
Privacy-Preserving Surveillance as an Edge Service Based on Lightweight Video Protection Schemes Using Face De-Identification and Window Masking




Abstract
:1. Introduction
- Thorough investigations were carried out on how to identify privacy attributes and achieve a privacy-aware surveillance service in a resource-constrained environment, along with a comparative security and performance analysis.
- A new optimal and lightweight Reversible Chaotic Masking (ReCAM) scheme is proposed for scrambling video frames/images color-channel wise to ensure end-to-end privacy. It is more suitable for video frame/image scrambling at the edge than traditional data encryption schemes and existing chaotic schemes. ReCAM is a faster scheme when safety and resilience are proven based on standard security parameters and performance metrics, respectively.
- A simplified foreground object detection algorithm is introduced to ensure that edge-cameras forward only frames that contain foreground objects to improve the processing time and utilization of bandwidth and storage.
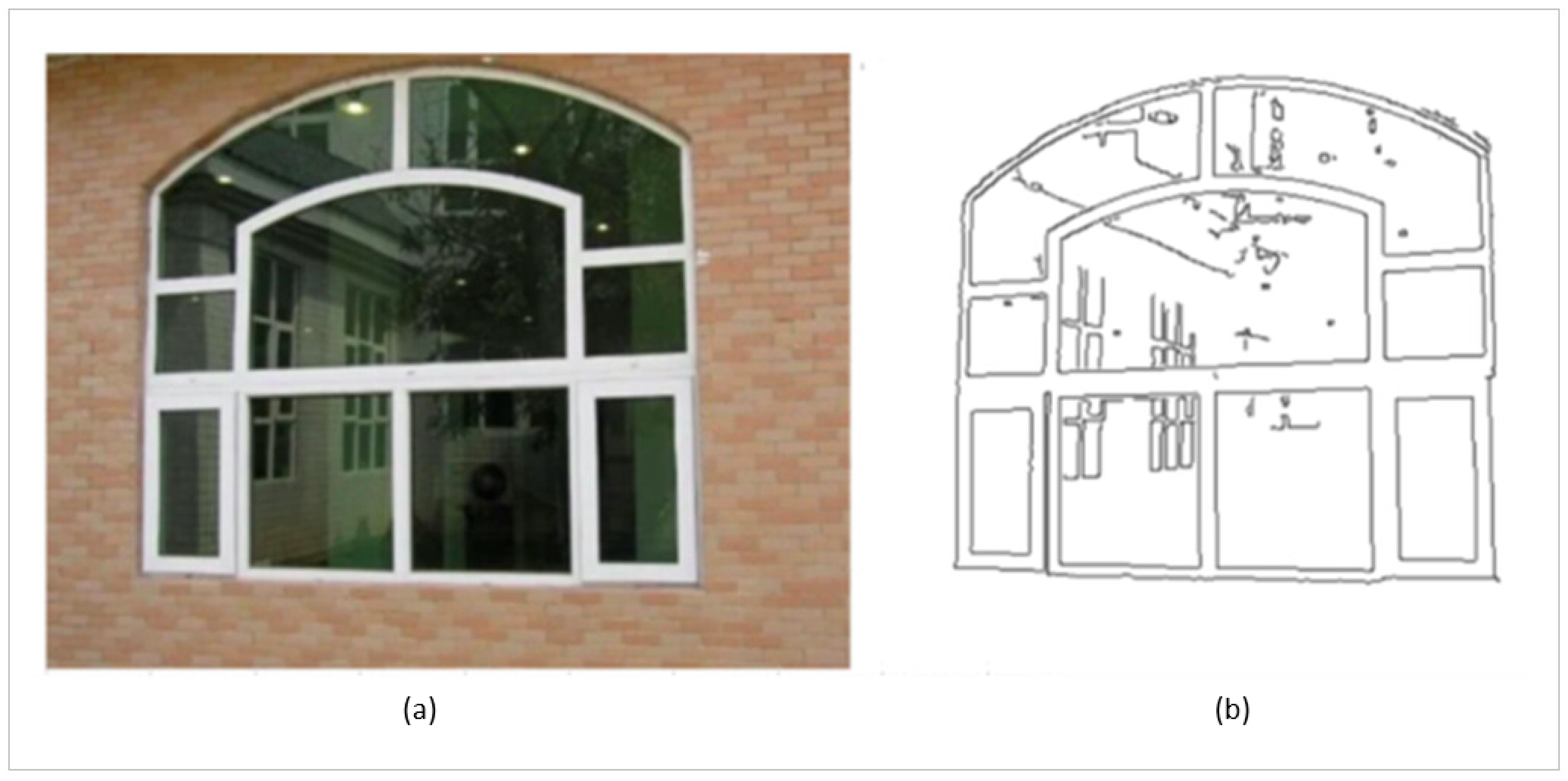
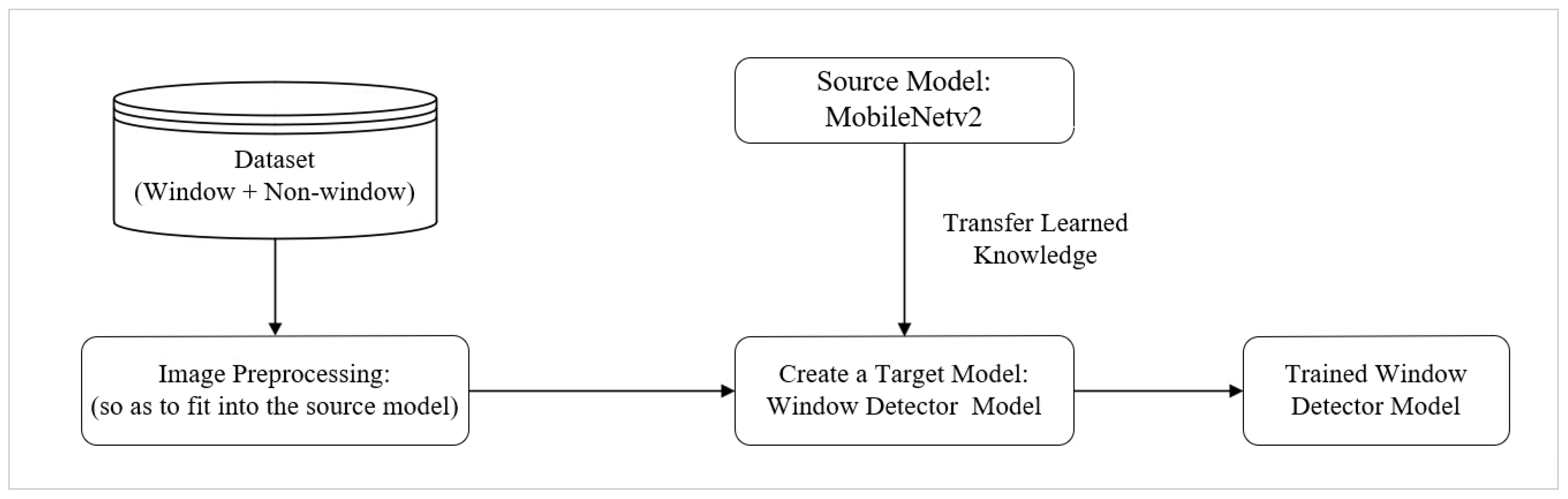
- Deep neural network (DNN) and machine learning (ML) based models to detect window-and-face objects and to identify fugitives from justice were developed and efficiently integrated. The window-object detector is developed to detect window objects so as to prevent images taken by maneuvering the cameras.
- A number of experimental studies and analyses were carried out, including performance analysis and a comparison with existing equivalent methods. The results verify that the proposed PriSE scheme provides an end-to-end privacy protection against possible interception attacks and it is able detect and denature window and face objects to prevent unauthorized data collection about people and identification of individuals caught on cameras. Besides, fugitives whose face features have been stored on databases are effectively identified and authorized personnel are alerted right away.
