
Short-Term Load Forecasting with an Ensemble Model Based on 1D-UCNN and Bi-LSTM



Abstract
:1. Introduction
- We designed a densely connected residual block (DCRB) based on an unshared convolutional layer (UCL), which can effectively relieve over-fitting and gradient disappearance;
- We proposed a novel ensemble method for deterministic electricity load forecasting. The model includes a one-dimensional unshared convolutional neural network (1D-UCNN) and a bidirectional long short-term memory layer (Bi-LSTM). In addition, the generalization ability of the proposed model was verified by testing it on two benchmark datasets.
2. Method
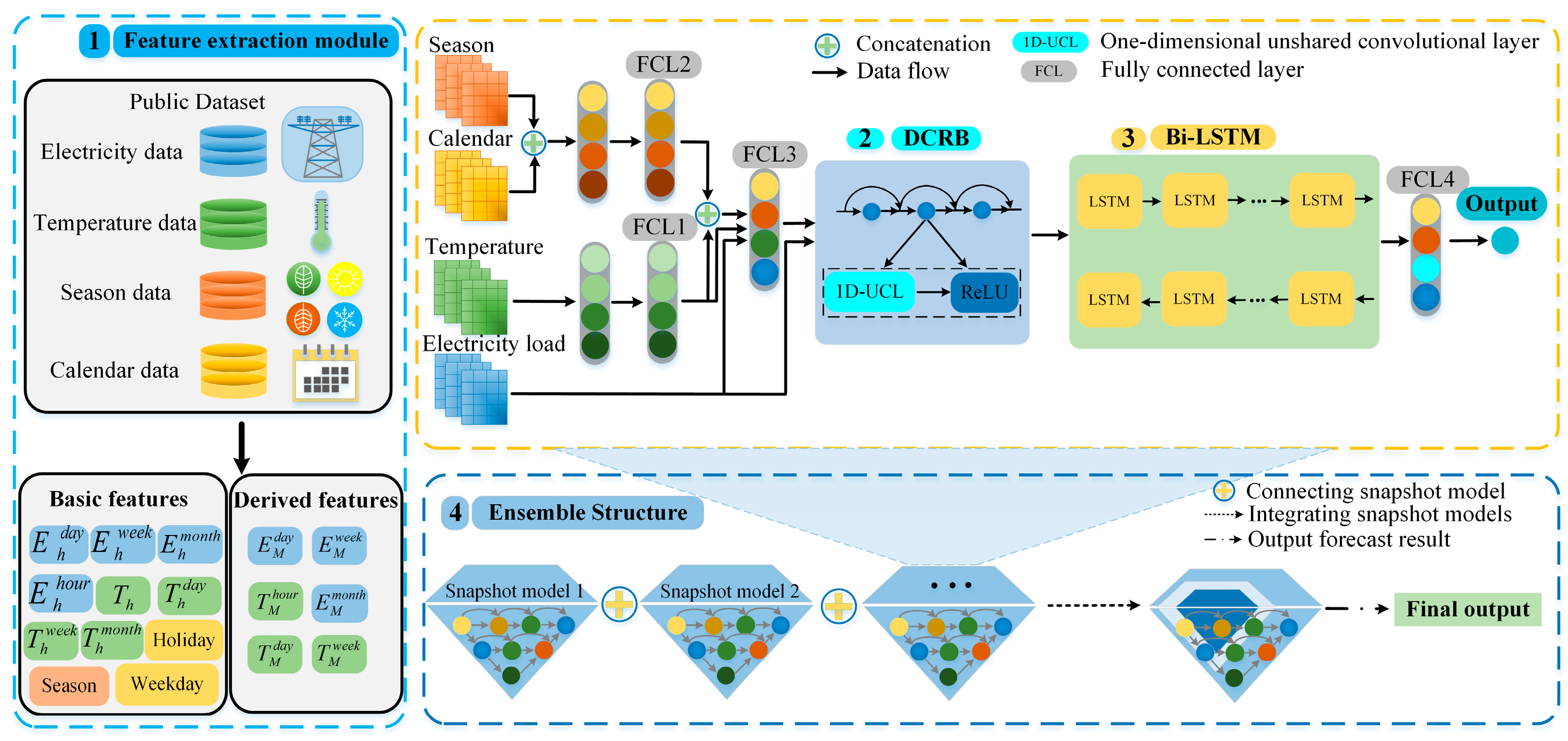
2.1. Overall Framework
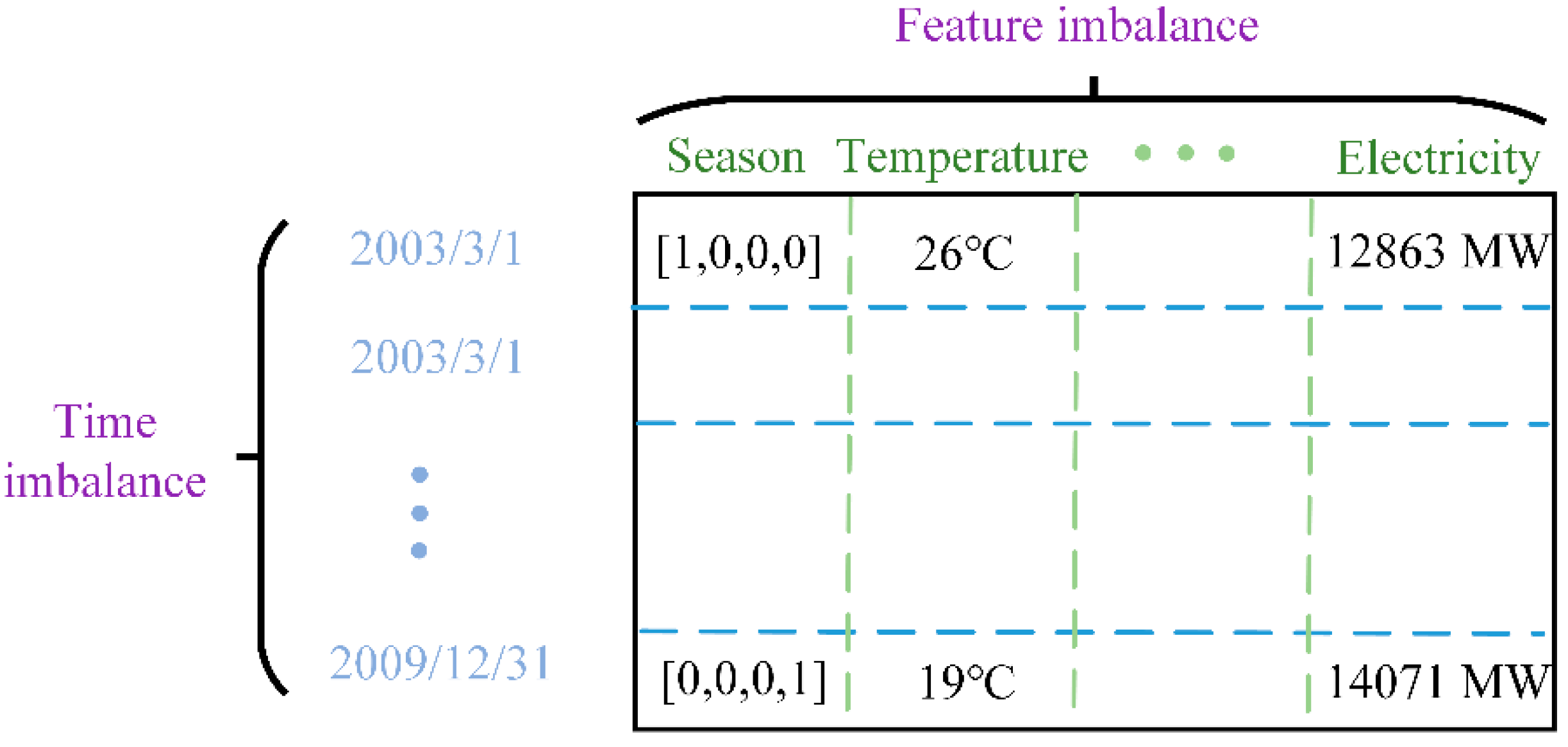
2.2. Feature Extraction
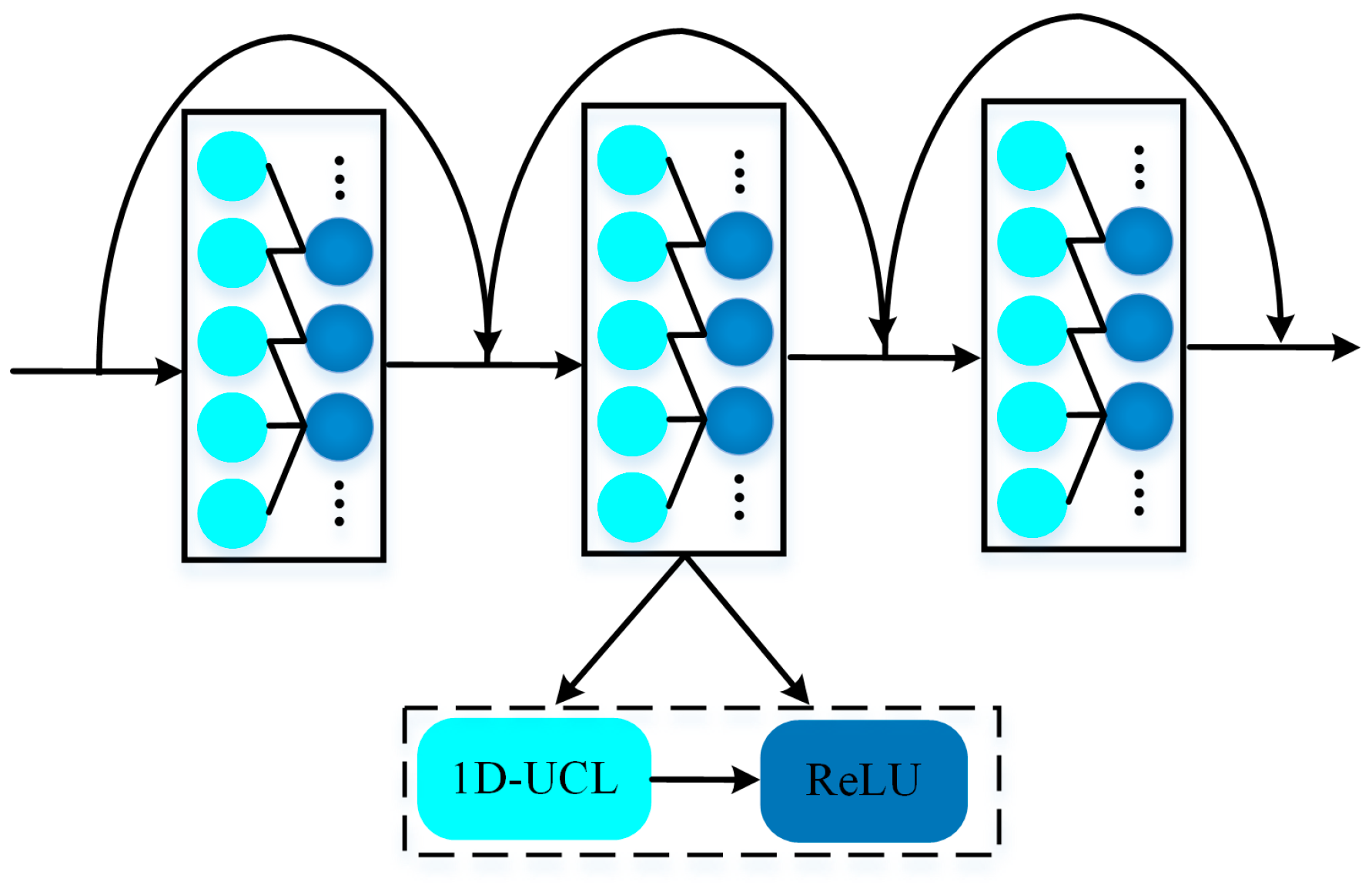
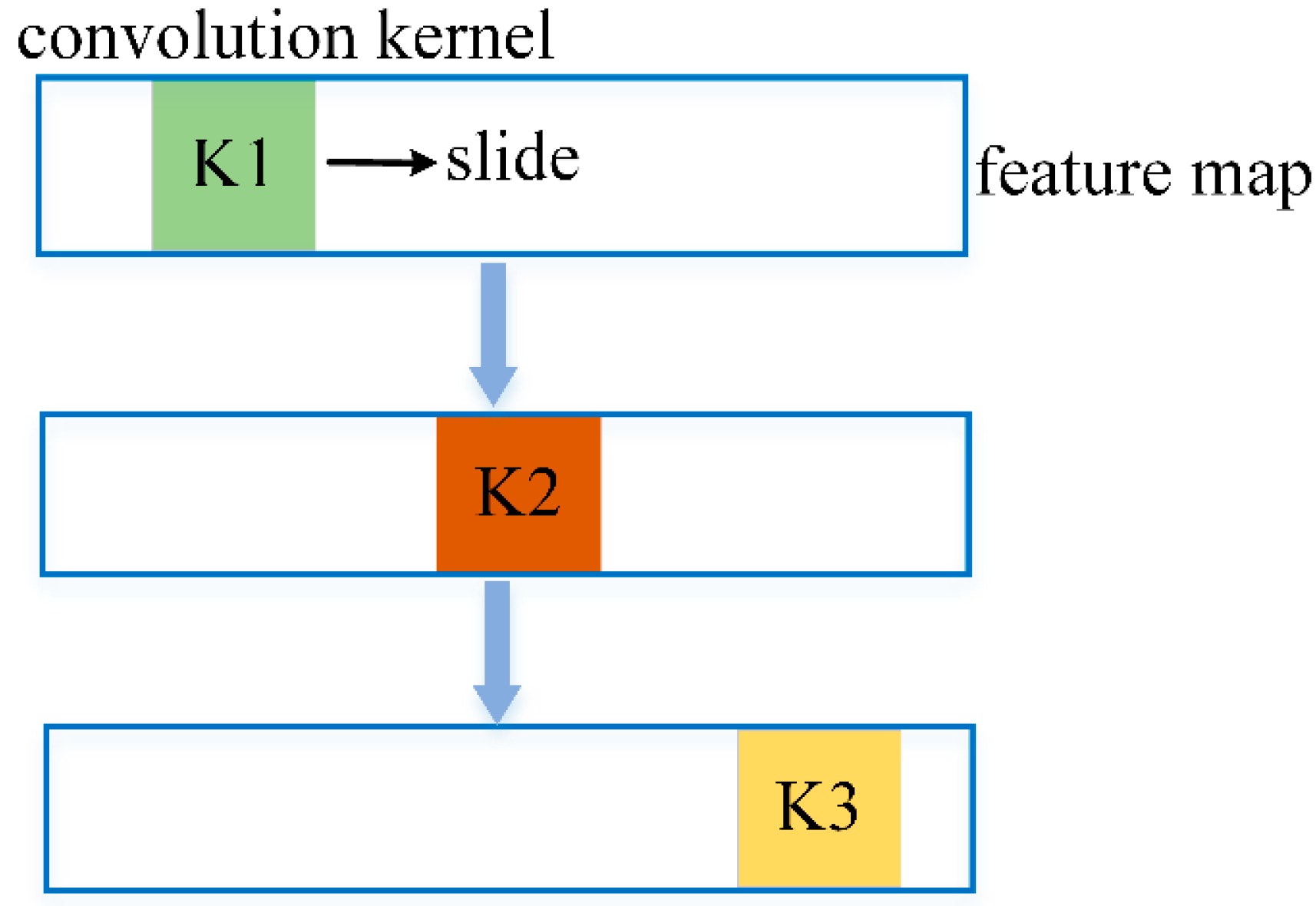
2.3. Densely Connected Residual Block
2.4. Bidirectional Long Short-Term Memory (Bi-LSTM)
2.5. Ensemble Structure
3. Experiment Results
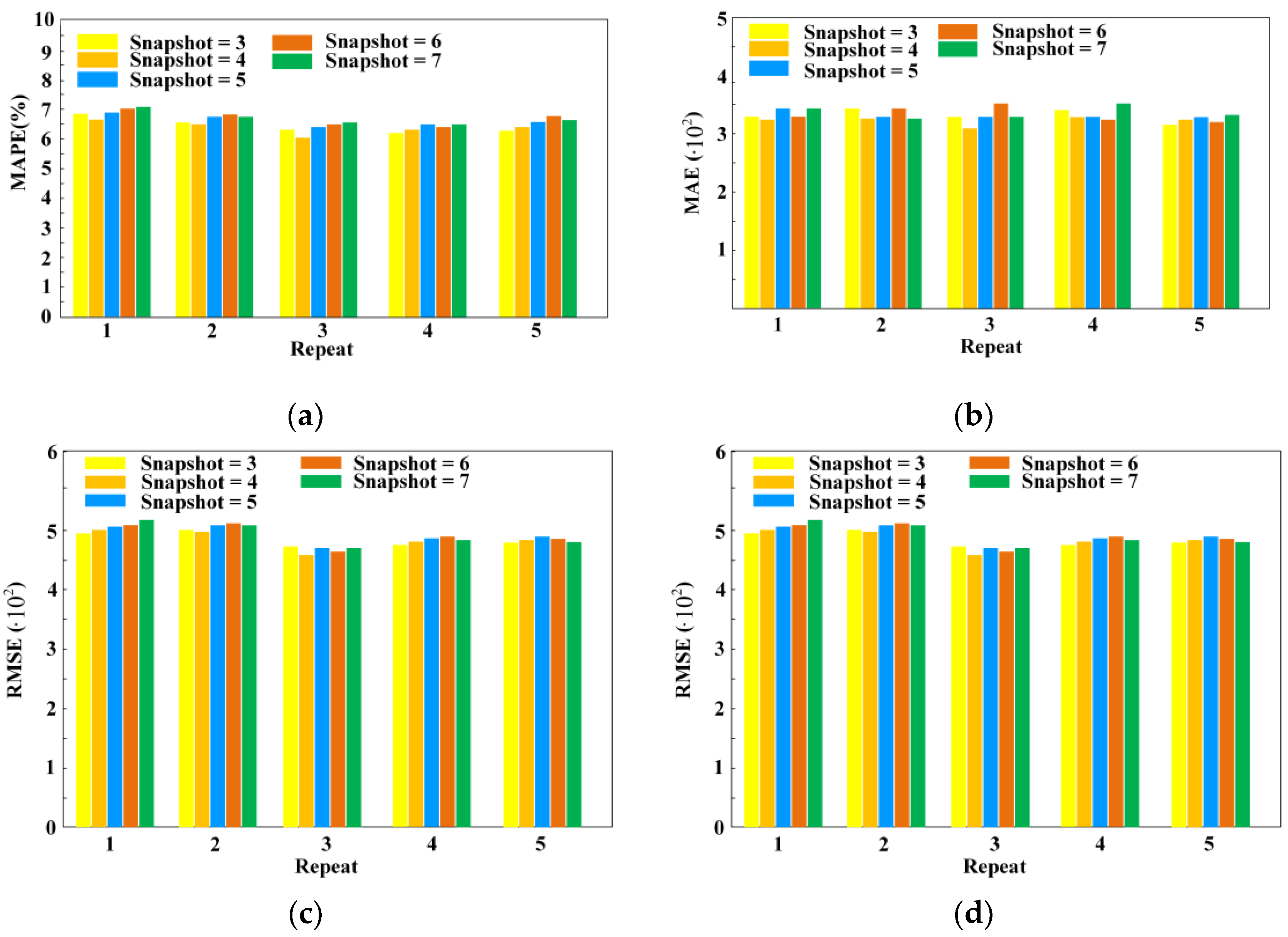
3.1. Test Settings
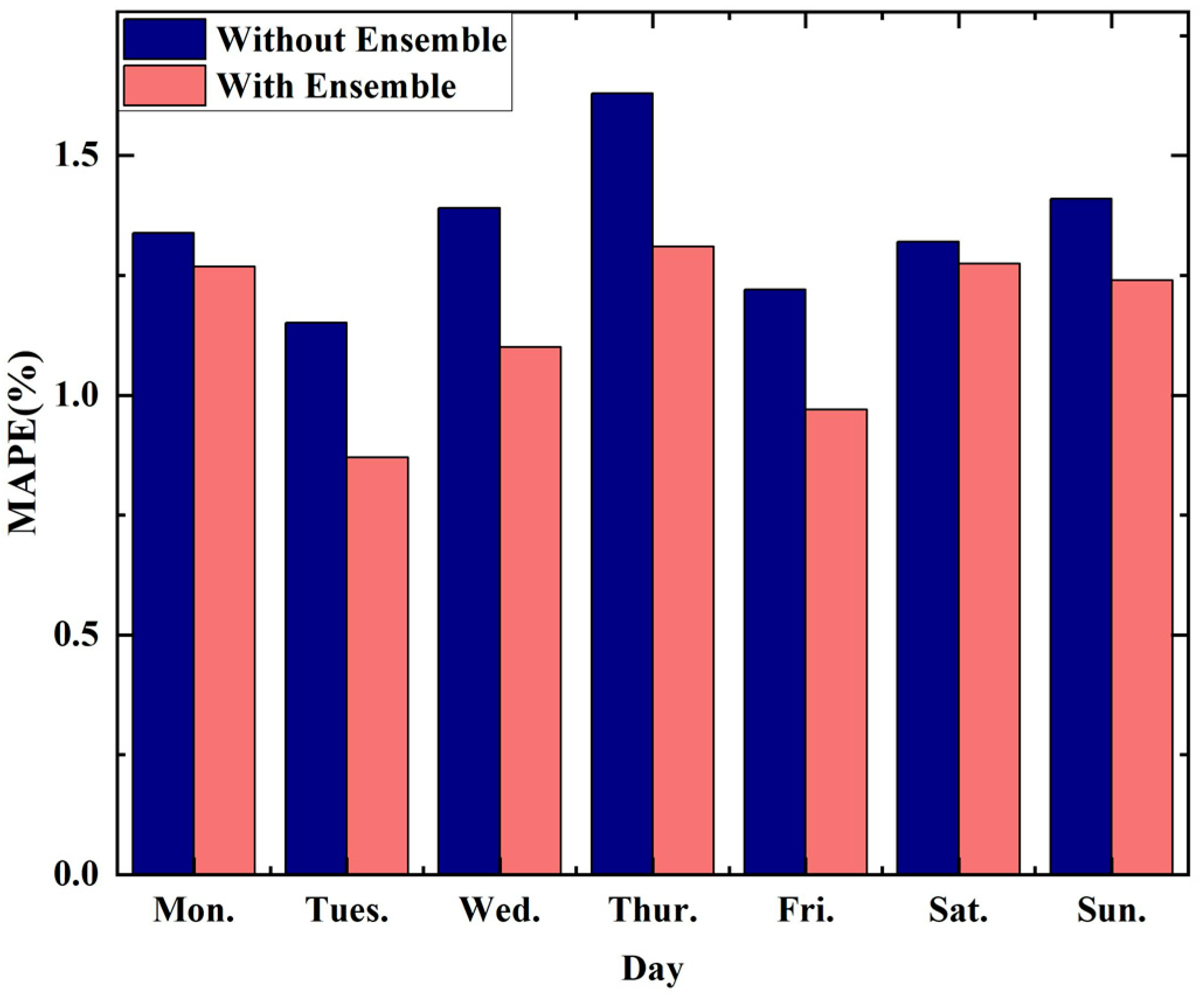
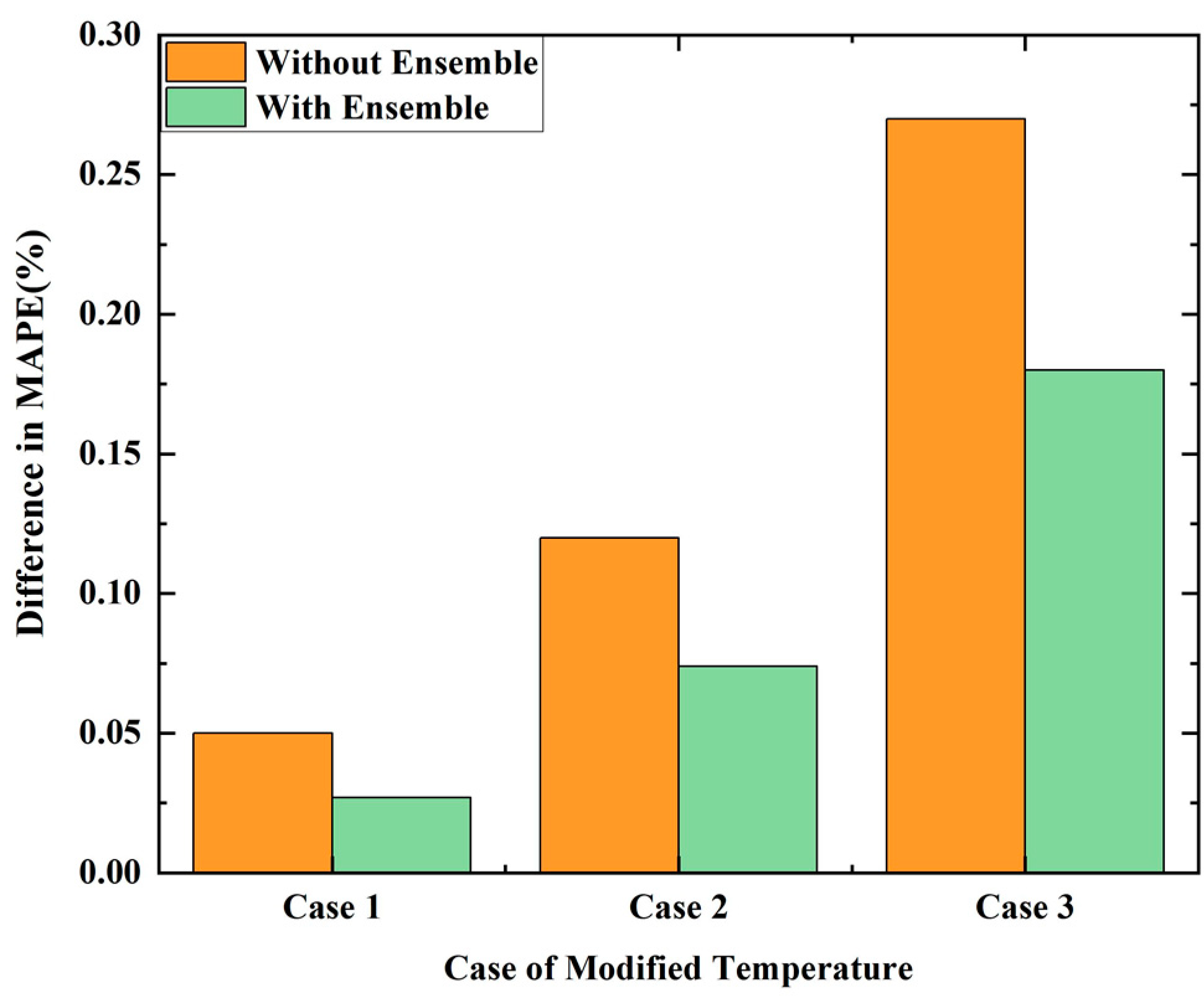
3.2. Results of the North American Dataset
3.3. Results of the New England Dataset
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Acronyms | |
| LTLF | Long-term load forecasting |
| MTLF | Medium-term load forecasting |
| STLF | Short-term load forecasting |
| AR | Auto-regressive |
| ARMA | Auto-regressive moving average |
| ARIMA | Auto-regressive integrated moving average |
| SVM | Support vector machine |
