
Classifying Emotions in Film Music—A Deep Learning Approach


Abstract
:1. Introduction
2. Related Work
2.1. Emotion/Mood Representation
- Categorical—emotions in models are described using labels that can be further divided into appropriate classes;
- Dimensional—emotions are defined on the basis of their location in a designated space.
2.2. Emotion Classification

| Author | Method | Emotion Model | Input Data Form | Results |
|---|---|---|---|---|
| Orjesek R. et al. [17] | CNN-RNN (one-dimensional CNN, time-distributed fully-connected layer and bidirectional gated recurrent unit) | V/A | Raw audio files | RMSE (Root Mean Square Error): Valence—0.123 ± 0.003 Arousal—0.116 ± 0.004 |
| Er et al. [18] | Two neural networks (VGG-16, AlexNet) and two classifiers (softmax, SVM) | Four classes | Chromatograms | Accuracy approx. 89% |
| Yang Y.-H. et al. [19] | FKNN (Fuzzy k-Nearest Neighbor) | V/A | Feature vector | Accuracy 70.88% |
| FNM (Fuzzy Neural Network) | V/A | Feature vector | Accuracy 78.33% | |
| Bargaje M. [45] | GA+SVM | V/A/L | Feature vector | Accuracy 84.57% |
| Sarkar R. et al. [46] | Transfer learning | Happy, Anger, Sad, Neutral | Mel-spectrogram | Accuracy 77.82 ± 4.06 % |
| Pandeya et al. [6] | 2D/3D convolution | six distinct classes: excited, fear, neutral, relaxation, sad, tension | Mel-spectrogram | Accuracy 74%, f1-score of 0.73 |
| Seo and Huh [47] | SVM/random forest/deep learning/kNN | ‘Happy, Glad,’ ‘Excited, Aroused,’ ‘Sad, Angry’ and ‘Calm, Bored.’ mapped on valence and arousal model; | Feature vector | Accuracy 73.96%/69.01% 72.90%/70.13% for k = 5 Av. match of 73.96% between the proposed method and the survey participants’ responses |
