
Human Action Recognition of Spatiotemporal Parameters for Skeleton Sequences Using MTLN Feature Learning Framework



Abstract
:1. Introduction
- We generate points for frames from various human actions as input that originate from datasets.
- We develop a new deep CNN network model to transform each skeleton sequence. By learning from the hierarchical structure of deep CNNs, we enable long-term temporal modeling of the skeleton structure for frame images.
- We create an MTLN to pick up the skeleton structure’s spatial configuration and material factors to produce the CNN frames.
- Our experimental results prove that MTLN achieves improvement compared to concatenating or pooling the features of the frames.
- For better and efficient results, we implement AlexNet in the proposed network model. The final results also show the significance of our methodology.
- Standard datasets are used to establish the presence of the proposed model. Some classic procedures are implemented for comparison.
2. Related Work
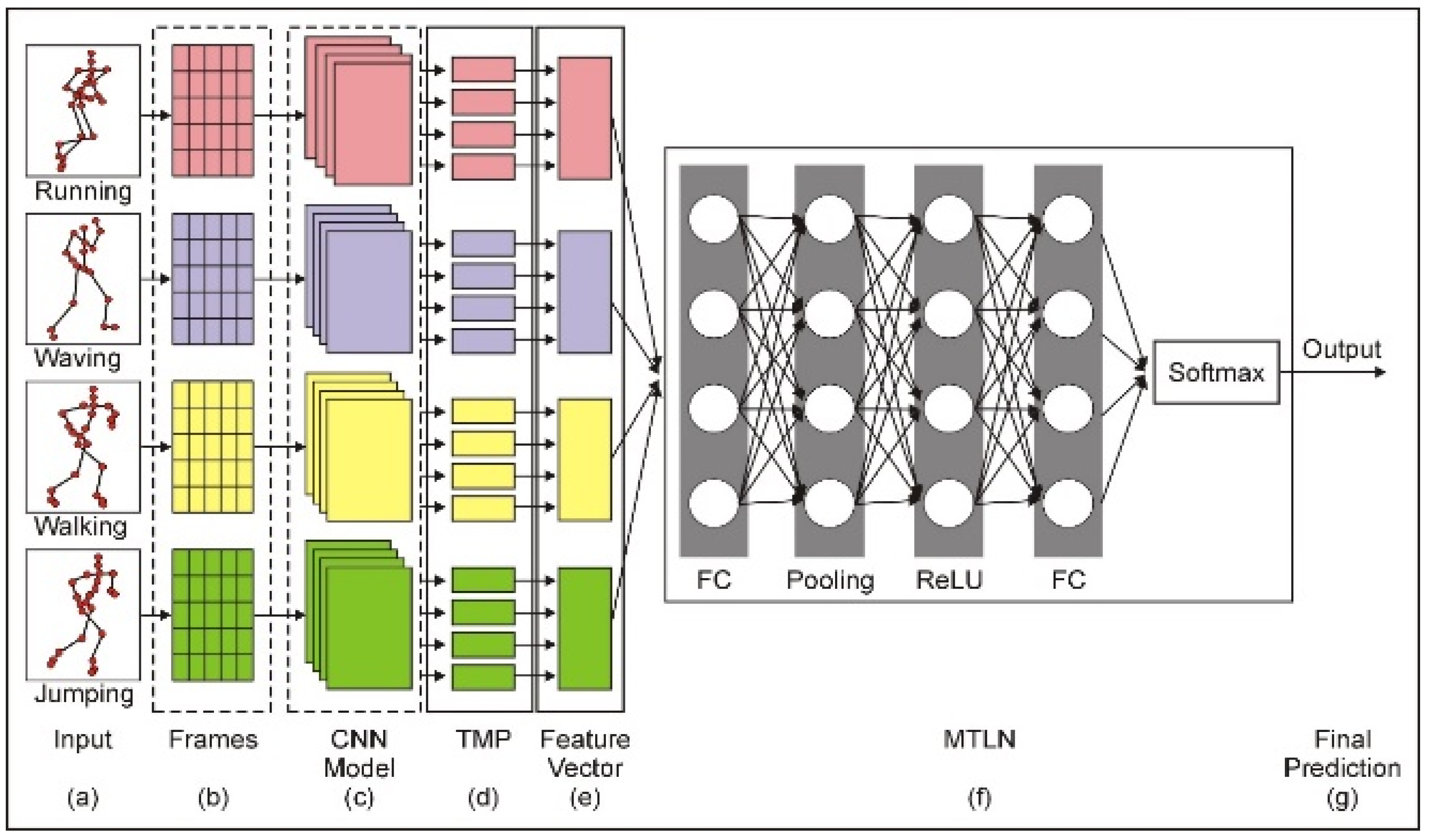
3. Proposed Methodology
3.1. Implementation Details
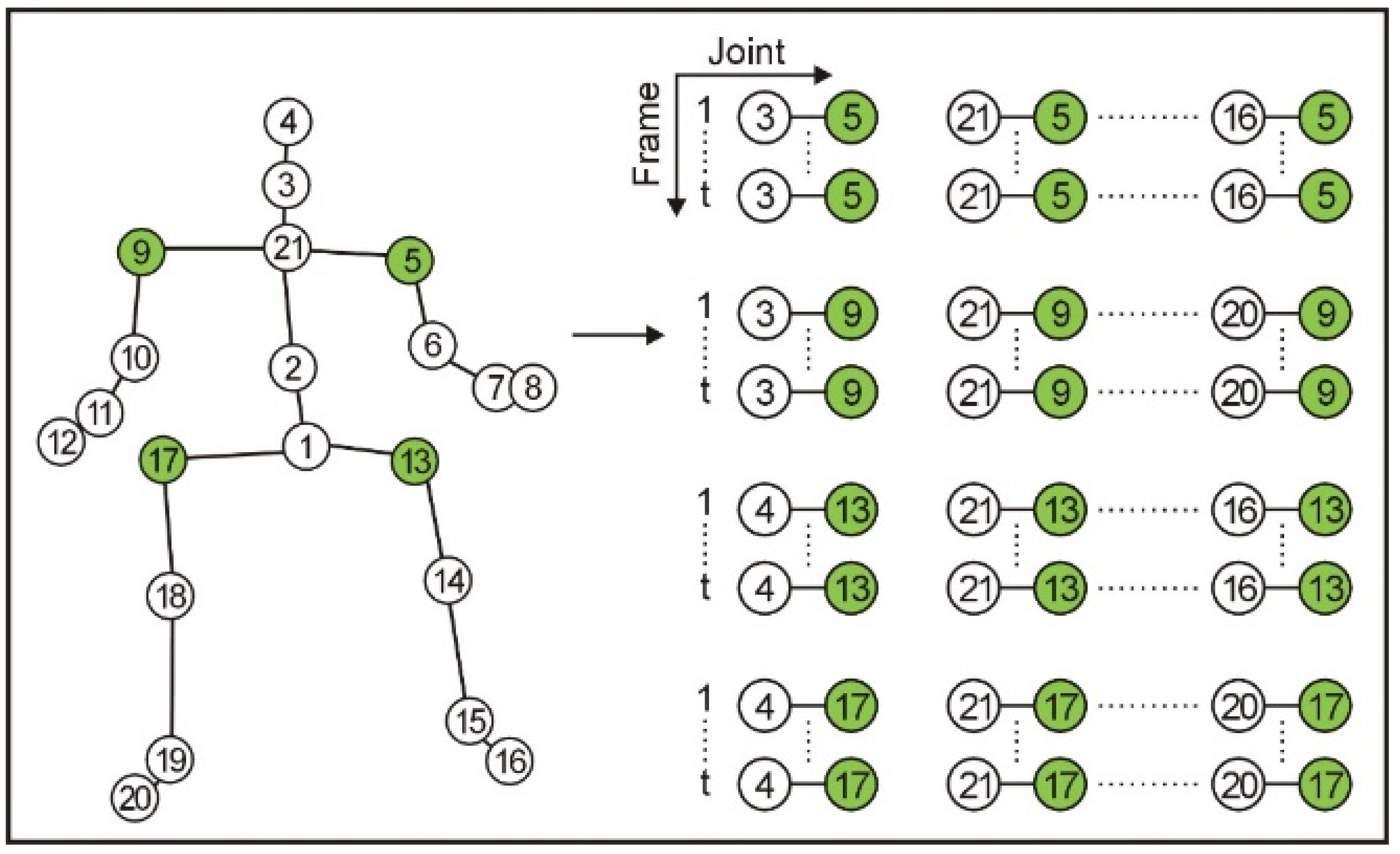
3.2. Frame Process
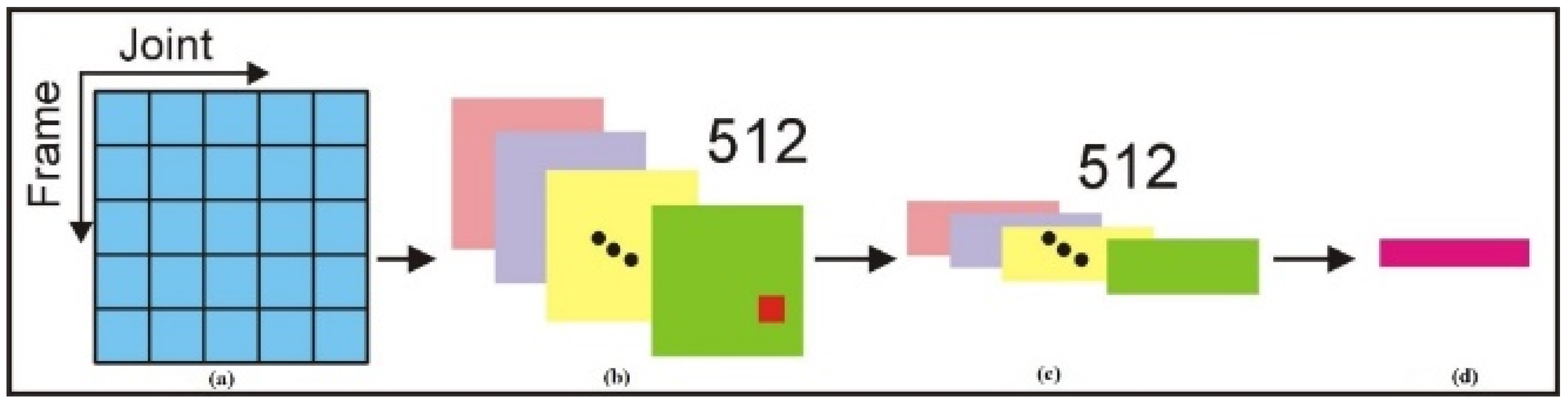
3.3. CNN Training for Feature Extraction
3.4. Multi-Task Learning Network
3.5. Architecture of Network
4. Experiments
Datasets
- The NTU RGB+D dataset [27] is currently the largest dataset for action recognition with more than 56,000 sequences and four million frames. The applied dataset has 50 different human poses and 70 class actions with 40 regular action classes. Cross-subject (CS) and cross-view (CV) are the two suggested elevation protocols. In general, at the beginning of our research, we followed the settings of [27]. In the CS evaluation, 40,500 samples from 40 subjects were used for training a planned model, using the other 18,540 examples for analysis. For the cross-view evaluation, 38,700 samples were taken from the second camera, while the third camera was used for training the model and analyzing the other 18,600 samples from camera 1.
