
UFace: An Unsupervised Deep Learning Face Verification System


Abstract
:1. Introduction
- Unlike many other face verification methods, the UFace system uses the k most similar and k most dissimilar images of the original input face image for training.
- The k most similar/dissimilar images are selected from a small amount of training data, significantly increasing the size of data available for training in applications where only small datasets exist. For example, having only 100 images with k = 10 results in 1 K + 1 K training images.
- To use the k most similar/dissimilar images, we propose the new loss functions for calculating the error.
- The performance of the UFace system is demonstrated using autoencoder and Siamese networks.
2. System Architecture
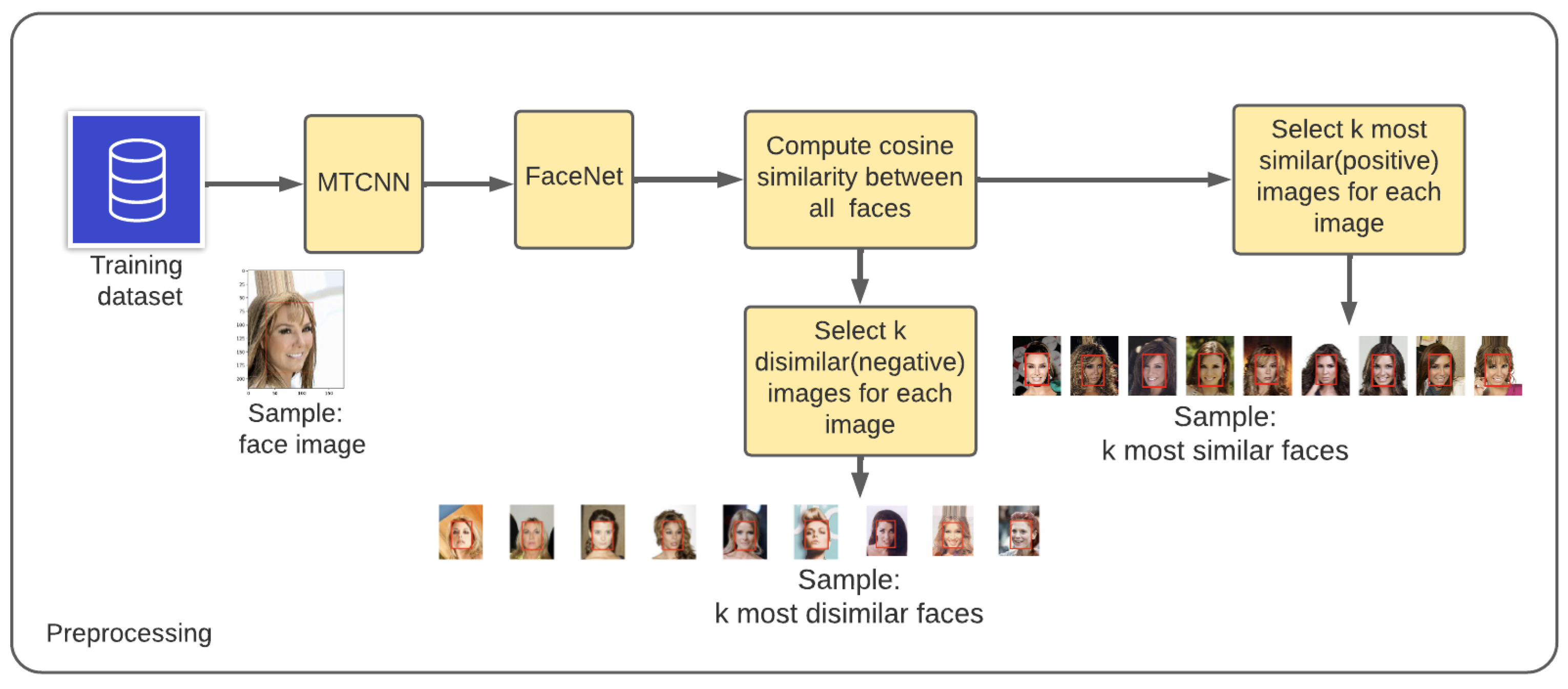
2.1. Preprocessing
| Algorithm 1 To select the k most similar and k most dissimilar images for each image in a dataset. |
| Require: The thresholds ths and thd, and m training images x Ensure: k most similar () and k most dissimilar images () for each image in a dataset, 1 ≤ i ≤ m, 1 ≤ p ≤ k and 1 ≤ n ≤ k for to N, N← do for to N, N← do if = cosine(, ) end for end for Select k most similar images above the ths = 0.6, and randomly select k most dissimilar images below the thd = 0.2, end |
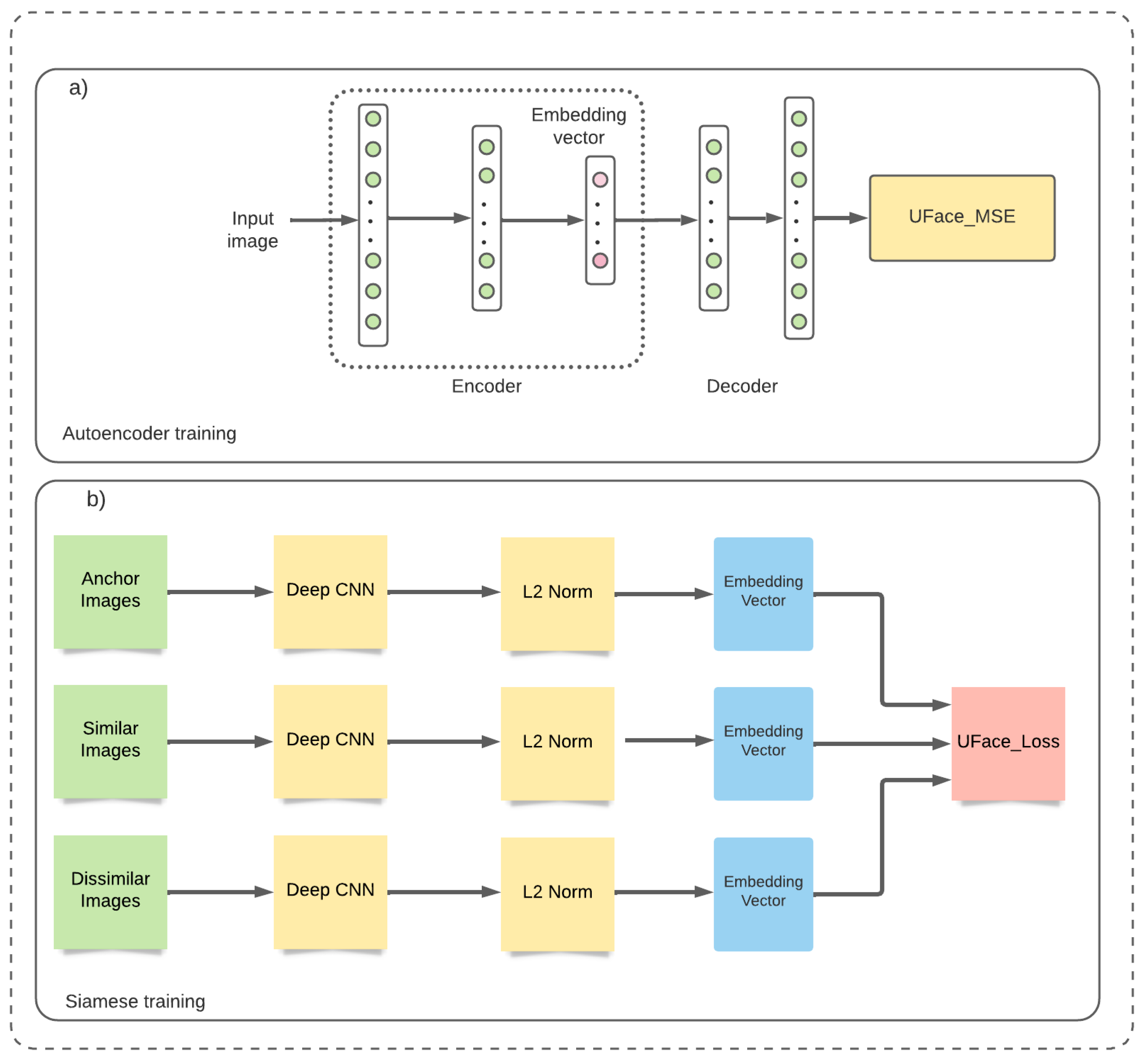
2.2. Training
2.2.1. UFace with Autoencoder Training
2.2.2. UFace with Siamese Training
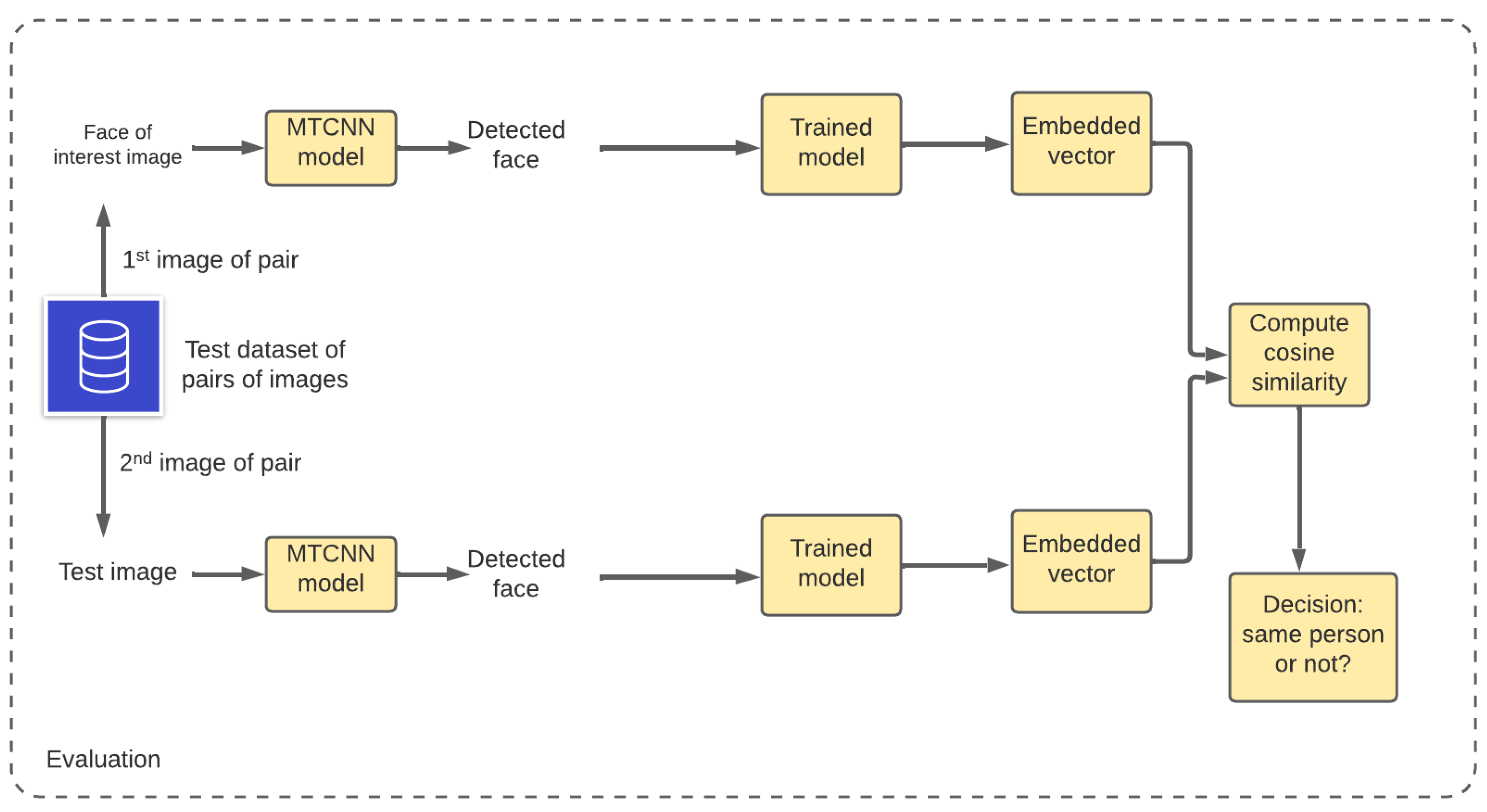
2.3. Evaluation
3. Datasets Used
4. Experiments
4.1. Experimental Setup
4.2. UFace Training Using Autoencoder and Comparing It with Classical Autoencoder Training
