
Two-Dimensional Audio Compression Method Using Video Coding Schemes

 ,
, 


Abstract
:1. Introduction
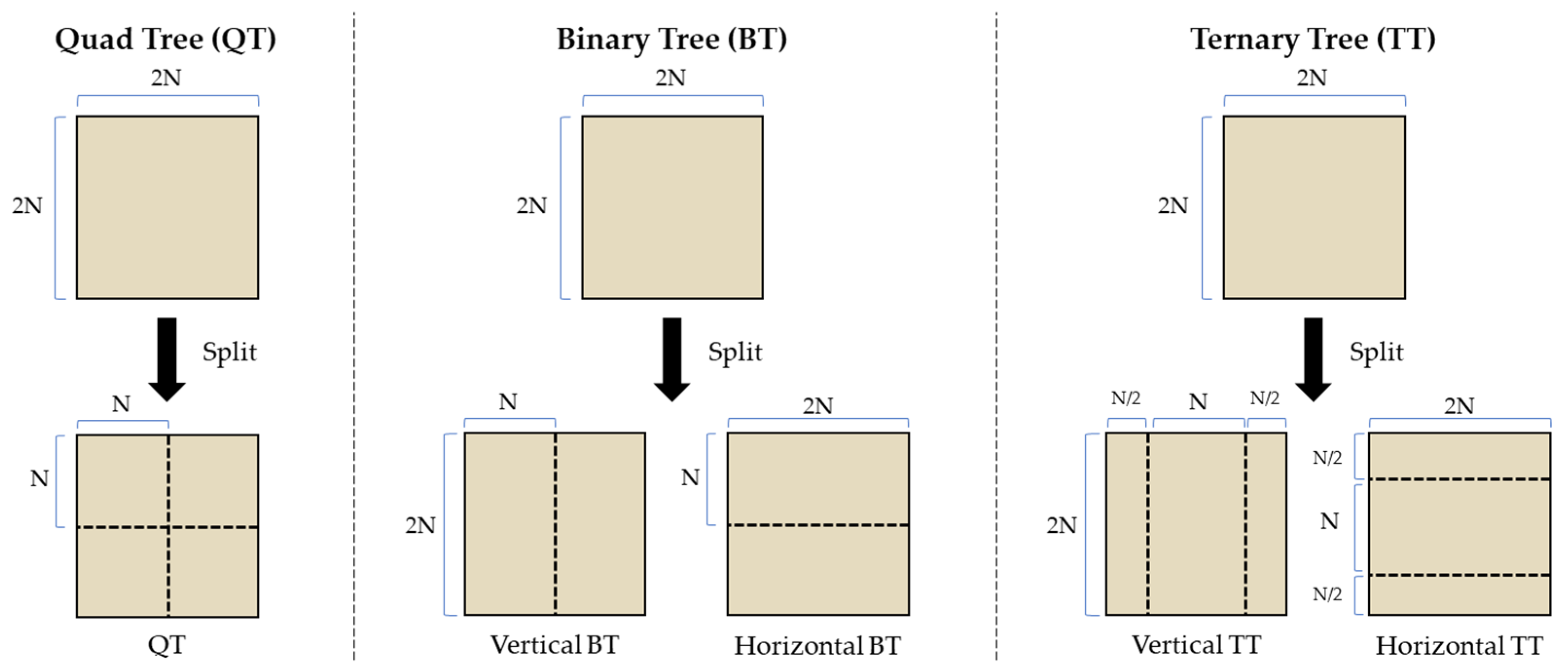
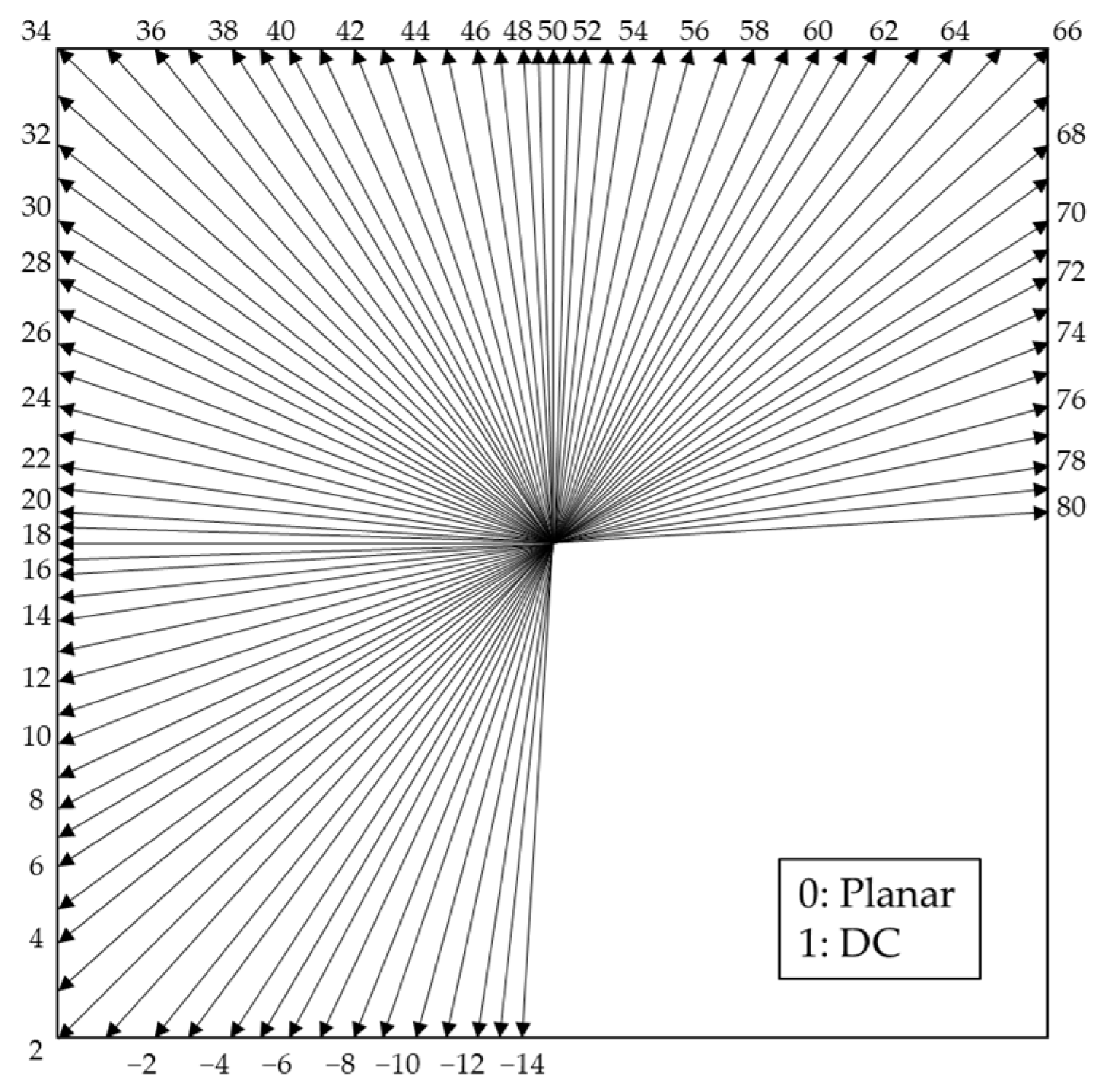
