
A Multi-Domain Embedding Framework for Robust Reversible Data Hiding Scheme in Encrypted Videos


Abstract
:1. Introduction
- The proposed framework for RDH-EV can achieve both robustness and reversibility.
- In terms of robustness, the proposed scheme outperforms the existing ones.
- Video encryption and data hiding in the proposed scheme are commutative.
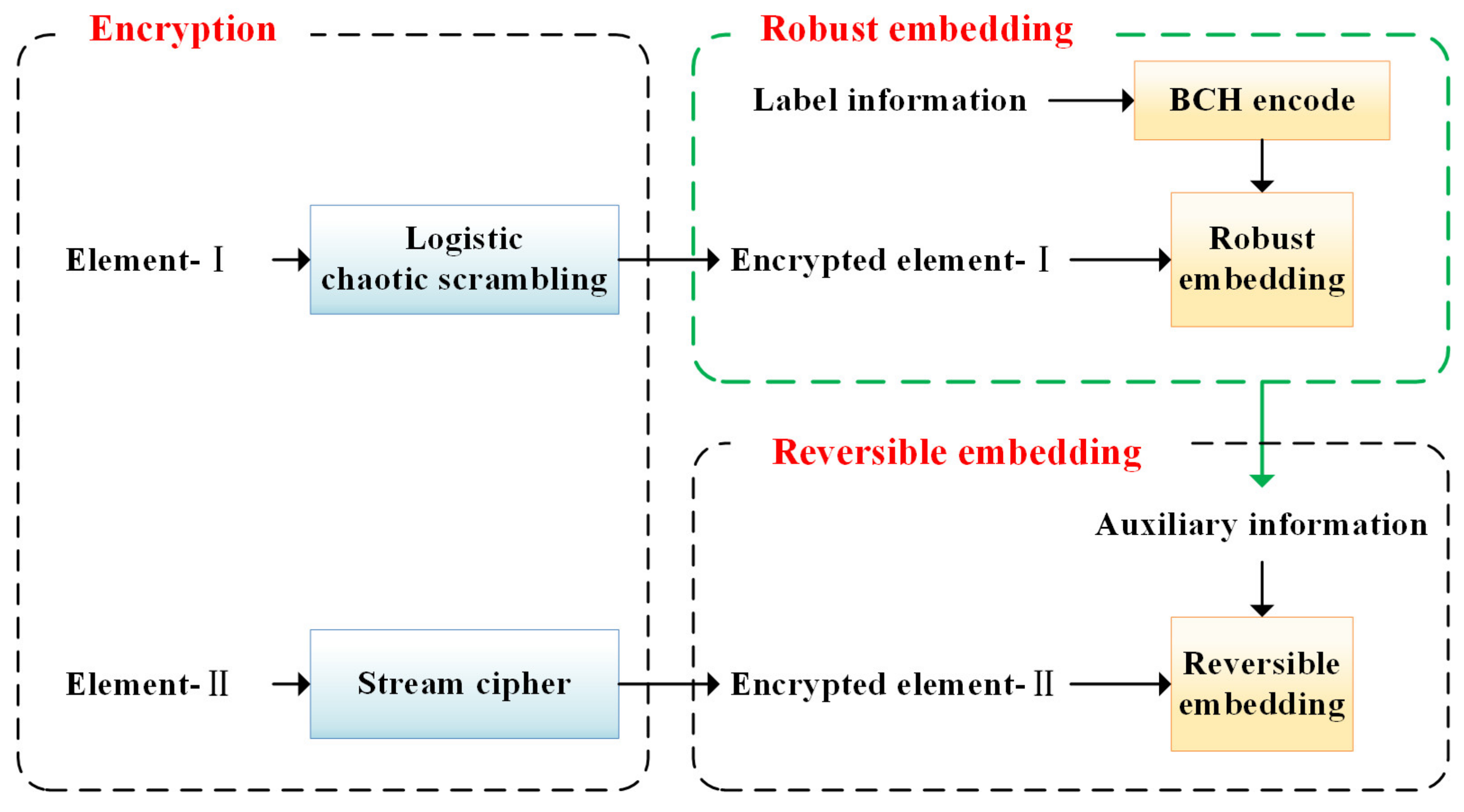
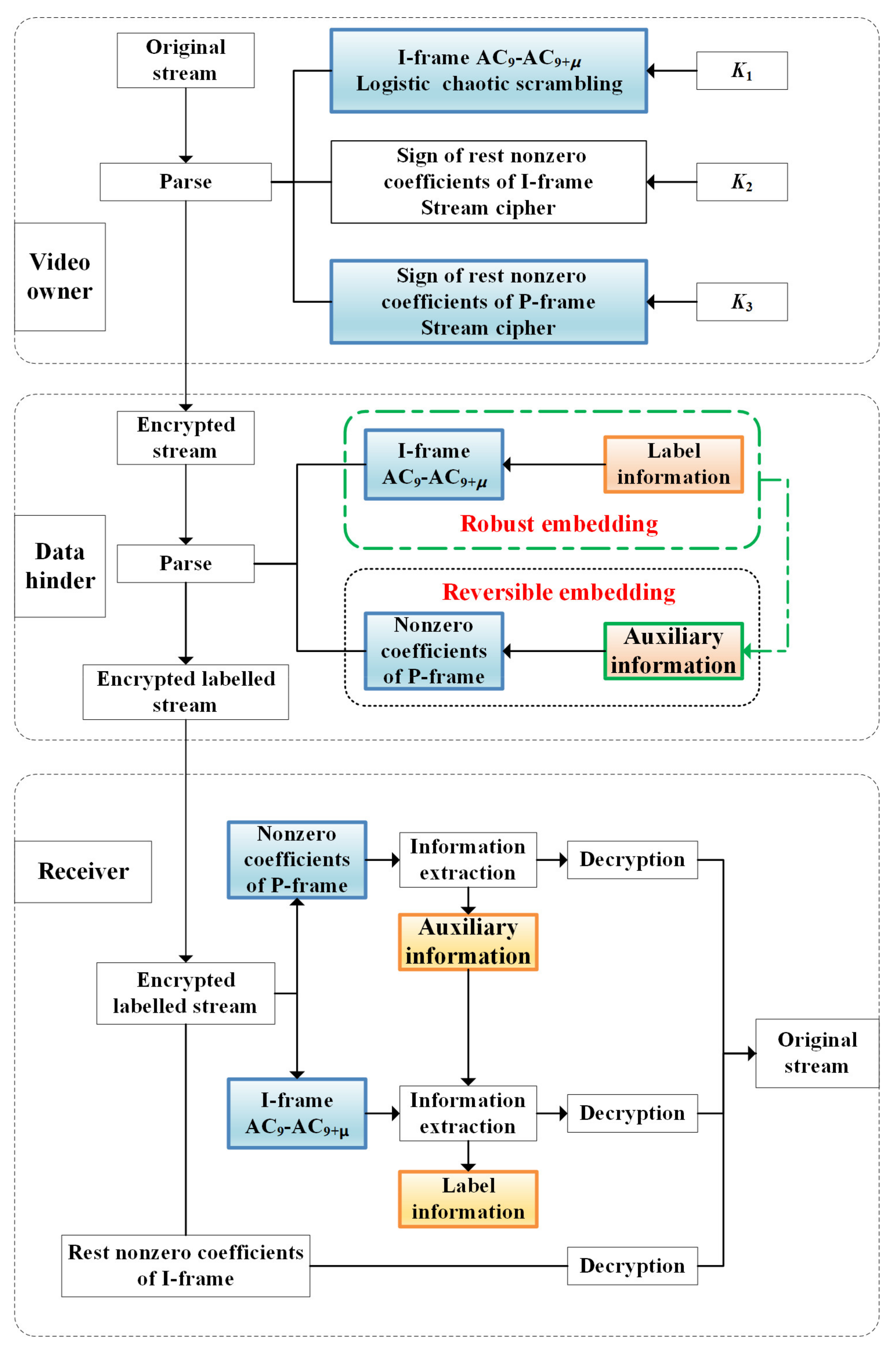
2. Proposed Framework and Scheme
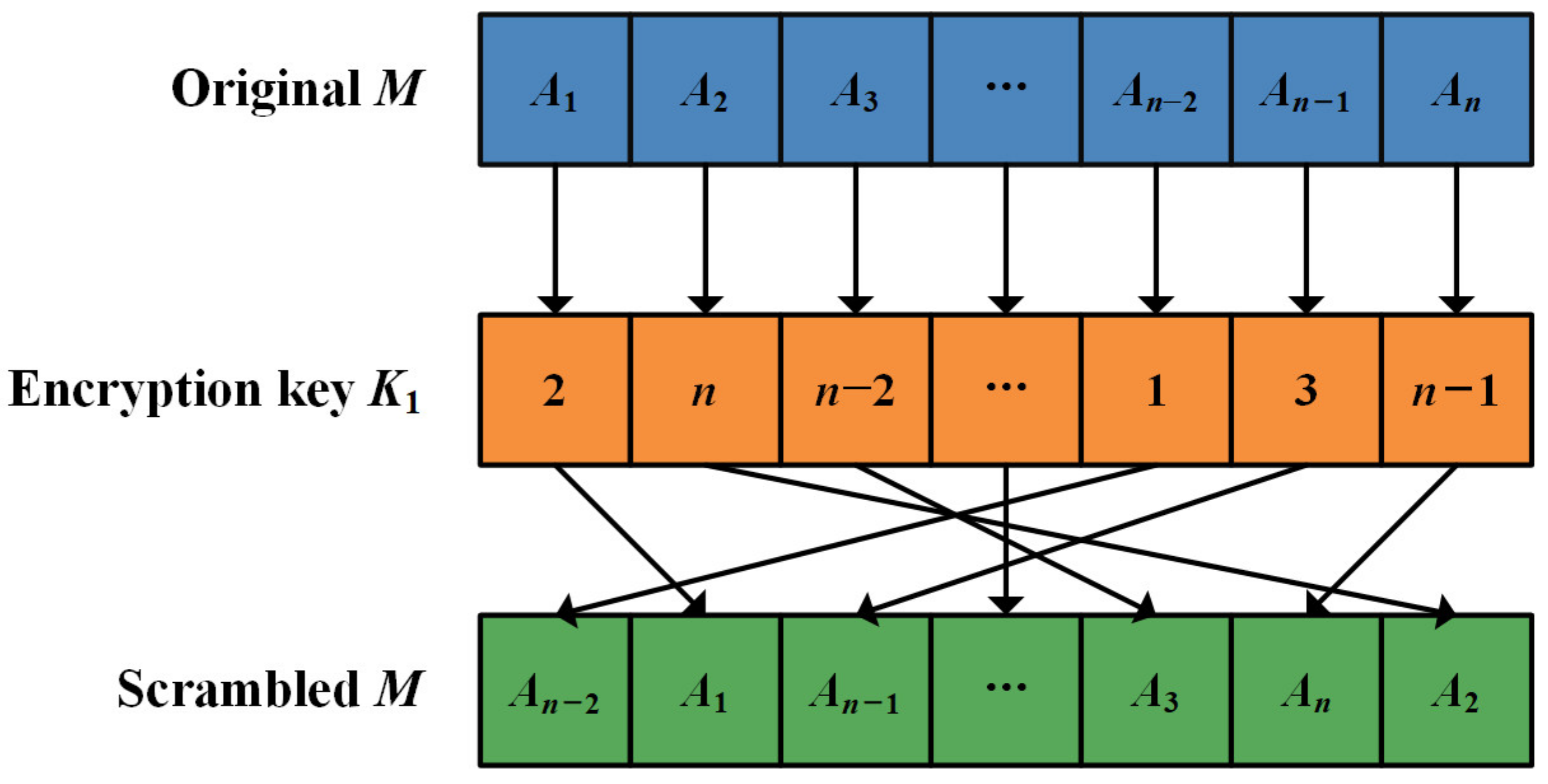
2.1. Video Encryption
2.2. Data Embedding in Encrypted Videos
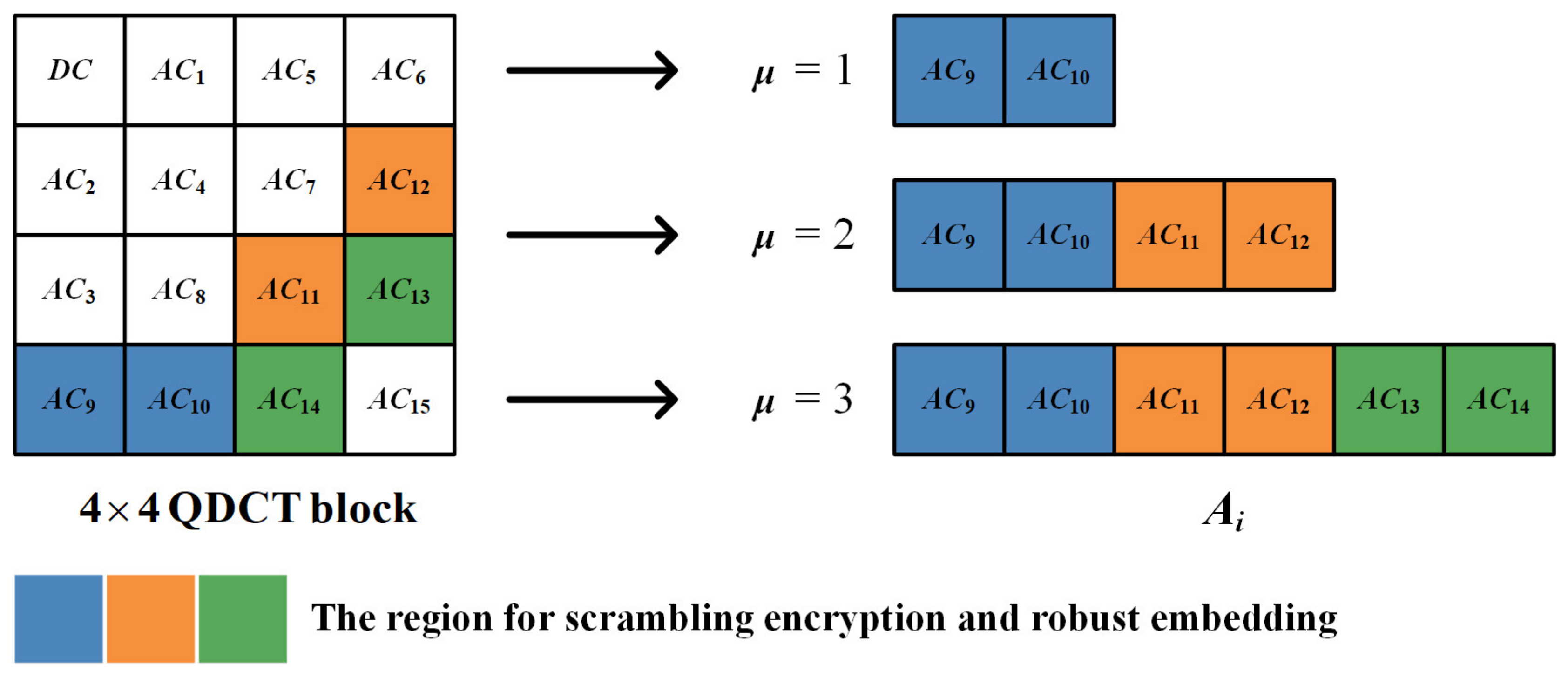
- Element selection
- 2.
