

PDF Malware Detection Based on Optimizable Decision Trees



Abstract
:
1. Introduction
2. Literature Review

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Model | Datasets | Analysis Method | Advantages | Limitation |
|---|---|---|---|---|---|
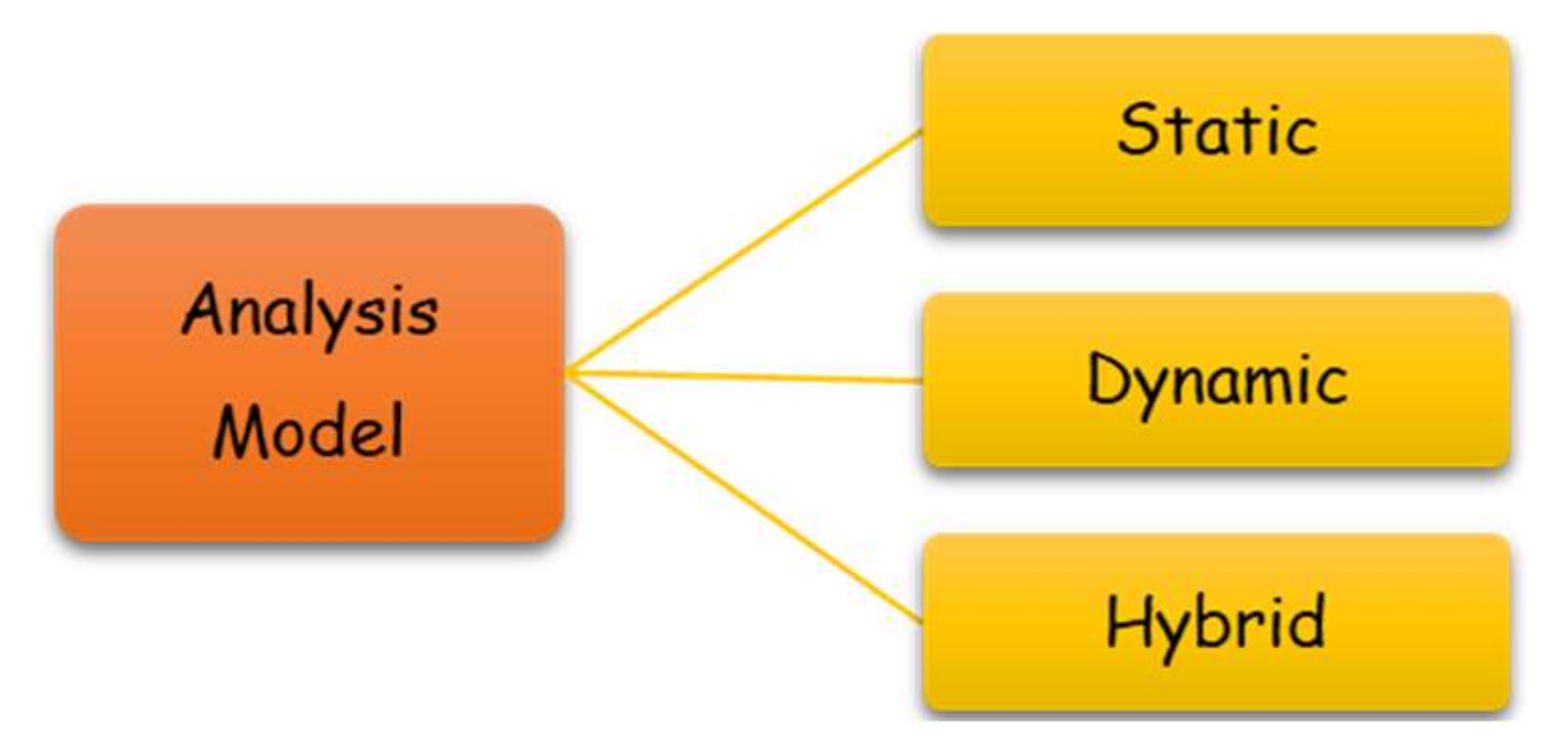
| [22] | SVM, RF | 997 virus files and 490 clean files | Hybrid | The high accuracy rate for static, dynamic, and combined techniques. | Very small dataset |
| [24] | Markov n-gram | 37,000 malware and 1800 benign | Static | The Markov n-gram detector offers higher detection and false-positive rates than the other embedded malware detection method currently in use. | An evasion test is not available. |
| [25] | (J48) classifier | VX Heavens Virus Collection [50] | Static | The proposed model may identify the malware file’s family, such as virus, trojan, etc. | An evasion test is not available. |
| [26] | RF | Contagio [27] | Static | Even though the training set, classification technique, and document features are known, the classifier is resistant to mimicking attacks. | Evasion is much more challenging because classification depends more evenly on many parameters. |