- The SBU Kinect Interaction dataset [39] contains 280 skeleton sequences and 6810 frames. We followed the regular research protocol of fivefold cross-validation with delivered splits, yielding eight classes. In each skeleton, frames had two people, and 15 joints were labeled for each person. While training, two samples were used for two skeleton sequences. While testing, the average forecast score was calculated. During the training process, random collection was used to augment data. Five recent crops were taken for prediction scores, and four corners were averaged for the testing calculation.
- Kinetics-Motion [45], the most significant RGB action recognition dataset, has 400 action classes, including three lac video clips. Videos were downloaded from YouTube, and each clip has a 10 s duration. Yan et al. [38] provided estimated poses for action recognition based on joints. In the first step, videos were resized to 340,256 pixel resolution at 30 frames per second. Furthermore, an OpenPose toolbox was used Hu, et al., 2016 which cannot separate the particular classes of RGB action recognition datasets because it has no background context and image presence. Yan et al. [38] proposed a Kinetics-Motion dataset, a 30-class subset of Kinetics with action labels associated with body movement. We followed the suggested process on the Kinetics-Motion dataset. The 30 classes were skateboarding, tai chi hopscotch, pull-ups, capoeira, punching bag, squat, deadlifting, clean and jerk, push up, punching bag, belly dancing, country line dancing, surfing crowd, swimming backstroke, front raises, crawling baby, windsurfing, skipping rope, throwing discus, snatch weight lifting tobogganing, hitting a baseball, roller skating, arm wrestling, riding a mechanical bull, salsa dancing, hurling (sport), lunge, hammer throw, and juggling balls.
- The SYSU-3D dataset [51] contains 480 sequences and 12 distant actions executed by 40 people. Twenty joints from each frame of the series were connected with 3D coordinates. We set a 0.2 ration of training and validation datasets for the random split of the data, the same ration is used by existing studies [52,53].