| Cuningham et al. [48] | ANN | Valence and arousal model | Feature vector | Accuracy: 64.4% for arousal and 65.4% for valence |
| Tong, L. et al. [49] | CNN/SVM | Valence and arousal model | Spectrograms | Accuracy for CNN model: 72.4% Accuracy for SVM model: 38.5% |
| Panda, R. et al. [50] | Simple Linear Regression (SLR)/KNN/Support Vector Regression (SVR) | Valence and arousal model | Feature vector | Accuracy for SLR: 54.62% for arousal and 3.31% for valence/accuracy for KNN: 61.07% for arousal and 11.97% for valence/accuracy for SVR: 67.39% for arousal and 40.56% for valence |
| Hizlisoy, S. et al. [51] | Long short-term memory deep neural network (CLDNN) | Valence and arousal model | Feature vector | Accuracy: 91.93% |
| Chaudhary, D. et al. [52] | CNN/SVM | Valence and arousal model | Spectograms | Accuracy: 91% |
| Yang, J. [53] | Back propagation | Valence and arousal model | Feature vector | RMSE (Root Mean Square Error): Valence—0.1066/Arousal—0.1322 |
3. Methodology
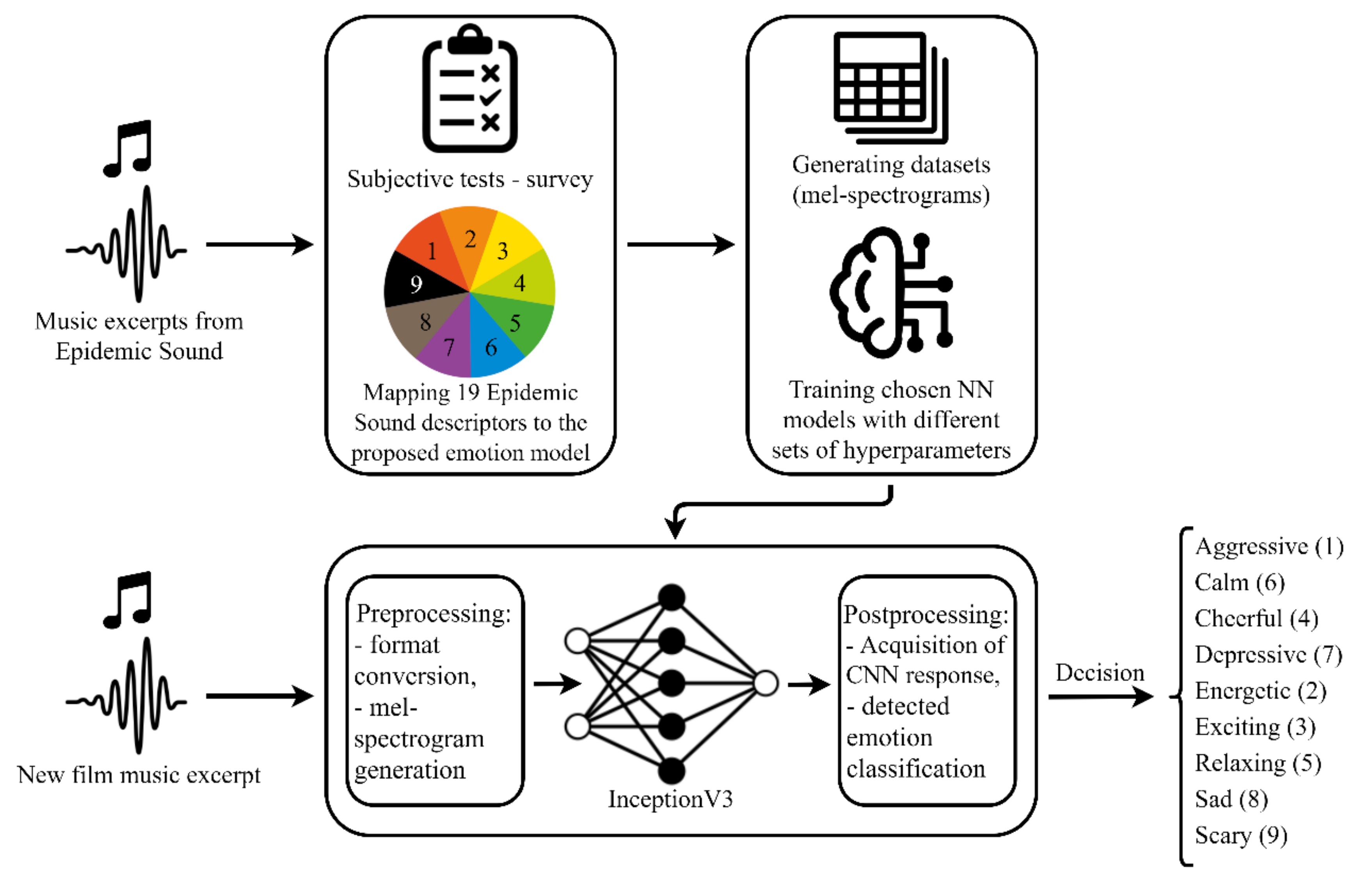
3.1. Subjective Tests
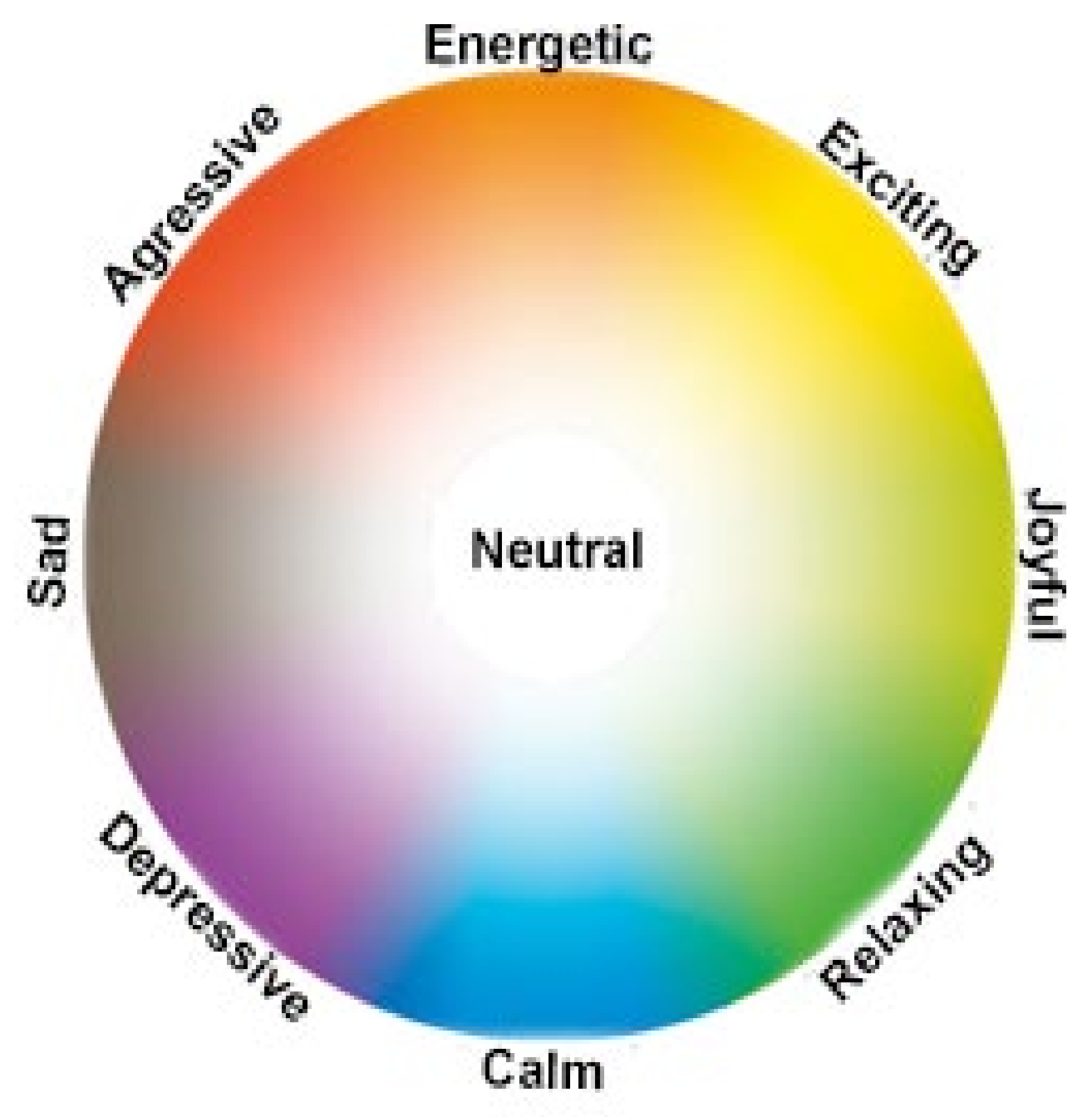
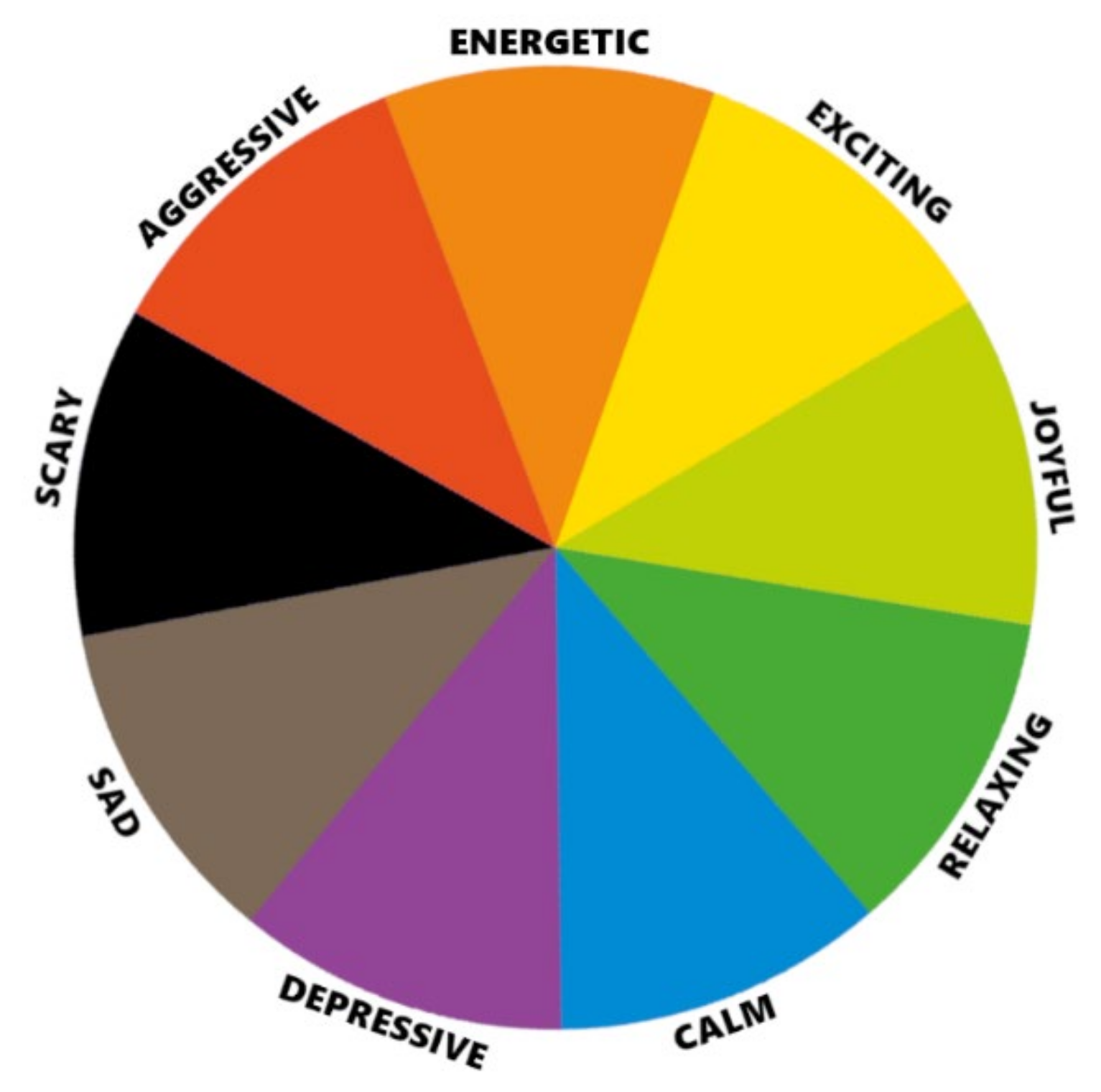
3.1.1. Emotion Model Proposal
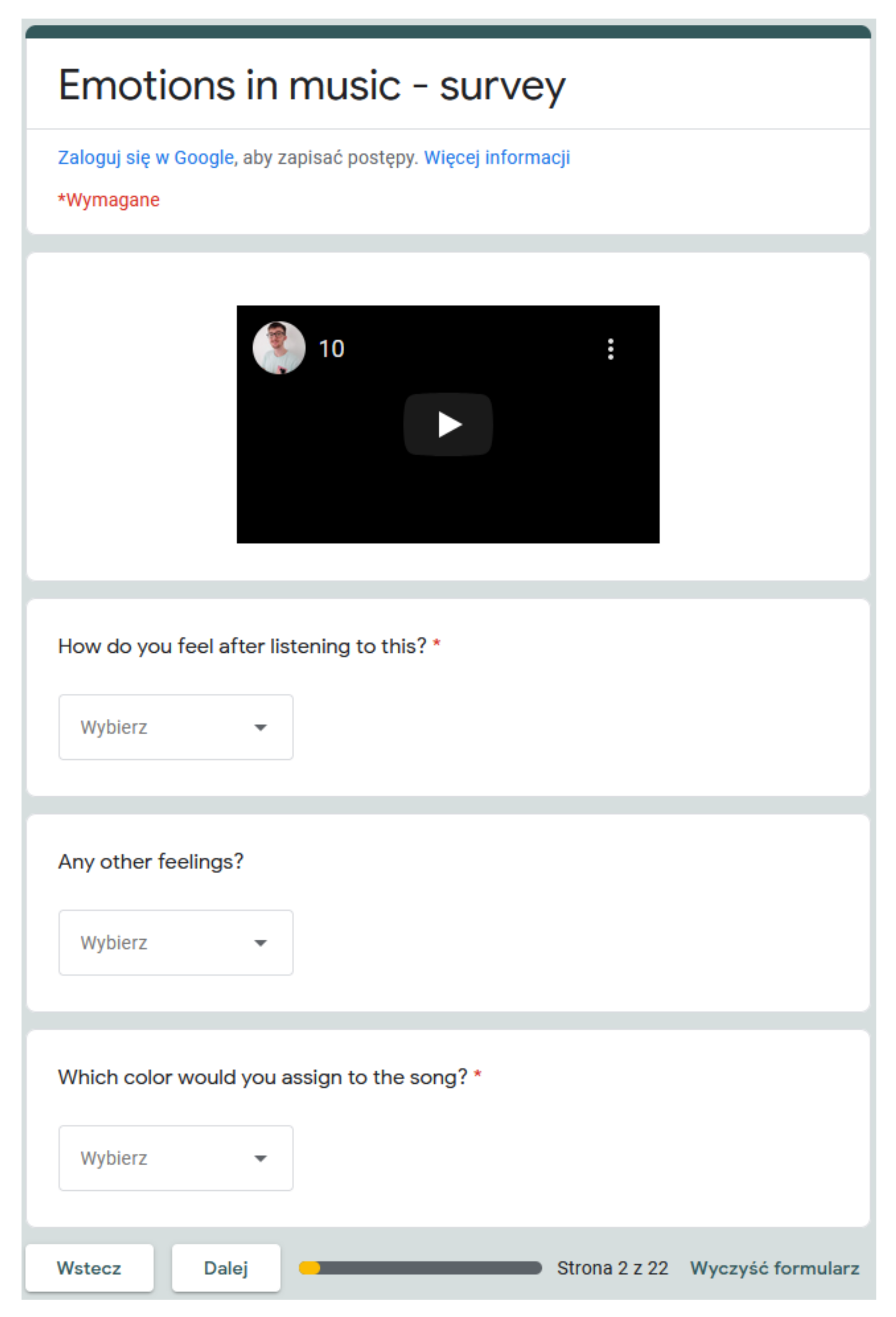
3.1.2. Survey Preparation: Music Dataset and Questionnaire Form
- How do you feel after hearing this?—possibility to choose: one of the nine emotions from the assumed model;
- Any other feelings?—optional answer, also one of nine emotions from the assumed model to choose from;
- What color would you assign to the song?—possibility to choose: one of the nine colors of the assumed model.