| GRNN | Generalized regression neural network |
| WNN | Wavelet neural network |
| CNN | Convolutional neural network |
| LSTM | Long short-term memory network |
| ANN | Artificial neural network |
| Bi-LSTM | Bidirectional long short-term memory network |
| MAPE | Mean absolute percentage error |
| MAE | Mean absolute error |
| MSE | Mean-squared error |
| RMSE | Root-mean-squared error |
| DCRB | Densely connected residual block |
| ESN | Echo state network |
| Nomenclature | |
| xi | Training data |
| yi | Forecasted value |
| Θ | 1D-UCNN model |
| h | Convolution area |
| o | Convolutional output |
| Ψ | Unshared convolution operator |
| g | Input data |
| f | Forget gate |
| q | Output gate |
| Self-recurrent unit | |
| s | Internal memory unit of each LSTM cell |
| Forward propagation output | |
| Backward propagation output | |
References
- Wu, L.; Shahidehpour, M. A hybrid model for day-ahead price forecasting. IEEE Trans. Power Syst. 2010, 25, 519–1530. [Google Scholar]
- Abedinia, O.; Amjady, N.; Zareipour, H. A new feature selection technique for load and price forecast of electrical power systems. IEEE Trans. Power Syst. 2017, 32, 62–74. [Google Scholar] [CrossRef]
- Chen, X.; Hou, Y.; Hui, S.Y.R. Distributed control of multiple electric springs for voltage control in microgrid. IEEE Trans. Smart Grid 2017, 8, 1350–1359. [Google Scholar] [CrossRef]
- Borges, C.E.; Penya, Y.K.; Fernandez, I. Evaluating combined load forecasting in large power systems and smart grids. IEEE Trans. Ind. Informat. 2013, 9, 1570–1577. [Google Scholar] [CrossRef]
