
HW-Flow-Fusion: Inter-Layer Scheduling for Convolutional Neural Network Accelerators with Dataflow Architectures

 , ,
, ,
Abstract
:1. Introduction
- An analytical model of inter-layer scheduling with the constraints and parameters that define the communication and computation patterns in spatial arrays.
- HW-Flow-Fusion, a layer fusion framework that can explore the map-space across multiple layers.
- An improved data reuse model for zero recomputation when executing layers with data dependencies, leveraging multiple tile-sets to compute only non-redundant intermediate data.
- An evaluation of different hardware partitioning policies to allocate storage and processing units to different layers processed simultaneously on the same accelerator.
2. Related Works
2.1. Loop Tiling and Loop Unrolling
2.2. Scheduling and Mapping
2.3. Execution of Multiple Layers on the Same Hardware Accelerator
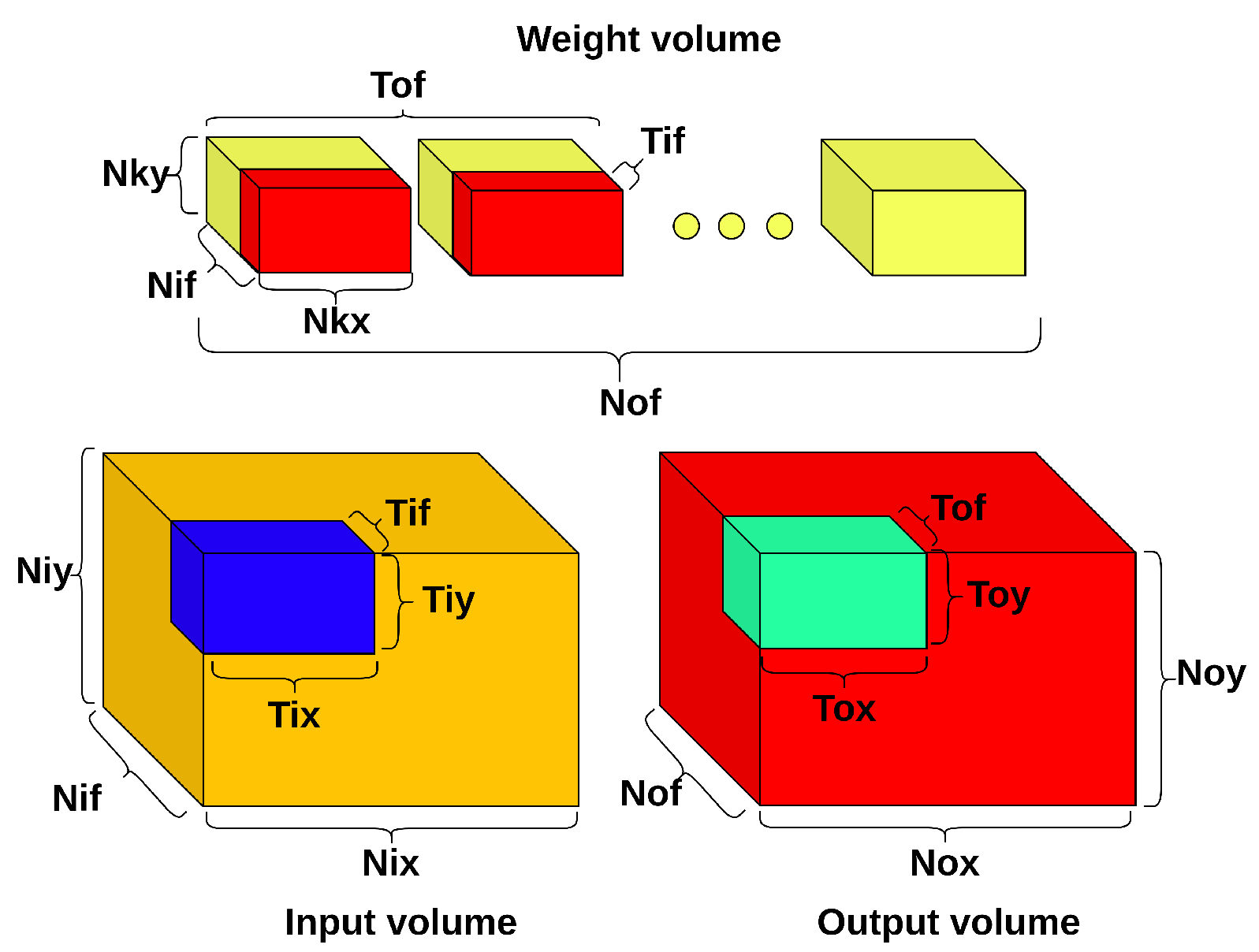
3. Background on Loop Scheduling
| Algorithm 1: Convolutional loop pseudocode. | |
 | |
- Input reuse: each input pixel is reused during the convolution to generate Nof feature maps;
- Output reuse: each output pixel is reused during the accumulation of Nif feature maps;
- Kernel reuse: kernel weights are reused Nox * Noy times over each input feature map;
- Convolutional reuse: each input pixel is reused Nkx * Nky times for a single Hadamard product at a time.
3.1. Optimal Loop Scheduling on Dataflow Architectures
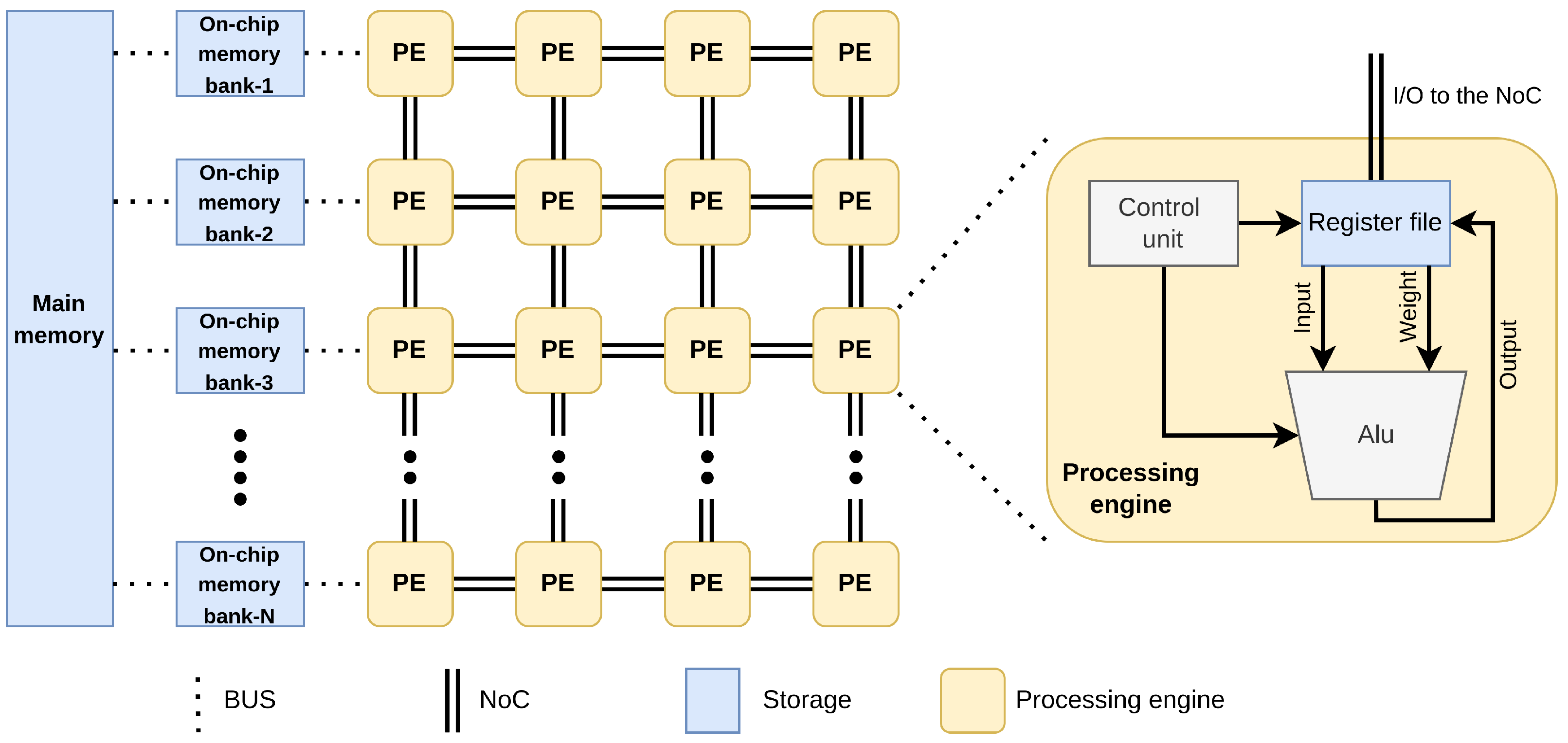
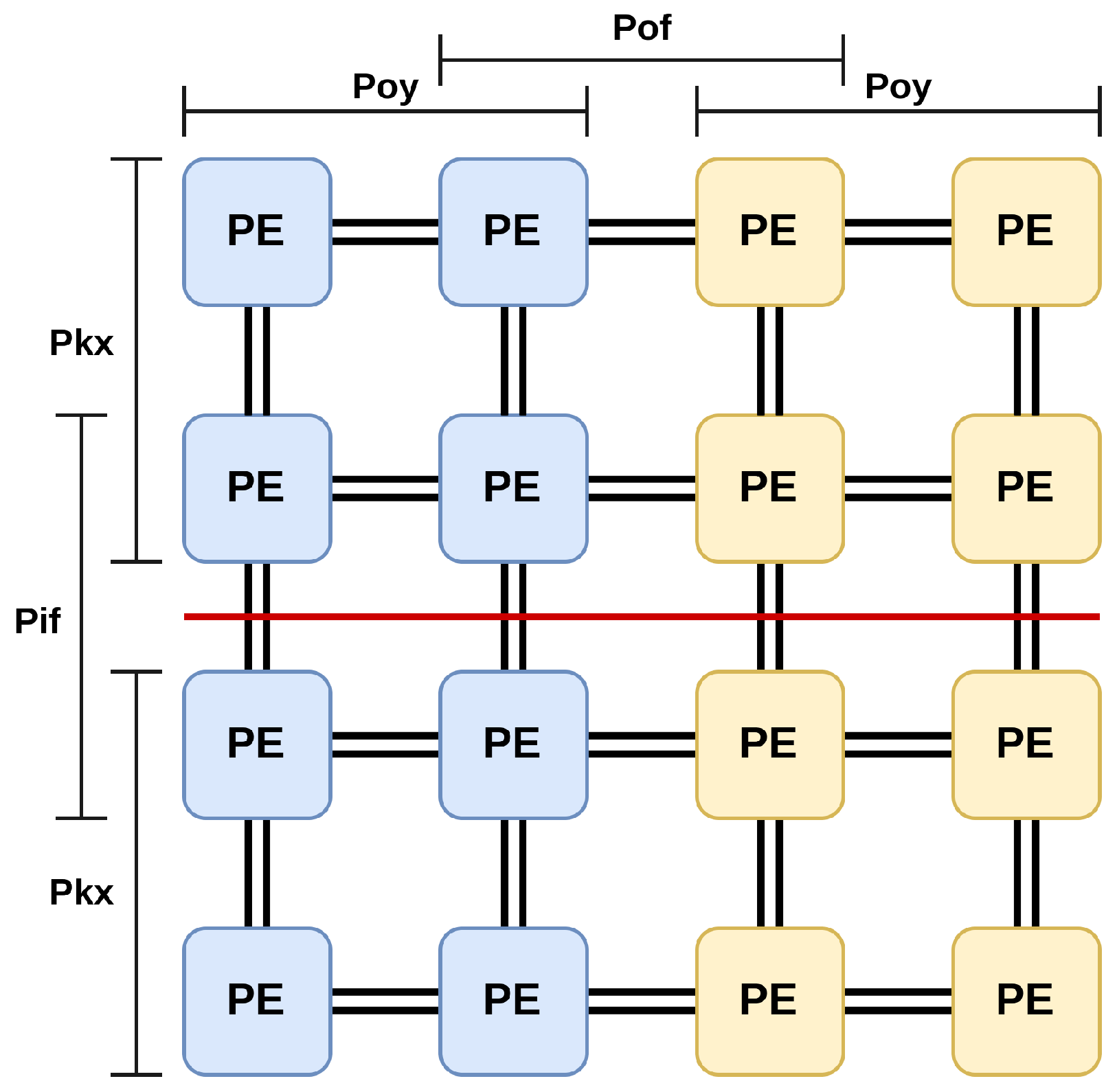
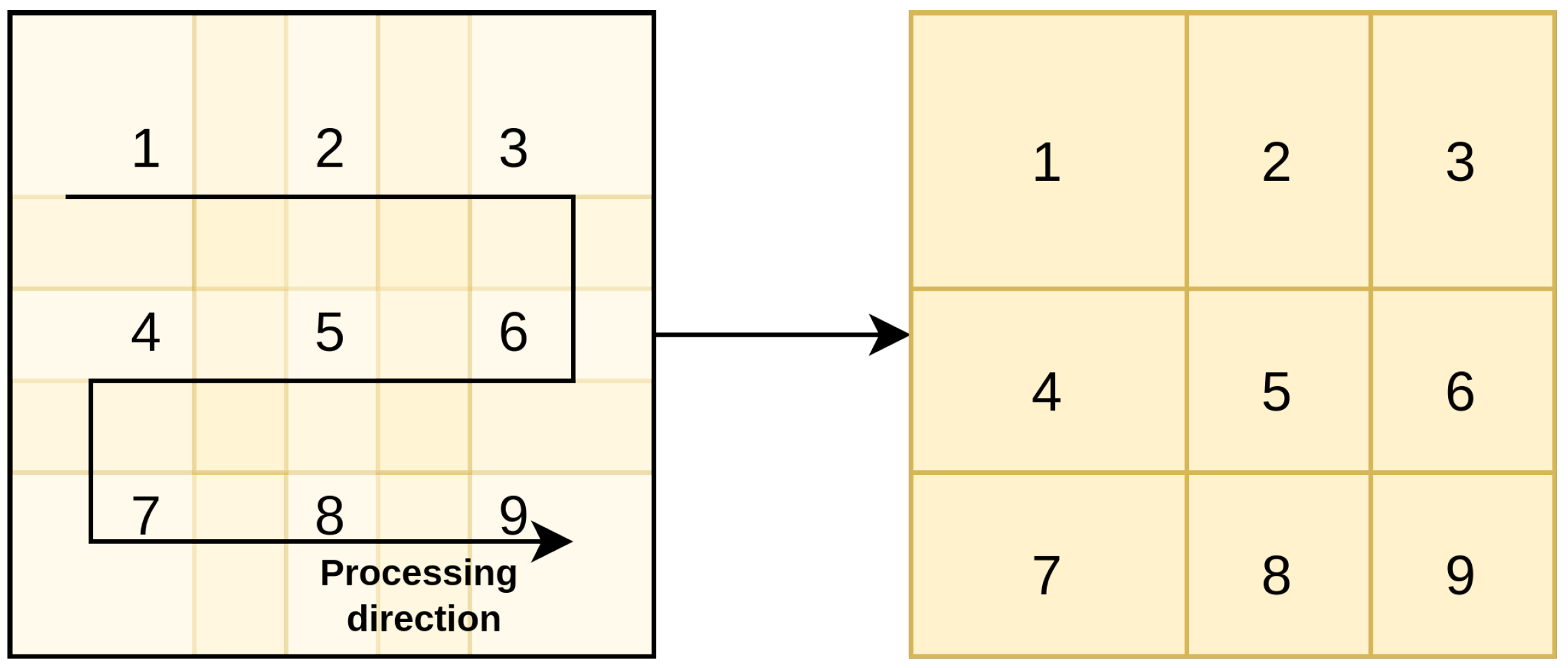
3.2. Temporal and Spatial Mapping
3.3. Loop Tiling and Reordering in Single-Layer Scheduling
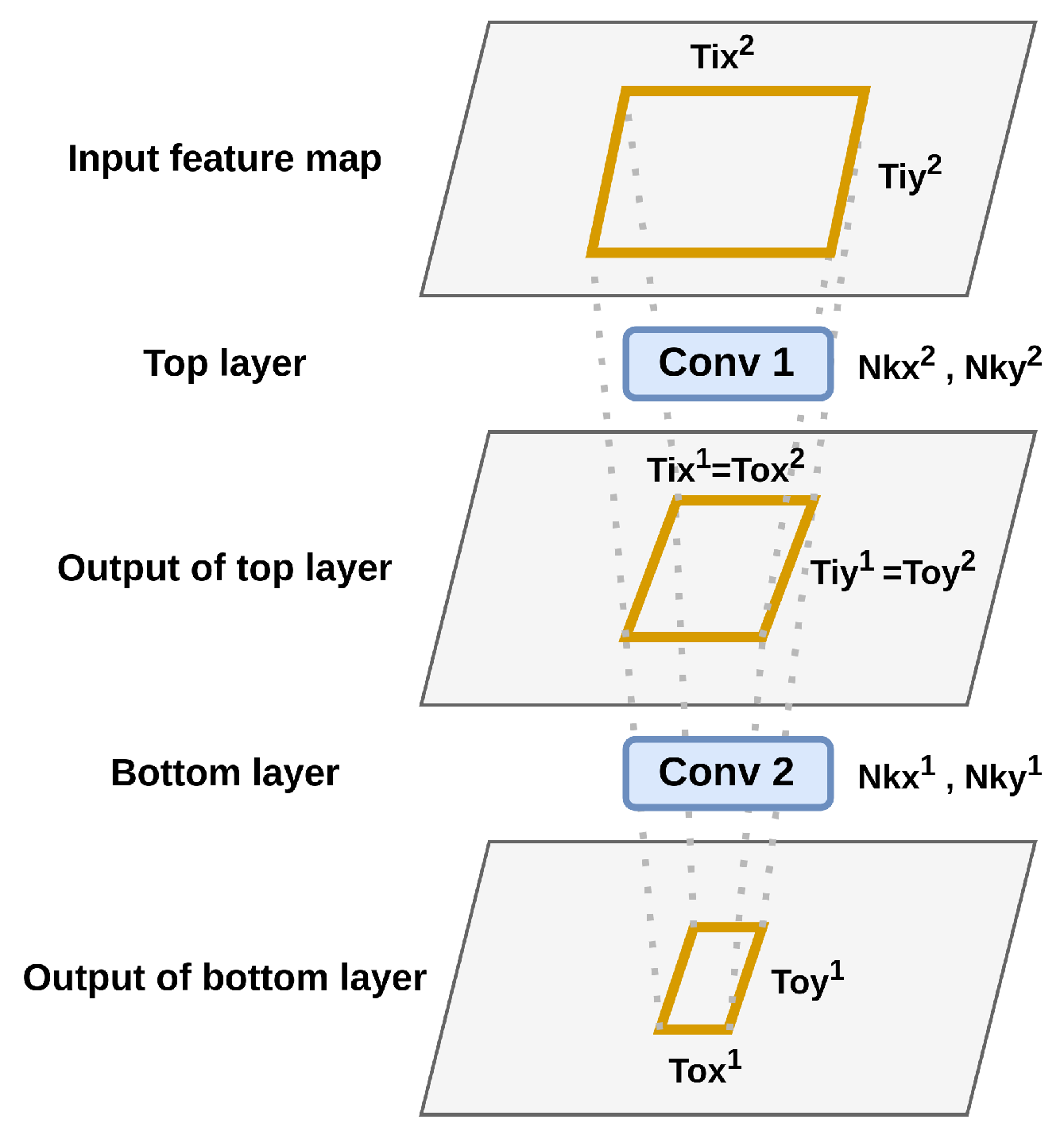
3.4. Inter-Layer Scheduling Concepts and Constraints
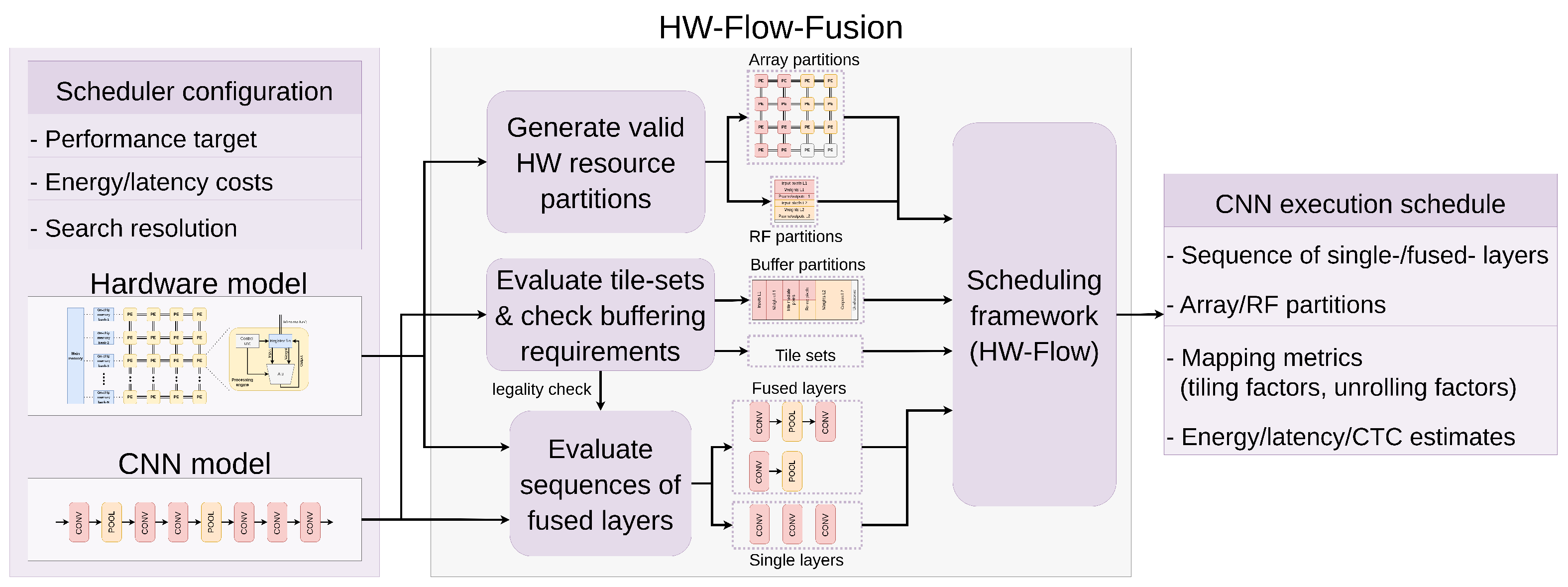