- Robust embedding in I-frame
- 3.
- Reversible embedding in P-frame
- 4.
- Multi-domain embedding process
2.3. Information Extraction and Video Recovery
- There are two steps to information extraction:
- 2.
- Video recovery is divided into the following two cases:
3. Experimental Results with Analysis
3.1. Experimental Settings
- Video sequences
- 2.
- Experimental runtime environment and parameter setting
- 3.
- Representative methods used for comparison
- 4.
- Objective evaluation metrics
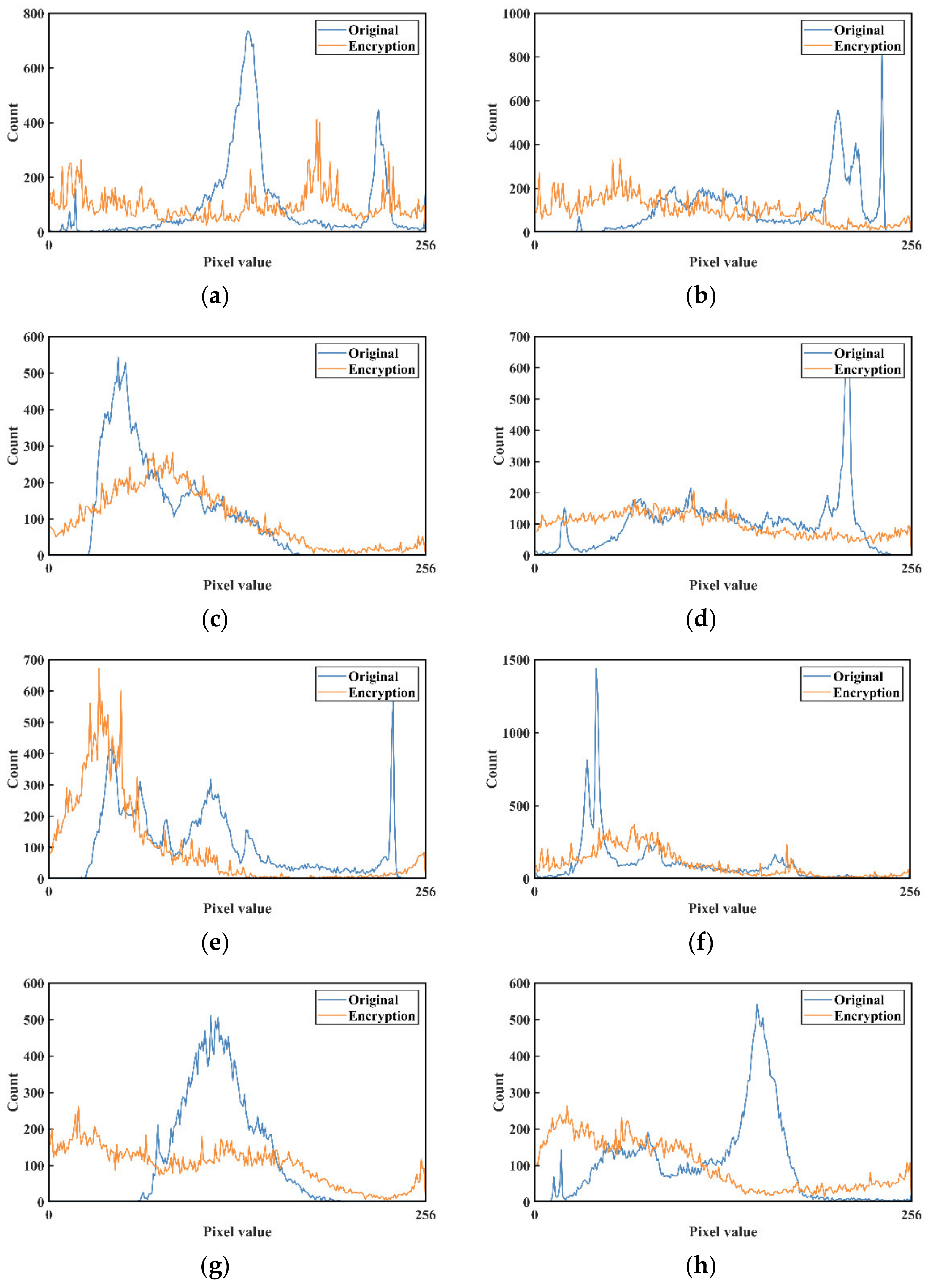
3.2. Security Analysis of Encrypted Video
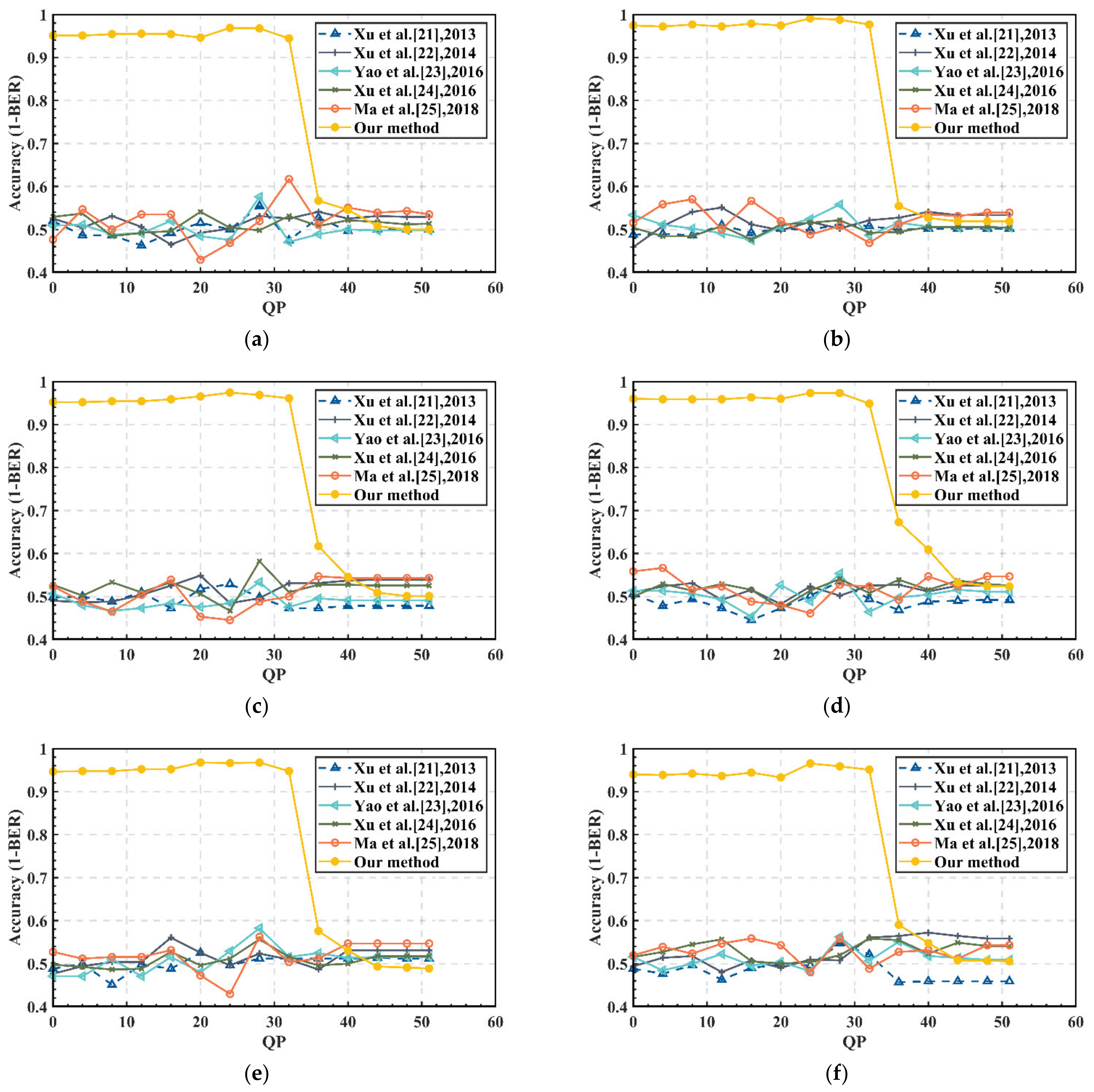
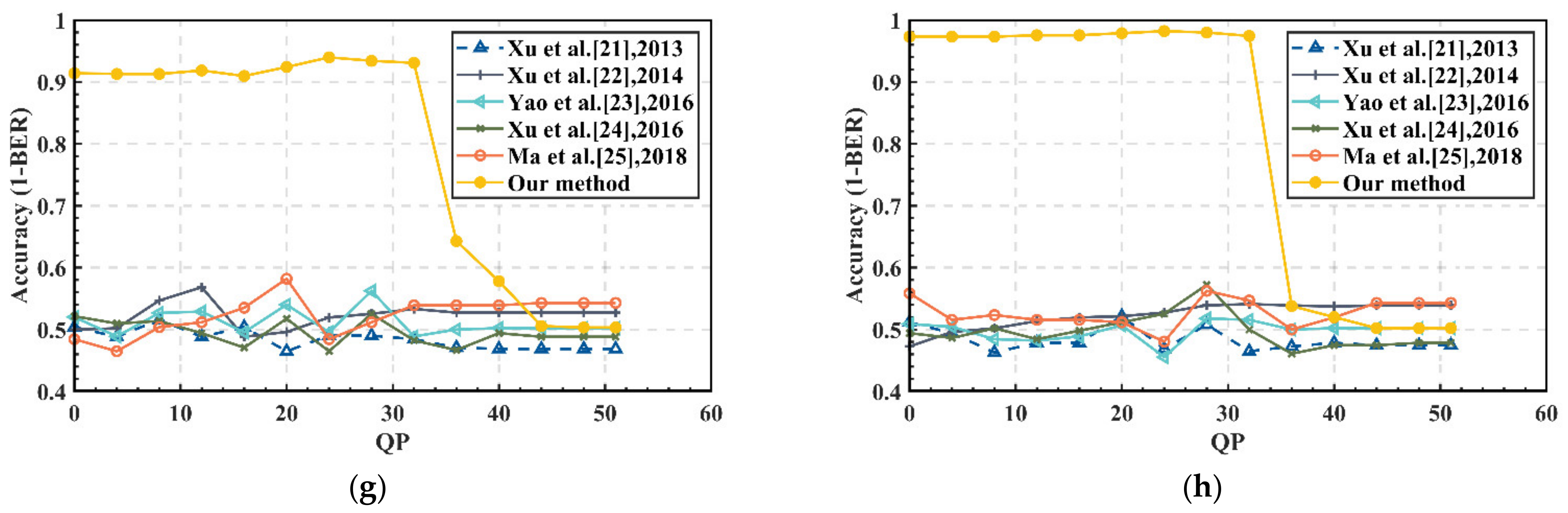
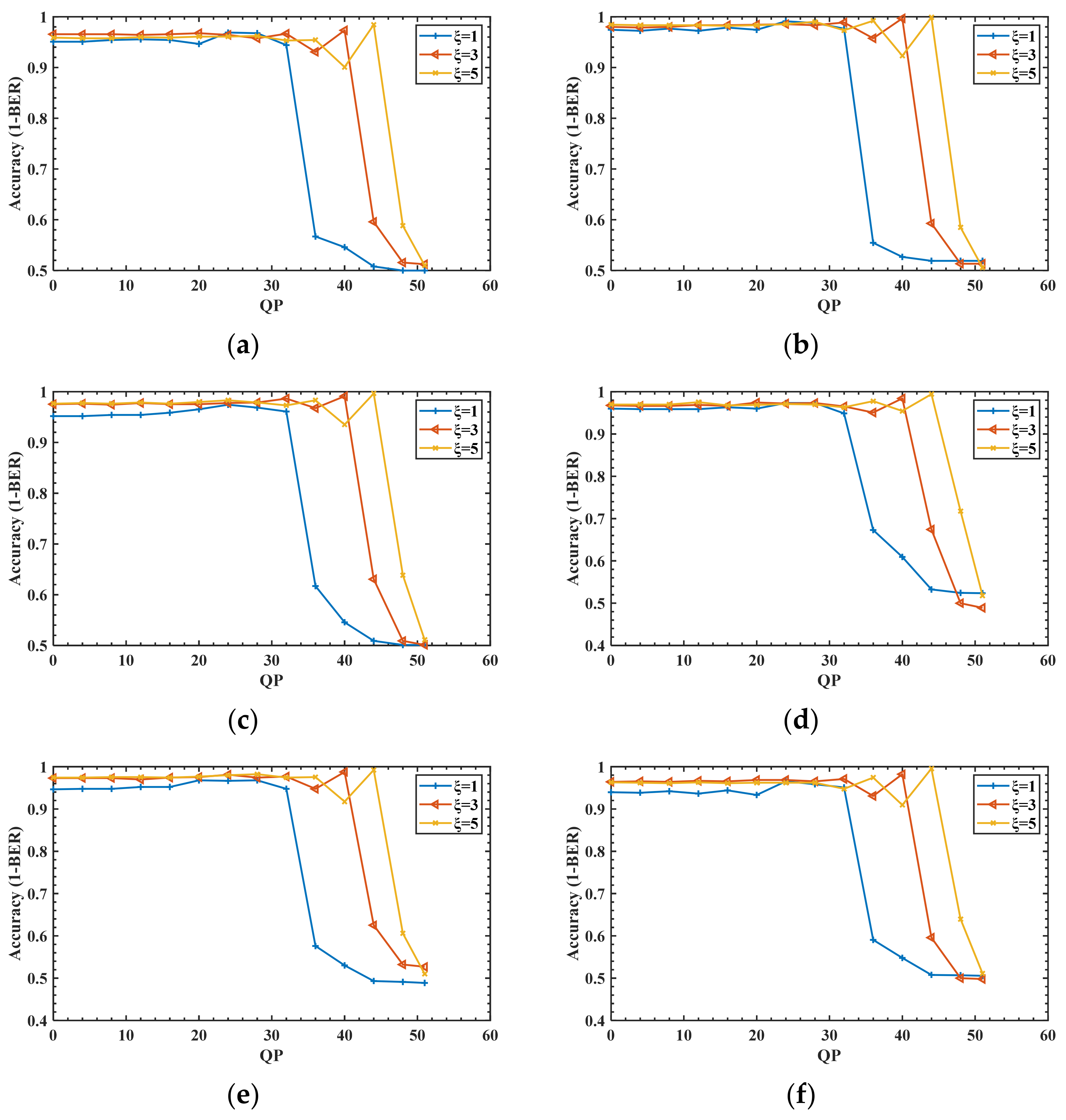
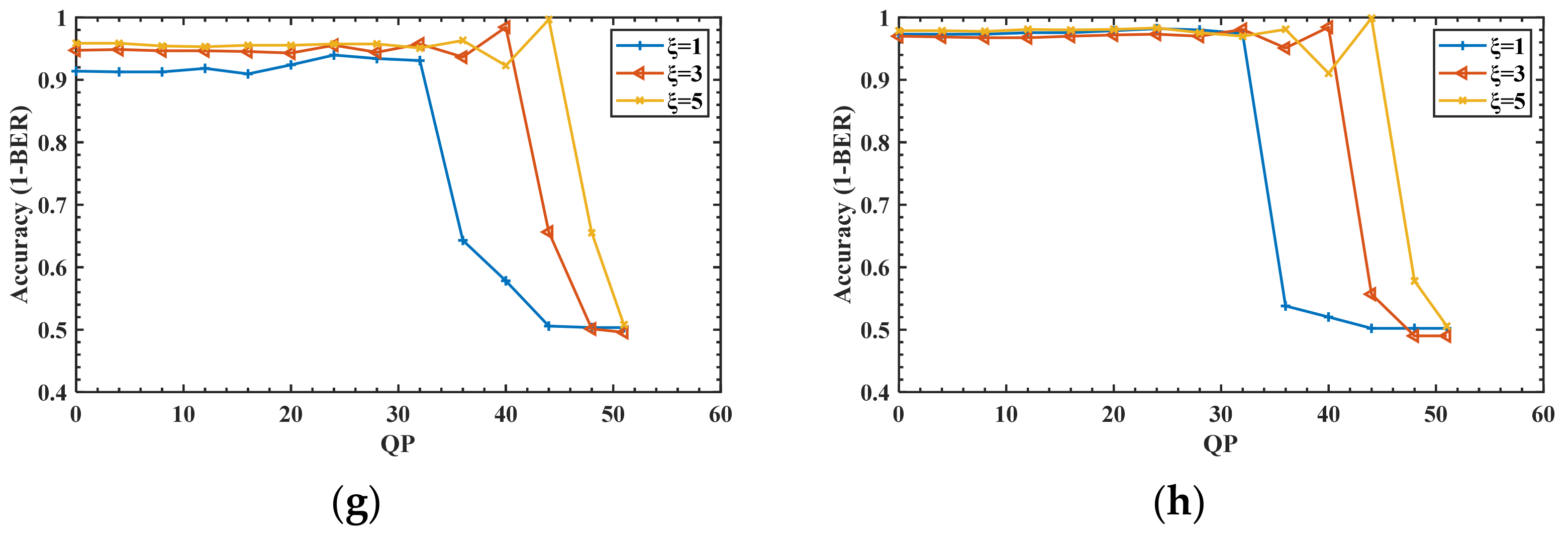
3.3. Robustness Analysis
3.4. Embedding Capacity
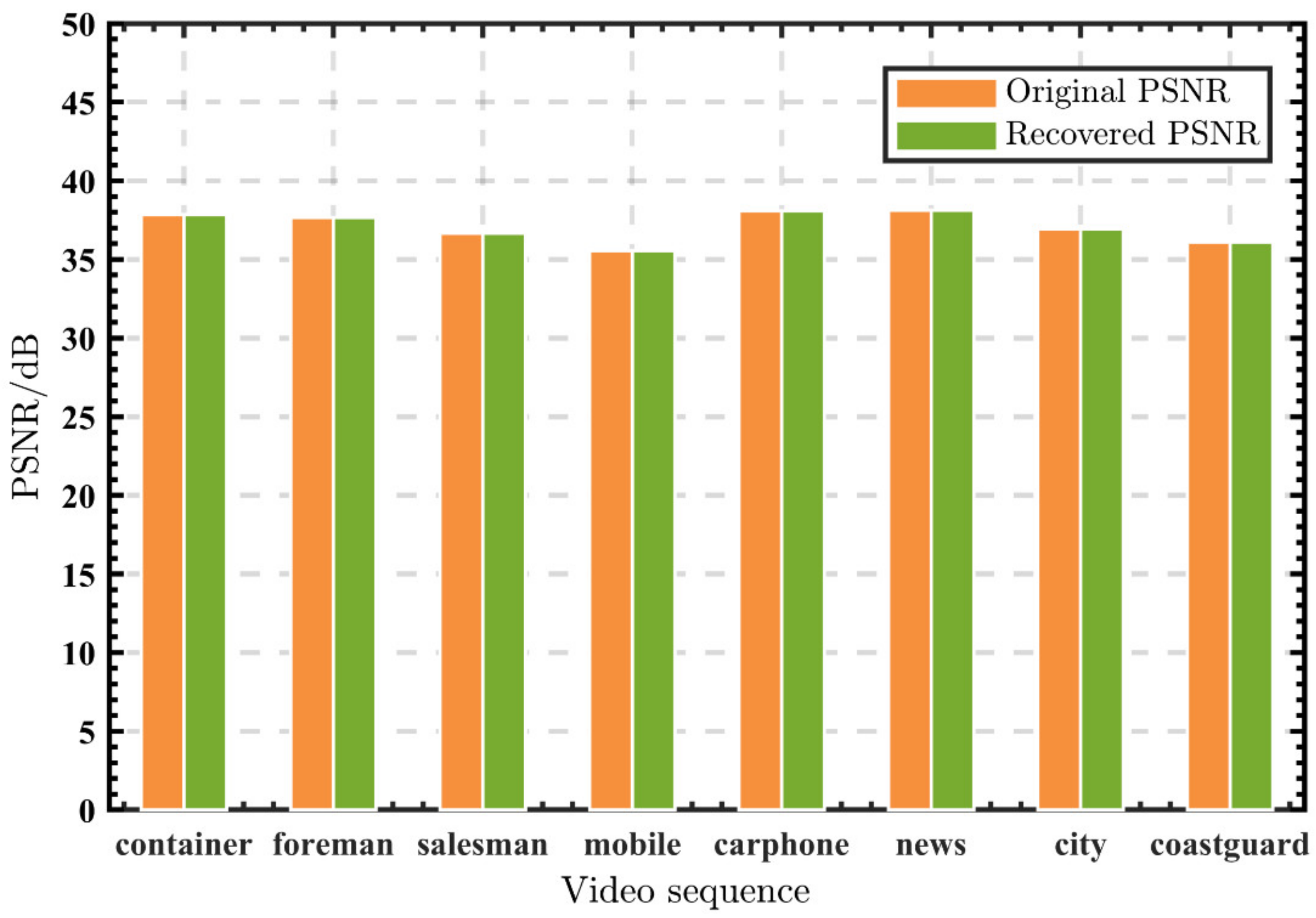
3.5. Visual Quality of the Decrypted Labeled Video
3.6. Bit Rate Variation Analysis
3.7. Reversibility Analysis
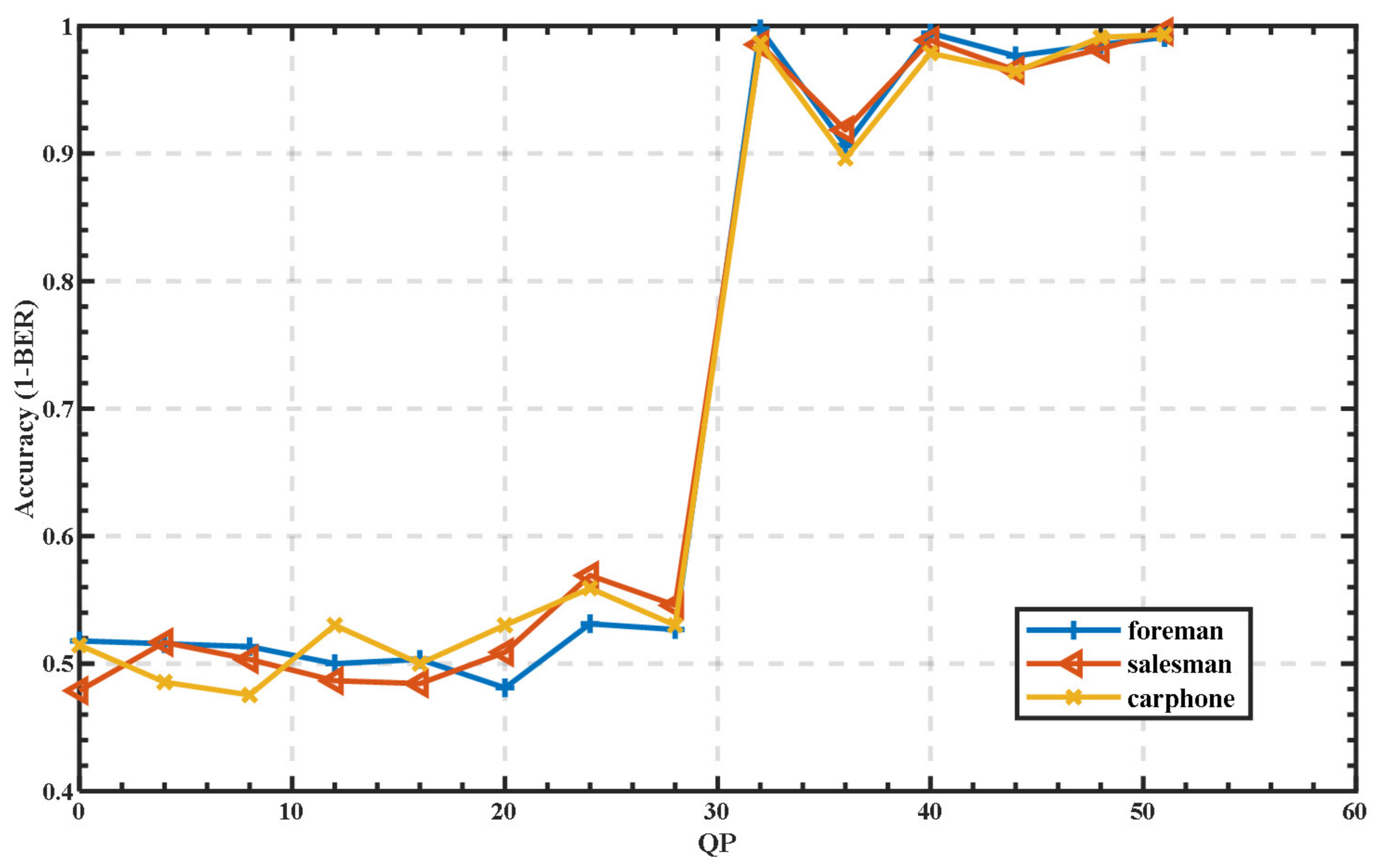
3.8. Qualitative Analysis
3.9. Further Discussion
- Coefficient selection for scrambling and embedding
- 2.
- Element selection for robust embedding
- 3.
- Robust embedding algorithm
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mansour, R.F.; Parah, S.A. Reversible Data Hiding for Electronic Patient Information Security for Telemedicine Applications. Arab. J. Sci. Eng. 2021, 46, 9129–9144. [Google Scholar] [CrossRef]
- Zhang, X. Reversible Data Hiding in Encrypted Image. IEEE Signal Processing Lett. 2011, 18, 255–258. [Google Scholar] [CrossRef]
- Yin, Z.; Peng, Y.; Xiang, Y. Reversible Data Hiding in Encrypted Images Based on Pixel Prediction and Bit-Plane Compression. IEEE Trans. Dependable Secur. Comput. 2022, 19, 992–1002. [Google Scholar] [CrossRef]
- Kong, W.; Miao, Q.; Liu, R.; Lei, Y.; Cui, J.; Xie, Q. Multimodal Medical Image Fusion Using Gradient Domain Guided Filter Random Walk and Side Window Filtering in Framelet Domain. Inf. Sci. 2022, 585, 418–440. [Google Scholar] [CrossRef]
- Balasamy, K.; Suganyadevi, S. A Fuzzy Based ROI Selection for Encryption and Watermarking in Medical Image Using DWT and SVD. Multim. Tools Appl. 2021, 80, 7167–7186. [Google Scholar] [CrossRef]
- Xu, D. Commutative Encryption and Data Hiding in HEVC Video Compression. IEEE Access 2019, 7, 66028–66041. [Google Scholar] [CrossRef]
- Guan, B.; Xu, D.; Li, Q. An Efficient Commutative Encryption and Data Hiding Scheme for HEVC Video. IEEE Access 2020, 8, 60232–60245. [Google Scholar] [CrossRef]
