
A Survey on Applications of Reinforcement Learning in Flying Ad-Hoc Networks



Abstract
:1. Introduction
- Communication: UAVs can move at high speed, which poses difficulties in maintaining communication with other UAVs. In addition, the distance among the nodes is higher than that other ad-hoc networks [10].
- Power constraint: Generally, UAVs carry batteries as a power supply, which is limited to support their operations and flying time. Increasing the capacity of the battery may degrade the performance of the UAVs after a certain point owing to the energy and weight ratio. Therefore, effective battery and charging management is one of the major challenges of FANETs [11].
- Routing protocol: Routing in FANETs is also a challenge owing to the high mobility and power constraints of the UAVs. Many routing protocols have been designed for ad-hoc networks but FANET requires a highly dynamic routing protocol to cope with the dynamic changes in the FANET topology [12].
- Ensuring QoS: There are also some quality of service (QoS) related challenges that should be addressed such as ensuring low latency, determining the trajectory path to provide service, synchronization among UAVs, and protection against jamming attacks.
2. Fundamentals of Deep Reinforcement Learning
2.1. Reinforcement Learning
| Algorithm 1. The Q-learning Algorithm. |
 |
2.2. Deep Reinforcement Learning
| Algorithm 2. The Deep Q-learning Algorithm |
 |
3. Fundamentals of FANET
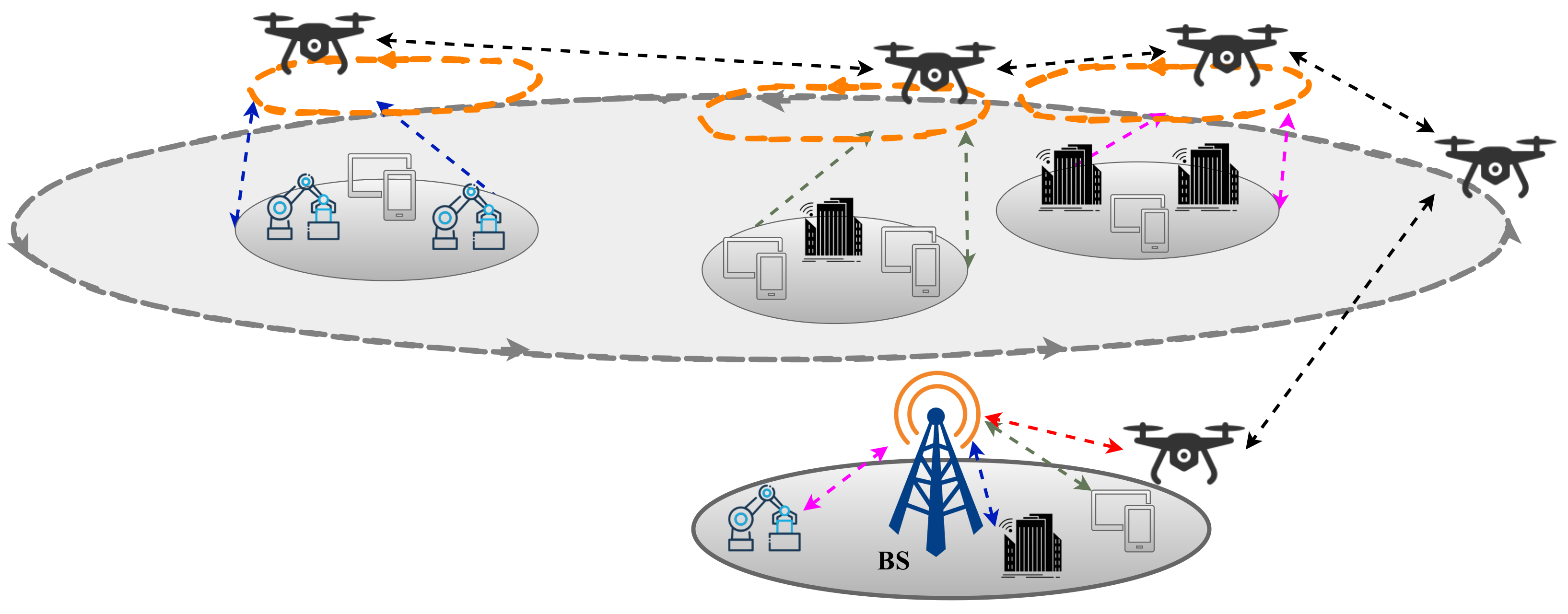
3.1. FANET Architecture
- Centralized topology: An example of centralized topology is shown in Figure 6, where all UAVs are communicating with a GGU directly to transmit data to the control center. In this topology, UAVs also communicate with each other via the GGU [28]. This topology is more fault-tolerant but requires higher bandwidth, causes high latency, and constrains high-speed UAV mobility. Furthermore, putting up GGUs for multiple UAV groups is not economically feasible.
