1. Introduction
Electricity plays a major role in modern society since it is required to satisfy most of the needs of industrial and residential facilities. According with the International Energy Agency (IEA), the global electricity consumption has exceeded the 25,000 TWh since 2019 [
1]; only in 2020 did this value present a reduction of the 4% associated with the restrictions imposed by the COVID-19 pandemic. However, in 2021, with all the actions taken by the nations around the world pursuing an economic recovery, the energy demands that year experienced an increment five times larger than the reduction reached during the pandemic [
1]. The main problem with these energy needs relies in the fact that the conventional generation processes are still based in the combustion of fossil fuels, resulting in high levels of greenhouse gas emission. In actuality, the energy market is responsible of around the 80% of the global
emissions [
2]. It is well known that the greenhouse effect has caused, among others, an increment in the annual average temperature of the world [
3,
4]; moreover, the air pollution due to
has a negative impact on human health, causing respiratory diseases, lung cancer, and depression, among other conditions [
5,
6]. To deal with all these undesired effects, important actions are being adopted worldwide, such as the Paris Agreement [
7] and the Sustainable Development Goals (SDG) [
8] established by the United Nations. What is clear is the need of a reduction in the amount of greenhouse gases emissions, and in this sense, the renewable energy sources (RES) become of great importance to reduce the
emissions associated with energy generation. RES have been experiencing important growth in recent years, and during 2021, 28.3% of the total world electricity consumption came from RES [
9]. Among all the RES, solar photovoltaics (PV) is the one with the highest growth in the last two years, reaching a total installed capacity of 942 GW in 2021 [
9]. The amount of energy generated using RES is still far from the amount required in order to reach the compromises made in the Paris Agreement and in the SDG; however, this amount is expected to continue growing, and thus the challenges associated with a new electricity generation paradigm must be faced, and the development of new strategies for the condition monitoring, fault detection, and maintenance in RES will become an essential research topic towards a reliable and robust power grid.
Although the RES are useful in the reduction of environmental and human health problems, their use supposes some drawbacks, with the most important being the dependence of weather conditions that makes the generation variable and unstable. To deal with this situation, the use of load-leveling techniques based in energy storage devices is a common and useful solution [
10]. Some of the most common energy storage appliances are the compressed-air energy storage [
11], the potential hydro storage [
12], the use of super capacitors [
13], super magnetic storage systems [
14], batteries [
15], and thermal energy storage systems [
16,
17]. All these systems consider that there are some periods over the day where the energy production exceeds the energy consumption; thus, the surplus energy can be stored and used later when the energy production is lower than the energy demand. However, to correctly operate, these technologies need to know the behavior of both the energy demand and the energy generation. Moreover, it is important to detect when the variability in the generation process is due to the action of environmental conditions and when it is due to some other external causes. In this sense, the development of methodologies for assessing and detecting abnormal operating conditions in RES is an important issue to be addressed.
Additionally, the PV panels need to be located outdoors, with the dust particles suspended in the environment tending to accumulate in the surface of the PV panel, creating a layer that reduces the amount of sunlight that reaches the cells and diminishes the efficiency of the production process [
18]. The deposition of dust and sand on PV panels always appears in outdoors conditions and it can be different from one system to another, depending on factors such as surface area of the panel, tilt angle, and wind speed [
19]. It is important to detect and correct this condition in a timely manner since it can cause a reduction of the 15% per month in the amount of energy delivered by a PV system [
20]. Several studies have been developed for determining how the dust accumulation affects the generation process in PV systems [
21,
22,
23]. These works conduct a series of experiments wherein different concentrations of dust are placed on the surface of a PV panel with the only purpose of evaluating the reduction of the output power delivered by the PV system. On their part, the authors in [
24] demonstrated that the dust accumulation directly affects the efficiency achieved by a PV panel. Moreover, they trained an artificial neural network (ANN) to predict the level of affection in the PV panel efficiency in terms of the size of the dust particles. Similar studies are presented in [
25,
26], wherein the authors agree with the fact that the type and characteristics of the dust particles (such as size and composition) affect the process of generation in PV systems, and they conclude that a reduction up to 57% in the efficiency of the PV panels can be caused by the effect of the dust accumulation. All these works state the importance of developing methods and strategies that allow for the determination of the moment when the PV panel must be cleaned to avoid loses and to prevent faults related to the poor efficiency developed by the panels. Therefore, some other works go beyond and try to propose a mathematical model for predicting how the delivered power behaves under different dust levels. For instance, in [
