
Using Stochastic Computing for Virtual Screening Acceleration

 , , , , , ,
, , , , , ,  and
and 
Abstract
:1. Introduction
1.1. Artificial Neural Networks Applied to Virtual Screening
1.2. Objective of the Paper
- −
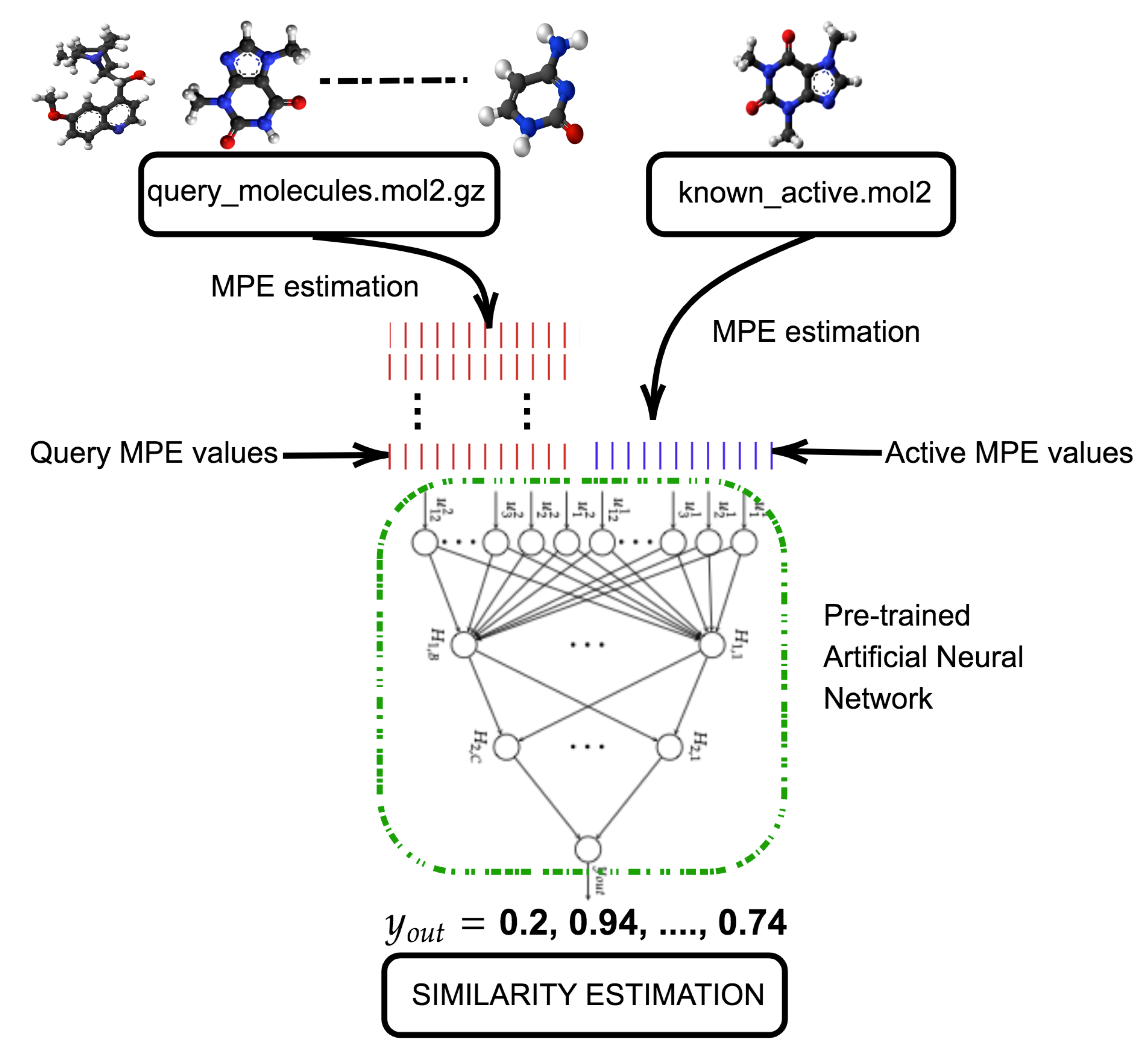
- Electron distribution assigned to individual atoms must be taken into consideration along with their spacial distribution. The MOL2 file type is therefore needed for each compound since this information is included in this format.
- −
- A set of molecular descriptors are estimated from the MOL2 files. Molecular pairing energies (MPE) [44], dependent on both charge distribution and molecular geometry, are adopted as descriptors. These descriptors are independent of rotations and translations of the compound, and provide valuable information about its binding possibilities.
- −
- Once the MPE values are obtained from the query and active compounds, a preconfigured ANN estimates the similarity between queries and active compounds.
- −
- The database is finally ordered, according to the similarity values provided by the system and, consequently, only the top-most compounds are selected for laboratory assays.