2. Overview of VVC
3. VVC-Based 2D Audio Compression Method
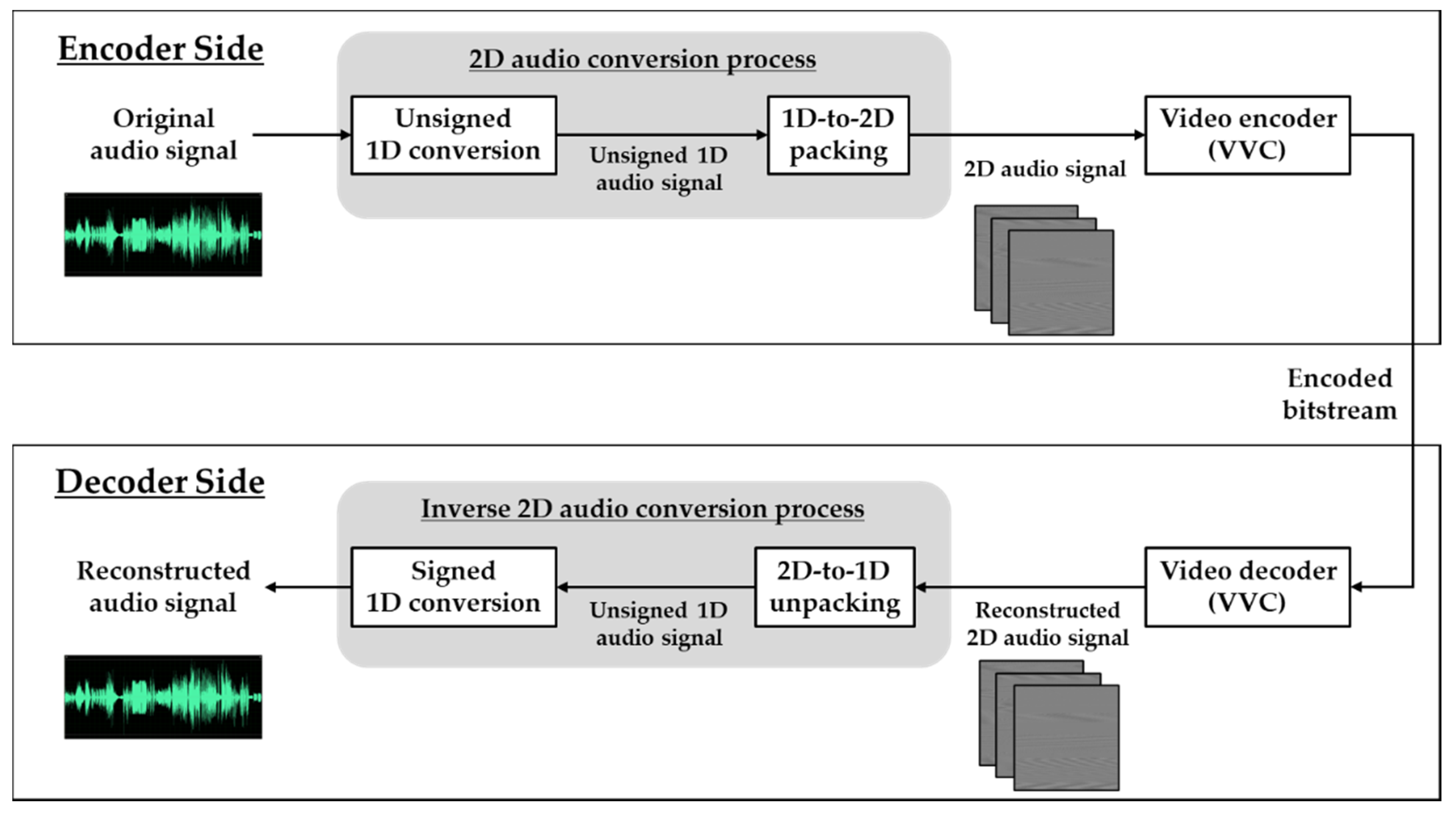
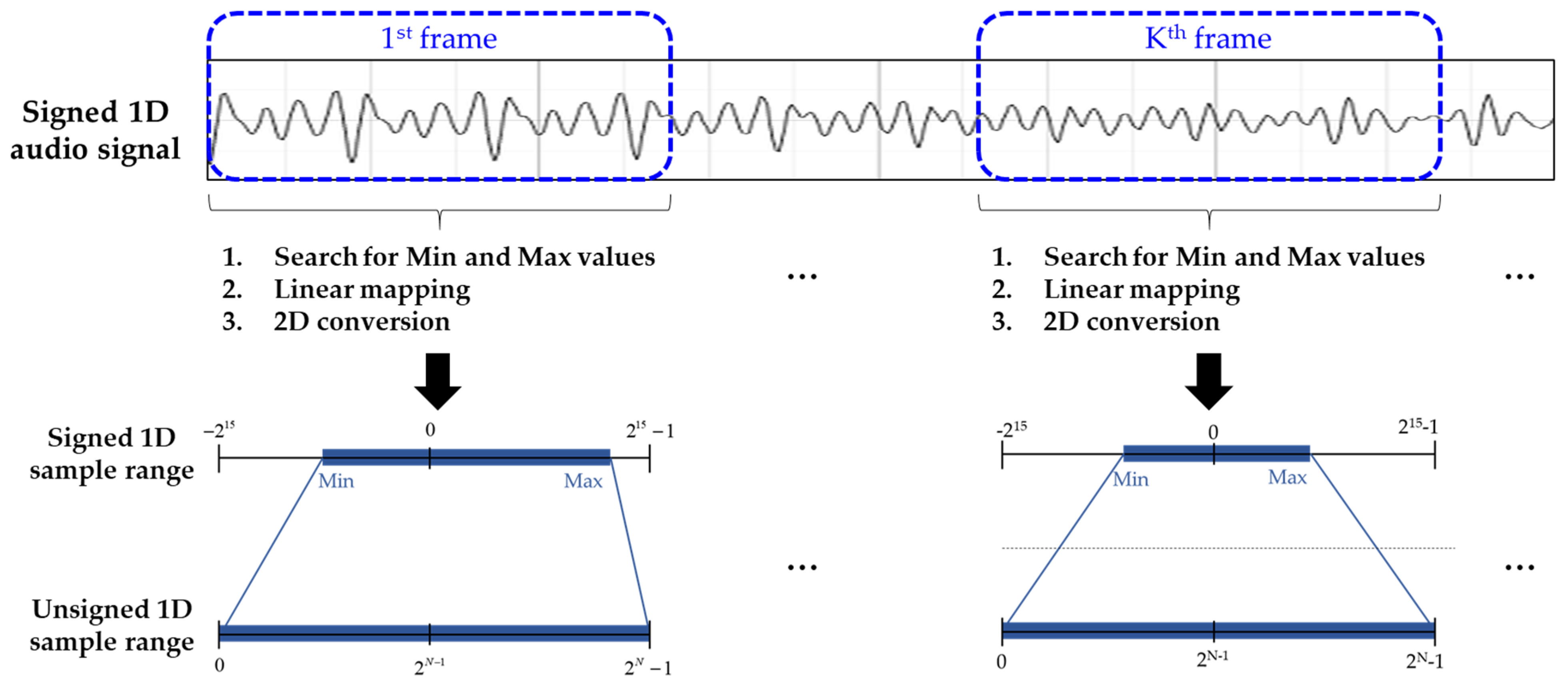
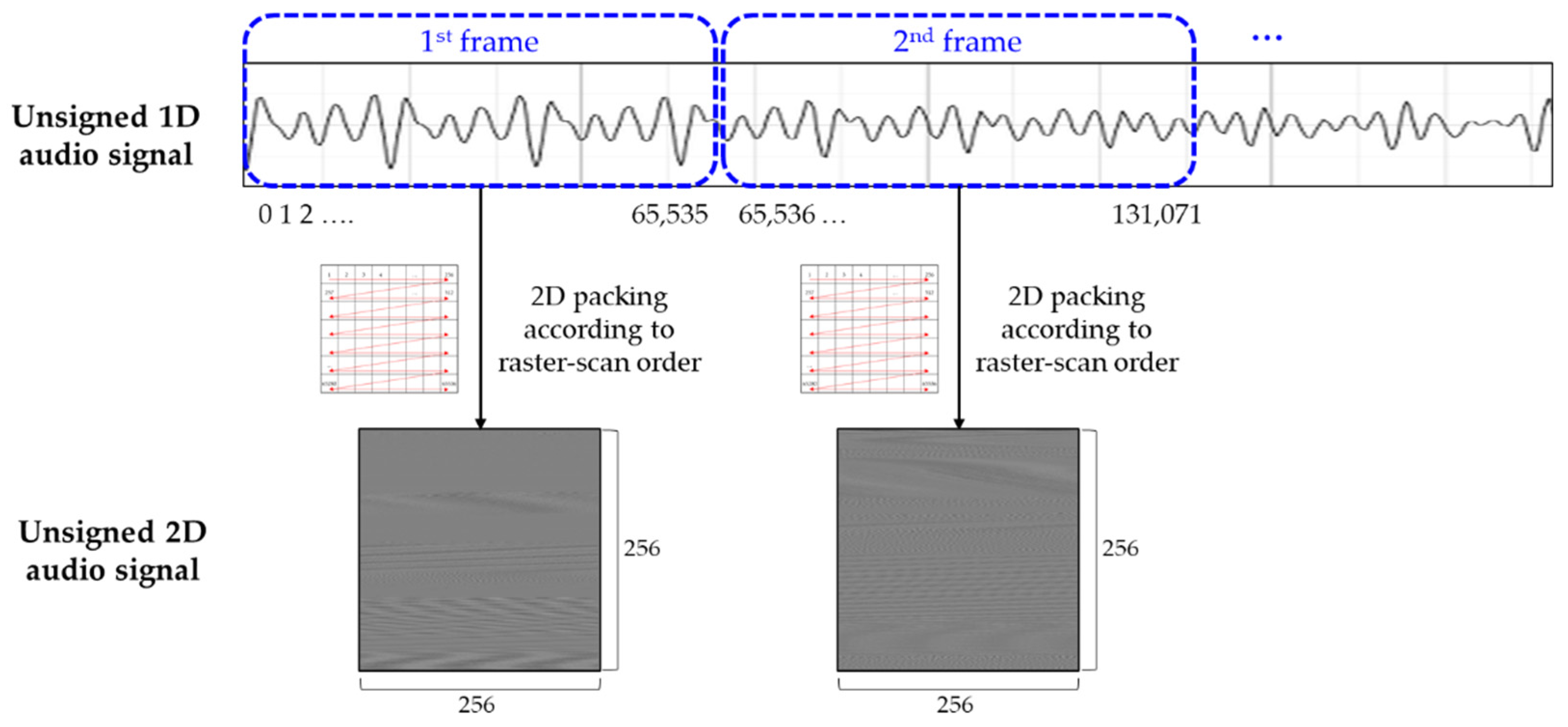
