
Research on Short-Term Load Forecasting Based on Optimized GRU Neural Network


Abstract
:1. Introduction
2. Model Principle
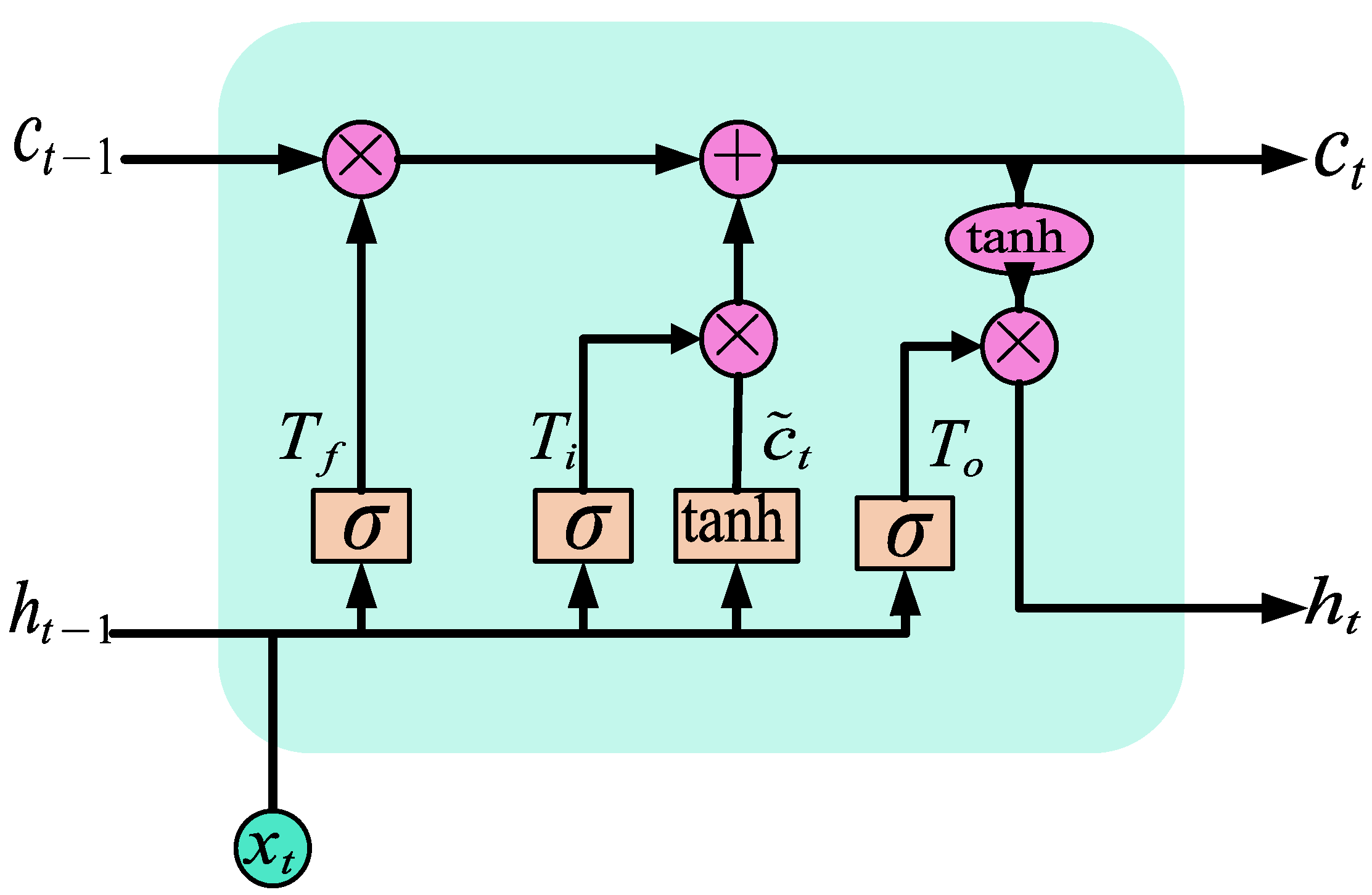
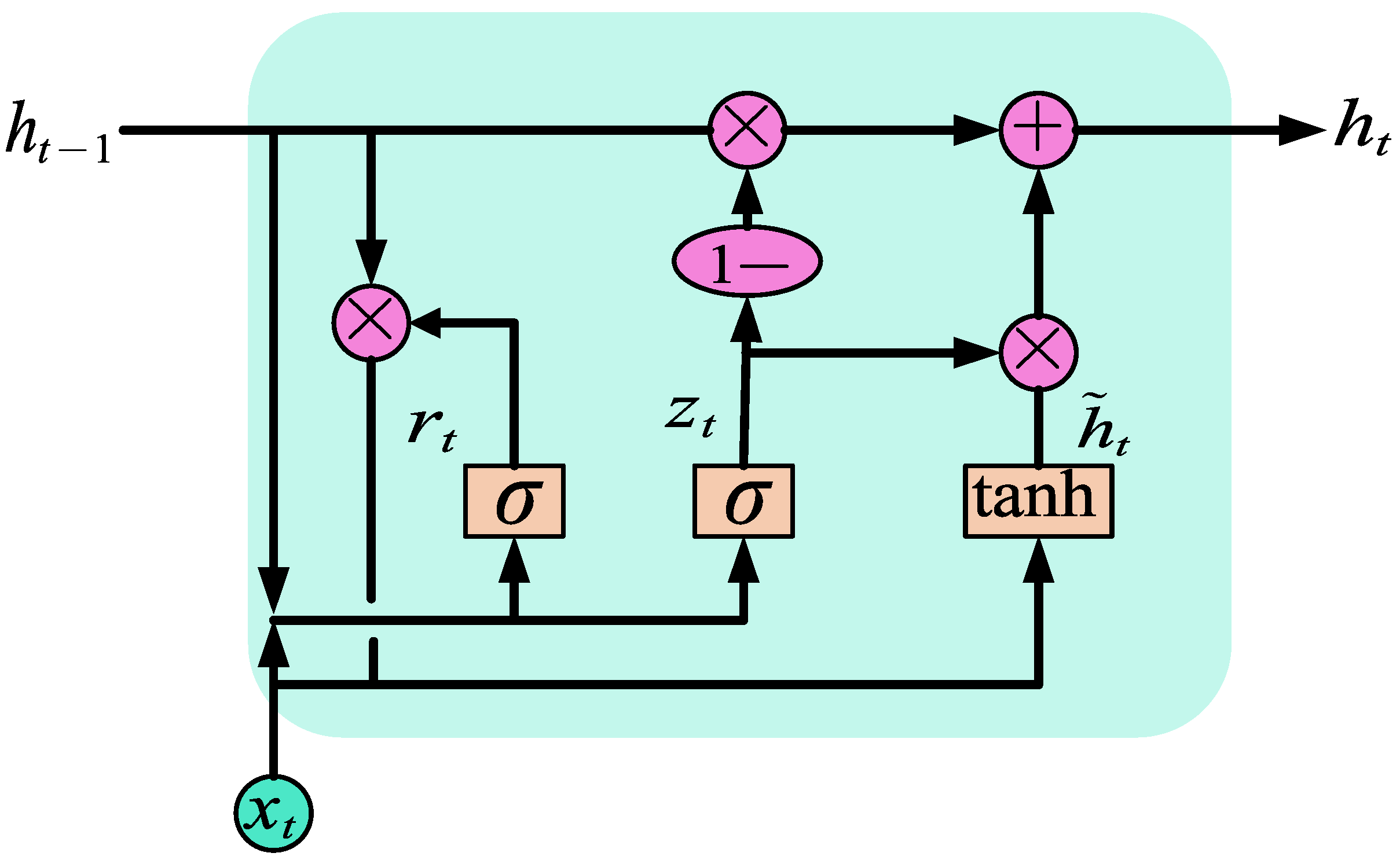
2.1. GRU
2.2. Comparison of GRU Model and BP Model
2.2.1. Error Evaluation Criteria
- (1)
- Mean absolute error (MAE)
- (2)
- Root mean square error (RMSE)
- (3)
- Mean absolute percentage error (MAPE)
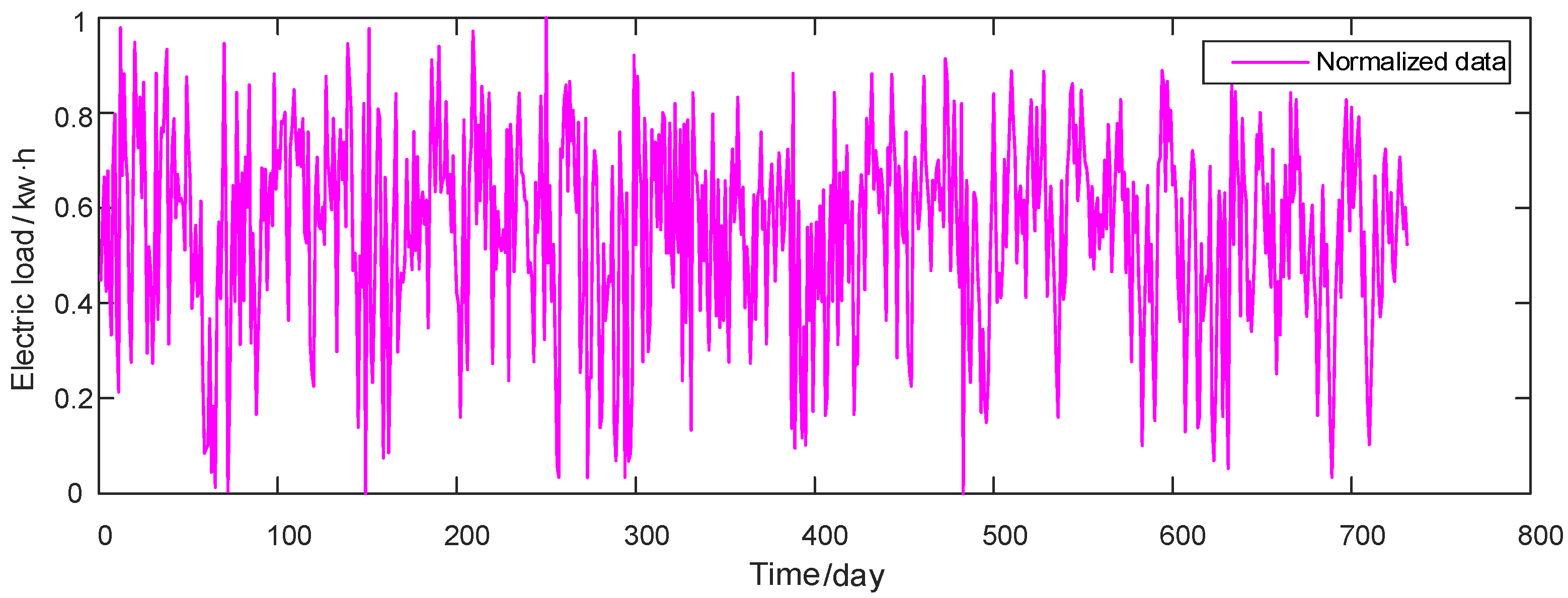
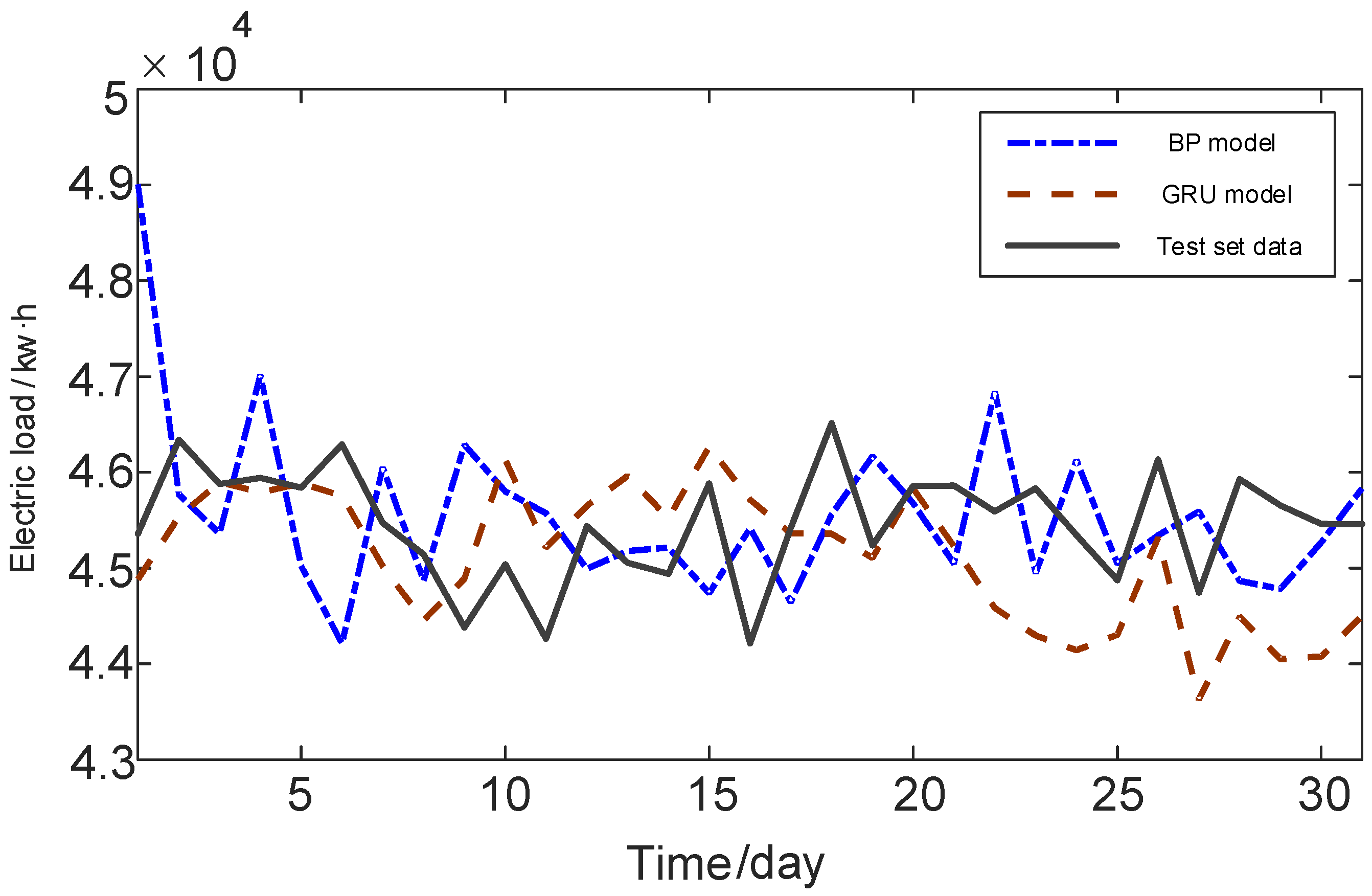
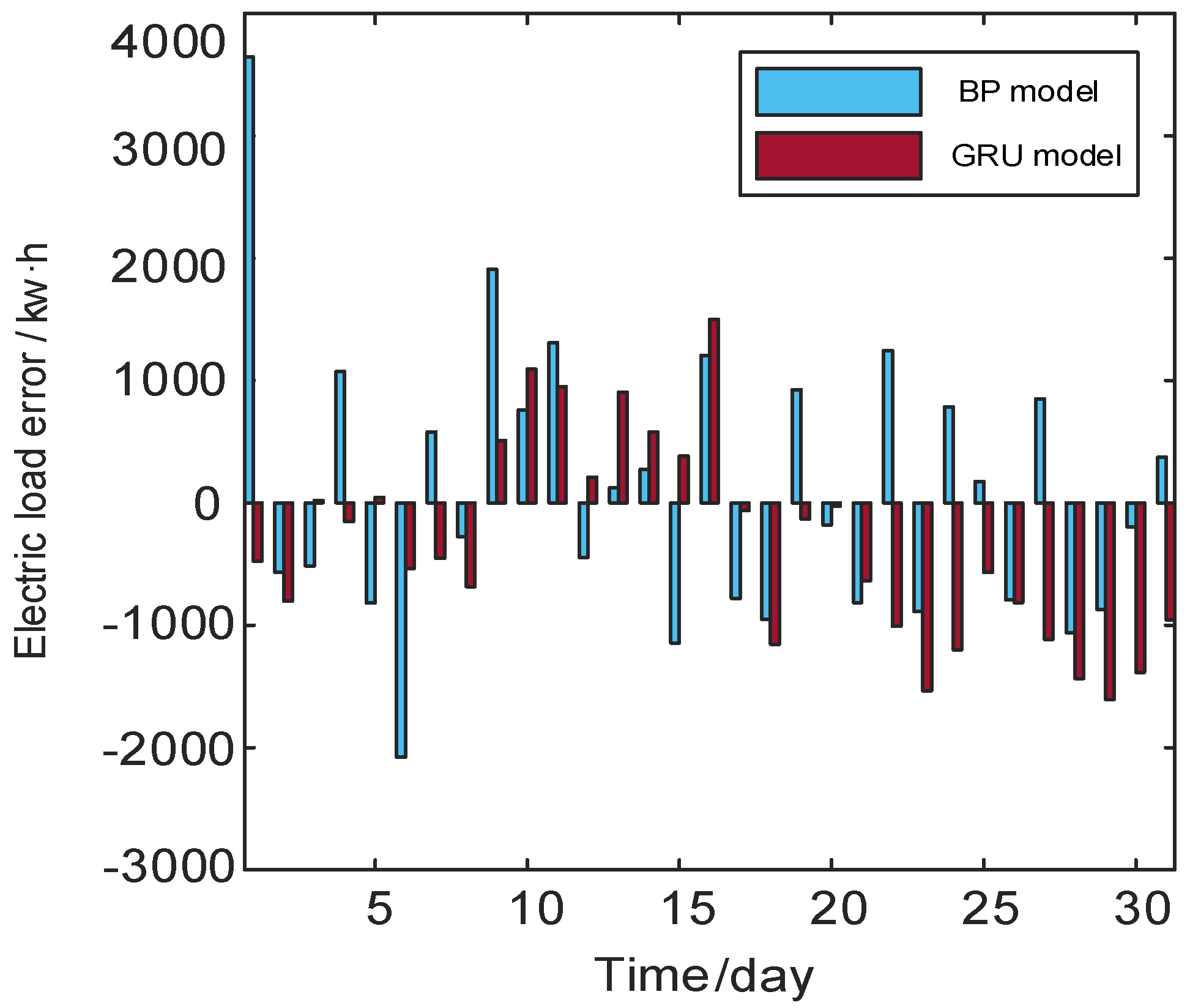
2.2.2. Model Comparison
2.3. Sparrow Search Algorithm
2.3.1. Update Discoverer Location
2.3.2. Update Follower Position
2.3.3. Update the Guard Position
2.4. Comparison of Optimization Algorithms
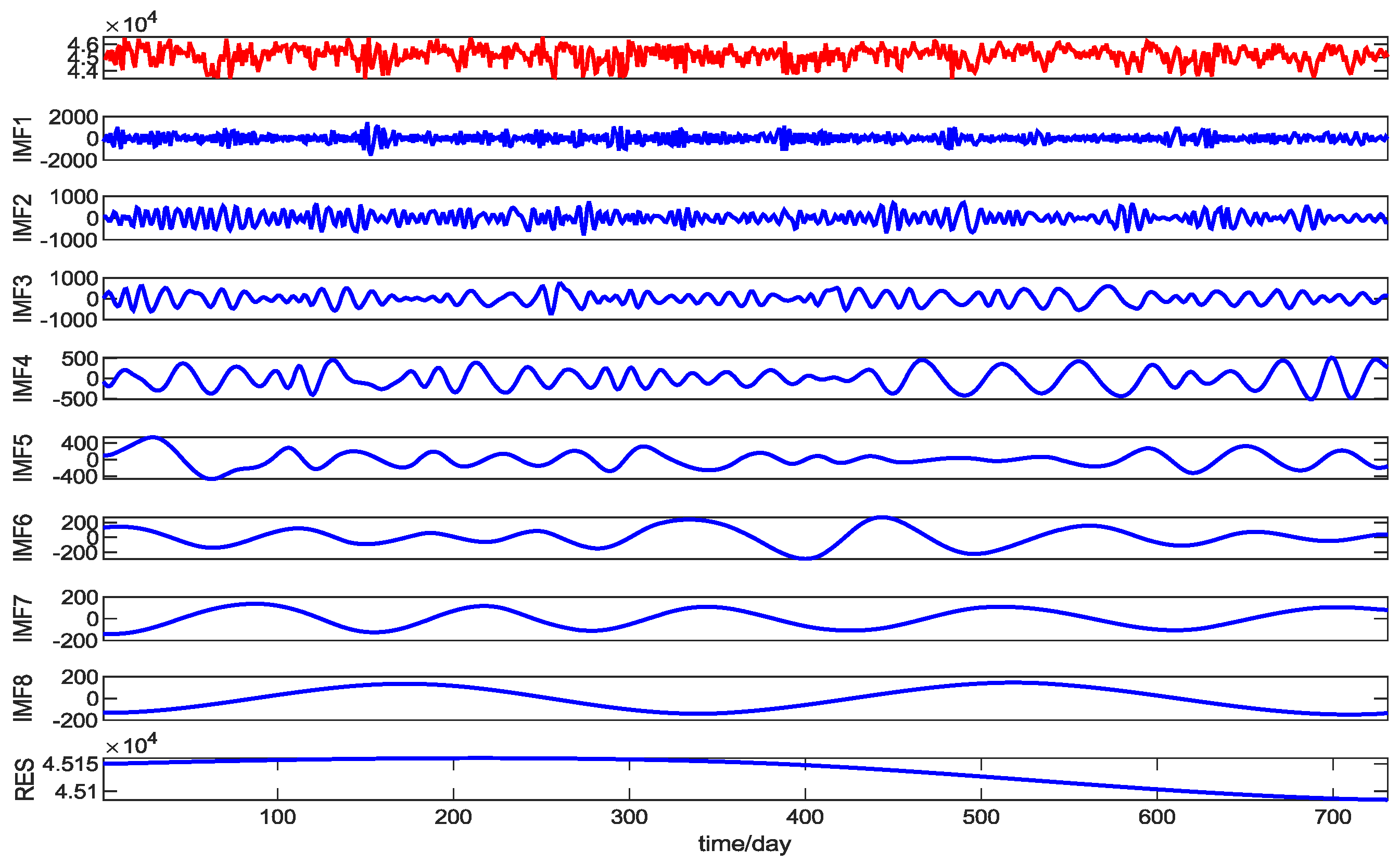
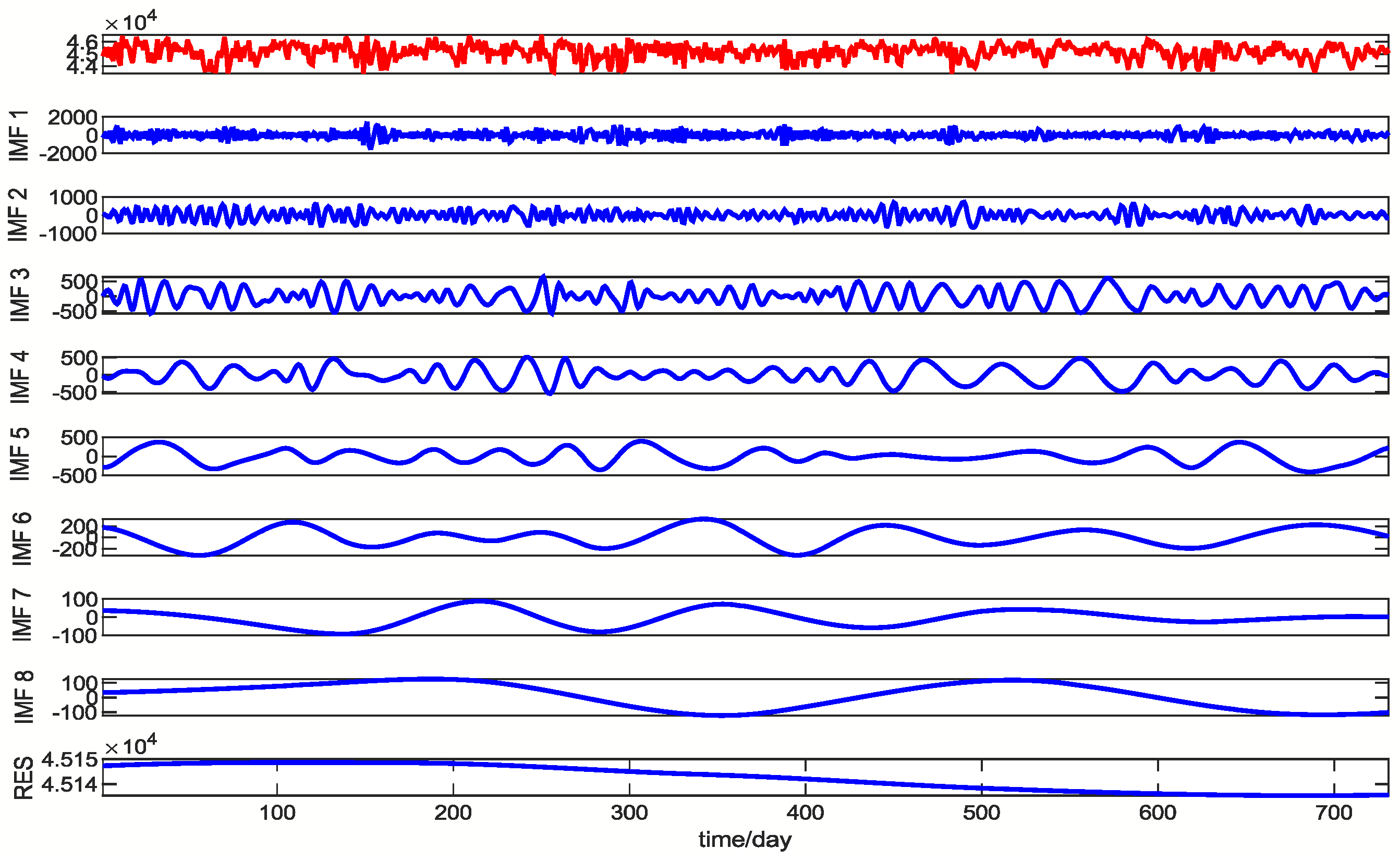
2.5. CEEMD
- (1)
- First, groups of white noise with opposite signs are added to the original signal to obtain a pair of new signals, which can be expressed as shown in Equation (15):where represents added white noise; denotes signals obtained by adding positive and negative white noise, respectively;
- (2)
- Then, EMD decomposition is performed on the 2n signals obtained, and a group of IMF components are obtained for each signal, and the jth IMF component of the ith signal is recorded as ; the last IMF component is taken as the residual component RES;
- (3)
