
Optimising Hardware Accelerated Neural Networks with Quantisation and a Knowledge Distillation Evolutionary Algorithm

 ,
,
Abstract
:1. Introduction
- Speed up inference time: The size of neural network models are limited by memory capacity and bandwidth. Training and inference computations switch from compute-bound to memory-bound workloads as model sizes increase. This memory capacity bottleneck limits the practical use of very large models [9].
- Improve energy efficiency: It costs orders-of-magnitude more energy to access off-chip DDR memory compared to on-chip memory e.g., SRAM, BRAM and cache memory. Fitting weights into on-chip memories reduces frequency of energy inefficient off-chip memory accesses. Quantised fixed-point representations can significantly reduce energy costs [10], e.g., less than 5 Watts on FPGAs [11].
- Reduce verification costs: Recent SMT-based verification approaches aim to prove a neural network’s robustness against adversarial attacks e.g., [12,13]. SMT solvers generally do not support non-linear arithmetic so activation functions must be linearised. This approximates a model for the purpose verification, rendering verification results unreliable. Quantising activation functions can increase reliability of verifying neural networks robust [14], because it is the same model being verified and deployed. Moreover quantised models can be as robust against adversarial attack as their full precision version, possibly because quantisation acts as a filter of subtle adversarial noise [15].
Contributions
- A new framework called NEMOKD for hardware aware evolution of knowledge-distilled student models (Section 3).
- An evaluation of neural network quantisation by measuring inference accuracy, throughput, hardware requirements and training time, targeting programmable FPGA hardware (Section 4.2).
- An evaluation of NEMOKD showing its ability to minimise both latency and accuracy loss on Intel’s fixed Movidius Myriad X VPU architecture (Section 4.3).
- A comparison of NEMOKD and quantisation performance on these architectures (Section 4.4).
2. Quantisation Methodology
2.1. Quantisation for FPGAs
- Quantisation [22] shiftsvalues from 32 bit floating point continuous values to reduced bit discrete values. In a neural network, weights between neurons and activiation functions can be quantised.
