
Enabling Parallelized-QEMU for Hardware/Software Co-Simulation Virtual Platforms



Abstract
:1. Introduction
2. Background and Proposal Description
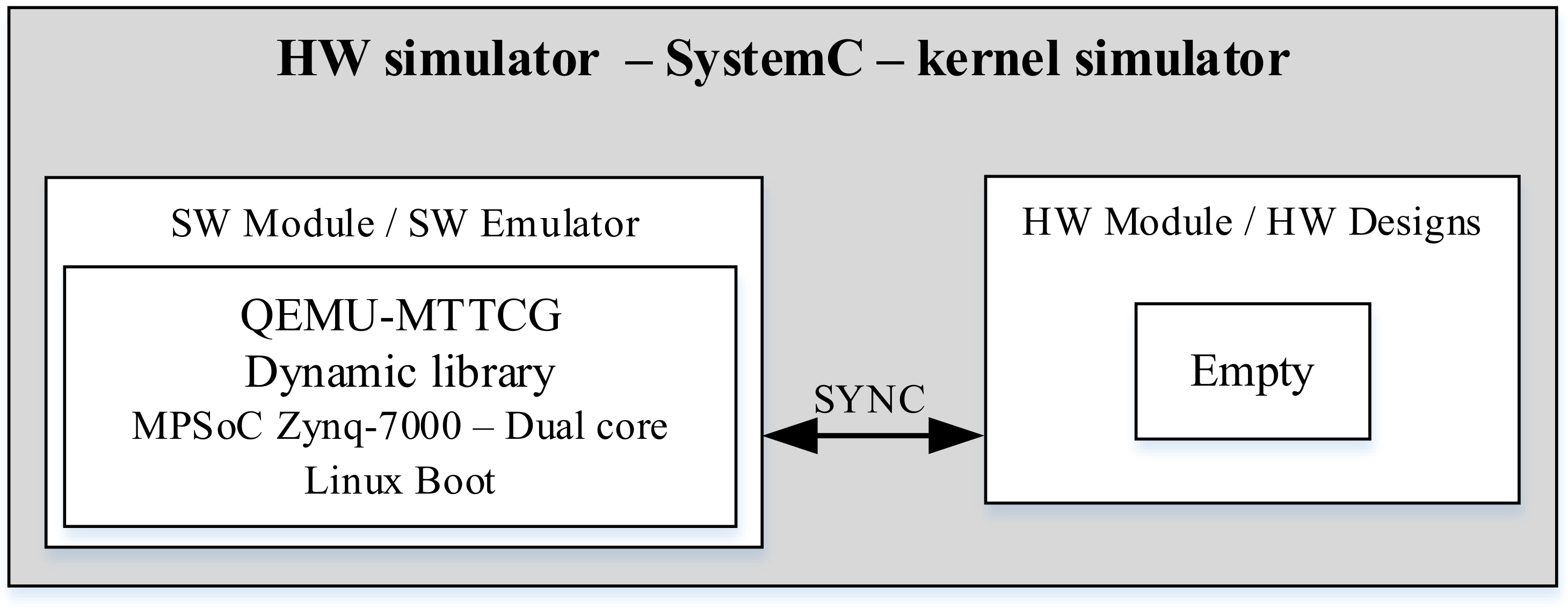
2.1. Hardware/Software Co-Simulation Virtual Platforms
2.2. QEMU as Software Emulator
2.3. Parallelized-QEMU Project
2.4. Proposal Description
- A procedure to obtain the number of instructions executed by each processor in a multicore emulation. The notion of time for each virtual CPU can be calculated from this instruction counter, providing an approximately timed processor model.
- A method to break the QEMU translation loop and execute a synchronization point with the hardware simulator. This is critical as to not affect the performance of QEMU translation loop and achieve fast emulations.
- A method to manage the software timing notion from hardware simulator point of view in multi-core systems. A synchronization between the external hardware simulator and the software emulator (QEMU) is essential to allow a correct co-simulation.
3. QEMU External Synchronization Mechanism
- Input/Output (I/O) accesses from software to hardware (physical).
- Asynchronous interrupts (physical).
- Synchronization points (virtual).