- Finally, the 2n groups of IMF components obtained are averaged, and the components obtained by CEEMD decomposition of the original signal are expressed as:where represents the jth IMF component obtained after decomposition.
3. Combined Forecasting Model
3.1. Introduction to Combination Model
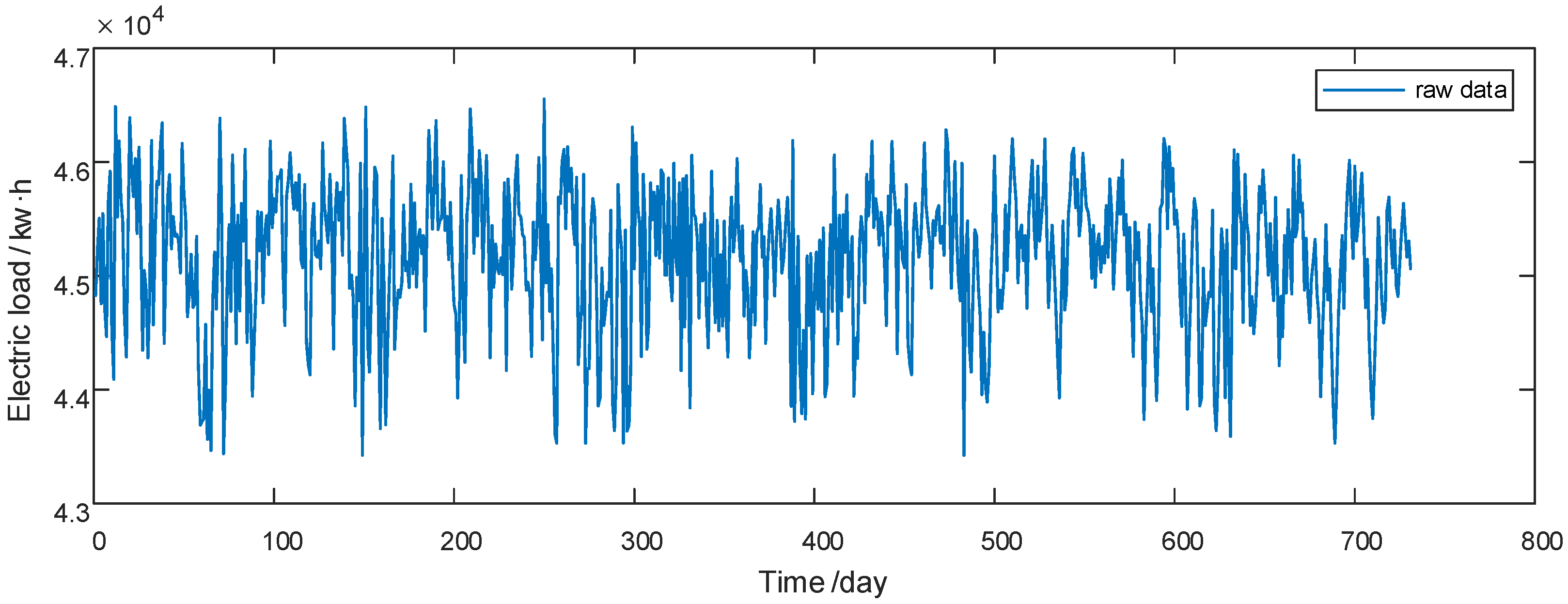
3.2. Model Example Analysis
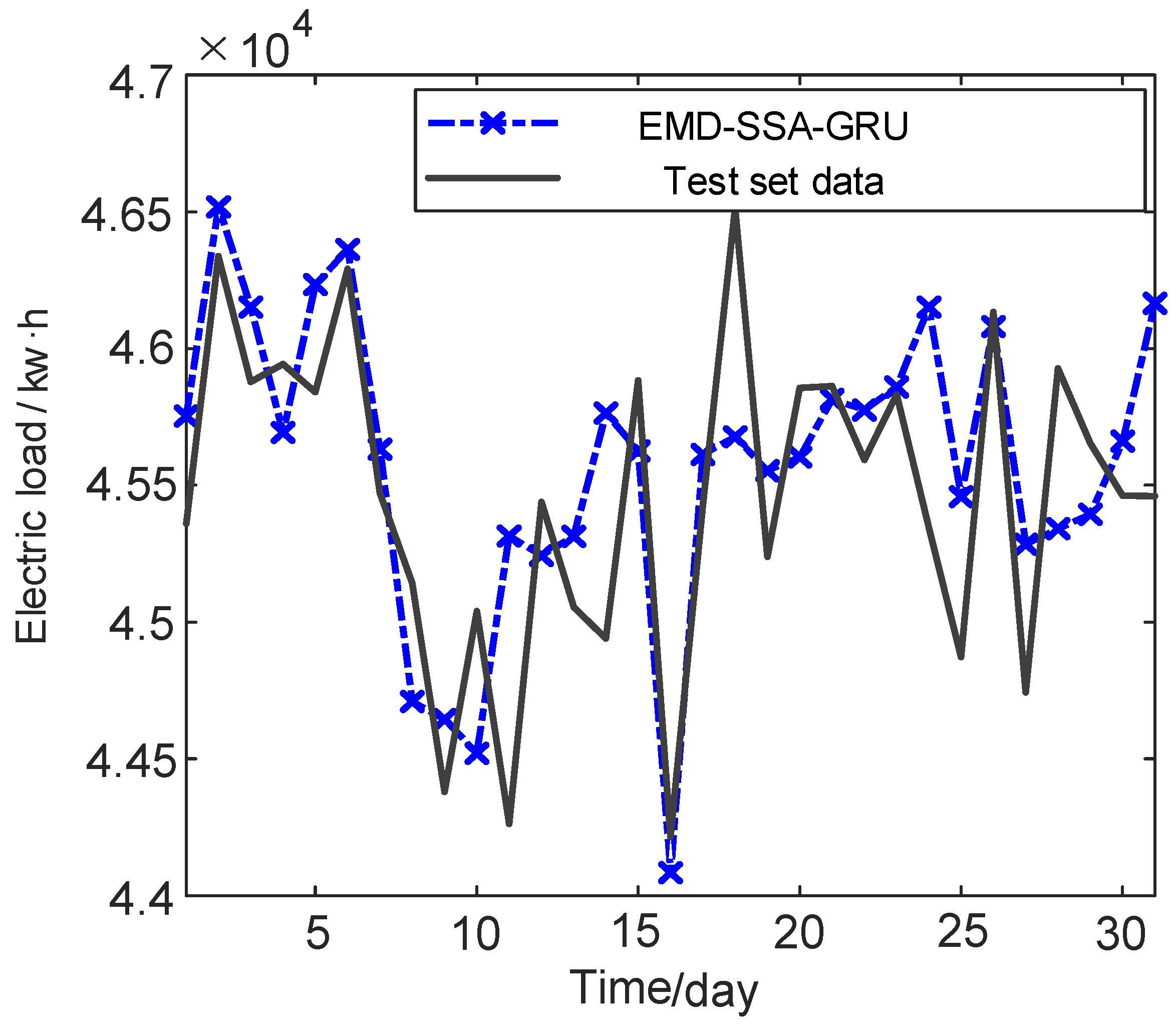
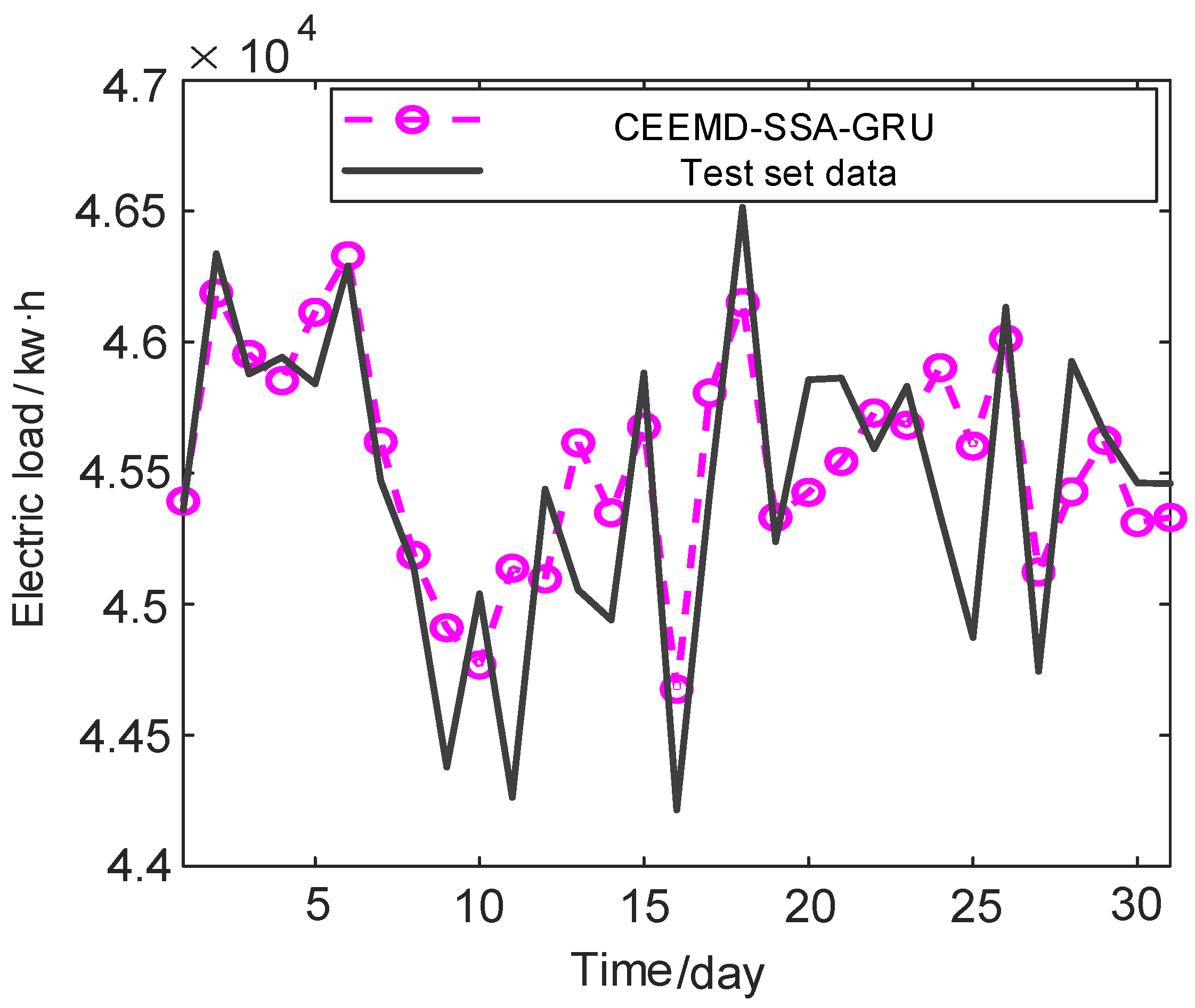
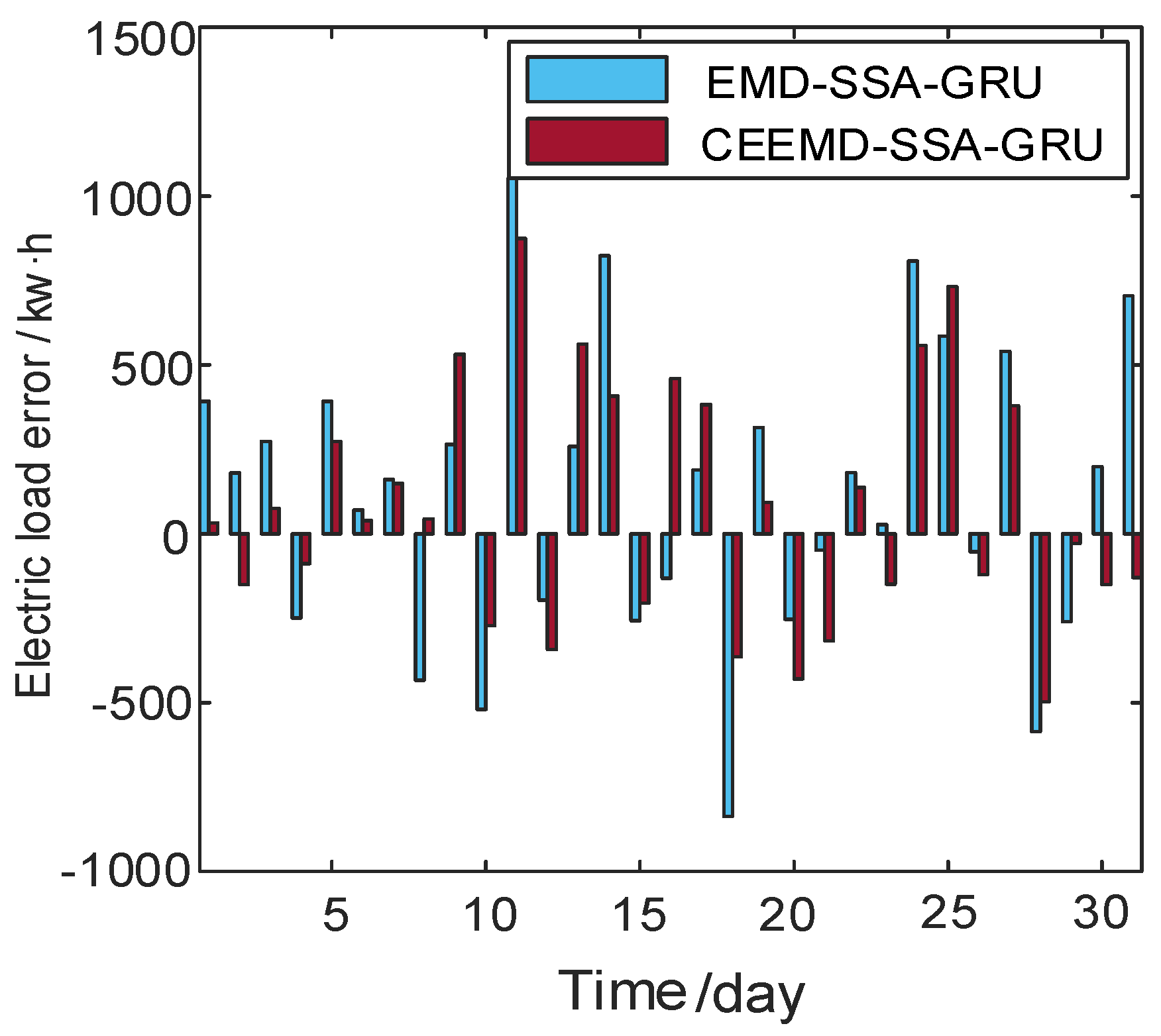
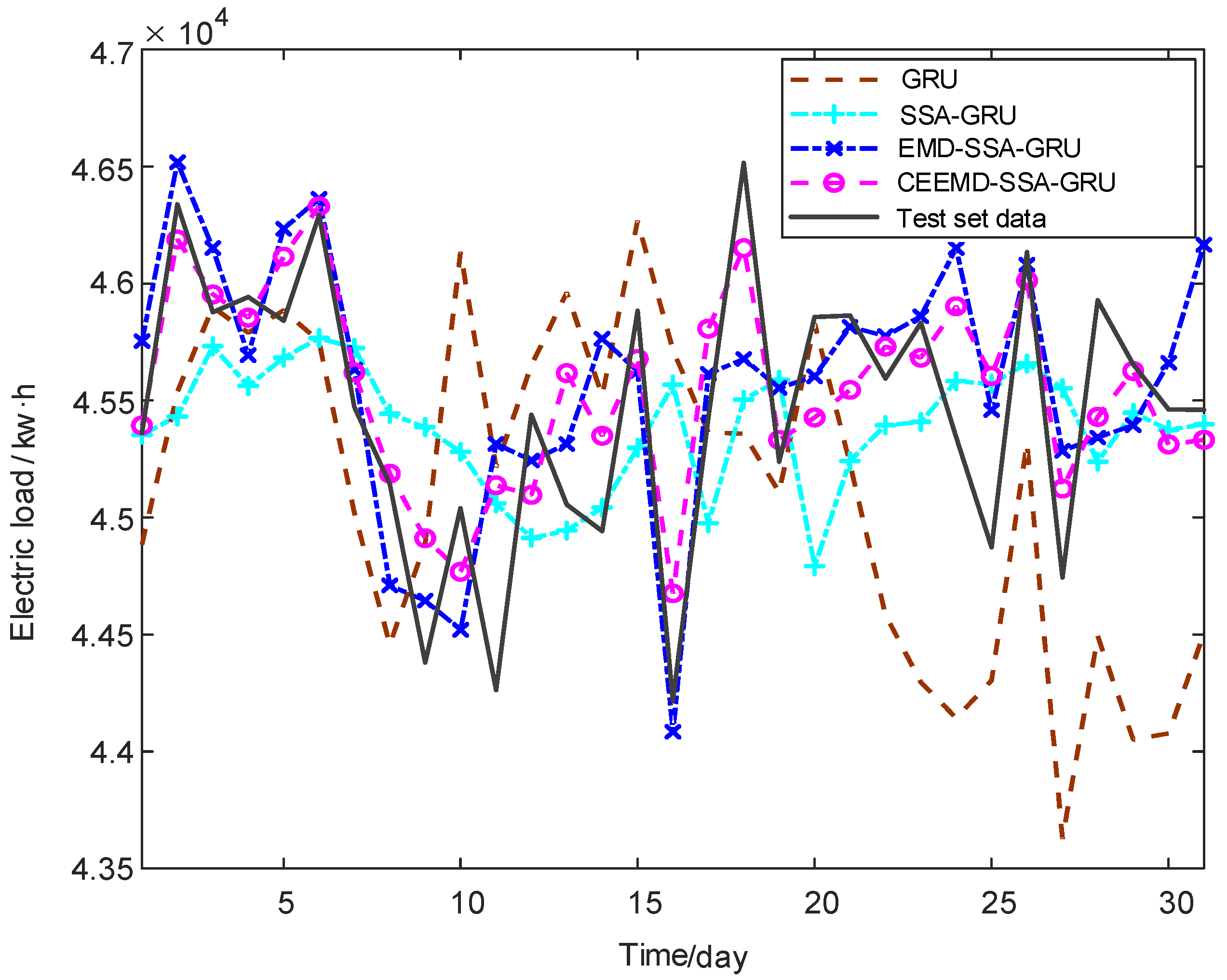
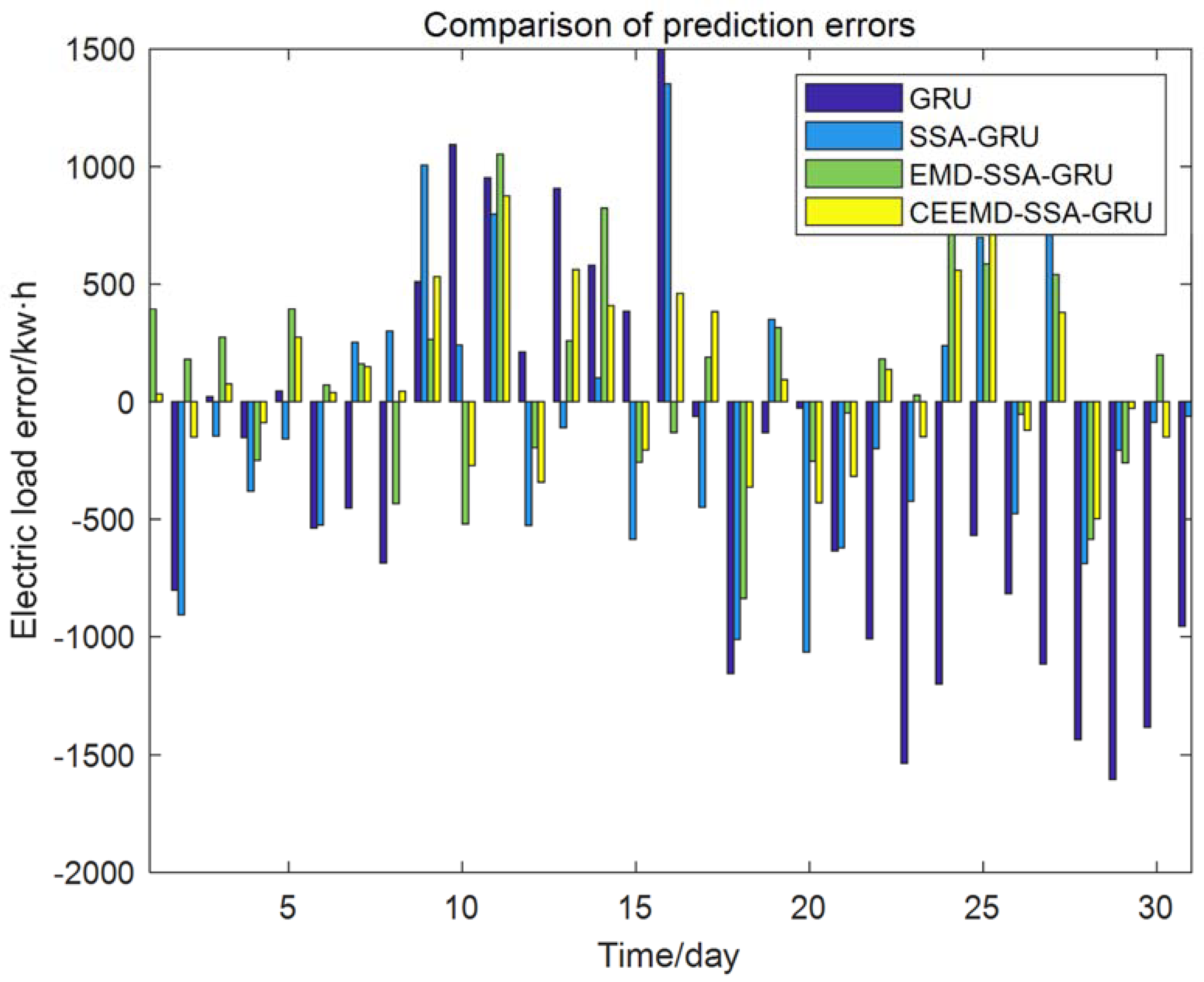
4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Haq, R.; Ni, Z. A New Hybrid Model for Short-Term Electricity Load Forecasting. IEEE Access 2019, 7, 125413–125423. [Google Scholar] [CrossRef]
- Chen, K.; Chen, K.; Wang, Q.; He, Z.; Hu, J.; He, J. Short-Term Load Forecasting With Deep Residual Networks. IEEE Trans. Smart Grid 2019, 10, 3943–3952. [Google Scholar] [CrossRef] [Green Version]
- Jie, C. Research on Short-term Power Load Forecasting Model and its Improvement Method. Master’s Thesis, China University of Mining and Technology, Beijing, China, 2020. [Google Scholar]
- Živanović, R. Local Regression-Based Short-Term Load Forecasting. J. Intell. Robot. Syst. 2001, 31, 115–127. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Theocharis, J.; Bakirtzis, A. Fuzzy modeling for short term load forecasting using the orthogonal least squares method. IEEE Trans. Power Syst. 1999, 14, 29–36. [Google Scholar] [CrossRef]