- Xu, D.; Guan, B. An Improved Commutative Encryption and Data Hiding Scheme for HEVC Video. Multim. Tools Appl. 2022, 81, 18105–18127. [Google Scholar] [CrossRef]
- Zhang, X. Separable Reversible Data Hiding in Encrypted Image. IEEE Trans. Inf. Forensics Secur. 2012, 7, 826–832. [Google Scholar] [CrossRef]
- Wang, X.; Chang, C.-C.; Lin, C.-C.; Chang, C.-C. Reversal of Pixel Rotation: A Reversible Data Hiding System towards Cybersecurity in Encrypted Images. J. Vis. Commun. Image Represent. 2022, 82, 103421. [Google Scholar] [CrossRef]
- Yu, C.; Zhang, X.; Li, G.; Zhan, S.; Tang, Z. Reversible Data Hiding with Adaptive Difference Recovery for Encrypted Images. Inf. Sci. 2022, 584, 89–110. [Google Scholar] [CrossRef]
- Qin, C.; Zhang, X. Effective Reversible Data Hiding in Encrypted Image with Privacy Protection for Image Content. J. Vis. Commun. Image Represent. 2015, 31, 154–164. [Google Scholar] [CrossRef]
- Yin, Z.; Xiang, Y.; Zhang, X. Reversible Data Hiding in Encrypted Images Based on Multi-MSB Prediction and Huffman Coding. IEEE Trans. Multim. 2020, 22, 874–884. [Google Scholar] [CrossRef]
- Yin, Z.; She, X.; Tang, J.; Luo, B. Reversible Data Hiding in Encrypted Images Based on Pixel Prediction and Multi-MSB Planes Rearrangement. Signal Processing 2021, 187, 108146. [Google Scholar] [CrossRef]
- Huang, D.; Wang, J. High-Capacity Reversible Data Hiding in Encrypted Image Based on Specific Encryption Process. Signal Processing Image Commun. 2020, 80, 115632. [Google Scholar] [CrossRef]
- Ke, Y.; Zhang, M.-Q.; Liu, J.; Su, T.; Yang, X. Fully Homomorphic Encryption Encapsulated Difference Expansion for Reversible Data Hiding in Encrypted Domain. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2353–2365. [Google Scholar] [CrossRef]
- Ke, Y.; Zhang, M.; Zhang, X.; Liu, J.; Su, T.; Yang, X. A Reversible Data Hiding Scheme in Encrypted Domain for Secret Image Sharing Based on Chinese Remainder Theorem. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2469–2481. [Google Scholar] [CrossRef]
- Lian, S.; Liu, Z.; Ren, Z.; Wang, H. Commutative Encryption and Watermarking in Video Compression. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 774–778. [Google Scholar] [CrossRef]
- Xu, D.; Wang, R.; Shi, Y.Q. Data Hiding in Encrypted H.264/AVC Video Streams by Codeword Substitution. IEEE Trans. Inf. Forensics Secur. 2014, 9, 596–606. [Google Scholar] [CrossRef]
- Xu, D.; Wang, R.; Shi, Y.Q. An Improved Scheme for Data Hiding in Encrypted H.264/AVC Videos. J. Vis. Commun. Image Represent. 2016, 36, 229–242. [Google Scholar] [CrossRef]