- Binarisation [23] is a special case of quantisation that represents weights and/or activation function outputs with a single bit. These methods replace arithmetic operation with bit-wise operations, reducing the energy consumption and memory requirements.
2.2. FINN Framework
2.3. Weight Quantisation for Training
2.4. Activation Function Quantisation for Training
3. NEMOKD: Knowledge Distillation and Multi-Objective Optimisation of Neural Networks
3.1. Evolutionary Algorithms
3.2. Knowledge Distillation
- 1.
- Student loss: cross entropy of the student’s standard softmax output () with the ground truth vector.
- 2.
- Distillation loss: cross entropy of the teacher’s high temperature () output with the students high temperature output.
3.3. Multi-Objective Optimisation
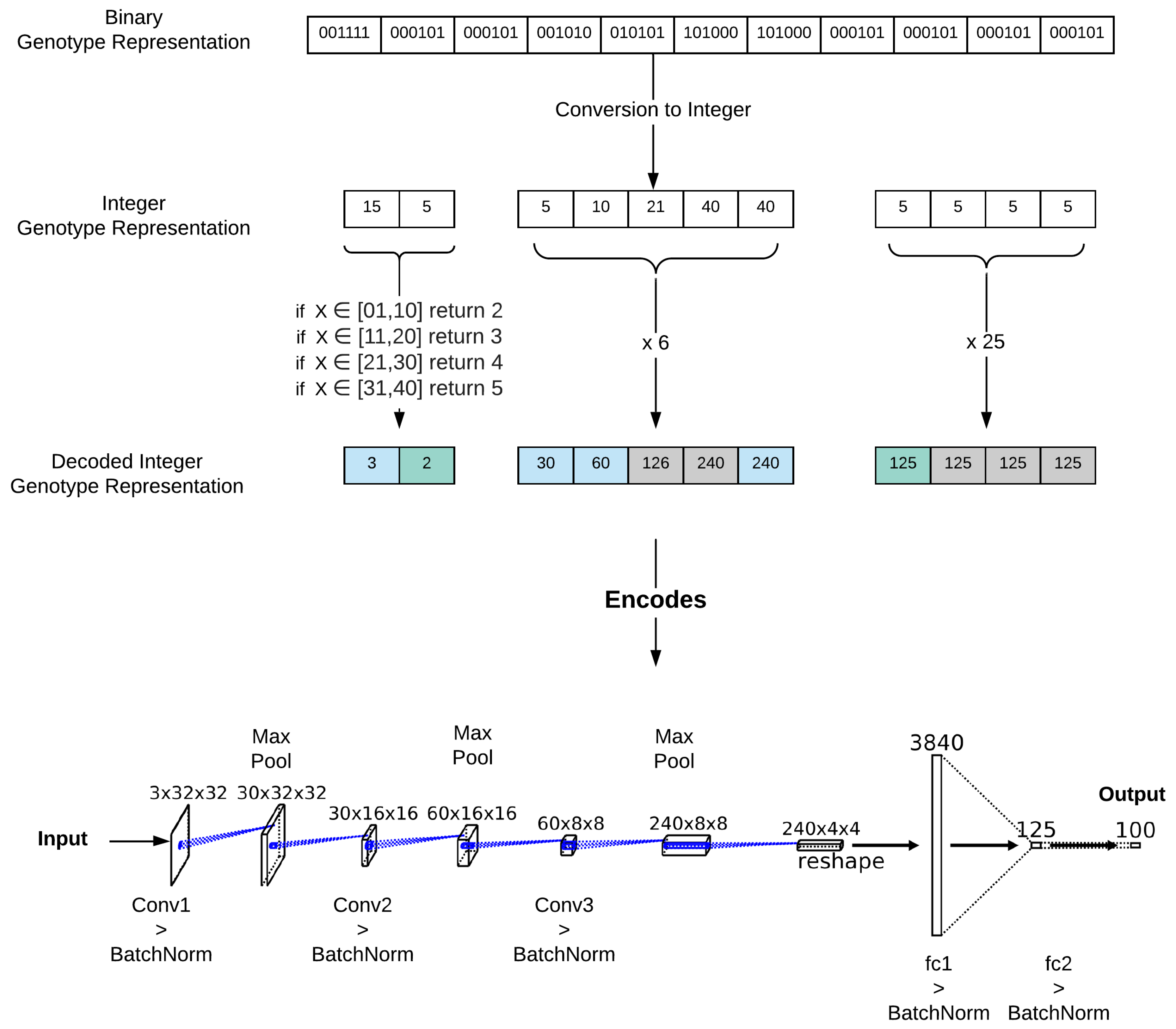
3.3.1. Encoding Student Models for Evolution
3.3.2. Multi-Objective Evolution
- 1.
- The number of convolutional layers.
- 2.
- The number of Fully Connect layers.
- 3.
- The number of output channels.
- 4.
- The number of Fully-Connected neurons.
3.4. NEMOKD Methodology
- Phase 1: Knowledge Distillation: A baseline model is trainedwith knowledge distillation to provide a comparison for NEMOKD performance. NEMOKD uses that baseline architecture as a starting point to generate variants using evolutionary multi-objective optimisation.
- Phase 2: Model Evolution: Each generation produces 10–20 variations of the baseline model, each then trained using knowledge distillation. The two objectives, minimising latency and minimising error, are measured for each model on the VPU device. The Pareto optimal models are retained to form part of the next generation. The other models are discarded. This process repeats for a specified number of generations. In our NEMOKD evaluation (Section 4.3), generations range from 14 to 27.
3.5. NEMOKD versus NEMO
- Knowledge distillation replaces standard training in the learning phase of the evaluation procedure.
- To conserve time and computational resources in the learning phase, partial training is provided with only 30 epochs (in phase 1) as opposed to fully training each member of initial population.