- Multigroup topology: In this topology, UAVs are divided into multiple clusters, and each group contains a cluster head (CH), which is responsible for communicating with the GGU and other groups of UAVs as shown in Figure 8 [29]. With this topology, a large number of UAVs can be covered. However, it increases the probability of a single-point failure problem.
3.2. Characteristics of FANET
- Node mobility and model: There are different types of aerial vehicles which can move at an average speed of 6–500 km/h [9]. Thus, node mobility is the most important distinguishable factor which makes the FANET different from other ad-hoc networks. Furthermore, node mobility results in several challenges in communication designing. In FANET, UAVs can move freely at any direction and speed, depending on the task on its own. By contrast, other ad-hoc networks have regular, low, predefined, and controlled mobility [27]. Moreover, high mobility in FANET results in frequent changes in network topology compared to other ad-hoc networks.
- Node density: In wireless ad-hoc networks, node density is a crucial parameter for selecting data routing path. In FANET, node density mostly depends on the type of UAV, objective, UAV speed, and communication range. As UAVs can be speedy and have a long communication range, the number of UAV per unit area can decrease [30]. In other ad-hoc networks, such as VANETs, SANETs, WSNs, and SPANs, the node density is high compared to FANET [31].
- Localization: In ad-hoc network, global positing system (GPS) is widely used to locate the nodes. However, owing to the high speed mobility, FANETs use low latency GPS system to locate the UAVs such as network-based positioning [32], height-based positioning [33], differential GPS (DGPS) [34], and assisted GPS (AGPS) [35]. Moreover, localization is a major factor in flight trajectory and routing path selection.
- Radio propagation: When it comes to radio propagation model, FANETs have a great advantage of line-of-sight (LoS) over other ad-hoc networks. In FANET, UAVs can have a clear LoS among them due to their free mobility in the air. By contrast, in other ad-hoc networks, there is little or no LoS between the source and the destination owing to the geographical structure of the terrain.
- Energy Constraint: Energy limitation is one of the major design issues in ad-hoc networks. In FANET, it depends on the size of the UAV. Most of the large UAVs are not power-sensitive, whereas energy limitation is a concern for mini-UAVs [9]. In other ad-hoc networks, it varies from type to type as shown in Table 1.
3.3. Optimal FANET Design
4. Applications of RL in FANET
4.1. Routing Protocol
- Proactive routing: Like wired network routing, all nodes in an ad-hoc network maintain a route table consisting of routes to other nodes. Whenever a node transmits data, a route table is used to determine the route to the destination. The route table continues to be updated to maintain the change in topology. This type of routing protocol is unsuitable for FANETs owing to the frequent high-speed mobility of the nodes [43].
- Reactive routing: Whenever a node initiates communication, this type of routing protocol starts discovering routes to the destination. Predefined routing tables were not maintained in this protocol. These types of routing protocols are known as on-demand routing protocols. The main drawbacks of this protocol in terms of FANETs are poor stability, high delay, high energy consumption, and low security [44].
- Hybrid routing: This is a combination of and a trade-off between proactive and reactive routing protocols. In this protocol, nodes maintain a route table consisting of routers to their neighbors and start route discovery whenever the nodes try to communicate the nodes beyond their neighbors. [45].
