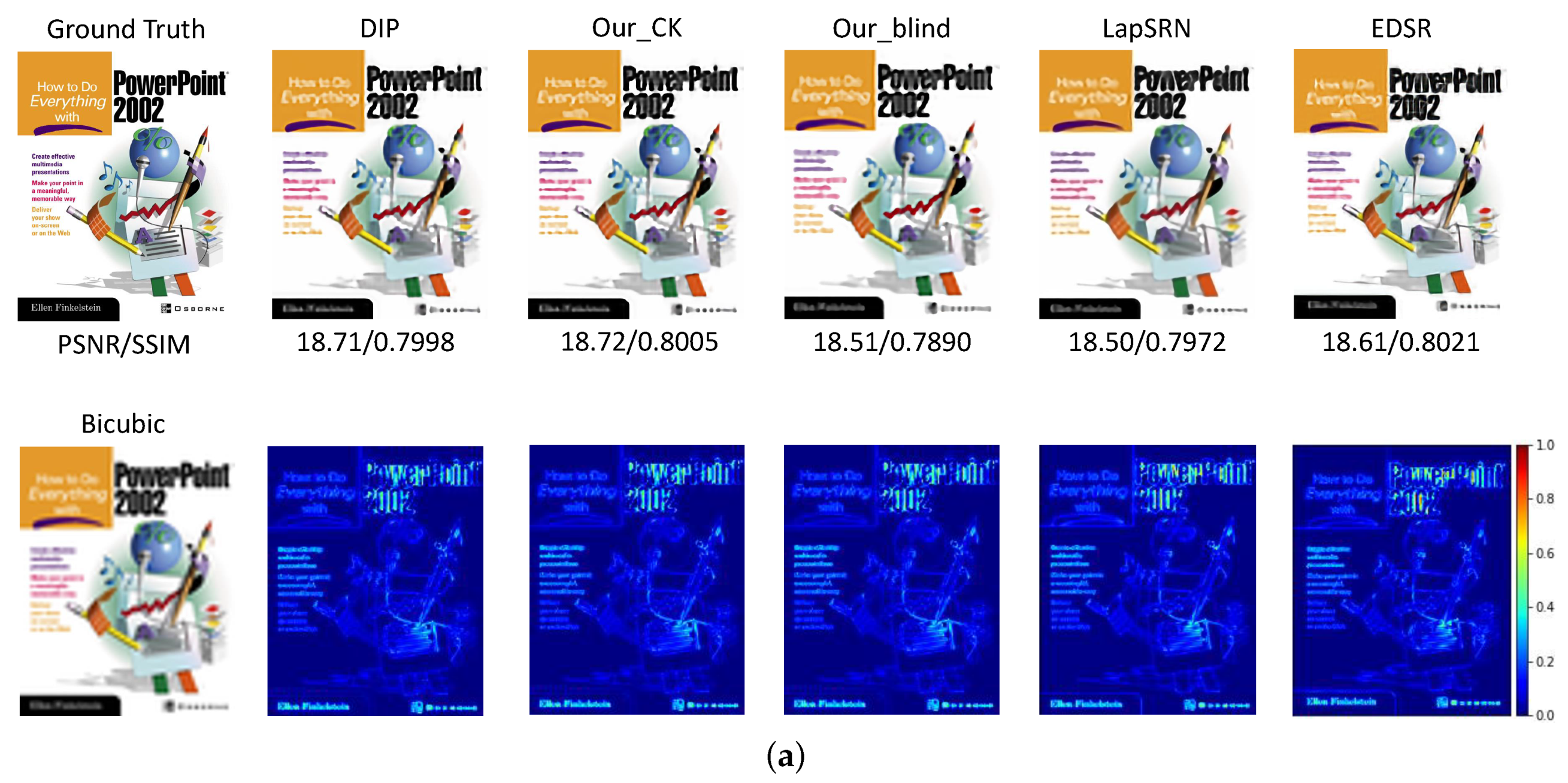
4.3. Comparison with State-of-the-Arts
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nasrollahi, T.; Moeslund, T.B. Super-resolution: A comprehensive survey. Mach. Vis. Appl. 2014, 25, 1423–1468. [Google Scholar] [CrossRef] [Green Version]
- Yang, Q.; Yang, R.; Davis, J.; Nister, D. Spatial-depth super Resolution for range images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 18–23 June 2007; pp. 1–7. [Google Scholar]
- Zou, W.W.W.; Yuen, P.C. Very Low Resolution Face Recognition Problem. IEEE Trans. Image Process. 2011, 21, 327–340. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Gao, X.; Tao, D.; Li, X. Single image super-resolution with non-local means and steering kernel regression. IEEE Trans. Image Process. 2012, 21, 4544–4556. [Google Scholar] [CrossRef] [PubMed]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. Int. Conf. Curves Surf. 2010, 6920, 711–730. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution based on Nonnegative Neighbor Embedding. Proc. Br. Mach. Vis. Conf. 2012, 135, 1–10. [Google Scholar]
- Begin, I.; Ferrie, F. Blind super-resolution using a learning-based approach. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 26 August 2004; Volume 2, pp. 85–89. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate superresolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 2. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z. Photorealistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4539–4547. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-local recurrent network for image restoration. arXiv 2018, arXiv:1806.02919. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-sr: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1575–1584. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image superresolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Ji, X.; Cao, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F. Real-World Super-Resolution via Kernel Estimation and Noise Injection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Chen, H.; He, X.; Qing, L.; Wu, Y.; Ren, C.; Zhu, C. Real-World Single Image Super-Resolution: A Brief Review. arXiv 2021, arXiv:2103.02368. [Google Scholar]
- He, H.; Siu, W.C. Single image super-resolution using gaussian process regression. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 449–456. [Google Scholar]
- He, Y.; Yap, K.H.; Chen, L.; Chau, L.P. A soft map framework for blind super-resolution image reconstruction. Image Vis. Comput. 2009, 27, 364–373. [Google Scholar] [CrossRef]
- Joshi, N.; Szeliski, R.; Kriegman, D.J. Psf estimation using sharp edge prediction. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Wang, Q.; Tang, X.; Shum, H. Patch based blind image super resolution. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–20 October 2005; Volume 1, pp. 709–716. [Google Scholar]
- Michaeli, T.; Irani, M. Nonparametric blind super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 945–952. [Google Scholar]
- Riegler, G.; Schulter, S.; Ruther, M.; Bischof, H. Conditioned regression models for non-blind single image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 522–530. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Dmitry, U.; Andrea, V.; Victor, L. Deep Image Prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Dmitry, U.; Andrea, V.; Victor, L. Deep Image Prior. arXiv 2017, arXiv:1711.10925. [Google Scholar]