- Latency and accuracy is measured on the VPU device to asses the fitness of population members. This evaluation data is fed into the evolutionary NSGAII algorithm.
4. Evaluation
4.1. Hardware Platforms
4.2. Quantisation Results
- (1)
- Absolute accuracy and hardware resource costs of the 64quantised neural networks (Section 4.2.1).
- (2)
- Relative performance comparison of accuracy and hardware resource costs, compared with the other 63 quantised models (Section 4.2.2).
4.2.1. Absolute Performance
Absolute Accuracy Performance
Absolute Resource Utilisation Performance
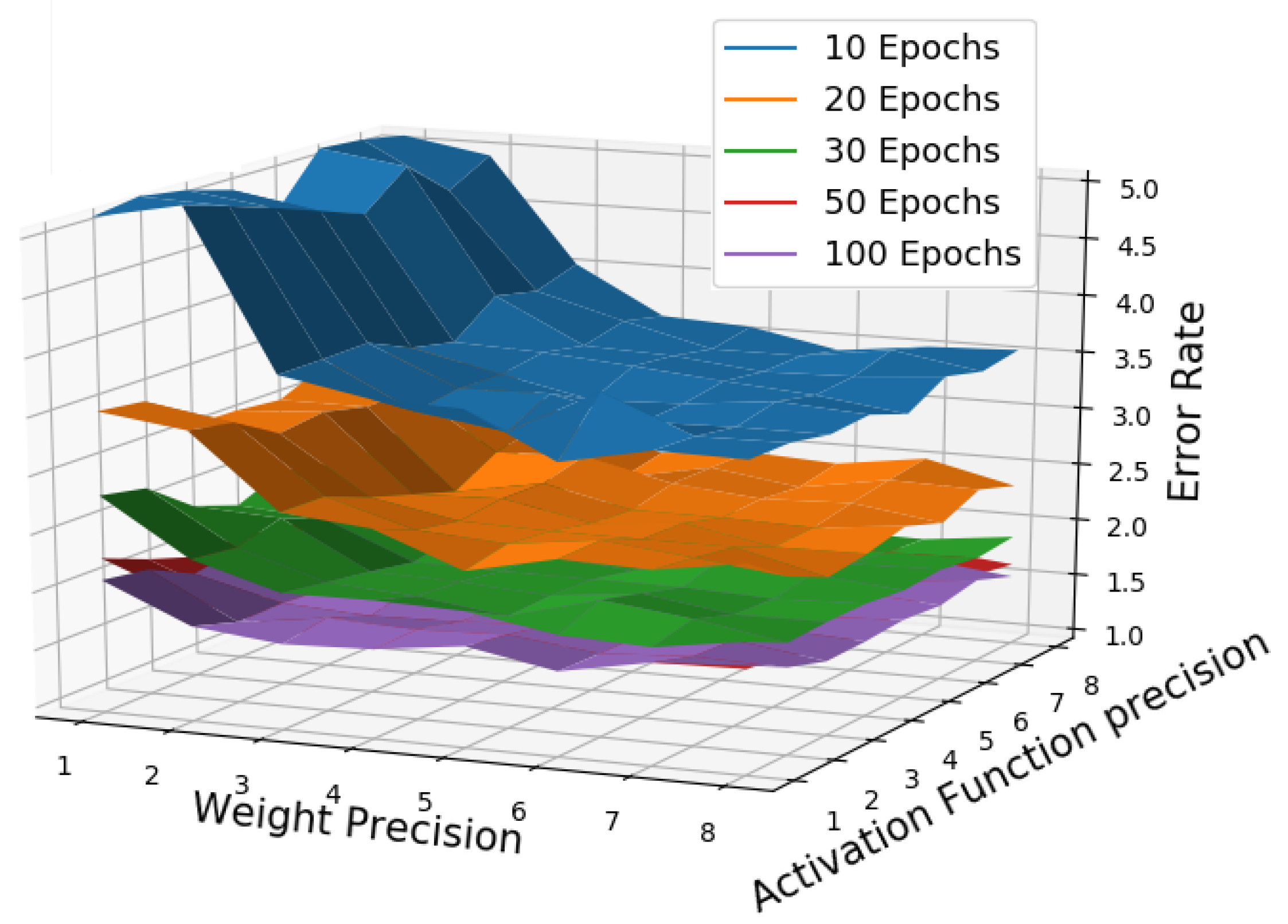
4.2.2. Relative Performance
- Weight oriented distribution (Figure 7a) increased the weight precision and kept the activation function constant at 4 bits, i.e., W1–A4, W3–A4, W6–A4 and W8–A4.