4.1.1. QMR
4.1.2. RLSRP with PPMAC
4.1.3. Multiobjective Routing Protocol
4.2. Flight Trajectory Selection
4.2.1. Q-SQUARE
4.2.2. Decentralized Trajectory Design
4.2.3. Joint Trajectory Design and Power Control
4.2.4. Multi-UAV Deployment and Movement Design
4.2.5. Trajectory Optimization for UBS
4.3. Other Scenarios
5. Open Research Issues
- Energy constraint: UAVs carry batteries as the main power source to support all the functionalities, such as flying, communication, and computation. However, the capacity of the batteries is insufficient for long-term deployment. Many researchers used solar energy for on-board energy harvesting and used RL to optimize the energy consumption. Unfortunately, these solutions are not sufficient for long flights. This opens a key research issue, where UAVs can harvest power wireless from nearby roadside units or base stations or power beacons for communicational and computational functionalities utilizing RL. Another way to solve the energy issue is that UAV has to exploit DRL to visit charging stations while other UAVs fill up the void.
- 3D deployment and movement: Many studies have been carried out regarding deployment and movement. However, most of the researchers have made some significant assumptions, such as constraining UAV and user mobility [59] or reducing action-state space [56], in multi-UAV scenario. Consequently, 3D deployment and movement design considering all the constraints is still an open research issue of FANET. Furthermore, it is also important for cooperative communication of other networks, where UAVs act as relays.
- Routing issue: A few works have been done on routing protocols utilizing RL for FANET. Routing protocol is crucial for FANETs due to their high node mobility, low node density, and 3D node movement. There are still scopes of improvements, such as handling no neighbor problem, multiflow transmission, directional antenna problem, and scalability issues, utilizing RL. Moreover, the scope of extending the routing protocols of VANETs and MANETs for FANET using RL is still an open research issue.
- Interference management: Recently, UAVs are using WiFi for communicating with each other. However, interference can occur when working areas of two different FANETs with different targets overlap. Furthermore, UBSs can interfere with each others’ UAV to ground communication owing to their high moving speed. These scenarios are still open challenges, where RL can be utilized.
- Fault handling: Fault occurrence is widespread in any network. Fault handling is crucial in FANET to avoid interruption. However, there are no existing RL-based solutions that can handle any fault, such as UAV hardware problems, equipped component problems, and communication failure due to any software issues. Thus, fault handling using RL needs to be deeply explored.
- Security issue: Many RL-based strategies were developed in the past to prevent jamming and cyber attacks for MANET and VANET [66]. However, there are few RL-based solutions available for FANET security. If even all the aforementioned issues were solved, communication in FANET can still be interrupted due to a security breach. Consequently, RL-based security solutions require an in-depth investigation.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, J.; Jiang, C.; Han, Z.; Ren, Y.; Maunder, R.G.; Hanzo, L. Taking Drones to the Next Level: Cooperative Distributed Unmanned-Aerial-Vehicular Networks for Small and Mini Drones. IEEE Veh. Technol. Mag. 2017, 12, 73–82. [Google Scholar] [CrossRef] [Green Version]
- Batista da Silva, L.C.; Bernardo, R.M.; de Oliveira, H.A.; Rosa, P.F.F. Multi-UAV agent-based coordination for persistent surveillance with dynamic priorities. In Proceedings of the 2017 International Conference on Military Technologies (ICMT), Brno, Czech Republic, 31 May–2 June 2017; pp. 765–771. [Google Scholar] [CrossRef]