2. Methods
2.1. Molecular Pairing Energies Descriptors
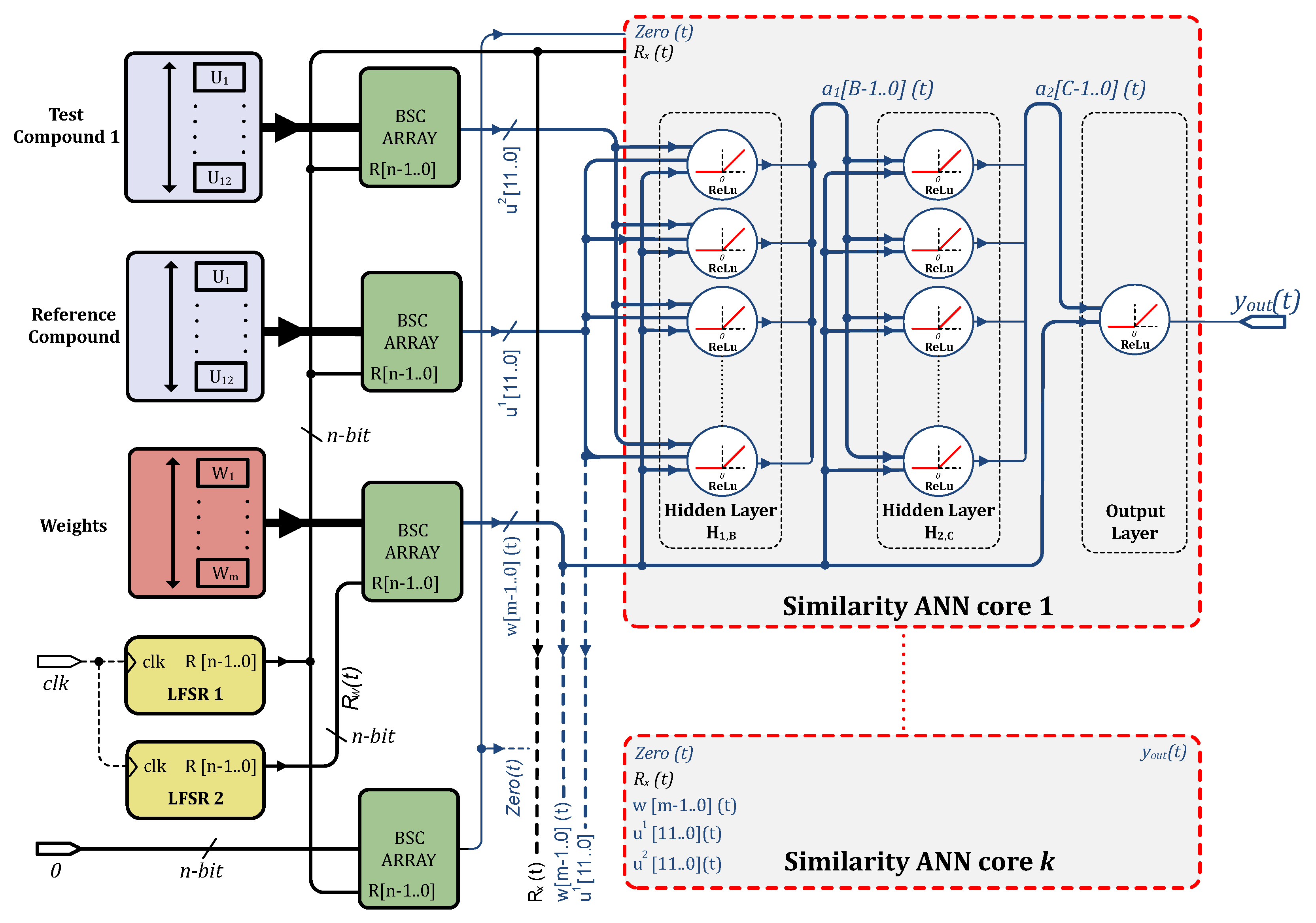
2.2. Artificial Neural Network Implementation
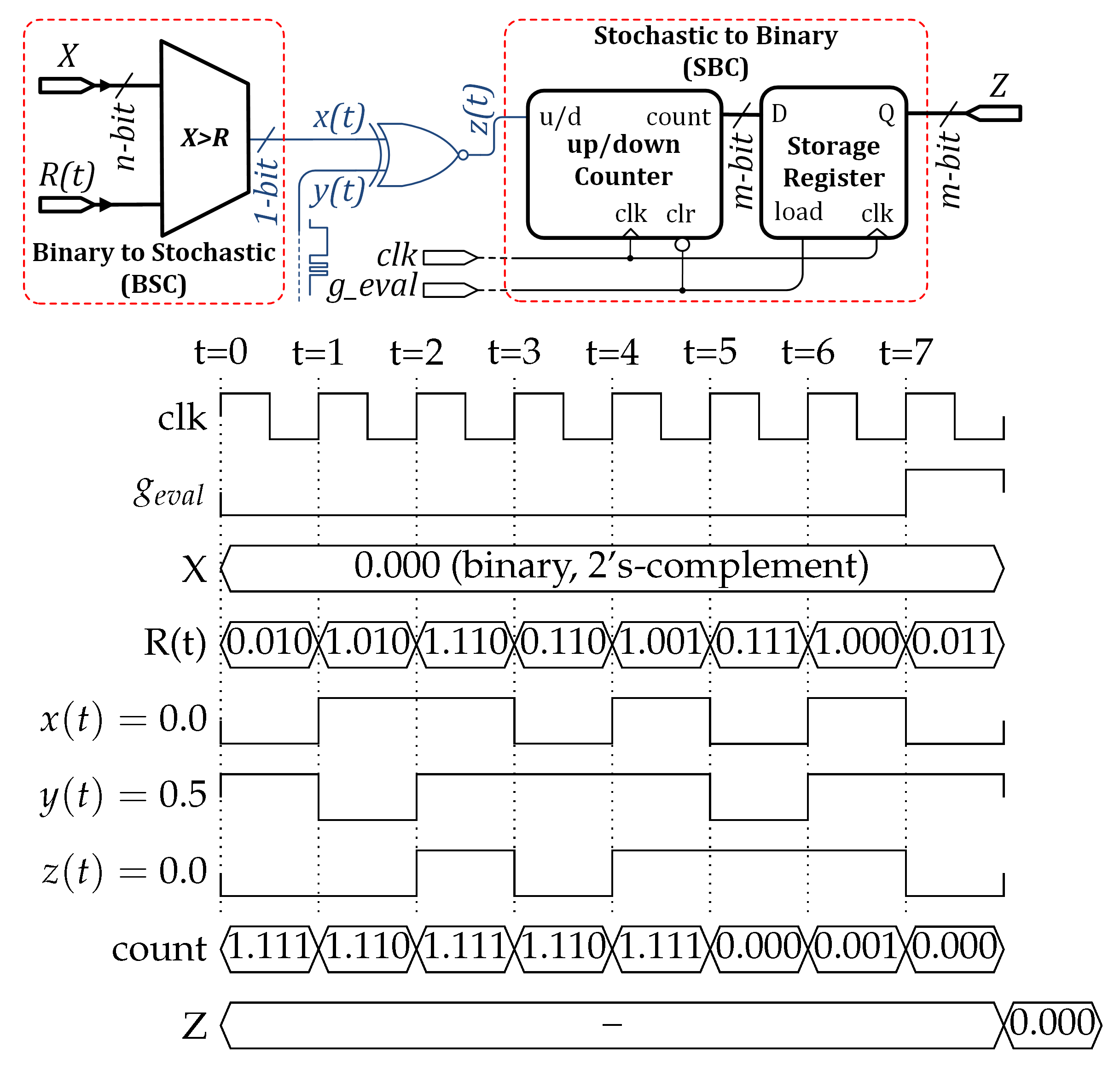
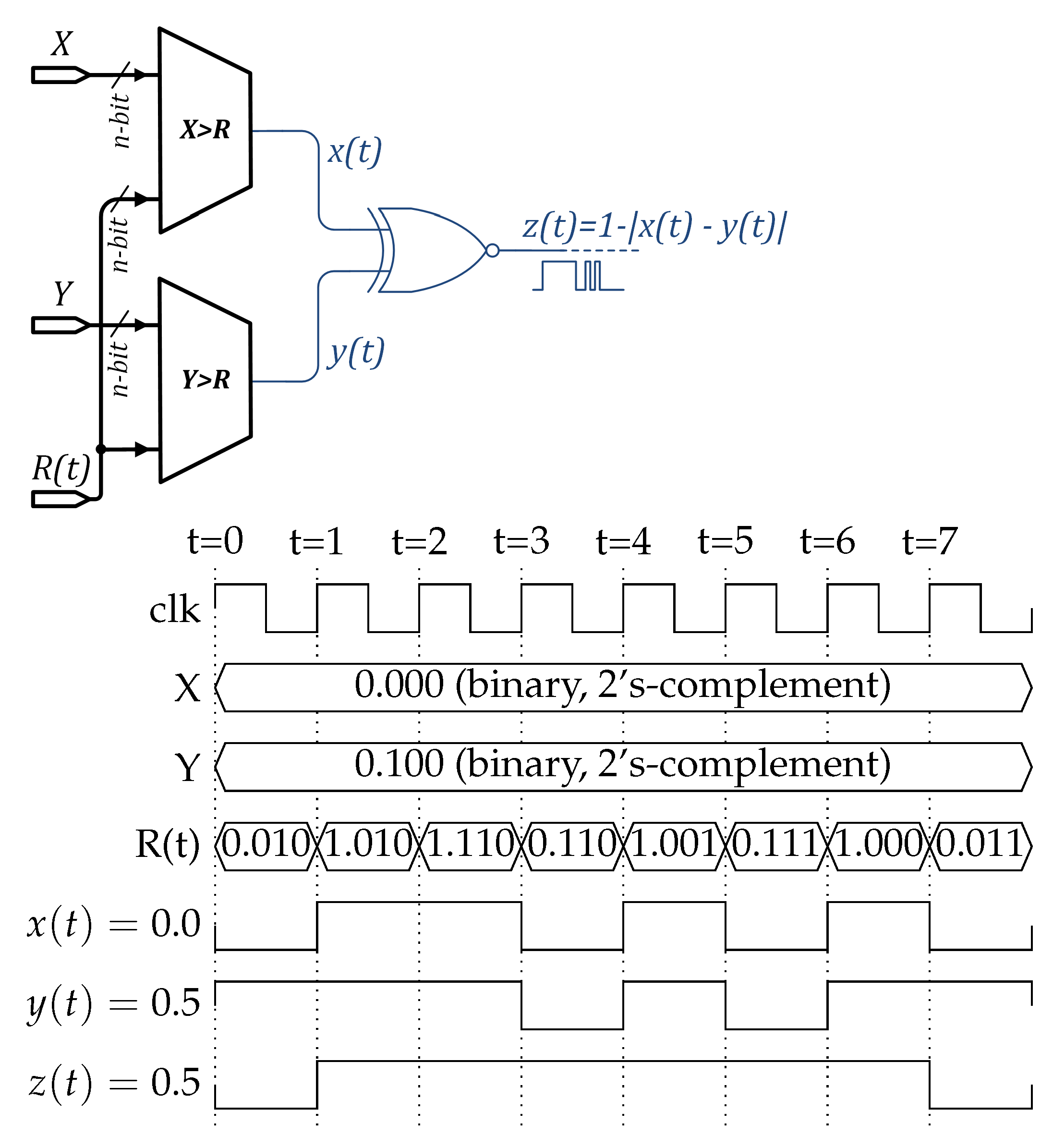
2.3. Stochastic Computing
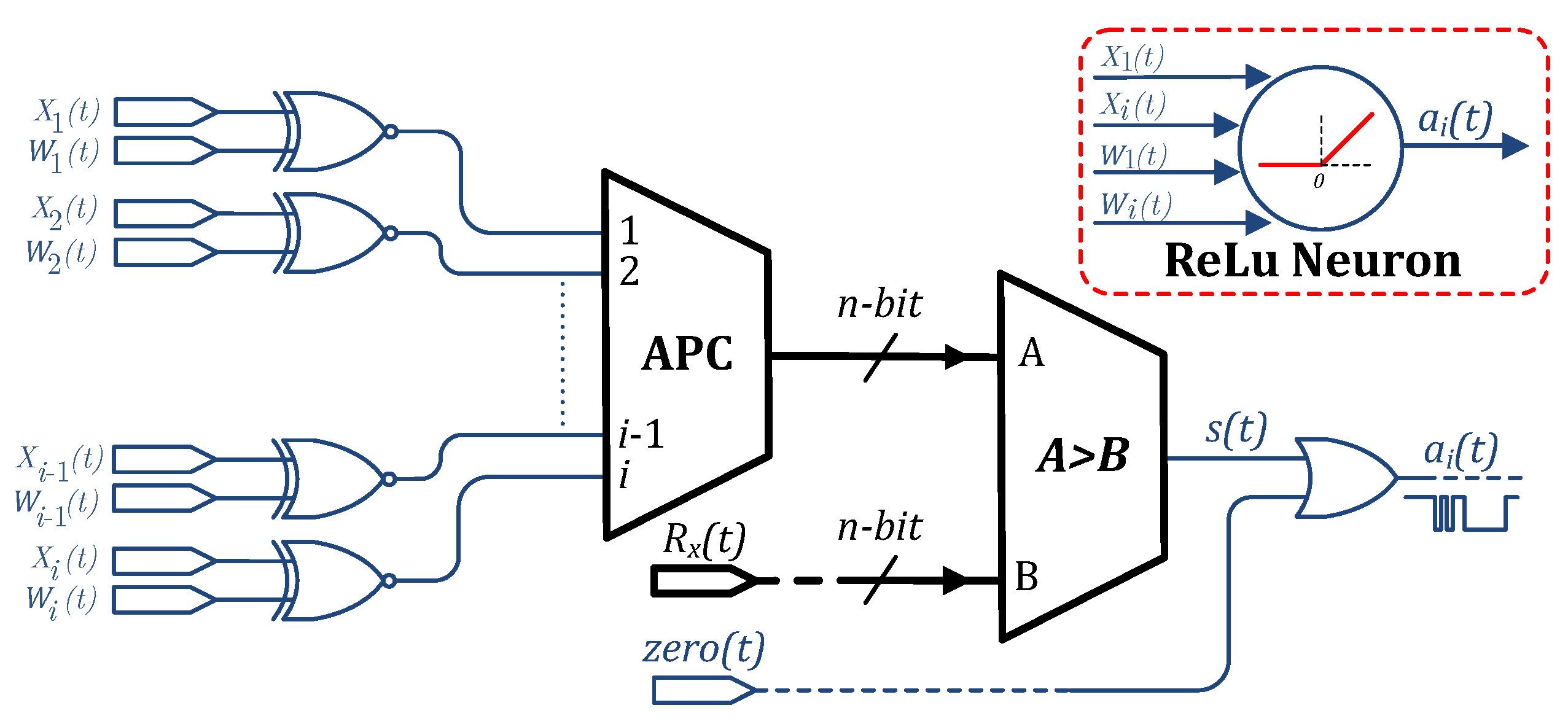
2.4. Stochastic Computing Neuron
2.5. Stochastic Computing ANN
3. Results
3.1. Experimental Methodology
3.2. Hardware Measurements vs. Software Simulations
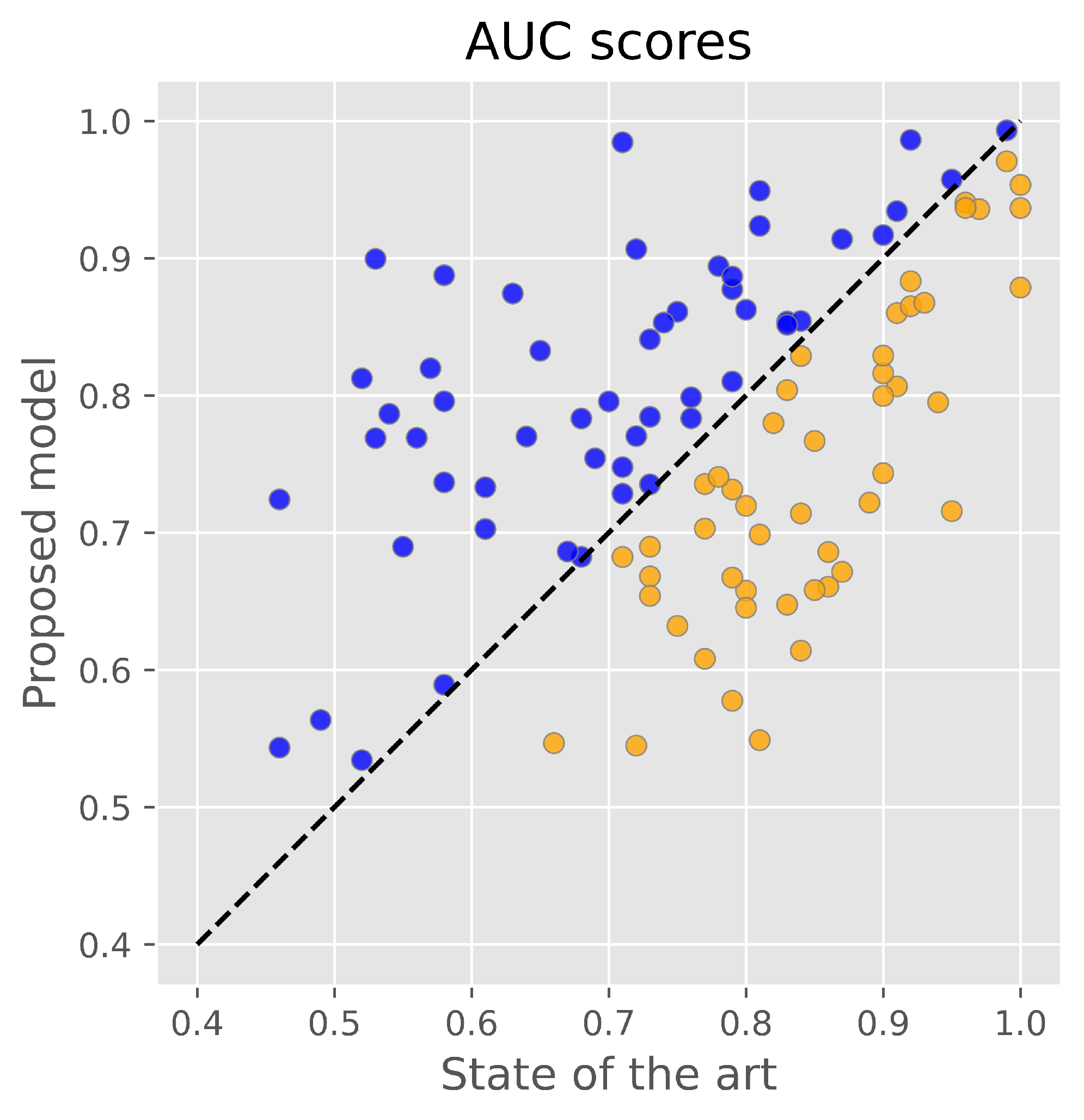
3.3. Comparison with Other Ligand-Based Models
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANN | Artificial Neural Networks |
| APC | Accumulative Parallel Counter |
| AUC | Area Under the Curve |
| DSP | Digital Signal Processor |
| DUD-E | Database of Useful (Docking) Decoys—Enhanced |
| FPGA | Field Programmable Gate Array |
| LFSR | Linear Feedback Shift Register |
| MPE | Molecular Pairing Energies |
| NH | Neuromorphic Hardware |
| RAM | Random Access Memory |
| ReLU | Rectified linear activation function |
| RNG | Random Numbers Generator |
| ROC | Receiver Operating Characteristic |
| SC | Stochastic Computing |
| SC-ANN | Stochastic Computing-based Artificial Neural Network |
| TPR | True Positive Rate |
| VS | Virtual Screening |
References
- Hoffmann, T.; Gastreich, M. The next level in chemical space navigation: Going far beyond enumerable compound libraries. Drug Discov. Today 2019, 24, 1148–1156. [Google Scholar] [CrossRef]
- Adeshina, Y.O.; Deeds, E.J.; Karanicolas, J. Machine learning classification can reduce false positives in structure-based virtual screening. Proc. Natl. Acad. Sci. USA 2020, 117, 18477–18488. [Google Scholar] [CrossRef] [PubMed]
- Fresnais, L.; Ballester, P.J. The impact of compound library size on the performance of scoring functions for structure-based virtual screening. Brief. Bioinform. 2020, 22, bbaa095. [Google Scholar] [CrossRef]
- Lavecchia, A.; Giovanni, C. Virtual screening strategies in drug discovery: A critical review. Curr. Med. Chem. 2013, 20, 2839–2860. [Google Scholar] [CrossRef] [PubMed]
- Singh, N.; Chaput, L.; Villoutreix, B. Virtual screening web servers: Designing chemical probes and drug candidates in the cyberspace. Brief. Bioinform. 2021, 22, 1790–1818. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Glaab, E. Building a virtual ligand screening pipeline using free software: A survey. Brief. Bioinform. 2016, 17, 352–366. [Google Scholar] [CrossRef] [Green Version]
- Ghislat, G.; Rahman, T.; Ballester, P.J. Recent progress on the prospective application of machine learning to structure-based virtual screening. Curr. Opin. Chem. Biol. 2021, 65, 28–34. [Google Scholar] [CrossRef]