- Activation oriented distribution (Figure 7b) increased the activation function precision and kept the weight precision constant at 4 bits, i.e., W4–A1, W4–A3, W4–A6 and W4–A8.
4.2.3. Parallel Speedups
- Inference accuracy.
- Frames-Per-Second (FPS) image throughput.
- Quantisation configurations W2A2, W3A3 and W4A4.
- The parallelism degree for PE and SIMD for all layers, setting both at 2, 8 then 16.
4.2.4. Quantisation Results Discussion
- LUT and FF resources increase with increased activation function precision, because increasing arithmetic calculation complexity increases the number of required processing units.
- BRAM increases with increased weight precision, because weight parameters are stored in BRAM memories.
- Inference accuracy is highest with higher precision, i.e., least aggressive quantisation. The biggest improvement in accuracy with a 1 bit increment is switching from 1 to 2 bits weight precision.
- With enough training beyond 50 epochs, 2 bit precision achieves almost the same inference accuracy as 3–8 bit precision.
- Increasing the parallelisation of hardware neural network implementations significantly increases throughput performance from 6.1 k FPS to 373 k FPS, a 62 speedup.
- The trade-off between precision, throughput and accuracy is the W3A3 model with 16 for PE and SIMD, achieving 373 k FPS and 85.5% accuracy for the FASHION-MNIST dataset.
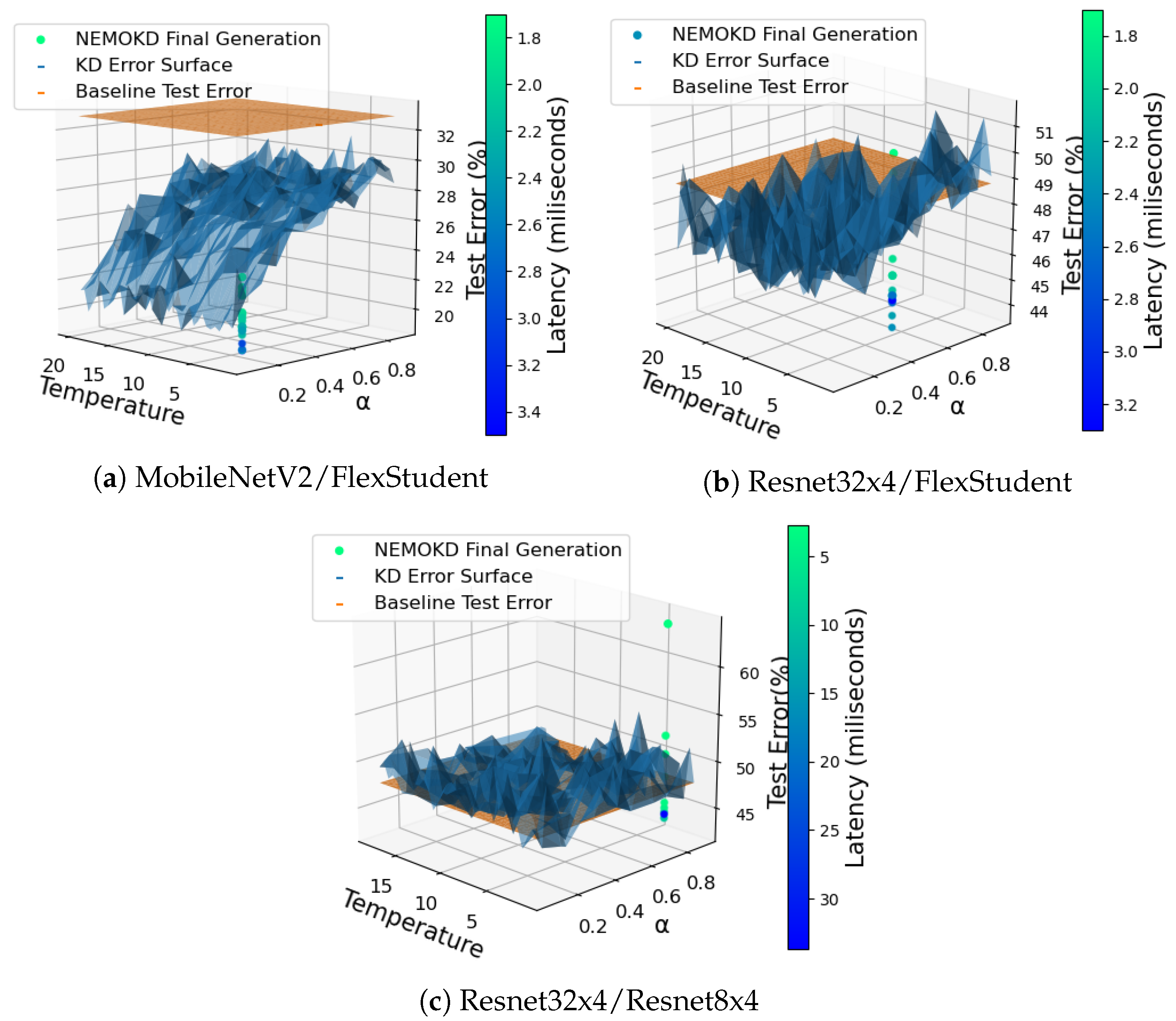
4.3. NEMOKD Results
- A version of the Resnet8x4 architecture, modified to enable the NEMOKD hyper-parameter evolutionary process.