3.1. Overall Frameworks of 2D Audio Coding
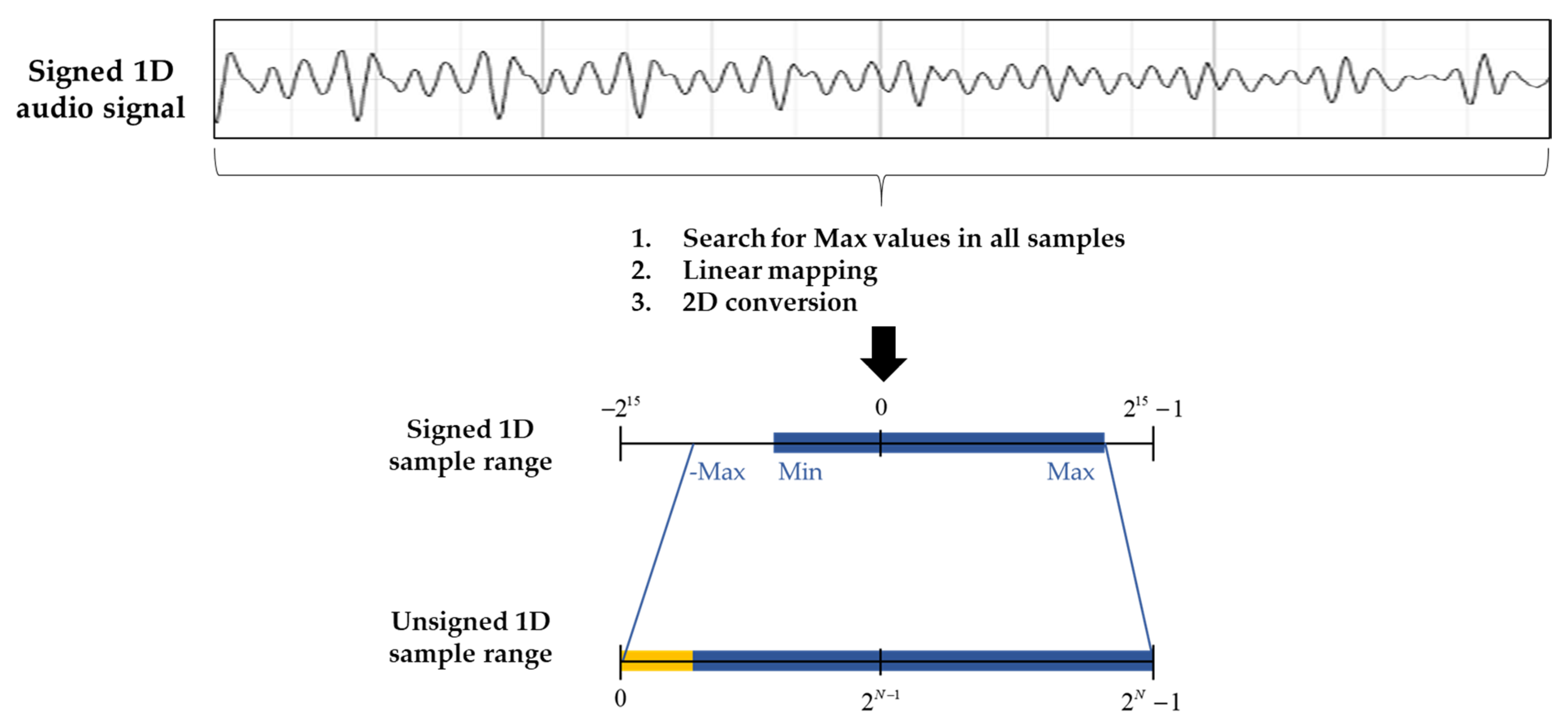
3.2. Proposed 2D Audio Conversion Process
- Non-linear mapping (NLM) to generate unsigned 8 bits per sample;
- Linear mapping (LM) to generate unsigned 10 bits per sample;
- Adaptive linear mapping (ALM) to generate unsigned 10 bits per sample.
