




A Graph-Based Metadata Model for DevOps in Simulation-Driven Development and Generation of DCP Configurations


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Motivational Examples
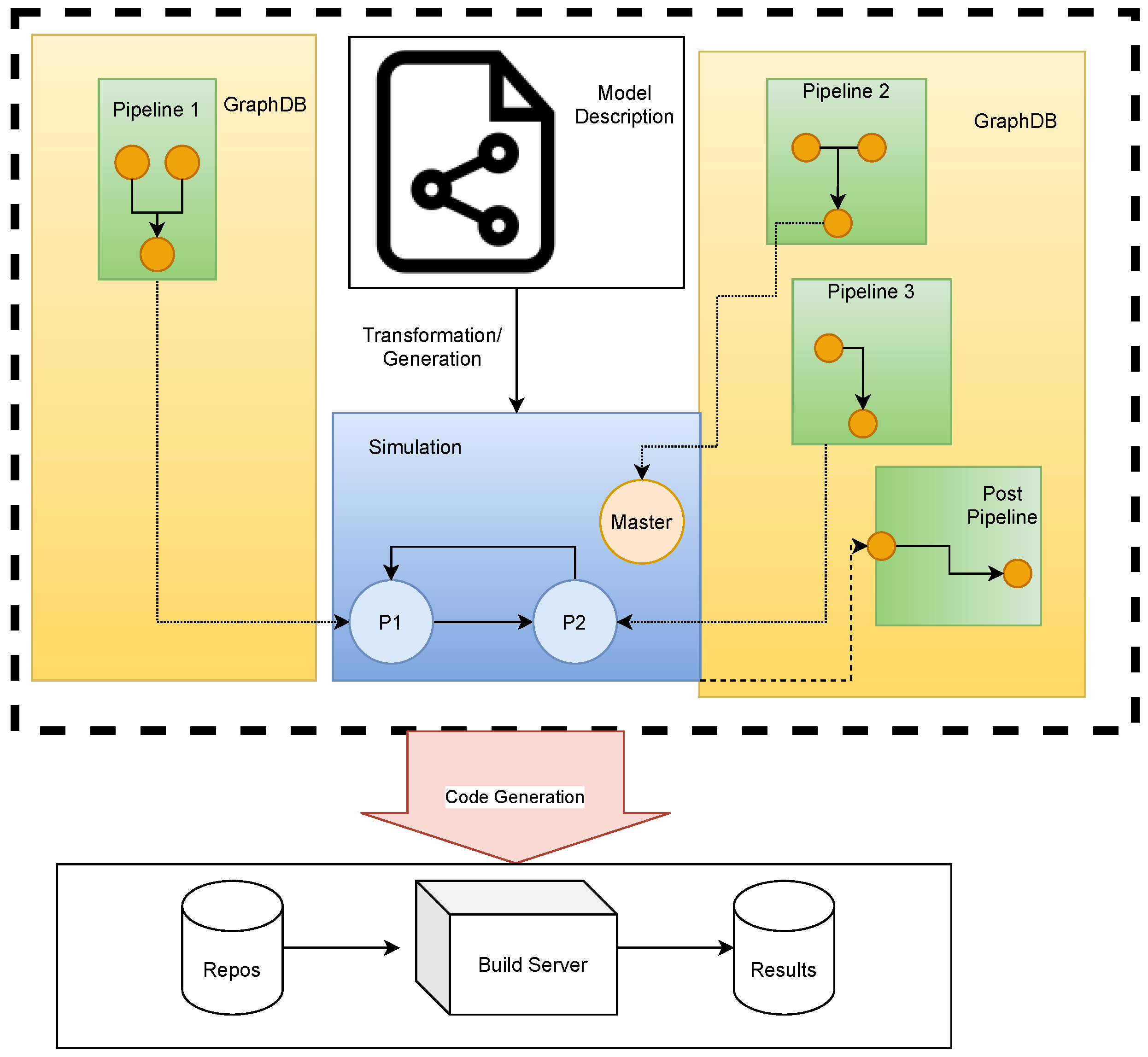
2.1. Description of a Development Process: From Systems Engineering to Automatic Deployment
- get access to the code;
- build a pipeline (or script) to build the model; and
- set up a co-simulation scenario and run it.