- Dong, C.; Loy, C.C.; Tan, X. Accelerating the Super-Resolution Convolutional Neural Network. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 63–79. [Google Scholar]
- Sajjadi, M.S.M.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Cai, J.; Zeng, H.; Yong, H.; Cao, Z.; Zhang, L. Toward real-world single image super-resolution: A new benchmark and A new model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Gu, J.; Lu, H.; Zuo, W.; Dong, C. Blind super-resolution with iterative kernel correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1604–1613. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Deep plug-and-play super-resolution for arbitrary blur kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Timofte, R.; Fritsche, M.; Gu, S.; Purohit, K.; Irani, M. Aim 2019 challenge on real-world image super-resolution: Methods and results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Unsupervised dual learning for image-to-image translation. arXiv 2017, arXiv:1704.02510. [Google Scholar]
- Yuan, Y.; Liu, S.; Zhang, J.; Zhang, Y.; Dong, C.; Lin, L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhao, T.; Ren, W.; Zhang, C.; Ren, D.; Hu, Q. Unsupervised degradation learning for single image super-resolution. arXiv 2018, arXiv:1812.04240. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Timofte, R. Unsupervised learning for real-world super-resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Fritsche, M.; Gu, S.; Timofte, R. Frequency separation for real-world super-resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Bulat, A.; Yang, J.; Tzimiropoulos, G. To learn image super-resolution, use a gan to learn how to do image degradation first. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, S.; Han, Z.; Dai, E.; Jia, X.; Liu, Z.; Liu, X.; Zou, X.; Xu, C.; Liu, J.; Tian, Q. Unsupervised Image Super-Resolution with an Indirect Supervised Path. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Shocher, A.; Cohen, N.; Irani, M. “Zero-shot” super-resolution using deep internal learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3118–3126. [Google Scholar]
- Soh, J.W.; Cho, S.; Cho, N.I. Meta-Transfer Learning for Zero-Shot Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3516–3525. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-To-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. arXiv 2019, arXiv:1805.08318. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv 2018, arXiv:1710.10196. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial Feature Learning. arXiv 2017, arXiv:1605.09782. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv 2019, arXiv:1812.04948. [Google Scholar]
- Tseng, P. Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 2001, 109, 475–494. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lererr, A. Automatic differentiation in pytorch. In Proceedings of the NIPS Workshop: The Future of Gradient-Based Machine Learning Software and Techniques, Los Angles, CA, USA, 8–9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representation, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and meauring ecological statics. In Proceedings of the International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Factor | Correct Kernel | Wrong Kernel | Learnable |
|---|---|---|---|---|
| Set5 | X4 | 28.36/0.9049 | 19.10/0.6965 | 27.31/0.9053 |
| X8 | 24.25/0.7944 | 19.00/0.6475 | 23.35/0.7750 | |