| [28] | RF, C5.0 Decion Tree (DT), and 2-class SVM | Contagio [27] + VirusTool [51] | Static | It gives us a thorough grasp of how these selected features affect classification, and this will improve the training time. | All datasets provided by VirusTotal are benign, and this will make decisions biased. |
| [30] | ensemble classifier (random sampling/bagging) | Contagio [27] | Dynamic | Using real data | It does not examine any potential embedded PDF payload. |
| [32] | Heuristic-based | Contagio [27] | Dynamic | More resistant to code obfuscation | Any API extraction mistakes could compromise the accuracy of the detector. |
| [10] | Bayesian, SVM, J48, and RF | Contagio [27] | Static | Multi-classifier system | Not efficient with different types of embedded malicious codes in PDF files |
| [35] | KNN | Generated Dataset | Static | It drastically lowers false negatives and improves detection accuracy by at least 15%. | An evasion test is not available. |
| [36] | heuristic search, RF, AND DT | Generated Dataset | Static | Identifying advanced persistent threats | It was not tested against evasion techniques and mimicry attacks. |
| [37] | Naive SVM | Dump [52] | Static | Prevent gradient-descent attacks | Slower than other algorithms |
| [39] | RF, SVM, and NB | Contagio malware dump between November 2009 and June 2018 [44] | Static | Adequately for malware detection | Not detect adversarial samples |