27], the authors performed an analysis considering six different types of dust, and they placed different concentrations of them on the surface of a PV panel in order to measure the effect of these pollutants in the system output power. The authors concluded that the smallest particles are more harmful for the generation process, and, as expected, an increase in the amount of dust results in higher output power losses. Additionally, they provided six experimental models (one per dust type) that can predict the losses that appear in the system at a certain irradiance and dust concentration. However, to use this model, it is necessary to have a priori knowledge of the type of dust that is covering the panel, and the models do not consider the possibility of a combination of different types of pollutants that is the most common case in real scenarios. A similar study is presented in [
28], wherein different concentrations of dust were placed in the surface of a PV panel, and a model for assessing the efficiency of the panel was developed. Here, it was concluded that dust accumulation causes an increment in the temperature of the surface of the PV panel, as well as a reduction of the short circuit current and open circuit voltage. Moreover, it is mentioned that the most detrimental effects appeared at early stages of the dust deposition. All the aforementioned works provide a good explanation of the effects of dust accumulation in the PV generation process, and they allow for modelling of the behavior of the panel under different levels of dust deposited on the panel surface. Additionally, the works that deal with the identification of different dust accumulation levels mention that it is not sufficient to perform the analysis considering only the electrical variables, due to the dependence of the environmental conditions, and that it is necessary to include at least the sun radiance and the environmental temperature to ensure an accurate estimation. Notwithstanding, these works do not provide a tool for automatically detecting the moment where the dust accumulation is critical and needs to be attended to. This situation is left to the consideration of the user.
In order to offer an alternative that automatically detects when dust levels on the PV panel are high enough to require a maintenance action, some works propose considering the dust accumulation a faulty condition of the PV system. Here, the use of statistical analysis and linear regression models [
29,
30], image processing techniques [
31,
32], and artificial intelligence approaches such as ANN [
33] and fuzzy logic [
34] are common solutions. All these works perform a characterization of different types of faults in PV panels, with dust accumulation being one of them. Every methodology performs a classification of the fault, considering as inputs the electric variables of the system (voltage and current) and some environmental parameters such as sun irradiance and environmental temperature. Although these methodologies are good for identifying when the fault condition appears in the system, they do not allow us to obtain information regarding the amount of dust that has been deposited on the panel surface. To overcome this situation, machine learning approaches have turned out to be effective. For instance, in [
35], a methodology is introduced that uses a deep residual neural network (DRNN) along with image processing techniques including nonlinear interpolation, equivalent segmentation, and clustering for detecting specific regions in the PV panel where the dust is being accumulated. Additionally, a model is proposed that allows for the determination of the concentration and distribution of the dust on the PV panel. Another useful solution is presented in [
36], where the use of regression models and decision trees for the quantification of dust levels in a PV panel is proposed. There, the authors develop a model that allows for the estimation of a quantity between the 0 g/m
2 and the 0.9 g/m
2 of dust accumulation. These last two works are able to classify and quantify different levels of dust in the surface of a PV panel; however, they do not provide information regarding when maintenance actions must be performed.
At this point, it must be said that for all the aforementioned techniques to be able to work, they require of a series of parameters that characterize every one of the operating conditions that they address. The selection of the best parameters is not a trivial task; therefore, the use of optimization approaches for parameter selection has gained attention. In this regard, the use of bio-inspired and heuristic techniques has been widely explored in order to solve optimization problems. Genetic algorithms (GA) are a very popular solution for optimization problems [
37]—they are inspired in the natural selection process explained by Darwin and they use binary chains to represent various potential solutions. The set of potential solutions is called the population, and using the selection, crossover, and mutation operators, the population evolves to its optimal state, that is, the solution. A variant of the GA is the technique known as differential evolution (DE) [
38]—this technique also considers the existence of a population that has to evolve to an optimal state, with the encoding and the combination mechanisms being the main differences between GA and DE. Other optimization techniques try to replicate the behavior of certain natural species—for instance, Harris hawks optimization (HHO), which emulates a hawk hunting a rabbit [
39]; particle swarm optimization (PSO), which copies the social interaction of certain individuals within a group such as flocks of birds and schools of fish [
40]; and the bat algorithm, which mimics the echolocation used by bats to identify the position of nearby objects [
41], among others. All these techniques use a group of potential solutions and confine them within a search space; then, using a model that replicates the natural behavior they try to imitate, they generate new potential solutions that are better than the previous ones until the best solution is found at the end of the algorithm. Although all the optimization techniques reported thus far are efficient and reliable, it has been reported that GA is the simplest solution that delivers rapid and accurate results [
37], and that is the reason why it was selected to be implemented here.