4. HW-Flow-Fusion: Inter-Layer Scheduling and Hardware Resource Optimization
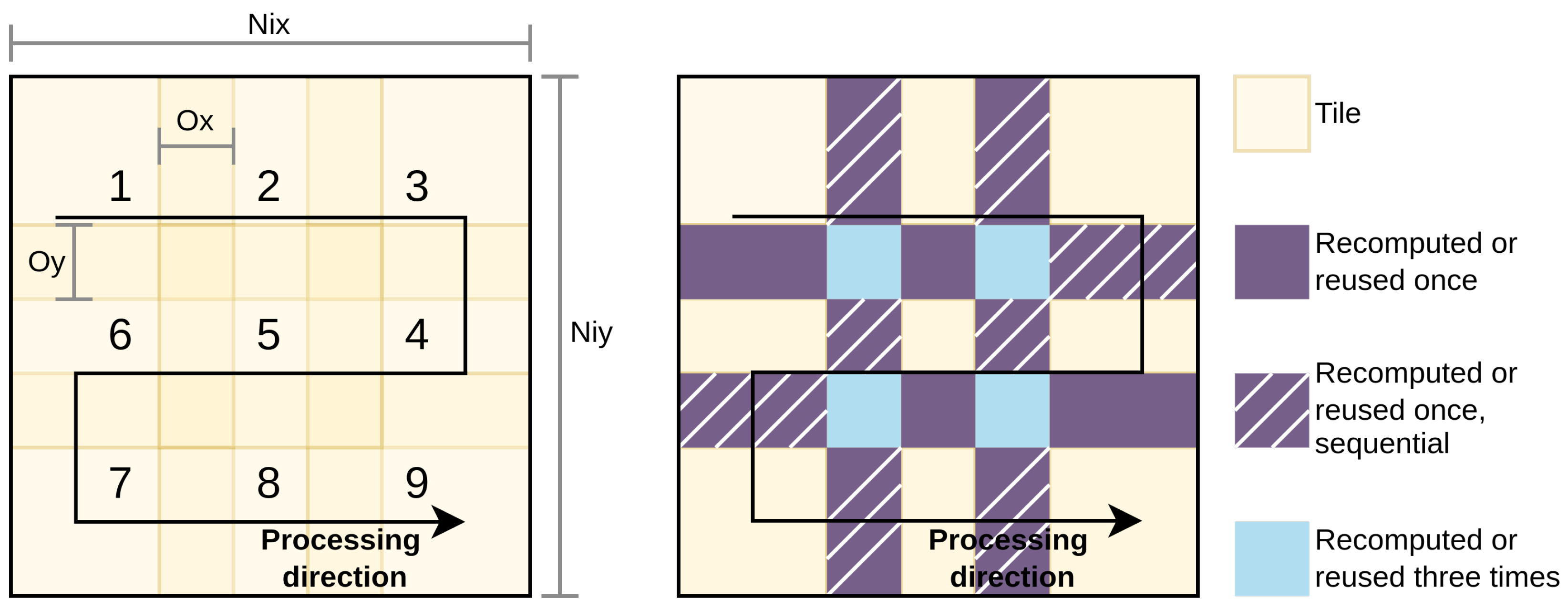
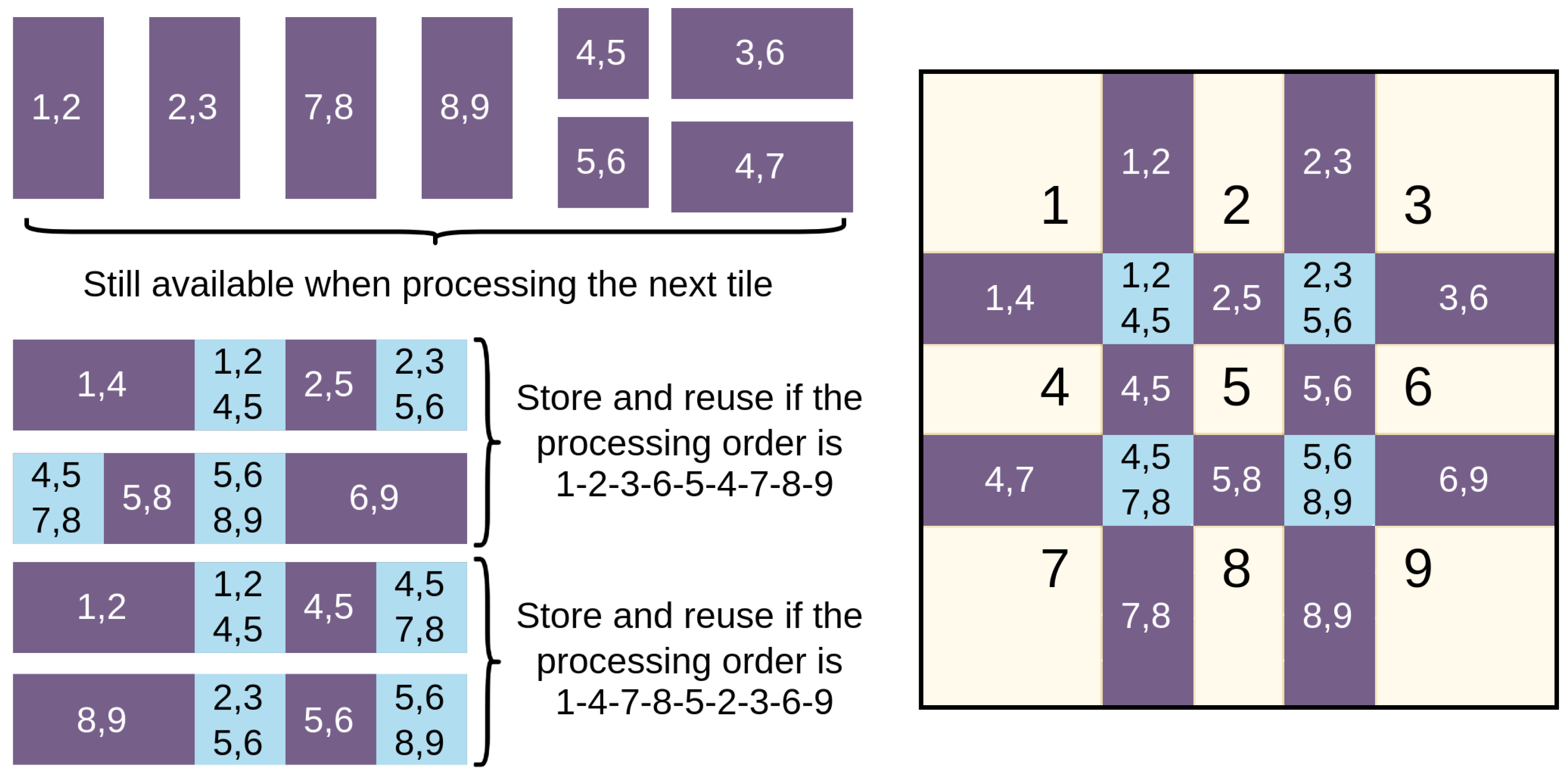
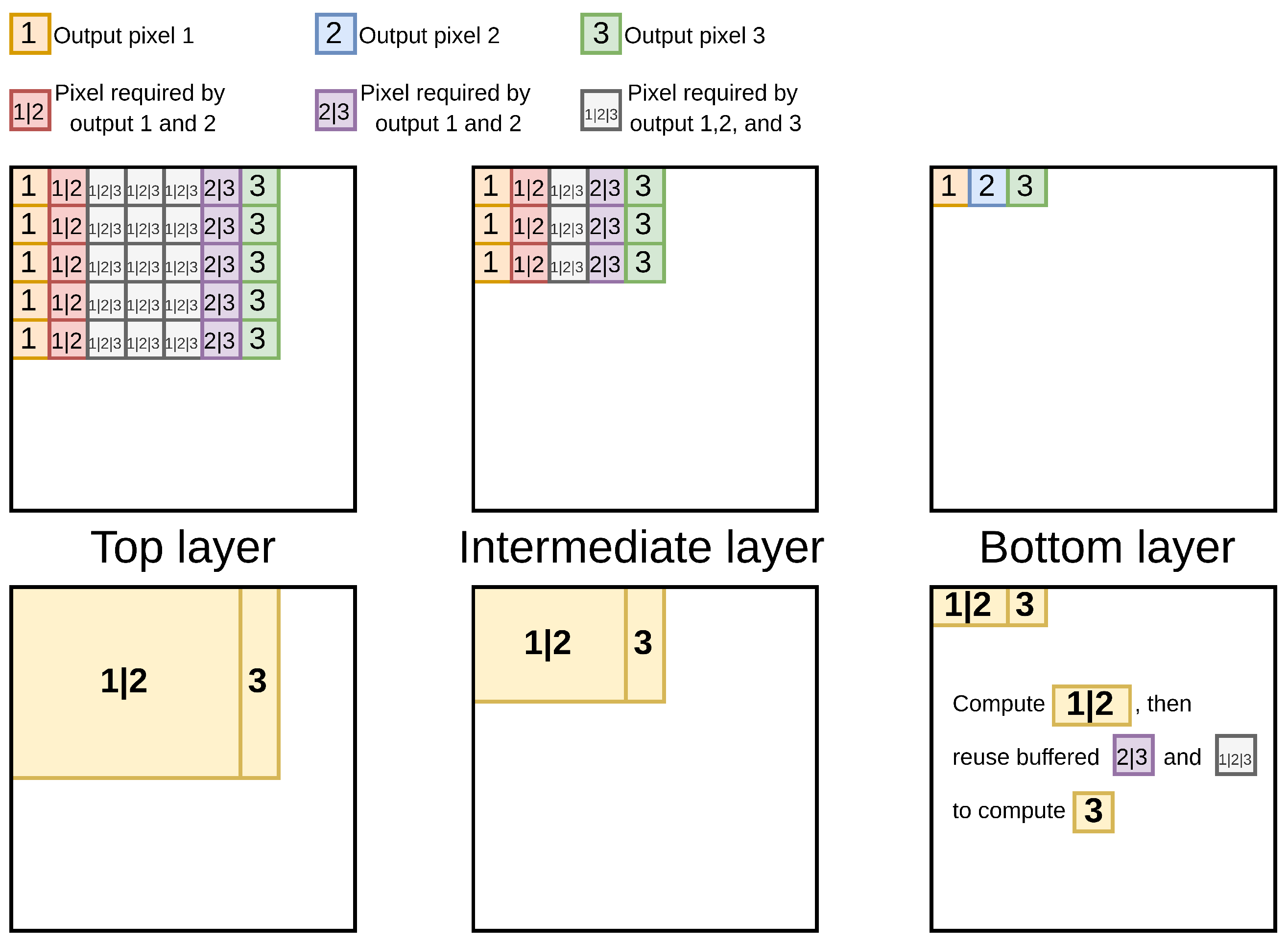
4.1. Optimized Intermediate Pixel Reuse Model
4.2. Multi-Tiling for Minimum Reuse Memory with No Recomputation
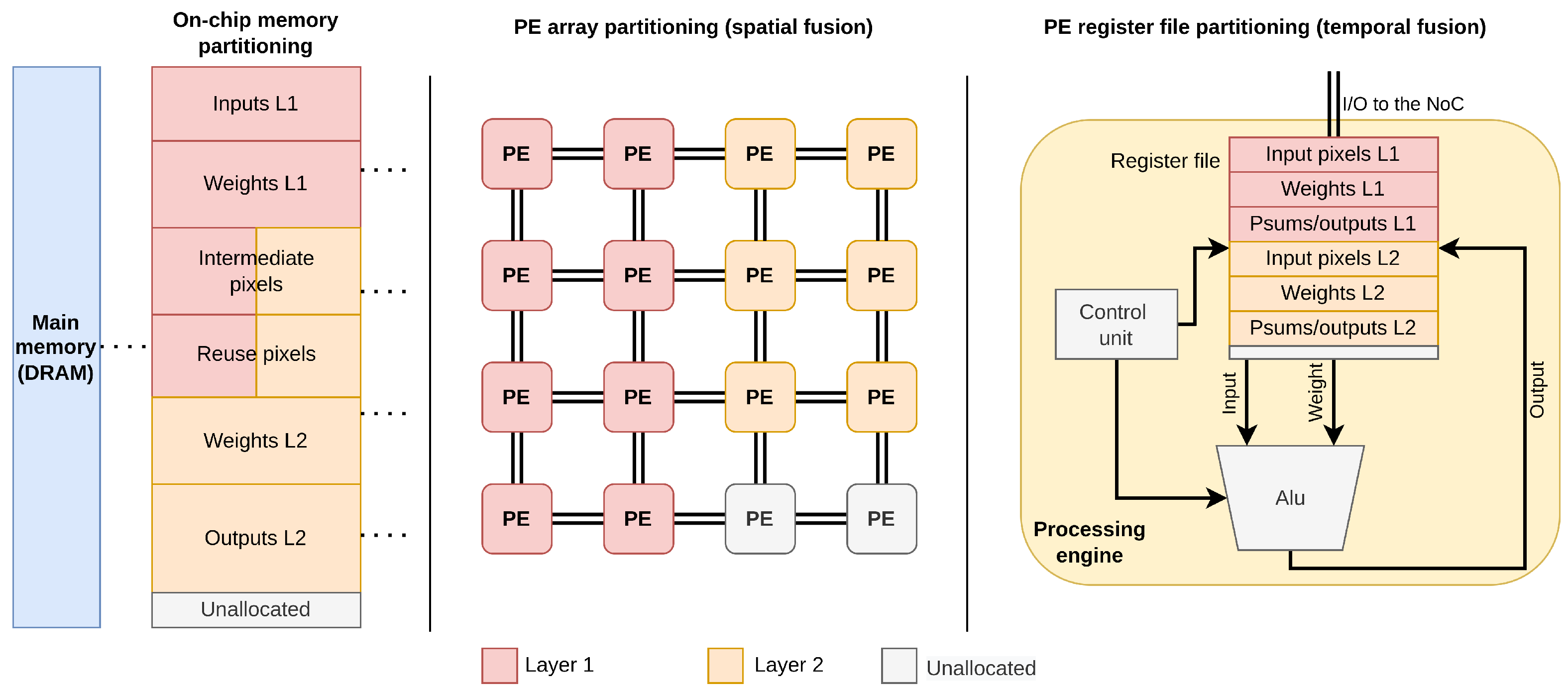
4.3. Hardware Resource Partitioning
4.3.1. Spatial Fusion
4.3.2. Temporal Fusion
4.4. Proposed Inter-Layer Scheduling Framework
5. Results
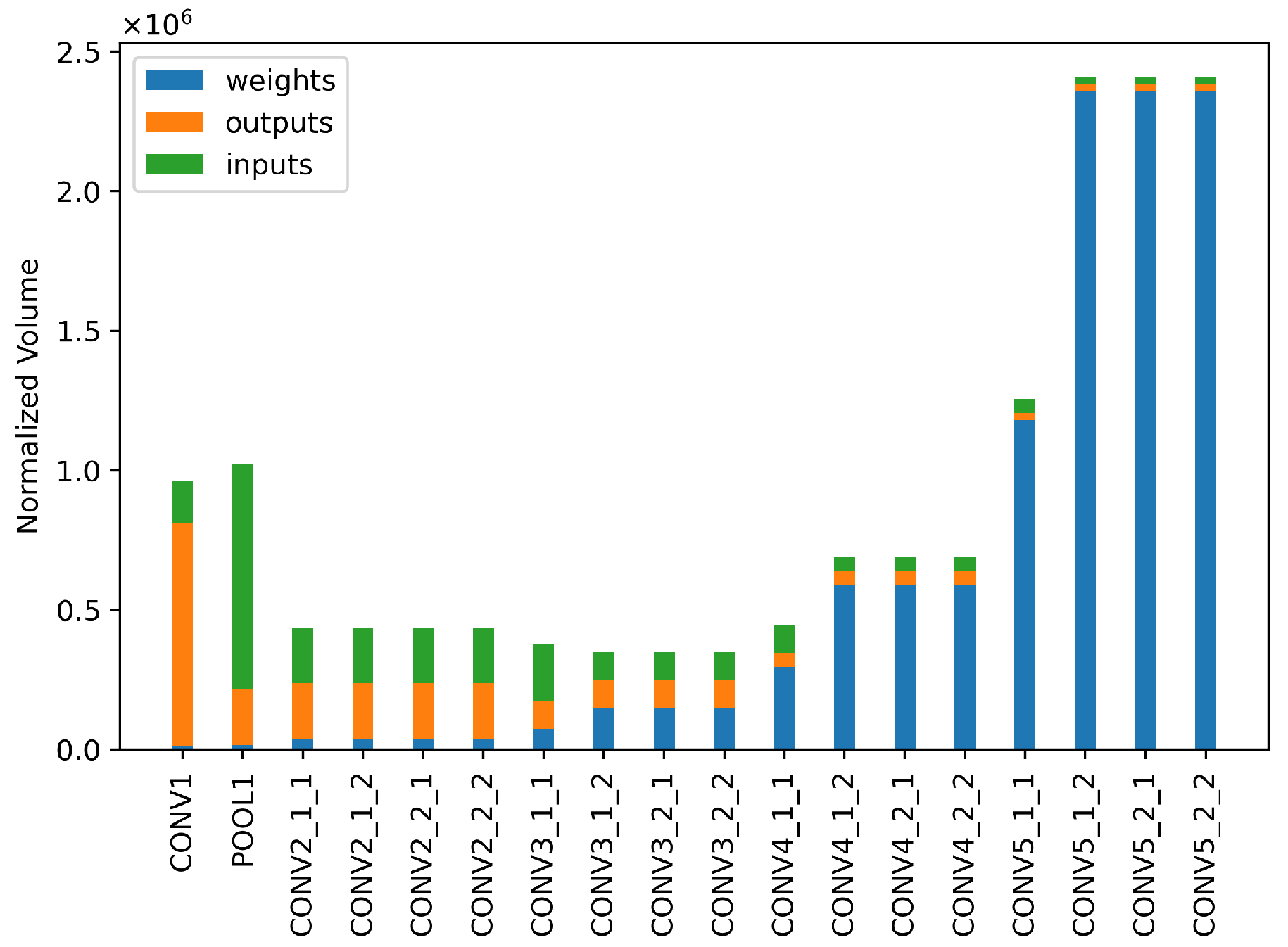
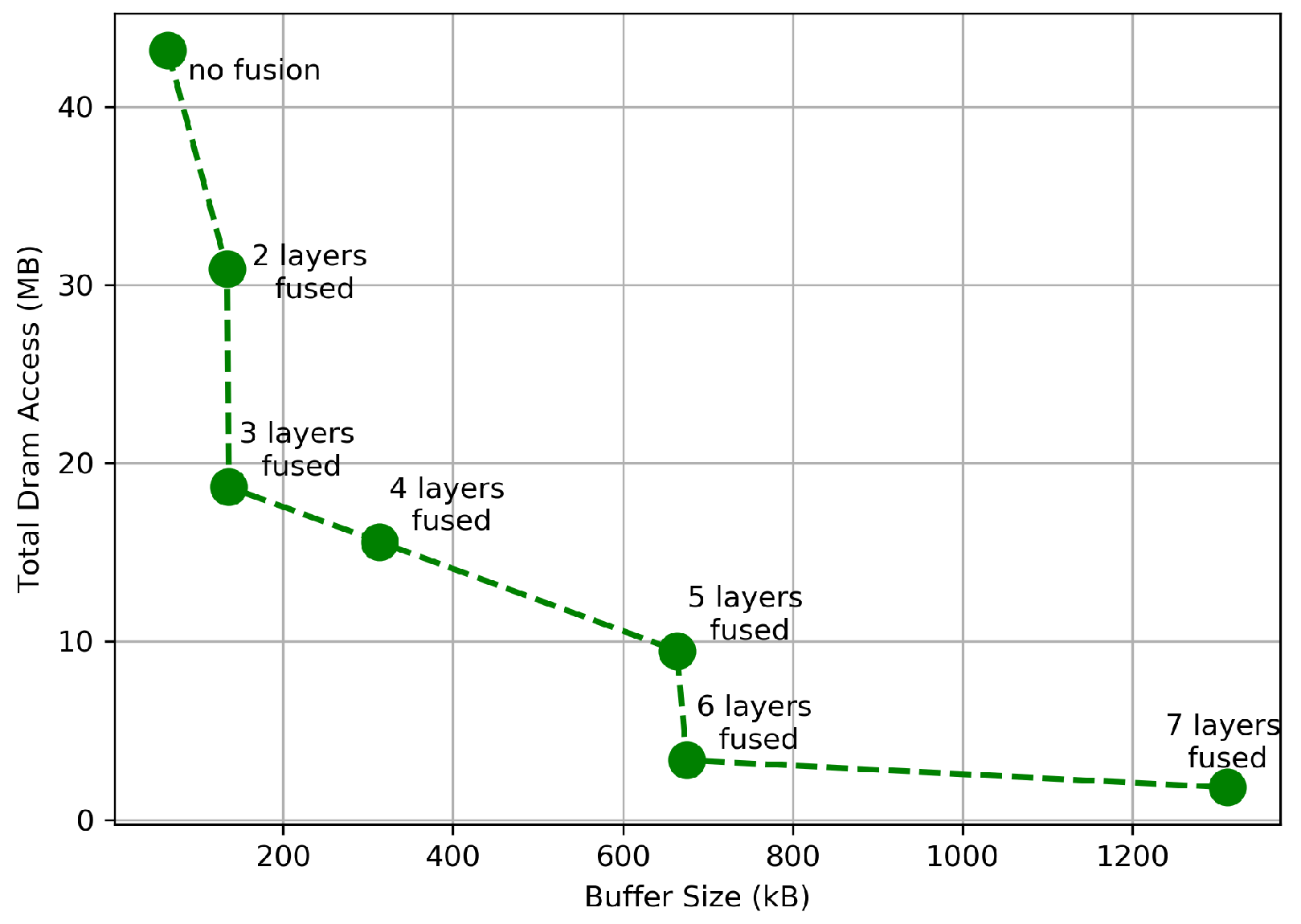
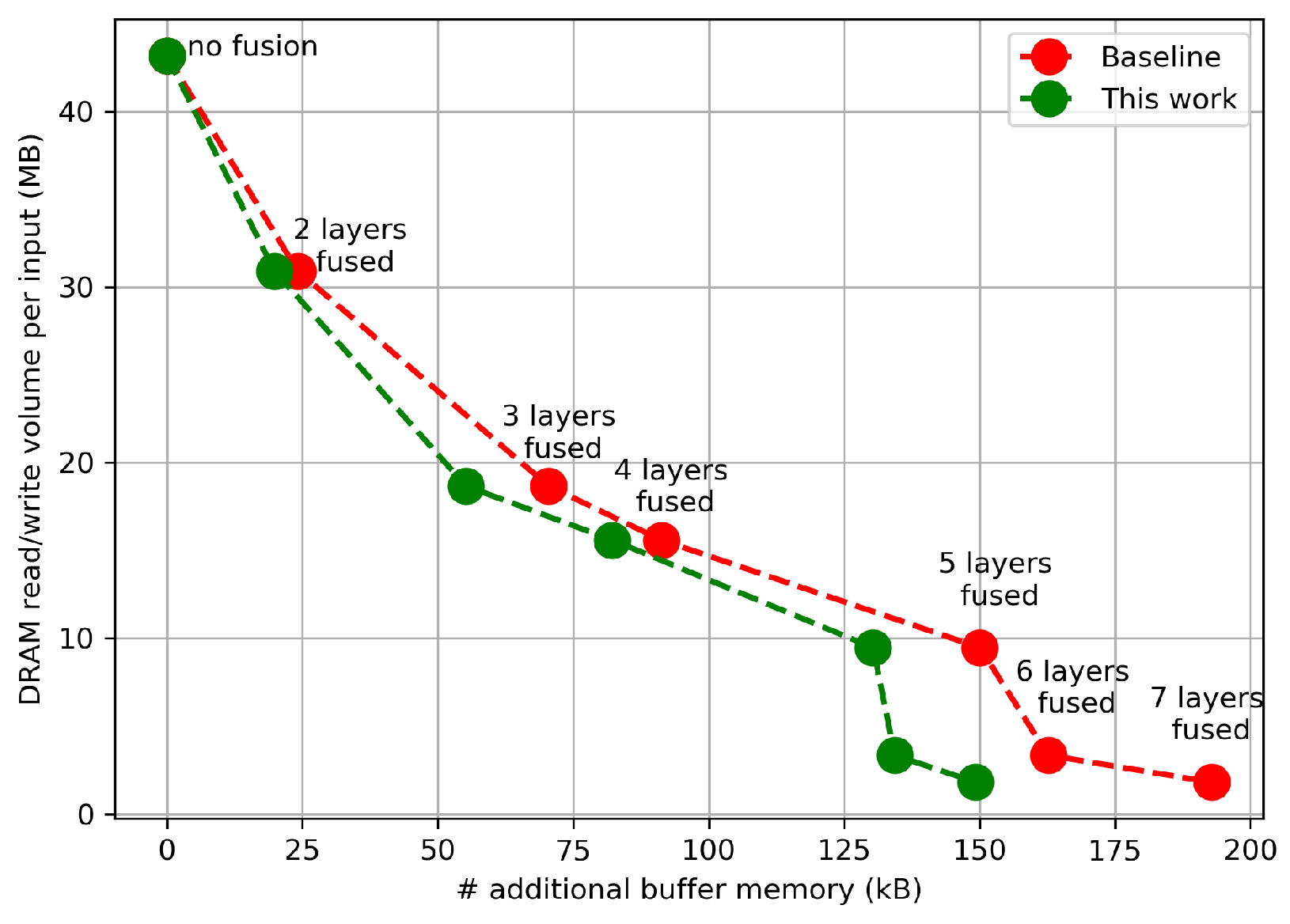
5.1. Reuse Buffer Comparison and Impact of On-Chip Memory on Layer-Fusion
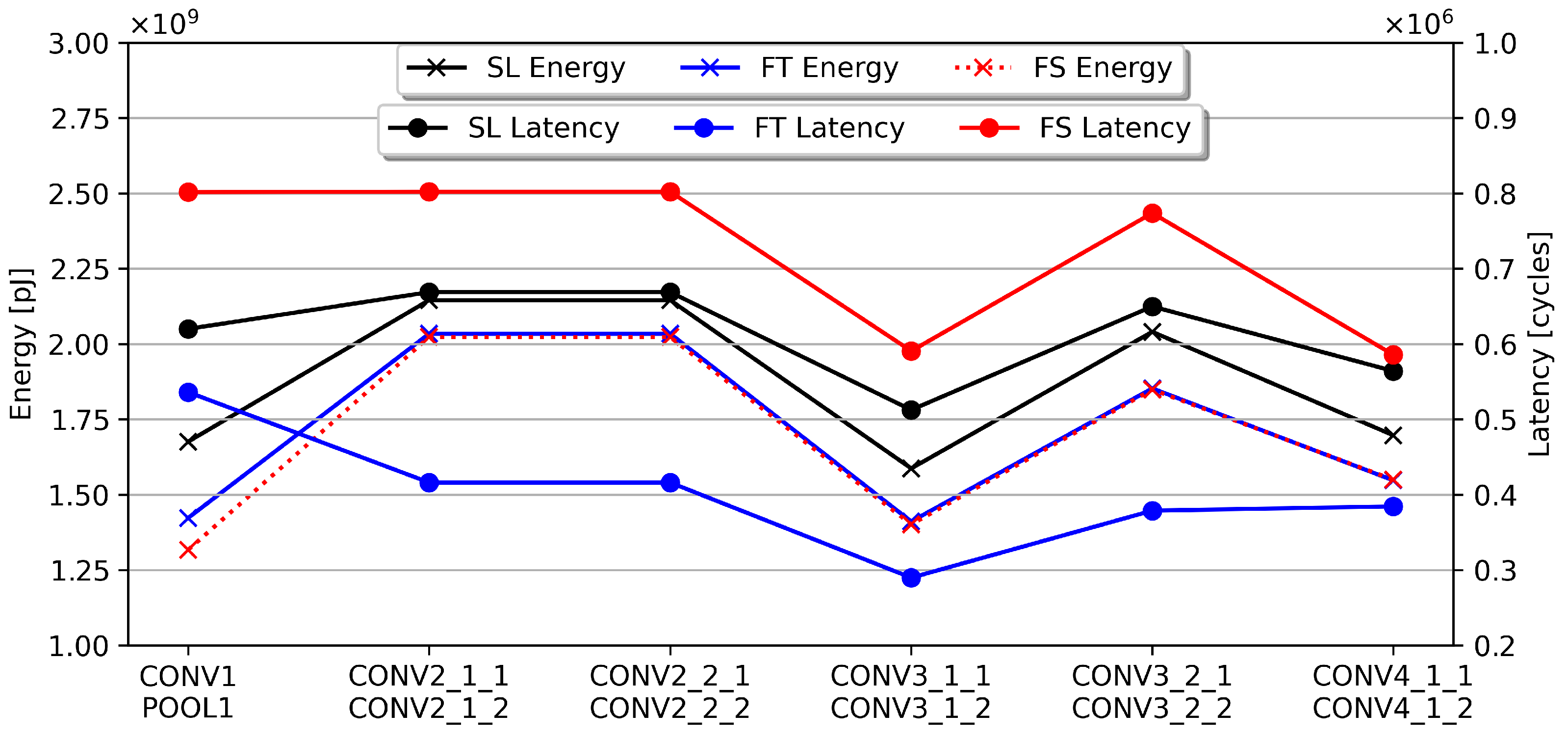
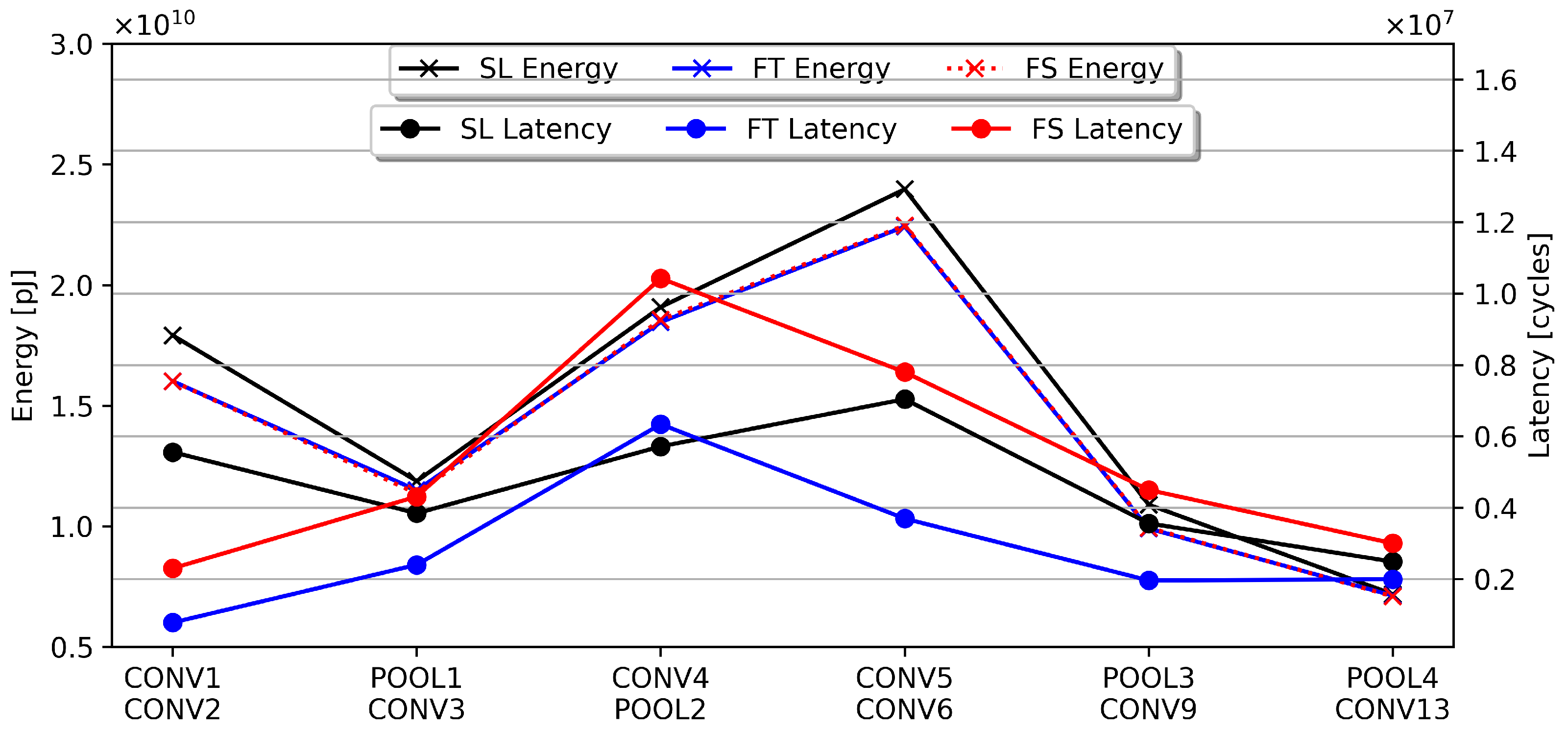
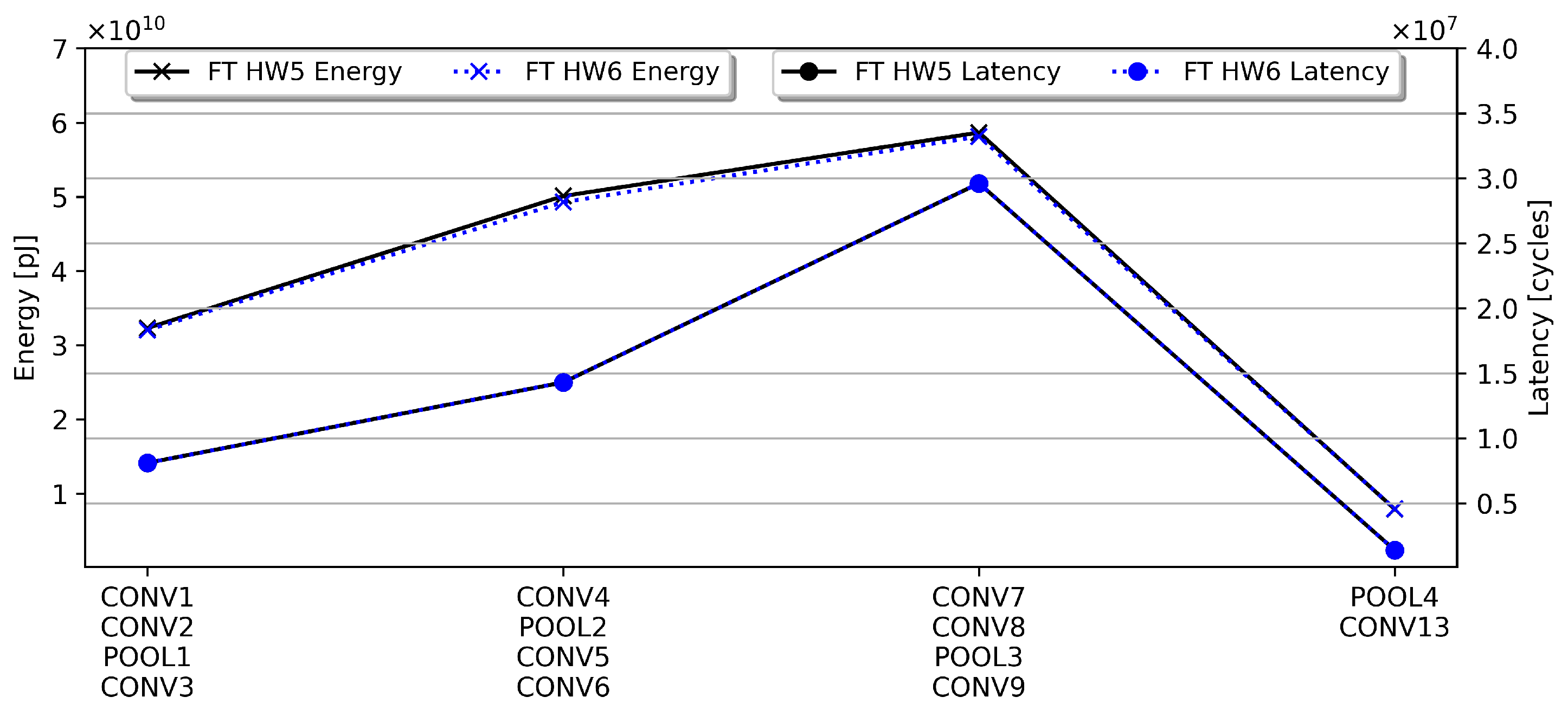
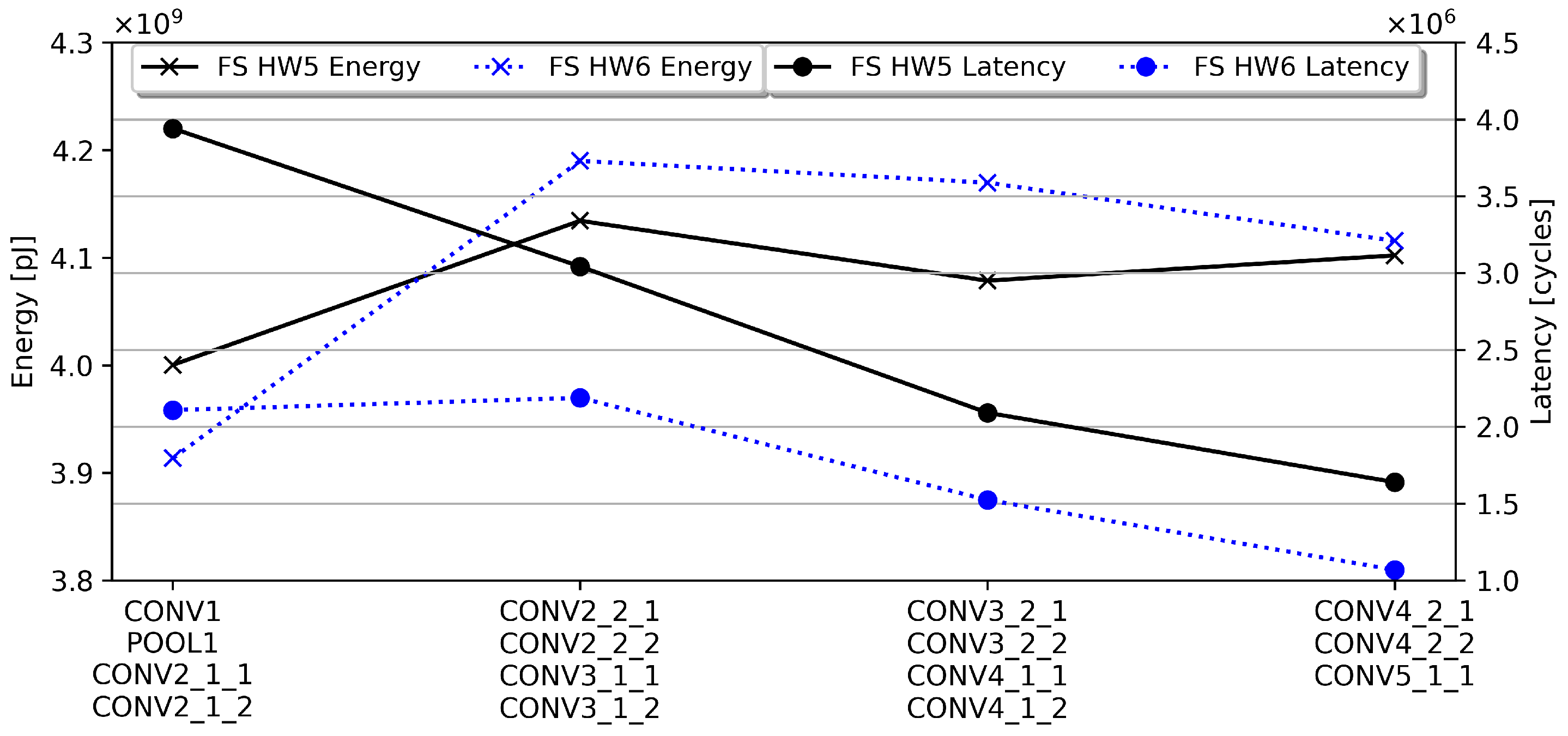
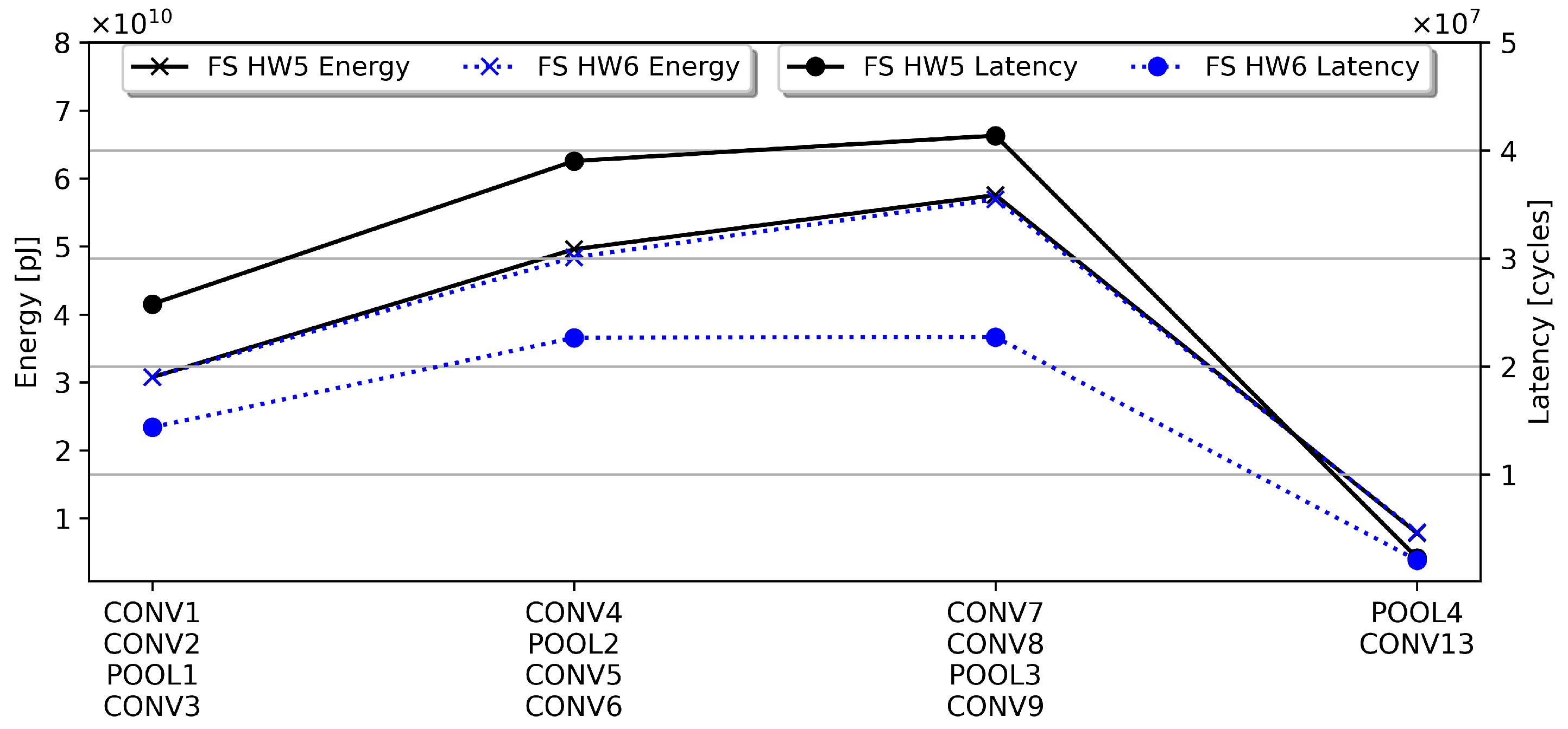
5.2. Comparison of Spatial, Temporal Fusion, and Single Layer Hardware Metrics
