
IPGM: Inertial Proximal Gradient Method for Convolutional Dictionary Learning


Abstract
:1. Introduction
2. Related Knowledge
2.1. Convex CDL in the Time Domain via Local Processing
2.2. Forward–Backward Splitting
2.3. Inertia Item
3. Proposed IPGM Algorithm
| Algorithm 1 The IPGM algorithm for solving the proposed CDL problem via local processing |
| Input: initial dictionary ; initial dictionary ; initial coefficients map ; initial coefficient maps ; adaptive parameter ; choose close to 0; inertial parameter ; and descent parameter , where is the Lipschitz constant of . Output: learned dictionary ; learned coefficients ; 1: Initialization: 2: repeat 3: if , then 4: , 5: else 6: compute using Equation (19) 7: 8: end if 9: 10: repeat 11: compute and using Equations (13) and (14) 12: compute using Equations (15) and (16) 13: update using Equation (17) 14: 15: 16: 17: until Equation (21) is satisfied 18: , 19: 20: 21: until and is monotonically decreasing 22: 23: until convergence 24: return |
4. Computational Complexity Analysis
5. Proof of the Convergence of Algorithm 1
6. Convergence Rate
7. Experimental Results and Analysis
7.1. Experimental Setup
7.1.1. List of Compared Methods
- SBDL denotes the method proposed in [23] based on convex optimization with an norm-based sparsity-inducing function that uses slices via local processing.
- Local block coordinate descent (LoBCoD) denotes the method proposed in [24] based on convex optimization with an norm-based sparsity-inducing function that utilizes needle-based representation via local processing.
- The PGM denotes the method proposed in [1] based on convex optimization with an norm-based sparsity-inducing function that uses the Fast Fourier transform (FFT) operation.