- Li, H.; Sze, K.H.; Lu, G.; Ballester, P. Machine-learning scoring functions for structure-based virtual screening. Compu. Mol. Sci. 2021, 11, e1478. [Google Scholar] [CrossRef]
- Batool, M.; Ahmad, B.; Choi, S. A structure-based drug discovery paradigm. Int. J. Mol. Sci. 2019, 20, 2783. [Google Scholar] [CrossRef] [Green Version]
- Pinzi, L.; Rastelli, G. Molecular docking: Shifting paradigms in drug discovery. Int. J. Mol. Sci. 2019, 20, 4331. [Google Scholar] [CrossRef] [Green Version]
- Zoete, V.; Daina, A.; Bovigny, C.; Michielin, O. SwissSimilarity: A Web Tool for Low to Ultra High Throughput Ligand-Based Virtual Screening. J. Chem. Inf. Model. 2016, 56, 1399–1404. [Google Scholar] [CrossRef]
- Li, H.; Leung, K.S.; Wong, M.H.; Ballester, P. USR-VS: A web server for large-scale prospective virtual screening using ultrafast shape recognition techniques. Nucleic Acids Res. 2016, 44, W436–W441. [Google Scholar] [CrossRef]
- Kumar, A.; Zhang, K. Advances in the development of shape similarity methods and their application in drug discovery. Front. Chem. 2018, 6, 315. [Google Scholar] [CrossRef] [PubMed]
- Neves, B.; Braga, R.; Melo-Filho, C.; Moreira-Filho, J.; Muratov, E.; Andrade, C. QSAR-based virtual screening: Advances and applications in drug discovery. Front. Pharmacol. 2018, 9, 1275. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soufan, O.; Ba-Alawi, W.; Magana-Mora, A.; Essack, M.; Bajic, V. DPubChem: A web tool for QSAR modeling and high-throughput virtual screening. Sci. Rep. 2018, 8, 9110. [Google Scholar] [CrossRef] [PubMed]
- Speck-Planche, A.; Kleandrova, V.; Luan, F.; Cordeiro, M. Chemoinformatics in anti-cancer chemotherapy: Multi-target QSAR model for the in silico discovery of anti-breast cancer agents. Eur. J. Pharm. Sci. 2012, 47, 273–279. [Google Scholar] [CrossRef]
- Olier, I.; Sadawi, N.; Bickerton, G.; Vanschoren, J.; Grosan, C.; Soldatova, L.; King, R. Meta-QSAR: A large-scale application of meta-learning to drug design and discovery. Mach. Learn. 2018, 107, 285–311. [Google Scholar] [CrossRef] [Green Version]
- Sidorov, P.; Naulaerts, S.; Ariey-Bonnet, J.; Pasquier, E.; Ballester, P.J. Predicting Synergism of Cancer Drug Combinations Using NCI-ALMANAC Data. Front. Chem. 2019, 7, 509. [Google Scholar] [CrossRef]
- Lavecchia, A. Machine-learning approaches in drug discovery: Methods and applications. Drug Discov. Today 2015, 20, 318–331. [Google Scholar] [CrossRef] [Green Version]
- Azghadi, M.; Linares-Barranco, B.; Abbott, D.; Leong, P. A Hybrid CMOS-Memristor Neuromorphic Synapse. IEEE Trans. Biomed. Circuits Syst. 2017, 11, 434–445. [Google Scholar] [CrossRef] [Green Version]