2. Related Works
2.1. Privacy in Surveillance Systems
2.2. Personal Privacy Attributes
2.3. Advancements in Object-Detection Methods
2.4. Video Frame Enciphering Schemes
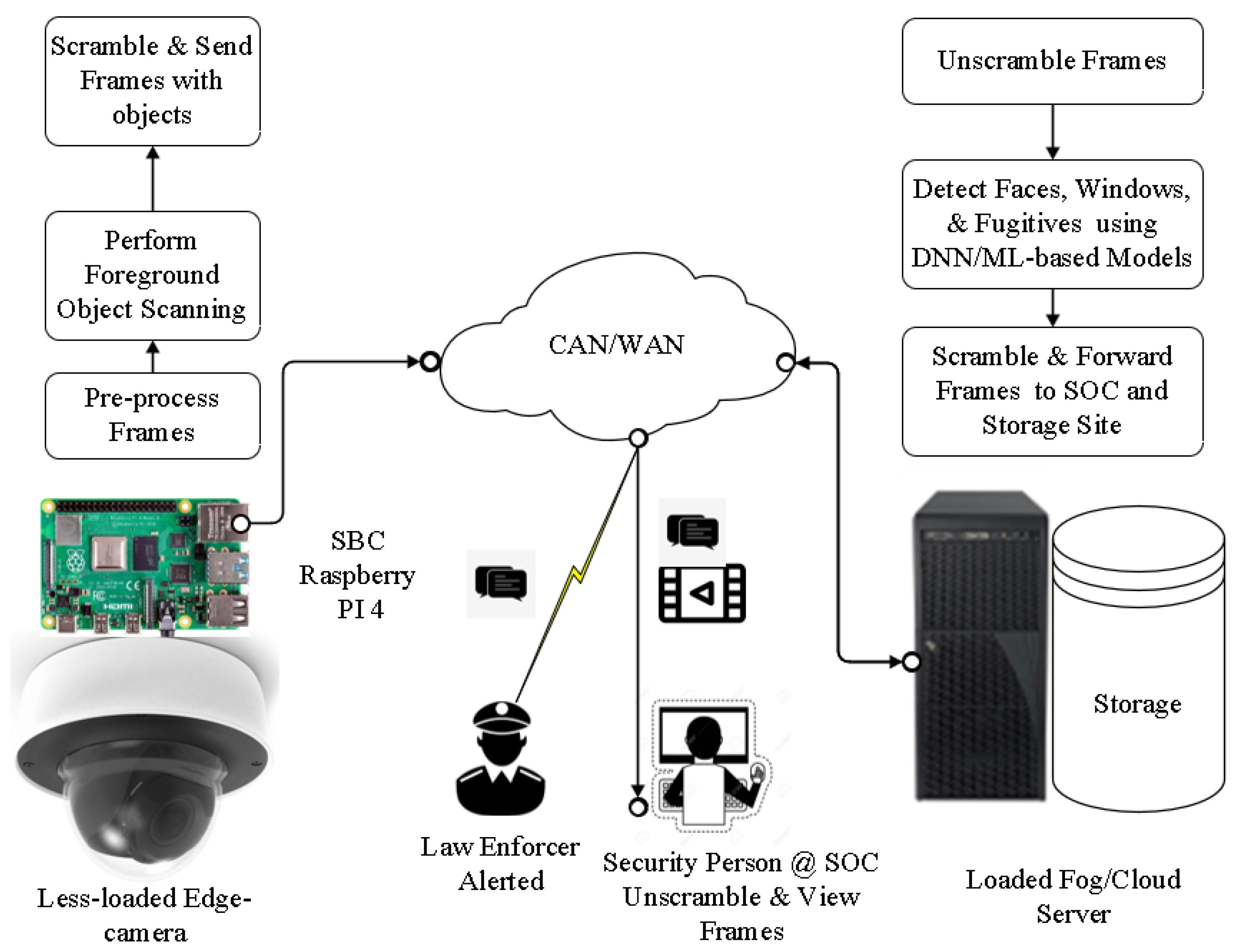
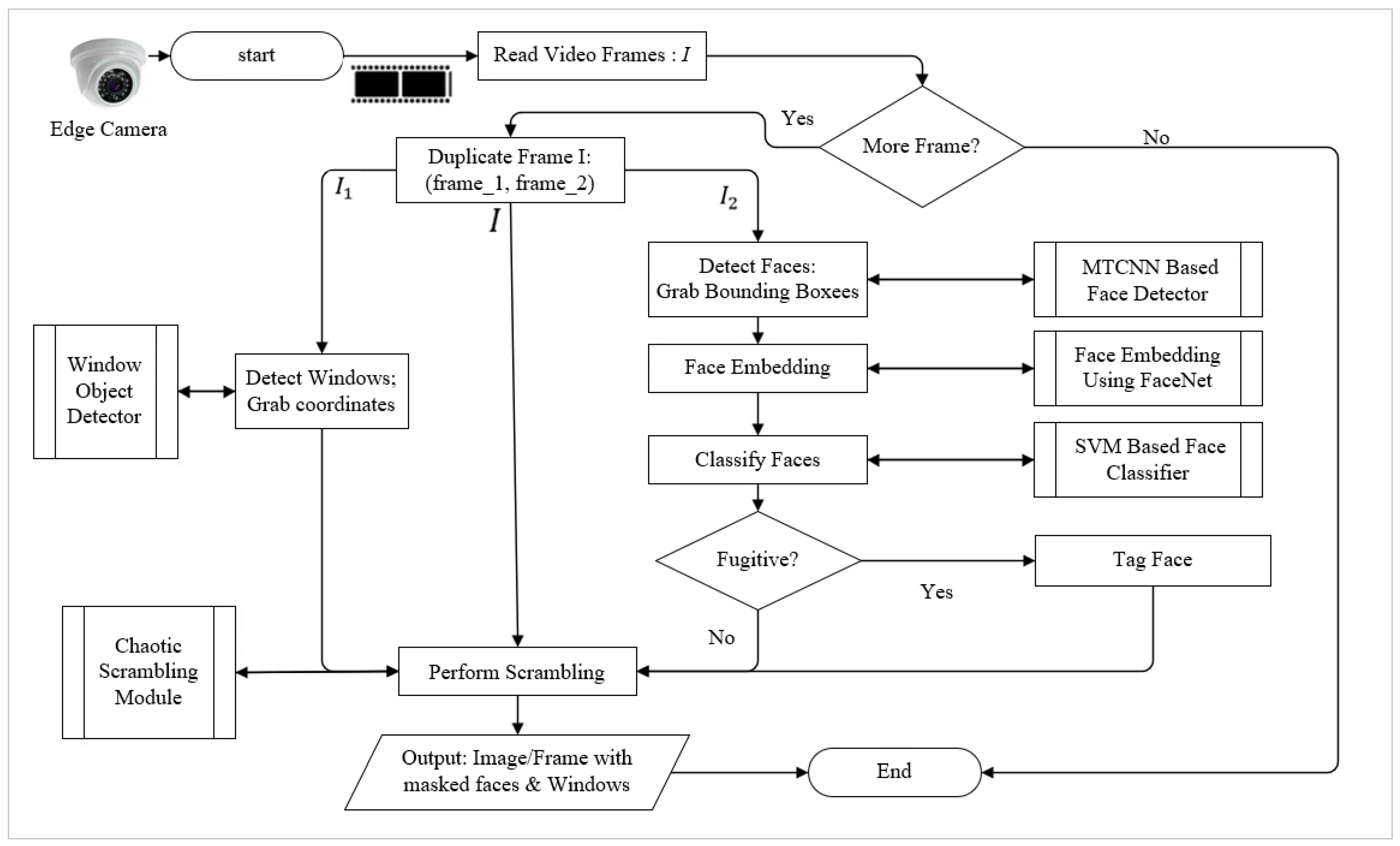
3. PriSE System Architecture
- Simplified Foreground-object Detector: It is designed to detect the presence of foreground objects or a motion based on significant changes of pixels on a current frame in comparison to a reference frame. Hence, frames that do not contain foreground objects are discarded at the edge camera for their of no interest surveillance-wise thereby saving processing time, bandwidth, and storage.