- Chen, X.; Shi, M.; Sun, H.; Li, Y.; He, H. Distributed cooperative control and stability analysis of multiple DC electric springs in a DC microgrid. IEEE Trans. Ind. Electron. 2018, 65, 5611–5622. [Google Scholar] [CrossRef]
- Hippert, H.S.; Pedreira, C.E.; Souza, R.C. Neural networks for short-term load forecasting: A review and evaluation. IEEE Trans. Power Syst. 2001, 16, 44–55. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Mbamalu, G.; Hawary, M. Load forecasting via suboptimal seasonal autoregressive models and iteratively reweighted least squares estimation. IEEE Trans. Power Syst. 1993, 8, 343–348. [Google Scholar] [CrossRef]
- Huang, S.J.; Shih, K.R. Short-term load forecasting via ARMA model identification including non-gaussian process considerations. IEEE Trans. Power Syst. 2003, 18, 673–679. [Google Scholar] [CrossRef] [Green Version]
- Contreras, J.; Espinola, R.; Nogales, F.J.; Conejo, A.J. ARIMA models to predict next-day electricity prices. IEEE Trans. Power Syst. 2003, 18, 1014–1020. [Google Scholar] [CrossRef]
- Ceperic, E.; Ceperic, V.; Baric, A. A strategy for short-term load forecasting by support vector regression machines. IEEE Trans. Power Syst. 2013, 28, 4356–4364. [Google Scholar] [CrossRef]
- Wu, Z.; Zhao, X.; Ma, Y.; Zhao, X. A hybrid model based on modified multi-objective cuckoo search algorithm for short-term load forecasting. Appl. Energy 2019, 237, 896–909. [Google Scholar] [CrossRef]
- Chen, Y.; Luh, P.B.; Rourke, S.J. Short-term load forecasting: Similar day-based wavelet neural networks. IEEE Trans. Power Syst. 2010, 25, 322–330. [Google Scholar] [CrossRef]