- Tsaur, R.-C. Forecasting by fuzzy double exponential smoothing model. Int. J. Comput. Math. 2003, 80, 1351–1361. [Google Scholar] [CrossRef]
- Amjady, N. Short-term hourly load forecasting using time-series modeling with peak load estimation capability. IEEE Trans. Power Syst. 2001, 16, 498–505. [Google Scholar] [CrossRef]
- Ma, T.; Wang, F.; Wang, J.; Yao, Y.; Chen, X. A combined model based on seasonal autoregressive integrated moving average and modified particle swarm optimization algorithm for electrical load forecasting. J. Intell. Fuzzy Syst. 2017, 32, 3447–3459. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, Z.Z.; Li, S. Research on power load forecasting based on support vector machine. J. Balk. Tribol. Assoc. 2016, 22, 151–159. [Google Scholar]
- Ribeiro, G.T.; Sauer, J.G.; Fraccanabbia, N.; Mariani, V.C.; Coelho, L.D.S. Bayesian Optimized Echo State Network Applied to Short-Term Load Forecasting. Energies 2020, 13, 2390. [Google Scholar] [CrossRef]
- Farahat, M.A.; Talaat, M. The Using of Curve Fitting Prediction Optimized by Genetic Algorithms for Short-Term Load Forecasting. Int. Rev. Electr. Eng. 2012, 7, 6209–6215. [Google Scholar] [CrossRef]
- Pandian, S.C.; Duraiswamy, K.; Rajan, C.C.A.; Kanagaraj, N. Fuzzy approach for short term load forecasting. Electr. Power Syst. Res. 2006, 76, 541–548. [Google Scholar] [CrossRef]