- Xu, D.; Wang, R.; Shi, Y.-Q. Reversible Data Hiding in Encrypted H.264/AVC Video Streams. In Proceedings of the Digital-Forensics and Watermarking—12th International Workshop, IWDW 2013, Auckland, New Zealand, 1–4 October 2013; Revised Selected Papers; Shi, Y.-Q., Kim, H.-J., Pérez-González, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8389, pp. 141–152. [Google Scholar]
- Xu, D.; Wang, R. Efficient Reversible Data Hiding in Encrypted H.264/AVC Videos. J. Electron. Imaging 2014, 23, 053022. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, W.; Yu, N. Inter-Frame Distortion Drift Analysis for Reversible Data Hiding in Encrypted H.264/AVC Video Bitstreams. Signal Processing 2016, 128, 531–545. [Google Scholar] [CrossRef]
- Xu, D.; Zhu, Y.; Wang, R.; Fu, J.; Chen, K. Two-Dimensional Histogram Modification for Reversible Data Hiding in Partially Encrypted H.264/AVC Videos. In Proceedings of the Digital Forensics and Watermarking—15th International Workshop, IWDW 2016, Beijing, China, 17–19 September 2016; Revised Selected Papers; Shi, Y.-Q., Kim, H.-J., Pérez-González, F., Liu, F., Eds.; Springer: Cham, Switzerland, 2016; Volume 10082, pp. 393–406. [Google Scholar]
- Long, M.; Peng, F.; Li, H. Separable Reversible Data Hiding and Encryption for HEVC Video. J. Real Time Image Processing 2018, 14, 171–182. [Google Scholar] [CrossRef]
- Wang, X.; Li, X.; Pei, Q. Independent Embedding Domain Based Two-Stage Robust Reversible Watermarking. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2406–2417. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, M.; Ma, X.; Zhao, H. A New Robust Data Hiding Method for H.264/AVC without Intra-Frame Distortion Drift. Neurocomputing 2015, 151, 1076–1085. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Ma, X.; Liu, J. A Robust without Intra-Frame Distortion Drift Data Hiding Algorithm Based on H.264/AVC. Multim. Tools Appl. 2014, 72, 613–636. [Google Scholar] [CrossRef]
- Dolati, N.; Shirazi, A.A.B.; Azadegan, H. A Selective Encryption for H.264/AVC Videos Based on Scrambling. Multim. Tools Appl. 2021, 80, 2319–2338. [Google Scholar] [CrossRef]
- He, J.; Xu, Y.; Luo, W.; Tang, S.; Huang, J. A Novel Selective Encryption Scheme for H.264/AVC Video with Improved Visual Security. Signal Process. Image Commun. 2020, 89, 115994. [Google Scholar] [CrossRef]
- YUV Video Sequences. Available online: http://trace.eas.asu.edu/yuv/index.html (accessed on 26 June 2022).