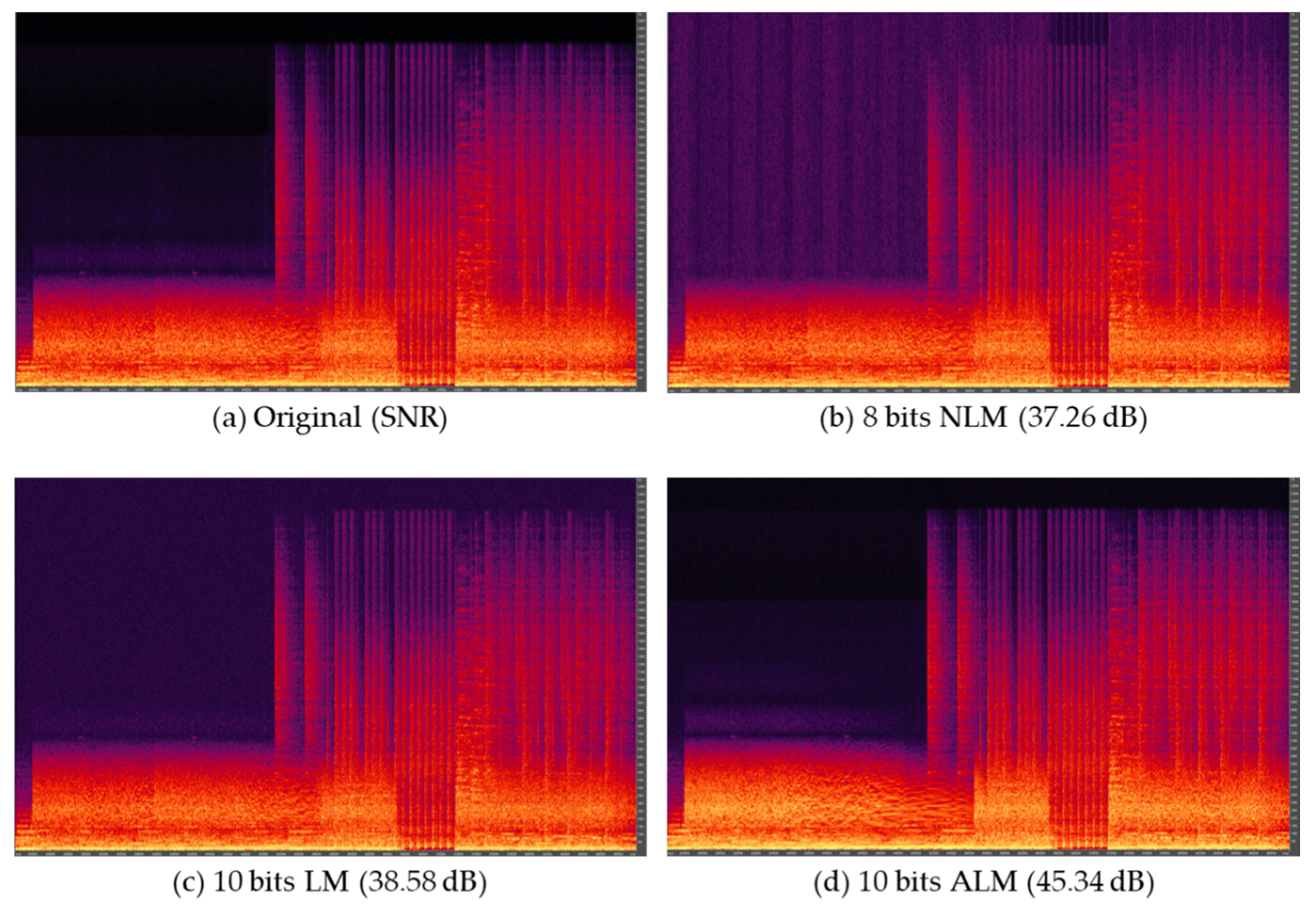
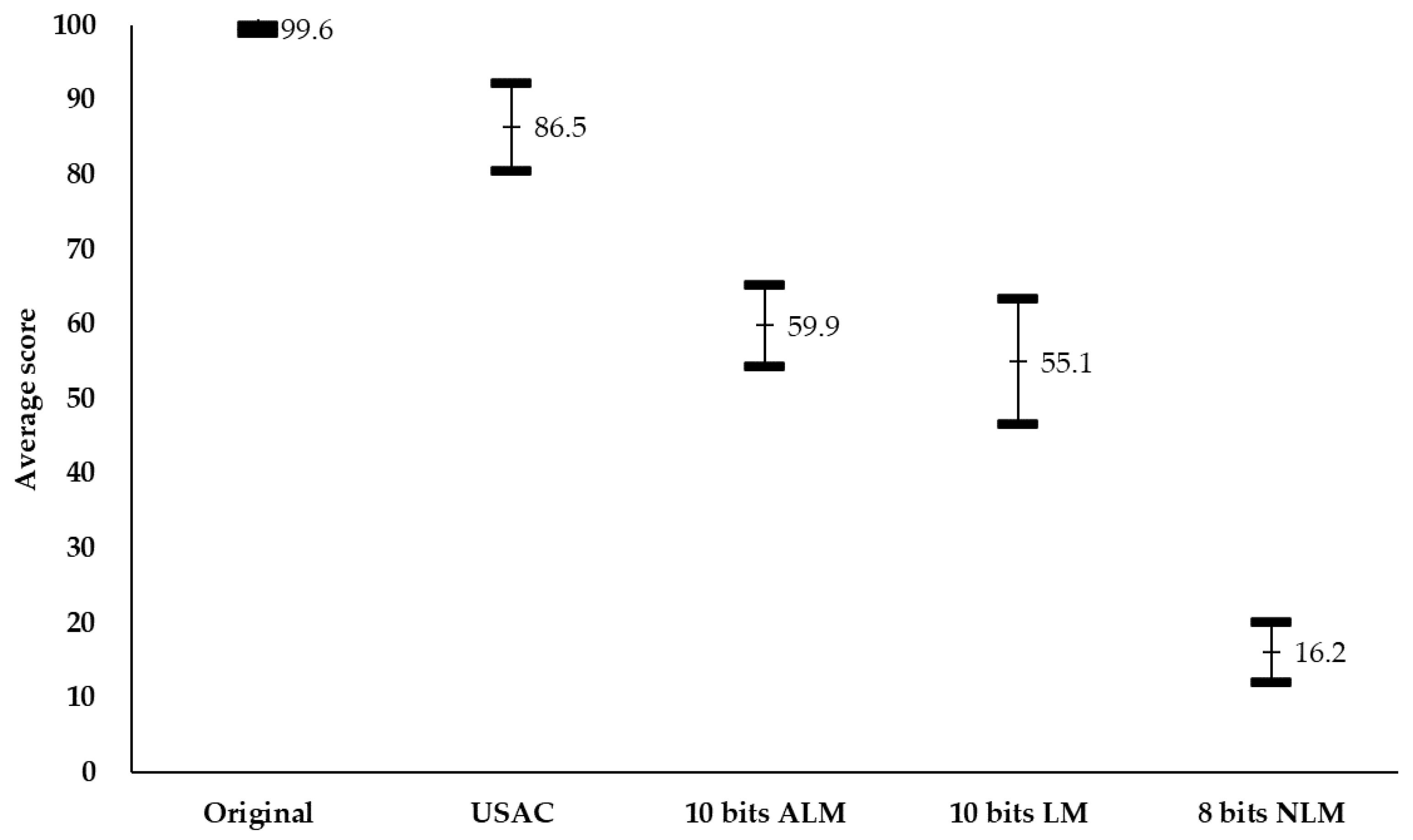
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bross, B.; Chen, J.; Liu, S.; Wang, Y. Versatile Video Coding Editorial Refinements on Draft 10. Available online: https://jvet.hhi.fraunhofer.de/ (accessed on 10 October 2020).
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- ISO/IEC. Information Technology—MPEG Audio Technologies—Part 3: Unified Speech and Audio Coding; International Standard 23003-3; ISO/IEC: Geneva, Switzerland, 2012. [Google Scholar]
- Bossen, F.; Li, X.; Suehring, K. AHG Report: Test Model Software Development (AHG3). In Proceedings of the 20th Meeting Joint Video Experts Team (JVET), Document JVET-T0003, Teleconference (Online), Ljubljana, Slovenia, 10–18 July 2018. [Google Scholar]
- VVC Reference Software (VTM). Available online: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM (accessed on 21 March 2021).
- HEVC Reference Software (HM). Available online: https://vcgit.hhi.fraunhofer.de/jvet/HM (accessed on 21 March 2021).
- Bossen, F.; Boyce, J.; Suehring, K.; Li, X.; Seregin, V. VTM Common Test Conditions and Software Reference Configurations for SDR Video. In Proceedings of the 20th Meeting Joint Video Experts Team (JVET), Document JVET-T2021, Teleconference (Online), 6–15 January 2021. [Google Scholar]
- Auwera, G.; Seregin, V.; Said, A.; Ramasubramonian, A.; Karczewicz, M. CE3: Simplified PDPC (Test 2.4.1). In Proceedings of the 11th Meeting Joint Video Experts Team (JVET), Document JVET-K0063, Ljubljana, Slovenia, 10–18 July 2018. [Google Scholar]
- Ma, X.; Yang, H.; Chen, J. CE3: Tests of Cross-Component Linear Model in BMS. In Proceedings of the 11th Meeting Joint Video Experts Team (JVET), Document JVET-K0190, Ljubljana, Slovenia, 10–18 July 2018. [Google Scholar]
- Racapé, F.; Rath, G.; Urban, F.; Zhao, L.; Liu, S.; Zhao, X.; Li, X.; Filippov, A.; Rufitskiy, V.; Chen, J. CE3-Related: Wide-Angle Intra Prediction for Non-Square Blocks. In Proceedings of the 11th Meeting Joint Video Experts Team (JVET), Document JVET-K0500, Ljubljana, Slovenia, 10–18 July 2018. [Google Scholar]
- Pfaff, J.; Stallenberger, B.; Schäfer, M.; Merkle, P.; Helle, P.; Hinz, T.; Schwarz, H.; Marpe, D.; Wiegand, T. CE3: Affine Linear Weighted Intra Prediction. In Proceedings of the 14th Meeting Joint Video Experts Team (JVET), Document JVET-N0217, Geneva, Switzerland, 19–27 March 2019. [Google Scholar]