- Hernández, L.; Baladron, C.; Aguiar, J.M.; Calavia, L.; Carro, B.; Sánchez-Esguevillas, A.; Pérez, F.; Fernández, A.; Lloret, J. Artificial Neural Network for Short-Term Load Forecasting in Distribution Systems. Energies 2014, 7, 1576–1598. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.H.; Park, J.K.; Hwang, K.J.; Kim, S.H.; Han, H.G.; Kang, S.H. Implementation of short-term load forecasting expert systems in a real environment. Eng. Intell. Syst. Electr. Eng. Commun. 2000, 8, 139–144. [Google Scholar]
- Imani, M. Electrical load-temperature CNN for residential load forecasting. Energy 2021, 227, 120480. [Google Scholar] [CrossRef]
- Itoh, M.; Chua, L.O. DESIGNING CNN GENES. Int. J. Bifurc. Chaos 2003, 13, 2739–2824. [Google Scholar] [CrossRef]
- Shi, H.; Xu, M.; Li, R. Deep Learning for Household Load Forecasting—A Novel Pooling Deep RNN. IEEE Trans. Smart Grid 2017, 9, 5271–5280. [Google Scholar] [CrossRef]
- Kim, J.; Moon, J.; Hwang, E.; Kang, P. Recurrent inception convolution neural network for multi short-term load forecasting. Energy Build. 2019, 194, 328–341. [Google Scholar] [CrossRef]
- Hochreiter, S. The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Liu, M.; Bao, Z.; Zhang, S. Short-Term Load Forecasting with Multi-Source Data Using Gated Recurrent Unit Neural Networks. Energies 2018, 11, 1138. [Google Scholar] [CrossRef] [Green Version]