- Alshbatat, A.I.; Dong, L. Cross layer design for mobile Ad-Hoc Unmanned Aerial Vehicle communication networks. In Proceedings of the 2010 International Conference on Networking, Sensing and Control (ICNSC), Chicago, IL, USA, 10–12 April 2010; pp. 331–336. [Google Scholar] [CrossRef] [Green Version]
- Semsch, E.; Jakob, M.; Pavlicek, D.; Pechoucek, M. Autonomous UAV Surveillance in Complex Urban Environments. In Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Milan, Italy, 15–19 September 2009; Volume 2, pp. 82–85. [Google Scholar] [CrossRef]
- Maza, I.; Caballero, F.; Capitan, J.; Martinez-de Dios, J.R.; Ollero, A. Experimental Results in Multi-UAV Coordination for Disaster Management and Civil Security Applications. J. Intell. Robot. Syst. 2011, 61, 563–585. [Google Scholar] [CrossRef]
- De Freitas, E.P.; Heimfarth, T.; Netto, I.F.; Lino, C.E.; Pereira, C.E.; Ferreira, A.M.; Wagner, F.R.; Larsson, T. UAV relay network to support WSN connectivity. In Proceedings of the International Congress on Ultra Modern Telecommunications and Control Systems, Moscow, Russia, 18–20 October 2010; pp. 309–314. [Google Scholar] [CrossRef]
- Xiang, H.; Tian, L. Development of a low-cost agricultural remote sensing system based on an autonomous unmanned aerial vehicle (UAV). Biosyst. Eng. 2011, 108, 174–190. [Google Scholar] [CrossRef]
- Barrado, C.; Messeguer, R.; Lopez, J.; Pastor, E.; Santamaria, E.; Royo, P. Wildfire monitoring using a mixed air-ground mobile network. IEEE Pervasive Comput. 2010, 9, 24–32. [Google Scholar] [CrossRef]
- Bekmezci, I.; Sahingoz, O.; Temel, Ş. Flying ad-hoc networks (FANETs): A survey. Ad Hoc Netw. 2013, 11, 1254–1270. [Google Scholar] [CrossRef]
- Mukherjee, A.; Keshary, V.; Pandya, K.; Dey, N.; Satapathy, S. Flying Ad-hoc Networks: A Comprehensive Survey. Inf. Decis. Sci. 2018, 701, 569–580. [Google Scholar]
- Shin, M.; Kim, J.; Levorato, M. Auction-Based Charging Scheduling With Deep Learning Framework for Multi-Drone Networks. IEEE Trans. Veh. Technol. 2019, 68, 4235–4248. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Wang, Q.; He, C.; Jaffres-Runser, K.; Xu, Y.; Li, Z.; Xu, Y.J. QMR: Q-learning based Multi-objective optimization Routing protocol for Flying Ad Hoc Networks. Comput. Commun. 2019, 150. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef] [Green Version]
- Bithas, P.S.; Michailidis, E.T.; Nomikos, N.; Vouyioukas, D.; Kanatas, A.G. A Survey on Machine-Learning Techniques for UAV-Based Communications. Sensors 2019, 19, 5170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiong, Z.; Zhang, Y.; Niyato, D.; Deng, R.; Wang, P.; Wang, L. Deep Reinforcement Learning for Mobile 5G and Beyond: Fundamentals, Applications, and Challenges. IEEE Veh. Technol. Mag. 2019, 14, 44–52. [Google Scholar] [CrossRef]
- Forster, A. Machine Learning Techniques Applied to Wireless Ad-Hoc Networks: Guide and Survey. In Proceedings of the 2007 3rd International Conference on Intelligent Sensors, Sensor Networks and Information, Melbourne, Australia, 3–6 December 2007; pp. 365–370. [Google Scholar] [CrossRef]
- Qian, Y.; Wu, J.; Wang, R.; Zhu, F.; Zhang, W. Survey on Reinforcement Learning Applications in Communication Networks. J. Commun. Inf. Netw. 2019, 4, 30–39. [Google Scholar] [CrossRef]
- Ponsen, M.; Taylor, M.E.; Tuyls, K. Abstraction and Generalization in Reinforcement Learning: A Summary and Framework. In Adaptive and Learning Agents; Taylor, M.E., Tuyls, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–32. [Google Scholar]