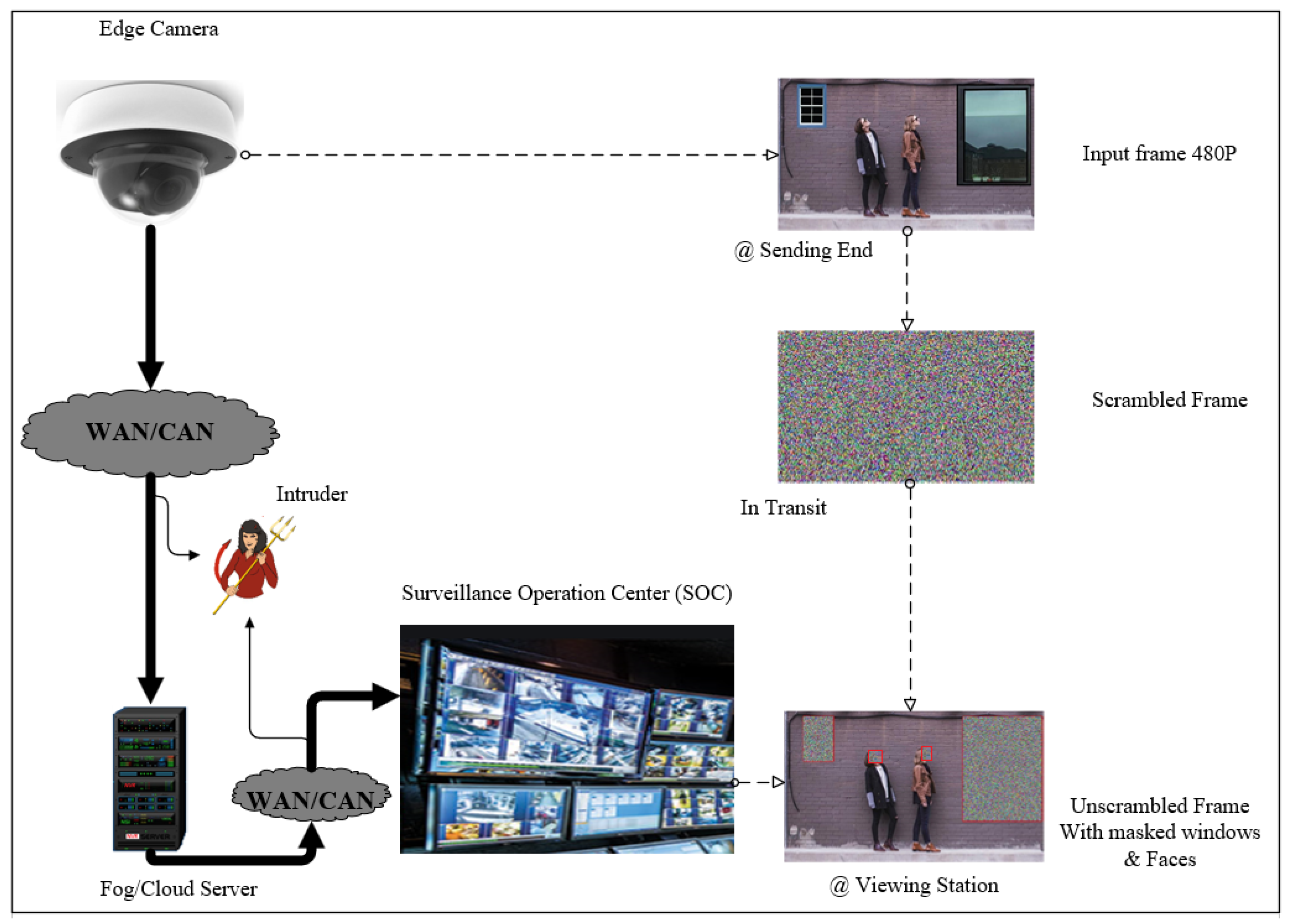
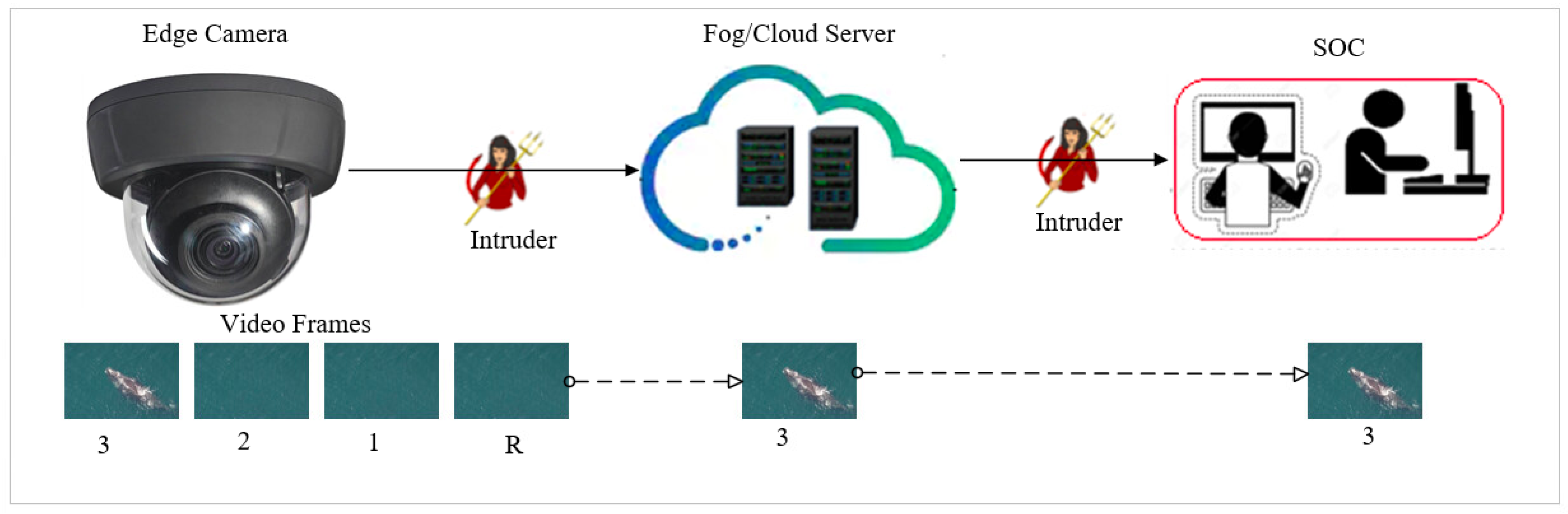
- Frame Privacy-preserving Scheme: It is the backbone of the entire proposed scheme. Primarily, the privacy of individuals could be affected either when the collected raw information is intercepted while in transit from edge cameras to cloud/fog servers over communication channels or when cameras are abused by people in charge of them to collect unauthorized information about individuals, like peeping via windows. This paper tries to address the first problem through the introduction of a slender novel chaotic image scrambling technique, ReCAM. Every frame that contains an object or objects other than the background object is encrypted at the edge camera and sent over the WAN or CAN to a cloud/fog surveillance server connected to a surveillance operation or viewing center. On arrival at the server, the unscrambling process is carried out to uncover the object-containing plain frames for subsequent processing.
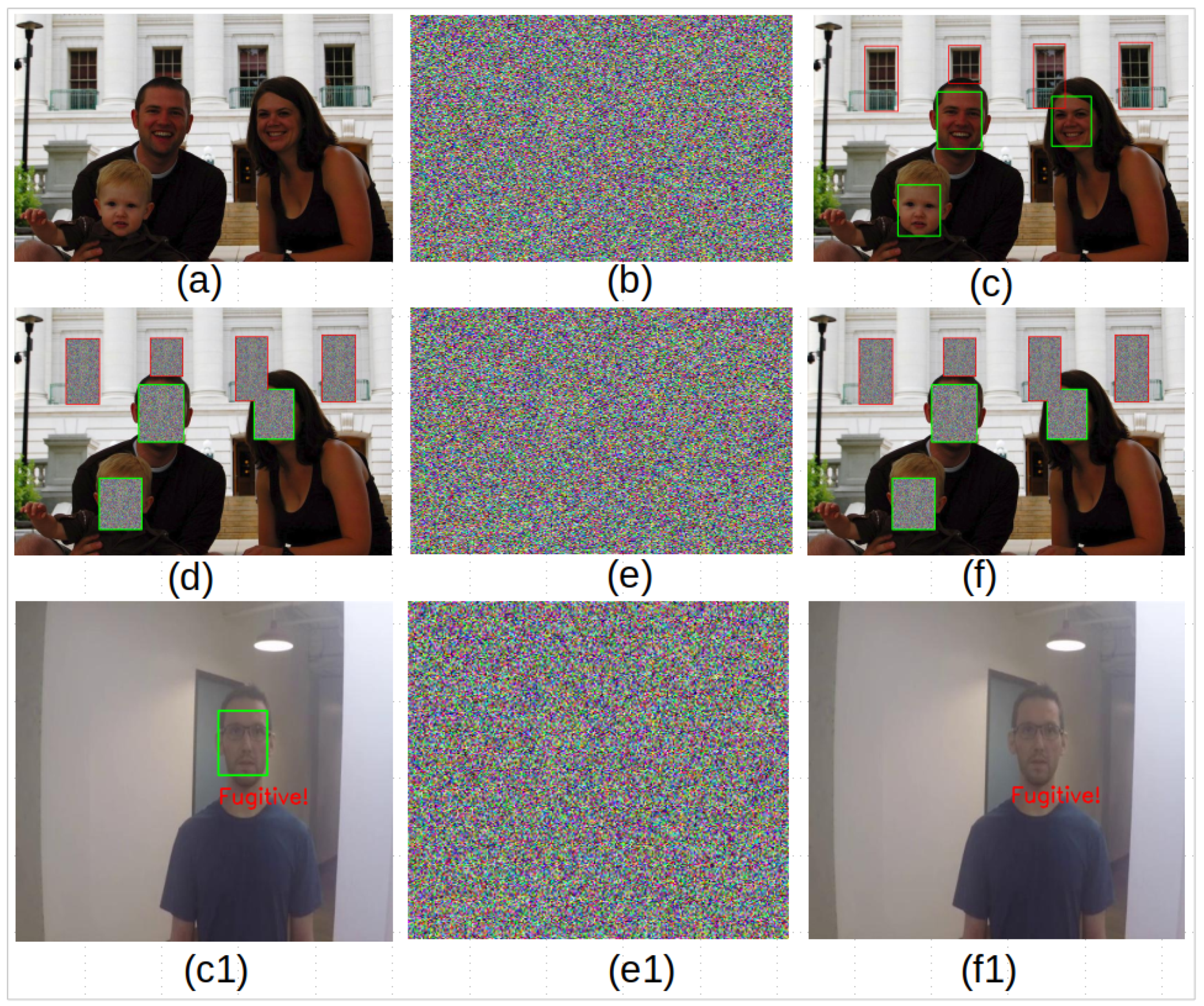
- Window and Face Objects Detection and Masking: it is introduced to stop the collection of private information and activities of individuals at their homes through the notorious practices of furtively peeping through windows and face recognition. In this paper, frames are checked if they contain windows and faces using pertinent object-detectors. If they do, the windows and faces are reversibly masked at the server before they are forwarded to the viewing station to prevent peeping and face identification, respectively.