3.2. Automatic Emotion Classification in Film Music
3.2.1. Choosing Data and Programming Language Environment
3.2.2. Choosing Neural Network
- Xception—the size of the input image 299 × 299;
- VGG19—the size of the input image 224 × 224;
- ResNet50V2—the size of the input image 224 × 224;
- NASNetLarge—the size of the input image 331 × 331;
- Inception V3—the size of the input image 299 × 299.
4. Results and Discussion
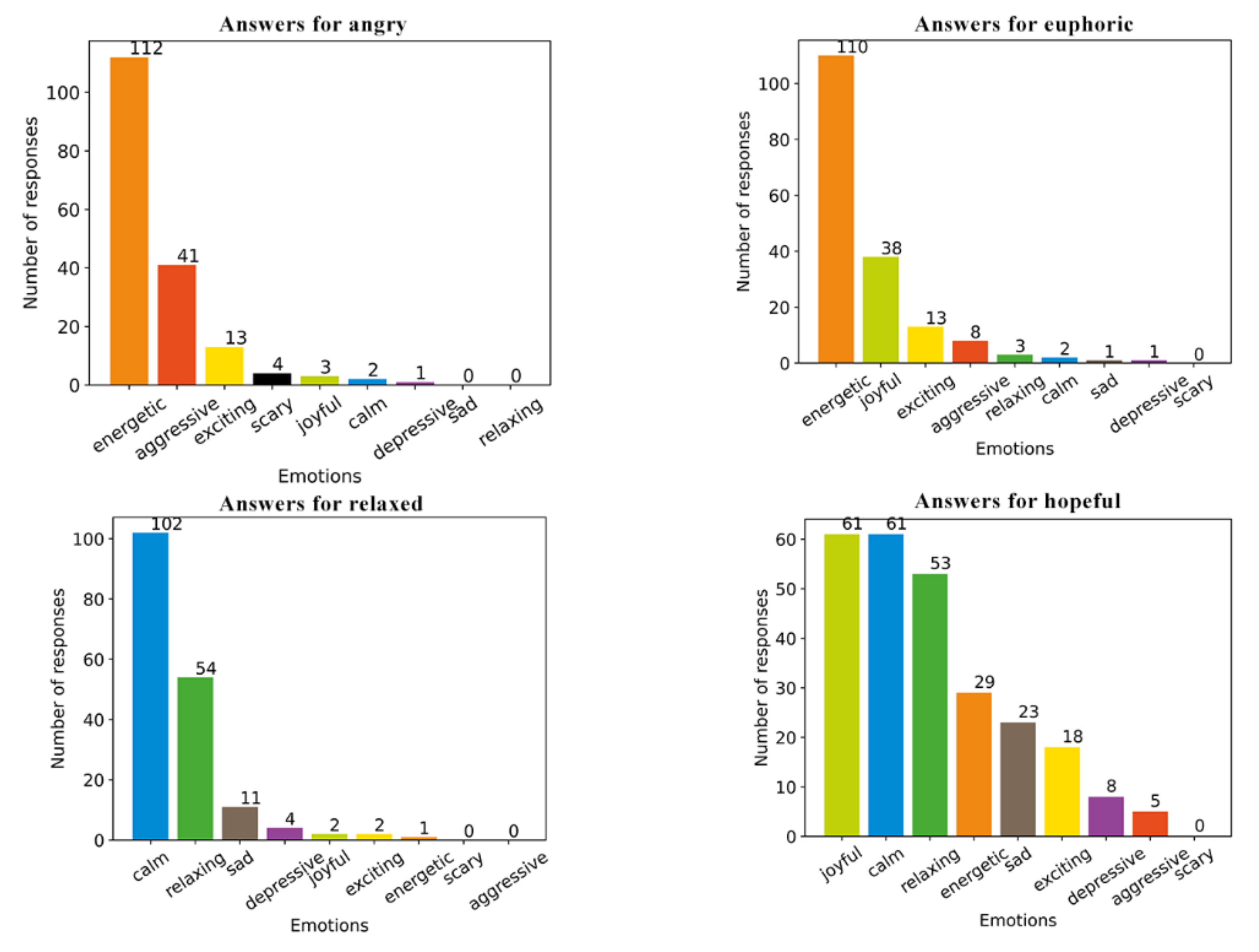
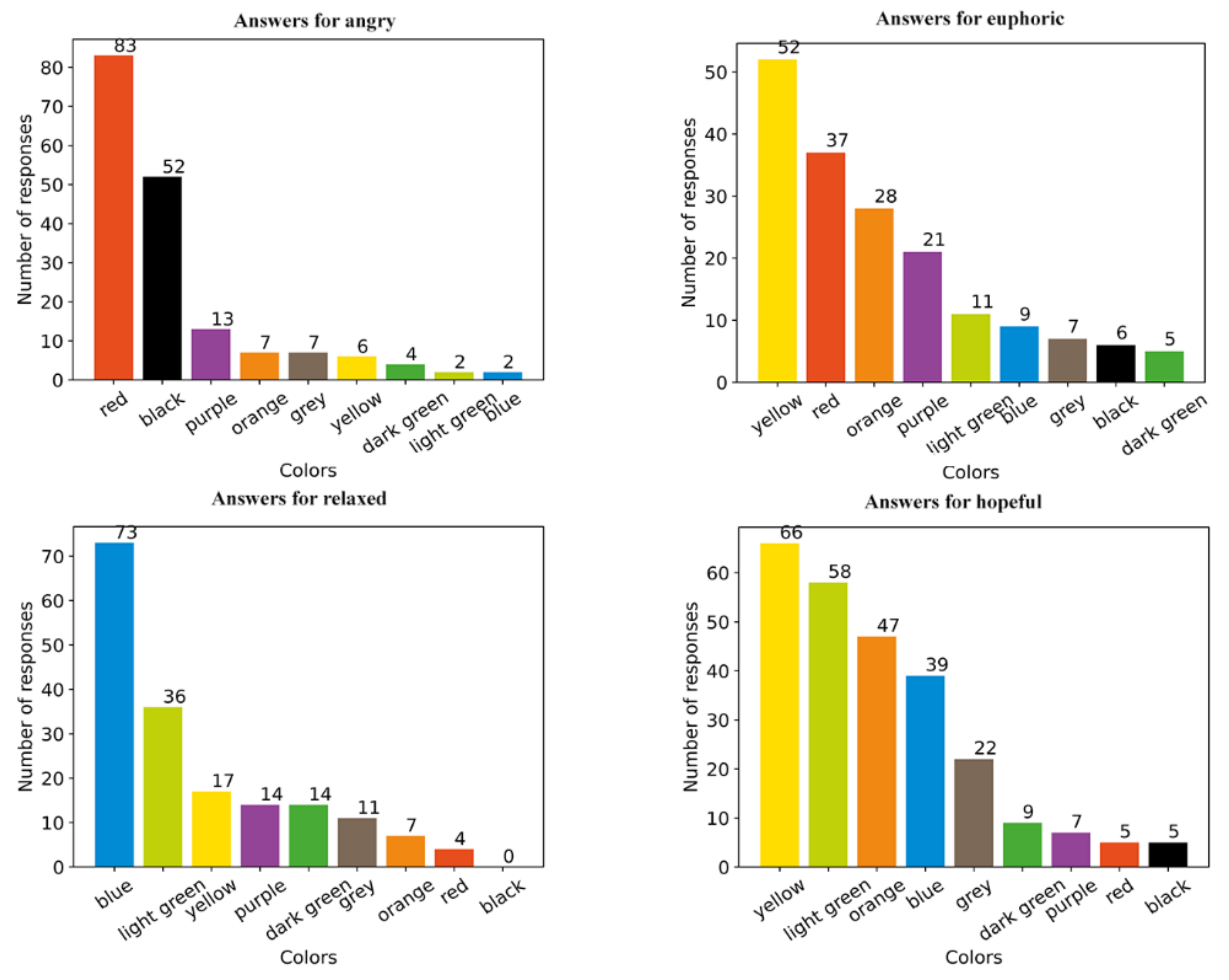
4.1. Survey Results
- [0; 0.3]—weak correlation;
- [0.3; 0.5]—moderate correlation;
- [0.5; 0.7]—strong correlation;
- [0.7; 1]—very strong correlation;
- If r is positive, then the x and y values are directly proportional;
- If r is negative, then the x and y values are inversely proportional.