- Tuyls, K.; Nowe, A. Evolutionary game theory and multi-agent reinforcement learning. Knowl. Eng. Rev. 2005, 20, 63–90. [Google Scholar] [CrossRef]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An Introduction to Deep Reinforcement Learning. arXiv 2018, arXiv:1811.12560. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Bau, D.; Zhu, J.Y.; Strobelt, H.; Lapedriza, A.; Zhou, B.; Torralba, A. Understanding the role of individual units in a deep neural network. Proc. Natl. Acad. Sci. USA 2020, 117, 30071–30078. [Google Scholar] [CrossRef]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2018, arXiv:1701.07274. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. arXiv 2016, arXiv:1602.01783. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Lillicrap, T.; Hunt, J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Oubbati, O.S.; Atiquzzaman, M.; Lorenz, P.; Tareque, M.H.; Hossain, M.S. Routing in Flying Ad Hoc Networks: Survey, Constraints, and Future Challenge Perspectives. IEEE Access 2019, 7, 81057–81105. [Google Scholar] [CrossRef]
- Bacco, M.; Cassarà, P.; Colucci, M.; Gotta, A.; Marchese, M.; Patrone, F. A Survey on Network Architectures and Applications for Nanosat and UAV Swarms. In Proceedings of the 2018 International Conference on Wireless and Satellite Systems, Oxford, UK, 14–15 September 2017; Springer International Publishing: Oxford, UK, 2017; pp. 75–85. [Google Scholar]
- Vanitha, N.; Padmavathi, G. A Comparative Study on Communication Architecture of Unmanned Aerial Vehicles and Security Analysis of False Data Dissemination Attacks. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Van Der Bergh, B.; Chiumento, A.; Pollin, S. LTE in the sky: Trading off propagation benefits with interference costs for aerial nodes. IEEE Commun. Mag. 2016, 54, 44–50. [Google Scholar] [CrossRef]
- Chriki, A.; Touati, H.; Snoussi, H.; Kamoun, F. FANET: Communication, Mobility models and Security issues. Comput. Netw. 2019, 163, 106877. [Google Scholar] [CrossRef]
- Fadlullah, Z.; Takaishi, D.; Nishiyama, H.; Kato, N.; Miura, R. A dynamic trajectory control algorithm for improving the communication throughput and delay in UAV-aided networks. IEEE Network 2016, 30, 100–105. [Google Scholar] [CrossRef]
- Al-Hourani, A.; Al-Hourani, S.; Lardner, S. Optimal LAP Altitude for Maximum Coverage. IEEE Wirel. Commun. Lett. 2014, 3, 569–572. [Google Scholar] [CrossRef] [Green Version]
- Ahn, H.; Won, C. DGPS/IMU integration-based geolocation system: Airborne experimental test results. Aerosp. Sci. Technol. 2009, 13, 316–324. [Google Scholar] [CrossRef]
- Wong, A.; Woo, T.; Lee, A.; Xiao, X.; Luk, V. An AGPS-based elderly tracking system. In Proceedings of the 2009 First International Conference on Ubiquitous and Future Networks, Hong Kong, China, 7–9 June 2009; pp. 100–105. [Google Scholar] [CrossRef]
- Mahmood, M.; Seah, M.; Welch, I. Reliability in Wireless Sensor Networks: Survey and Challenges Ahead. Comput. Netw. 2015, 79, 166–187. [Google Scholar] [CrossRef]
- Li, W.; Song, H. ART: An Attack-Resistant Trust Management Scheme for Securing Vehicular Ad Hoc Networks. IEEE Trans. Intell. Transp. Syst. 2016, 17, 960–969. [Google Scholar] [CrossRef]
- Vandenberghe, W.; Moerman, I.; Demeester, P. Adoption of Vehicular Ad Hoc Networking Protocols by Networked Robots. Wirel. Pers. Commun. 2012, 64, 489–522. [Google Scholar] [CrossRef] [Green Version]
- Al-Zaidi, R.; Woods, J.; Al-Khalidi, M.; Hu, H. Building Novel VHF-Based Wireless Sensor Networks for the Internet of Marine Things. IEEE Sens. J. 2018, 18, 2131–2144. [Google Scholar] [CrossRef] [Green Version]
- Mitra, P.; Poellabauer, C. Emergency response in smartphone-based Mobile Ad-Hoc Networks. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 6091–6095. [Google Scholar] [CrossRef]
- Yang, H.; Liu, Z. An optimization routing protocol for FANETs. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 120. [Google Scholar] [CrossRef] [Green Version]
- Nayyar, A. Flying Adhoc Network (FANETs): Simulation Based Performance Comparison of Routing Protocols: AODV, DSDV, DSR, OLSR, AOMDV and HWMP. In Proceedings of the 2018 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 6–7 August 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Corson, M.S.; Macker, J. Mobile Ad hoc Networking (MANET): Routing Protocol Performance Issues and Evaluation Considerations. RFC 1999, 2501, 1–12. Available online: https://dl.acm.org/doi/pdf/10.17487/RFC2501 (accessed on 15 January 2020).