- H.264 Baseline Codec. Available online: https://ww2.mathworks.cn/matlabcentral/fileexchange/39927-h-264-baseline-codec (accessed on 26 June 2022).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Sequence | QP | PSNR/dB | SSIM |
|---|---|---|---|
| container | 24 | 4.6496 | 0.1155 |
| 28 | 5.4236 | 0.1430 | |
| 32 | 8.7477 | 0.0689 | |
| foreman | 24 | 5.9519 | 0.0065 |
| 28 | 6.9626 | 0.0280 | |
| 32 | 10.1921 | 0.2689 | |
| salesman | 24 | 12.2562 | 0.0239 |
| 28 | 13.8443 | 0.2343 | |
| 32 | 12.3003 | 0.1822 | |
| mobile | 24 | 5.6959 | 0.0293 |
| 28 | 5.9292 | 0.1186 | |
| 32 | 3.5338 | 0.0637 | |
| carphone | 24 | 8.2273 | 0.0769 |
| 28 | 8.8277 | 0.0030 | |
| 32 | 8.2801 | 0.1087 | |
| news | 24 | 10.1027 | 0.0361 |
| 28 | 10.3231 | 0.1732 | |
| 32 | 11.3371 | 0.2230 | |
| city | 24 | 9.8430 | 0.0578 |
| 28 | 9.4672 | 0.0079 | |
| 32 | 11.8376 | 0.1018 | |
| coastguard | 24 | 8.2926 | 0.2086 |
| 28 | 6.8150 | 0.0350 | |
| 32 | 3.4344 | 0.1214 |
| Video Sequence | ξ | Accuracy (1-BER) | ||||||
|---|---|---|---|---|---|---|---|---|
| QP = 16 | QP = 20 | QP = 24 | QP = 28 | QP = 32 | QP = 36 | QP = 40 | ||
| container | 1 | 0.9542 | 0.9464 | 0.9687 | 0.9676 | 0.9883 | 0.5669 | 0.5457 |
| 2 | 0.9575 | 0.9486 | 0.9564 | 0.9620 | 0.9118 | 0.9676 | 0.8805 | |
| 3 | 0.9654 | 0.9676 | 0.9642 | 0.9575 | 0.9665 | 0.9308 | 0.9732 | |
| foreman | 1 | 0.9787 | 0.9743 | 0.9910 | 0.9877 | 0.9765 | 0.5546 | 0.5267 |
| 2 | 0.9843 | 0.9854 | 0.9754 | 0.9810 | 0.9520 | 0.9910 | 0.8973 | |
| 3 | 0.9832 | 0.9843 | 0.9854 | 0.9832 | 0.9888 | 0.9575 | 0.9966 | |
| salesman | 1 | 0.9587 | 0.9654 | 0.9743 | 0.9687 | 0.9609 | 0.6171 | 0.5457 |
| 2 | 0.9665 | 0.9709 | 0.9642 | 0.9698 | 0.9720 | 0.9888 | 0.8962 | |
| 3 | 0.9754 | 0.9754 | 0.9776 | 0.9787 | 0.9866 | 0.9676 | 0.9910 | |
| mobile | 1 | 0.9631 | 0.9598 | 0.9732 | 0.9732 | 0.9486 | 0.6729 | 0.6093 |
| 2 | 0.9709 | 0.9709 | 0.9698 | 0.9709 | 0.9620 | 0.9787 | 0.8928 | |
| 3 | 0.9665 | 0.9743 | 0.9720 | 0.9732 | 0.9654 | 0.9508 | 0.9843 | |
| carphone | 1 | 0.9520 | 0.9676 | 0.9665 | 0.9676 | 0.9475 | 0.5758 | 0.5301 |
| 2 | 0.9642 | 0.9665 | 0.9676 | 0.9709 | 0.9341 | 0.9799 | 0.8660 | |
| 3 | 0.9743 | 0.9754 | 0.9810 | 0.9743 | 0.9765 | 0.9475 | 0.9877 | |
| news | 1 | 0.9441 | 0.9330 | 0.9654 | 0.9587 | 0.9508 | 0.5904 | 0.5479 |
| 2 | 0.9598 | 0.9631 | 0.9654 | 0.9642 | 0.9397 | 0.9765 | 0.9006 | |
| 3 | 0.9654 | 0.9687 | 0.9687 | 0.9654 | 0.9709 | 0.9308 | 0.9821 | |
| city | 1 | 0.9095 | 0.9241 | 0.9397 | 0.9341 | 0.9308 | 0.6428 | 0.5781 |
