
Colorization of Logo Sketch Based on Conditional Generative Adversarial Networks




Abstract
:1. Introduction
- (1)
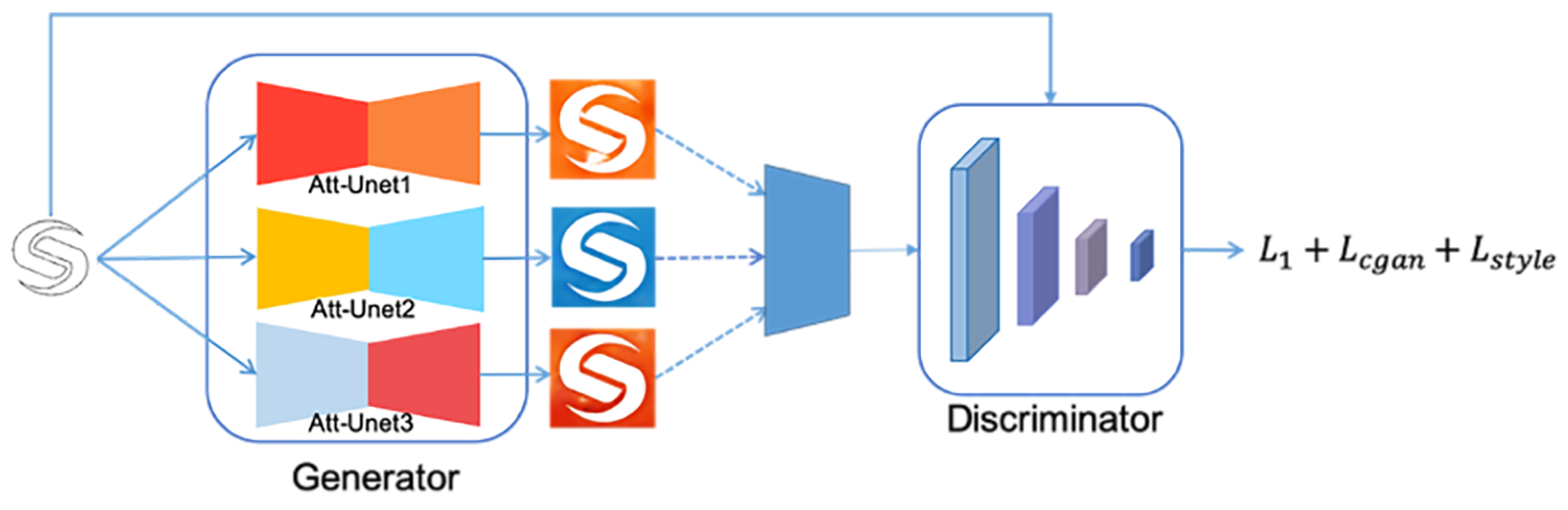
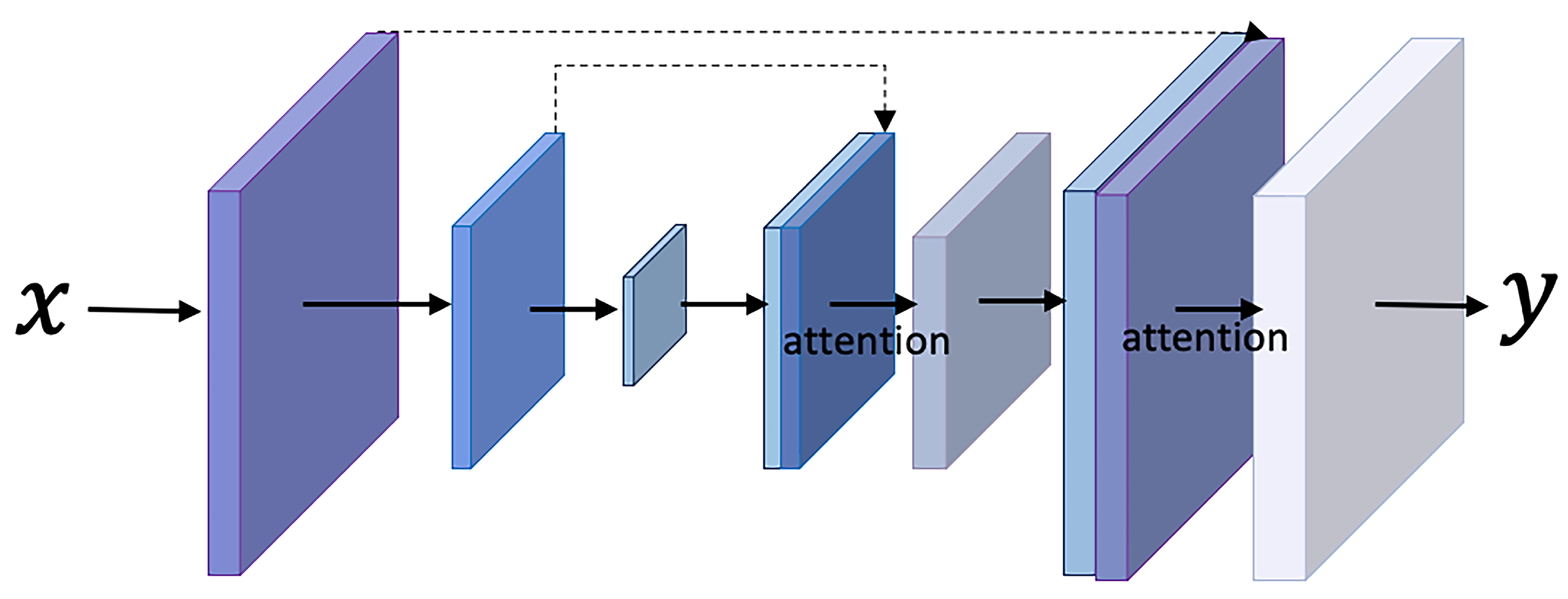
- We improve the traditional U-Net structure. Channel attention and spatial attention mechanism [23] are added to the skip-connection in the U-Net module to improve the stability of the output.
- (2)