- The MobileNetV2 model distilled into a FlexStudent student model with the CIFAR10 dataset.
- The Resnet32x4 model distilled into a FlexStudent student model with CIFAR100.
- The Resnet32x4 model distilled into a Resnet8x4 student model with CIFAR100. For this experiment, the number of layers remained fixed.
4.3.1. Knowledge Distillation Parameter Search
4.3.2. Efficacy of NEMOKD Evolution
4.4. Discussion
4.4.1. Quantisation for FPGAs
Device Specific Quantisation
Domain Specific Quantisation
4.4.2. NEMO with Knowledge Distillation for the VPU
4.4.3. Comparing Quantisation and NEMOKD
5. Conclusions and Future Work
5.1. Conclusions
5.2. Future Work
5.2.1. Larger Datasets and Models
5.2.2. Profile Guided Automating Compression
5.2.3. Performance Portability of Compressed Models
5.2.4. Combining Knowledge Distillation with Quantisation
Author Contributions
Funding
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Lu, D. Creating an AI Can Be Five Times Worse for the Planet Than a Car. New Scientist. 2019. Available online: https://www.newscientist.com/article/2205779-creating-an-ai-can-be-five-times-worse-for-the-planet-than-a-car (accessed on 28 December 2020).
- Intel. Intel® Movidius™ Vision Processing Units (VPUs). Available online: https://www.intel.com/content/www/us/en/products/processors/movidius-vpu.html (accessed on 28 December 2020).
- Edge TPU: Google’s Purpose-Built ASIC Designed to Run Inference at the Edge. Available online: https://cloud.google.com/edge-tpu (accessed on 28 December 2020).