- Detection and Classification of Fugitives: This has the goal of identifying fugitives, who elude police detection, when they happen to be caught on cameras and alerting authorized parties by means SMS texts or emails. This task is performed at the fog/cloud server following face detection and face embedding processes.
4. Simplified Motion Detector
| Algorithm 1 @ Edge Camera Foreground Detector. |
|
5. Reversible Privacy-Conserving Scheme
| Algorithm 2 Frame Scrambling and its Inverse Process. |
|
6. Window and Face Detection and Denaturing
- MTCNN based Face Detector: The MTCNN employs a three-stage cascaded framework. The first stage is the proposed network (P-Net) that estimates the bounding box regression vectors to calibrate the candidate faces after which non-maximum suppression (NMS) is applied to put highly overlapped faces together. The Refined Network (R-Net) is the second stage that refines false faces and carries out the bounding box regression calibration and NMS candidate merging. The output network (O-Net) is the third stage that describes the face in a more detailed manner. It outputs the five facial landmarks’ positions (eyes, nose, and two mouth endings). This way, the MTCNN addresses the alignment problems in many other face detection algorithms. Then, we built MTCNN-based face-detector using TensorFlow and trained it using images from the open source Challenge of Recognizing One Million Celebrities in the Real World [56].
- FaceNet [35]: A deep CNN-based unified embedding for face detection and clustering that uses a triplet loss function for training. The triplets loss function is calculated from the triplet of three pictures, Anchor (A), Negative (N), and Positive (P) images. Its main goal is to distinguish positive and negative classes by distance boundaries. It extracts high-quality 128 element vector features from the face used for future prediction and detection of faces. We employed it to create face embedding. That is, to extract the high-quality 128 element vector features from every face on a frame to be used for identifying fugitives or wanted criminals using the support vector machine (SVM) model.
- SVM Model: A Linear SVM model is developed to classify face embeddings as one of the wanted criminals or fugitives. The faces of wanted criminals or fugitives from justice are first detected and extracted using MTCNN followed by face embedding performed by the FaceNet model. Then, the face embedding vectors are normalized and fit into the SVM model. Hence, every incoming frame is tested using the trained SVM model to check whether it contains faces of wanted people. If a face is classified as wanted, it is tagged and is not denatured. Besides, the system alerts the authorized people about the detected wanted person.