- The system engineer defines the system design including model boundaries, their scope, and, in particular, the flow of model signals between models. This can either be done from scratch or by working in part with previously established models.
- The model developer creates the models and their implementation according to the previously defined system design.
- The DevOps engineer provides build pipelines—or templates for build pipelines—to build the models and deploy the resulting instances of these models as artifacts.
2.2. Auto-Configuration of Co-Simulations
2.3. Automatic Test Generation from Already Executed Simulations
3. The Co-Simulation Graph and the DCP Standard
3.1. Challenges and Contributions
3.2. Definition and Computational Framework for Co-Simulation Process Graphs
- The set of nodes consists of data nodes, transformation nodes, master nodes, signal nodes and communication (or gateway) nodes.
- To represent the instantiation of a process or the usage of a signal inside a simulation, copies of the nodes which represent these instances are made. Instances have to be directly connected to their originals.
- Instead of using the bi-partite structure to represent data transformations, only instances of processes can connect to data nodes to perform operations. In this way, the nodes which perform operations and their instantiation can be determined with a suitable algorithm, which determines a different partition of the graph with help of the defined structure, to provide the correct order of executions. This is necessary because it is allows that transformation nodes are neighboring, e.g., a Docker container which is built and then used for executing a program afterwards
- An information node can never be the successor or predecessor of another information node. A process must be placed in between. However, neighboring process nodes are allowed. This may happen if a program-performing transformation at a later stage is modified beforehand by another process (e.g., parameterization of tools).