- Zhang, H.; Chen, H.; Ma, X.; Yang, H. Performance Analysis of Affine Inter Prediction in JEM 1.0. In Proceedings of the 2nd Meeting Joint Video Experts Team (JVET), Document JVET-B0037, San Diego, CA, USA, 20–26 February 2016. [Google Scholar]
- Gao, H.; Esenlik, S.; Alshina, E.; Kotra, A.; Wang, B.; Liao, R.; Chen, J.; Ye, Y.; Luo, J.; Reuzé, K.; et al. Integrated Text for GEO. In Proceedings of the 17th Meeting Joint Video Experts Team (JVET), Document JVET-Q0806, Brussels, Belgium, 20–26 February 2016. [Google Scholar]
- Jeong, S.; Park, M.; Piao, Y.; Park, M.; Choi, K. CE4 Ultimate Motion Vector Expression. In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Document JVET-L0054, Macao, China, 3–12 October 2018. [Google Scholar]
- Sethuraman, S. CE9: Results of DMVR Related Tests CE9.2.1 and CE9.2.2. In Proceedings of the 13th Meeting Joint Video Experts Team (JVET), Document JVET-M0147, Marrakech, Morocco, 9–18 January 2019. [Google Scholar]
- Chiang, M.; Hsu, C.; Huang, Y.; Lei, S. CE10.1.1: Multi-Hypothesis Prediction for Improving AMVP Mode, Skip or Merge Mode, and Intra Mode. In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Document JVET-L0100, Macao, China, 3–12 October 2018. [Google Scholar]
- Ye, Y.; Chen, J.; Yang, M.; Bordes, P.; François, E.; Chujoh, T.; Ikai, T. AHG13: On Bi-Prediction with Weighted Averaging and Weighted Prediction. In Proceedings of the 13th Meeting Joint Video Experts Team (JVET), Document JVET-M0111, Marrakech, Morocco, 9–18 January 2019. [Google Scholar]
- Zhang, Y.; Chen, C.; Huang, H.; Han, Y.; Chien, W.; Karczewicz, M. Adaptive Motion Vector Resolution Rounding Align. In Proceedings of the 12th Meeting Joint Video Experts Team (JVET), Document JVET-L0377, Macao, China, 3–12 October 2018. [Google Scholar]
- Luo, J.; He, Y. CE4-Related: Simplified Symmetric MVD Based on CE4.4.3. In Proceedings of the 13th Meeting Joint Video Experts Team (JVET), Document JVET-M0444, Marrakech, Morocco, 9–18 January 2019. [Google Scholar]
- Chen, J.; Ye, Y.; Kim, S. Algorithm description for Versatile Video Coding and Test Model 11 (VTM 11). In Proceedings of the 20th Meeting Joint Video Experts Team (JVET), Document JVET-T2002, Teleconference (Online), 10–18 July 2018. [Google Scholar]
- Chien, W.; Boyce, J.; Chen, W.; Chen, Y.; Chernyak, R.; Choi, K.; Hashimoto, R.; Huang, Y.; Jang, H.; Liao, R.; et al. JVET AHG Report: Tool Reporting Procedure (AHG13). In Proceedings of the 20th Meeting Joint Video Experts Team (JVET), Document JVET-T0013, Teleconference (Online), 7–16 October 2020. [Google Scholar]