- Frenkel, C.; Legat, J.D.; Bol, D. MorphIC: A 65-nm 738k-Synapse/mm2 Quad-Core Binary-Weight Digital Neuromorphic Processor with Stochastic Spike-Driven Online Learning. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 999–1010. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.; Yantır, H.; Fouda, M.; Eltawil, A.; Salama, K. Towards efficient neuromorphic hardware: Unsupervised adaptive neuron pruning. Electronics 2020, 9, 1059. [Google Scholar] [CrossRef]
- Son, H.; Cho, H.; Lee, J.; Bae, S.; Kim, B.; Park, H.J.; Sim, J.Y. A Multilayer-Learning Current-Mode Neuromorphic System with Analog-Error Compensation. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 986–998. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.; Lee, Y.; Park, M. Energy efficiency of machine learning in embedded systems using neuromorphic hardware. Electronics 2020, 9, 1069. [Google Scholar] [CrossRef]
- Morro, A.; Canals, V.; Oliver, A.; Alomar, M.; Galan-Prado, F.; Ballester, P.; Rossello, J. A Stochastic Spiking Neural Network for Virtual Screening. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1371–1375. [Google Scholar] [CrossRef] [PubMed]
- Nascimento, I.; Jardim, R.; Morgado-Dias, F. A new solution to the hyperbolic tangent implementation in hardware: Polynomial modeling of the fractional exponential part. Neural Comput. Appl. 2013, 23, 363–369. [Google Scholar] [CrossRef]
- Carrasco-Robles, M.; Serrano, L. Accurate differential tanh(nx) implementation. Int. J. Circuit Theory Appl. 2009, 37, 613–629. [Google Scholar] [CrossRef]
- Liu, B.; Zou, D.; Feng, L.; Feng, S.; Fu, P.; Li, J. An FPGA-based CNN accelerator integrating depthwise separable convolution. Electronics 2019, 8, 281. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Li, L.; Wang, H.; Liu, Y.; Qin, H.; Zhao, W. Optimized compression for implementing convolutional neural networks on FPGA. Electronics 2019, 8, 295. [Google Scholar] [CrossRef] [Green Version]
- Gaines, B.R. Stochastic computing systems. In Advances in Information Systems Science; Springer: New York, NY, USA, 1969; pp. 37–172. [Google Scholar]
- Alaghi, A.; Hayes, J. Survey of stochastic computing. Trans. Embed. Comput. Syst. 2013, 12, 1–19. [Google Scholar] [CrossRef]
- Canals, V.; Morro, A.; Rosselló, J. Stochastic-based pattern-recognition analysis. Pattern Recognit. Lett. 2010, 31, 2353–2356. [Google Scholar] [CrossRef] [Green Version]
- Faix, M.; Laurent, R.; Bessiere, P.; Mazer, E.; Droulez, J. Design of stochastic machines dedicated to approximate Bayesian inferences. IEEE Trans. Emerg. Top. Comput. 2019, 7, 60–66. [Google Scholar] [CrossRef] [Green Version]