- Perkins, C.E.; Royer, E.M. Ad-hoc on-demand distance vector routing. In Proceedings of the Second IEEE Workshop on Mobile Computing Systems and Applications (Proceedings WMCSA’99), New Orleans, LA, USA, 25–26 February 1999; pp. 90–100. [Google Scholar] [CrossRef] [Green Version]
- Ben Haj Frej, M.; Mandalapa Bhoopathy, V.; Ebenezer Amalorpavaraj, S.R.; Bhoopathy, A. Zone Routing Protocol (ZRP)—A Novel Routing Protocol for Vehicular Ad-hoc Networks. In Proceedings of the ASEE-NE 2016, Kingston, RI, USA, 28–30 April 2016. [Google Scholar]
- Khan, I.U.; Qureshi, I.M.; Aziz, M.A.; Cheema, T.A.; Shah, S.B.H. Smart IoT Control-Based Nature Inspired Energy Efficient Routing Protocol for Flying Ad Hoc Network (FANET). IEEE Access 2020, 8, 56371–56378. [Google Scholar] [CrossRef]
- Dao, N.; Koucheryavy, A.; Paramonov, A. Analysis of Routes in the Network Based on a Swarm of UAVs. In Information Science and Applications (ICISA) 2016; Kim, K.J., Joukov, N., Eds.; Springer: Singapore, 2016; pp. 1261–1271. [Google Scholar]
- Chettibi, S.; Chikhi, S. A Survey of Reinforcement Learning Based Routing Protocols for Mobile Ad-Hoc Networks. In Recent Trends in Wireless and Mobile Networks; Özcan, A., Zizka, J., Nagamalai, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–13. [Google Scholar]
- Zheng, Z.; Sangaiah, A.K.; Wang, T. Adaptive Communication Protocols in Flying Ad Hoc Network. IEEE Commun. Mag. 2018, 56, 136–142. [Google Scholar] [CrossRef]
- Yang, Q.; Jang, S.; Yoo, S.J. Q-Learning-Based Fuzzy Logic for Multi-objective Routing Algorithm in Flying Ad Hoc Networks. Wirel. Pers. Commun. 2020, 113. [Google Scholar] [CrossRef]
- He, C.; Liu, S.; Han, S. A Fuzzy Logic Reinforcement Learning-Based Routing Algorithm For Flying Ad Hoc Networks. In Proceedings of the 2020 International Conference on Computing, Networking and Communications (ICNC), Big Island, HI, USA, 17–20 February 2020; pp. 987–991. [Google Scholar] [CrossRef]
- Colonnese, S.; Cuomo, F.; Pagliari, G.; Chiaraviglio, L. Q-SQUARE: A Q-learning approach to provide a QoE aware UAV flight path in cellular networks. Ad Hoc Netw. 2019, 91, 101872. [Google Scholar] [CrossRef]
- Valente Klaine, P.; Nadas, J.; Souza, R.; Imran, M. Distributed Drone Base Station Positioning for Emergency Cellular Networks Using Reinforcement Learning. Cogn. Comput. 2018, 10. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Yu, P.; Feng, L.; Zhou, F.; Li, W.; Qiu, X. 3D Aerial Base Station Position Planning based on Deep Q-Network for Capacity Enhancement. In Proceedings of the 2019 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Arlington, VA, USA, 8–12 April 2019; pp. 482–487. [Google Scholar]
- Bayerlein, H.; De Kerret, P.; Gesbert, D. Trajectory Optimization for Autonomous Flying Base Station via Reinforcement Learning. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, H.; Song, L. Reinforcement Learning for Decentralized Trajectory Design in Cellular UAV Networks With Sense-and-Send Protocol. IEEE Internet Things J. 2019, 6, 6177–6189. [Google Scholar] [CrossRef]
- Liu, C.H.; Ma, X.; Gao, X.; Tang, J. Distributed Energy-Efficient Multi-UAV Navigation for Long-Term Communication Coverage by Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2020, 19, 1274–1285. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Chen, Y.; Hanzo, L. Trajectory Design and Power Control for Multi-UAV Assisted Wireless Networks: A Machine Learning Approach. IEEE Trans. Veh. Technol. 2019, 68, 7957–7969. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Liu, Y.; Chen, Y. Reinforcement Learning in Multiple-UAV Networks: Deployment and Movement Design. IEEE Trans. Veh. Technol. 2019, 68, 8036–8049. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.Y.; Li, J.; He, X. Deep Reinforcement Learning for NLP. In Tutorial Abstracts, Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 19–21. [Google Scholar] [CrossRef]