- Véstias, M.P.; Neto, H.C. Trends of CPU, GPU and FPGA for high-performance computing. In Proceedings of the 2014 24th International Conference on Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014; pp. 1–6. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both Weights and Connections for Efficient Neural Network. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.H.W.; Jahre, M.; Vissers, K.A. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate, Monterey, CA, USA, 22–24 February 2017; pp. 65–74. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Diamos, G.; Sengupta, S.; Catanzaro, B.; Chrzanowski, M.; Coates, A.; Elsen, E.; Engel, J.H.; Hannun, A.Y.; Satheesh, S. Persistent RNNs: Stashing Recurrent Weights On-Chip. In Proceedings of the 33nd International Conference on Machine Learning (ICML 2016), New York, NY, USA, 19–24 June 2016; Volume 48, pp. 2024–2033. [Google Scholar]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. DianNao: A small-footprint high-throughput accelerator for ubiquitous machine-learning. In Proceedings of the ASPLOS 2014, Salt Lake City, UT, USA, 1–5 March 2014; pp. 269–284. [Google Scholar]
- Park, J.; Sung, W. FPGA based implementation of deep neural networks using on-chip memory only. In Proceedings of the ICASSP 2016, Shanghai, China, 20–25 March 2016; pp. 1011–1015. [Google Scholar]
- Katz, G.; Barrett, C.W.; Dill, D.L.; Julian, K.; Kochenderfer, M.J. Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks. In Proceedings of the Computer Aided Verification-29th International Conference (CAV 2017), Heidelberg, Germany, 24–28 July 2017; pp. 97–117. [Google Scholar]
- Liu, C.; Arnon, T.; Lazarus, C.; Barrett, C.W.; Kochenderfer, M.J. Algorithms for Verifying Deep Neural Networks. arXiv 2019, arXiv:1903.06758. [Google Scholar]
- Kokke, W.; Komendantskaya, E.; Kienitz, D.; Atkey, R.; Aspinall, D. Neural Networks, Secure by Construction: An Exploration of Refinement Types. In Asian Symposium on Programming Languages and Systems (APLAS), Fukuoka, Japan; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Duncan, K.; Komendantskaya, E.; Stewart, R.; Lones, M.A. Relative Robustness of Quantized Neural Networks against Adversarial Attacks. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN 2020), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Zhang, X.; Li, Z.; Loy, C.C.; Lin, D. PolyNet: A Pursuit of Structural Diversity in Very Deep Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 3900–3908. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Mahajan, D.; Girshick, R.B.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; van der Maaten, L. Exploring the Limits of Weakly Supervised Pretraining. arXiv 2018, arXiv:1805.00932. [Google Scholar]
- Wang, E.; Davis, J.J.; Zhao, R.; Ng, H.; Niu, X.; Luk, W.; Cheung, P.Y.K.; Constantinides, G.A. Deep Neural Network Approximation for Custom Hardware: Where We’ve Been, Where We’re Going. ACM Comput. Surv. 2019, 52, 40:1–40:39. [Google Scholar] [CrossRef] [Green Version]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations. J. Mach. Learn. Res. 2017, 18, 187:1–187:30. [Google Scholar]
- Courbariaux, M.; Bengio, Y. BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Blott, M.; Preußer, T.B.; Fraser, N.J.; Gambardella, G.; O’Brien, K.; Umuroglu, Y.; Leeser, M.; Vissers, K.A. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks. TRETS 2018, 11, 16:1–16:23. [Google Scholar] [CrossRef]