- A simulation is a subgraph with the following properties: (a) It contains the instance of a master node. (b) The instance of the master node is connected to all instances of signal nodes that belong to the simulation. (c) All the other nodes inside the simulation (i.e., the simulation participants and communication gateways) neighbor a signal instance. (d) Each instance of a signal is only allowed to appear once inside a simulation.
- Cycles are only allowed inside a simulation subgraph.
- 1.
- Scan and contract the simulations within the graph. This can be achieved by collecting the master nodes and collect all connected nodes, and their connected gateways. Then contract the simulation, i.e., all involved nodes in the simulation will be replaced by one node representing the simulation as a whole. This node is treated like a bridge, as the simulation can also be seen as a transformation from input data (e.g., configuration data) to output data (simulation results). See also [10] for a discussion of the efficient implementation of contractions within graph databases.
- 2.
- Apply Algorithm 1 to transform the circle free co-simulation process graph into a pipeline.
| Algorithm 1: Creating the vertices of a pipeline from an extended pipeline graph. Lists are denoted with square brackets. |
 |
3.3. Graph Databases and the Metadata Model
4. Implementation of the Use Cases
4.1. Autogeneration of Co-Simulations from System Descriptions
- 1.
- A ProtocolStateMachine is mapped onto a master node. Its properties are added as data to the node.
- 2.
- The class objects are represented as bridge nodes which again hold the property fields as information.
- 3.
- The port objects are mapped onto signal nodes.
- 4.
- The InformationFlow objects are then used to define connection nodes and the edges between the participants.
4.2. Autoconfiguration of Execution Orders of Participants in Co-Simulations
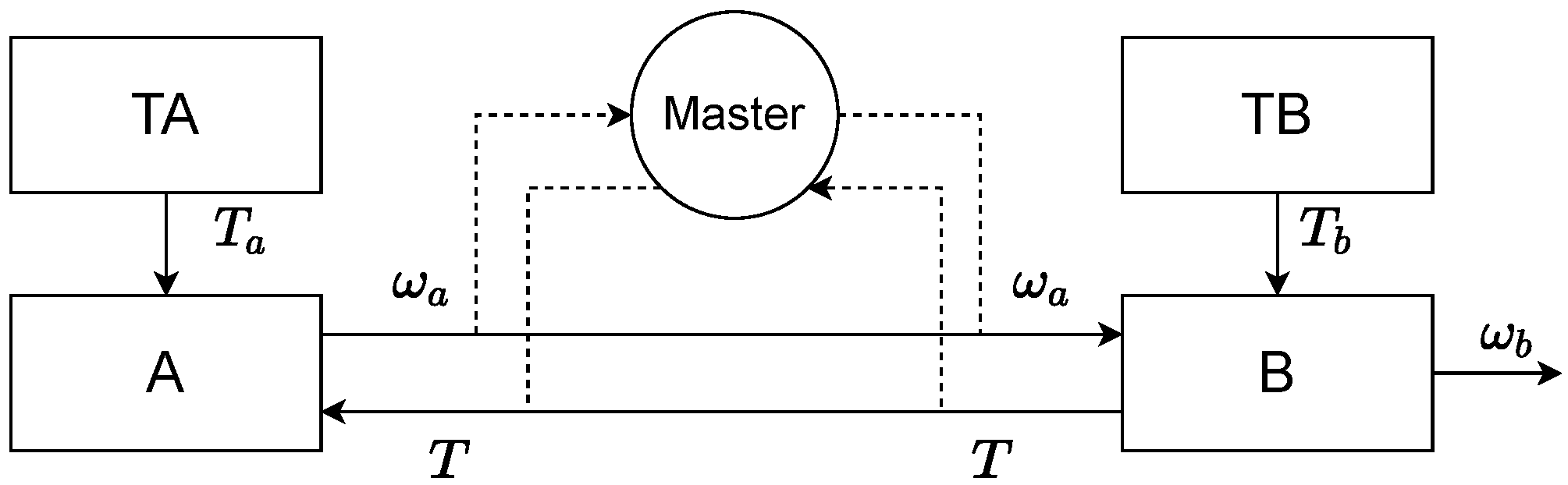
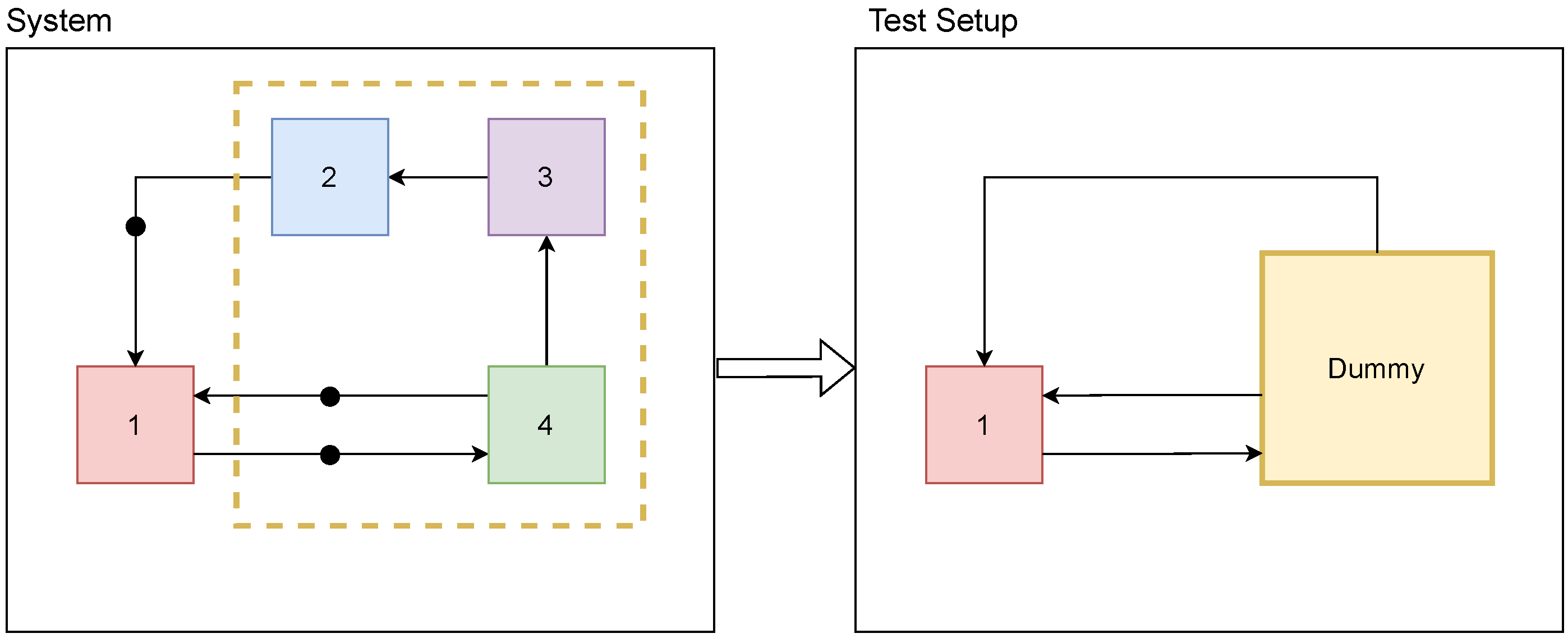
4.3. Autogeneration of Test Scenarios
- The participant TA sends the time-dependent signal defined by the curvewith a = 10 Nm.