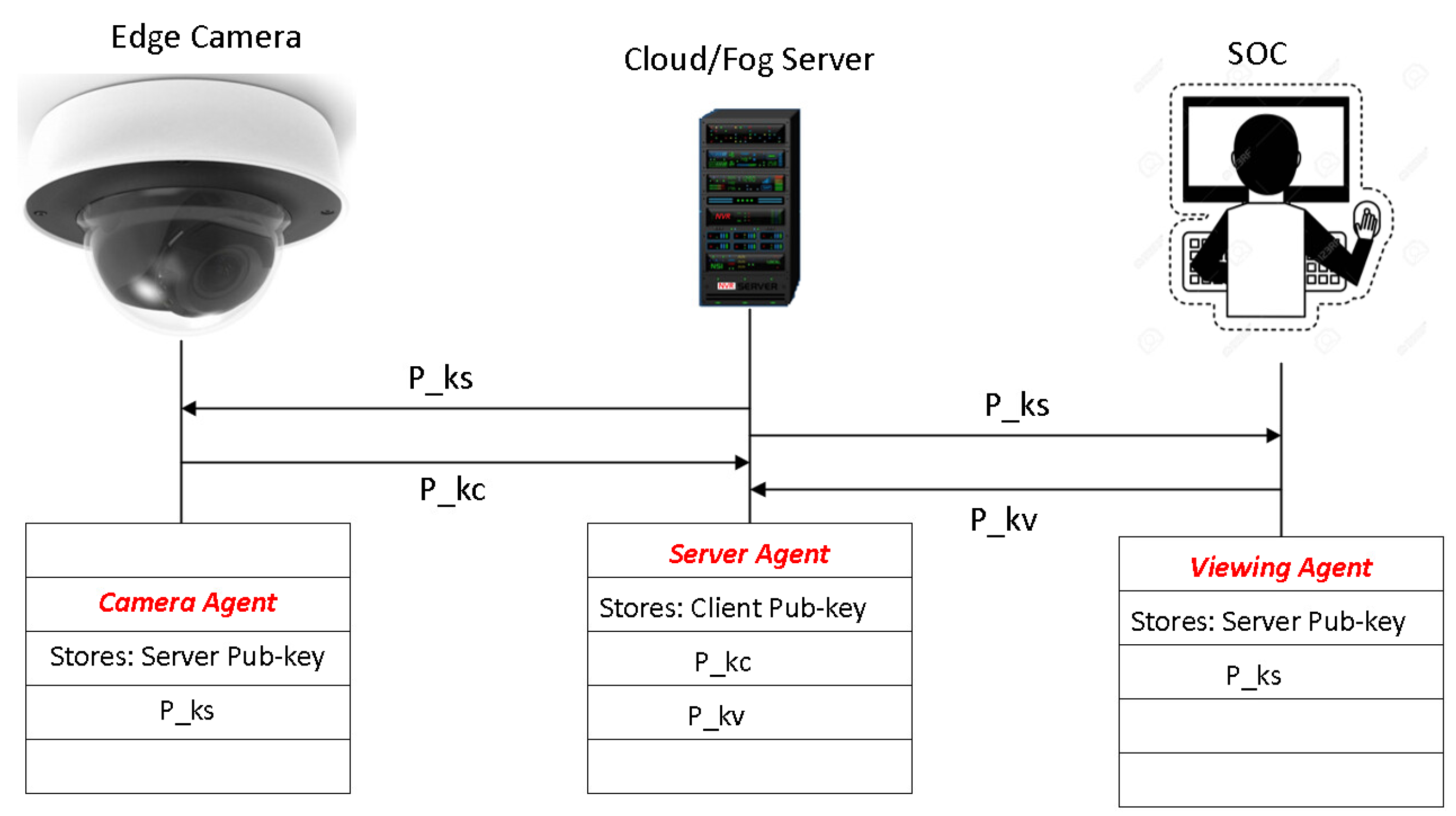
7. Key Management
8. Experimental Study
8.1. Experimental Environment Setup
8.2. Simple Motion Detector Algorithm
8.3. Security Analysis of the Scrambling Method
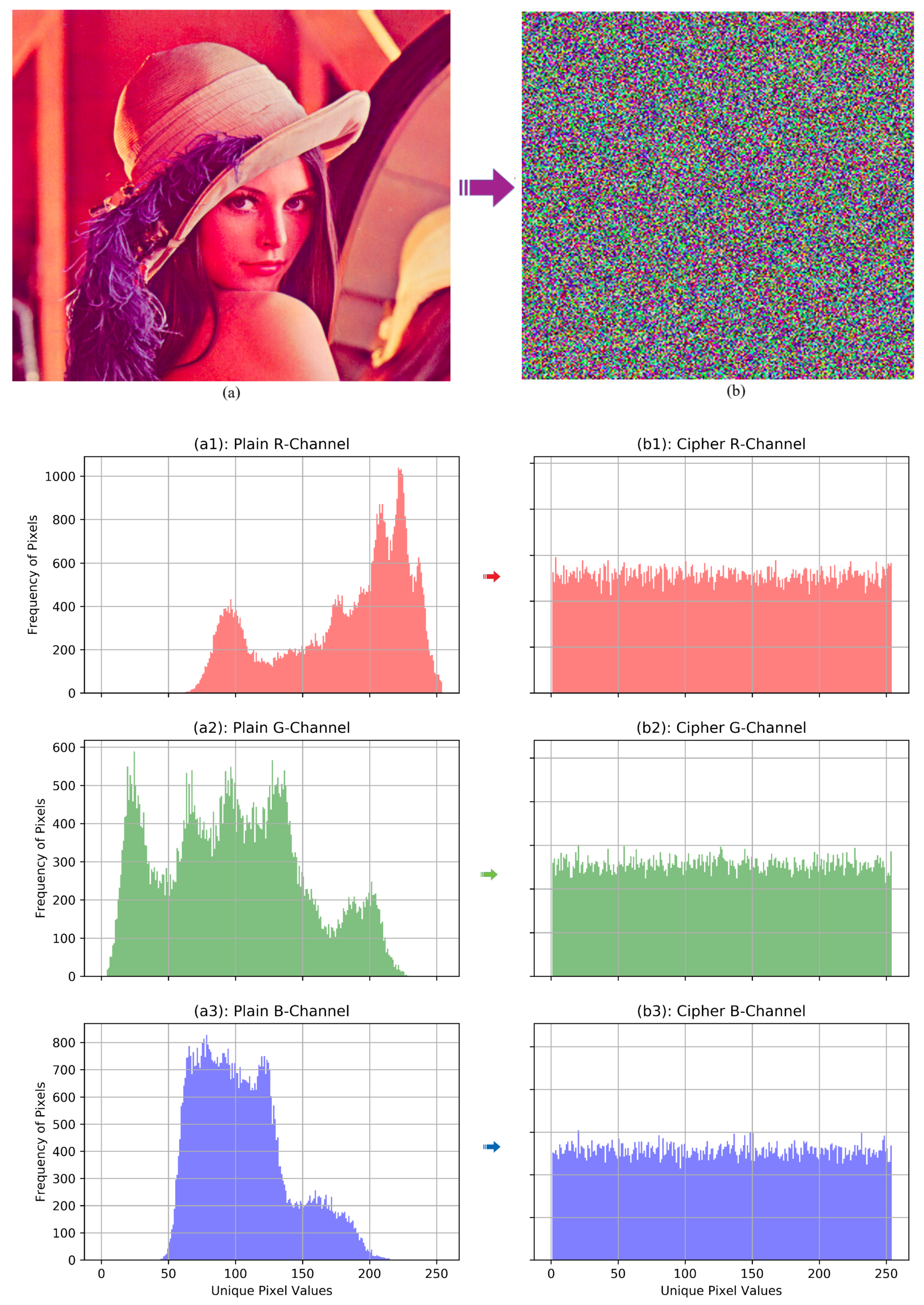
8.3.1. Visual Assessment
8.3.2. NIST Randomness Test Suite
8.3.3. Statistical Comparison
8.3.4. Histogram Analysis
8.3.5. Comparative Security Analysis
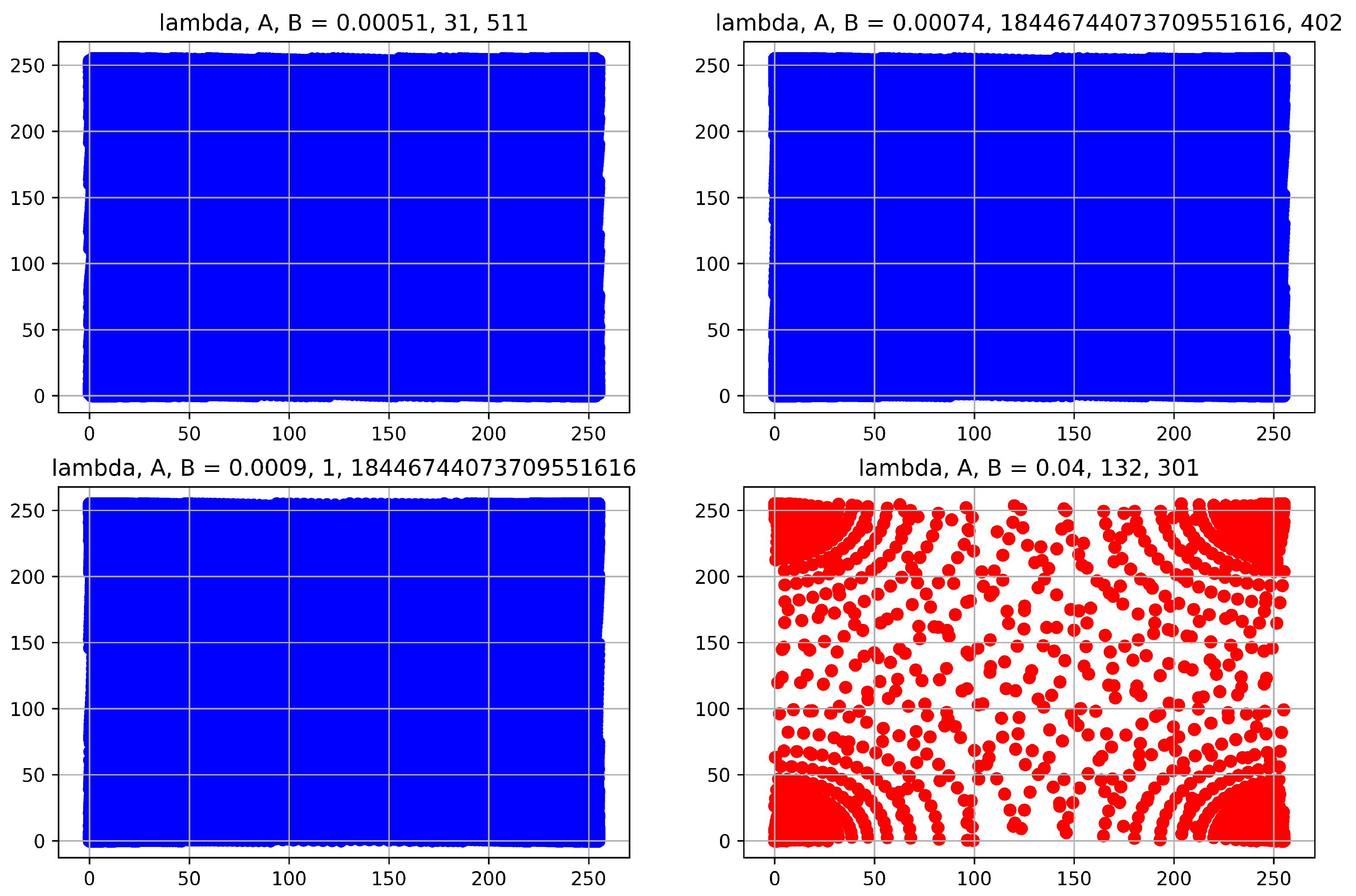
- Key Space: Key space tells whether a given scheme is resistant against exhaustive-key-search analysis. The lower boundary of a secure key space of a symmetrical encryption scheme is often considered to be , which is often determined by using Equation (12).
- Key Senstivity: Key sensitivity measures how much the cipher changes when the key is slightly changed, in this case by only a bit. It is measured in terms of Number of Pixel Change Rate (NPCR) and Unified Average Changing Intensity (UACI). A scheme with NPCR over 99% and UACI over 33% is considered to be secure against differential analysis attacks. The UACI is defined by Equation (13), which is employed to measure the average intensity difference in a color channel between its two cipher versions and . Besides, the mathematical definition of the NPCR, measures the change rate of the number of pixels of the cipher-frame when only a bit of the original key or pixel is modified, is provided by Equation (14).where H and W are the height and width of the cipher images, encrypted using and that vary from each other by only a bit. is defined by Equation (15).
- Peak Signal to Noise Ratio (PSNR): PSNR measures of the quality of reconstruction of a lossy compression technique, and usually the acceptable PSNR measurement falls between 33 and 50 decibels (dB). Nonetheless, it is employed in the opposite sense here. That is, the PSNR of a good scrambling scheme, where the plain image is considered as a signal and the cipher is considered as noise is expected to be lower, usually . A smaller PSNR indicates huge difference between the plain image and its cipher. It is defined by using Equation (16), using the input image width (W) and height (H) and the mean square error (MSE) between pairing pixels of the plain and cipher images.
- Entropy Analysis: The information entropy , defined by Equation (17), measures the amount of randomness in the information content of the scrambled image containing N pixels, where each cipher pixel is represented by . The ideal value of entropy for an 8-bit pixel image I is . Hence, a scheme with an entropy value very close to eight is secure against an entropy attack.