| 2 | 0.9408 | 0.9430 | 0.9453 | 0.9453 | 0.9330 | 0.9587 | 0.8671 | |
| 3 | 0.9453 | 0.9430 | 0.9553 | 0.9441 | 0.9575 | 0.9363 | 0.9843 | |
| coastguard | 1 | 0.9754 | 0.9787 | 0.9821 | 0.9799 | 0.9743 | 0.5379 | 0.5200 |
| 2 | 0.9720 | 0.9698 | 0.9698 | 0.9776 | 0.9654 | 0.9877 | 0.8939 | |
| 3 | 0.9699 | 0.9721 | 0.9732 | 0.9699 | 0.9810 | 0.9509 | 0.9843 | |
| Video Sequence | QP | PSNR/dB | ΔPSNR/dB | SSIM | ΔSSIM | ||
|---|---|---|---|---|---|---|---|
| Original | Labeled | Original | Labeled | ||||
| container | 24 | 40.70 | 37.89 | 2.81 | 0.9987 | 0.9976 | 0.0011 |
| 28 | 37.85 | 34.87 | 2.98 | 0.9975 | 0.9951 | 0.0024 | |
| 32 | 34.65 | 31.18 | 3.47 | 0.9949 | 0.9886 | 0.0063 | |
| foreman | 24 | 40.51 | 38.54 | 1.97 | 0.9990 | 0.9984 | 0.0006 |
| 28 | 37.67 | 36.06 | 1.61 | 0.9981 | 0.9971 | 0.0010 | |
| 32 | 34.68 | 32.79 | 1.89 | 0.9962 | 0.9939 | 0.0023 | |
| salesman | 24 | 39.90 | 34.47 | 5.43 | 0.9971 | 0.9894 | 0.0077 |
| 28 | 36.66 | 32.78 | 3.88 | 0.9939 | 0.9844 | 0.0095 | |
| 32 | 33.47 | 30.47 | 3.00 | 0.9873 | 0.9738 | 0.0135 | |
| mobile | 24 | 39.16 | 33.86 | 5.30 | 0.9989 | 0.9963 | 0.0026 |
| 28 | 35.56 | 32.51 | 3.05 | 0.9974 | 0.9947 | 0.0027 | |
| 32 | 31.75 | 29.84 | 1.91 | 0.9937 | 0.9905 | 0.0032 | |
| carphone | 24 | 41.06 | 38.88 | 2.18 | 0.9992 | 0.9987 | 0.0005 |
| 28 | 38.08 | 36.17 | 1.91 | 0.9985 | 0.9977 | 0.0008 | |
| 32 | 34.98 | 29.88 | 5.10 | 0.9969 | 0.9902 | 0.0067 | |
| news | 24 | 41.16 | 35.80 | 5.36 | 0.9990 | 0.9966 | 0.0024 |
| 28 | 38.13 | 32.65 | 5.48 | 0.9980 | 0.9930 | 0.0050 | |
| 32 | 34.76 | 29.54 | 5.22 | 0.9958 | 0.9858 | 0.0100 | |
| city | 24 | 41.75 | 37.28 | 4.47 | 0.9962 | 0.9886 | 0.0076 |
| 28 | 36.93 | 33.14 | 3.79 | 0.9885 | 0.9712 | 0.0173 | |
| 32 | 33.48 | 30.71 | 2.77 | 0.9746 | 0.9493 | 0.0253 | |
| coastguard | 24 | 39.34 | 34.69 | 4.65 | 0.9982 | 0.9949 | 0.0033 |
| 28 | 36.09 | 35.03 | 1.06 | 0.9963 | 0.9953 | 0.0010 | |
| 32 | 32.98 | 29.72 | 3.26 | 0.9924 | 0.9842 | 0.0082 | |
| Video Sequence | QP | BIR/% | |
|---|---|---|---|
| Encryption | Embedding | ||
| container | 24 | 0.89 | 0.92 |
| 28 | 0.92 | 1.47 | |
| 32 | 0.69 | 2.26 | |
| foreman | 24 | 0.24 | 0.48 |
| 28 | 0.17 | 0.87 | |
| 32 | 0.08 | 1.52 | |
| salesman | 24 | 0.42 | 0.36 |
| 28 | 0.40 | 0.75 | |
| 32 | 0.31 | 1.62 | |
| mobile | 24 | 0.26 | 0.10 |
| 28 | 0.27 | 0.18 | |
| 32 | 0.24 | 0.39 | |
| carphone | 24 | 0.47 | 0.59 |
| 28 | 0.45 | 1.04 | |
| 32 | 0.34 | 1.70 | |
| news | 24 | 1.14 | 0.72 |