- We stack several attention-based U-Net modules (Att-UNet) in the generator, and each Att-UNet module output one image. We randomly select one image from Att-UNet modules and feed it to the discriminator training, which can prevent the problem of mode crash and make the training more stable.
- (3)
- We add a new loss function based on the Pix2Pix objective function to make the output of the generator more diversified.
2. Related Work
2.1. Image Colorization
2.2. Conditional Generative Adversarial Networks
2.3. Attention Mechanism
3. Methodology
3.1. Preliminaries
3.2. Network Structure and Loss Function
3.2.1. Att-Unet
3.2.2. Loss Function
3.3. Training Strategy
4. Results and Discussion
4.1. Datasets
4.2. Experimental Setup
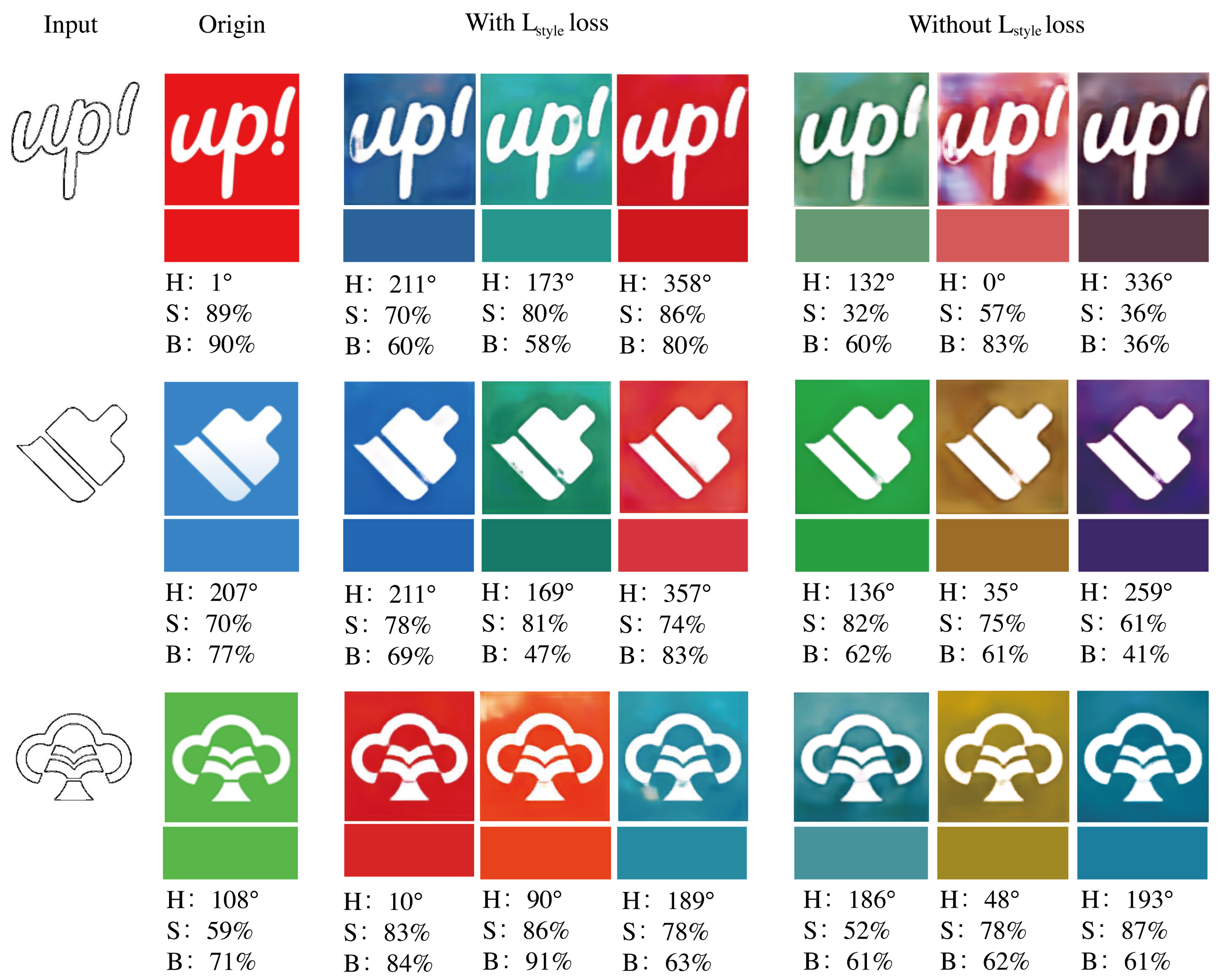
4.3. Objective Function Analysis
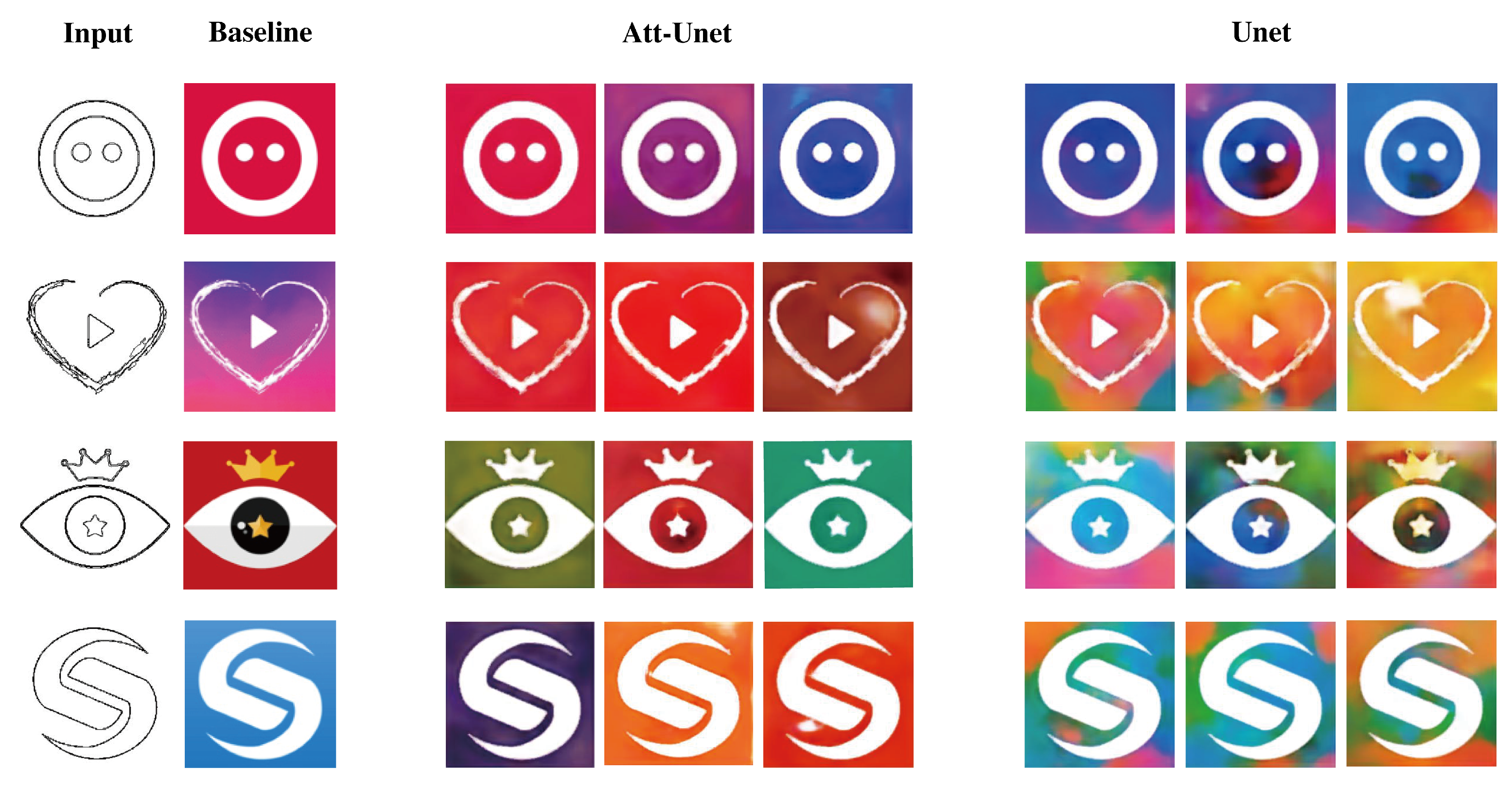
4.4. Att-UNet Analysis
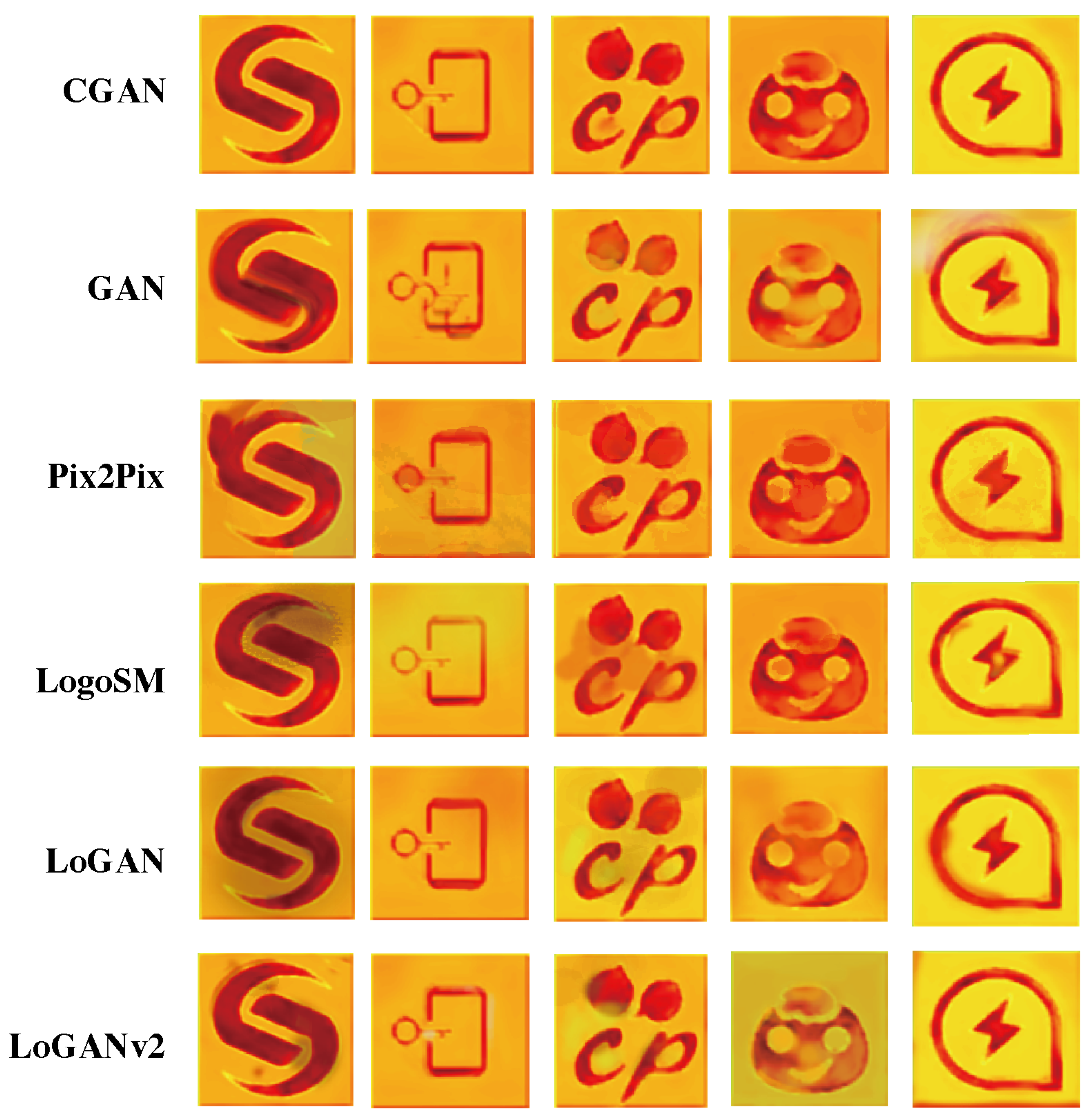
4.5. Comparison and Analysis
4.6. Future Research on Generating Colorful LOGO
- Increase the diversity of training dataset.(1) Randomly add different colors to the original data to enrich the color features of the training dataset.(2) Add conditional information (such as semantics, combine contours and semantics) to GAN networks which is used to generate icons and logos that designers want as our training data.
- Add prior information to the network input.To generate colorful logo images, the input of our network is not just the logo sketch, but also other prior information (such as the basic color provided by the designer, the desired color information).
- Constrain the loss function of our network.In our method, is used to increase the variety of logo color. On the basis of increasing the diversity of training samples, we can increase the weight of in our loss function to expand the color diversity of network output. Thus, the color of the logo images can be enriched.