- Joe, H.; Kim, Y. Novel stochastic computing for energy-efficient image processors. Electronics 2019, 8, 720. [Google Scholar] [CrossRef] [Green Version]
- Alaghi, A.; Li, C.; Hayes, J. Stochastic circuits for real-time image-processing applications. In Proceedings of the 50th Annual Design Automation Conference, Austin, TX, USA, 2–6 June 2013. [Google Scholar]
- Xiao, S.; Liu, W.; Guo, Y.; Yu, Z. Low-Cost Adaptive Exponential Integrate-and-Fire Neuron Using Stochastic Computing. IEEE Trans. Biomed. Circuits Syst. 2020, 14, 942–950. [Google Scholar] [CrossRef] [PubMed]
- Rosselló, J.L.; Canals, V.; Morro, A. Hardware implementation of stochastic-based Neural Networks. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Tomlinson, M.S., Jr.; Walker, D.; Sivilotti, M. A digital neural network architecture for VLSI. In Proceedings of the 1990 IJCNN International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; Volume 2, pp. 545–550. [Google Scholar] [CrossRef]
- Moon, G.; Zaghloul, M.; Newcomb, R. VLSI implementation of synaptic weighting and summing in pulse coded neural-type cells. IEEE Trans. Neural Netw. 1992, 3, 394–403. [Google Scholar] [CrossRef]
- Sato, S.; Yumine, M.; Yama, T.; Murota, J.; Nakajima, K.; Sawada, Y. LSI implementation of pulse-output neural network with programmable synapse. In Proceedings of the [Proceedings 1992] IJCNN International Joint Conference on Neural Networks, Baltimore, MD, USA, 7–11 June 1992; Volume 1, pp. 172–177. [Google Scholar] [CrossRef]
- Yousefzadeh, A.; Stromatias, E.; Soto, M.; Serrano-Gotarredona, T.; Linares-Barranco, B. On Practical Issues for Stochastic STDP Hardware with 1-bit Synaptic Weights. Front. Neurosci. 2018, 12, 665. [Google Scholar] [CrossRef] [Green Version]
- Fox, S.; Faraone, J.; Boland, D.; Vissers, K.; Leong, P.H. Training Deep Neural Networks in Low-Precision with High Accuracy Using FPGAs. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Ichihara, H.; Ishii, S.; Sunamori, D.; Iwagaki, T.; Inoue, T. Compact and accurate stochastic circuits with shared random number sources. In Proceedings of the 2014 IEEE 32nd International Conference on Computer Design (ICCD), Seoul, Korea, 19–22 October 2014; pp. 361–366. [Google Scholar] [CrossRef]
- Oliver, A.; Canals, V.; Rosselló, J. A Bayesian target predictor method based on molecular pairing energies estimation. Sci. Rep. 2017, 7, 43738. [Google Scholar] [CrossRef] [Green Version]
- Mysinger, M.; Carchia, M.; Irwin, J.; Shoichet, B. Directory of useful decoys, enhanced (DUD-E): Better ligands and decoys for better benchmarking. J. Med. Chem. 2012, 55, 6582–6594. [Google Scholar] [CrossRef]