| 28 | 1.14 | 1.24 | |
| 32 | 0.89 | 1.95 | |
| city | 24 | 0.24 | 0.44 |
| 28 | 0.18 | 0.75 | |
| 32 | 0.14 | 1.41 | |
| coastguard | 24 | 0.11 | 0.36 |
| 28 | 0.08 | 0.64 | |
| 32 | 0.05 | 1.22 | |
| Scheme | Elements for Encryption | Data Embedding | Bit Rate Increase | Separability | Format Compliant | Reversibility | Robustness |
|---|---|---|---|---|---|---|---|
| [18] | IPM | No | Yes | Yes | Yes | No | Yes |
| sign of MVD | No | ||||||
| sign of QDCT | Amplitude of QDCT | ||||||
| [19] | IPM | No | No | Yes | Yes | No | No |
| sign of MVD | No | ||||||
| sign of QDCT | Codeword Level | ||||||
| [20] | IPM | No | No | Yes | Yes | No | No |
| sign of MVD | No | ||||||
| sign of QDCT | Codeword Level | ||||||
| [21] | IPM | No | Yes | Yes | Yes | Yes | No |
| sign of MVD | No | ||||||
| sign of QDCT | Amplitude of QDCT | ||||||
| [22] | IPM | No | Yes | Yes | Yes | Yes | No |
| sign of MVD | No | ||||||
| sign of QDCT | Amplitude of QDCT | ||||||
| [23] | IPM | No | Yes | Yes | Yes | Yes | No |
| sign of MVD | No | ||||||
| sign of QDCT coefficient | Amplitude of QDCT coefficient | ||||||
| [24] | IPM | No | Yes | Yes | Yes | Yes | No |
| sign of MVD | No | ||||||
| sign of QDCT coefficient | Amplitude of QDCT coefficient | ||||||
| [25] | Sign of MVD | No | Yes | Yes | Yes | Yes | No |
| amplitude of MVD | No | ||||||
| sign of QDCT | Amplitude of QDCT | ||||||
| Proposed | IPM | No | Yes | Yes | Yes | Yes | Yes |
| sign of QDCT | Amplitude of QDCT | ||||||
| position of QDCT | Amplitude of QDCT |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Zhang, Z.; Lei, Y.; Niu, K.; Yang, X. A Multi-Domain Embedding Framework for Robust Reversible Data Hiding Scheme in Encrypted Videos. Electronics 2022, 11, 2552. https://doi.org/10.3390/electronics11162552
Chen P, Zhang Z, Lei Y, Niu K, Yang X. A Multi-Domain Embedding Framework for Robust Reversible Data Hiding Scheme in Encrypted Videos. Electronics. 2022; 11(16):2552. https://doi.org/10.3390/electronics11162552
Chicago/Turabian StyleChen, Pei, Zhuo Zhang, Yang Lei, Ke Niu, and Xiaoyuan Yang. 2022. "A Multi-Domain Embedding Framework for Robust Reversible Data Hiding Scheme in Encrypted Videos" Electronics 11, no. 16: 2552. https://doi.org/10.3390/electronics11162552
APA StyleChen, P., Zhang, Z., Lei, Y., Niu, K., & Yang, X. (2022). A Multi-Domain Embedding Framework for Robust Reversible Data Hiding Scheme in Encrypted Videos. Electronics, 11(16), 2552. https://doi.org/10.3390/electronics11162552