3.1. Hardware/Software Interactions
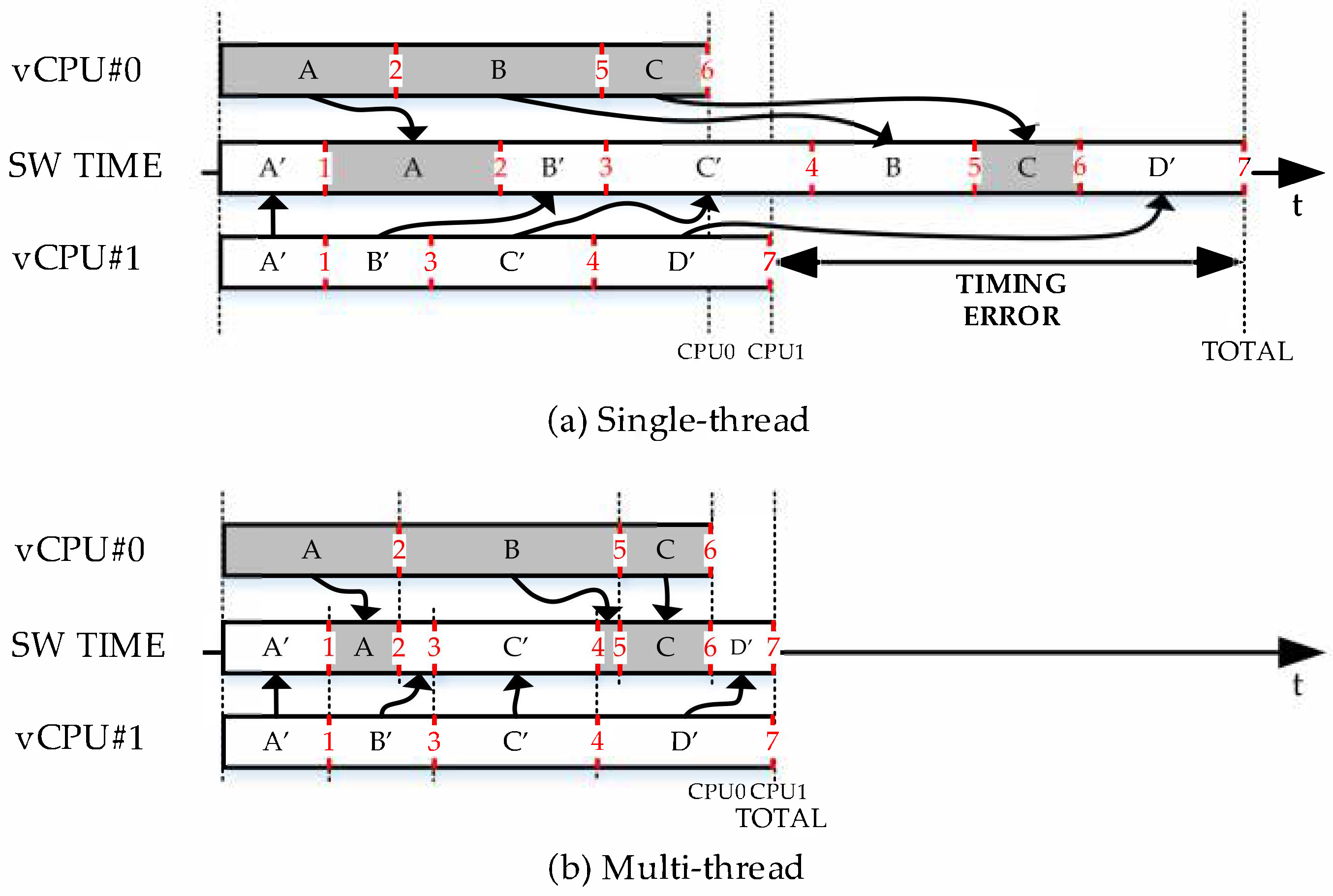
3.2. The Notion of Time in QEMU
3.3. Implementation of External Synchronization in QEMU-MTTCG
3.3.1. Location of the Synchronization Points
- Exceeding the maximum limit of instructions executed (icountMax). This exception enables carrying out other pending tasks and processing events associated with the management of the whole emulated system. The icountMax value is the maximum limit of instructions executed in a translation-execution loop (in Equation (1), it equals variable N) and is user-configurable.
- An external interaction toward the vCPU. Which is any signal that is generated outside vCPU flow and modifies its state (i.e., asynchronous interrupts).
- Other exceptions generated by the guest code. Most of them are related to the guest code, the QEMU management of the vCPUs, and the emulated peripherals.