- Sliwoski, G.; Kothiwale, S.; Meiler, J.; Lowe, E., Jr. Computational methods in drug discovery. Pharmacol. Rev. 2014, 66, 334–395. [Google Scholar] [CrossRef] [Green Version]
- Gasteiger, J.; Marsili, M. Iterative partial equalization of orbital electronegativity—A rapid access to atomic charges. Tetrahedron 1980, 36, 3219–3228. [Google Scholar] [CrossRef]
- Halgren, T. Merck molecular force field. I. Basis, form, scope, parameterization, and performance of MMFF94. J. Comput. Chem. 1996, 17, 490–519. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Gaines, B.R. Origins of Stochastic Computing. In Stochastic Computing: Techniques and Applications; Springer International Publishing: Cham, Switzerland, 2019; pp. 13–37. [Google Scholar]
- Alaghi, A.; Hayes, J. Exploiting correlation in stochastic circuit design. In Proceedings of the 2013 IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013. [Google Scholar]
- Parhami, B.; Chi-Hsiang, Y. Accumulative parallel counters. In Proceedings of the Conference Record of The Twenty-Ninth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 30 October–2 November 1995; Volume 2, pp. 966–970. [Google Scholar] [CrossRef]
- Ren, A.; Li, Z.; Ding, C.; Qiu, Q.; Wang, Y.; Li, J.; Qian, X.; Yuan, B. Sc-dcnn: Highly-scalable deep convolutional neural network using stochastic computing. ACM SIGPLAN Not. 2017, 52, 405–418. [Google Scholar] [CrossRef]
- Yu, J.; Kim, K.; Lee, J.; Choi, K. Accurate and efficient stochastic computing hardware for convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Computer Design (ICCD), Boston, MA, USA, 5–8 November 2017; pp. 105–112. [Google Scholar]
- Li, Z.; Li, J.; Ren, A.; Cai, R.; Ding, C.; Qian, X.; Draper, J.; Yuan, B.; Tang, J.; Qiu, Q.; et al. HEIF: Highly efficient stochastic computing-based inference framework for deep neural networks. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 38, 1543–1556. [Google Scholar] [CrossRef]
- Yaguchi, A.; Suzuki, T.; Asano, W.; Nitta, S.; Sakata, Y.; Tanizawa, A. Adam Induces Implicit Weight Sparsity in Rectifier Neural Networks. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 318–325. [Google Scholar] [CrossRef] [Green Version]
- Cleves, A.; Johnson, S.; Jain, A. Electrostatic-field and surface-shape similarity for virtual screening and pose prediction. J. Comput.-Aided Mol. Des. 2019, 33, 865–886. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Von Behren, M.; Rarey, M. Ligand-based virtual screening under partial shape constraints. J. Comput.-Aided Mol. Des. 2017, 31, 335–347. [Google Scholar] [CrossRef] [PubMed]