- UCF101-Motion [24] contains 13,300 videos from 100 action classes fixed at 320 × 240 pixel resolution at 25 FPS. At the same time, as input RGB videos, approximately 16 joint actions were taken using the AlphaPose toolbox. Similarly to Kinetics-Motion, in UCF101, predefined actions such as “cutting in the kitchen” are more closely related to items and actions. To verify this, we followed the method in ST-GCN [38] and established a subset of UCF-101 named “UCF-Motion”. UCF-Motion has 24 classes associated with the poses in a total of 3170 videos: jump rope, playing the piano, crawling baby, playing the flute, playing the cello, punch, tai chi, boxing speed bag, pushups, juggling balls, golf swing, clean and jerk, playing the guitar, bowling, ice dancing, playing soccer juggling, playing dhol, the tabla, boxing punching bag, salsa spins, hammer throw, rafting, and writing on board.
5. Experiment Results and Analysis
5.1. Data Preprocessing
- All frames were created from the original skeleton sequence with preprocessing steps such as temporal downsampling, noise filtering, and normalization.
- In the first FC, the layer had 512 hidden units. In the second FC layer (i.e., the output layer), the action classes in each dataset and the number of the units were identical. The network was trained using the stochastic gradient descent algorithm at a training rate of 0.002 with 200 batch sizes and 50 epochs used in preparing the model.
- The performance of the developed model on each dataset was compared with existing methods.
5.2. Classification Report
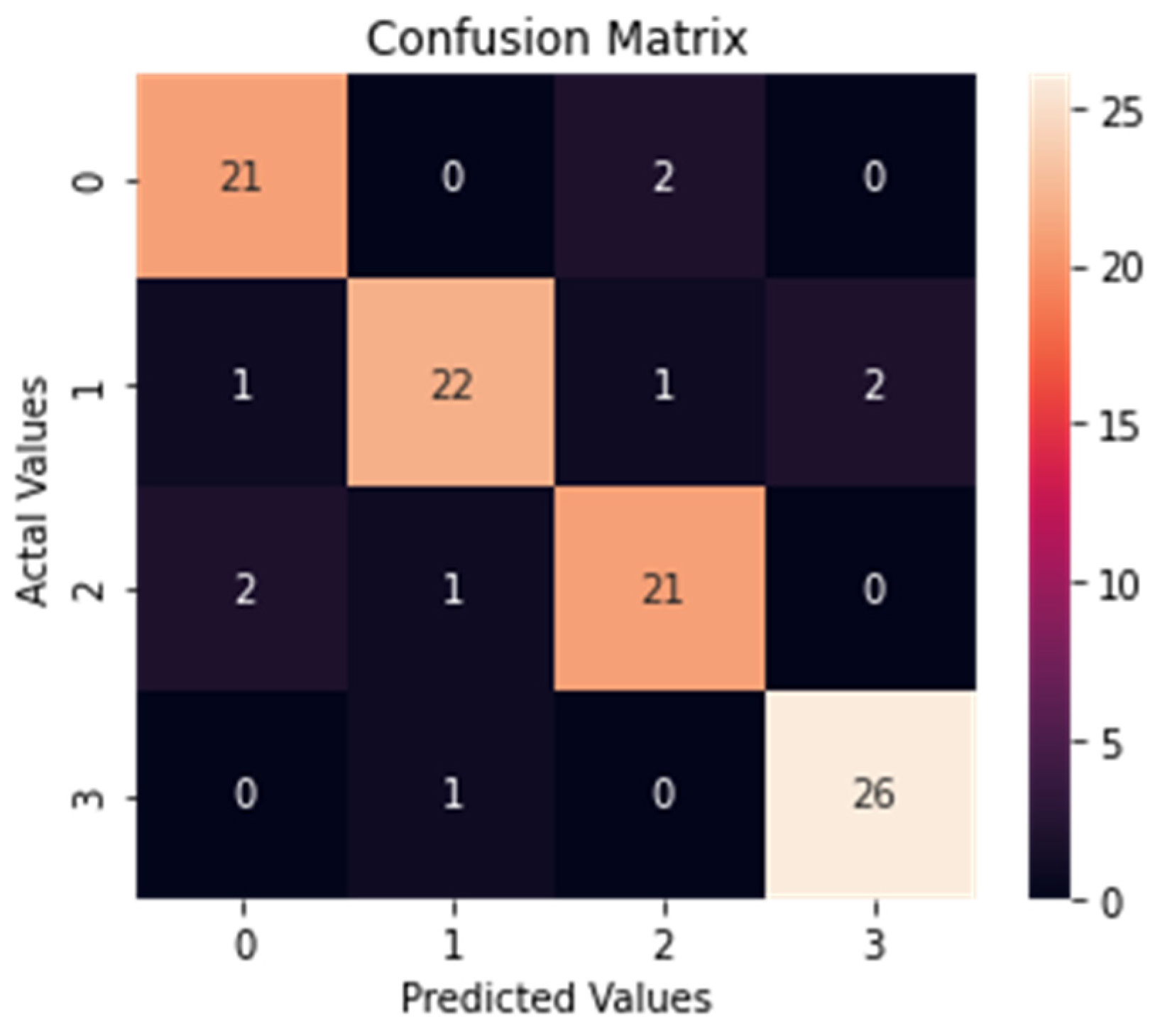
5.3. Confusion Matrix
5.4. Comparison with Different Models for Action Recognition
5.5. Comparison with State-of-the-Art Methods
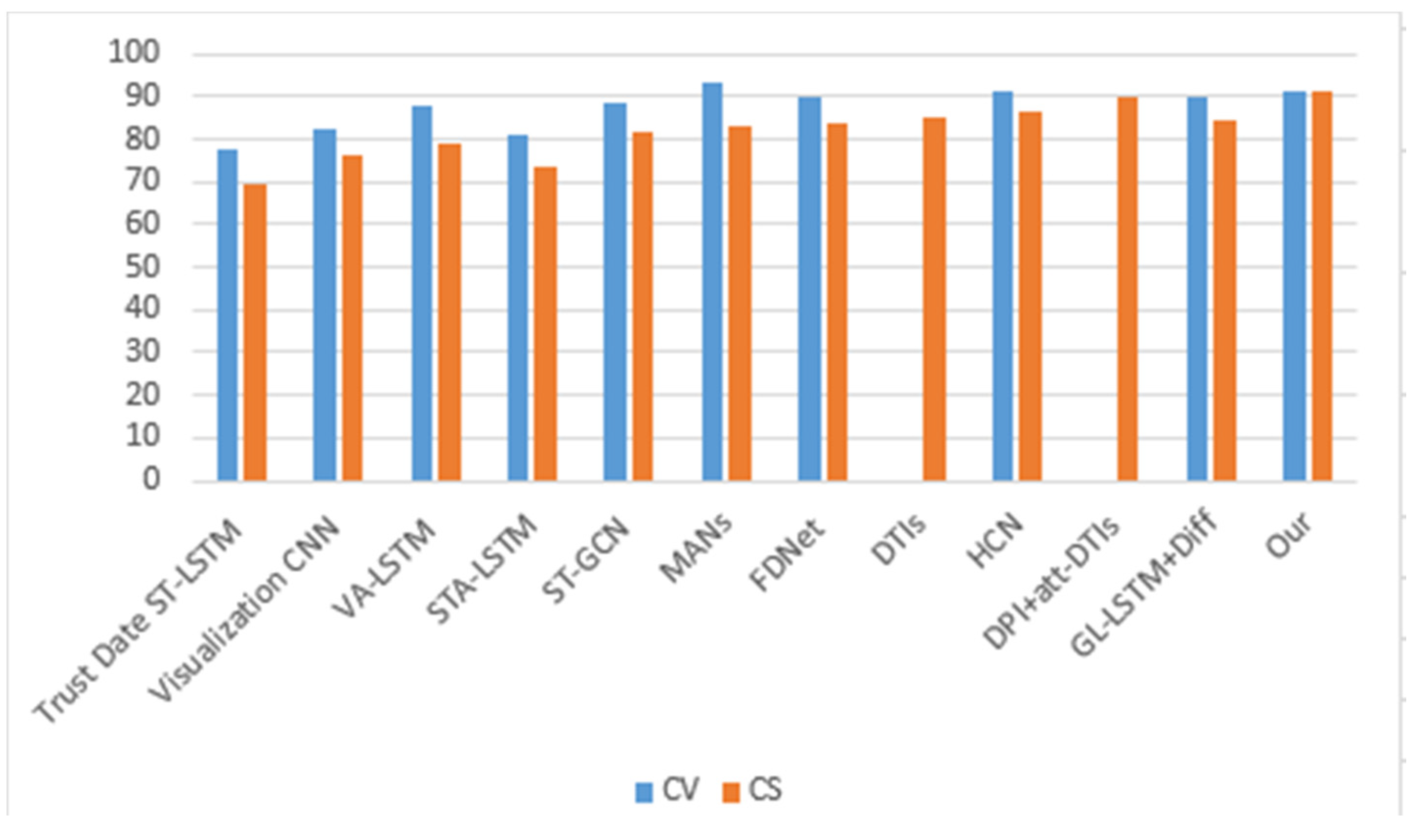
- The NTU RGB+D dataset (Table 3) is currently the most extensive dataset; the proposed model achieved greater recognition accuracy than previous approaches, showing a 0.3% enhancement compared to previous CNN-based models for cross-view evaluation. We compared our model-generated accuracy with the latest DPI + att-DTIs-based model, showing a 1.1% improvement (Table 3).