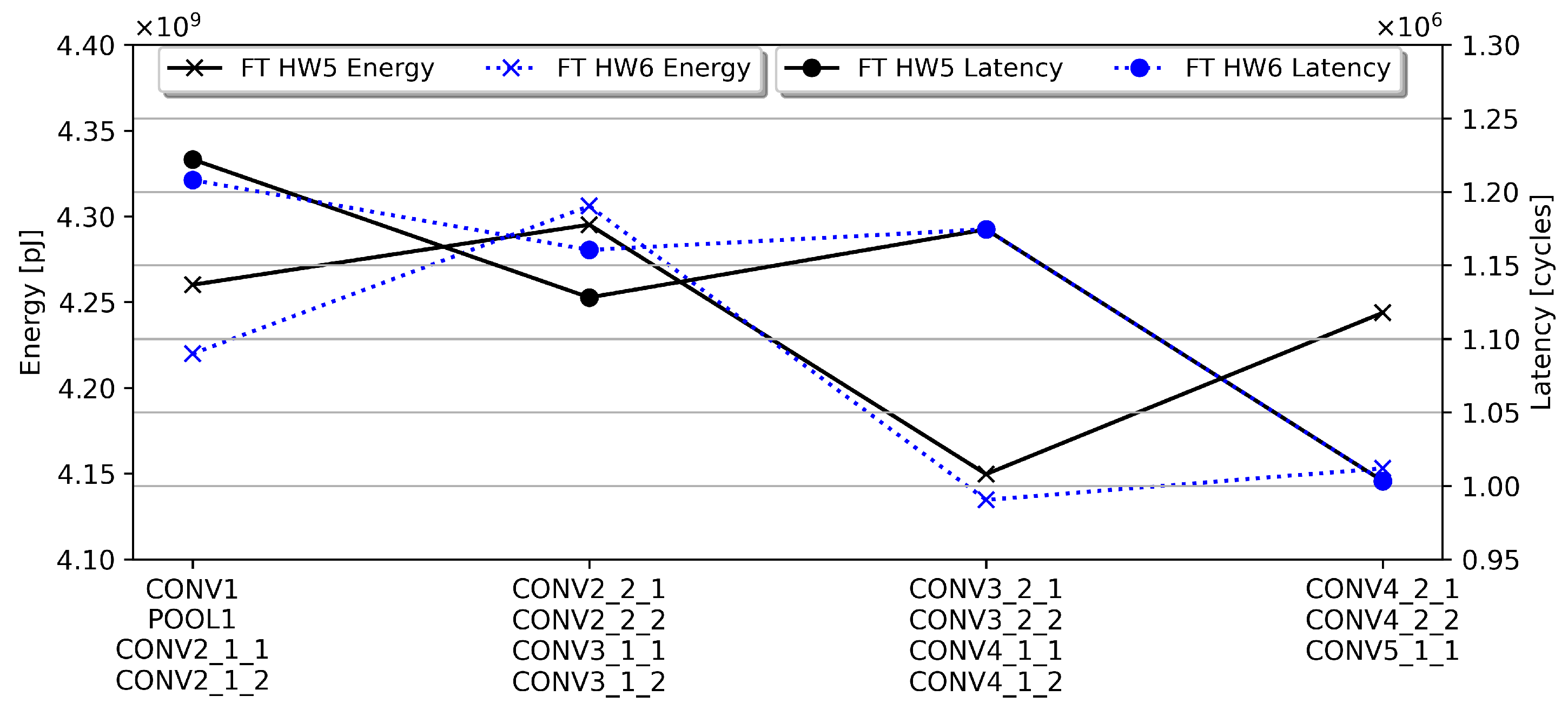
5.3. Hardware Constraints and Scaling on Inter-Layer Scheduling
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| HW | Hardware |
| PE | Processing engine |
| RF | Register file |
| NoC | Network on chip |
| CTC | Computation to communication |
| MAC | Multiply and accumulate |
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region and semantic segmentation-aware cnn model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1134–1142. [Google Scholar]
- Capra, M.; Bussolino, B.; Marchisio, A.; Masera, G.; Martina, M.; Shafique, M. Hardware and Software Optimizations for Accelerating Deep Neural Networks: Survey of Current Trends, Challenges, and the Road Ahead. IEEE Access 2020, 8, 225134–225180. [Google Scholar] [CrossRef]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2016, 52, 127–138. [Google Scholar] [CrossRef]