- Fan, Y.; Sun, H.; Katto, J.; Ming’E, J. A fast QTMT partition decision strategy for VVC intra prediction. IEEE Access 2020, 8, 107900–107911. [Google Scholar] [CrossRef]
- Jin, Z.; An, P.; Yang, C.; Shen, L. Fast QTBT partition algorithm for intra frame coding through convolutional neural network. IEEE Access 2018, 6, 54660–54673. [Google Scholar] [CrossRef]
- Yang, H.; Shen, L.; Dong, X.; Ding, Q.; An, P.; Jiang, G. Low-complexity CTU partition structure decision and fast intra mode decision for versatile video coding. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1668–1682. [Google Scholar] [CrossRef]
- Fast Intra Mode Decision Algorithm for Versatile Video Coding. Available online: https://doi.org/10.1109/TMM.2021.3052348 (accessed on 5 May 2021).
- Park, S.; Kang, J. Fast affine motion estimation for versatile video coding (VVC) encoding. IEEE Access 2019, 7, 158075–158084. [Google Scholar] [CrossRef]
- ITU-T G.711 Pulse Code Modulation (PCM) of Voice Frequencies. Available online: http://handle.itu.int/11.1002/1000/911 (accessed on 21 March 2021).
- International Telecommunication Union. Method for the Subjective Assessment of Intermediate Sound Quality (MUSH-RA). ITU-T, Recommendation BS 1543-1. Available online: https://www.itu.int/pub/R-REC/en (accessed on 1 January 2016).
- Beack, S.; Seong, J.; Lee, M.; Lee, T. Single-Mode-Based Unified Speech and Audio Coding by Extending the Linear Prediction Domain Coding Mode. ETRI J. 2017, 39, 310–318. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | HEVC | VVC |
|---|---|---|
| Intra prediction | 35 Intra-prediction modes | 67 intra-prediction modes |
| Wide angle intra-prediction (WAIP) | ||
| Position-dependent intra-prediction combination (PDPC) | ||
| Matrix-based intra-prediction (MIP) | ||
| Multi reference line prediction (MRL) | ||
| Intra sub-block partitioning (ISP) | ||
| Cross-component linear model (CCLM) | ||
| Skip/Merge | Regular skip/merge | Regular skip/merge |
| Sub-block-based temporal motion vector predictors (SbTMVP) | ||
| Geometric partitioning mode (GPM) | ||
| Merge with motion vector difference (MMVD) | ||
| Decoder-side motion vector refinement (DMVR) | ||
| Bi-directional optical flow (BDOF) | ||
| Combined inter- and intra-prediction (CIIP) | ||
| Inter prediction | Advanced motion vector prediction (AMVP) | Advanced motion vector prediction (AMVP) |
| Symmetric motion vector difference (SMVD) | ||