- Rafi, S.H.; Masood, N.A.; Deeba, S.R.; Hossain, E. A Short-Term Load Forecasting Method Using Integrated CNN and LSTM Network. IEEE Access 2021, 9, 32436–32448. [Google Scholar] [CrossRef]
- Shi, H.; Miao, K.; Ren, X. Short-term load forecasting based on CNN-BiLSTM with Bayesian optimization and attention mechanism. Concurr. Comput. Pr. Exp. 2021, 12606, e6676. [Google Scholar] [CrossRef]
- Gao, X.; Li, X.; Zhao, B.; Ji, W.; Jing, X.; He, Y. Short-Term Electricity Load Forecasting Model Based on EMD-GRU with Feature Selection. Energies 2019, 12, 1140. [Google Scholar] [CrossRef]
- Liao, G.-C. Fusion of Improved Sparrow Search Algorithm and Long Short-Term Memory Neural Network Application in Load Forecasting. Energies 2021, 15, 130. [Google Scholar] [CrossRef]


















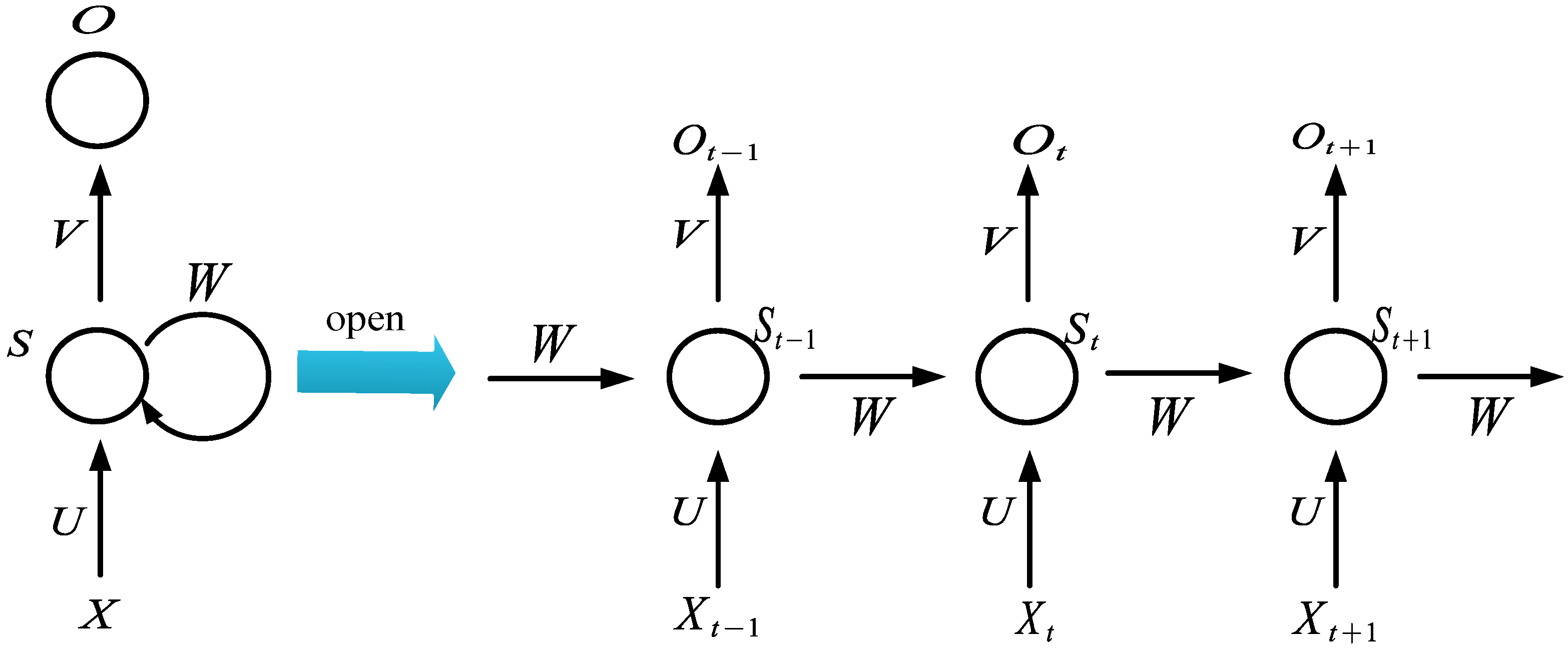{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time/Days | Actual Value (kw·h) | BP Predicted Value (kw·h) | GRU Predicted Value (kw·h) | Time/Days | Actual Value (kw·h) | BP Predicted Value (kw·h) | GRU Predicted Value (kw·h) |
|---|---|---|---|---|---|---|---|
| 1 | 45,360.37 | 49,005.88 | 44,884.87 | 17 | 45,424.44 | 44,644.86 | 45,362.05 |
| 2 | 46,338.27 | 45,771.37 | 45,536.35 | 18 | 46,514.46 | 45,562.02 | 45,358.09 |
| 3 | 45,877.85 | 45,362.05 | 45,899.23 | 19 | 45,238.45 | 46,166.70 | 45,106.73 |