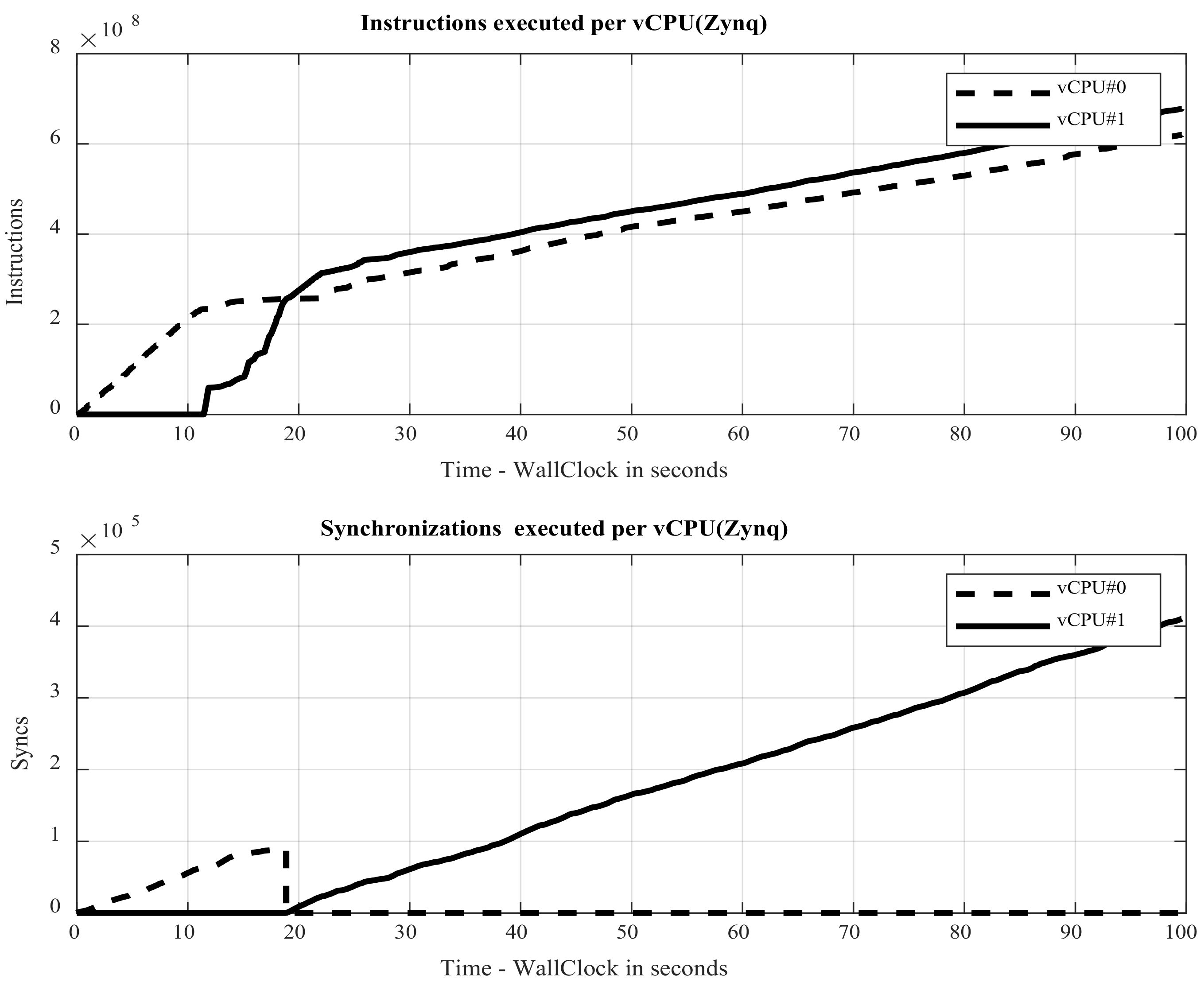
3.3.2. vCPU Instruction Counter
3.3.3. Management of Synchronization Points
- Instructions shared between vCPUs. The synchronization in parallel execution of vCPUs is guaranteed by QEMU-MTTCG when an instruction affects multiple vCPUs. As with DES, the affected vCPUs are blocked until all vCPUs reach the same simulation time. Otherwise, and for most of the instructions, the instructions of each vCPU are executed as fast as possible [25].
- The structure of the guest code in each vCPU is decisive in its speed of execution. A complex structure of the guest code means that QEMU will make more translations and changes to the TB cache table. Therefore fewer executions will be chained, decreasing the performance of the vCPU simulation.