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Souly, N.; Spampinato, C.; Shah, M. Semi supervised semantic segmentation using generative adversarial network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5688–5696. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv 2016, arXiv:1605.05396. [Google Scholar]
- Ak, K.E.; Lim, J.H.; Tham, J.Y.; Kassim, A.A. Semantically consistent text to fashion image synthesis with an enhanced attentional generative adversarial network. Pattern Recognit. Lett. 2020, 135, 22–29. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, J.; Yao, Y.; Sun, Y.; Rao, H.; Shu, X. CAN-GAN: Conditioned-attention normalized GAN for face age synthesis. Pattern Recognit. Lett. 2020, 138, 520–526. [Google Scholar] [CrossRef]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3943–3956. [Google Scholar] [CrossRef] [Green Version]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H. A medical image fusion method based on convolutional neural networks. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–7. [Google Scholar]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 2017, 30, 700–708. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Sage, A.; Agustsson, E.; Timofte, R.; Van Gool, L. Logo synthesis and manipulation with clustered generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5879–5888. [Google Scholar]
- Mino, A.; Spanakis, G. LoGAN: Generating logos with a generative adversarial neural network conditioned on color. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 965–970. [Google Scholar]
- Oeldorf, C.; Spanakis, G. LoGANv2: Conditional Style-Based Logo Generation with Generative Adversarial Networks. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 462–468. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Zhang, L.; Ji, Y.; Lin, X.; Liu, C. Style transfer for anime sketches with enhanced residual u-net and auxiliary classifier gan. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 506–511. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 649–666. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Learning representations for automatic colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 577–593. [Google Scholar]
- Deshpande, A.; Lu, J.; Yeh, M.C.; Jin Chong, M.; Forsyth, D. Learning diverse image colorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6837–6845. [Google Scholar]
- Mouzon, T.; Pierre, F.; Berger, M.O. Joint cnn and variational model for fully-automatic image colorization. In Proceedings of the International Conference on Scale Space and Variational Methods in Computer Vision, Hofgeismar, Germany, 30 June–4 July 2019; pp. 535–546. [Google Scholar]
- Wan, S.; Xia, Y.; Qi, L.; Yang, Y.H.; Atiquzzaman, M. Automated colorization of a grayscale image with seed points propagation. IEEE Trans. Multimed. 2020, 22, 1756–1768. [Google Scholar] [CrossRef]
- Suárez, P.L.; Sappa, A.D.; Vintimilla, B.X. Infrared image colorization based on a triplet dcgan architecture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 18–23. [Google Scholar]
- Nazeri, K.; Ng, E.; Ebrahimi, M. Image colorization using generative adversarial networks. In Proceedings of the International Conference on Articulated Motion and Deformable Objects, Palma de Mallorca, Spain, 12–13 July 2018; pp. 85–94. [Google Scholar]
- Sharma, M.; Makwana, M.; Upadhyay, A.; Singh, A.P.; Badhwar, A.; Trivedi, A.; Saini, A.; Chaudhury, S. Robust image colorization using self attention based progressive generative adversarial network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2188–2196. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 2642–2651. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ramchoun, H.; Idrissi, M.A.J.; Ghanou, Y.; Ettaouil, M. Multilayer Perceptron: Architecture Optimization and Training. IJIMAI 2016, 4, 26–30. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DataSet | Loss | MAE | MSE | SSIM |
|---|---|---|---|---|
| edgaes2logos | without | 98.87 | 307.64 | 0.64 |
| 110.89 | 572.55 | 0.77 | ||
| edgaes2shoes | without | 21.73 | 86.89 | 0.58 |
| 35.01 | 110.45 | 0.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, N.; Liu, Y.; Wu, B.; Li, X. Colorization of Logo Sketch Based on Conditional Generative Adversarial Networks. Electronics 2021, 10, 497. https://doi.org/10.3390/electronics10040497
Tian N, Liu Y, Wu B, Li X. Colorization of Logo Sketch Based on Conditional Generative Adversarial Networks. Electronics. 2021; 10(4):497. https://doi.org/10.3390/electronics10040497
Chicago/Turabian StyleTian, Nannan, Yuan Liu, Bo Wu, and Xiaofeng Li. 2021. "Colorization of Logo Sketch Based on Conditional Generative Adversarial Networks" Electronics 10, no. 4: 497. https://doi.org/10.3390/electronics10040497
APA StyleTian, N., Liu, Y., Wu, B., & Li, X. (2021). Colorization of Logo Sketch Based on Conditional Generative Adversarial Networks. Electronics, 10(4), 497. https://doi.org/10.3390/electronics10040497