- The IPGM denotes the method proposed in Algorithm 1 in this paper uses needle-based representation via local processing.
7.1.2. Parameter Settings
- In SBDL [23], the model parameter is , and its initial value is 1. The maximum nonzero value of the LARS algorithm is 5. The filter size of the dictionary is 11*11*100. In addition, special techniques are used in the first few iterations of the dictionary learning process.
- In LoBCoD [24], the model parameter is initialized to 1. The maximum nonzero value of the LARS algorithm is 5. The filter format of the dictionary is 11*11*100. In addition, the dictionary learning process first carries out 40 iterations and then uses the proximal gradient descent algorithm.
- In the PGM [1] model, the Lipschitz constant L is set to 1000 for fruit, and .
- In the IPGM, the model parameter is set at 1000 for fruit, and .
7.1.3. Implementation Details
7.2. Efficiency of Dictionary Learning Algorithms
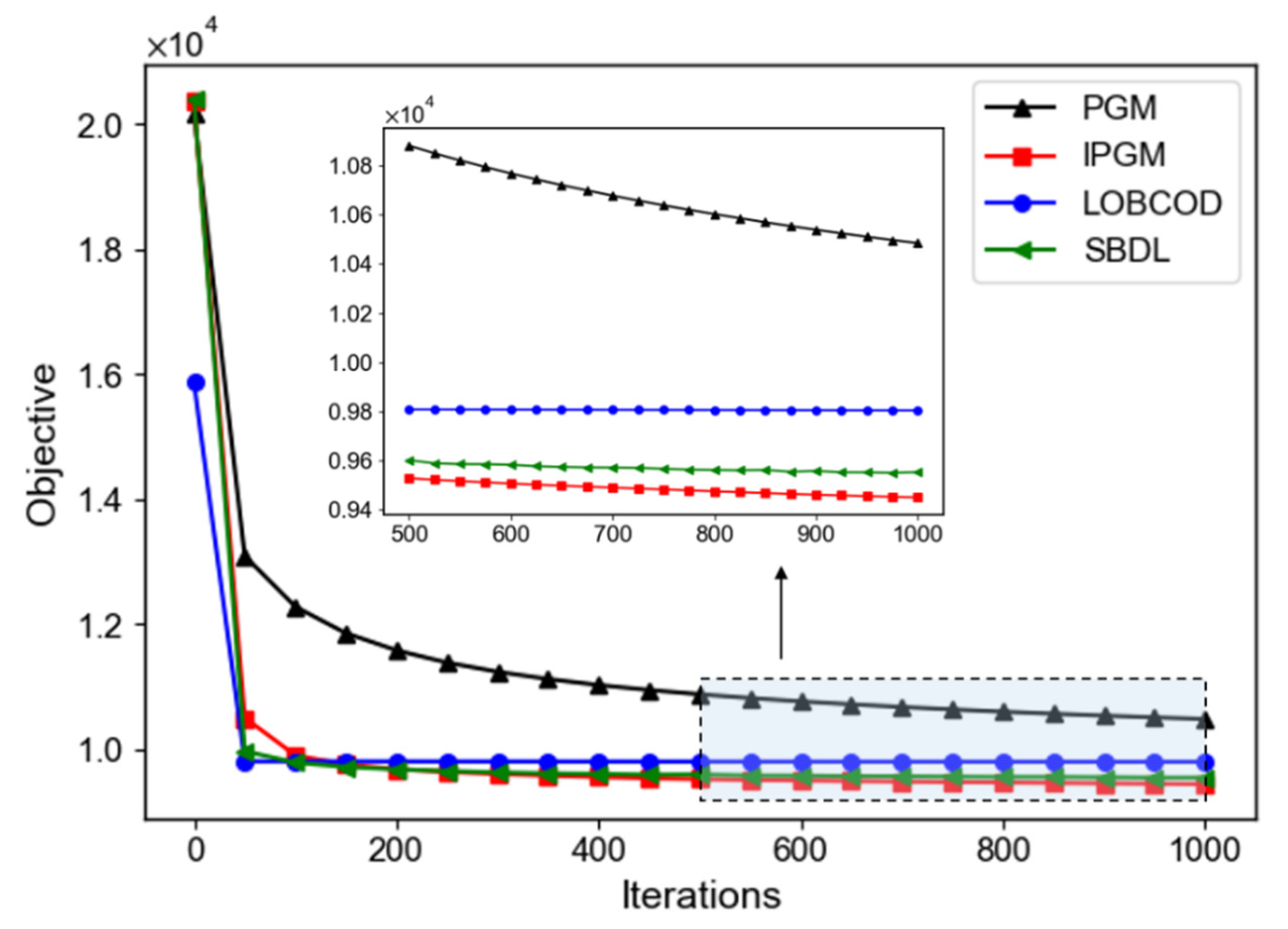
7.2.1. Motivation and Evaluation Metrics
- Final Value of and the Algorithmic Convergence Properties: In the minimization-based analysis method, we use the function value of the generated sequence to evaluate its optimization efficiency and convergence.
- Computing Time: We compare the computing times of the SBDL, LoBCoD, PGM, and IPGM algorithms and compare the computing efficiency.
7.2.2. Training Data and Experimental Settings
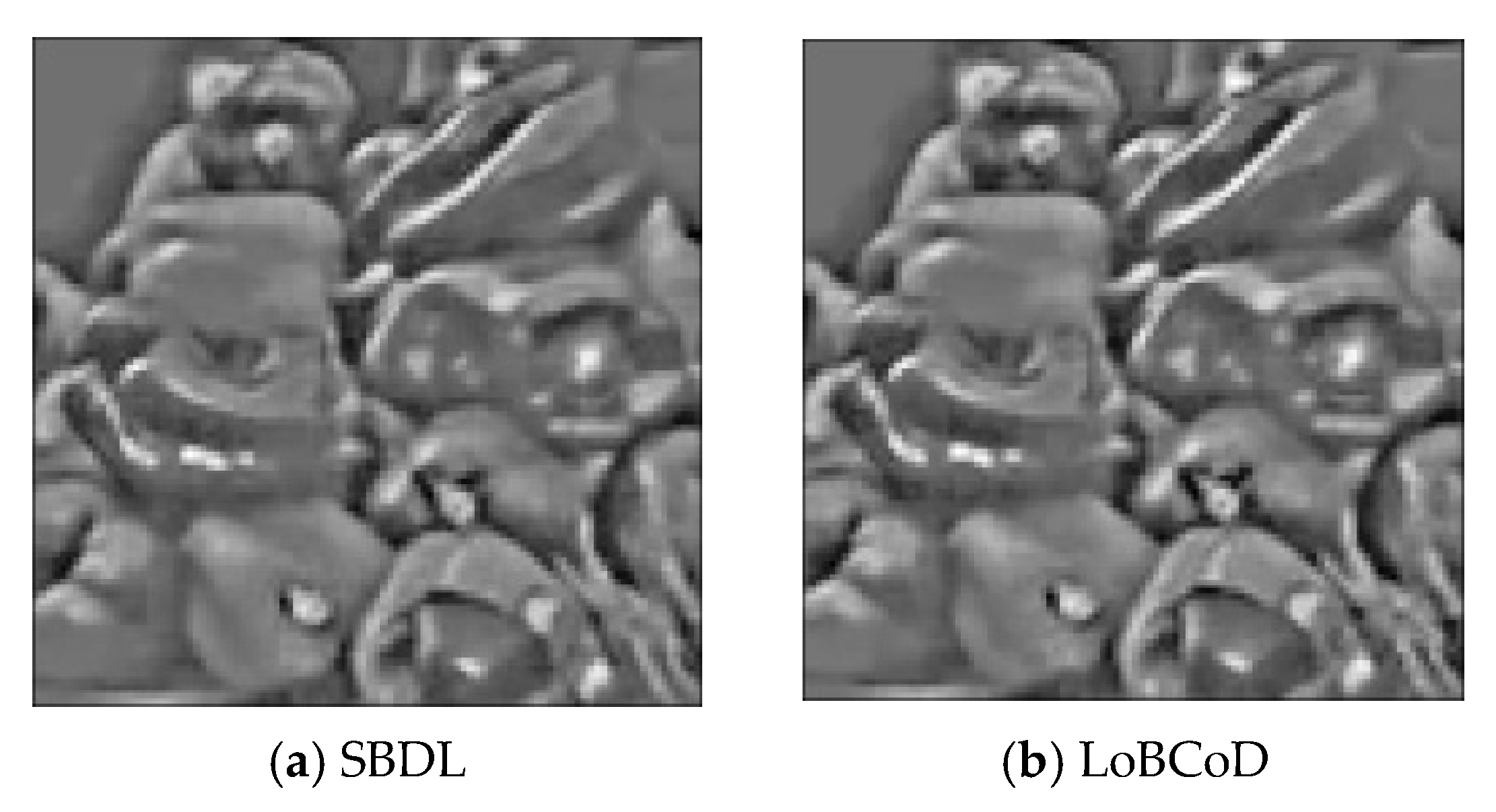
7.2.3. Results
7.2.4. Discussion
7.3. Ablation Experiment
7.3.1. Motivation and Evaluation Metrics
7.3.2. Training Data and Experimental Settings