- Ghanavi, R.; Kalantari, E.; Sabbaghian, M.; Yanikomeroglu, H.; Yongacoglu, A. Efficient 3D aerial base station placement considering users mobility by reinforcement learning. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Chen, M.; Yin, C. Optimized Trajectory Design in UAV Based Cellular Networks for 3D Users: A Double Q-Learning Approach. J. Commun. Inf. Netw. 2019, 4, 24–32. [Google Scholar] [CrossRef]
- Koushik, A.M.; Hu, F.; Kumar, S. Deep Q -Learning-Based Node Positioning for Throughput-Optimal Communications in Dynamic UAV Swarm Network. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 554–566. [Google Scholar] [CrossRef]
- Mowla, N.I.; Tran, N.H.; Doh, I.; Chae, K. Federated Learning-Based Cognitive Detection of Jamming Attack in Flying Ad-Hoc Network. IEEE Access 2020, 8, 4338–4350. [Google Scholar] [CrossRef]
- Mowla, N.I.; Tran, N.H.; Doh, I.; Chae, K. AFRL: Adaptive federated reinforcement learning for intelligent jamming defense in FANET. J. Commun. Netw. 2020, 22, 244–258. [Google Scholar] [CrossRef]
- Bekmezci, İ.; Şentürk, E.; Türker, T. Security issues in flying Ad-hoc Networks (FANETs). J. Aeronaut. Space Technol. 2016, 9, 13–21. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | FANETs | VANETs | SANETs | RANETs | SPANs | WSNs |
|---|---|---|---|---|---|---|
| Node mobility | Random | Regular | Predefined | Controlled | Regular | Static or regular |
| Node Speed | Upto 500 km/h | Upto 150 km/h | Upto 130 km/h | Upto 25 km/h | Upto 6 km/h | Upto 8 km/h |
| Node Density | Low | High | Medium | Low | Medium | Varies with application |
| Localization | DGPS/AGPS/Net/Height | GPS | GPS | GPS | GPS | GPS |
| Radio propagation | In air and high LoS | On ground and low LoS | On water and high LoS | On ground and low LoS | On ground and low LoS | On ground and low LoS |
| Energy Limitation | Depends on the UAV | Low | Low | High | High | High |
| Routing Protocol | Algorithm | Advantages | Limitations |
|---|---|---|---|
| QMR [12] | Q-learning with dynamic learning rate, discount factor, and adaptive mechanism of exploration and exploitation | 1. Multiple objectives, such as end-to-end delay, energy consumption are considered. | 1. Re-establishing communication is uncertain if a node gets lost. |
| 2. Dynamic and adaptive Q-learning parameters, such as learning rate, and discount factor based on nodes’ velocity and link stability. | 2. Whole route stability is not considered. | ||
| 3. An adaptive mechanism is used for balancing exploration and exploitation. | 3. Computational energy consumption is not considered. | ||
| 4. A penalty mechanism is used to combat "neighbor unavailability" problem. | |||
| RLSRP with PPMAC [49] | Reinforcement learning with partially observable Markov decision process (POMDP) | 1. The positions of nodes are predictable. | 1. Fixed RL parameters. |
| 2. Antenna direction can be changed towards the routing direction. | 2. Only end-to-end delay is considered for route selection. | ||
| 3. Partially observable Markov decision process (POMDP) is used. | 3. There is no adaptive mechanism for balancing exploration and exploitation. | ||
| 4. Broadcasting is used for re-establishing the communication with other nodes. | 4. Computational energy consumption is not considered. | ||
| Multiobjective Routing Protocol [50,51] | Q-learning-based fuzzy logic | 1. Multiple factors, such as the transmission rate, residual energy, energy drain rate, hop count, and successful packet delivery time are considered. | 1. There is no adaptive mechanism for balancing exploration and exploitation. |
| 2. Both single and whole route performances are considered. | 2. Fixed RL parameters. | ||
| 3. Two Q-values are used from two Q-learning algorithm. | 3. There is no mechanism to remedy the “neighbor unavailability” problem. | ||
| 4. Fuzzy logic is used to select the optimal route. | 4. Computational energy consumption is not considered. |