- Gao, M.; Yang, X.; Pu, J.; Horowitz, M.; Kozyrakis, C. TANGRAM: Optimized Coarse-Grained Dataflow for Scalable NN Accelerators. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, Providence, RI, USA, 13–17 April 2019; Association for Computing Machinery: New York, NY, USA, 2019. ASPLOS ’19. pp. 807–820. [Google Scholar] [CrossRef]
- Parashar, A.; Raina, P.; Shao, Y.S.; Chen, Y.H.; Ying, V.A.; Mukkara, A.; Venkatesan, R.; Khailany, B.; Keckler, S.W.; Emer, J. Timeloop: A Systematic Approach to DNN Accelerator Evaluation. In Proceedings of the 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Madison, WA, USA, 24–26 March 2019; pp. 304–315. [Google Scholar] [CrossRef]
- Huang, Q.; Kalaiah, A.; Kang, M.; Demmel, J.; Dinh, G.; Wawrzynek, J.; Norell, T.; Shao, Y.S. CoSA: Scheduling by Constrained Optimization for Spatial Accelerators. In Proceedings of the 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; IEEE: Manhattan, NY, USA, 2021; pp. 554–566. [Google Scholar]
- Mei, L.; Houshmand, P.; Jain, V.; Giraldo, S.; Verhelst, M. ZigZag: Enlarging Joint Architecture-Mapping Design Space Exploration for DNN Accelerators. IEEE Trans. Comput. 2021, 70, 1160–1174. [Google Scholar] [CrossRef]
- Fasfous, N.; Vemparala, M.R.; Frickenstein, A.; Valpreda, E.; Salihu, D.; Doan, N.A.V.; Unger, C.; Nagaraja, N.S.; Martina, M.; Stechele, W. HW-FlowQ: A Multi-Abstraction Level HW-CNN Co-Design Quantization Methodology. ACM Trans. Embed. Comput. Syst. 2021, 20. [Google Scholar] [CrossRef]
- Alwani, M.; Chen, H.; Ferdman, M.; Milder, P. Fused-layer CNN accelerators. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–12. [Google Scholar] [CrossRef]
- Niu, W.; Guan, J.; Wang, Y.; Agrawal, G.; Ren, B. DNNFusion: Accelerating Deep Neural Networks Execution with Advanced Operator Fusion. In Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, Virtual, 20–25 June 2021; Association for Computing Machinery: New York, NY, USA, 2021. PLDI 2021. pp. 883–898. [Google Scholar] [CrossRef]
- Kao, S.; Huang, X.; Krishna, T. DNNFuser: Generative Pre-Trained Transformer as a Generalized Mapper for Layer Fusion in DNN Accelerators. arXiv 2022, arXiv:2201.11218. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. Optimizing the Convolution Operation to Accelerate Deep Neural Networks on FPGA. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1354–1367. [Google Scholar] [CrossRef]
- Tu, F.; Yin, S.; Ouyang, P.; Tang, S.; Liu, L.; Wei, S. Deep Convolutional Neural Network Architecture With Reconfigurable Computation Patterns. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 2220–2233. [Google Scholar] [CrossRef]
- Nvidia. NVDLA Open Source Project. 2017. Available online: https://nvdla.org/ (accessed on 28 June 2022).