7.3.3. Results
7.3.4. Discussion
- The above table summarizes the performance of the IPGM algorithm under different inertia parameter settings. Under nonconvex optimization, with the increase in the inertia parameter, the objective function value decreases, and the PSNR value increases. The effect is the best when the inertia parameter is 0.4. The objective function value is 1.167 × 104, and the PSNR value is 32.734. Under convex optimization, with the increase in the inertia parameter, the value of the objective function decreases, and the value of PSNR increases. The effect is the best when the inertia parameter is 0.9. At this time, the value of the objective function is 9.449 × 103, and the value of PSNR is 29.438. The results show that the larger the inertia parameter setting is, the better the performance of IPGM is under both convex and nonconvex constraints.
- According to the ranges of inertia parameters allowed under different constraints, the results in the above table are obtained. By comparing Table 2 and Table 3, it can be found that with the increase in inertia parameters, the PSNR of the IPGM algorithm under convex optimization constraints is higher, the objective function value is low, and the performance improves. Under the constraint of nonconvex optimization, although the PSNR of the IPGM algorithm is high, the value of the objective function is also high, and the performance is not ideal. This result shows that the simple utilized inertia term cannot achieve the perfect effect under the nonconvex constraint. In the future, we will continue to study the IPGM algorithm with dynamic inertia parameters under nonconvex optimization.