4.2. CNN Model Training
- The first time with the patience value of 20, fragment lengths of 30 s, and a step of 10 s—the maximum number of epochs was set to 150;
- The second time with the patience value equal to 15, the training set with a length of 30 s, and a step of 8 s—the maximum number of epochs was set to 150.
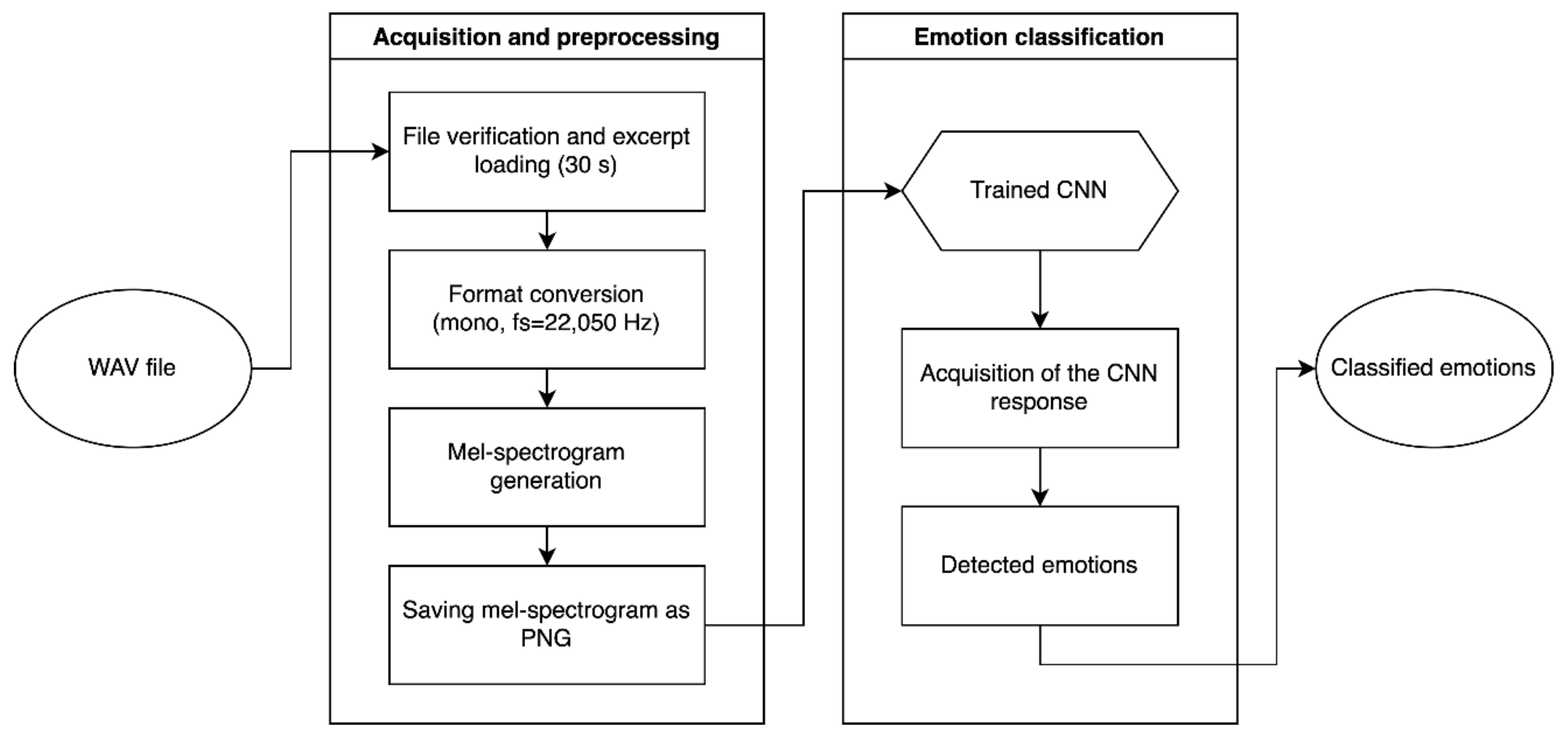
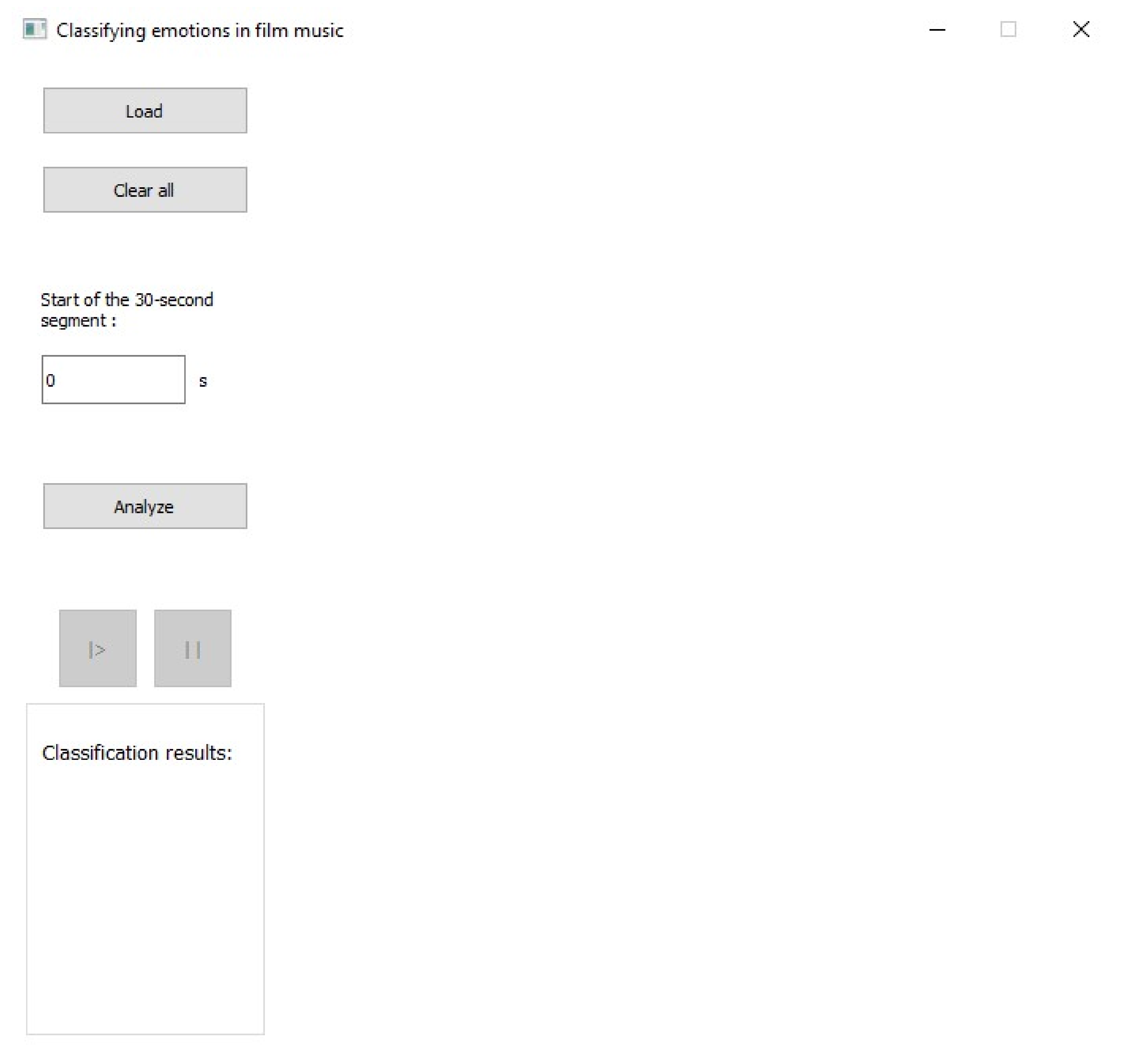
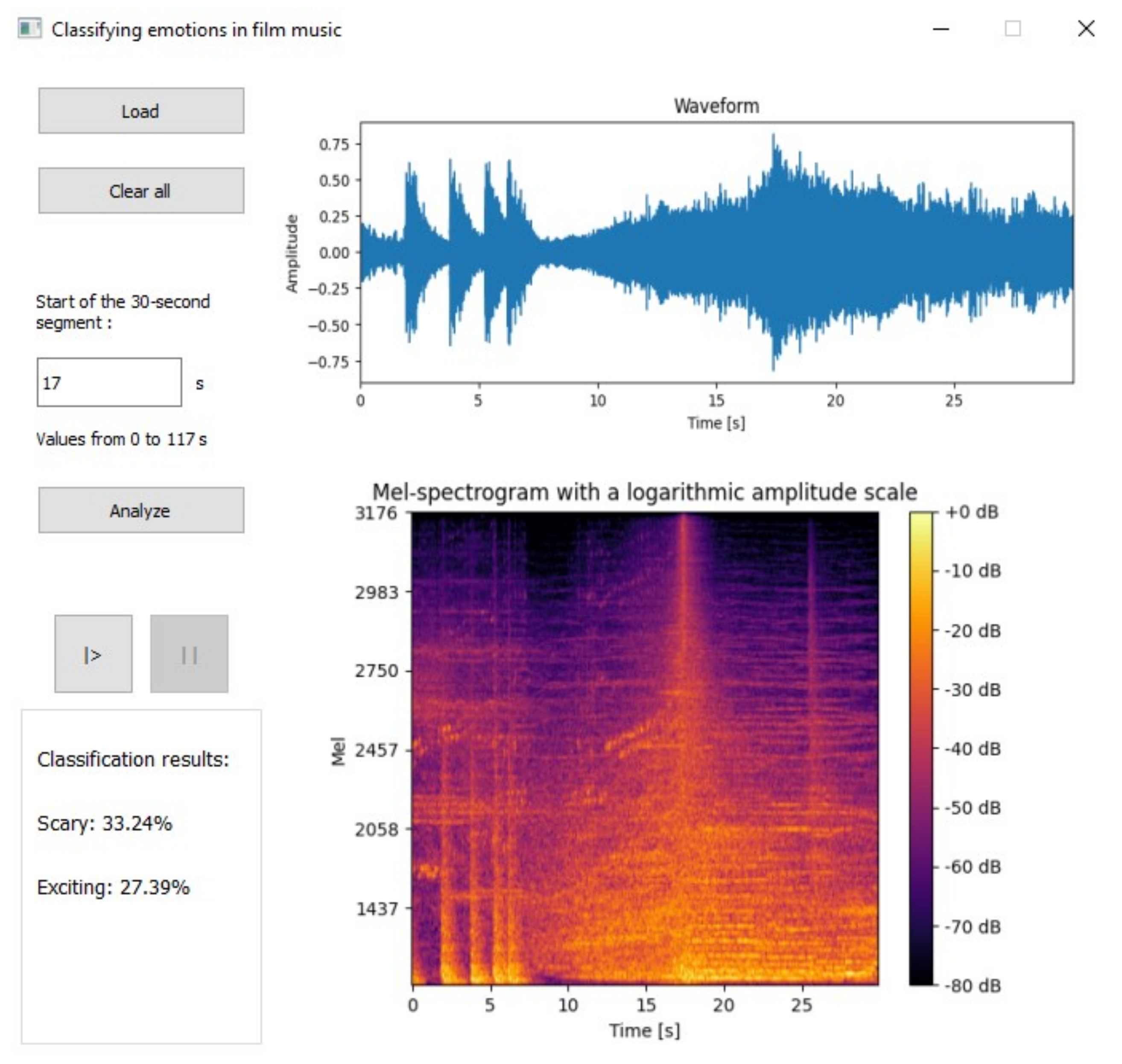
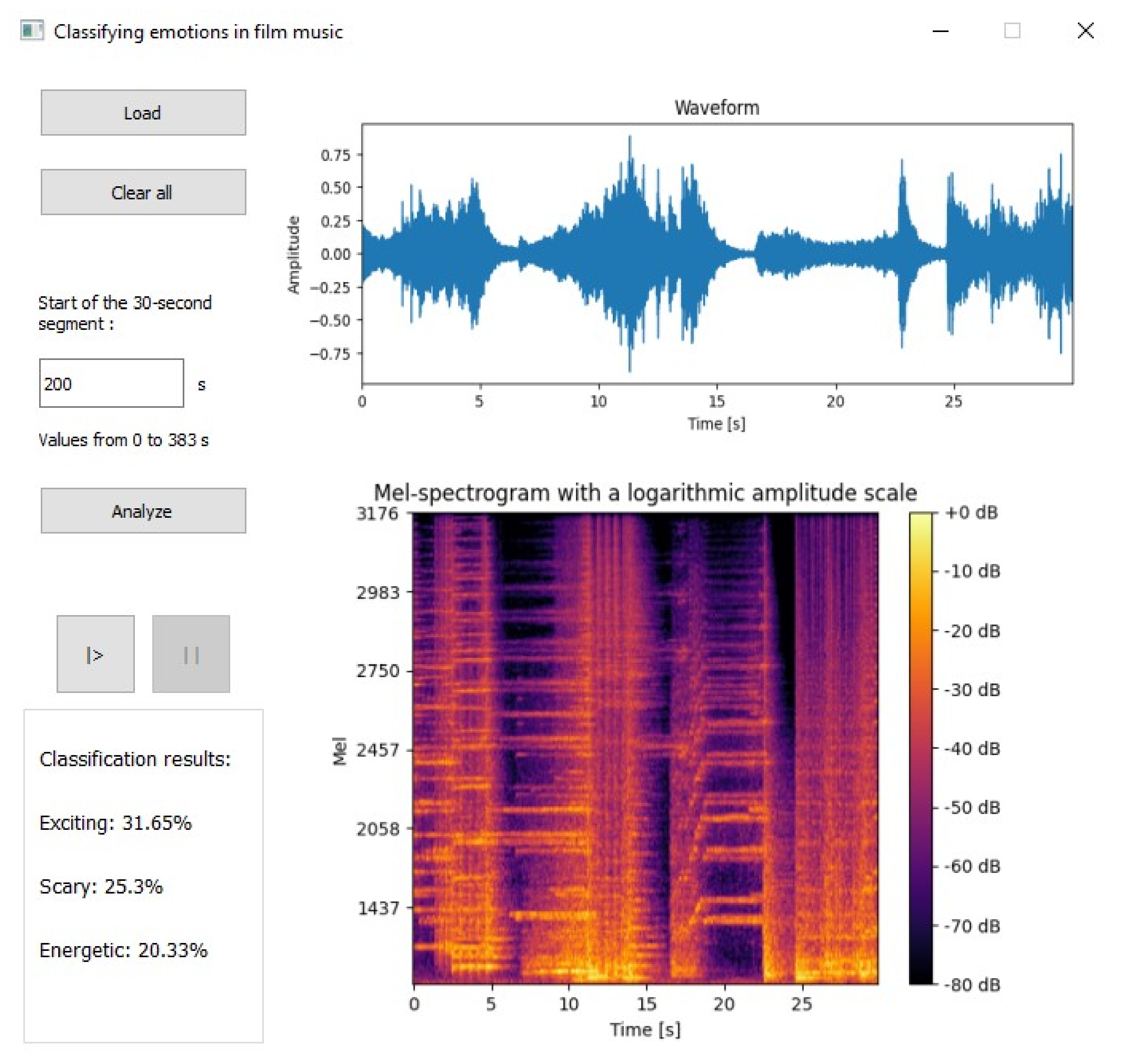
5. Application Construction
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- Barthet, M.; Fazekas, G.; Sandler, M. Emotion Music Recognition: From Content-to Context-Based Models. In CMMR 2012: From Sounds to Music and Emotions; Aramaki, M., Brathet, M., Kronland-Martinet, R., Ystad, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7900. [Google Scholar] [CrossRef]
- Kostek, B.; Piotrowska, M. Rough Sets Applied to Mood of Music Recognition. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016; Ganzha, M., Maciaszek, L., Paprzycki, M., Eds.; Volume 8, pp. 73–80. [Google Scholar] [CrossRef] [Green Version]
- Grekow, J. From Content-Based Music Emotion Recognition to Emotion Maps of Musical Pieces; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Dwivedi, P. Using CNNs and RNNs for Music Genre Recognition. Towards Data Science. Available online: https://towardsdatascience.com/using-cnns-and-rnns-for-music-genre-recognition-2435fb2ed6af (accessed on 12 October 2021).