In this work, we propose the use of a machine learning approach for the identification and classification of dust accumulation in the surface of a PV generation system. The proposed approach uses a statistical feature extraction for the tracking of the different system conditions combined with the linear discriminant analysis (LDA) for the reduction of the dimensionality of the problem and to perform a clustering that allows for the determination of the dust accumulation level on the PV system. The system considers two types of inputs: the electrical (DC voltage and DC current) and the environmental (the amount of solar radiation that reaches the panel and the environmental temperature). In order to increase the reliability of the method, an optimized feature selection based on a genetic algorithm (GA) and principal component analysis (PCA) was implemented for retaining only the features that provide relevant information and discarding the rest. The methodology proposed here considers three dust accumulation levels: clean panel (CLN), moderate accumulation level (MAL), and high accumulation level (HAL). When the MAL condition is detected, the methodology delivers a message indicating that a maintenance action will be required soon, and when the HAL condition is reached, a message is generated indicating that the maintenance action must be performed immediately. The proposed methodology is tested in a low-power isolated PV system, and the results prove that the methodology delivers an accuracy that is always higher than 94%; therefore, it is an effective tool for tasks of maintenance and prevention of losses in PV generation systems. The main contribution of this work consists of the development of a tool for preventive maintenance in PV systems that allows not only for the determination of whether a dust accumulation condition is present but also when cleaning actions must be performed. This way, it is not necessary to see the panels to evaluate if maintenance is required. Moreover, a visual inspection may lead to subjective conclusions, and to perform or not perform the maintenance actions is a decision left for the operator. With the proposed methodology, the results are objective because they are based in the measurement of physical variables, and the operator does not require being an expert in order to decide the action that must be taken because the proposed methodology delivers as an output what must be done.
3. Methodology
The proposed method for the classification of dust accumulation in PV systems was carried out, considering different stages.
Figure 2 shows a step-by-step diagram of the process. As can be seen, a total of 5 stages were required to identify the level of dust deposited in the surface of the panel: generation of the dataset, statistical feature extraction, optimized feature selection, dimensionality reduction, and estimation of the dust level.