| [40] | Convolutional Neural Network (CNN) | VirusTotal | Static | Robustness against evasive samples | Can not detect adversarial samples |
| [41] | Coding style | HAL dataset [53] | Static | Trust generation process for PDF files | Time-consuming: the complexity depends on the file size. |
| [42] | Distance metric in the PDF tree structure | Contagio [27] | Static | Verified robust accuracy | Time-consuming due to insertion and deletion of the tree |
| [43] | Active Learning boost | Generated Dataset | Static | Reducing the training time consumption | Not all outcomes are predictable |
| [44] | Supervised machine learning | Generated Dataset | Hybrid | Both approaches (Dynamic and Static) enhance performance when run separately. | Time consumption |
| [45] | Image Visualization | Contagio [27] | Static | Robust to resist reverse mimicry attacks | An evasion test is not available. |
| [46] | feature-vector generative adversarial network (fvGAN) | generate realistic samples | Static | High evasion rate within a limited time | The complexity depends on the file size, and a 135-dimensional real vector represents each PDF file |
| [47] | Machine Learning methods and traditional malware analysis procedures | Contagio Malware Dump, PRA Lab. | Hybrid | High-performance results in malware detection and analysis | Time consumption |
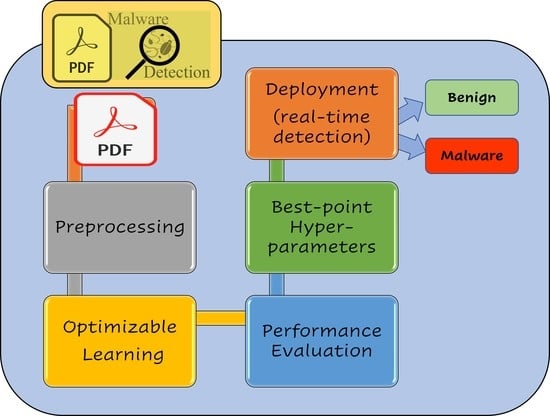
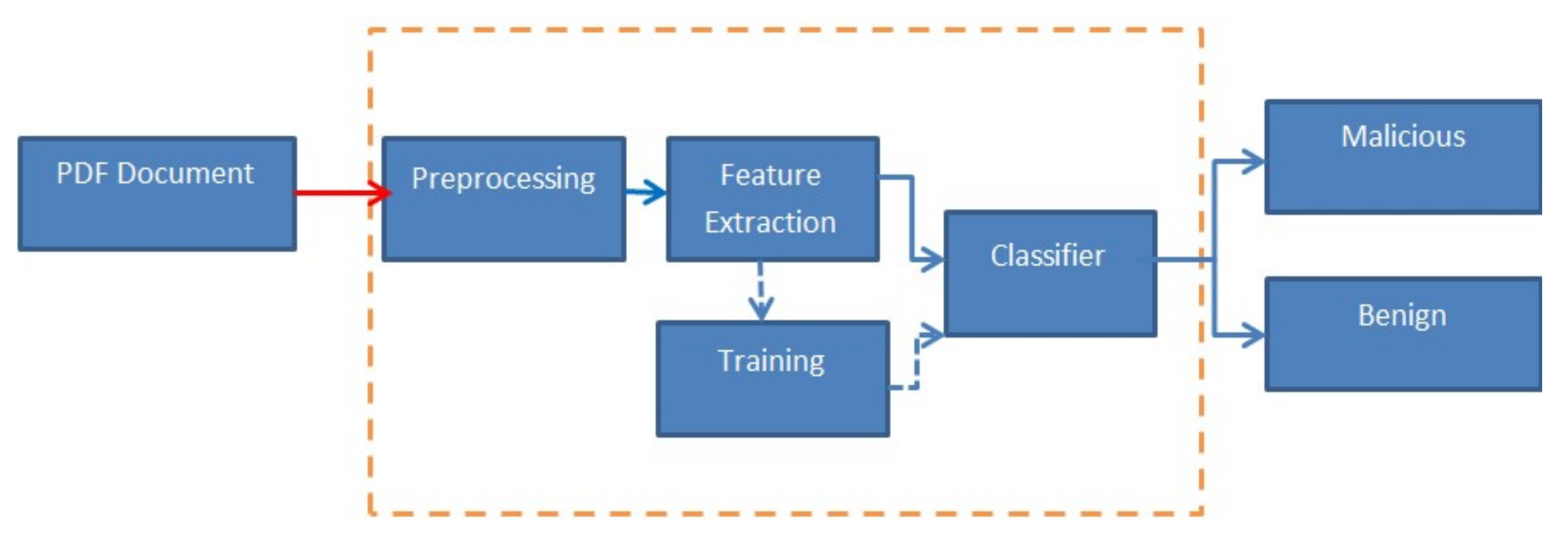
3. Proposed Classification System
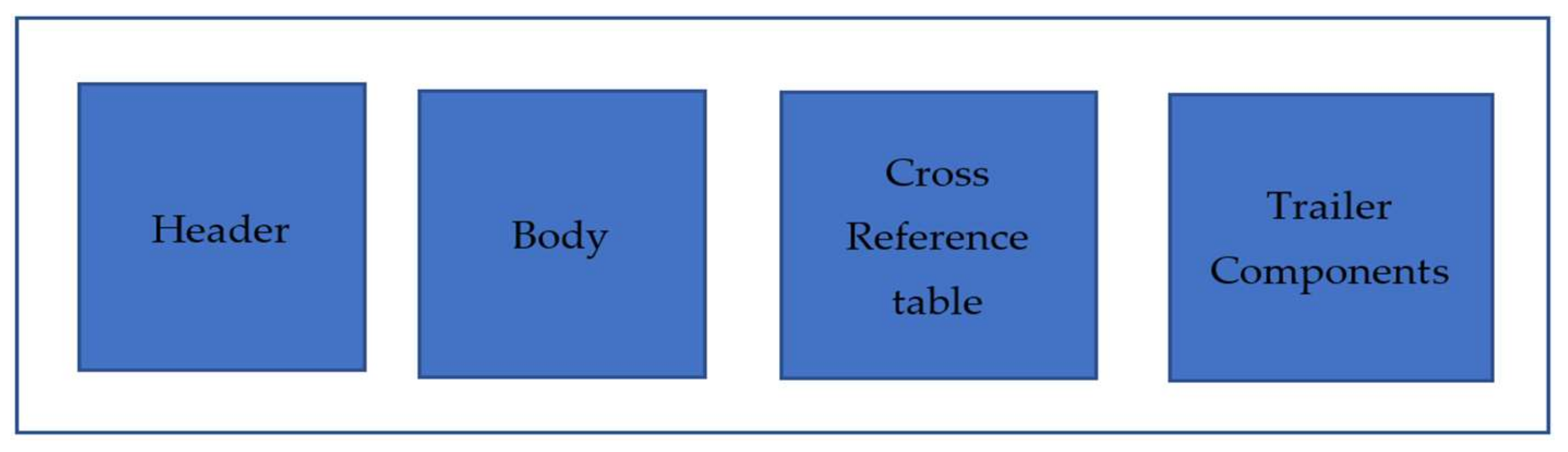
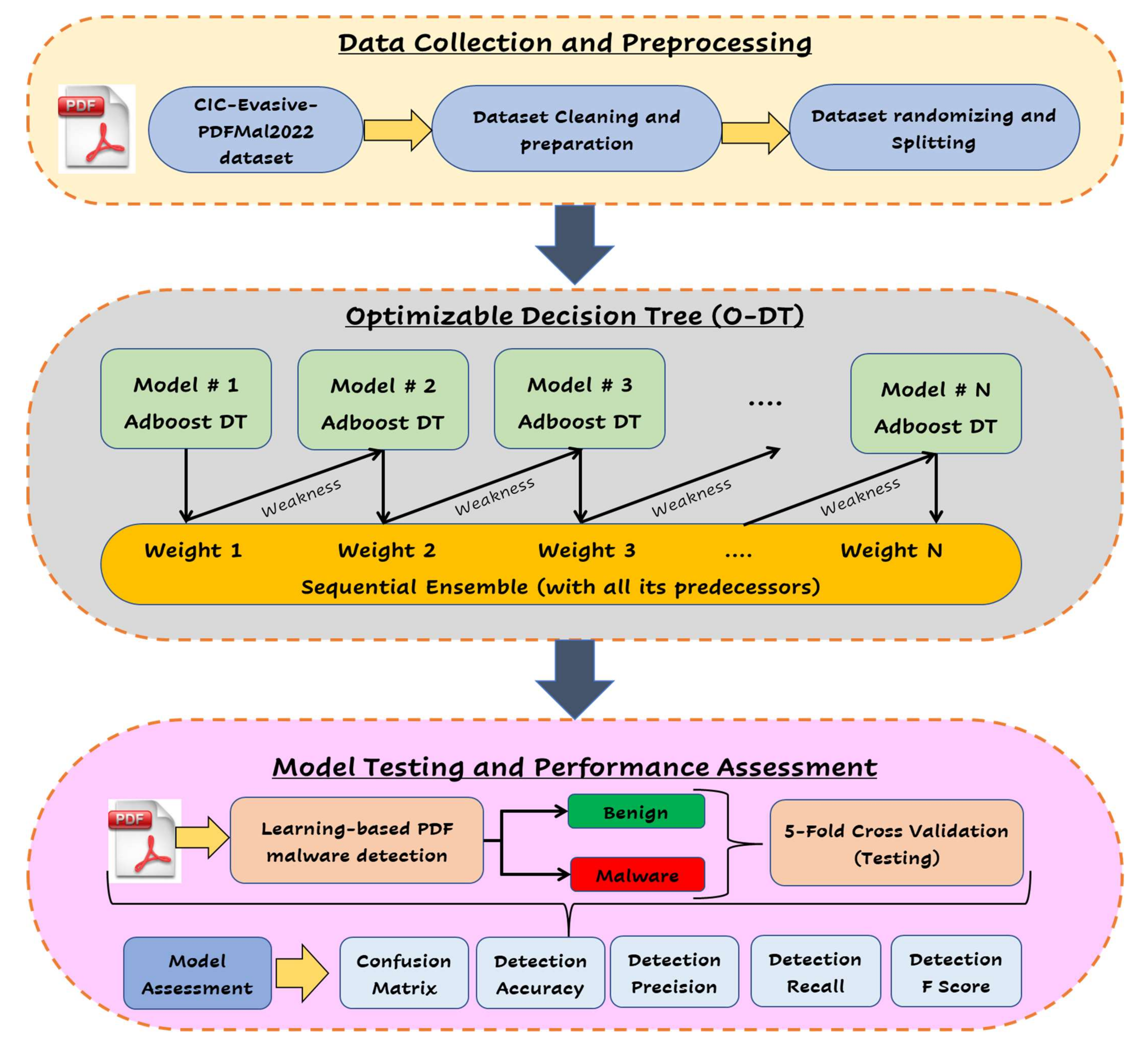
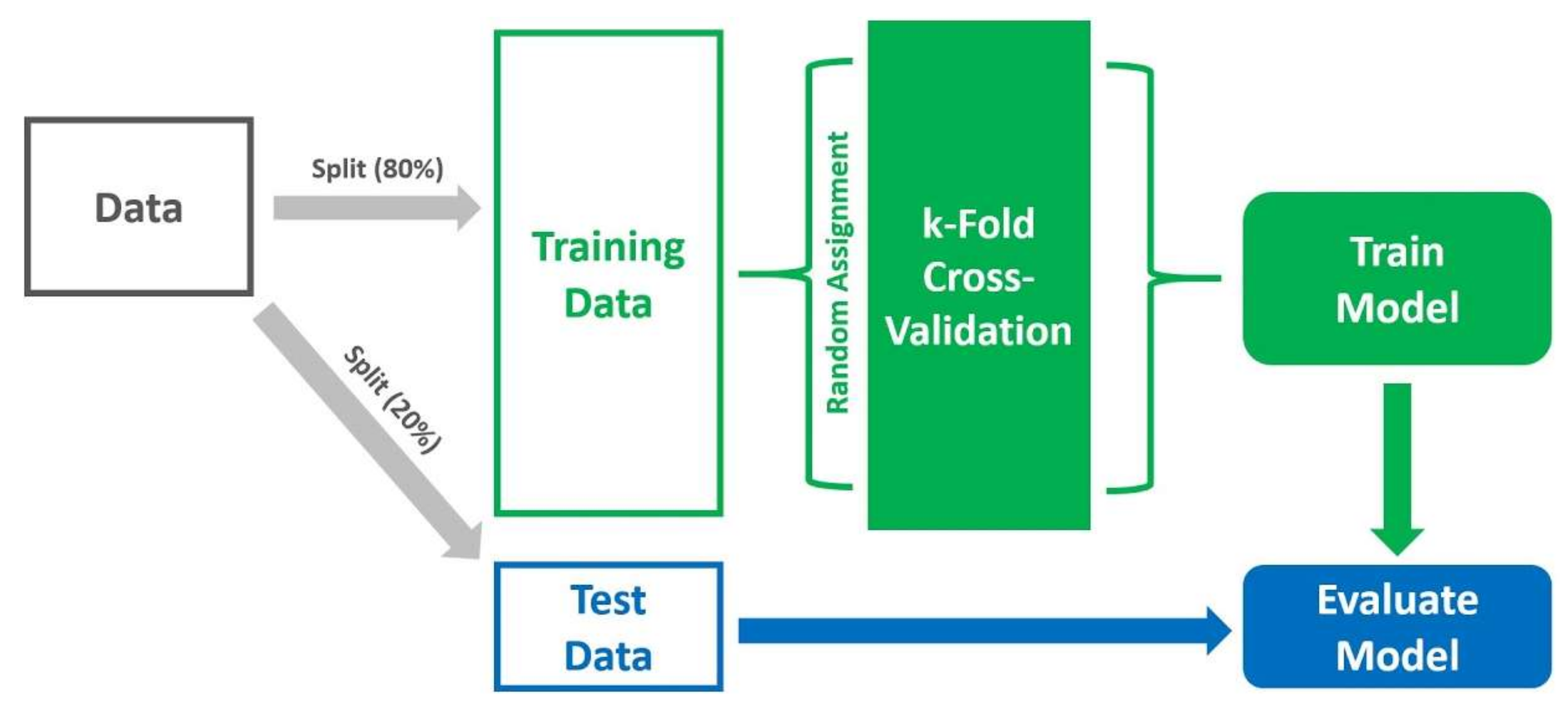
3.1. Data Collection and Preprocessing
3.2. Optimizable Decision Tree (O-DT) Model
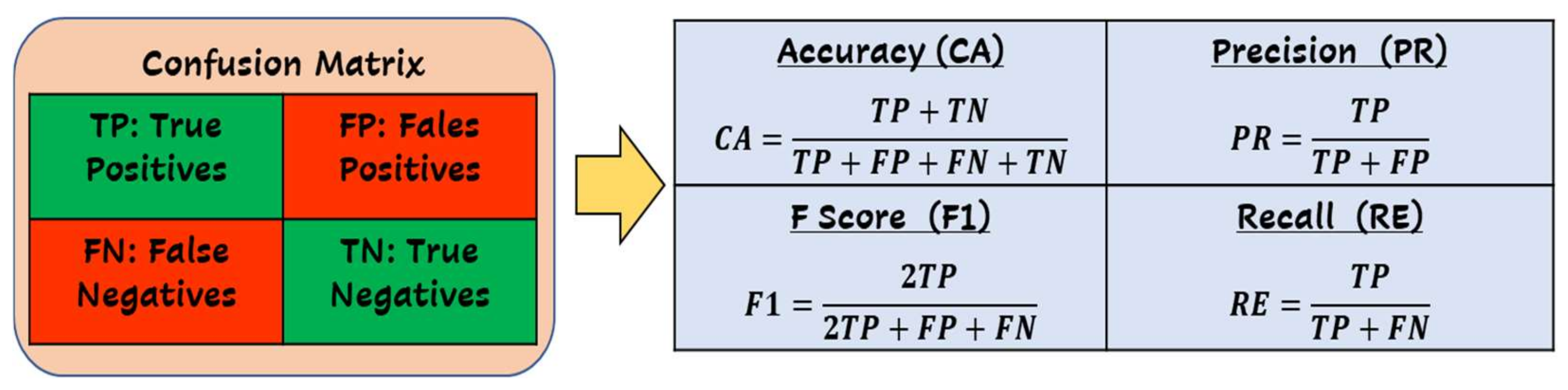
3.3. Model Testing and Evaluation
4. Results and Analysis
5. Conclusions and Remarks
- A comprehensive machine-learning-based model for analyzing PDF documents to identify the malicious PDF files from benign files.
- The proposed model makes use of optimizable decision trees with the AdaBoost algorithm and optimal hyperparameters.
- The proposed model relies on the utilization of a new dataset (Evasive-PDFMal2022) composed of 10,025 records distributed and 37 significant static features (general and structural features) extracted from each PDF file.
- The experimental results proved the efficiency of the proposed PDF detection system, realizing a 98.84% prediction accuracy with a short prediction interval of 2.174 μSec.