| Type | Algorithm | Advantages | Limitations |
|---|---|---|---|
| Q-SQUARE [52] | Single-agent Q-learning | 1. Energy limitation is considered. | 1. Fixed RL parameters. |
| 2. Autonomous visit to charging stations is incorporated. | 2. Single UAV is considered for learning. | ||
| Decentralized Trajectory Design [56,57] | Decentralized RL/DRL | 1. POMDP is used to determine the trajectory path. | 1. Fixed altitude setting. |
| 2 Energy limitation is considered. | 2. Autonomous visit to charging stations is not considered. | ||
| 3. Actor-critic method is used for distributed control. | 3. User mobility is not considered. | ||
| Joint Trajectory design and Power Control [58] | Multi-agent Q-learning | 1. Low complexity and fast convergence due to individual agent training. | 1. Fixed policy for other agents is considered while training an agent. |
| 2. User location is predictable, and action is possible accordingly. | 2. Autonomous visit to charging stations is not considered. | ||
| 3. Fixed RL parameters. | |||
| 4. Energy limitation is not considered. | |||
| Multi-UAV Deployment and Movement Design [59,60,61] | Q-learning /Double Q-learning | 1. User mobility is considered. | 1. User mobility is constrained within the cluster. |
| 2. Multiple UAVs are incorporated together by dividing the users in clusters. | 2. Energy limitation is not considered. | ||
| 3. 3D deployment scenario is considered. | 3. Autonomous visit to charging stations is not considered. | ||
| 4.-greedy policy is used. | 4. Mobility of UAVs is constrained within 7 directions. | ||
| Trajectory Optimization for UBS [53,55] | Q-learning | 1.-greedy policy is used. | 1. Fixed altitude setting. |
| 2. Obstacles are considered during flying towards destination. | 2. Autonomous visit to charging stations is not considered. | ||
| 3. Safety check is incorporated within the system. | 3. Mobility of UAVs is constrained within 4 directions. | ||
| 4. Energy limitation is considered in terms of flying time. | 4. User mobility is not considered. |
| Type | Algorithm | Characteristics | Goal |
|---|---|---|---|
| Relaying | Deep Q-learning | Multiple UAVs are positioned in dynamic UAV swarming applications by using the replay-buffer-based DQN learning algorithm which can keep track of the network topology changes [63]. | Achieve the optimal communication among swarming nodes. |
| Protection against jamming | Federated Q-learning | Mowla et al. developed a cognitive jamming detection technique using priority-based federated learning in [64]. Then, the authors developed an adaptive model-free jamming defense mechanism based on federated Q-learning with spatial retreat strategy in [65] for FANETs. | Jamming protection for other networks. |
| Charging UAVs | Deep Q-learning | The mobile charging scheduling problem is interpreted as an auction problem where each UAV bids its own valuation and then the charging station schedules drones based on it in terms of revenue optimality. The charging auction enables efficient scheduling by learning the bids distribution using DQL [11]. | Scheduling UAVs for charging. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rezwan, S.; Choi, W. A Survey on Applications of Reinforcement Learning in Flying Ad-Hoc Networks. Electronics 2021, 10, 449. https://doi.org/10.3390/electronics10040449
Rezwan S, Choi W. A Survey on Applications of Reinforcement Learning in Flying Ad-Hoc Networks. Electronics. 2021; 10(4):449. https://doi.org/10.3390/electronics10040449
Chicago/Turabian StyleRezwan, Sifat, and Wooyeol Choi. 2021. "A Survey on Applications of Reinforcement Learning in Flying Ad-Hoc Networks" Electronics 10, no. 4: 449. https://doi.org/10.3390/electronics10040449
APA StyleRezwan, S., & Choi, W. (2021). A Survey on Applications of Reinforcement Learning in Flying Ad-Hoc Networks. Electronics, 10(4), 449. https://doi.org/10.3390/electronics10040449