- Similar to TA, TB is defined bywith .
- The system A is defined by the differential equationwith and parameter .
- The system B is described bywith the initial conditions , , and parameters , and . The outgoing signal is determined by the relation
5. Conclusions
6. Discussion and Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACC | Adaptive Cruise Control |
| CD | Continuous Deployment |
| CI | Continuous Integration |
| CPS | Cyber Physical System |
| DAG | Directed Acylic Graph |
| DCP | Distributed Co-Simulation Protocol |
| ECU | Electronic Control Unit |
| FMI | Functional Mockup Interface |
| FMU | Function Mockup Unit |
| NRT | Non Real Time |
| PDU | Protocol Data Unit |
| SRT | Soft Real Time |
Appendix A. Node Samples
| Listing A1: Example of a Data Node: This sample represents the code for the ACC function FMU which was pulled from a repository. |
 |
| Listing A2: Example of a Bridge Node: This node represents the ACC function FMU binary which can be used within a simulation. Note that IID is None. |
 |
| Listing A3: Example of a Bridge Node Instance: This node is used within the simulation. Note that IID is not None but 0. |
 |
| Listing A4: Example of a Signal Node: The signal consists of information which are needed for the simulation. |
 |
References
- Bass, L.; Weber, I.; Zhu, L. DevOps: A Software Architect’s Perspective; Addison-Wesley Professional: New York, NY, USA, 2015. [Google Scholar]
- Leite, L.; Rocha, C.; Kon, F.; Milojicic, D.; Meirelles, P. A Survey of DevOps Concepts and Challenges. ACM Comput. Surv. 2020, 52, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Palihawadana, S.; Wijeweera, C.H.; Sanjitha, M.G.T.N.; Liyanage, V.K.; Perera, I.; Meedeniya, D.A. Tool support for traceability management of software artefacts with DevOps practices. In Proceedings of the 2017 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 29–31 May 2017; pp. 129–134. [Google Scholar] [CrossRef]
- Rubasinghe, I.; Meedeniya, D.; Perera, I. Traceability Management with Impact Analysis in DevOps based Software Development. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 1956–1962. [Google Scholar] [CrossRef]
- Rodrigues, M.R.; Magalhães, W.C.; Machado, M.; Tarazona-Santos, E. A graph-based approach for designing extensible pipelines. BMC Bioinform. 2012, 13, 163. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balci, S.; Reiterer, S.; Benedikt, M.; Soppa, A.; Filler, T.; Szczerbicka, H. Kontinuierliche Integration von vernetzten Steuergerätefunktionen im automatisierten Modellierungs- und Build-Prozess bei Volkswagen. In Proceedings of the SIMVEC 2018, Baden-Baden, Germany, 20–21 November 2018. [Google Scholar]
- Reiterer, S.H.; Balci, S.; Fu, D.; Benedikt, M.; Soppa, A.; Szczerbicka, H. Continuous Integration for Vehicle Simulations. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; Volume 1, pp. 1023–1026. [Google Scholar]
- Modelica Association Project SSP. SSP Specification Document; Version 1.0; Modelica Association: Linköping, Sweden, 2019. [Google Scholar]
- Reiterer, S.H.; Schiffer, C. A Graph-Based Meta-Data Model for DevOps in Simulation-Driven Development and Generation of DCP Configurations. In Proceedings of the 14th Modelica Conference 2021, Linköping, Sweden, 20–24 September 2021; pp. 411–417. [Google Scholar] [CrossRef]
- Reiterer, S.; Kalab, M. Modelling Deployment Pipelines for Co-Simulations with Graph-Based Metadata. Int. J. Simul. Process. Model. 2021, 16, 333–342. [Google Scholar] [CrossRef]
- Modelica Association Project DCP. DCP Specification Document; Version 1.0; Modelica Association: Linköping, Sweden, 2019. [Google Scholar]