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wohlberg, B. Efficient algorithms for convolutional sparse representations. IEEE Trans. Image Process. 2016, 25, 301–315. [Google Scholar] [CrossRef] [PubMed]
- Simon, D.; Elad, M. Rethinking the CSC Model for Natural Images. In Proceedings of the Thirty-third Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 1–8. [Google Scholar]
- Zhang, H.; Patel, V.M. Convolutional Sparse and Low-Rank Coding-Based Image Decomposition. IEEE Trans. Image Process. 2018, 27, 2121–2133. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Li, C.; Han, J.; Chen, C.; Ye, Q.; Zhang, B.; Cao, X.; Liu, W. Image Reconstruction via Manifold Constrained Convolutional Sparse Coding for Image Sets. IEEE J. Sel. Top. Signal Process. 2017, 11, 1072–1081. [Google Scholar] [CrossRef] [Green Version]
- Bao, P.; Sun, H.; Wang, Z.; Zhang, Y.; Xia, W.; Yang, K.; Chen, W.; Chen, M.; Xi, Y.; Niu, S.; et al. Convolutional Sparse Coding for Compressed Sensing CT Reconstruction. IEEE Trans. Med. Imaging 2019, 38, 2607–2619. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, X.-M.; Heide, F.; Dai, Q.; Wetzstein, G. Convolutional Sparse Coding for RGB+NIR Imaging. IEEE Trans. Image Process. 2018, 27, 1611–1625. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Lucey, S. Convolutional Sparse Coding for Trajectory Reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 529–540. [Google Scholar] [CrossRef] [Green Version]
- Annunziata, R.; Trucco, E. Accelerating Convolutional Sparse Coding for Curvilinear Structures Segmentation by Refining SCIRD-TS Filter Banks. IEEE Trans. Med Imaging 2016, 35, 2381–2392. [Google Scholar] [CrossRef]
- Gu, S.; Zuo, W.; Xie, Q.; Meng, D.; Feng, X.; Zhang, L. Convolutional sparse coding for image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1823–1831. [Google Scholar]
- Wang, J.; Xia, J.; Yang, Q.; Zhang, Y. Research on Semi-Supervised Sound Event Detection Based on Mean Teacher Models Using ML-LoBCoD-NET. IEEE Access 2020, 8, 38032–38044. [Google Scholar] [CrossRef]
- Chen, S.; Billings, S.A.; Luo, W. Orthogonal least squares methods and their application to non-linear system identification. Int. J. Control 1989, 50, 1873–1896. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic Decomposition by Basis Pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef] [Green Version]
- Aharon, M.; Elad, M.; Bruckstein, A. K-svd: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Engan, K.; Aase, S.O.; Husoy, J.H. Method of optimal directions for frame design. In Proceedings of the 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing, Phoenix, AZ, USA, 15–19 March 1999; Volume 5, pp. 2443–2446. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online dictionary learning for sparse coding. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 689–696. [Google Scholar]
- Sulam, J.; Ophir, B.; Zibulevsky, M.; Elad, M. Trainlets: Dictionary learning in high dimensions. IEEE Trans. Signal Process. 2016, 64, 3180–3193. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papyan, V.; Sulam, J.; Elad, M. Working locally thinking globally: Theoretical guarantees for convolutional sparse coding. IEEE Trans. Signal Process. 2017, 65, 5687–5701. [Google Scholar] [CrossRef]
- Garcia-Cardona, C.; Wohlberg, B. Convolutional dictionary learning: A comparative review and new algorithms. IEEE Trans. Comput. Imaging 2018, 4, 366–381. [Google Scholar] [CrossRef] [Green Version]
- Bristow, H.; Eriksson, A.; Lucey, S. Fast convolutional sparse coding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 13–28 June 2013; pp. 391–398. [Google Scholar]
- Heide, F.; Heidrich, W.; Wetzstein, G. Fast and flexible convolutional sparse coding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 513–5143. [Google Scholar]
- Rey-Otero, I.; Sulam, J.; Elad, M. Variations on the Convolutional Sparse Coding Model. IEEE Trans. Signal Process. 2020, 68, 519–528. [Google Scholar] [CrossRef]
- Papyan, V.; Romano, Y.; Sulam, J.; Elad, M. Convolutional dictionary learning via local processing. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5306–5314. [Google Scholar]
- Zisselman, E.; Sulam, J.; Elad, M. A Local Block Coordinate Descent Algorithm for the Convolutional Sparse Coding Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 8200–8209. [Google Scholar]
- Peng, G. Adaptive ADMM for Dictionary Learning in Convolutional Sparse Representation. IEEE Trans. Image Process. 2019, 28, 3408–3422. [Google Scholar] [CrossRef] [PubMed]
- Elad, P.; Raja, G. Matching Pursuit Based Convolutional Sparse Coding. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6847–6851. [Google Scholar]