- The discussion indicated some gaps in the current state-of-the-art methods which can provide directions for future research.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ndibanje, B.; Kim, K.H.; Kang, Y.J.; Kim, H.H.; Kim, T.Y.; Lee, H.J. Cross-method-based analysis and classification of malicious behavior by API calls extraction. Appl. Sci. 2019, 9, 239. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Al Badawi, A.; Bojja, G.R. Boost-Defence for resilient IoT networks: A head-to-toe approach. Expert Syst. 2022, e12934. [Google Scholar] [CrossRef]
- Ali, M.; Shiaeles, S.; Bendiab, G.; Ghita, B. MALGRA: Machine learning and N-gram malware feature extraction and detection system. Electronics 2020, 9, 1777. [Google Scholar] [CrossRef]
- Faruk, M.J.H.; Shahriar, H.; Valero, M.; Barsha, F.L.; Sobhan, S.; Khan, M.A.; Whitman, M.; Cuzzocrea, A.; Lo, D.; Rahman, A.; et al. Malware detection, and prevention using artificial intelligence techniques. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021. [Google Scholar]
- Ghanei, H.; Manavi, F.; Hamzeh, A. A novel method for malware detection based on hardware events using deep neural networks. J. Comput. Virol. Hacking Tech. 2021, 17, 319–331. [Google Scholar] [CrossRef]
- Atkinson, S.; Carr, G.; Shaw, C.; Zargari, S. Drone forensics: The impact and challenges. In Digital Forensic Investigation of Internet of Things (IoT) Devices; Springer: Berlin/Heidelberg, Germany, 2021; pp. 65–124. [Google Scholar]
- Liu, C.; Lou, C.; Yu, M.; Yiu, S.M.; Chow, K.P.; Li, G.; Jiang, J.; Huang, W. A novel adversarial example detection method for malicious PDFs using multiple mutated classifiers. Forensic Sci. Int. Digit. Investig. 2021, 38, 301124. [Google Scholar] [CrossRef]
- Al-Haijaa, Q.A.; Ishtaiwia, A. Machine Learning Based Model to Identify Firewall Decisions to Improve Cyber-Defense. Int. J. Adv. Sci. Eng. Inf. Technol. 2021, 11, 1688–1695. [Google Scholar] [CrossRef]
- Livathinos, N.; Berrospi, C.; Lysak, M.; Kuropiatnyk, V.; Nassar, A.; Carvalho, A.; Dolfi, M.; Auer, C.; Dinkla, K.; Staar, P. Robust PDF document conversion using recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Wiseman, Y. Efficient embedded images in portable document format. Int. J. 2019, 124, 129–138. [Google Scholar] [CrossRef]
- Ijaz, M.; Durad, M.H.; Ismail, M. Static and dynamic malware analysis using machine learning. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019. [Google Scholar]
- Chakkaravarthy, S.S.; Sangeetha, D.; Vaidehi, V. A malware analysis, and mitigation techniques survey. Comput. Sci. Rev. 2019, 32, 1–23. [Google Scholar] [CrossRef]
- Abdelsalam, M.; Gupta, M.; Mittal, S. Artificial intelligence assisted malware analysis. In Proceedings of the 2021 ACM Workshop on Secure and Trustworthy Cyber-Physical Systems, Virtual Event, 28 April 2021. [Google Scholar]
- Or-Meir, O.; Nissim, N.; Elovici, Y.; Rokach, L. Dynamic malware analysis in the modern era—A state of the art survey. ACM Comput. Surv. 2019, 52, 1–48. [Google Scholar] [CrossRef]
- Albulayhi, K.; Abu Al-Haija, Q.; Alsuhibany, S.A.; Jillepalli, A.A.; Ashrafuzzaman, M.; Sheldon, F.T. IoT Intrusion Detection Using Machine Learning with a Novel High Performing Feature Selection Method. Appl. Sci. 2022, 12, 5015. [Google Scholar] [CrossRef]
- Wang, W.; Shang, Y.; He, Y.; Li, Y.; Liu, J. BotMark: Automated botnet detection with hybrid analysis of flow-based and graph-based traffic behaviors. Inf. Sci. 2020, 511, 284–296. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Al-Saraireh, J. Asymmetric Identification Model for Human-Robot Contacts via Supervised Learning. Symmetry 2022, 14, 591. [Google Scholar] [CrossRef]
- Al-Haija, Q.A.; Gharaibeh, M.; Odeh, A. Detection in Adverse Weather Conditions for Autonomous Vehicles via Deep Learning. AI 2022, 3, 303–317. [Google Scholar] [CrossRef]
- Yang, L.; Ciptadi, A.; Laziuk, I.; Ahmadzadeh, A.; Wang, G. BODMAS: An open dataset for learning based temporal analysis of PE malware. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 21–27 May 2021. [Google Scholar]
- Maiorca, D.; Biggio, B. Digital investigation of pdf files: Unveiling traces of embedded malware. IEEE Secur. Priv. 2019, 17, 63–71. [Google Scholar] [CrossRef]
- Wu, Y.X.; Wu, Q.B.; Zhu, J.Q. Data-driven wind speed forecasting using deep feature extraction and LSTM. IET Renew. Power Gener. 2019, 13, 2062–2069. [Google Scholar] [CrossRef]
- Shijo, P.; Salim, A. Integrated static and dynamic analysis for malware detection. Procedia Comput. Sci. 2015, 46, 804–811. [Google Scholar] [CrossRef]
- Al-Haija, A.Q. Top-Down Machine Learning-Based Architecture for Cyberattacks Identification and Classification in IoT Communication Networks. Front. Big Data 2022, 4, 782902. [Google Scholar] [CrossRef]
- Shafiq, M.Z.; Khayam, S.A.; Farooq, M. Embedded malware detection using Markov n-grams. In Proceedings of the International Conference on Detection of Intrusions and Malware and Vulnerability Assessment, Paris, France, 10–11 July 2008. [Google Scholar]
- Tabish, S.M.; Shafiq, M.Z.; Farooq, M. Malware detection using statistical analysis of byte-level file content. In Proceedings of the ACM SIGKDD Workshop on CyberSecurity and Intelligence Informatics, Paris, France, 28 June 2009. [Google Scholar]
- Smutz, C.; Stavrou, A. Malicious PDF detection using metadata and structural features. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012. [Google Scholar]
- Contagio, M.P. 2011. Available online: http://contagiodump.blogspot.com/2010/08/malicious-documents-archive-for.html (accessed on 2 September 2022).