- Arif, A.; Wang, Z.; Wang, J.; Matheret, B.; Bashualdo, H.; Zhao, D. Load modeling—A review. IEEE Trans. Smart Grid 2018, 9, 5986–5999. [Google Scholar] [CrossRef]
- Zhang, H.; Zhu, T. Stacking model for photovoltaic-power-generation prediction. Sustainability 2022, 14, 5669. [Google Scholar] [CrossRef]
- Abdellatif, A.; Mubrak, H.; Ahmad, S.; Ahmed, T.; Shafiullah, G.M.; Hammoudeh, A.; Abdellatef, H.; Rahman, M.M.; Gheni, H.M. Forecasting photovoltaic power generation with a stacking ensemble model. Sustainability 2022, 14, 11083. [Google Scholar] [CrossRef]
- Lateko, A.A.H.; Yang, H.T.; Huang, C.M.; Aprillia, H.; Hsu, C.Y.; Zhong, J.L.; Phuong, N.H. Stacking ensemble method with the RNN meta-learner for short-term PV power forecasting. Energies 2021, 14, 4733. [Google Scholar] [CrossRef]
- Deng, Z.; Wang, B.; Xu, Y.; Xu, T.; Liu, C.; Zhu, Z. Multi-scale convolutional neural network with time-cognition for multi-step short-term load forecasting. IEEE Access 2019, 7, 88058–88071. [Google Scholar] [CrossRef]
- Dong, X.; Qian, L.; Huang, L. Short-term load forecasting in smart grid: A combined CNN and k-means clustering approach. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 119–125. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Tan, M.; Yuan, S.; Liet, S.; Li, H.; He, F. Ultra-short-term industrial power demand forecasting using LSTM based hybrid ensemble learning. IEEE Trans. Power Syst. 2020, 35, 937–2948. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y. Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM. Energy Convers. Manag. 2018, 159, 54–64. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Toubeau, J.; Bottieau, J.; Vallée, F.; Grève, Z.D. Deep learning-based multivariate probabilistic forecasting for short-term scheduling in power markets. IEEE Trans. Power Syst. 2019, 34, 1203–1215. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2016, arXiv:1512.03385. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Du, S.; Li, T.; Yang, Y.; Horng, S.J. Deep air quality forecasting using hybrid deep learning framework. IEEE Trans. Knowl. Data Eng. 2021, 33, 2412–2424. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Li, Y.; Liu, Y.; Wang, P.; Lu, R.; Gooi, H.B. Deep learning based densely connected network for load forecasting. IEEE Trans. Power Syst. 2021, 36, 2829–2840. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, C.; Gao, Z.; Rodrigues, J.J.P.C.; Albuquerque, V.H.C. Industrial pervasive edge computing-based intelligence iot for surveillance saliency detection. IEEE Trans Ind. Informat. 2021, 17, 5012–5020. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Wan, C.; Zhang, Z.; Li, F.; Song, Y. Hybrid ensemble deep learning for deterministic and probabilistic low-voltage load forecasting. IEEE Trans. Power Syst. 2020, 35, 1881–1897. [Google Scholar] [CrossRef]
- Felice, M.D.; Yao, X. Short-term load forecasting with neural network ensembles: A comparative study [application notes]. IEEE Trans Ind. Informat. 2011, 6, 47–56. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Huang, G.; Li, Y.; Pleisse., G. Snapshot ensembles: Train 1, get M for free. arXiv 2017, arXiv:1704.00109. [Google Scholar]