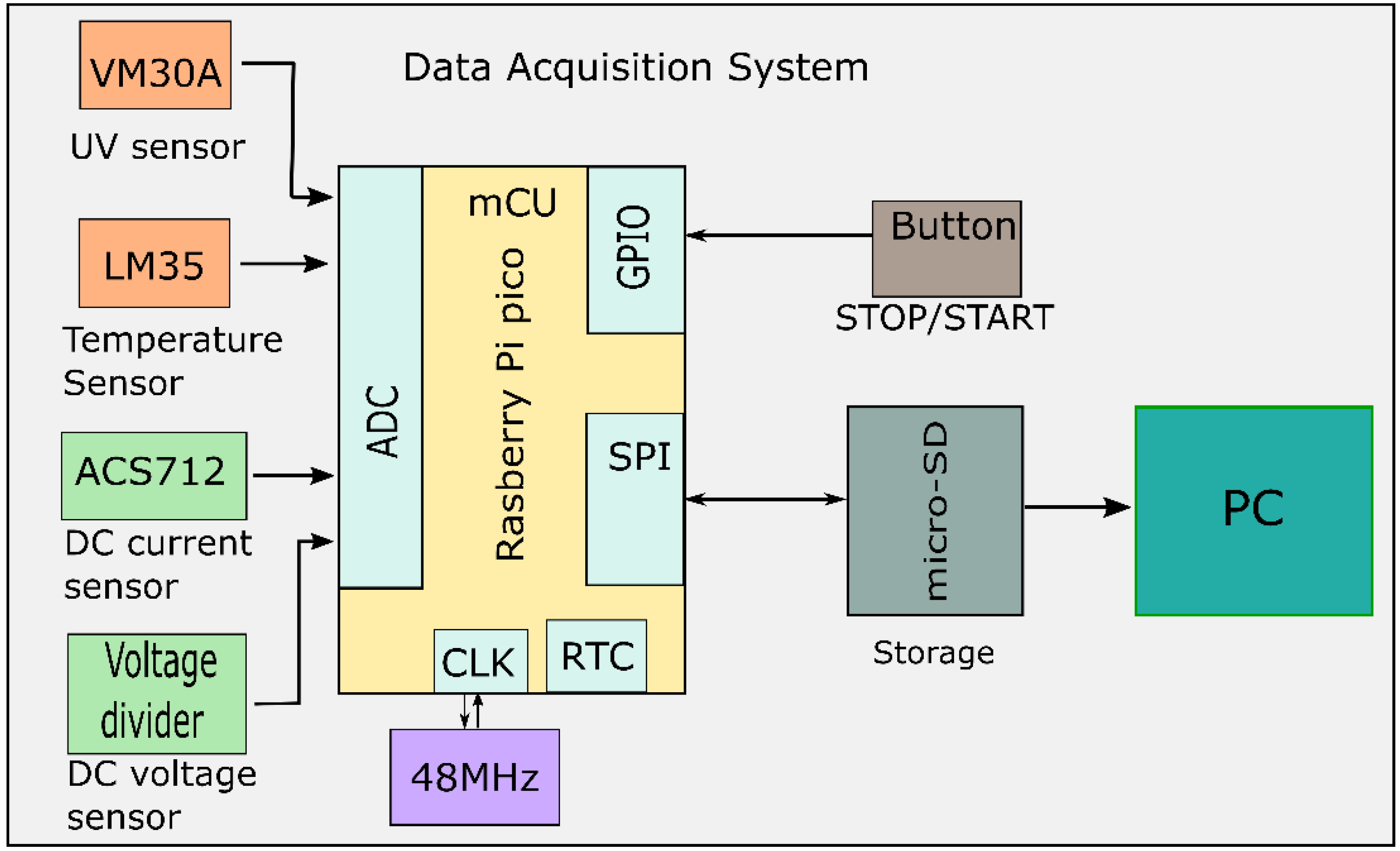
3.1. Data Acquisition
To perform the task of identifying the dust accumulation levels, the proposed methodology requires a set of inputs that must be collected. This particular work considers the acquisition and use of for different physical variables: the electrical variables (DC voltage and DC current) and the environmental variables (sun radiance and environmental temperature). All of these variables are essential to obtain accurate and reliable results. In this regard, the most important variables turned out to be the electrical signals delivered by the PV panel because it has been demonstrated in the revised literature that a dust layer in the surface of the PV panel directly affects the amount of generated power. Notwithstanding, using only electrical variables may not be sufficient for properly dealing with the dust accumulation problem. It is important to mention that dust deposition in the surface of the PV panel causes the same effect as the presence of clouds. Thus, in order to avoid false predictions associated with cloudy days, the sunlight that reaches the PV panel is also acquired and considered in the next stages of the process. Furthermore, it is known that temperature is another environmental factor that affects the amount of power that can be generated by a PV system, thus providing more robustness to the classification process, and therefore the environmental temperature is also considered in this study.
3.2. Statistical Feature Extraction
Before performing the feature extraction, all the signals acquired in the previous stage are pre-processed with an amplitude normalization. This task is carried out using (22):
where
is the normalized signal.
As previously mentioned, the statistical features are responsible for detecting specific trends that allow for the distinguishing from one operating condition to another. Therefore, a set of features is obtained by processing each one of the signals acquired in the previous stage and that have been already normalized. At this stage, the 15 statistical features shown in
Table 1 are separately computed for the DC voltage, the DC current, the sun radiance, and the environmental temperature. As result, a feature set of dimensionality
is obtained. This is a considerable number of features, and there is no guarantee that all of them provide relevant information of the dust level on the surface of the PV panel. Hence, the whole set of features is taken to the next stage in order to select only those features that are important for describing each operating condition.