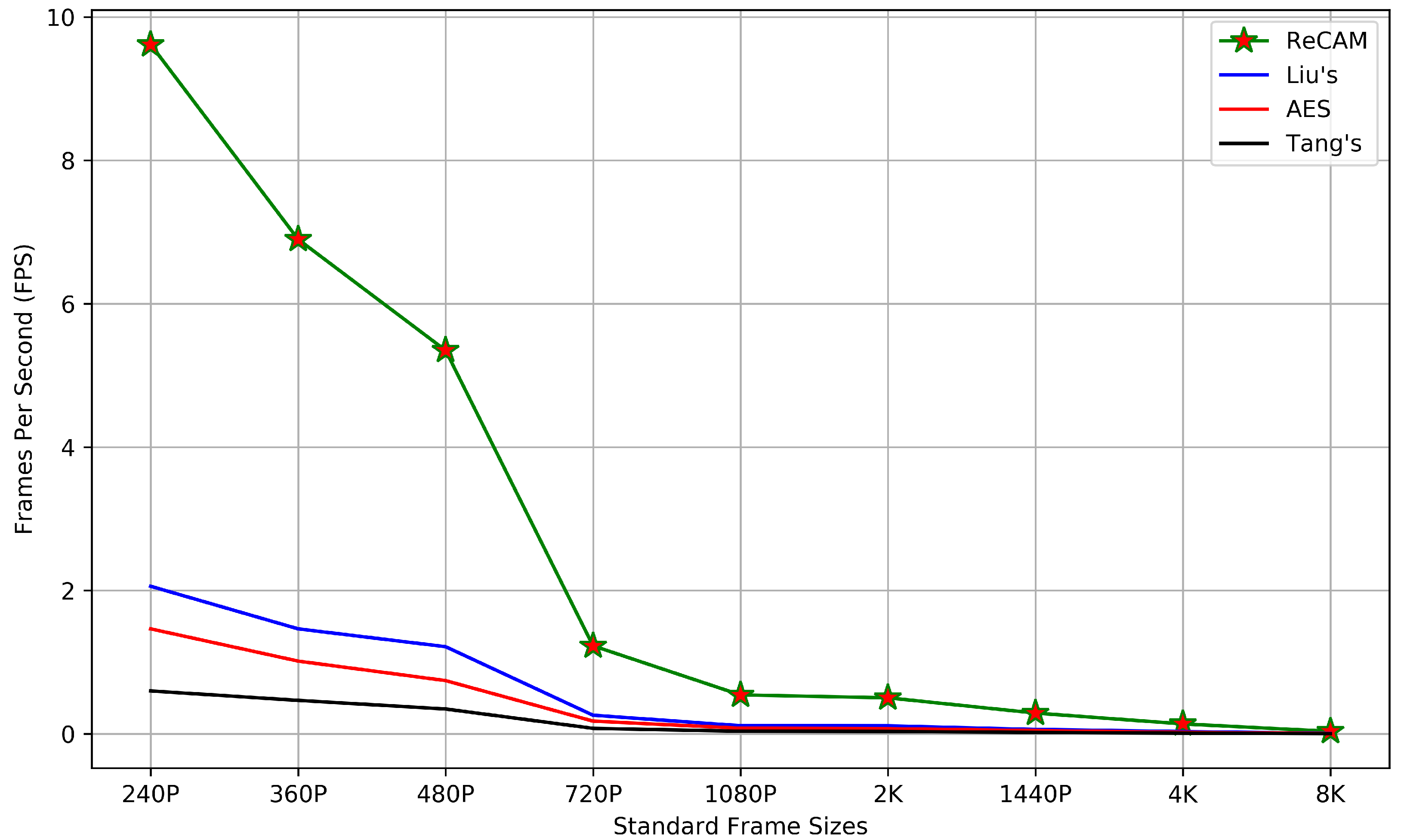
- Number of Frames/Images Processed per Second (FPS): The time complexity compares the efficiency of the methods over the amount of time required to process a frames per second (FPS), computed by using Equation (18). An observation period of one second is considered in this experiment. The higher the FPS, the better scheme is in terms of speed over processing steps such as encryption, detection, or classification.
8.3.6. Overhead Analysis
8.4. Denaturing Window and Face Objects
- Sensitivity/True Positive Rate/Recall: The sensitivity of a window detector is its ability to correctly determine the positive class (window objects). To estimate sensitivity, Equation (25) calculates the proportion of true positive in window objects. In other words, sensitivity determines what proportion of the actual window-objects got correctly detected by the model. The window-object detector has a sensitivity measure about 98.8%, whereas the SVM based fugitive classifier has a sensitivity of 89.9%.
- Specificity/True Negative Rate (TPR): The specificity of a window detection model is its ability to correctly determine the non-window objects. It is computed as the proportion of true negative in non-window objects by using Equation (26). Specificity deetrmines what proportion of the negative class (non-window objects) got correctly classified by the model. It could also be defined in terms of the false positive rate (FPR), which indicates what proportion of the negative class got incorrectly classified by the classifier. The specificity of the window-detector model was 99/7% and the SVM based fugitive classifier was 90.29%.
- Accuracy: The accuracy of a model (for example a window detector) is its ability to differentiate the window and non-window containing images or video frames correctly. To estimate the accuracy of a model, Equation (27) calculates the proportion of true positive and true negative in all evaluated cases. Hence, the accuracy measures of the window-object detector model was 99.3% and the SVM classifier was 93%.
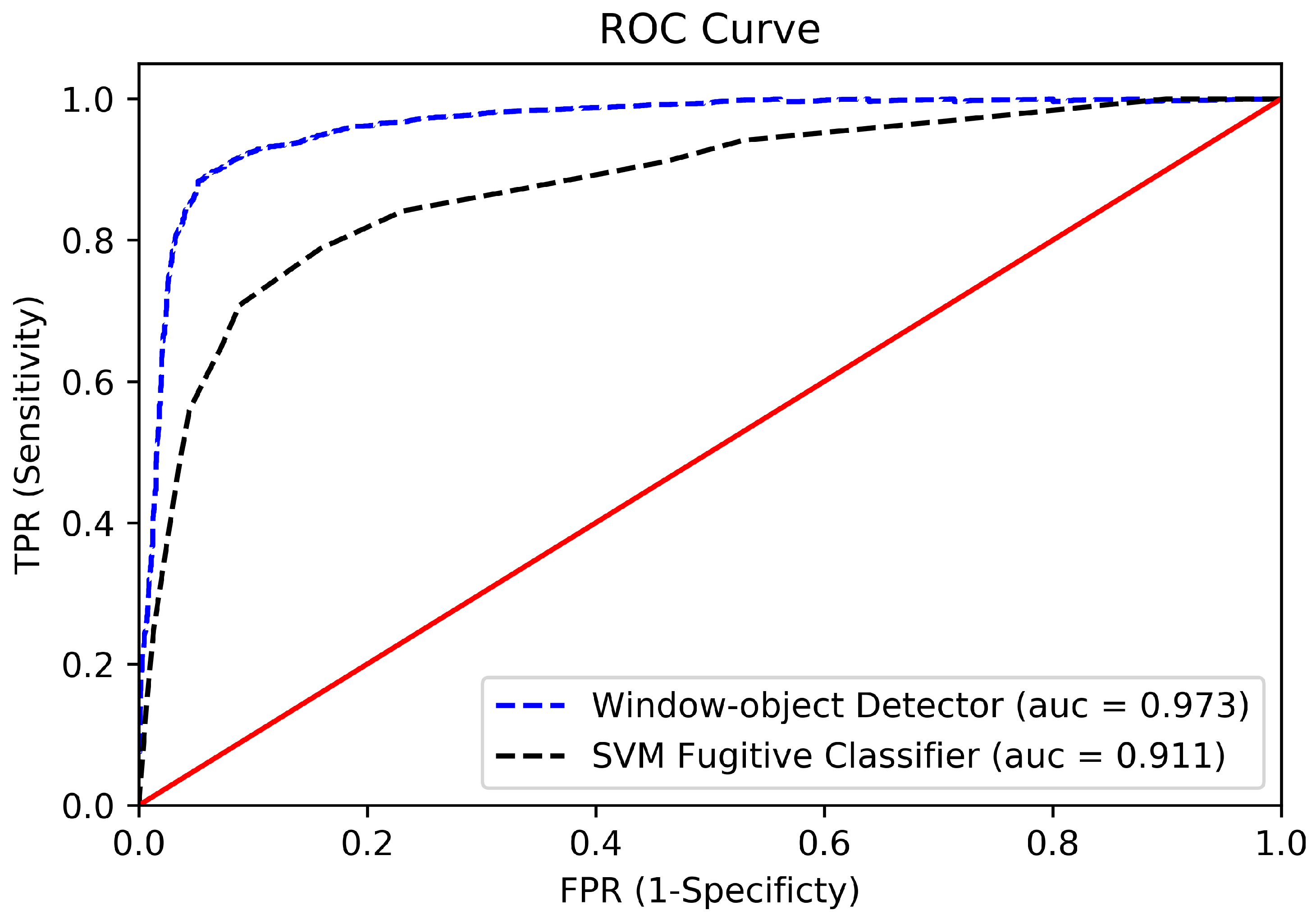
- Receiver Operating Characteristic (ROC) Curve: The ROC curve plots the TPR (sensitivity) against FPR (1-specificity) at various threshold values and essentially separates the ‘signal’ from the ‘noise’. The Area Under the Curve (AUC) is the measure of the ability of a detector to distinguish between classes and is used as a summary of the ROC curve. The higher the AUC, the better the performance of the model at distinguishing between the positive and negative classes.As portrayed in Figure 16, the window-object detector and the SVM classifier have higher areas under their respective curves that signify good performance at detecting windows and identifying fugitive faces, respectively.