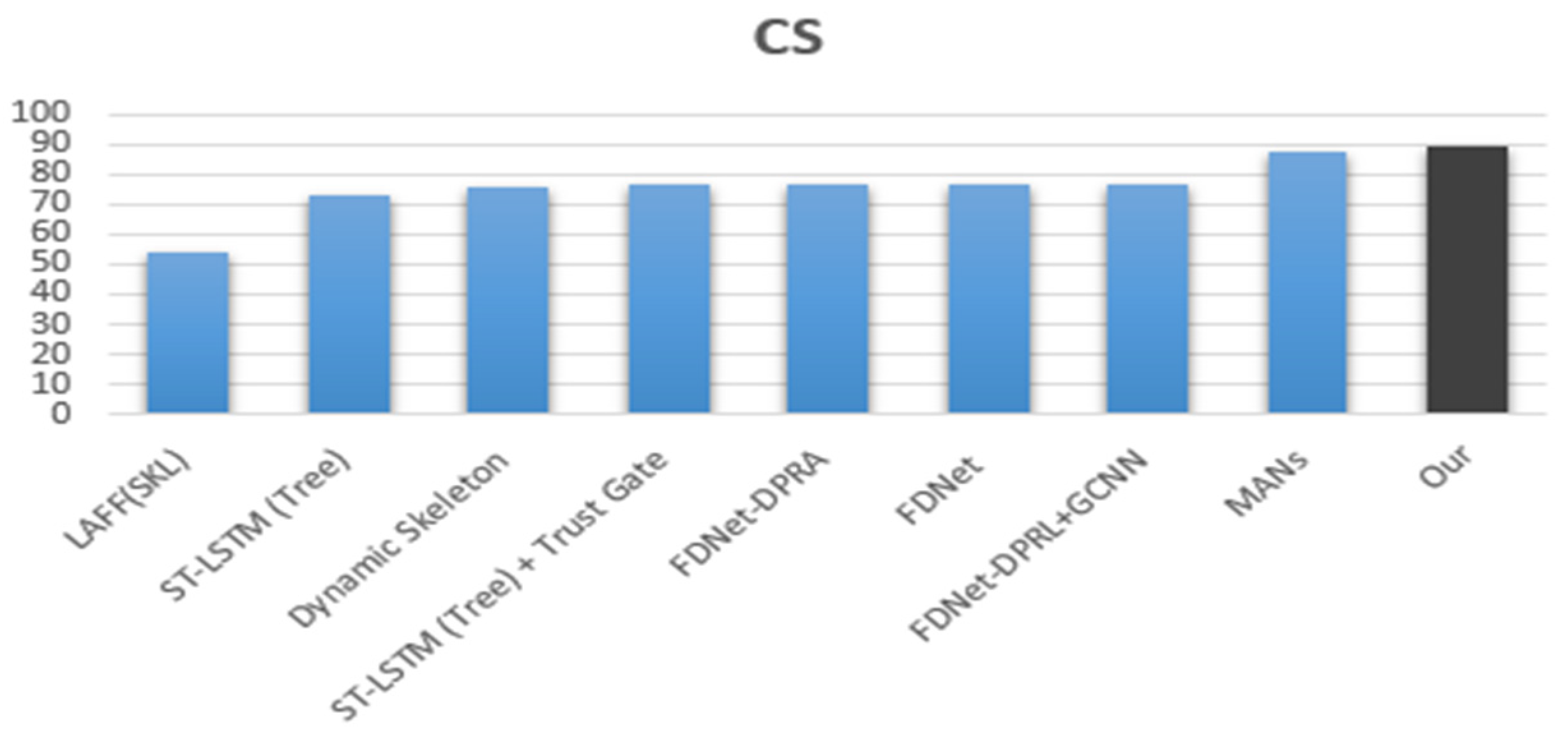
- Using the SUSU-3D dataset (Table 4), our proposed model improved the recognition accuracy compared to previous models by a considerable margin, e.g., 1.6% compared with the well-known MANs [55] model. This demonstrates that our suggested model can thoroughly explore the characteristics of skeleton-based sequences to complete the action recognition test at a high level.
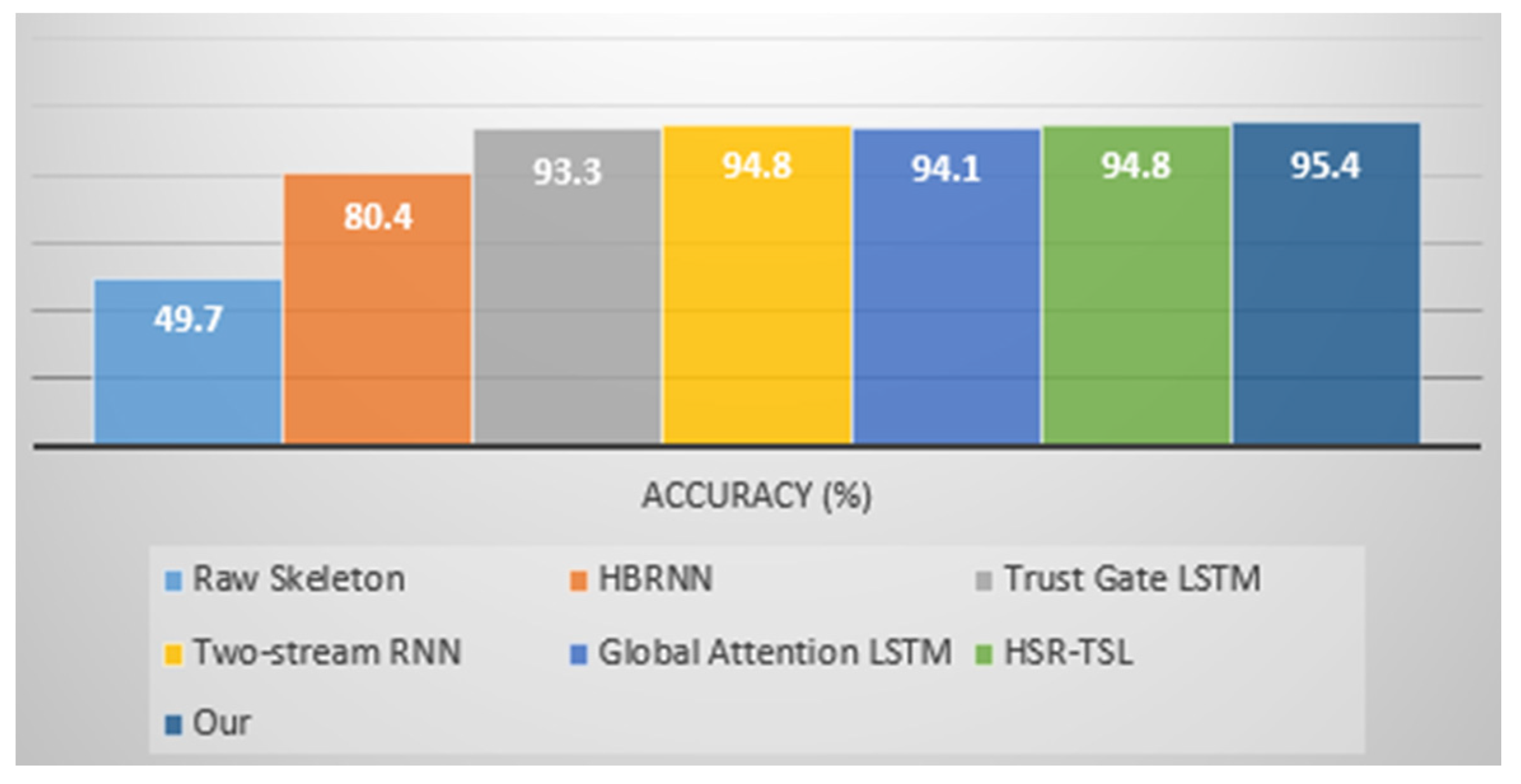
- For the SBU Kinect Interaction, the MTLN approach exceeded the performance of other studies in the literature in terms of recognition