- Chen, K.; Wang, Q.; He, Z.; Hu, J.; He, J. Short-term load forecasting with deep residual networks. IEEE Trans. Smart Grid 2019, 10, 3943–3952. [Google Scholar] [CrossRef] [Green Version]
- Reis, A.R.; Silva, A.A.D. Feature extraction via multiresolution analysis for short-term load forecasting. IEEE Trans. Power Syst. 2005, 20, 189–198. [Google Scholar]
- Amjady, N.; Keynia, F. Short-term load forecasting of power systems by combination of wavelet transform and neuro-evolutionary algorithm. Energy 2009, 34, 46–57. [Google Scholar] [CrossRef]
- Deihimi, A.; Showkati, H. Application of echo state networks in short-term electric load forecasting. Energy 2012, 39, 327–340. [Google Scholar] [CrossRef]
- Eskandari, H.; Imani, M.; Moghaddam, M.P. Convolutional and recurrent neural network-based model for short-term load forecasting. Electr. Pow. Syst. Res. 2021, 195, 107173. [Google Scholar] [CrossRef]
- Xu, Q.; Yang, X.; Huang, X. Ensemble residual networks for short term load forecasting. IEEE Access 2020, 8, 64750–64759. [Google Scholar] [CrossRef]
- Yu, H.; Reiner, P.D.; Xie, T.; Bartczak, T.; Wilamowski, B.M. An incremental design of radial basis function networks. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1793–1803. [Google Scholar] [CrossRef]
- Singh, P.; Dwivedi, P. A novel hybrid model based on neural network and multi-objective optimization for effective load forecast. Energy 2019, 182, 606–622. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Model | Input Variables | Horizon |