4.3. UFace Training Using Siamese Network
4.3.1. Comparison of UFace on LFW Dataset
4.3.2. Comparison of the UFace on YTF Dataset
4.3.3. Comparison of UFace on CALFW and CFP-FP Datasets
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jain, A.; Li, S. Handbook of Face Recognition; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Woubie, A.; Koivisto, L.; Bäckström, T. Voice-quality Features for Deep Neural Network Based Speaker Verification Systems. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 176–180. [Google Scholar]
- Nagrani, A.; Chung, J.; Xie, W.; Zisserman, A. Voxceleb: Large-scale speaker verification in the wild. Comput. Speech Lang. 2020, 60, 101027. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cios, K.; Shin, I. Image recognition neural network: IRNN. Neurocomputing 1995, 7, 159–185. [Google Scholar] [CrossRef]
- Shin, J.; Smith, D.; Swiercz, W.; Staley, K.; Rickard, J.; Montero, J.; Kurgan, L.; Cios, K. Recognition of partially occluded and rotated images with a network of spiking neurons. IEEE Trans. Neural Netw. 2010, 21, 1697–1709. [Google Scholar] [CrossRef] [PubMed]
- Cachi, P.; Ventura, S.; Cios, K. CRBA: A Competitive Rate-Based Algorithm Based on Competitive Spiking Neural Networks. Front. Comput. Neurosci. 2021, 15, 627567. [Google Scholar] [CrossRef] [PubMed]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Parkhi, O.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. British Machine Vision Association. 2015. Available online: http://www.bmva.org/bmvc/2015/papers/paper041/paper041.pdf (accessed on 11 May 2022).