accuracy, similarly to the NTU RGB+D dataset. Our model achieved 95.4% ± 1.7% accuracy across the five splits in the case of SBU Kinect Interaction presented in Table 5 and Figure 7.
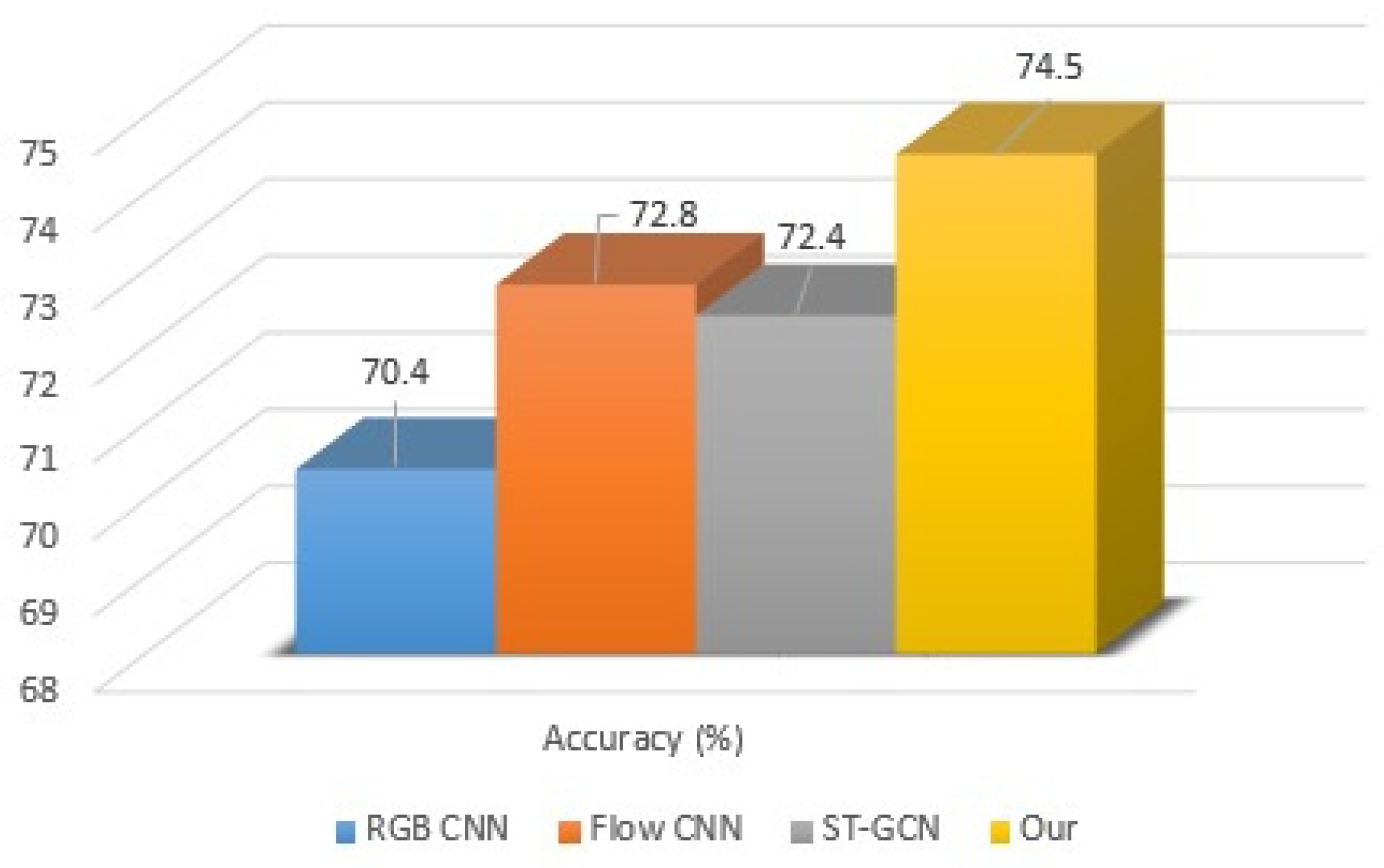
- For Kinetics-Motion (Table 6), the previously developed models showed inferior performance to our proposed model using MTLN [60]. The accuracy of recognition was also comparable to systems using other modalities such as RGB and optical flow. The proposed model was robust toward noise, whereas deficiencies were commonly produced due to missing or improper pose estimates (Figure 8).