- Chun, I.I.Y.; Fessler, J. Convolutional dictionary learning: Acceleration and convergence. IEEE Trans. Image Process. 2017, 27, 1697–1712. [Google Scholar] [CrossRef] [PubMed]
- Peng, G. Joint and Direct Optimization for Dictionary Learning in Convolutional Sparse Representation. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 559–573. [Google Scholar] [CrossRef]
- Attouch, H.; Bolte, J.; Svaiter, B.F. Convergence of descentmethods for semi-algebraic and tame problems: Proximal algorithms, forward–backward splitting, and regularized Gauss–Seidel methods. Math. Program. 2013, 137, 91–129. [Google Scholar] [CrossRef]
- Polyak, B.T. Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Ochs, P.; Chen, Y.; Brox, T.; Pock, T. iPiano: Inertial proximal algorithm for nonconvex optimization. SIAM J. Imaging Sci. 2014, 7, 1388–1419. [Google Scholar] [CrossRef]
- Rockafellar, R.T. Monotone Operators and the Proximal Point Algorithm. SIAM J. Appl. Math. 1976, 14, 877–898. [Google Scholar] [CrossRef] [Green Version]
- Moursi, W.M. The Forward-Backward Algorithm and the Normal Problem. J. Optim. Theory Appl. 2018, 176, 605–624. [Google Scholar] [CrossRef] [Green Version]
- Franci, B.; Staudigl, M.; Grammatico, S. Distributed forward-backward (half) forward algorithms for generalized Nash equilibrium seeking. In Proceedings of the 2020 European Control Conference (ECC), Saint-Petersburg, Russia, 12–15 May 2020; pp. 1274–1279. [Google Scholar]
- Molinari, C.; Peypouquet, J.; Roldan, F. Alternating forward–backward splitting for linearly constrained optimization problems. Optim. Lett. 2020, 14, 1071–1088. [Google Scholar] [CrossRef]
- Guan, W.B.; Song, W. The forward–backward splitting method and its convergence rate for the minimization of the sum of two functions in Banach spaces. Optim. Lett. 2021, 15, 1735–1758. [Google Scholar] [CrossRef]
- Abass, H.A.; Izuchukwu, C.; Mewomo, O.T.; Dong, Q.L. Strong convergence of an inertial forward-backward splitting method for accretive operators in real Hilbert space. Fixed Point Theory 2020, 21, 397–412. [Google Scholar] [CrossRef]
- Bot, R.I.; Grad, S.M. Inertial forward–backward methods for solving vector optimization problems. Optimization 2018, 67, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahookhosh, M.; Hien, L.T.K.; Gillis, N.; Patrinos, P. A block inertial Bregman proximal algorithm for nonsmooth nonconvex problems with application to symmetric nonnegative matrix tri-factorization. J. Optim. Theory Appl. 2020, 190, 234–258. [Google Scholar] [CrossRef]
- Xu, J.; Chao, M. An inertial Bregman generalized alternating direction method of multipliers for nonconvex optimization. J. Appl. Math. Comput. 2021, 1–27. [Google Scholar] [CrossRef]
- Pock, T.; Sabach, S. Inertial proximal alternating linearized minimization (iPALM) for nonconvex and nonsmooth problems. SIAM J. Imaging Sci. 2016, 9, 1756–1787. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fruit | SBDL | LoBCoD | PGM | IPGM |
|---|---|---|---|---|
| Obj | 9.545 × 103 | 9.857 × 103 | 1.048 × 104 | 9.449 × 103 |
| Data consistent | 3.067 × 103 | 3.136 × 103 | 3.528 × 103 | 3.035 × 103 |
| Regularization | 6.478 × 103 | 6.722 × 103 | 6.957 × 103 | 6.415 × 103 |
| Sparsity | 0.146% | 0.141% | 1.696% | 0.145% |
| Time (s) | 1110.134 | 1879.400 | 1955.365 | 1222.722 |
| PSNR (dB) | 29.348 | 29.252 | 28.799 | 29.438 |
| 0.1 | 0.2 | 0.3 | 0.4 | |
|---|---|---|---|---|
| Obj | 1.072 × 104 | 1.059 × 104 | 1.097 × 104 | 1.167 × 104 |
| PSNR | 31.960 | 32.139 | 32.335 | 32.734 |
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |
|---|---|---|---|---|---|---|---|---|---|
| Obj | 9.737 × 103 | 9.642 × 103 | 9.604 × 103 | 9.569 × 103 | 9.565 × 103 | 9.543 × 103 | 9.516 × 103 | 9.484 × 103 | 9.449 × 103 |
| PSNR | 29.350 | 29.394 | 29.401 | 29.427 | 29.414 | 29.422 | 29.433 | 29.431 | 29.438 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wei, X.; Wang, F.; Wang, J. IPGM: Inertial Proximal Gradient Method for Convolutional Dictionary Learning. Electronics 2021, 10, 3021. https://doi.org/10.3390/electronics10233021
Li J, Wei X, Wang F, Wang J. IPGM: Inertial Proximal Gradient Method for Convolutional Dictionary Learning. Electronics. 2021; 10(23):3021. https://doi.org/10.3390/electronics10233021
Chicago/Turabian StyleLi, Jing, Xiao Wei, Fengpin Wang, and Jinjia Wang. 2021. "IPGM: Inertial Proximal Gradient Method for Convolutional Dictionary Learning" Electronics 10, no. 23: 3021. https://doi.org/10.3390/electronics10233021
APA StyleLi, J., Wei, X., Wang, F., & Wang, J. (2021). IPGM: Inertial Proximal Gradient Method for Convolutional Dictionary Learning. Electronics, 10(23), 3021. https://doi.org/10.3390/electronics10233021