| Set14 | X4 | 25.14/0.8144 | 18.31/0.6398 | 23.41/0.8107 |
| X8 | 23.37/0.7046 | 18.48/0.5950 | 20.84/0.6896 | |
| B100 | X4 | 25.16/0.7869 | 19.60/0.6452 | 23.11/0.7858 |
| X8 | 23.02/0.6824 | 20.02/0.6083 | 20.82/0.6751 |
| Semi-Blind | Blind | ||||
|---|---|---|---|---|---|
| Dataset | Known DS and Gaussian Kernel with Different | Unknown Kernel | |||
| = 0 | = 1.1 | True | |||
| = 1.0 | 24.17/0.7895 | 24.34/0.7962 | 24.39/0.7976 | 24.07/0.7875 | |
| = 1.2 | 24.00/0.7846 | 24.34/0.8087 | 24.44/0.8000 | 23.84/0.7789 | |
| = 1.5 | 23.83/0.7786 | 24.24/0.7911 | 24.36/0.7962 | 23.62/0.7812 | |
| Set5 | = 2.0 | 23.73/0.7732 | 24.25/0.7918 | 24.38/0.7968 | 23.84/0.7886 |
| = 2.5 | 21.42/0.6913 | 21.84/0.7055 | 23.73/0.7716 | 21.54/0.7000 | |
| = 3.0 | 20.77/0.668 | 21.05/0.6776 | 23.09/0.7464 | 20.80/0.6719 | |
| = 1.0 | 22.17/0.6951 | 22.30/0.6912 | 22.45/0.7052 | 22.10/0.6971 | |
| = 1.2 | 22.12/0.6925 | 22.38/0.7030 | 22.46/0.7041 | 21.87/0.6902 | |
| = 1.5 | 22.05/0.6898 | 22.28/0.6988 | 22.45/0.7043 | 20.88/0.6897 | |
| Set14 | = 2.0 | 21.99/0.6867 | 22.33/0.6995 | 22.41/0.7029 | 21.12/0.6940 |
| = 2.5 | 20.43/0.6314 | 20.74/0.6407 | 22.03/0.6821 | 19.66/0.6355 | |
| = 3.0 | 19.92/0.6145 | 19.92/0.6145 | 21.69/0.6673 | 19.27/0.6163 | |
| Datasets | |||||||
|---|---|---|---|---|---|---|---|
| Categories | Methods | Set5 | Set14 | BSD100 | |||
| X4 | X8 | X4 | X8 | X4 | X8 | ||
| Bicubic | 26.71/0.8660 | 22.74/0.7278 | 24.20/0.7860 | 21.37/0.6624 | 24.78/0.7725 | 22.48/0.6618 | |
| Unsuper | TV_Prior | 26.66/0.8761 | 23.01/0.7433 | 24.34/0.7870 | 21.60/0.6761 | - | - |
| Non-Blind | DIP [30] | 27.93/0.8928 | 24.04/0.7828 | 25.01/0.8030 | 22.17/0.6953 | 25.15/0.7862 | 23.01/0.6859 |
| ZSSR_CK [49] | 28.85/0.8009 | 24.18/0.6272 | 26.86/0.7381 | 23.07/0.5627 | −/− | ||
| Our_CK | 28.36/0.9049 | 24.25/0.7944 | 25.14/0.8144 | 23.37/0.7046 | 25.19/0.7919 | 23.02/0.6824 | |
| Unsuper | Our_blind | 27.31/0.9053 | 23.73/0.7876 | 23.41/0.8107 | 20.84/0.6896 | 23.11/0.7858 | 20.82/0.675 |
| Blind | |||||||
| Super | LapSRN [10] | 29.36/0.9196 | 24.22/0.7913 | 25.90/0.8327 | 22.43/0.7061 | 25.97/0.8115 | 23.21/0.6926 |
| Non-Blind | EDSR [15] | 29.99/0.9275 | 24.25/0.7959 | 26.37/0.8441 | 22.39/0.7060 | 26.20/0.8178 | 23.05/0.6890 |
| Factors | = 0 | = 0.01 | = 0.03 | = 0.05 | = 0.08 |
|---|---|---|---|---|---|
| X4 | 25.80/0.8567 | 26.93/0.8932 | 27.31/0.9053 | 26.88/0.8989 | 26.25/0.8850 |
| X8 | 22.07/0.7176 | 23.62/0.7900 | 23.73/0.7876 | 23.35/0.7750 | 23.18/0.7651 |
| Optimizers | SGD | Adadelta | Adagrad | ADAM |
|---|---|---|---|---|
| 17.67/0.5862 | 18.22/0.5950 | 21.38/0.7474 | 23.73/0.7876 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamawaki, K.; Sun, Y.; Han, X.-H. Blind Image Super Resolution Using Deep Unsupervised Learning. Electronics 2021, 10, 2591. https://doi.org/10.3390/electronics10212591
Yamawaki K, Sun Y, Han X-H. Blind Image Super Resolution Using Deep Unsupervised Learning. Electronics. 2021; 10(21):2591. https://doi.org/10.3390/electronics10212591
Chicago/Turabian StyleYamawaki, Kazuhiro, Yongqing Sun, and Xian-Hua Han. 2021. "Blind Image Super Resolution Using Deep Unsupervised Learning" Electronics 10, no. 21: 2591. https://doi.org/10.3390/electronics10212591
APA StyleYamawaki, K., Sun, Y., & Han, X. -H. (2021). Blind Image Super Resolution Using Deep Unsupervised Learning. Electronics, 10(21), 2591. https://doi.org/10.3390/electronics10212591