- The workload of the machine/OS on which QEMU runs. Therefore, the speed at which QEMU executes its instructions can change in function on the host OS load.
4. Test and Results
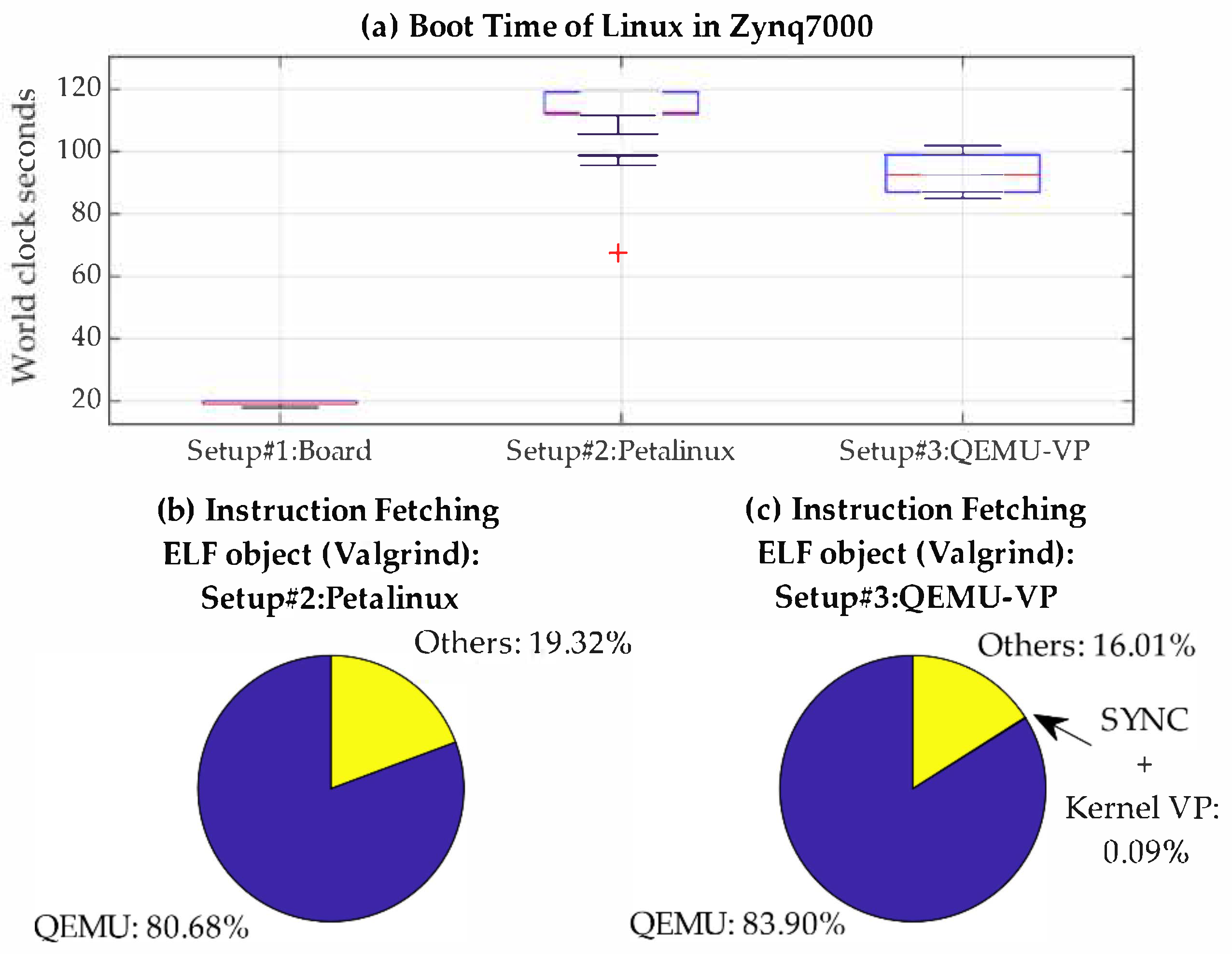
4.1. Overhead of Virtual Interactions in Co-Simulation
- Setup#1: Real board. Linux boot in the physical system (ZedBoard-Zynq7000).
- Setup#2: QEMU-PetaLinux. Linux boot using QEMU-MTTCG provided by PetaLinux. This setup shows the execution time using the QEMU version included in PetaLinux. Therefore, we selected this version as star point to apply our solution.