- Zhu, Z.; Luo, P.; Wang, X.; Tang, X. Recover canonical-view faces in the wild with deep neural networks. arXiv 2014, arXiv:1404.3543. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Huang, Y.; Wang, Y.; Tai, Y.; Liu, X.; Shen, P.; Li, S.; Li, J.; Huang, F. Curricularface: Adaptive curriculum learning loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5901–5910. [Google Scholar]
- Deng, J.; Guo, J.; Yang, J.; Lattas, A.; Zafeiriou, S. Variational prototype learning for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11906–11915. [Google Scholar]
- Deng, J.; Zhou, Y.; Zafeiriou, S. Marginal loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 60–68. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. Deepid3: Face recognition with very deep neural networks. arXiv 2015, arXiv:1502.00873. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Web-scale training for face identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2746–2754. [Google Scholar]
- Kim, Y.; Park, W.; Roh, M.; Shin, J. Groupface: Learning latent groups and constructing group-based representations for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5621–5630. [Google Scholar]
- Wang, X.; Zhang, S.; Wang, S.; Fu, T.; Shi, H.; Mei, T. Mis-classified vector guided softmax loss for face recognition. AAAI Conf. Artif. Intell. 2020, 34, 12241–12248. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, X.; Cheng, Z.; Shen, X. A face recognition algorithm based on feature fusion. Concurr. Comput. Pract. Exp. 2022, 34, e5748. [Google Scholar] [CrossRef]