3.3. Optimized Feature Selection
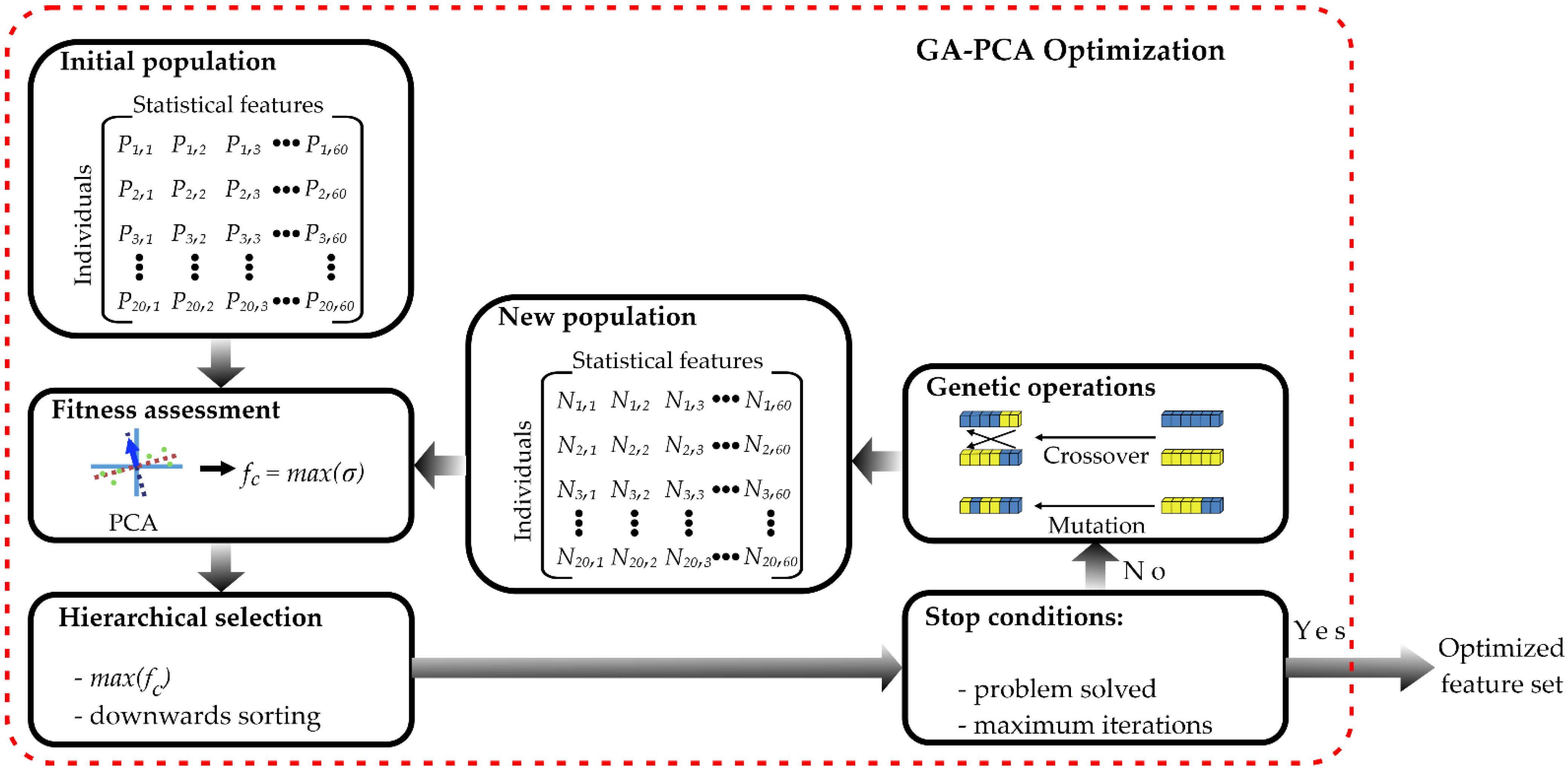
The proper selection of the features that describe the behavior of the system is essential in order to obtain accurate and reliable results. Then, this stage plays a major role towards obtaining a correct classification of the dust accumulation levels. To be able to determine whether a feature is important or not, a combined GA-PCA methodology is implemented. The GA is in charge of selecting different feature combinations that will be sent to the PCA in order to evaluate which set of features is the one that maximizes the data dispersion.
Figure 3 depicts the block diagram of the process that is implemented for the optimized feature selection through the GA-PCA methodology.