| 4 | 45,942.52 | 47,015.26 | 45,789.56 | 20 | 45,856.65 | 45,677.46 | 45,829.11 |
| 5 | 45,840.91 | 45,021.95 | 45,886.01 | 21 | 45,862.76 | 45,046.72 | 45,227.82 |
| 6 | 46,291.17 | 44,214.40 | 45,753.38 | 22 | 45,593.45 | 46,841.13 | 44,584.44 |
| 7 | 45,471.49 | 46,052.58 | 45,018.84 | 23 | 45,831.85 | 44,945.20 | 44,296.32 |
| 8 | 45,142.91 | 44,868.51 | 44,456.50 | 24 | 45,343.99 | 46,129.58 | 44,143.25 |
| 9 | 44,379.54 | 46,287.86 | 44,890.29 | 25 | 44,872.57 | 45,047.65 | 44,303.67 |
| 10 | 45,039.70 | 45,801.54 | 46,133.09 | 26 | 46,133.70 | 45,341.62 | 45,317.62 |
| 11 | 44,262.69 | 45,572.41 | 45,215.21 | 27 | 44,743.78 | 45,592.95 | 43,627.78 |
| 12 | 45,438.92 | 44,993.34 | 45,650.29 | 28 | 45,927.41 | 44,866.74 | 44,493.00 |
| 13 | 45,054.37 | 45,178.43 | 45,961.51 | 29 | 45,654.40 | 44,784.20 | 44,050.53 |
| 14 | 44,940.83 | 45,213.52 | 45,521.12 | 30 | 45,462.24 | 45,267.86 | 44,076.97 |
| 15 | 45,883.15 | 44,737.06 | 46,267.10 | 31 | 45,460.24 | 45,833.42 | 44,504.96 |
| 16 | 44,214.98 | 45,417.60 | 45,714.39 |
| Optimization Algorithm | Set Value |
|---|---|
| GA | Crossing probability = 0.8; Variation probability = 0.05 |
| PSO | Acceleration factor c1, c2 = 1.5; Inertia factor w = 0.8 |
| ABC | Maximum mining times of honey source = 100 |
| SSA | The discoverers account for 20%, the vigilantes account for 10%, ST = 0.6 |
| Relevant Parameters | Set Value |
|---|---|
| Population number | 20 |