- Falah, A.; Pan, L.; Huda, S.; Pokhrel, S.R.; Anwar, A. Improving malicious PDF classifier with feature engineering: A data-driven approach. Future Gener. Comput. Syst. 2021, 115, 314–326. [Google Scholar] [CrossRef]
- Al-Haija, Q.A.; Nasr, K.A. Supervised Regression Study for Electron Microscopy Data. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 2661–2668. [Google Scholar] [CrossRef]
- Smutz, C.; Stavrou, A. When a Tree Falls: Using Diversity in Ensemble Classifiers to Identify Evasion in Malware Detectors. In Proceedings of the The Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Abu Al-Haija, Q. A Stochastic Estimation Framework for Yearly Evolution of Worldwide Electricity Consumption. Forecasting 2021, 3, 256–266. [Google Scholar] [CrossRef]
- Corona, I.; Maiorca, D.; Ariu, D.; Giacinto, G. Lux0r: Detection of malicious pdf-embedded javascript code through discriminant analysis of API references. In Proceedings of the 2014 Workshop on Artificial Intelligence and Security Workshop, New York, NY, USA, 7 November 2014. [Google Scholar]
- Maiorca, D.; Giacinto, G.; Corona, I. A pattern recognition system for malicious pdf file detection. In Proceedings of the International Workshop on Machine Learning and Data Mining in Pattern Recognition, New York, NY, USA, 15–19 July 2012. [Google Scholar]
- Li, M.; Liu, Y.; Yu, M.; Li, G.; Wang, Y.; Liu, C. FEPDF: A robust feature extractor for malicious PDF detection. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, Australia, 1–4 August 2017; pp. 218–224. [Google Scholar] [CrossRef]
- Li, K.; Gu, Y.; Zhang, P.; An, W.; Li, W. Research on KNN algorithm in malicious PDF file classification under adversarial environment. In Proceedings of the 2019 4th International Conference on Big Data and Computing, Guangzhou, China, 10–12 May 2019. [Google Scholar]
- Sayed, S.G.; Shawkey, M. Data mining-based strategy for detecting malicious PDF files. In Proceedings of the 2018 17th IEEE International Conference On Trust, Security, and Privacy in Computing and Communica-tions/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018. [Google Scholar]
- Cuan, B.; Damien, A.; Delaplace, C.; Valois, M. Malware detection in pdf files using machine learning. In Proceedings of the SECRYPT 2018-15th International Conference on Security and Cryptography, Porto, Portugal, 26–28 July 2018. [Google Scholar]
- Badawi, A.A.; Al-Haija, Q.A. Detection of money laundering in bitcoin transactions. In Proceedings of the 4th Smart Cities Symposium (SCS 2021), Online Conference, Bahrain, 21–23 November 2021; pp. 458–464. [Google Scholar] [CrossRef]
- Kang, A.R.; Jeong, Y.S.; Kim, S.L.; Woo, J. Malicious PDF detection model against adversarial attack built from benign PDF containing javascript. Appl. Sci. 2019, 9, 4764. [Google Scholar] [CrossRef]
- He, K.; Zhu, Y.; He, Y.; Liu, L.; Lu, B.; Lin, W. Detection of Malicious PDF Files Using a Two-Stage Machine Learning Algorithm. Chin. J. Electron. 2020, 29, 1165–1177. [Google Scholar] [CrossRef]
- Adhatarao, S.; Lauradoux, C. Robust PDF files forensics using coding style. In Proceedings of the IFIP International Conference on ICT Systems Security and Privacy Protection, Copenhagen, Denmark, 13–15 June 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Singh, P.; Tapaswi, S.; Gupta, S. Malware detection in pdf and office documents: A survey. Inf. Secur. J. A Glob. Perspect. 2020, 29, 134–153. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, S.; She, D.; Jana, S. On training robust {PDF} malware classifiers. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Berkeley, CA, USA, 12–14 August 2020; pp. 2343–2360. [Google Scholar]
- Li, Y.; Wang, X.; Shi, Z.; Zhang, R.; Xue, J.; Wang, Z. Boosting training for PDF malware classifier via active learning. Int. J. Intell. Syst. 2022, 37, 2803–2821. [Google Scholar] [CrossRef]
- Santos, I.; Devesa, J.; Brezo, F.; Nieves, J.; Bringas, P.G. Open A static-dynamic approach for machine-learning-based malware detection. In Proceedings of the International Joint Conference CISIS’12-ICEUTE´ 12-SOCO´ 12 Special Sessions, Ostrava, Czech Republic, 5–7 September 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 271–280. [Google Scholar]
- Corum, A.; Jenkins, D.; Zheng, J. Robust PDF malware detection with image visualization and processing techniques. In Proceedings of the 2019 2nd International Conference on Data Intelligence and Security (ICDIS), South Padre Island, TX, USA, 28–30 June 2019; pp. 108–114. [Google Scholar]
- Li, Y.; Wang, Y.; Wang, Y.; Ke, L.; Tan, Y.A. A feature-vector generative adversarial network for evading PDF malware classifiers. Inf. Sci. 2020, 523, 38–48. [Google Scholar] [CrossRef]
- Tay, K.Y.; Chua, S.; Chua, M.; Balachandran, V. Towards Robust Detection of PDF-based Malware. In Proceedings of the Twelfth ACM Conference on Data and Application Security and Privacy, Baltimore, MD, USA, 24–27 April 2022; pp. 370–372. [Google Scholar]
- Maiorca, D.; Biggio, B.; Giacinto, G. Towards adversarial malware detection: Lessons learned from PDF-based attacks. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef]
- VX Heavens Virus Collection, VX Heavens Website. Available online: http://vx.netlux.org (accessed on 21 July 2022).
- Available online: https://www.virustotal.com/gui/home/upload (accessed on 19 September 2022).
- Contaigo, 16,800 Clean and 11,960 Malicious Files for Signature Testing and Research. 2013. Available online: http://contagiodump.blogspot.com/2013/03/16800-clean-and-11960-malicious-files.html (accessed on 19 September 2022).
- Available online: https://hal.archives-ouvertes.fr/ (accessed on 19 September 2022).
- Abu Al-Haija, Q.; Al-Dala’ien, M. ELBA-IoT: An Ensemble Learning Model for Botnet Attack Detection in IoT Networks. J. Sens. Actuator Netw. 2022, 11, 18. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Al Badawi, A. High-performance intrusion detection system for networked UAVs via deep learning. Neural Comput. Appl. 2022, 34, 10885–10900. [Google Scholar] [CrossRef]
- Odeh, A.; Keshta, I.; Al-Haija, Q.A. Analysis of Blockchain in the Healthcare Sector: Application and Issues. Symmetry 2022, 14, 1760. [Google Scholar] [CrossRef]
- PDF Dataset. CIC-Evasive-PDFMal2022. Canadian Institute for Cybersecurity (CIC). 2022. Available online: https://www.unb.ca/cic/datasets/pdfmal-2022.html (accessed on 1 June 2022).