- Rybalkin, V.; Pappalardo, A.; Ghaffar, M.M.; Gambardella, G.; Wehn, N.; Blott, M. FINN-L: Library Extensions and Design Trade-Off Analysis for Variable Precision LSTM Networks on FPGAs. In Proceedings of the FPL 2018, Dublin, Ireland, 27–31 August 2018; pp. 89–96. [Google Scholar]
- Stanley, K.O.; Miikkulainen, R. Evolving Neural Networks through Augmenting Topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Cheng, A.; Juan, D.; Wei, W.; Sun, M. DPP-Net: Device-Aware Progressive Search for Pareto-Optimal Neural Architectures. In Proceedings of the Computer Vision-ECCV 2018-15th European Conference, Munich, Germany, 8–14 September 2018; pp. 540–555. [Google Scholar]
- Huang, G.; Liu, S.; van der Maaten, L.; Weinberger, K.Q. CondenseNet: An Efficient DenseNet Using Learned Group Convolutions. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2752–2761. [Google Scholar]
- Kim, Y.H.; Reddy, B.; Yun, S.; Seo, C. NEMO: Neuro-Evolution with Multiobjective Optimization of Deep Neural Network for Speed and Accuracy. In Proceedings of the AutoML 2017: Automatic Machine Learning Workshop (ICML 2017), Sydney, Australia, 10 August 2017. [Google Scholar]
- Zmora, N.; Jacob, G.; Zlotnik, L.; Elharar, B.; Novik, G. Neural Network Distiller: A Python Package For DNN Compression Research. arXiv 2019, arXiv:1910.12232. [Google Scholar]
- Deb, K.; Agrawal, S.; Pratap, A.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Su, J.; Fraser, N.J.; Gambardella, G.; Blott, M.; Durelli, G.; Thomas, D.B.; Leong, P.H.W.; Cheung, P.Y.K. Accuracy to Throughput Trade-Offs for Reduced Precision Neural Networks on Reconfigurable Logic. In Proceedings of the ARC 2018, Santorini, Greece, 2–4 May 2018; pp. 29–42. [Google Scholar]
- Exploring Knowledge Distillation of Deep Neural Nets for Efficient Hardware Solutions. CS230 Report. Available online: http://cs230.stanford.edu/files_winter_2018/projects/6940224.pdf (accessed on 28 December 2020).
- Hadka, D. Platypus: Multiobjective Optimization in Python. Available online: https://platypus.readthedocs.io (accessed on 28 December 2020).
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Representation Distillation. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar]
- Radu, V.; Kaszyk, K.; Wen, Y.; Turner, J.; Cano, J.; Crowley, E.J.; Franke, B.; Storkey, A.; O’Boyle, M. Performance Aware Convolutional Neural Network Channel Pruning for Embedded GPUs. In Proceedings of the 2019 IEEE International Symposium on Workload Characterization (IISWC), Orlando, FL, USA, 3–5 November 2019. [Google Scholar]
- Zhao, Y.; Gao, X.; Guo, X.; Liu, J.; Wang, E.; Mullins, R.; Cheung, P.Y.K.; Constantinides, G.A.; Xu, C. Automatic Generation of Multi-Precision Multi-Arithmetic CNN Accelerators for FPGAs. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019; pp. 45–53. [Google Scholar]
- Wang, J.; Lou, Q.; Zhang, X.; Zhu, C.; Lin, Y.; Chen, D. Design Flow of Accelerating Hybrid Extremely Low Bit-Width Neural Network in Embedded FPGA. In Proceedings of the FPL 2018, Dublin, Ireland, 27–31 August 2018; pp. 163–169. [Google Scholar]
- Liang, S.; Yin, S.; Liu, L.; Luk, W.; Wei, S. FP-BNN: Binarized neural network on FPGA. Neurocomputing 2018, 275, 1072–1086. [Google Scholar] [CrossRef]
- Ding, C.; Wang, S.; Liu, N.; Xu, K.; Wang, Y.; Liang, Y. REQ-YOLO: A Resource-Aware, Efficient Quantization Framework for Object Detection on FPGAs. In Proceedings of the FPGA 2019, Seaside, CA, USA, 24–26 February 2019; pp. 33–42. [Google Scholar]