- Setup#3: QEMU-VP. (QEMU for virtual platforms) Linux boot using the version of QEMU-MTTCG patched with our external synchronization mechanism. In this setup, QEMU is included in a SystemC-based Virtual Co-simulation Platform (see Figure 7).

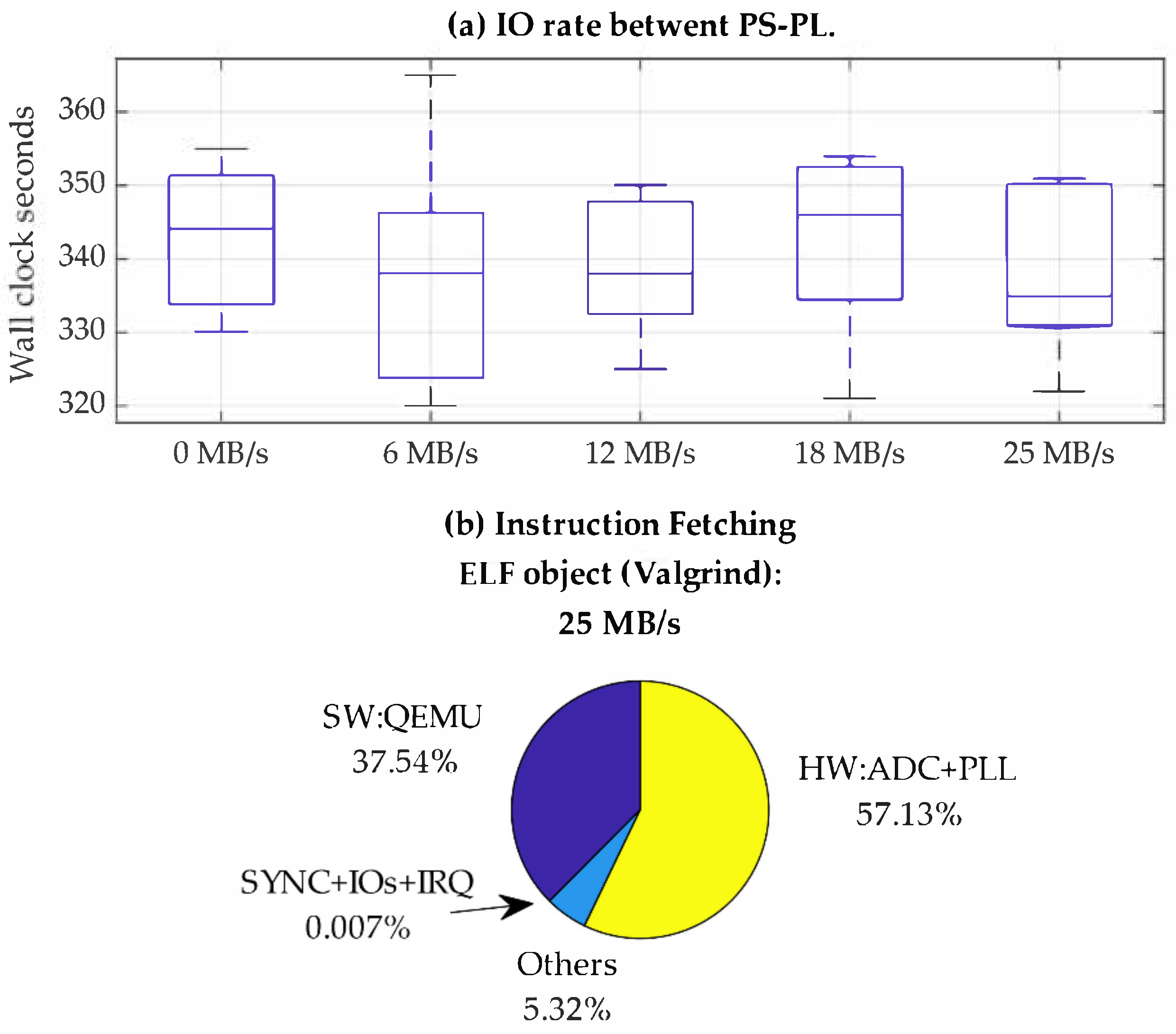
4.2. Overhead of Physical Interactions in Co-Simulation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rodriguez-Andina, J.J.; Valdes-Pena, M.D.; Moure, M.J. Advanced Features and Industrial Applications of FPGAS-A Review. IEEE Trans. Ind. Inform. 2015, 11, 853–864. [Google Scholar] [CrossRef]
- Wu, Y.; Fu, L.; Ma, F.; Hao, X. Cyber-Physical Co-Simulation of Shipboard Integrated Power System Based on Optimized Event-Driven Synchronization. Electronics 2020, 9, 540. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Kim, S.W.; Han, Y. EPSim-C: A Parallel Epoch-Based Cycle-Accurate Microarchitecture Simulator Using Cloud Computing. Electronics 2019, 8, 716. [Google Scholar] [CrossRef] [Green Version]
- Xu, B. Boyi Xu; Li Da Xu; Hongming Cai; Cheng Xie; Jingyuan Hu; Fenglin Bu; Ubiquitous Data Accessing Method in IoT-Based Information System for Emergency Medical Services. IEEE Trans. Ind. Inform. 2014, 10, 1578–1586. [Google Scholar] [CrossRef]
- Mendoza, F.; Pascal, J.; Nenninger, P.; Becker, J. Framework for dynamic verification of multi-domain virtual platforms in industrial automation. In Proceedings of the IEEE 10th International Conference on Industrial Informatics, Beijing, China, 25–27 July 2012; pp. 935–940. [Google Scholar] [CrossRef]
- Design Automation Standards Committee. Standard IEEE Standard for Reference SystemC® Language Manual; IEEE Standards Association: New York, NY, USA, 2011. [Google Scholar]
- Duraton, M.; De Bosschere, K.; Coppens, B.; Gamrat, C.; Gray, M. HiPEAC Vision. UGent: Ghent, The Netherlands, 2019. [Google Scholar]
- QEMU. QEMU Official Web Page. Available online: https://www.qemu.org/ (accessed on 21 December 2020).
- Fujimoto, R.M. Parallel and Distributed Simulation Systems, 1st ed.; John Wiley & Sons, Inc: Hoboken, NJ, USA, 2000. [Google Scholar]
- Weinstock, J.H.; Murillo, L.G.; Leupers, R.; Ascheid, G. Parallel SystemC Simulation for ESL Design. ACM Trans. Embed. Comput. Syst. 2016, 16, 1–25. [Google Scholar] [CrossRef]