- For UCF101-Motion (Table 7), the proposed approach outperformed existing algorithms that only used one modality [28,31] or both the presence feature and optical flow [61]. This experiment demonstrates that joints are a natural modality for identifying motion associated with actions, but that joints alone cannot distinguish all unique action classes (Figure 9). Knowing specific categories requires an object and part appearances, whereas incorrect pose estimation decreases the limit of recognition accuracy (Figure 9). Performance can be improved using our model.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Year | CS |
|---|---|---|
| LAFF(SKL) [61] | 2016 | 54.2 |
| ST-LSTM (Tree) [62] | 2017 | 73.4 |
| Dynamic Skeleton [50] | 2015 | 75.5 |
| ST-LSTM (Tree) + Trust Gate [62] | 2017 | 76.5 |
| FDNet-DPRA [56] | 2018 | 76.7 |
| FDNet [56] | 2018 | 76.9 |
| FDNet DPRL + GCNN [63] | 2018 | 76.9 |
| MANs [55] | 2018 | 87.6 |
| Our model | - | 89.2 |
| Methods | Accuracy (%) |
|---|---|
| Raw Skeleton [39] | 49.7 |
| HBRNN [2] | 80.4 |
| Trust Gate LSTM [5] | 93.3 |
| Two-stream RNN [35] | 94.8 |
| Global Attention LSTM [33] | 94.1 |
| HSR-TSL [64] | 94.8 |
| Our model | 95.4 |
| Methods | Accuracy (%) |
|---|---|
| RGB CNN [45] | 70.4 |
| Flow CNN [45] | 72.8 |
| ST-GCN [38] | 72.4 |
| Our model | 74.5 |
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Han, F.; Reily, B.; Hoff, W.; Zhang, H. Space-time representation of people based on 3D skeletal data: A review. Comput. Vis. Image Underst. 2017, 158, 85–105. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Ke, Q.; An, S.; Bennamoun, M.; Sohel, F.; Boussaid, F. Skeletonnet: Mining deep part features for 3-d action recognition. IEEE Signal Process. Lett. 2017, 24, 731–735. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Li, Z.; Hou, Y.; Li, W. Action recognition based on joint trajectory maps using convolutional neural networks. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 102–106. [Google Scholar]
- Cregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Ke, Q.; Li, Y. Is rotation a nuisance in shape recognition? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 4146–4153. [Google Scholar]
- Fernando, B.; Gavves, E.; Oramas, J.M.; Ghodrati, A.; Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5378–5387. [Google Scholar]
- Gaidon, A.; Harchaoui, Z.; Schmid, C. Temporal localization of actions with actions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2782–2795. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ke, Q.; Bennamoun, M.; An, S.; Boussaid, F.; Sohel, F. Human interaction prediction using deep temporal features. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 403–414. [Google Scholar]
- Niebles, J.C.; Chen, C.-W.; Fei-Fei, L. Modeling temporal structure of decomposable motion segments for activity classification. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 392–405. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Latent hierarchical model of temporal structure for complex activity classification. IEEE Trans. Image Process. 2013, 23, 810–822. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Xie, X. Co-occurrence feature learning for skeleton-based action recognition using regularized deep LSTM networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Graves, A. Supervised sequence labeling. In Supervised Sequence Labeling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 5–13. [Google Scholar]
- Graves, A.; Mohamed, A.-R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 816–833. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Veeriah, V.; Zhuang, N.; Qi, G.-J. Differential recurrent neural networks for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4041–4049. [Google Scholar]
- Gu, J.; Wang, G.; Cai, J.; Chen, T. An empirical study of language CNN for image captioning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1222–1231. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, UK, 1995; Volume 3361, p. 1995. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–12 October 2016; pp. 20–36. [Google Scholar]
- Caruana, R. Multitask learning. In Learning to Learn; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Gowayyed, M.A.; Torki, M.; Hussein, M.E.; El-Saban, M. Histogram of oriented displacements (HOD): Describing trajectories of human joints for action recognition. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Ng, J.Y.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Lee, I.; Kim, D.; Kang, S.; Lee, S. Ensemble deep learning for skeleton-based action recognition using temporal sliding lstm networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1012–1020. [Google Scholar]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.-Y.; Kot, A.C. Global context-aware attention LSTM networks for 3D action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1656. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end Spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the Thirty-first AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Wang, H.; Wang, L. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 499–508. [Google Scholar]
- Weng, J.; Weng, C.; Yuan, J. Spatio-temporal naive-Bayes nearest-neighbor (st-nbnn) for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4171–4180. [Google Scholar]
- Li, C.; Cui, Z.; Zheng, W.; Xu, C.; Ji, R.; Yang, J. Action-attending graphic neural network. IEEE Trans. Image Process. 2018, 27, 3657–3670. [Google Scholar] [CrossRef] [PubMed]
- Yan, S.; Xiong, Y.; Lin, D. Spatial-temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person interaction detection using body-pose features and multiple instance learning. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 28–35. [Google Scholar]
- Yang, Z.; Li, Y.; Yang, J.; Luo, J. Action recognition with visual attention on skeleton images. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3309–3314. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning action ensemble for 3D human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 914–927. [Google Scholar]
- Yang, X.; Tian, Y. Effective 3d action recognition using eigenjoints. J. Vis. Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Li, C.; Wang, P.; Wang, S.; Hou, Y.; Li, W. Skeleton-based action recognition using LSTM and CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 585–590. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; p. 9. [Google Scholar]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchett: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 806–813. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Peng, X.; Schmid, C. Encoding Feature Maps of CNN for Action Recognition. Hal-Inria, Faranc. Available online: https://hal.inria.fr/hal-01236843/ (accessed on 29 April 2017).