| Number of iterations | 50 |
| Safety threshold | 0.6 |
| Number of discoverers | 20% |
| Number of vigilantes | 10% |
| Time/Day | Actual Value (kw·h) | EMD–SSA–GRU (kw·h) | CEEMD–SSA–GRU (kw·h) | Time/Day | Actual Value (kw·h) | EMD–SSA–GRU (kw·h) | CEEMD–SSA–GRU (kw·h) |
|---|---|---|---|---|---|---|---|
| 1 | 45,360.37 | 45,753.35 | 45,392.99 | 17 | 45,424.44 | 45,613.16 | 45,806.91 |
| 2 | 46,338.27 | 46,518.48 | 46,188.03 | 18 | 46,514.46 | 45,677.67 | 46,150.98 |
| 3 | 45,877.85 | 46,151.58 | 45,953.33 | 19 | 45,238.45 | 45,553.17 | 45,332.02 |
| 4 | 45,942.52 | 45,693.28 | 45,853.42 | 20 | 45,856.65 | 45,603.49 | 45,426.96 |
| 5 | 45,840.91 | 46,234.02 | 46,114.57 | 21 | 45,862.76 | 45,814.70 | 45,545.24 |
| 6 | 46,291.17 | 46,362.10 | 46,330.02 | 22 | 45,593.45 | 45,775.15 | 45,730.47 |
| 7 | 45,471.49 | 45,632.27 | 45,620.18 | 23 | 45,831.85 | 45,859.43 | 45,682.67 |
| 8 | 45,142.91 | 44,709.40 | 45,187.37 | 24 | 45,343.99 | 46,151.51 | 45,902.67 |
| 9 | 44,379.54 | 44,644.54 | 44,911.17 | 25 | 44,872.57 | 45,458.34 | 45,604.36 |
| 10 | 45,039.70 | 44,519.86 | 44,767.94 | 26 | 46,133.70 | 46,080.31 | 46,012.50 |
| 11 | 44,262.69 | 45,314.84 | 45,137.64 | 27 | 44,743.78 | 45,284.60 | 45,123.53 |
| 12 | 45,438.92 | 45,243.34 | 45,096.62 | 28 | 45,927.41 | 45,341.90 | 45,429.72 |
| 13 | 45,054.37 | 45,313.75 | 45,616.59 | 29 | 45,654.40 | 45,394.16 | 45,626.17 |