- Gu, Q.; Ishii, I. Review of some advances and applications in real-time high-speed vision: Our views and experiences. Int. J. Autom. Comput. 2016, 13, 305–318. [Google Scholar] [CrossRef]
- Cheng, C.H. Towards Robust Direct Perception Networks for Automated Driving. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020. [Google Scholar]
- Nguyen, D.T.; Kim, H.; Lee, H. Layer-specific Optimization for Mixed Data Flow with Mixed Precision in FPGA Design for CNN-based Object Detectors. IEEE Trans. Circuits Syst. Video Technol. 2020. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Y.; Ni, B.; Zhuang, L.; Xu, H. Flexible Network Binarization with Layer-Wise Priority. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2346–2350. [Google Scholar]
- Turner, J.; Crowley, E.J.; Radu, V.; Cano, J.; Storkey, A.; O’Boyle, M. Distilling with Performance Enhanced Students. arXiv 2018, arXiv:1810.10460. [Google Scholar]
- Polino, A.; Pascanu, R.; Alistarh, D. Model compression via distillation and quantization. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Cheng, Y.; Yu, F.X.; Feris, R.S.; Kumar, S.; Choudhary, A.N.; Chang, S. Fast Neural Networks with Circulant Projections. arXiv 2015, arXiv:1502.03436. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Value | Precision (bits) | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 0.136 | 1 | 0 | 0 | 0.25 | 0.125 | 0.125 | 0.125 | 0.140625 |
| 0.357 | 1 | 0 | 0.5 | 0.25 | 0.375 | 0.375 | 0.34375 | 0.359375 |
| 0.639 | 1 | 1 | 0.5 | 0.75 | 0.625 | 0.625 | 0.625 | 0.640625 |
| 1.135 | 1 | 1 | 1 | 1.25 | 1.125 | 1.125 | 1.125 | 1.140625 |
| 2 | 1 | 1 | 1.5 | 1.75 | 1.875 | 1.9375 | 1.96875 | 1.984375 |
| Device | Model | Dataset | Section | |
|---|---|---|---|---|
| Xilinx Z7020 FPGA | 3 layer fully connected MLP | MNIST | Section 4.2.1 and Section 4.2.2 | |
| (quantisation) | 3 layer fully connected MLP | FASHION-MNIST | Section 4.2.3 | |
| Intel Movidius Myriad X VPU | Teacher | Student | ||
| MobileNetV2 | FlexStudent | CIFAR10 | Section 4.3 | |
| (model evolution) | Resnet32x4 | FlexStudent | CIFAR100 | Section 4.3 |
| Resnet32x4 | Resnet8x4 | CIFAR100 | Section 4.3 | |
| Metric | Relative Performance | |
|---|---|---|
| Worst | Best | |
| Accuracy loss | 2.07% | 1.52% |
| BRAM | 1643 | 224 |
| Flip Flops | 226,282 | 31,954 |
| Look Up Tables | 223,910 | 53,336 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stewart, R.; Nowlan, A.; Bacchus, P.; Ducasse, Q.; Komendantskaya, E. Optimising Hardware Accelerated Neural Networks with Quantisation and a Knowledge Distillation Evolutionary Algorithm. Electronics 2021, 10, 396. https://doi.org/10.3390/electronics10040396
Stewart R, Nowlan A, Bacchus P, Ducasse Q, Komendantskaya E. Optimising Hardware Accelerated Neural Networks with Quantisation and a Knowledge Distillation Evolutionary Algorithm. Electronics. 2021; 10(4):396. https://doi.org/10.3390/electronics10040396
Chicago/Turabian StyleStewart, Robert, Andrew Nowlan, Pascal Bacchus, Quentin Ducasse, and Ekaterina Komendantskaya. 2021. "Optimising Hardware Accelerated Neural Networks with Quantisation and a Knowledge Distillation Evolutionary Algorithm" Electronics 10, no. 4: 396. https://doi.org/10.3390/electronics10040396
APA StyleStewart, R., Nowlan, A., Bacchus, P., Ducasse, Q., & Komendantskaya, E. (2021). Optimising Hardware Accelerated Neural Networks with Quantisation and a Knowledge Distillation Evolutionary Algorithm. Electronics, 10(4), 396. https://doi.org/10.3390/electronics10040396