- Marcialis, G.; Roli, F. Fusion of LDA and PCA for Face Verification. In Proceedings of the International Workshop on Biometric Authentication, Copenhagen, Denmark, 1 June 2002; pp. 30–37. [Google Scholar]
- Marcel, S.; Bengio, S. Improving face verification using skin color information. Object Recognit. Support. User Interact. Serv. Robot. 2022, 2, 378–381. [Google Scholar]
- McCool, C.; Marcel, S. Parts-based face verification using local frequency bands. In Proceedings of the International Conference on Biometrics, Alghero, Italy, 2–5 June 2009; pp. 259–268. [Google Scholar]
- Pereira, T.; Angeloni, M.; Simões, F.; Silva, J. Video-based face verification with local binary patterns and svm using gmm supervectors. In Proceedings of the International Conference on Computational Science and Its Applications, Salvador de Bahia, Brazil, 8–21 June 2012; pp. 240–252. [Google Scholar]
- Wang, Y.; Wu, Q. Research on Face Recognition Technology Based on PCA and SVM. In Proceedings of the 2022 7th International Conference on Big Data Analytics (ICBDA), Guangzhou, China, 4–6 March 2022; pp. 248–252. [Google Scholar]
- Serson, C.; Saban, M.; Gao, Y. On local features for GMM based face verification. In Proceedings of the Third International Conference on Information Technology and Applications (ICITA’05), Sydney, Australia, 4–7 July 2005; Volume 1, pp. 650–655. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a" siamese" time delay neural network. Adv. Neural Inf. Process. Syst. 1993, 6, 737–744. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database Forstudying Face Recognition in Unconstrained Environments. 2008. Available online: https://hal.inria.fr/inria-00321923 (accessed on 10 May 2022).