| Affine inter-prediction | ||
| Adaptive motion vector resolution (AMVR) | ||
| Bi-prediction with CU-level weight (BCW) |
| Category | Item Name | Description |
|---|---|---|
| Music | salvation | Classical chorus music |
| te15 | Classical music | |
| Music_1 | Rock music | |
| Music_3 | Pop music | |
| phi7 | Classical music | |
| Speech | es01 | English speech |
| louis_raquin_15 | French speech | |
| Wedding_speech | Korean speech | |
| te1_mg54_speech | German speech | |
| Arirang_speech | Korean speech | |
| Mixed | twinkle_ff51 | Speech with pop music |
| SpeechOverMusic_1 | Speech with chorus music | |
| SpeechOverMusic_4 | Speech with pop music | |
| HarryPotter | Speech with background music | |
| lion | Speech with background music |
| 8 bits NLM | 10 bits LM | 10 bits ALM | |
|---|---|---|---|
| Input bit-depth | 8 bits | 10 bits | 10 bits |
| VTM version | VTM10.0 | ||
| Chroma format | YUV4:0:0 | ||
| Encoding mode | All-intra, Low-delay-B, Random-access | ||
| Target bps | 0.5 and 1.0 | ||
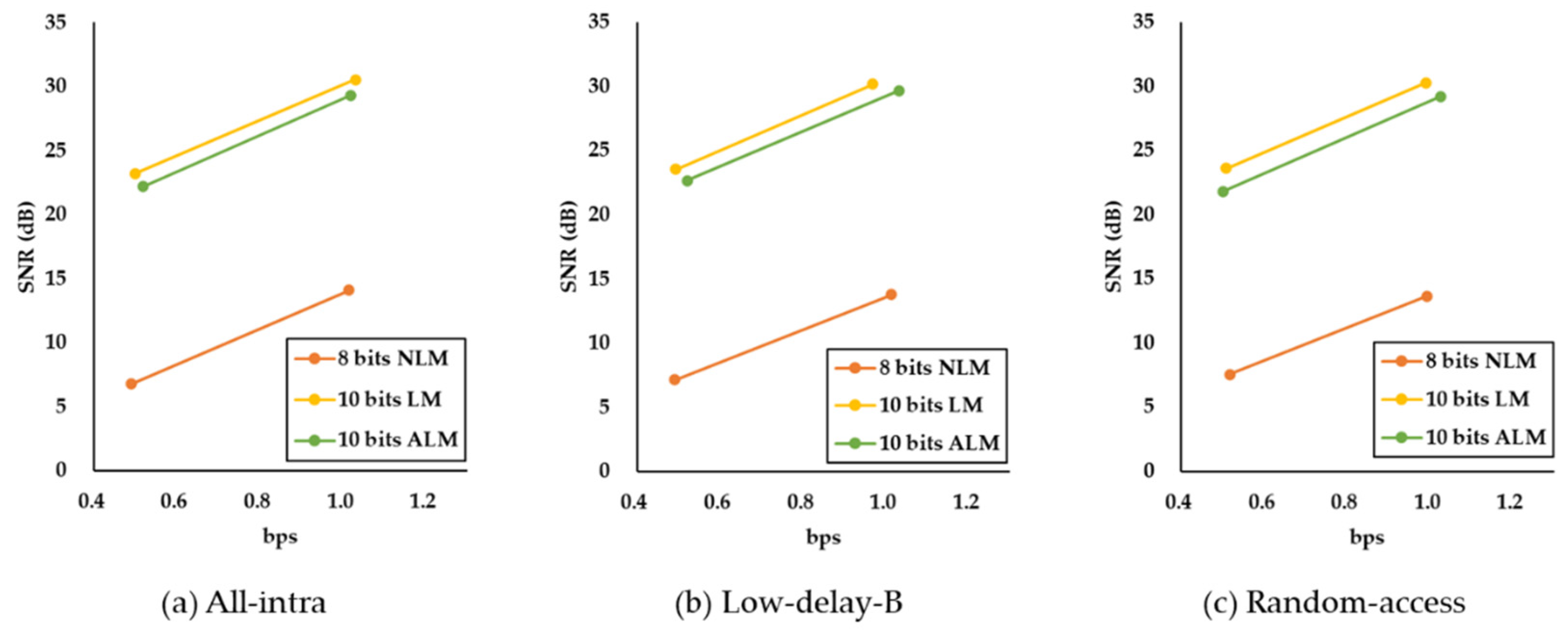
| Encoding Mode | Target bps | 8 bits NLM | 10 bits LM | 10 bits ALM | |||
|---|---|---|---|---|---|---|---|
| SNR (dB) | bps | SNR (dB) | bps | SNR (dB) | bps | ||
| All-intra | 1.0 | 14.09 | 1.01 | 30.55 | 1.03 | 29.30 | 1.02 |
| 0.5 | 6.78 | 0.49 | 23.21 | 0.50 | 22.18 | 0.52 | |
| Low-delay-B | 1.0 | 13.78 | 1.01 | 30.17 | 0.97 | 29.66 | 1.03 |
| 0.5 | 7.15 | 0.49 | 23.55 | 0.49 | 22.64 | 0.52 | |
| Random-access | 1.0 | 13.63 | 0.99 | 30.28 | 0.99 | 29.21 | 1.03 |
| 0.5 | 7.55 | 0.52 | 23.62 | 0.51 | 21.82 | 0.50 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Jun, D.; Kim, B.-G.; Beack, S.; Lee, M.; Lee, T. Two-Dimensional Audio Compression Method Using Video Coding Schemes. Electronics 2021, 10, 1094. https://doi.org/10.3390/electronics10091094
Kim S, Jun D, Kim B-G, Beack S, Lee M, Lee T. Two-Dimensional Audio Compression Method Using Video Coding Schemes. Electronics. 2021; 10(9):1094. https://doi.org/10.3390/electronics10091094
Chicago/Turabian StyleKim, Seonjae, Dongsan Jun, Byung-Gyu Kim, Seungkwon Beack, Misuk Lee, and Taejin Lee. 2021. "Two-Dimensional Audio Compression Method Using Video Coding Schemes" Electronics 10, no. 9: 1094. https://doi.org/10.3390/electronics10091094
APA StyleKim, S., Jun, D., Kim, B. -G., Beack, S., Lee, M., & Lee, T. (2021). Two-Dimensional Audio Compression Method Using Video Coding Schemes. Electronics, 10(9), 1094. https://doi.org/10.3390/electronics10091094