- Chiang, M.C.; Yeh, T.C.; Tseng, G.F. A QEMU and SystemC-based cycle-accurate ISS for performance estimation on SoC development. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2011, 30, 593–606. [Google Scholar] [CrossRef]
- Manbachi, M.; Sadu, A.; Farhangi, H.; Monti, A.; Palizban, A.; Ponci, F.; Arzanpour, S. Real-Time Co-Simulation Platform for Smart Grid Volt-VAR Optimization Using IEC 61850. IEEE Trans. Ind. Inform. 2016, 12, 1392–1402. [Google Scholar] [CrossRef]
- Delbergue, G.; Burton, M.; Konrad, F.; Le Gal, B.; Jego, C. QBox: An industrial solution for virtual platform simulation using QEMU and SystemC TLM-20. In Proceedings of the 8th European Congress on Embedded Real Time Software and Systems (ERTS 2016), Toulouse, France, 27–29 January 2016. [Google Scholar]
- Alian, M.; Kim, D.; Sung Kim, N. pd-gem5: Simulation Infrastructure for Parallel/Distributed Computer Systems. IEEE Comput. Archit. Lett. 2016, 15, 41–44. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, R.; Chen, Y.; Wu, X.; Chen, H.; Zhang, W.; Zang, B. COREMU. ACM Sigplan Not. 2011, 46, 213. [Google Scholar] [CrossRef]
- Magnusson, P.S.; Christensson, M.; Eskilson, J.; Forsgren, D.; Hallberg, G.; Hogberg, J.; Larsson, F.; Moestedt, A.; Werner, B. Simics: A full system simulation platform. Computer 2002, 35, 50–58. [Google Scholar] [CrossRef] [Green Version]
- Domer, R. Seven Obstacles in the Way of Standard-Compliant Parallel SystemC Simulation. IEEE Embed. Syst. Lett. 2016, 8, 81–84. [Google Scholar] [CrossRef]
- Becker, D.; Moy, M.; Cornet, J. Parallel Simulation of Loosely Timed SystemC/TLM Programs: Challenges Raised by an Industrial Case Study. Electronics 2016, 5, 22. [Google Scholar] [CrossRef] [Green Version]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The gem5 simulator. ACM Sigarch Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Lonardi, A.; Pravadelli, G. On the co-simulation of systemC with QEMU and OVP virtual platforms. In IFIP Advances in Information and Communication Technology; Springer: Cham, Switzerland, 2015; Volume 464, pp. 110–128. [Google Scholar]
- Imperas. OVPsim. 2008. Available online: http://www.ovpworld.org/ (accessed on 20 January 2021).