8.5. Overall Performance of the PriSE Scheme
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ACLU | American Civil Liberties Union |
| AES | Advanced Data Encryption |
| AUC | Area Under Curve |
| CAN | Campus Area Network |
| CCTV | Closed Circuit Television |
| CPU | Central Processing Unit |
| DNN | Deep Neural Network |
| E2E | End-to-End |
| FPR | False Positive Rate |
| FPS | Frames Per Second |
| GIL | Global Interpreter Lock |
| GSM | Global System for Mobile Communications |
| HOG | Histogram Oriented Gradient |
| LFW | Labeled Faces in the Wild |
| ML | Machine Learning |
| MTCNN | Multi-Tasked cascaded Convolutional Neural Network |
| NIST | National Institute of Technology |
| NMS | Non-Maximum Suppression |
| NPCR | Number of Pixels Change Rate |
| NVR | Network Video Recorder |
| PSNR | Peak Signal to Noise Ratio |
| PriSE | Privacy-preserving Surveillance as an Edge service |
| PTZ | Pan-Tilt-Zoom camera |
| ReCAM | Reversible Chaotic Masking |
| ROC | Receiver Operating Characteristics |
| SBC | Single Board Computers |
| SMS | Short Message Service |
| SOC | Surveillance Operation Center |
| SVM | Support Vector Machine |
| TLS | Transport Layer Security |
| UACI | Unified Averaged Changing Intensity |
| WAN | Wide Area Network |
References
- Varghese, B.; Buyya, R. Next generation cloud computing: New trends and research directions. Future Gener. Comput. Syst. 2018, 79, 849–861. [Google Scholar] [CrossRef] [Green Version]
- Cavailaro, A. Privacy in video surveillance [in the spotlight]. IEEE Signal Process. Mag. 2007, 24, 166–168. [Google Scholar] [CrossRef]
- Xu, R.; Nikouei, S.Y.; Nagothu, D.; Fitwi, A.; Chen, Y. BlendSPS: A BLockchain-ENabled Decentralized Smart Public Safety System. Smart Cities 2020, 3, 928–951. [Google Scholar] [CrossRef]
- Clement, J. Global Digital Population as of July 2020. Available online: https://www.statista.com/statistics/617136/digital-population-worldwide/ (accessed on 24 August 2020).
- Fitwi, A.; Chen, Y.; Zhu, S. A Lightweight Blockchain-based Privacy Protection for Smart Surveillance at the Edge. In Proceedings of the 1st International Workshop on Lightweight Blockchain for Edge Intelligence and Security (LightChain, Colocated with IEEE BlockChain Conference), Atlanta, GA, USA, 14–17 July 2019. [Google Scholar]
- Kumar, V.; Svensson, J. Promoting Social Change and Democracy through Information Technology; IGI Global: Hershey, PA, USA, 2015. [Google Scholar]
- Streiffer, C.; Srivastava, A.; Orlikowski, V.; Velasco, Y.; Martin, V.; Raval, N.; Machanavajjhala, A.; Cox, L.P. ePrivateEye: To the edge and beyond! In Proceedings of the Second ACM/IEEE Symposium on Edge Computing, San Jose, CA, USA, 12–14 October 2017; p. 18. [Google Scholar]
- Yu, J.; Zhang, B.; Kuang, Z.; Lin, D.; Fan, J. iPrivacy: Image privacy protection by identifying sensitive objects via deep multi-task learning. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1005–1016. [Google Scholar] [CrossRef]
- Wang, J.; Amos, B.; Das, A.; Pillai, P.; Sadeh, N.; Satyanarayanan, M. Enabling Live Video Analytics with a Scalable and Privacy-Aware Framework. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 64. [Google Scholar] [CrossRef]
- Fitwi, A.; Chen, Y.; Zhu, S. PriSE: Slenderized Privacy-Preserving Surveillance as an Edge Service. In Proceedings of the 6th IEEE International Conference on Collaboration and Internet Computing (CIC 2020), Atlanta, GA, USA, 1–3 December 2020; pp. 1–10. [Google Scholar]
- Sun, Y.; Chen, S.; Zhu, S.; Chen, Y. iRyP: A purely edge-based visual privacy-respecting system for mobile cameras. In Proceedings of the 13th ACM Conference on Security and Privacy in Wireless and Mobile Networks, Linz, Austria, 8–10 July 2020; pp. 195–206. [Google Scholar]
- Du, L.; Yi, M.; Blasch, E.; Ling, H. GARP-face: Balancing privacy protection and utility preservation in face de-identification. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–8. [Google Scholar]
- Fitwi, A.; Chen, Y. Privacy-Preserving Selective Video Surveillance. In Proceedings of the 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; pp. 1–10. [Google Scholar]
- Yuan, M.; Nikouei, S.Y.; Fitwi, A.; Chen, Y.; Dong, Y. Minor Privacy Protection Through Real-time Video Processing at the Edge. arXiv 2020, arXiv:2005.01178. [Google Scholar]
- Altawy, R.; Youssef, A.M. Security, privacy, and safety aspects of civilian drones: A survey. ACM Trans. Cyber-Phys. Syst. 2017, 1, 7. [Google Scholar] [CrossRef]
- Cavoukian, A. Privacy and Drones: Unmanned Aerial Vehicles; Information and Privacy Commissioner of Ontario: Toronto, ON, Canada, 2012. [Google Scholar]
- Fitwi, A.; Chen, Y.; Zhou, N. An agent-administrator-based security mechanism for distributed sensors and drones for smart grid monitoring. In Proceedings of the Signal Processing, Sensor/Information Fusion, and Target Recognition XXVIII, International Society for Optics and Photonics, Baltimore, MD, USA, 15–17 April 2019; Volume 11018, p. 110180L. [Google Scholar]
- Vattapparamban, E.; Güvenç, İ.; Yurekli, A.İ.; Akkaya, K.; Uluağaç, S. Drones for smart cities: Issues in cybersecurity, privacy, and public safety. In Proceedings of the International Wireless Communications and Mobile Computing Conference (IWCMC), Paphos, Cyprus, 5–9 September 2016; pp. 216–221. [Google Scholar]
- Birnstill, P. Privacy-Respecting Smart Video Surveillance Based on Usage Control Enforcement; KIT Scientific Publishing: Amsterdam, The Netherlands, 2016; Volume 25. [Google Scholar]
- Myerson, J.M. Identifying enterprise network vulnerabilities. Int. J. Netw. Manag. 2002, 12, 135–144. [Google Scholar] [CrossRef]
- Senior, A.; Pankanti, S.; Hampapur, A.; Brown, L.; Tian, Y.L.; Ekin, A.; Connell, J.; Shu, C.F.; Lu, M. Enabling video privacy through computer vision. IEEE Secur. Priv. 2005, 3, 50–57. [Google Scholar] [CrossRef]
- Thornton, J.; Baran-Gale, J.; Butler, D.; Chan, M.; Zwahlen, H. Person attribute search for large-area video surveillance. In Proceedings of the IEEE International Conference on Technologies for Homeland Security (HST), Boston, MA, USA, 15–17 November 2011; pp. 55–61. [Google Scholar]
- Goldberg, C. Introduction to the World of Peeping Toms, Binoculars and Headset Included. New York Times, 6 August 1995; 35. [Google Scholar]
- Slobogin, C. Peeping Techno-Toms and the Fourth Amendment: Seeing Through Kyllo’s Rules Governing Technological Surveillance. Minn. L. Rev. 2001, 86, 1393. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Sharma, A.; Foroosh, H. Slim-CNN: A Light-Weight CNN for Face Attribute Prediction. arXiv 2019, arXiv:1907.02157. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Pang, Y.; Yuan, Y.; Li, X.; Pan, J. Efficient HOG human detection. Signal Process. 2011, 91, 773–781. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Jiang, B.; Ren, Q.; Dai, F.; Xiong, J.; Yang, J.; Gui, G. Multi-task Cascaded Convolutional Neural Networks for Real-Time Dynamic Face Recognition Method. In Proceedings of the International Conference in Communications, Signal Processing, and Systems, Dalian, China, 14–16 July 2018; pp. 59–66. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Al-Rubaie, M.; Chang, J.M. Privacy-Preserving Machine Learning: Threats and Solutions. IEEE Secur. Priv. 2019, 17, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Nikouei, S.Y.; Chen, Y.; Song, S.; Faughnan, T.R. Kerman: A hybrid lightweight tracking algorithm to enable smart surveillance as an edge service. In Proceedings of the 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; pp. 1–6. [Google Scholar]