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the CVPR, Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Meng, Q.; Zhao, S.; Huang, Z.; Zhou, F. Magface: A universal representation for face recognition and quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14225–14234. [Google Scholar]
- Huang, X.; Zeng, X.; Wu, Q.; Lu, Y.; Huang, X.; Zheng, H. Face Verification Based on Deep Learning for Person Tracking in Hazardous Goods Factories. Processes 2022, 10, 380. [Google Scholar] [CrossRef]
- Elaggoune, H.; Belahcene, M.; Bourennane, S. Hybrid descriptor and optimized CNN with transfer learning for face recognition. Multimed. Tools Appl. 2022, 81, 9403–9427. [Google Scholar] [CrossRef]
- Ben Fredj, H.; Bouguezzi, S.; Souani, C. Face recognition in unconstrained environment with CNN. Vis. Comput. 2021, 37, 217–226. [Google Scholar] [CrossRef]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.; Cubuk, E.; Kurakin, A.; Li, C. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 132–149. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. arXiv 2018, arXiv:1803.07728. [Google Scholar]
- Shu, Y.; Yan, Y.; Chen, S.; Xue, J.; Shen, C.; Wang, H. Learning spatial-semantic relationship for facial attribute recognition with limited labeled data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11916–11925. [Google Scholar]
- He, M.; Zhang, J.; Shan, S.; Chen, X. Enhancing Face Recognition With Self-Supervised 3D Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, Louisiana, USA, 21–24 June 2022; pp. 4062–4071. [Google Scholar]
- Yin, J.; Xu, Y.; Wang, N.; Li, Y.; Guo, S. Mask Guided Unsupervised Face Frontalization using 3D Morphable Model from Single-View Images: A face frontalization framework that can generate identity preserving frontal view image while maintaining the background and color tone from input with only front images for training using 3D Morphable Model. In Proceedings of the 2022 4th Asia Pacific Information Technology Conference, Bangkok, Thailand, 14–16 January 2022; pp. 23–30. [Google Scholar]
- Khan, M.; Jabeen, S.; Khan, M.; Saba, T.; Rehmat, A.; Rehman, A.; Tariq, U. A realistic image generation of face from text description using the fully trained generative adversarial networks. IEEE Access 2020, 9, 1250–1260. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, J. Unsupervised face frontalization for pose-invariant face recognition. Image Vis. Comput. 2021, 106, 104093. [Google Scholar] [CrossRef]
- Hu, Y.; Wu, X.; Yu, B.; He, R.; Sun, Z. Pose-guided photorealistic face rotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8398–8406. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 30. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Zabalza, J.; Ren, J.; Zheng, J.; Zhao, H.; Qing, C.; Yang, Z.; Du, P.; Marshall, S. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing 2016, 185, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Ling, Z.; Kang, S.; Zen, H.; Senior, A.; Schuster, M.; Qian, X.; Meng, H.; Deng, L. Deep learning for acoustic modeling in parametric speech generation: A systematic review of existing techniques and future trends. IEEE Signal Process. Mag. 2015, 32, 35–52. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Zheng, T.; Deng, W.; Hu, J. Cross-age lfw: A database for studying cross-age face recognition in unconstrained environments. arXiv 2017, arXiv:1708.08197. [Google Scholar]