- Koes, D.R.; Camacho, C.J. Shape-based virtual screening with volumetric aligned molecular shapes. J. Comput. Chem. 2014, 35, 1824–1834. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ballester, P.J.; Richards, W.G. Ultrafast shape recognition to search compound databases for similar molecular shapes. J. Comput. Chem. 2007, 28, 1711–1723. [Google Scholar] [CrossRef] [PubMed]
- Puertas-Martín, S.; Redondo, J.L.; Ortigosa, P.M.; Pérez-Sánchez, H. OptiPharm: An evolutionary algorithm to compare shape similarity. Sci. Rep. 2019, 9, 1398. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AUC Mean | Speed (inf/s) | Power (W) | Energy Efficiency (inf/Joule) | ANN Cores | FPGA ALM (%) | FPGA DSP (%) | FPGA BRAM (%) | Clk Freq (MHz) |
|---|---|---|---|---|---|---|---|---|---|
| SC-12 | 0.62 | 3,205,128 | 21 | 152,625 | 105 | 340,305 (80%) | 0 (0%) | 0 (0%) | 125 |
| SC-24 | 0.71 | 1,373,626 | 21 | 65,411 | 45 | 329,715 (77%) | 0 (0%) | 0 (0%) | 125 |
| SC-48 | 0.78 | 549,451 | 21 | 26,164 | 18 | 309,909 (73%) | 0 (0%) | 0 (0%) | 125 |
| SW-12 | 0.66 | 43,573 | 95 | 459 | 1 | - | - | - | - |
| SW-24 | 0.72 | 42,034 | 95 | 442 | 1 | - | - | - | - |
| SW-48 | 0.79 | 37,397 | 95 | 394 | 1 | - | - | - | - |
| Model | AUC Mean | Speed (inf/s) |
|---|---|---|
| This work (SC-48) | 0.78 | 549,451 |
| This work (SC-24) | 0.71 | 1,373,626 |
| eSim-pscreen [57] | 0.76 | 12.3 |
| eSim-pfast [57] | 0.74 | 61.2 |
| eSim-pfastf [57] | 0.71 | 274.9 |
| mRAISE [58] | 0.74 | – |
| ROCS [59] | 0.60 | 1820 |
| USR [59,60] | 0.52 | |
| VAMS [59] | 0.56 | 109,000 |
| WEGA [61] | 0.564 | |
| OptimPharm [61] | 0.56 |
| Model | % AUC <0.5 | % AUC ≥0.6 | % AUC ≥0.7 | % AUC ≥0.8 | % AUC ≥0.9 |
|---|---|---|---|---|---|
| This work (SC-48) | 0 | 92 | 74 | 43 | 18 |
| eSim-pscreen [57] | 5 | 81 | 69 | 43 | 17 |
| eSim-pfast [57] | 9 | 82 | 62 | 34 | 14 |
| eSim-pfast [57] | 5 | 79 | 53 | 26 | 6 |
| Target | Proposed Model | Max (Other) | Target | Proposed Model | Max (Other) | Target | Proposed Model | Max (Other) |
|---|---|---|---|---|---|---|---|---|
| aa2ar | 0.80 | 0.76 | fabp4 | 0.85 | 0.83 | mmp13 | 0.91 | 0.72 |
| abl1 | 0.69 | 0.73 | fak1 | 0.72 | 0.95 | mp2k1 | 0.87 | 0.63 |
| ace | 0.86 | 0.75 | fgfr1 | 0.98 | 0.71 | nos1 | 0.90 | 0.53 |
| aces | 0.81 | 0.52 | fkb1a | 0.77 | 0.72 | nram | 0.83 | 0.9 |
| ada | 0.81 | 0.91 | fnta | 0.74 | 0.78 | pa2ga | 0.85 | 0.74 |
| ada17 | 0.86 | 0.8 | fpps | 0.99 | 0.99 | parp1 | 0.74 | 0.9 |
| adrb1 | 0.80 | 0.7 | gcr | 0.77 | 0.64 | pde5a | 0.74 | 0.73 |
| adrb2 | 0.83 | 0.65 | glcm | 0.89 | 0.78 | pgh1 | 0.65 | 0.73 |
| akt1 | 0.74 | 0.58 | gria2 | 0.68 | 0.68 | pgh2 | 0.85 | 0.84 |
| akt2 | 0.55 | 0.66 | grik1 | 0.67 | 0.73 | plk1 | 0.78 | 0.82 |
| aldr | 0.75 | 0.71 | hdac2 | 0.77 | 0.53 | pnph | 0.86 | 0.92 |