- Xiao, Z.; Wu, D.; Zhang, X.; Tao, Z. Music mood tracking based in HCS. In Proceedings of the IEEE International Conference on Signal Processing, Bejing, China, 21–25 October 2012; pp. 1171–1175. [Google Scholar]
- Pandeya, Y.R.; Bhattarai, B.; Lee, J. Deep-Learning Multimodal Emotion Classification for Music Videos. Sensors 2021, 21, 4927. [Google Scholar] [CrossRef]
- Malik, M.; Adavanne, S.; Drossos, K.; Virtanen, T.; Jarina, R. Stacked convolutional and recurrent neural networks for music emotion recognition. In Proceedings of the 14th Sound and Music Computing Conference, Espoo, Finland, 5–8 July 2017; pp. 208–213. [Google Scholar]
- Yu, X.; Zhang, J.; Liu, J.; Wan, W.; Yang, W. An audio retrieval method based on chromogram and distance metrics. In Proceedings of the 2010 International Conference on Audio, Language and Image Processing, Shanghai, China, 23–25 November 2010; pp. 425–428. [Google Scholar]
- Grzywczak, D.; Gwardys, G. Audio features in music information retrieval. In Active Media Technology; Springer International Publishing: Cham, Switzerland, 2014; Volume 8610, pp. 187–199. [Google Scholar]
- Grzywczak, D.; Gwardys, G. Deep image features in music information retrieval. Int. J. Electron. Telecommun. 2014, 60, 321–326. [Google Scholar]
- Novet, J. Google, Spotify & Pandora Bet a Computer Could Generate a Better Playlist Than You Can; VenturaBeat: San Francisco, CA, USA, 2014. [Google Scholar]
- Payne, C. MuseNet, OpenAI. 2019. Available online: https://openai.com/blog/musenet/ (accessed on 12 October 2021).
- McCoulloch, W.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Robinson, J. Deeper Than Reason: Emotion and Its Role in Literature, Music and Art; Oxford University Press: Oxford, UK, 2005; pp. 310–313. [Google Scholar]
- Sherer, K.; Zentener, M. Emotional effects of music: Production rules. In Music and Emotion: Theory and Research; Oxford University Press: Oxford, UK, 1989; pp. 361–387. [Google Scholar]
- Spitify. Just the Way You Are: Music Listening and Personality. 2020. Available online: https://research.atspotify.com/just-the-way-you-are-music-listening-and-personality/ (accessed on 14 September 2021).
- Orjesek, R.; Jarina, R.; Chmulik, M.; Kuba, M. DNN Based Music Emotion Recognition from Raw Audio Signal. In Proceedings of the 29th International Conference Radioelektronika (RADIOELEKTRONIKA), Pardubice, Czech Republic, 16–18 April 2019; pp. 1–4. [Google Scholar]
- Bial Er, M.; Berkan Aydliek, I. Music Emotion Recognition by Using Chroma Spectrogram and Deep Visual Features. Int. J. Comput. Intell. Syst. 2019, 12, 1622–1634. [Google Scholar] [CrossRef]
- Yang, Y.H.; Lin, Y.C.; Su, Y.F.; Chen, H.H. A regression approach to music emotion recognition. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 448–457. [Google Scholar] [CrossRef]
- Hevner, K. Experimental Studies of the Elements of Expression in Music. Am. J. Psychol. 1936, 48, 246–268. [Google Scholar] [CrossRef] [Green Version]
- Thayer, R.E. The Biopsychology of Mood and Arousal; Oxford University Press: Oxford, UK, 1989. [Google Scholar]
- Thayer, R.E.; McNally, R.J. The biopsychology of mood and arousal. Cogn. Behav. Neurol. 1992, 5, 65–74. [Google Scholar]
- Russel, J.A. A circumflex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Olson, D.; Russell, C.S.; Sprenke, D.H. Circumplex Model: Systemic Assessment and Treatment of Families; Routledge: New York, NY, USA, 2014; pp. 7–40. [Google Scholar]
- Watson, D.; Tellegen, A. Toward a consensual structure of mood. Psychol. Bull. 1985, 98, 219–235. [Google Scholar] [CrossRef] [PubMed]
- Tellegen, A.; Watson, D.; Clark, L.A. On the dimensional and hierarchical structure of affect. Psychol. Sci. 1999, 10, 297–303. [Google Scholar] [CrossRef]
- Plewa, M.; Kostek, B. Music Mood Visualization Using Self-Organizing Maps. Arch. Acoust. 2015, 40, 513–525. [Google Scholar] [CrossRef]
- Plewa, M. Automatic Mood Indexing of Music Excerpts Based on Correlation between Subjective Evaluation and Feature Vector. Ph.D. Thesis, Gdańsk University of Technology, Gdańsk, Poland, 2015. Supervisor: Kostek, B. [Google Scholar]
- Lin, C.; Liu, M.; Hsiung, W.; Jhang, J. Music emotion recognition based on two-level support vector classification. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics, Jeju, Korea, 10–13 July 2016; pp. 375–389. [Google Scholar]
- Amiriparian, S.; Gerczuk, M.; Coutinho, E.; Baird, A.; Ottl, S.; Milling, M.; Schuller, B. Emotion and Themes Recognition in Music Utilizing Convolutional and Recurrent Neural Networks. In Proceedings of the MediaEval’19, Sophia Antipolis, France, 27–29 October 2019. [Google Scholar]
- Wang, X.; Wang, M.; Qi, W.; Su, W.; Wang, X.; Zhou, H. A Novel End-to-End Speech Emotion Recognition Network with Stacked Transformer Layers. In Proceedings of the ICASSP 2021 IEEE International Conference on Acoustic, Speech and Signal Processing on Acoustic, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6289–6293. [Google Scholar]
- Song, Y.; Cai, Y.; Tan, L. Video-Audio Emotion Recognition Based on Feature Fusion Deep Learning Method. In Proceedings of the 2021 IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Lansing, MI, USA, 9–11 August 2021; pp. 611–616. [Google Scholar]
- Xie, B.; Sidulova, M.; Park, C.H. Robust Multimodal Emotion Recognition from Conversation with Transformer-Based Crossmodality Fusion. Sensors 2021, 21, 4913. [Google Scholar] [CrossRef] [PubMed]
- Behzad, M.; Vo, N.; Li, X.; Zhao, G. Towards Reading Beyond Faces for Sparsity-Aware 3D/4D Affect Recognition. Neurocomputing 2021, 485, 297–307. [Google Scholar] [CrossRef]
- Lian, Z.; Liu, B.; Tao, J. CTNet: Conversational Transformer Network for Emotion Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 985–1000. [Google Scholar] [CrossRef]
- Chowdary, M.K.; Nguyen, T.N.; Hemanth, D.J. Deep Learning-Based Facial Emotion Recognition for Human Computer Interaction Applications. Neural Comput. Appl. 2021, 2021, 1–18. [Google Scholar] [CrossRef]
- Topic, A.; Russo, M. Emotion Recognition based on EEG Feature Maps trough Deep Learning Network. Eng. Sci. Technol. Int. J. 2021, 24, 1442–1454. [Google Scholar] [CrossRef]
- Tzirakis, P.; Chen, J.; Zafeiriou, S.; Schuller, B. End-to-End Multimodal Affect Recognition in Real-World Environments. Inf. Fusion 2021, 68, 46–53. [Google Scholar] [CrossRef]