- Cucchetto, F.; Lonardi, A.; Pravadelli, G. A common architecture for co-simulation of SystemC models in QEMU and OVP virtual platforms. In Proceedings of the 2014 22nd International Conference on Very Large Scale Integration (VLSI-SoC), Playa del Carmen, Mexico, 6–8 October 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Bellard, F. QEMU, a Fast and Portable Dynamic Translator. In Proceedings of the USENIX Annual Technical Conference, Anaheim, CA, USA, 10–15 April 2005; pp. 41–46. [Google Scholar]
- Morales, F.; Bismarck, J.L. Evaluating Gem5 and QEMU Virtual Platforms for ARM Multicore Architectures; KTH Royal Institute of Technology in Stockholm: Stockholm, Sweden, 2016. [Google Scholar]
- Cota, E.G.; Bonzini, P.; Bennee, A.; Carloni, L.P. Cross-ISA machine emulation for multicores. In Proceedings of the 2017 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Austin, TX, USA, 4–8 February 2017; pp. 210–220. [Google Scholar] [CrossRef]
- Butko, A.; Garibotti, R.; Ost, L.; Sassatelli, G. Accuracy evaluation of GEM5 simulator system. In Proceedings of the 7th International Workshop on Reconfigurable and Communication-Centric Systems-on-Chip (ReCoSoC), York, UK, 9–11 July 2012; pp. 1–7. [Google Scholar] [CrossRef]
- Menard, C.; Castrillon, J.; Jung, M.; Wehn, N. System simulation with gem5 and SystemC: The keystone for full interoperability. In Proceedings of the 2017 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS), Pythagorion, Greece, 17–20 July 2017; pp. 62–69. [Google Scholar] [CrossRef]
- Abudaqa, A.A.; Al-Kharoubi, T.M.; Mudawar, M.F.; Kobilica, A. Simulation of ARM and x86 microprocessors using in-order and out-of-order CPU models with Gem5 simulator. In Proceedings of the 2018 5th International Conference on Electrical and Electronic Engineering (ICEEE), Istanbul, Turkey, 3–5 May 2018; pp. 317–322. [Google Scholar] [CrossRef]
- Jünger, L.; Weinstock, J.H.; Leupers, R.; Ascheid, G. Fast SystemC Processor Models with Unicorn. In Proceedings of the Rapid Simulation and Performance Evaluation: Methods and Tools on—RAPIDO ’19, Valencia, Spain, 22 January 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Nguyen, A.Q.; Dang, H.V. Unicorn: Next Generation CPU Emulator Framework. 2015. Available online: http://www.unicorn-engine.org/ (accessed on 15 January 2021).