- Krammer, M.; Benedikt, M. Configuration of slaves based on the distributed co-simulation protocol. In Proceedings of the 2018 IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Torino, Italy, 4–7 September 2018; Volume 1, pp. 195–202. [Google Scholar] [CrossRef]
- Krammer, M.; Schiffer, C.; Benedikt, M. ProMECoS: A Process Model for Efficient Standard-Driven Distributed Co-Simulation. Electronics 2021, 10, 633. [Google Scholar] [CrossRef]
- Gomes, C.; Thule, C.; Broman, D.; Larsen, P.G.; Vangheluwe, H. Co-simulation: State of the art. arXiv 2017, arXiv:1702.00686. [Google Scholar]
- Holzinger, F.R.; Benedikt, M.; Watzenig, D. Optimal Trigger Sequence for Non-iterative Co-simulation with Different Coupling Step Sizes. In Simulation and Modeling Methodologies, Technologies and Applications; Obaidat, M.S., Ören, T., Szczerbicka, H., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 83–103. [Google Scholar]
- Bastian, J.; Clauß, C.; Wolf, S.; Schneider, P. Master for Co-Simulation Using FMI. In Proceedings of the 8th International Modelica Conference, Dresden, Germany, 20–22 March 2011; pp. 115–120. [Google Scholar] [CrossRef] [Green Version]
- O’Halloran, B.M.; Papakonstantinou, N.; Giammarco, K.; Van Bossuyt, D.L. A graph theory approach to functional failure propagation in early complex cyber-physical systems (CCPSs). In INCOSE International Symposium; Wiley Online Library: Hoboken, NJ, USA, 2017; Volume 27, pp. 1734–1748. [Google Scholar]
- Roche, J. Adopting DevOps practices in quality assurance. Commun. ACM 2013, 56, 38–43. [Google Scholar] [CrossRef]
- Korte, B.; Vygen, J. Combinatorial Optimization; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2012; Volume 2. [Google Scholar]
- Friedler, F.; Tarjan, K.; Huang, Y.; Fan, L. Combinatorial algorithms for process synthesis. Comput. Chem. Eng. 1992, 16, 313–320. [Google Scholar] [CrossRef]
- Tick, J. P-graph-based workflow modelling. Acta Polytech. Hung. 2007, 4, 75–88. [Google Scholar]
- Wood, P.T. Graph Database; Springer: Boston, MA, USA, 2009; pp. 1263–1266. [Google Scholar] [CrossRef]
- Fernandes, D.; Bernardino, J. Graph Databases Comparison: AllegroGraph, ArangoDB, InfiniteGraph, Neo4J, and OrientDB. In DATA; SciTePress: Porto, Portugal, 2018; pp. 373–380. [Google Scholar]
- FMI-Working-Group. Functional Mock-Up Interface for Model Exchange and Co-Simulation. 2020. Available online: https://github.com/modelica/fmi-standard/releases/download/v2.0.2/FMI-Specification-2.0.2.pdf (accessed on 12 April 2021).
- Benedikt, M.; Drenth, E. Relaxing stiff system integration by smoothing techniques for non-iterative co-simulation. In IUTAM Symposium on Solver-Coupling and Co-Simulation; Springer: Cham, Switzerland, 2019; pp. 1–25. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reiterer, S.H.; Schiffer, C.; Benedikt, M. A Graph-Based Metadata Model for DevOps in Simulation-Driven Development and Generation of DCP Configurations. Electronics 2022, 11, 3325. https://doi.org/10.3390/electronics11203325
Reiterer SH, Schiffer C, Benedikt M. A Graph-Based Metadata Model for DevOps in Simulation-Driven Development and Generation of DCP Configurations. Electronics. 2022; 11(20):3325. https://doi.org/10.3390/electronics11203325
Chicago/Turabian StyleReiterer, Stefan H., Clemens Schiffer, and Martin Benedikt. 2022. "A Graph-Based Metadata Model for DevOps in Simulation-Driven Development and Generation of DCP Configurations" Electronics 11, no. 20: 3325. https://doi.org/10.3390/electronics11203325
APA StyleReiterer, S. H., Schiffer, C., & Benedikt, M. (2022). A Graph-Based Metadata Model for DevOps in Simulation-Driven Development and Generation of DCP Configurations. Electronics, 11(20), 3325. https://doi.org/10.3390/electronics11203325