- Abbaschain, B.J.; Sierra-Sosa, D.; Elmaghraby, A. Deep Learning Techniques for Speech Emotion Recognition, from Databases to Models. Sensors 2021, 21, 1249. [Google Scholar] [CrossRef]
- Zainuddin, A.A.; Superamaniam, S.; Andrew, A.C.; Muraleedharan, R.; Rakshys, J.; Miriam, J.; Bostomi, M.A.S.M.; Rais, A.M.A.; Khalidin, Z.; Mansor, A.F.; et al. Patient Monitoring System Using Computer Vision for Emotional Recognition and Vital Signs Detection. In Proceedings of the 2020 IEEE Student Conference on Research and Development, Batu Pahat, Malaysia, 27–29 September 2020; pp. 22–27. [Google Scholar]
- Shamshirband, S.; Fathi, M.; Dehzangi, A.; Chronopoulos, A.T.; Alinejad-Rokny, H. A review on deep learning approaches in healthcare systems. Taxonomies, challenges and open issues. J. Biomed. Inform. 2021, 113, 103627. [Google Scholar] [CrossRef]
- Thomas, C.; Jayagopi, D.B. Predicting Student Engagement in Classrooms Using Facial Behavioural Cues. In Proceedings of the 1st ACM SIGCHI International Workshop on Multimodal Interaction for Education, Glasgow, UK, 13 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 33–40. [Google Scholar]
- Zhang, J. Movies and Pop Songs Recommendation System by Emotion Detection through Facial Recognition. In Proceedings of the International Conference on Applied Physics and Computing, Ottawa, ON, Canada, 12–13 September 2020. [Google Scholar]
- Joloudari, J.H.; Haderbadi, M.; Mashmool, A.; Ghasemigol, M.; Band, S.S.; Mosavi, A. Early Detection of the Advanced Persistent Threat Attack Using Performance Analysis of Deep Learning. IEEE Access 2020, 8, 186125–186137. [Google Scholar] [CrossRef]
- Bargaje, M. Emotion recognition and emotion based classification of audio using genetic algorithm—An optimized approach. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015; pp. 562–567. [Google Scholar]
- Sarkar, R.; Choudhurry, S.; Dutta, S.; Roy, A.; Saha, S.K. Recognition of emotion in music based on deep convolutional neural network. Multimed. Tools Appl. 2020, 79, 765–783. [Google Scholar] [CrossRef]
- Seo, Y.-S.; Huh, J.-H. Automatic Emotion-Based Music Classification for Supporting Intelligent IoT Applications. Electronics 2019, 8, 164. [Google Scholar] [CrossRef] [Green Version]
- Cunningham, S.; Ridley, H.; Weinel, J.; Picking, R. Supervised machine learning for audio emotion recognition. Pers. Ubiquitous Comput. 2021, 25, 637–650. [Google Scholar] [CrossRef] [Green Version]
- Tong, L.; Li, H.; Liangaki, M. Audio-based deep music emotion recognition. AIP Conf. Proc. 2018, 1967, 040021. [Google Scholar]
- Panda, R.; Rocha, B.; Pavia, R.P. Dimensional Music Emotions Recognition: Combining Standard and Melodic Features. In Proceedings of the 10th International Symposium on Computer Music Multidisciplinary Research—CMMR’2013, Marseille, France, 15–18 October 2013. [Google Scholar]
- Hizlisoy, S.; Yildirim, S.; Tufekci, Z. Music emotion recognition using convolutional long short term memory deep neural networks. Eng. Sci. Technol. Int. J. 2021, 24, 760–767. [Google Scholar] [CrossRef]
- Chaudhary, D.; Singh, N.P.; Singh, S. Development of music emotion classification system using convolutional neural network. Eng. Sci. Technol. Int. J. Speech Technol. 2021, 24, 571–580. [Google Scholar] [CrossRef]
- Yang, J. A Novel Music Emotion Recognition Model Using Neural Network Technology. Front. Psychol. 2021, 12, 760060. [Google Scholar] [CrossRef] [PubMed]
- Epidemic Sound. Epidemic Sound: Royalty Free Music and Sound Effects. Available online: www.epidemicsound.com (accessed on 14 June 2021).
- Keras. Keras Applications, Keras API Reference. Available online: https://keras.io/api/applications (accessed on 14 September 2021).
- Soundtrack.Net. Available online: https://www.soundtrack.net/content/article/?id=208 (accessed on 7 November 2021).
- Kostek, B. Soft set approach to the subjective assessment of sound quality. In Proceedings of the IEEE International Conference on Fuzzy Systems at the World Congress on Computational Intelligence (WCCI 98), Anchorage, AK, USA, 4–9 May 1998; Volume 1–2, pp. 669–674. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












| • angry • angry–dark • angry–epic • dark–mysterious • dark–suspense • dreamy–floating • epic–hopeful • epic–mysterious • euphoric–dreamy • happy–euphoric • happy–glamorous • happy–hopeful | • happy–relaxing • hopeful–euphoric • hopeful–sentimental • hopeful–smooth • laid back–glamorous • laid back–sentimental • mysterious–floating • mysterious • mysterious–sneaking • mysterious–suspense • relaxing–laid back • relaxing | • romantic–sad • romantic–sentimental • romantic–sexy • sad–dreamy • sad–relaxing • sad • sad–sentimental • sentimental–floating • sexy–laid back • smooth–laid back • sneaking–suspense |
| The Length of the Window Analysis [s] | Length of Analysis Windows [s] | Number of Images in the Set |
|---|---|---|
| 30 | 2 | 29,495 |
| 4 | 15,011 | |
| 5 | 12,045 | |
| 6 | 10,191 | |
| 8 | 7801 | |
| 10 | 6336 | |
| 15 | 10 | 7007 |
| agr | cal | dep | ene | exc | hap | rel | sad | sca | |
|---|---|---|---|---|---|---|---|---|---|
| ang | 0.233 | 0.0114 | 0.0057 | 0.6363 | 0.0739 | 0.017 | 0 | 0 | 0.0227 |
| dar | 0.0227 | 0.1705 | 0.0114 | 0.0568 | 0.2898 | 0.0057 | 0.0852 | 0.0511 | 0.3068 |
| dre | 0.017 | 0.3751 | 0.017 | 0.0739 | 0.1364 | 0 | 0.3011 | 0.017 | 0.0625 |
| epi | 0.0455 | 0.017 | 0.0114 | 0.5056 | 0.3693 | 0 | 0 | 0.0057 | 0.0455 |
| eup | 0.0455 | 0.0114 | 0.0057 | 0.6249 | 0.0739 | 0.2159 | 0.017 | 0.0057 | 0 |
| flo | 0.0057 | 0.4376 | 0.017 | 0.0398 | 0.142 | 0.0057 | 0.267 | 0.0852 | 0 |
| gla | 0.0227 | 0.1534 | 0 | 0.3808 | 0.017 | 0.1591 | 0.25 | 0.017 | 0 |
| hap | 0.0341 | 0.0909 | 0 | 0.3522 | 0.2045 | 0.2614 | 0.0398 | 0.0114 | 0.0057 |
| hop | 0.0194 | 0.2365 | 0.031 | 0.1124 | 0.0698 | 0.2364 | 0.2054 | 0.0891 | 0 |
| lai | 0.0227 | 0.3636 | 0.017 | 0.0795 | 0.0341 | 0.0625 | 0.4035 | 0.0114 | 0.0057 |
| mys | 0.0114 | 0.1193 | 0.0284 | 0 | 0.233 | 0.0227 | 0.0398 | 0.0966 | 0.4488 |
| rel | 0 | 0.5795 | 0.0227 | 0.0057 | 0.0114 | 0.0114 | 0.3068 | 0.0625 | 0 |
| rom | 0.0284 | 0.3581 | 0.0568 | 0.1534 | 0.0284 | 0.0795 | 0.2159 | 0.0795 | 0 |
| sad | 0.0057 | 0.267 | 0.1591 | 0.0114 | 0.0114 | 0.0114 | 0.1136 | 0.409 | 0.0114 |
| sen | 0.0185 | 0.237 | 0.1 | 0.0111 | 0.0222 | 0.0407 | 0.1667 | 0.3705 | 0.0333 |
| sex | 0.0227 | 0.3807 | 0.017 | 0.0455 | 0.0398 | 0.0284 | 0.4375 | 0.0284 | 0 |
| smo | 0.0398 | 0.3352 | 0.017 | 0.0114 | 0.0341 | 0.0682 | 0.4772 | 0.0114 | 0.0057 |