- Zhang, D.; Zeng, X.; Wang, Z.; Wang, W.; Chen, X. MCVP-NoC: Many-Core Virtual Platform with Networks-on-Chip support. In Proceedings of the 2013 IEEE 10th International Conference on ASIC, Shenzhen, China, 28–31 October 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Kilic, O.; Doddamani, S.; Bhat, A.; Bagdi, H.; Gopalan, K. Overcoming Virtualization Overheads for Large-vCPU Virtual Machines. In Proceedings of the 2018 IEEE 26th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS), Milwaukee, WI, USA, 25–28 September 2018; pp. 369–380. [Google Scholar] [CrossRef]
- Chen, I.-H.; King, C.-T.; Chen, Y.-H.; Lu, J.-M. Full System Emulation of Embedded Heterogeneous Multicores Based on QEMU. In Proceedings of the 2018 IEEE 24th International Conference on Parallel and Distributed Systems (ICPADS), Singapore, 11–13 December 2018; pp. 771–778. [Google Scholar] [CrossRef]
- Kang, S.; Yoo, D.; Ha, S. TQSIM: A fast cycle-approximate processor simulator based on QEMU. J. Syst. Archit. 2016, 66–67, 33–47. [Google Scholar] [CrossRef]
- Lee, K.; Han, W.; Lee, J.; Chwa, H.S.; Shin, I. Fast and accurate cycle estimation through hybrid instruction set simulation for embedded systems. In Proceedings of the 2016 IEEE Real-Time Systems Symposium (RTSS), Porto, Portugal, 29 November–2 December 2016; p. 370. [Google Scholar] [CrossRef]
- Iqbal, S.M.Z.; Liang, Y.; Grahn, H. ParMiBench—An Open-Source Benchmark for Embedded Multiprocessor Systems. IEEE Comput. Archit. Lett. 2010, 9, 45–48. [Google Scholar] [CrossRef]
- Sanchez, F.M.; Mateos, R.; Bueno, E.J.; Mingo, J.; Sanz, I. Comparative of HLS and HDL implementations of a grid synchronization algorithm. In Proceedings of the IECON 2013—39th Annual Conference of the IEEE Industrial Electronics Society, Vienna, Austria, 10–13 November 2013; pp. 2232–2237. [Google Scholar] [CrossRef]
- Xilinx. Zynq-7000 SoC Technical Reference Manual—UG565. 2021. Available online: https://www.xilinx.com/support.html (accessed on 22 March 2021).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SW Emulator | License | Engine | Accurate | Speed | Platforms Supported | Refs. |
|---|---|---|---|---|---|---|
| Simics (Wind River) | Private | KVM: Multi-thread | Function | ●●●●○ | ●○○○○ | [11,16] |
| OVPSim (Imperas) | Open/private | DBT: Single-thread | Instruction | ●●○○○ | ●●●●○ | [20,21,22] |
| QEMU-DBT | Open | DBT: Single-thread | Instruction | ●●●○○ | ●●●●● | [20,23] |
| QEMU-KVM | Open | KVM: Single-thread | Instruction | ●●●●● | ●○○○○ | [23,24] |
| QEMU-MTTCG | Open | DBT-Parallel: Multi-thread | Instruction | ●●●●○ | ●●●○○ | [25] |
| Gem5 | Open | DES: Single-thread | Cycle | ●○○○○ | ●○○○○ | [19,26,27,28] |
| Unicorn | Open | DBT: Single-thread | Instruction | ●●●○○ | ●●●○○ | [29,30] |
| Benchmark | Categories | Summary | Configuration |
|---|---|---|---|
| basicmath | Automation | It makes mathematical calculations such as cubic function solving, angle conversions, and integer square root. | Large data set: 1 Giga numbers. |
| bitcount | Automation | It measures the processor bit manipulation capability by counting the number of bits. | An input of long type (31 bits with 1). |
| susan | Automation | It is an image recognition application, which detects corners and edges. | PGM picture: 2.8 MB. |
| patricia | Network | It uses a sparse leaf nodes-based data structure used instead of a full-tree. | Text file containing 5000 IP addresses. |
| dijkstra | Network | It computes the single-source and all-pairs shortest paths in an adjacency matrix graph. | All-pairs: 160 × 160 matrix. |
| stringsearch | Office | It gets a specific word in several given phrases by using case sensitive or insensitive comparison algorithms. | Input data set size: 32 MB 1024 patterns or keys of length (m): 5 |
| sha | Security | Iterative one-way hash function cryptographic algorithm. | -P 2 (Dual-core) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Díaz, E.; Mateos, R.; Bueno, E.J.; Nieto, R. Enabling Parallelized-QEMU for Hardware/Software Co-Simulation Virtual Platforms. Electronics 2021, 10, 759. https://doi.org/10.3390/electronics10060759
Díaz E, Mateos R, Bueno EJ, Nieto R. Enabling Parallelized-QEMU for Hardware/Software Co-Simulation Virtual Platforms. Electronics. 2021; 10(6):759. https://doi.org/10.3390/electronics10060759
Chicago/Turabian StyleDíaz, Edel, Raúl Mateos, Emilio J. Bueno, and Rubén Nieto. 2021. "Enabling Parallelized-QEMU for Hardware/Software Co-Simulation Virtual Platforms" Electronics 10, no. 6: 759. https://doi.org/10.3390/electronics10060759
APA StyleDíaz, E., Mateos, R., Bueno, E. J., & Nieto, R. (2021). Enabling Parallelized-QEMU for Hardware/Software Co-Simulation Virtual Platforms. Electronics, 10(6), 759. https://doi.org/10.3390/electronics10060759