- Zhang, J. MLPdf: An Effective Machine Learning Based Approach for PDF Malware Detection. Cryptography and Security (cs.CR). arXiv 2018, arXiv:1808.06991. [Google Scholar]
- Jiang, J.; Song, N.; Yu, M.; Chow, K.P.; Li, G.; Liu, C.; Huang, W. Detecting Malicious PDF Documents Using Semi-Supervised Machine Learning. In Proceedings of the Advances in Digital Forensics XVII. Digital Forensics 2021, Virtual Event, 1–2 February 2021; IFIP Advances in Information and Communication Technology; Peterson, G., Shenoi, S., Eds.; Springer: Cham, Switzerland, 2021; Volume 612. [Google Scholar] [CrossRef]
- Nissim, N.; Cohen, A.; Moskovitch, R.; Shabtai, A.; Edry, M.; Bar-Ad, O.; Elovici, Y. ALPD: Active Learning Framework for Enhancing the Detection of Malicious PDF Files. In Proceedings of the 2014 IEEE Joint Intelligence and Security Informatics Conference, Washington, DC, USA, 24–26 September 2014; pp. 91–98. [Google Scholar] [CrossRef]
- Mohammed, T.M.; Nataraj, L.; Chikkagoudar, S.; Chandrasekaran, S.; Manjunath, B. Malware detection using frequency domain-based image visualization and deep learning. In Proceedings of the 54th Hawaii International Conference on System Sciences, Grand Wailea, HI, USA, 5–8 January 2021; p. 7132. [Google Scholar]
- Nataraj, L.; Manjunath, B.S.; Chandrasekaran, S. Malware Classification and Detection Using Audio Descriptors. U.S. Patent 11244050B2, 4 June 2020. [Google Scholar]
- Nataraj, L.; Mohammed, T.M.; Nanjundaswamy, T.; Chikkagoudar, S.; Chandrasekaran, S.; Manjunath, B.S. OMD: Orthogonal Malware Detection using Audio, Image, and Static Features. In Proceedings of the MILCOM 2021–2021 IEEE Military Communications Conference (MILCOM), San Diego, CA, USA, 29 November–1 December 2021. [Google Scholar]
- Cohen, A.; Nissim, N.; Wu, J.; Lanzi, A.; Rokach, L.; Elovici, Y.; Giles, L. Sec-Lib: Protecting Scholarly Digital Libraries From Infected Papers Using Active Machine Learning Framework. IEEE Access 2019, 7, 110050–110073. [Google Scholar] [CrossRef]
- Al-Haija, Q.A.; Saleh, E.; Alnabhan, M. Detecting Port Scan Attacks Using Logistic Regression. In Proceedings of the 2021 4th International Symposium on Advanced Electrical and Communication Technologies (ISAECT), Casablanca, Morocco, 15–17 March 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Krichen, M. A Lightweight In-Vehicle Alcohol Detection Using Smart Sensing and Supervised Learning. Computers 2022, 11, 121. [Google Scholar] [CrossRef]