| ampc | 0.78 | 0.76 | hdac8 | 0.77 | 0.85 | ppara | 0.92 | 0.9 |
| andr | 0.68 | 0.71 | hivint | 0.56 | 0.49 | ppard | 0.92 | 0.81 |
| aofb | 0.54 | 0.46 | hivpr | 0.83 | 0.84 | pparg | 0.89 | 0.79 |
| bace1 | 0.79 | 0.54 | hivrt | 0.73 | 0.71 | prgr | 0.70 | 0.81 |
| braf | 0.74 | 0.77 | hmdh | 0.86 | 0.91 | ptn1 | 0.82 | 0.57 |
| cah2 | 0.99 | 0.92 | hs90a | 0.65 | 0.8 | pur2 | 0.95 | 1 |
| casp3 | 0.89 | 0.58 | hxk4 | 0.82 | 0.9 | pygm | 0.80 | 0.58 |
| cdk2 | 0.72 | 0.8 | igf1r | 0.73 | 0.61 | pyrd | 0.80 | 0.9 |
| comt | 0.97 | 0.99 | inha | 0.54 | 0.72 | reni | 0.81 | 0.79 |
| cp2c9 | 0.53 | 0.52 | ital | 0.70 | 0.77 | rock1 | 0.58 | 0.79 |
| cp3a4 | 0.59 | 0.58 | jak2 | 0.55 | 0.81 | rxra | 0.87 | 0.93 |
| csf1r | 0.66 | 0.8 | kif11 | 0.65 | 0.83 | sahh | 0.94 | 1 |
| cxcr4 | 0.73 | 0.79 | kit | 0.75 | 0.69 | src | 0.69 | 0.67 |
| def | 0.66 | 0.86 | kith | 0.93 | 0.91 | tgfr1 | 0.71 | 0.84 |
| dhi1 | 0.78 | 0.68 | kpcb | 0.66 | 0.85 | thb | 0.72 | 0.89 |
| dpp4 | 0.78 | 0.73 | lck | 0.69 | 0.55 | thrb | 0.85 | 0.83 |
| drd3 | 0.72 | 0.46 | lkha4 | 0.61 | 0.84 | try1 | 0.91 | 0.87 |
| dyr | 0.96 | 0.95 | mapk2 | 0.69 | 0.86 | tryb1 | 0.80 | 0.83 |
| egfr | 0.61 | 0.77 | mcr | 0.88 | 0.79 | tysy | 0.88 | 0.92 |
| esr1 | 0.94 | 0.96 | met | 0.67 | 0.87 | urok | 0.95 | 0.81 |
| esr2 | 0.94 | 0.97 | mk01 | 0.67 | 0.79 | vgfr2 | 0.63 | 0.75 |
| fa10 | 0.84 | 0.73 | mk10 | 0.77 | 0.56 | wee1 | 0.88 | 1 |
| fa7 | 0.94 | 0.96 | mk14 | 0.70 | 0.61 | xiap | 0.79 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frasser, C.F.; de Benito, C.; Skibinsky-Gitlin, E.S.; Canals, V.; Font-Rosselló, J.; Roca, M.; Ballester, P.J.; Rosselló, J.L. Using Stochastic Computing for Virtual Screening Acceleration. Electronics 2021, 10, 2981. https://doi.org/10.3390/electronics10232981
Frasser CF, de Benito C, Skibinsky-Gitlin ES, Canals V, Font-Rosselló J, Roca M, Ballester PJ, Rosselló JL. Using Stochastic Computing for Virtual Screening Acceleration. Electronics. 2021; 10(23):2981. https://doi.org/10.3390/electronics10232981
Chicago/Turabian StyleFrasser, Christiam F., Carola de Benito, Erik S. Skibinsky-Gitlin, Vincent Canals, Joan Font-Rosselló, Miquel Roca, Pedro J. Ballester, and Josep L. Rosselló. 2021. "Using Stochastic Computing for Virtual Screening Acceleration" Electronics 10, no. 23: 2981. https://doi.org/10.3390/electronics10232981
APA StyleFrasser, C. F., de Benito, C., Skibinsky-Gitlin, E. S., Canals, V., Font-Rosselló, J., Roca, M., Ballester, P. J., & Rosselló, J. L. (2021). Using Stochastic Computing for Virtual Screening Acceleration. Electronics, 10(23), 2981. https://doi.org/10.3390/electronics10232981