|---|---|---|---|
| [8] | AR | Electricity load, temperature | 7 days ahead |
| [9] | ARMA | Time, electricity load | 1 day ahead |
| [11] | SVM | Season, Temperature, and electricity load | 1 h ahead |
| [12] | GRNN | Electricity load | 1 day ahead |
| [13] | WNN | Time, wind speed, and electricity load | 1 day ahead |
| [19] | K-means, CNN | Electricity load | 7 days ahead |
| [21] | LSTM | Time, electricity load | 1 day ahead |
| Proposed model | UCNN, Bi-LSTM | Season, time, electricity load, and temperature | 1 day ahead |
| Symbol | Size | Description of the Inputs |
|---|---|---|
| 24 | Electricity values within 24 h before the hour | |
| 7 | Electricity values of the hour of every day within a week | |
| 4 | Electricity values of the hour of days 7, 14, 21, and 28 before the forecasted day | |
| 3 | Electricity values of the hour of days 28, 56, and 84 before the forecasted day | |
| 1 | The average value of | |
| 1 | The average value of | |
| 1 | The average value of | |
| 1 | The actual temperature of the hour | |
| 7 | Temperatures of the hour of every day within a week | |
| 4 | Temperatures of the hour of days 7, 14, 21, and 28 before the forecasted day | |
| 3 | Temperatures of the hour of days 28, 56, and 84 before the forecasted day | |
| 1 | The average value of | |
| 1 | The average value of | |
| 1 | The average value of | |
| 4 | One-hot encoding for season | |
| 2 | One-hot encoding for weekday/weekend | |