- Fitwi, A.; Chen, Y.; Zhu, S. No peeking through my windows: Conserving privacy in personal drones. In Proceedings of the IEEE International Smart Cities Conference (ISC2), Casablanca, Morocco, 14–17 October 2019; pp. 199–204. [Google Scholar]
- Fitwi, A.H.; Nouh, S. Performance Analysis of Chaotic Encryption using a Shared Image as a Key. Zede J. 2011, 28, 17–29. [Google Scholar]
- Liu, L.; Miao, S. A new image encryption algorithm based on logistic chaotic map with varying parameter. SpringerPlus 2016, 5, 289. [Google Scholar] [CrossRef] [Green Version]
- Tang, Z.; Yang, Y.; Xu, S.; Yu, C.; Zhang, X. Image encryption with double spiral scans and chaotic maps. Secur. Commun. Netw. 2019, 2019, 8694678. [Google Scholar] [CrossRef] [Green Version]
- Pennebaker, W.B.; Mitchell, J.L. JPEG: Still Image Data Compression Standard; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Fitwi, A.; Yuan, M.; Nikouei, S.Y.; Chen, Y. Minor Privacy Protection by Real-time Children Identification and Face Scrambling at the Edge. EAI Endorsed Trans. Secur. Saf. Online First 2020. [Google Scholar] [CrossRef]
- Gleick, J. Chaos: Making a New Science; Open Road Media: Soho, NY, USA, 2011. [Google Scholar]
- Wu, R.; Liu, B.; Chen, Y.; Blasch, E.; Ling, H.; Chen, G. A container-based elastic cloud architecture for pseudo real-time exploitation of wide area motion imagery (wami) stream. J. Signal Process. Syst. 2017, 88, 219–231. [Google Scholar] [CrossRef]
- Wu, R.; Chen, Y.; Blasch, E.; Liu, B.; Chen, G.; Shen, D. A container-based elastic cloud architecture for real-time full-motion video (fmv) target tracking. In Proceedings of the IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 14–16 October 2014; pp. 1–8. [Google Scholar]
- Nikouei, S.Y.; Xu, R.; Nagothu, D.; Chen, Y.; Aved, A.; Blasch, E. Real-time index authentication for event-oriented surveillance video query using blockchain. In Proceedings of the IEEE International Smart Cities Conference (ISC2), Kansas City, MO, USA, 16–19 September 2018; pp. 1–8. [Google Scholar]
- Nikouei, S.Y.; Chen, Y.; Aved, A.; Blasch, E. I-ViSE: Interactive Video Surveillance as an Edge Service using Unsupervised Feature Queries. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Godbehere, A.B.; Matsukawa, A.; Goldberg, K. Visual tracking of human visitors under variable-lighting conditions for a responsive audio art installation. In Proceedings of the American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 4305–4312. [Google Scholar]
- Zivkovic, Z.; Van Der Heijden, F. Efficient adaptive density estimation per image pixel for the task of background subtraction. Pattern Recognit. Lett. 2006, 27, 773–780. [Google Scholar] [CrossRef]
- Durstenfeld, R. Algorithm 235: Random permutation. Commun. ACM 1964, 7, 420. [Google Scholar] [CrossRef]
- Fitwi, A. Windows Dataset. Available online: https://github.com/ahfitwi/win_wall_dataset (accessed on 4 January 2021).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Seeprettyface. 2018. Available online: http://www.seeprettyface.com/mydataset.html (accessed on 5 May 2020).
- Rukhin, A.; Soto, J.; Nechvatal, J.; Smid, M.; Barker, E. A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications; Technical Report; Booz-Allen and Hamilton Inc.: Mclean, VA, USA, 2001. [Google Scholar]
- Gallagher, A.; Chen, T. Understanding Images of Groups of People. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Intel. Intel® IoT Developer Kit. 2020. Available online: https://github.com/intel-iot-devkit/sample-videos (accessed on 10 December 2020).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Secure Domain |
|---|---|
| A | |
| C | |
| B | |
| D |
| Parameters | Specifications |
|---|---|
| CPU type/speed | Quad core Cortex-A72 (ARM v8) 64-bit SoC @ 1.5GHz |
| RAM size | 4GB LPDDR4-2400 SDRAM |
| Integrated Wi-Fi | 2.4GHz and 5GHz |
| Ethernet speed | 1Gbps |
| Camera port | 2-lane MIPI CSI |
| Bluetooth | 5.0 |
| Power Requirement | 3A, 5V |
| Operating System | Debian Linux 10 based |
| Tests | p-Value |
|---|---|
| The Frequency (Monobit) Test | 0.532 |
| Frequency Test within a Block | 0.172 |
| The Runs Test | 0.171 |
| Tests for the Longest-Run-of-Ones in a Block | 0.842 |
| The Binary Matrix Rank Test | 0.162 |
| The Discrete Fourier Transform (Spectral) Test | 0.243 |
| The Non-overlapping Template Matching Test | 0.052 |
| The Overlapping Template Matching Test | 0.241 |
| Maurer’s “Universal Statistical” Test | 0.999 |
| The Linear Complexity Test | 0.184 |
| The Serial Test | 0.502 |
| The Approximate Entropy Test | 0.602 |
| The Cumulative Sums (Cusums) Test | 0.598 |
| The Random Excursions Test | 0.667 |
| The Random Excursions Variant Test | 0.562 |
| Mean | STD | Min | 25% | 55% | 75% | Max |
|---|---|---|---|---|---|---|
| 127.5 | 73.901 | 0 | 63.75 | 127.5 | 191.25 | 255 |
| Statistics | ReCAM | Liu’s | Tang’s | AES |
|---|---|---|---|---|
| Count | 921,600 | 921,600 | 921,600 | 921,600 |
| Mean | ||||
| STD | 73.897 | 73.863 | 73.784 | 73.912 |
| Min | 0 | 0 | 0 | 0 |
| 25% | 63 | 64 | 63 | 63 |
| 50% | 127 | 128 | 127 | 127 |
| 75% | 191 | 191 | 192 | 191 |
| Max | 255 | 255 | 255 | 255 |
| Parameter | ReCAM | Liu’s | Tang’s | AES |
|---|---|---|---|---|
| Key Space r | ≈ | |||
| Key Sensitivity | ||||
| UACI | 33.456% | 33.381% | 33.379% | 33.478% |
| NPCR | 99.673% | 99.657% | 99.642% | 99.63% |
| PSNR | 9.43 dB | 11.231 dB | 10.73 dB | 9.102 dB |
| Entropy Analysis | 7.998 bits | 7.999 bits | 7.999 bits | 7.999 bits |
| Horizontal Correlation | 0.0006 | 0.0045 | −0.00485 | 0.021 |
| Vertical Correlation | 0.0009 | 0.0039 | 0.0643 | 0.0067 |
| Diagonal Correlation | 0.0003 | 0.0054 | 0.0035 | 0.0029 |
| Speed (FPS) | 5.61 | 1.215 | 0.346 | 0.722 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fitwi, A.; Chen, Y.; Zhu, S.; Blasch, E.; Chen, G. Privacy-Preserving Surveillance as an Edge Service Based on Lightweight Video Protection Schemes Using Face De-Identification and Window Masking. Electronics 2021, 10, 236. https://doi.org/10.3390/electronics10030236
Fitwi A, Chen Y, Zhu S, Blasch E, Chen G. Privacy-Preserving Surveillance as an Edge Service Based on Lightweight Video Protection Schemes Using Face De-Identification and Window Masking. Electronics. 2021; 10(3):236. https://doi.org/10.3390/electronics10030236
Chicago/Turabian StyleFitwi, Alem, Yu Chen, Sencun Zhu, Erik Blasch, and Genshe Chen. 2021. "Privacy-Preserving Surveillance as an Edge Service Based on Lightweight Video Protection Schemes Using Face De-Identification and Window Masking" Electronics 10, no. 3: 236. https://doi.org/10.3390/electronics10030236
APA StyleFitwi, A., Chen, Y., Zhu, S., Blasch, E., & Chen, G. (2021). Privacy-Preserving Surveillance as an Edge Service Based on Lightweight Video Protection Schemes Using Face De-Identification and Window Masking. Electronics, 10(3), 236. https://doi.org/10.3390/electronics10030236