- Sengupta, S.; Chen, J.C.; Castillo, C.; Patel, V.M.; Chellappa, R.; Jacobs, D.W. Frontal to Profile Face Verification in the Wild. In Proceedings of the IEEE Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Chollet, F. Keras, GitHub. 2015. Available online: https://github.com/fchollet/keras (accessed on 11 May 2022).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Duan, Y.; Lu, J.; Zhou, J. Uniformface: Learning deep equidistributed representation for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3415–3424. [Google Scholar]
- Zhao, K.; Xu, J.; Cheng, M. Regularface: Deep face recognition via exclusive regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1136–1144. [Google Scholar]
- Kang, B.; Kim, Y.; Jun, B.; Kim, D. Attentional feature-pair relation networks for accurate face recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 5472–5481. [Google Scholar]
- Rashedi, E.; Barati, E.; Nokleby, M.; Chen, X. “Stream loss”: ConvNet learning for face verification using unlabeled videos in the wild. Neurocomputing 2019, 329, 311–319. [Google Scholar] [CrossRef]
- Boragule, A.; Akram, H.; Kim, J.; Jeon, M. Learning to Resolve Uncertainties for Large-Scale Face Recognition. Pattern Recognit. Lett. 2022, 160, 58–65. [Google Scholar] [CrossRef]
- Wang, K.; Wang, S.; Zhang, P.; Zhou, Z.; Zhu, Z.; Wang, X.; Peng, X.; Sun, B.; Li, H.; You, Y. An efficient training approach for very large scale face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 4083–4092. [Google Scholar]
- Yang, J.; Ren, P.; Zhang, D.; Chen, D.; Wen, F.; Li, H.; Hua, G. Neural aggregation network for video face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4362–4371. [Google Scholar]
- Sohn, K.; Liu, S.; Zhong, G.; Yu, X.; Yang, M.; Chandraker, M. Unsupervised domain adaptation for face recognition in unlabeled videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3210–3218. [Google Scholar]
- Jiao, J.; Liu, W.; Mo, Y.; Jiao, J.; Deng, Z.; Chen, X. Dyn-arcFace: Dynamic additive angular margin loss for deep face recognition. Multimed. Tools Appl. 2021, 80, 25741–25756. [Google Scholar] [CrossRef]
- Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, L.; Wang, Z.; Wei, Y. Circle loss: A unified perspective of pair similarity optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6398–6407. [Google Scholar]
- Wang, M.; Deng, W.; Hu, J.; Tao, X.; Huang, Y. Racial faces in the wild: Reducing racial bias by information maximization adaptation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27–28 October 2019; pp. 692–702. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | LFW | YTF | CALFW | CFP-FP |
|---|---|---|---|---|
| UFace * | 92.76 | 89.97 | 89.22 | 91.88 |
| UFace ** | 95.81 | 93.24 | 92.63 | 95.13 |
| UFace *** | 96.42 | 93.92 | 93.08 | 95.78 |
| Model | Training Data Size | Labeled/Unlabeled | Testing Data Size | Testing Accuracy (%) |
|---|---|---|---|---|
| Fusion | 500 M | Labeled | 6 K | 98.37 [18] |
| Facenet | 200 M | Labeled | 6 K | 99.63 [8] |
| UniformFace | 6.1 M | Labeled | 6 K | 99.80 [60] |
| ArcFace | 5.8 M | Labeled | 6 K | 99.82 [16] |
| GroupFace | 5.8 M | Labeled | 6 K | 99.85 [19] |
| CosFace | 5 M | Labeled | 6 K | 99.73 [12] |
| DeepFace-ensemble | 4.4 M | Labeled | 6 K | 97.35 [9] |
| Marginal Loss | 4 M | Labeled | 6 K | 99.48 [15] |
| CurricularFace | 3.8 M | Labeled | 6 K | 99.80 [13] |
| RegularFace | 3.1 M | Labeled | 6 K | 99.61 [61] |