- Radenović, F.; Tolias, G.; Chum, O. CNN image retrieval learn from BoW: Unsupervised fine-tuning with hard examples. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 3–20. [Google Scholar]
- Hu, J.-F.; Zheng, W.-S.; Lai, J.; Zhang, J. Jointly learning heterogeneous features for RGB-D activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5344–5352. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Fang, H.-S.; Xie, S.; Tai, Y.-W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Liu, M.; Liu, H.; Chen, C. Enhanced skeleton visualization for view-invariant human action recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high-performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2117–2126. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. Spatio-Temporal Attention-Based LSTM Networks for 3D Action Recognition and Detection. IEEE Trans. Image Process. 2018, 27, 3459–3471. [Google Scholar] [PubMed]
- Tokuda, K.; Jadoulle, J.; Lambot, N.; Youssef, A.; Koji, Y.; Tadokoro, S. Dynamic robot programming by FDNet: Design of FDNet programming environment. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)(IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004; pp. 780–785. [Google Scholar]
- Liu, M.; Meng, F.; Chen, C.; Wu, S. Joint dynamic pose image and space-time reversal for human action recognition from videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2019; pp. 8762–8769. [Google Scholar]
- Han, Y.; Chung, S.L.; Xiao, Q.; Lin, W.Y.; Su, S.F. Global Spatio-Temporal Attention for Action Recognition Based on 3D Human Skeleton Data. IEEE Access 2020, 8, 88604–88616. [Google Scholar] [CrossRef]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Neural Networks for High-Performance Skeleton-Based Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1963–1978. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, J.-F.; Zheng, W.-S.; Ma, L.; Wang, G.; Lai, J. Real-time RGB-D activity prediction by soft regression. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 280–296. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Kot, A.C.; Wang, G. Skeleton-based action recognition using Spatio-temporal lstm network with trust gates. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 3007–3021. [Google Scholar] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Si, C.; Jing, Y.; Wang, W.; Wang, L.; Tan, T. Skeleton-based action recognition with hierarchical spatial reasoning and temporal stack learning network. Pattern Recognit. 2020, 107, 107511. [Google Scholar] [CrossRef]
- Zhou, K.; Wu, T.; Wang, C.; Wang, J.; Li, C. Skeleton Based Abnormal Behavior Recognition Using Spatio-Temporal Convolution and Attention-Based LSTM. Procedia Comput. Sci. 2020, 174, 424–432. [Google Scholar] [CrossRef]
- Jiang, X.; Xu, K.; Sun, T. Action Recognition Scheme Based on Skeleton Representation With DS-LSTM Network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2129–2140. [Google Scholar] [CrossRef]









| Methods | Approach | NTU RGB+D Cross Subject | SBU Kinect Interaction |
|---|---|---|---|
| Two-stream RNN [35] | RNN | 71.3% | 94.8% |
| Ensemble TS-LSTM [32] | RNN | 76.0% | - |
| Clips + CNN + MTLN [26] | CNN | 79.6% | 93.6% |
| GLAN [40] | CNN | 80.1% | 95.6% |
| A2GNN [37] | Graphic NN | 72.7% | - |
| ST-GCN [38] | Graphic NN | 81.5% | - |
| Class | Class Level | Precision | Recall | F1-Score | Accuracy (%) |
|---|---|---|---|---|---|
| Running | 0 | 0.88 | 0.91 | 0.89 | 90 |
| Waving | 1 | 0.92 | 0.85 | 0.88 | 90 |
| Walking | 2 | 0.88 | 0.88 | 0.88 | 90 |
| Jumping | 3 | 0.93 | 0.95 | 0.95 | 90 |
| Methods | Year | CV | CS |
|---|---|---|---|
| Trust Date ST-LSTM [15] | 2016 | 77.7 | 69.2 |
| Visualization CNN [54] | 2017 | 82.6 | 76.0 |
| VA-LSTM [55] | 2017 | 87.7 | 79.2 |
| STA-LSTM [56] | 2018 | 81.2 | 73.4 |
| ST-GCN [38] | 2018 | 88.3 | 81.5 |
| FDNet [57] | 2018 | 89.8 | 83.5 |
| DTIs [57] | 2019 | - | 85.4 |
| HCN [26] | 2018 | 91.1 | 86.5 |
| DPI + att-DTIs [58] | 2019 | - | 90.2 |
| GL LSTM + Diff [59] | 2020 | 90.2 | 84.4 |
| Our model | - | 91.4 | 91.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehmood, F.; Chen, E.; Akbar, M.A.; Alsanad, A.A. Human Action Recognition of Spatiotemporal Parameters for Skeleton Sequences Using MTLN Feature Learning Framework. Electronics 2021, 10, 2708. https://doi.org/10.3390/electronics10212708
Mehmood F, Chen E, Akbar MA, Alsanad AA. Human Action Recognition of Spatiotemporal Parameters for Skeleton Sequences Using MTLN Feature Learning Framework. Electronics. 2021; 10(21):2708. https://doi.org/10.3390/electronics10212708
Chicago/Turabian StyleMehmood, Faisal, Enqing Chen, Muhammad Azeem Akbar, and Abeer Abdulaziz Alsanad. 2021. "Human Action Recognition of Spatiotemporal Parameters for Skeleton Sequences Using MTLN Feature Learning Framework" Electronics 10, no. 21: 2708. https://doi.org/10.3390/electronics10212708
APA StyleMehmood, F., Chen, E., Akbar, M. A., & Alsanad, A. A. (2021). Human Action Recognition of Spatiotemporal Parameters for Skeleton Sequences Using MTLN Feature Learning Framework. Electronics, 10(21), 2708. https://doi.org/10.3390/electronics10212708