First, an initial population must be generated. At the setting up of the initial population, a total of 20 individuals are created, and it is considered that every individual is composed of a total of 60 chromosomes, wherein each chromosome corresponds to every one of the statistical features calculated in the previous stage. Thus, the initial population forms a matrix, where each row is an individual and each row contains a different statistical feature: 15 features per each one of the four input variables. Every individual of the population is represented as , where is the number of the individual, and states the statistical feature. A chromosome can take only the value of 1 or 0, with 1 representing the fact that the corresponding feature must be taken into account in the next stage and 0 representing the fact that the feature is not used in the following stage. The first generation is randomly generated with the only restriction that at least one chromosome must have the value of 1.
Next, every one of the individuals in the population must be evaluated to determine if it provides a solution to the optimization problem. In this work, this fitness assessment was performed using the PCA technique. This technique has the purpose of reducing the dimensionality of the dataset, preserving the data dispersion as much as possible; therefore, the GA is searching the feature combination that maximizes the cumulative data variance delivered by the PCA and it can be described by (23):
where
is the objective function or fitness function. To obtain the data variance, here, the value delivered by the two and the three first principal components is considered.
Continuing with the process, a hierarchical selection is performed. At this step, the values of the data variance achieved by each individual are sorted in descending order, and thus the first element of the array represents the best individual of the generation.
Once the population has been sorted, it must be verified if one of the stop conditions is reached. In this particular case, there are possibilities that will lead the GA to its end. The first one is achieved if the optimization problem is solved, i.e., if the GA finds the combination of features that delivers the highest maximization of the data variance. If this condition is not reached, there is another criterion that can finalize the GA, that is, reaching a maximum number of iterations. If any of these conditions are met, the GA delivers the best individual of the population as the optimized feature set.
If none of the stop criteria are met, a new population is created using the genetic operations of crossover and mutation. This work used the common single-point crossover operator and the roulette wheel selection for generating the new population. For this purpose, it is necessary to take two individuals in the population. Since the population has been previously ordered following an elitist selection, the most suitable individual is always selected as one of the two required in the crossover. The rest of the individuals in the population are then taken one by one to be combined with the best individual of the population. Once the two individuals are selected, they are cut at a randomly selected location called the pivot point. The genetic information to the left of these two individuals is swapped between them in order to obtain two new individuals known as children. Since each combination leads to two different children, the crossover of the original 20 individuals results in a new 40-individual population. This point is where the roulette wheel selection acts. This selection method uses (24) in order to work:
where
is fitness value for the
-th individual and
. After applying (24), the individuals are sorted from the highest to the lowest, and only the first 20 are selected to be part of the new population.
Additionally, and to prevent stagnation at a local maximum, the mutation operation is applied, considering a probability of mutation of 30%. The mutation operator is only applied if the probability of mutation is achieved; in this case, a single chromosome of the individual is randomly selected and its value is changed: a 1 is changed by a 0, and vice versa. Each one of the individuals of the new population is addressed as , where and continue having the same meaning described for the initial population. When the new population has been created, the process must be repeated from fitness assessment until one of the stop conditions is reached.
3.4. Dimensionality Reduction
At the end of the optimized feature selection stage, only the statistical features that are relevant for the description of each system condition remain, with the redundant information being previously discarded, reducing the dimensionality of the problem. Notwithstanding, the problem dimensionality still may be relatively high, making it necessary to perform an additional reduction prior to the classification of the dust levels. This task is conducted by the LDA technique. LDA is selected because, in addition to performing the dimensionality reduction, it allows for the maximization of the separation among classes, a situation that allows for the classification stage to be implemented in a simple and effective way. Moreover, LDA delivers a 2D projection with a combination of different weights of the optimized feature set. This 2D projection can be used to obtain a visual representation of the location of every considered condition in order to evaluate whether the separation among classes was effective. Such a 2D representation is possible because, at the end, only two features are selected by the LDA technique. It must be said that in this work, the final dimensionality of the set is selected as being two, and that is why the LDA delivers only two features that represent the coefficients of the linear transformations that are achieved when the LDA is applied. These two features will be the input data for the last stage that is the classifier for the estimation of the dust level.