| AFRN | 3.1 M | Labeled | 6 K | 99.85 [62] |
| VGG Face | 2.6 M | Labeled | 6 K | 98.95 [10] |
| Stream Loss | 1.5 M | Labeled | 6 K | 98.97 [63] |
| MDCNN | 1 M | Labeled | 6 K | 99.38 [32] |
| PSO AlexNet TL | 14 M | Labeled | 6 K | 99.57 [33] |
| ULNet | 1 M | Labeled | 6 K | 99.70 [64] |
| Ben Face | 0.5 M | Labeled | 6 K | 99.20 [34] |
| FC | 5.8 M | Labeled | 6 K | 99.83 [65] |
| PCCycleGAN | 0.5 M | Unlabeled | 6 K | 99.52 [43] |
| CAPG GAN | 1 M | Unlabeled | 6 K | 99.37 [44] |
| UFace | 200 K | Unlabeled | 6 K | 99.40 |
| Model | Training Data Size | Labeled/Unlabeled | Testing Data Size | Testing Accuracy (%) |
|---|---|---|---|---|
| Facenet | 200 M | Labeled | 5 K | 95.12 [8] |
| UniformFace | 6.1 M | Labeled | 5 K | 97.70 [60] |
| ArcFace | 5.8 M | Labeled | 5 K | 98.02 [16] |
| GroupFace | 5.8 M | Labeled | 5 K | 97.80 [19] |
| CosFace | 5 M | Labeled | 5 K | 97.60 [12] |
| DeepFace-single | 4.4 M | Labeled | 5 K | 91.40 [9] |
| Marginal Loss | 4 M | Labeled | 5 K | 95.98 [15] |
| RegularFace | 3.1 M | Labeled | 5 K | 96.70 [61] |
| AFRN | 3.1 M | Labeled | 5 K | 97.70 [62] |
| NAN | 3 M | Labeled | 5 K | 95.70 [66] |
| VGG Face | 2.6 M | Labeled | 5 K | 97.30 [10] |
| Stream Loss | 1.5 M | Labeled | 5 K | 96.40 [63] |
| MDCNN | 1 M | Labeled | 5 K | 94.69 [32] |
| Ben Face | 0.5 M | Labeled | 5 K | 96.63 [34] |
| FC | 1 M | Labeled | 5 K | 97.76 [65] |
| CORAL | 0.5 M | Unlabeled | 5 K | 94.50 [45] |
| UDAFRUV | 0.5 M | Unlabeled | 5 K | 95.38 [67] |
| UFace | 200 K | Unlabeled | 5 K | 96.04 |
| Model | Training Data Size | Labeled or Unlabeled | Testing Data Size | Testing Accuracy (%) |
|---|---|---|---|---|
| ArcFace | 5.8 M | Labeled | 6 K | 95.45 [16] |
| GroupFace | 5.8 M | Labeled | 6 K | 96.20 [19] |
| CurricularFace | 3.8 M | labeled | 6 K | 96.20 [13] |
| MegaFace | 3.8 M | Labeled | 6 K | 96.15 [31] |
| ULNet | 1 M | Labeled | 6 K | 95.71 [64] |
| FC | 1 M | Labeled | 6 K | 95.25 [65] |
| UFace | 200 K | Unlabeled | 6 K | 95.12 |
| Model | Training Data Size | Labeled or Unlabeled | Testing Data Size | Testing Accuracy (%) |
|---|---|---|---|---|
| ArcFace | 5.8 M | Labeled | 7 K | 98.27 [16] |
| GroupFace | 5.8 M | Labeled | 7 K | 98.63 [19] |
| CurricularFace | 3.8 M | Labeled | 7 K | 98.37 [13] |
| Dyn-ArcFace | 5.8 M | Labeled | 7 K | 94.25 [68] |
| MegaFace | 3.8 M | Labeled | 7 K | 98.46 [31] |
| CircleLoss | 5.8 M | Labeled | 7 K | 96.02 [69] |
| ULNet | 1 M | Labeled | 7 K | 98.23 [64] |
| FC | 1 M | Labeled | 7 K | 98.25 [65] |
| IMAN | 0.5 M | Unlabeled | 7 K | 92.74 [70] |
| UFace | 200 K | Unlabeled | 7 K | 97.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Solomon, E.; Woubie, A.; Cios, K.J. UFace: An Unsupervised Deep Learning Face Verification System. Electronics 2022, 11, 3909. https://doi.org/10.3390/electronics11233909
Solomon E, Woubie A, Cios KJ. UFace: An Unsupervised Deep Learning Face Verification System. Electronics. 2022; 11(23):3909. https://doi.org/10.3390/electronics11233909
Chicago/Turabian StyleSolomon, Enoch, Abraham Woubie, and Krzysztof J. Cios. 2022. "UFace: An Unsupervised Deep Learning Face Verification System" Electronics 11, no. 23: 3909. https://doi.org/10.3390/electronics11233909
APA StyleSolomon, E., Woubie, A., & Cios, K. J. (2022). UFace: An Unsupervised Deep Learning Face Verification System. Electronics, 11(23), 3909. https://doi.org/10.3390/electronics11233909