| 14 | 44,940.83 | 45,764.07 | 45,349.38 | 30 | 45,462.24 | 45,661.05 | 45,312.03 |
| 15 | 45,883.15 | 45,625.53 | 45,677.65 | 31 | 45,460.24 | 46,165.21 | 45,331.24 |
| 16 | 44,214.98 | 44,083.94 | 44,675.42 |
| Model | MAPE | MAE (%) | RMSE (%) |
|---|---|---|---|
| EMD–SSA–GRU | 0.0080 | 3.63 | 4.47 |
| CEEMD–SSA–GRU | 0.0064 | 2.90 | 3.60 |
| Model | MAPE | MAE (%) | RMSE (%) |
|---|---|---|---|
| GRU | 0.0163 | 7.40 | 8.82 |
| SSA–GRU | 0.0105 | 4.76 | 5.86 |
| EMD–SSA–GRU | 0.0080 | 3.63 | 4.47 |
| CEEMD–SSA–GRU | 0.0064 | 2.90 | 3.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Guo, Q.; Shao, L.; Li, J.; Wu, H. Research on Short-Term Load Forecasting Based on Optimized GRU Neural Network. Electronics 2022, 11, 3834. https://doi.org/10.3390/electronics11223834
Li C, Guo Q, Shao L, Li J, Wu H. Research on Short-Term Load Forecasting Based on Optimized GRU Neural Network. Electronics. 2022; 11(22):3834. https://doi.org/10.3390/electronics11223834
Chicago/Turabian StyleLi, Chao, Quanjie Guo, Lei Shao, Ji Li, and Han Wu. 2022. "Research on Short-Term Load Forecasting Based on Optimized GRU Neural Network" Electronics 11, no. 22: 3834. https://doi.org/10.3390/electronics11223834
APA StyleLi, C., Guo, Q., Shao, L., Li, J., & Wu, H. (2022). Research on Short-Term Load Forecasting Based on Optimized GRU Neural Network. Electronics, 11(22), 3834. https://doi.org/10.3390/electronics11223834