| Factor | Description |
|---|---|
| Preset | Optimizable Tree |
| Learning algorithm | AdaBoost Tree |
| Split criterion | Twoing rule |
| Surrogate decision splits | Off |
| Maximum number of splits | 6704 |
| Optimizer | Random Search |
| Iterations | 30 |
| Training time limit | False |
| Feature Selection | All features used in the model, No PCA |
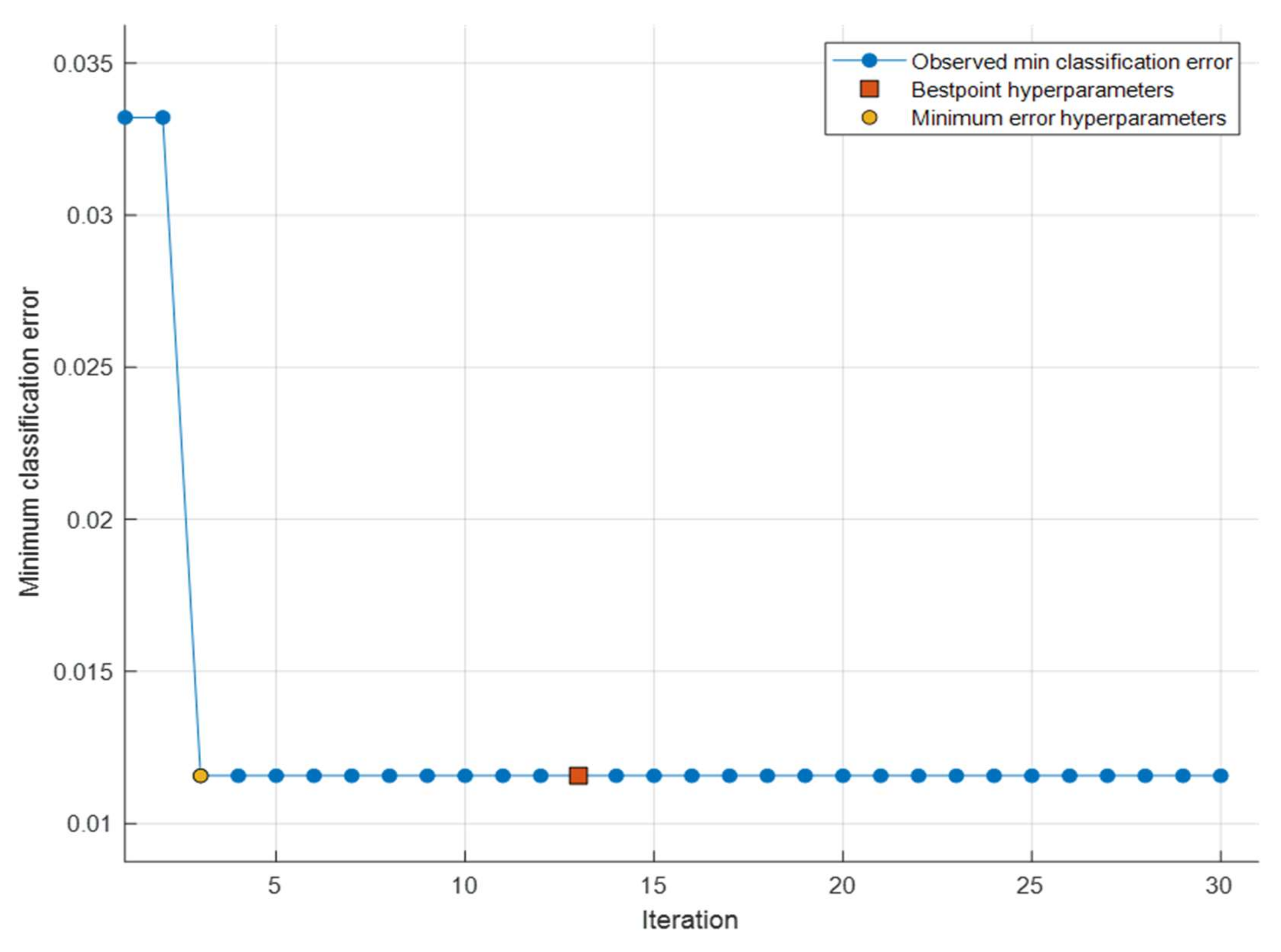
| Cost function | Minimum Classification Error |
| Factor | Value | Factor | Value |
|---|---|---|---|
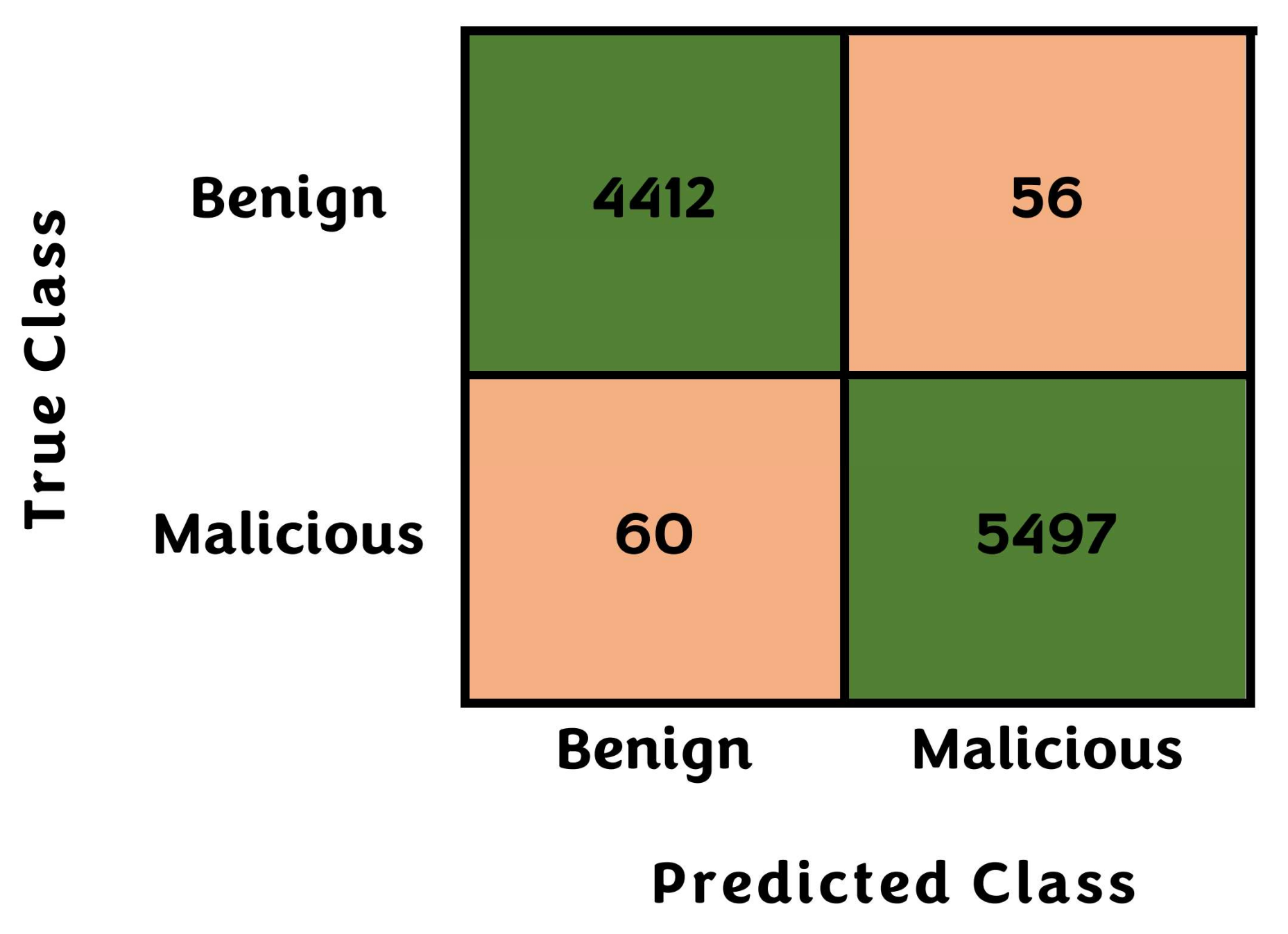
| IPS | 116 samples | CA | 98.84% |
| CPS | 9909 samples | AUC | 99.00% |
| TNS | 10,025 Samples | RE | 98.90% |
| PS | ~ 460,000 obs/sec | PR | 98.80% |
| PT | 2.174 µSec | F1 | 98.85% |
| TT | 11.848 s | BCA | 98.95% |
| Ref. | Model | Accuracy | Precision | Sensitivity | F Score |
|---|---|---|---|---|---|
| Zhang. et al. [58]/2018 | MLP-NN | - | - | 95.12% | - |
| Jiang et al. [34]/2021 | Semi-SL | 94.00% | - | - | - |
| Li et al. [59]/2017 | JSUNPACK | 95.11% | 97.57% | 90.87% | 94.10% |
| Nissim et al. [60]/2014 | SVM-Margin | - | - | 97.70% | - |
| Mohammed et al. [61]/2021 | ResNet-50 CNN | 89.56% | - | - | - |
| Nataraj et al. [62]/2020 | RFC | 96.94% | - | - | - |
| Lakshmanan et al. [63]/2020 | VEC | 95.93% | - | - | - |
| Cohen et al. [64]/2019 | SVM-Margin | - | - | 96.90% | - |
| Proposed | O-DT | 98.84% | 98.80% | 98.90% | 98.80% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abu Al-Haija, Q.; Odeh, A.; Qattous, H. PDF Malware Detection Based on Optimizable Decision Trees. Electronics 2022, 11, 3142. https://doi.org/10.3390/electronics11193142
Abu Al-Haija Q, Odeh A, Qattous H. PDF Malware Detection Based on Optimizable Decision Trees. Electronics. 2022; 11(19):3142. https://doi.org/10.3390/electronics11193142
Chicago/Turabian StyleAbu Al-Haija, Qasem, Ammar Odeh, and Hazem Qattous. 2022. "PDF Malware Detection Based on Optimizable Decision Trees" Electronics 11, no. 19: 3142. https://doi.org/10.3390/electronics11193142
APA StyleAbu Al-Haija, Q., Odeh, A., & Qattous, H. (2022). PDF Malware Detection Based on Optimizable Decision Trees. Electronics, 11(19), 3142. https://doi.org/10.3390/electronics11193142