| sne | 0.017 | 0.0966 | 0.0341 | 0.0795 | 0.4546 | 0.017 | 0.0455 | 0.0398 | 0.2159 |
| sus | 0.0739 | 0.0284 | 0.0057 | 0.108 | 0.3693 | 0.0057 | 0 | 0.0284 | 0.3806 |
| ang | angry |
| agr | aggressive |
| cal | calm |
| dar | dark |
| dep | depressive |
| dre | dreamy |
| ene | energized |
| epi | epic |
| eup | euphoric |
| exc | excited |
| flo | floating |
| gla | glamorous |
| hap | happy |
| hop | hopeful |
| lai | laid back |
| mys | mysterious |
| rel | relaxed |
| rom | romantic |
| sad | sad |
| sca | scary |
| sen | sentimental |
| sex | sexy |
| smo | smooth |
| sne | sneaking |
| sus | suspense |
| dar | - | |||||||||||||||||
| dre | - | - | ||||||||||||||||
| epi | - | - | - | |||||||||||||||
| eup | - | - | - | - | ||||||||||||||
| flo | - | - | X | - | - | |||||||||||||
| gla | - | - | - | - | - | - | ||||||||||||
| hap | - | - | - | - | - | - | - | |||||||||||
| hop | - | - | - | - | - | - | - | - | ||||||||||
| lai | - | - | X | - | - | - | - | - | - | |||||||||
| mys | - | X | - | - | - | - | - | - | - | - | ||||||||
| rel | - | - | - | - | - | X | - | - | - | - | - | |||||||
| rom | - | - | - | - | - | - | - | - | X | X | - | - | ||||||
| sad | - | - | - | - | - | - | - | - | - | - | - | - | - | |||||
| sen | - | - | - | - | - | - | - | - | - | - | - | - | - | X | ||||
| sex | - | - | X | - | - | X | - | - | - | X | - | X | - | - | - | |||
| smo | - | - | - | - | - | - | - | - | - | X | - | - | - | - | - | X | ||
| sne | - | X | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| sus | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| ang | dar | dre | epi | eup | flo | gla | hap | hop | lai | mys | rel | rom | sad | sen | sex | smo | sne |
| Red | Blue | Purple | Orange | Yellow | Light Green | Dark Green | Gray | Black | |
|---|---|---|---|---|---|---|---|---|---|
| Aggressive | 0.84 | −0.529 | −0.169 | −0.073 | −0.127 | −0.345 | −0.275 | −0.297 | 0.483 |
| Calm | −0.616 | 0.833 | −0.012 | −0.052 | 0.01 | 0.49 | 0.292 | 0.182 | −0.504 |
| Depressive | −0.246 | 0.366 | −0.228 | −0.17 | −0.146 | 0.014 | 0.469 | 0.845 | 0.127 |
| Energetic | 0.754 | −0.663 | −0.208 | 0.37 | 0.382 | −0.142 | −0.641 | −0.581 | −0.004 |
| Exciting | 0.192 | −0.322 | 0.179 | −0.25 | −0.273 | −0.307 | 0.084 | 0.059 | 0.396 |
| Joyful | −0.161 | −0.252 | −0.222 | 0.711 | 0.945 | 0.654 | −0.435 | −0.291 | −0.388 |
| Relaxing | −0.501 | 0.521 | 0.248 | 0.199 | 0.109 | 0.441 | 0.196 | −0.023 | −0.571 |
| Sad | −0.235 | 0.391 | −0.255 | −0.186 | −0.105 | 0.057 | 0.502 | 0.864 | 0.182 |
| Scary | −0.002 | −0.21 | 0.135 | −0.422 | −0.49 | −0.506 | 0.369 | 0.324 | 0.76 |
| Name of Model | Xception | ResNet50V2 | InceptionResNetV2 | InceptionV3 |
|---|---|---|---|---|
| Batch size | 32 | 16 | 32 | 64 |
| Learning rate | 10−4 | |||
| Accuracy—training dataset [%] | 99.82 | 98.32 | 98.33 | 96.89 |
| Accuracy—validation dataset [%] | 96.66 | 96.37 | 94.48 | 94.63 |
| Accuracy [%] | 59.49 | 59.9 | 60.38 | 62.95 |
| Own test [%] | 77.26 | 76.7 | 75.77 | 77.3 |
| Number of epochs | 100 | 100 | 100 | 83 |
| Name of Model | Xception | ResNet50V2 | InceptionResNetV2 | InceptionV3 | ||||
|---|---|---|---|---|---|---|---|---|
| Batch size | 32 | 16 | 64 | 64 | ||||
| Learning rate | 10−4 | |||||||
| Length of excerpt in learning dataset [s] | 30 | 15 | 30 | 15 | 30 | 15 | 30 | 15 |
| Accuracy—training dataset [%] | 97.47 | 97.85 | 91.16 | 95.57 | 98.95 | 97.42 | 96.52 | 93.25 |
| Accuracy—validation dataset [%] | 82.49 | 79.29 | 64.15 | 72.26 | 76.43 | 73.13 | 87.8 | 59.96 |
| Accuracy [%] | 58.18 | 55.61 | 53.6 | 57.84 | 63.47 | 61.98 | 61.04 | 59.96 |
| Own test [%] | 76.58 | 74.52 | 73.45 | 73.14 | 76.24 | 74.52 | 75.63 | 74.55 |
| Number of epochs | 100 | 99 | 19 | 40 | 69 | 48 | 97 | 29 |
| Name of Model | Xception | ResNet50V2 | InceptionResNetV2 | InceptionV3 |
|---|---|---|---|---|
| Batch size | 64 | 16 | 64 | 16 |
| Learning rate | 10−4 | |||
| Learning dataset | Length of excerpt = 30 s Shift = 10 s | Length of excerpt = 30 s Shift = 8 s | ||
| Accuracy—training dataset [%] | 98.43 | 99.63 | 98.64 | 97.25 |
| Accuracy—validation dataset [%] | 90.54 | 87.63 | 89.17 | 93.16 |
| Accuracy [%] | 60.86 | 59.9 | 61.11 | 61.66 |
| Own test [%] | 76.58 | 75.57 | 77.9 | 78.71 |
| Number of epochs | 150 | 150 | 141 | 68 |
| Model Name | Xception | ResNet50V2 | InceptionResNetV2 | InceptionV3 |
|---|---|---|---|---|
| Cosine similarity | 0.8695 | 0.8720 | 0.8717 | 0.8892 |
| Mean absolute error | 0.4735 | 0.4756 | 0.4573 | 0.4299 |
| Mean squared error | 0.0649 | 0.0632 | 0.0630 | 0.0542 |
| Beginning of the Fragment | Choose 1 | Choose 2 | Choose 3 | ||||
|---|---|---|---|---|---|---|---|
| Emotion | [%] | Emotion | [%] | Emotion | [%] | ||
| Main Theme | 0 | Energetic | 36.59 | Exciting | 17.26 | Joyful | 15.29 |
| African Rundown | 0 | Energetic | 35.32 | Exciting | 29.05 | Scary | 16.04 |
| Dumbledore’s Farewell | 15 | Calm | 29.64 | Relaxing | 23.2 | Sad | 18.39 |
| Time | 10 | Exciting | 27.0 | Scary | 20.68 | Calm | 17.46 |
| Who is She | 42 | Energetic | 30.77 | Joyful | 18.53 | Exciting | 17.19 |
| Seizure of Power | 20 | Energetic | 48.18 | Aggressive | 16.46 | Exciting | 15.29 |
| Flesh-16374 | 0 | Scary | 40.16 | Exciting | 28.09 | Calm | 11.11 |
| Auschwitz_Birkenau | 0 | Calm | 30.39 | Sad | 18.38 | Relaxing | 17.31 |
| Discombobulate | 20 | Energetic | 48.29 | Exciting | 22.32 | Aggressive | 12.69 |
| Ragnar Says Goodby to Gyda | 0 | Calm | 25.32 | Sad | 20.08 | Relaxing | 16.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ciborowski, T.; Reginis, S.; Weber, D.; Kurowski, A.; Kostek, B. Classifying Emotions in Film Music—A Deep Learning Approach. Electronics 2021, 10, 2955. https://doi.org/10.3390/electronics10232955
Ciborowski T, Reginis S, Weber D, Kurowski A, Kostek B. Classifying Emotions in Film Music—A Deep Learning Approach. Electronics. 2021; 10(23):2955. https://doi.org/10.3390/electronics10232955
Chicago/Turabian StyleCiborowski, Tomasz, Szymon Reginis, Dawid Weber, Adam Kurowski, and Bozena Kostek. 2021. "Classifying Emotions in Film Music—A Deep Learning Approach" Electronics 10, no. 23: 2955. https://doi.org/10.3390/electronics10232955
APA StyleCiborowski, T., Reginis, S., Weber, D., Kurowski, A., & Kostek, B. (2021). Classifying Emotions in Film Music—A Deep Learning Approach. Electronics, 10(23), 2955. https://doi.org/10.3390/electronics10232955