- Kao, S.C.; Krishna, T. MAGMA: An Optimization Framework for Mapping Multiple DNNs on Multiple Accelerator Cores. In Proceedings of the 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Korea, 2–6 April 2022; pp. 814–830. [Google Scholar] [CrossRef]
- Venkatesan, R.; Shao, Y.S.; Wang, M.; Clemons, J.; Dai, S.; Fojtik, M.; Keller, B.; Klinefelter, A.; Pinckney, N.; Raina, P.; et al. MAGNet: A Modular Accelerator Generator for Neural Networks. In Proceedings of the 2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Westminster, CO, USA, 4–7 November 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Aimar, A.; Mostafa, H.; Calabrese, E.; Rios-Navarro, A.; Tapiador-Morales, R.; Lungu, I.A.; Milde, M.B.; Corradi, F.; Linares-Barranco, A.; Liu, S.C.; et al. Nullhop: A flexible convolutional neural network accelerator based on sparse representations of feature maps. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 644–656. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Sun, G.; Fang, Z.; Zhou, P.; Pan, P.; Cong, J. Caffeine: Toward Uniformed Representation and Acceleration for Deep Convolutional Neural Networks. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 38, 2072–2085. [Google Scholar] [CrossRef]
- Huang, E.; Korf, R.E. Optimal rectangle packing: An absolute placement approach. J. Artif. Intell. Res. 2013, 46, 47–87. [Google Scholar] [CrossRef]
- Yang, X.; Gao, M.; Liu, Q.; Setter, J.; Pu, J.; Nayak, A.; Bell, S.; Cao, K.; Ha, H.; Raina, P.; et al. Interstellar: Using Halide’s Scheduling Language to Analyze DNN Accelerators. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 369–383. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Output | Weights | Batch | |
|---|---|---|---|---|
| Width/Height/Channels | Width/Height/Channels | Width/Height | ||
| Loop size | Nix, Niy, Nif | Nox, Noy, Nof | Nkx, Nky | B |
| Tile size | Tix, Tiy, Tif | Tox, Toy, Tof | Tkx, Tky | Tb |
| Unroll size | Pix, Piy, Pif | Pox, Poy, Pof | Pkx, Pky | Pb |
| Parameter | Value | Maximum Value |
|---|---|---|
| PE set | Pkx · Poy | Pkx ≡ Nkx, Poy ≤ Toy |
| Unrolling | Pif, Pof | Pif ≤ PEx ÷ Pkx, Pof ≤ PEy ÷ Poy |
| HW Config. | PEx | PEy | On-Chip Buffer (kB) | Register File (B) | Precision |
|---|---|---|---|---|---|
| 1 | 32 | 16 | 512 | 512 | 8 |
| 2 | 32 | 16 | 1536 | 512 | 8 |
| 3 | 32 | 32 | 1536 | 512 | 8 |
| 4 | 48 | 32 | 1536 | 512 | 8 |
| 5 | 32 | 16 | 1536 | 1024 | 8 |
| 6 | 32 | 16 | 1536 | 1536 | 8 |
| HW Config. | MAC 8 bit [pJ] | On-Chip Buffer Access [pJ] | DRAM Access [pJ] |
|---|---|---|---|
| 1 | 1.75 | 26.70 | 200.0 |
| 2, 3, 4 | 1.75 | 78.16 | 200.0 |
| 5 | 1.79 | 78.16 | 200.0 |
| 6 | 1.83 | 78.16 | 200.0 |
| CNN | VGG16-E | ResNet18 | VGG16-E | ResNet18 | VGG16-E | ResNet18 |
| Energy | 94% | 91% | 94% | 90% | 100% | 98% |
| Latency | 61% | 66% | 114% | 118% | 188% | 180% |
| Com. volume | 49% | 47% | 49% | 48% | 100% | 101% |
| ResNet18 | VGG16-E | ||||
|---|---|---|---|---|---|
| Layer |
Spatial PE Array [PEx, PEy] |
Temporal Register File [Wgt, In, Out] | Layer |
Spatial PE Array [PEx, PEy] |
Temporal Register File [Wgt, In, Out] |
| CONV1 | [16, 16] | [192, 12, 16] | CONV1 | [8, 8] | [192, 12, 16] |
| POOL1 | [16, 16] | [192, 12, 16] | CONV2 | [8, 8] | [192, 12, 16] |
| CONV2_1_1 | [32, 8] | [192, 12, 16] | POOL1 | [32, 8] | [192, 12, 16] |
| CONV2_1_2 | [32, 8] | [192, 12, 16] | CONV3 | [32, 8] | [192, 12, 16] |
| CONV2_2_1 | [32, 8] | [192, 12, 16] | CONV4 | [32, 8] | [192, 12, 16] |
| CONV2_2_2 | [32, 8] | [192, 12, 16] | POOL2 | [32, 8] | [192, 12, 16] |
| CONV3_1_1 | [32, 8] | [192, 12, 16] | CONV5 | [32, 8] | [192, 12, 16] |
| CONV3_1_2 | [32, 8] | [192, 12, 16] | CONV6 | [32, 8] | [192, 12, 16] |
| CONV3_2_1 | [32, 8] | [192, 12, 16] | POOL3 | [16, 8] | [192, 12, 16] |
| CONV3_2_2 | [32, 8] | [192, 12, 16] | CONV9 | [32, 8] | [192, 12, 16] |
| CONV4_1_1 | [32, 8] | [192, 12, 16] | POOL4 | [16, 16] | [192, 12, 16] |
| CONV4_1_2 | [32, 8] | [192, 12, 16] | CONV13 | [16, 16] | [192, 12, 16] |
| ResNet18 | VGG16-E | ||||||
|---|---|---|---|---|---|---|---|
| Layers | Single | Temporal | Spatial | Layers | Single | Temporal | Spatial |
| CONV1 | 3.52 | 9.62 | 9.48 | CONV1 | 0.80 | 58.06 | 58.06 |
| POOL1 | 0.03 | CONV2 | 6.97 | ||||
| CONV2_1_1 | 5.03 | 14.65 | 14.65 | POOL1 | 0.05 | 15.09 | 15.09 |
| CONV2_1_2 | 5.03 | CONV3 | 9.50 | ||||
| CONV2_2_1 | 5.03 | 14.65 | 14.65 | CONV4 | 12.91 | 23.02 | 23.93 |
| CONV2_2_2 | 5.03 | POOL2 | 0.053 | ||||
| CONV3_1_1 | 4.73 | 10.90 | 10.80 | CONV5 | 8.53 | 42.47 | 42.47 |
| CONV3_1_2 | 9.95 | CONV6 | 9.68 | ||||
| CONV3_2_1 | 9.95 | 9.90 | 9.90 | POOL3 | 0.05 | 11.76 | 11.76 |
| CONV3_2_2 | 9.95 | CONV9 | 15.95 | ||||
| CONV4_1_1 | 3.99 | 5.10 | 5.05 | POOL4 | 0.05 | 4.83 | 4.83 |
| CONV4_1_2 | 5.12 | CONV13 | 5.58 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valpreda, E.; Morì, P.; Fasfous, N.; Vemparala, M.R.; Frickenstein, A.; Frickenstein, L.; Stechele, W.; Passerone, C.; Masera, G.; Martina, M. HW-Flow-Fusion: Inter-Layer Scheduling for Convolutional Neural Network Accelerators with Dataflow Architectures. Electronics 2022, 11, 2933. https://doi.org/10.3390/electronics11182933
Valpreda E, Morì P, Fasfous N, Vemparala MR, Frickenstein A, Frickenstein L, Stechele W, Passerone C, Masera G, Martina M. HW-Flow-Fusion: Inter-Layer Scheduling for Convolutional Neural Network Accelerators with Dataflow Architectures. Electronics. 2022; 11(18):2933. https://doi.org/10.3390/electronics11182933
Chicago/Turabian StyleValpreda, Emanuele, Pierpaolo Morì, Nael Fasfous, Manoj Rohit Vemparala, Alexander Frickenstein, Lukas Frickenstein, Walter Stechele, Claudio Passerone, Guido Masera, and Maurizio Martina. 2022. "HW-Flow-Fusion: Inter-Layer Scheduling for Convolutional Neural Network Accelerators with Dataflow Architectures" Electronics 11, no. 18: 2933. https://doi.org/10.3390/electronics11182933
APA StyleValpreda, E., Morì, P., Fasfous, N., Vemparala, M. R., Frickenstein, A., Frickenstein, L., Stechele, W., Passerone, C., Masera, G., & Martina, M. (2022). HW-Flow-Fusion: Inter-Layer Scheduling for Convolutional Neural Network Accelerators with Dataflow Architectures. Electronics, 11(18), 2933. https://doi.org/10.3390/electronics11182933