| 2 | One-hot encoding for holiday |
| Model | Actual Temperature | Noisy Temperature |
|---|---|---|
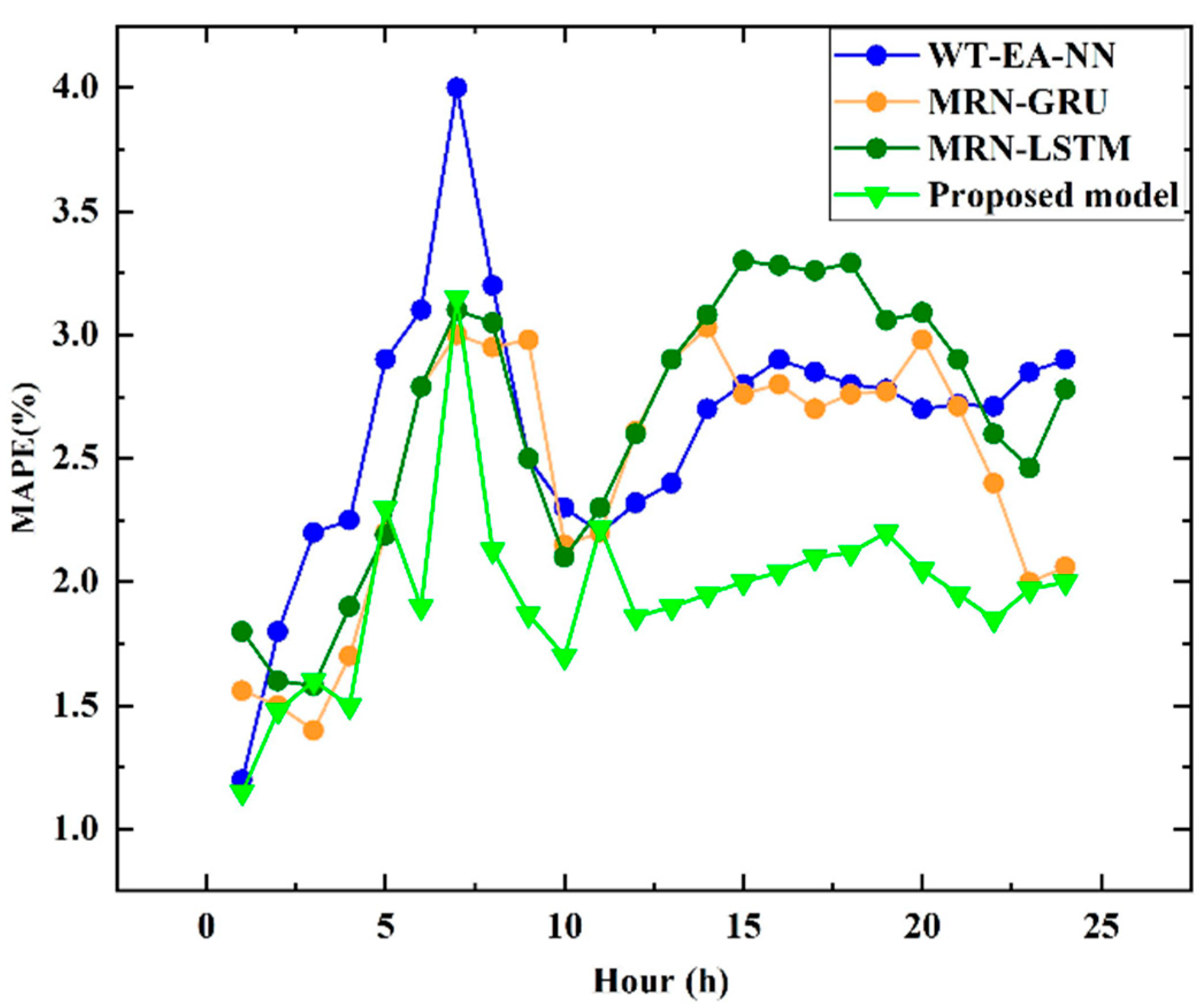
| WT-NN [37] | 2.64 | 2.84 |
| WT-EA-NN [38] | 2.04 | - |
| ESN [39] | 2.37 | 2.53 |
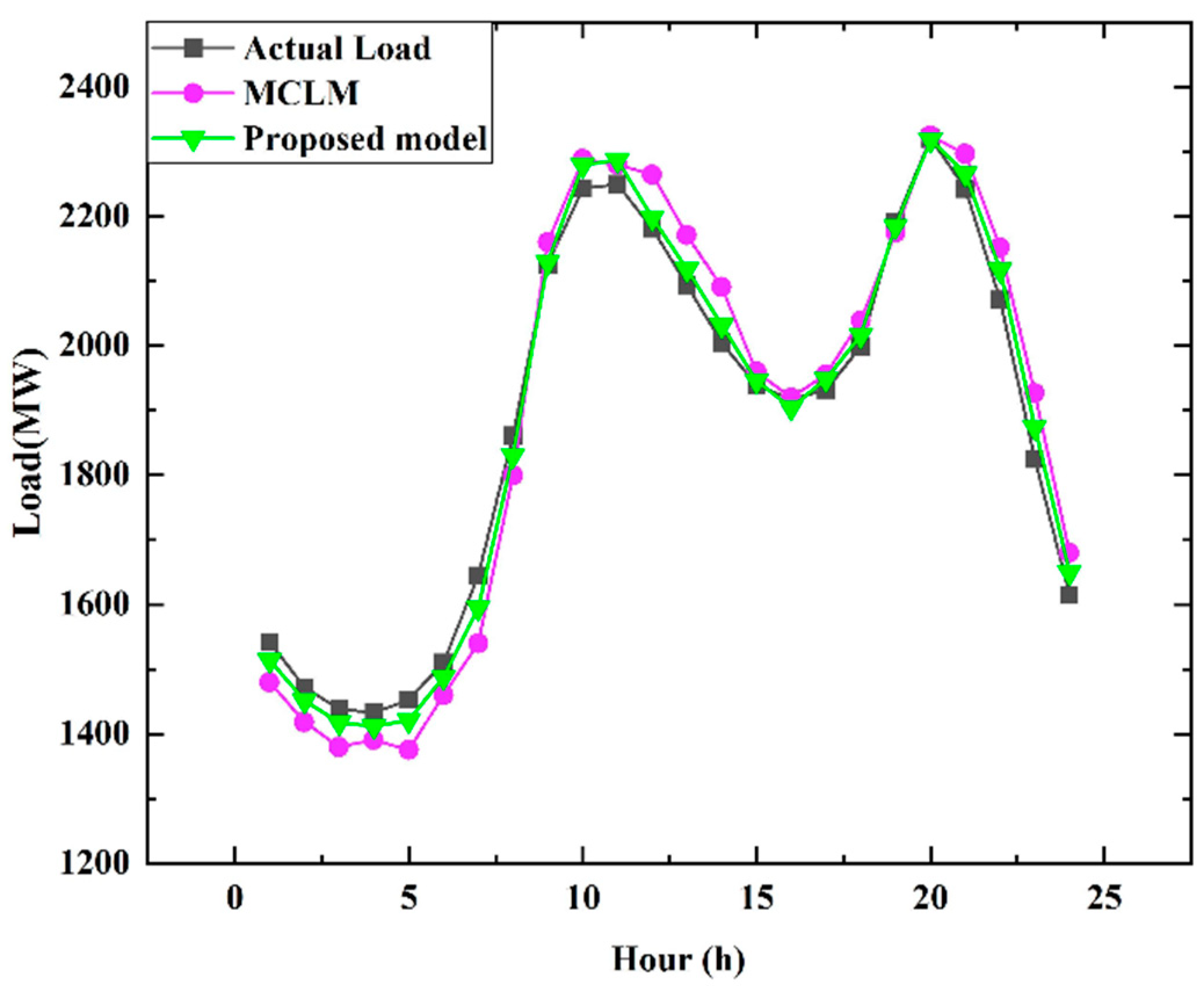
| MCLM [40] | 2.17 | 2.25 |
| Proposed model | 1.96 | 2.01 |
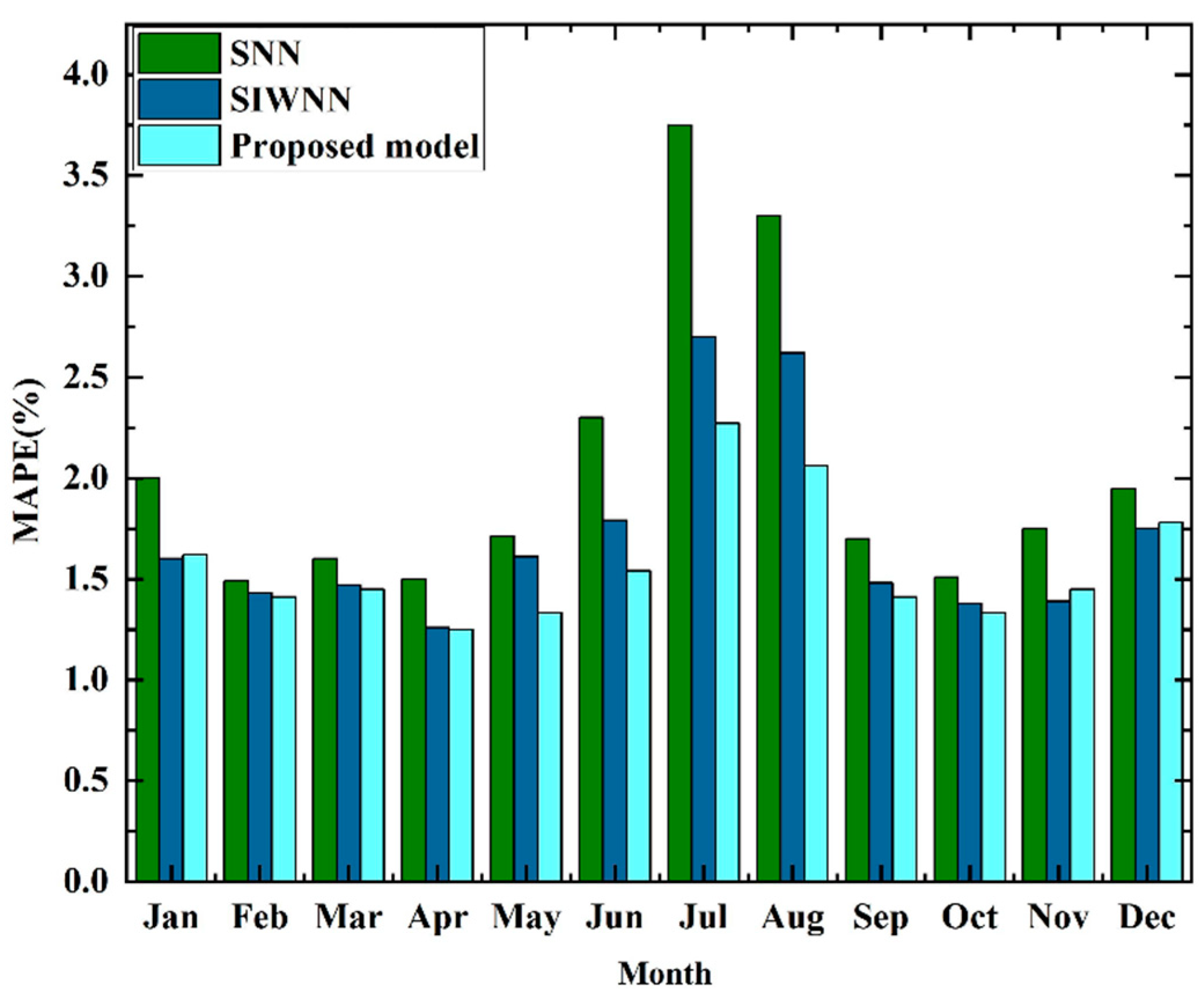
| Model | 2010 | 2011 |
|---|---|---|
| CNN | 3.78 | 3.93 |
| ErrCorr-RBF [42] | 1.80 | 2.02 |
| MErrCorr-RBF [43] | 1.75 | 1.98 |
| MRN [41] | 1.50 | 1.80 |
| Proposed model | 1.49 | 1.78 |
| Case | With Ensemble | Without Ensemble |
|---|---|---|
| Case 1 | 18.78 s | 12.93 s |
| Case 2 | 18.80 s | 12.91 s |
| Case 3 | 18.75 s | 12.98 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Han, G.; Zhu, H.; Liao, L. Short-Term Load Forecasting with an Ensemble Model Based on 1D-UCNN and Bi-LSTM. Electronics 2022, 11, 3242. https://doi.org/10.3390/electronics11193242
Chen W, Han G, Zhu H, Liao L. Short-Term Load Forecasting with an Ensemble Model Based on 1D-UCNN and Bi-LSTM. Electronics. 2022; 11(19):3242. https://doi.org/10.3390/electronics11193242
Chicago/Turabian StyleChen, Wenhao, Guangjie Han, Hongbo Zhu, and Lyuchao Liao. 2022. "Short-Term Load Forecasting with an Ensemble Model Based on 1D-UCNN and Bi-LSTM" Electronics 11, no. 19: 3242. https://doi.org/10.3390/electronics11193242
APA StyleChen, W., Han, G., Zhu, H., & Liao, L. (2022). Short-Term Load Forecasting with an Ensemble Model Based on 1D-UCNN and Bi-LSTM. Electronics, 11(19), 3242. https://doi.org/10.3390/electronics11193242