3.5. Estimation of the Dust Level
All the previous stages are implemented with the purpose of facilitating the estimation of the dust level that is accumulated in the surface of a PV panel. To perform this last task, a classifier that uses a simple perceptron ANN composed of three layers is implemented. A backpropagation strategy is implemented for the training process and the sigmoid function is used as activation function for each neuron. Since the LDA technique delivers two features in the previous stage, the input layer of the classifier contains only two neurons. In the hidden layer, a total of 10 neurons are considered, whereas for the output layer, a neuron for each one of the operating conditions is designed in order to be evaluated that in this work turned out to be three in number: a clean panel (CLN), a moderate accumulation level (MAL), and a high accumulation level (HAL).
5. Results and Discussion
The proposed methodology was implemented in order to perform the detection of the different dust accumulation levels in the PV system. The process starts with the selection of the features that provide relevant information for the description of each condition using the GA-PCA methodology.
Table 4 summarizes the statistical features that were encountered as being relevant by the GA-PCA method. Each statistical feature was represented by a number that coincides with its index introduced in
Table 1. It was observed that the most important features were kurtosis and crest factor because they were considered in the for signals under test. The less relevant features turned out to be the mean, the variance, and the SRM shape factor since they were considered in only one of the signals under analysis. Thus, from
Table 4, it can be inferred that from the 60 original features, only 37 were considered to be relevant for the description of the dust accumulation levels in the PV panels. These 37 features were those that maximized the variance of the dataset under analysis, and they were taken to be used with the LDA technique in order to perform the dimensionality reduction.
Figure 7a depicts the 2D projection achieved by the LDA technique when the reduction of the dimensionality was performed using the optimized feature set. It was easy to identify the existence of three different clusters at first sight (one for each one of the studied conditions). A slight overlap was present between the clean panel condition (CLN) and the moderate dust accumulation level (MAL). On the other hand, the high dust accumulation level was completely separated from the two other conditions. This was an advantage since it meant that it would be easier for the classifier to correctly identify and categorize the dust accumulation levels. Hence, the two features delivered by the LDA with the optimized feature set were used as inputs of the ANN-based classifier.
Table 5 shows the confusion matrix for the classification of the dust levels using the whole methodology proposed in this work. It was observed that the classifier produced a few mistakes in distinguishing between the clean panel condition and the moderate dust accumulation. This was a more or less expected situation based on the clustering shown in
Figure 7a, where an overlap between the data of these two conditions was observed. This overlap was caused because the MAL condition was not harmful enough to represent significant power losses in the PV system. However, only 96.5% of the CLN cases were correctly classified, whereas the remaining 3.5% was misclassified as the MAL condition. In terms of the MAL condition, only 94.1% of the tests were properly identified, and the missing 5.9% was erroneously identified as the CLN condition. It is worth noticing that the errors in the classification occurred between two classes that did not require fast attention so it will not represent any risk for the system users. Finally, it must be noticed that for the HAL condition, 100% of the tests were correctly classified. This was an important advantage because the worst condition, the one that needs to be attended to immediately, is always correctly identified, allowing actions to be taken at the correct moment in order to avoid damages and severe power losses in the PV system. To show the importance of performing an optimized feature selection,
Figure 7b shows the 2D projection obtained by the LDA technique when the complete set of 60 statistical features was used. It can be appreciated that there were three different groups in the representation; however, all of them appeared overlapped among each other over the same straight line. The overlap among the different operating conditions was the result of the redundant information because there were features that present the similar behaviors for all the conditions, making it hard to distinguish which one is occurring. From
Figure 7b, it can be inferred that the high overlap among the different conditions would result in misclassifications that would compromise the accuracy of the results.
Finally, the proposed methodology tries to avoid ambiguity in the decision of performing cleaning tasks or not. Therefore, it delivers a message to the operators depending on the condition that is detected in the PV system. When the CLN condition is detected, the message delivered indicates that there is no need to perform any action at the moment (see
Figure 8a). When the described method finds a MAL condition, the message that is received by the operator is that maintenance will be required soon (see
Figure 8b)—this way it is possible to schedule the maintenance task when it is more convenient for the users. If a HAL condition is detected, it is informed that the maintenance task should be performed immediately in order to avoid severe losses or damages in the PV system (see
Figure 8c). Thus, the proposed methodology is helpful in the planning of maintenance tasks since it avoids the need of performing a visual evaluation of the systems and notes that cleaning actions are only required when the dust accumulation is high enough to cause significant power losses that compromise the integrity of the system.






 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}