1. Introduction
Artificial intelligence (AI) has a sub-area called machine learning (ML), which focuses on studying and developing approaches to computational learning. ML has been successful in various fields, such as fraud detection, computer vision, online advertising, robotics, and automatic drivers, among others [
1,
2,
3].
The success of applying ML in the areas of disease diagnosis, treatment, patient monitoring, drug discovery, and epidemiology, among others, allows for foreseeing the potential and impact of ML in the design and implementation of new and better solutions in the mentioned areas [
4,
5]. For example, in [
6], a review of the importance of using drones, AI, the internet of things (IoT), and block chain, among other emerging technologies, was prepared to address the pandemic; for example, [
7] uses blockchain to propose a method that prevents manipulation of information, such as COVID-19 test results. Additionally, in [
8], a review of current approaches to automatic image processing of computed tomography (CT) scans is presented. Likewise, papers were introduced that elaborate in a basic way on the various modeling techniques to predict the pandemic, including mathematical and AI approaches. Another paper ([
8]) presents a review of modern approaches to COVID-19. Other work ([
9]) shows a reflection of different points of view on the approaches used in AI. [
10] characterizes and presents deep transfer learning (DTL) in managing aspects related to COVID-19. In [
11], a review of machine learning and AI algorithms for pandemic management is conducted. In [
12], the limitations, restrictions, and difficulties of the application of AI in the fight against the disease are reviewed. Finally, we highlight works based on artificial intelligence techniques using X-ray images to detect COVID-19 and various lung diseases [
13,
14].
One of the fields of application of ML is the area of health. ML has led different researchers to approach, from this technique, the study of COVID-19. COVID-19 is a contagious virus that belongs to the coronavirus family. The disease causes flu-like symptoms such as cough, fever, fatigue, and shortness of breath. The primary source of the virus is still under debate. However, studies on the genome sequence of the virus have determined that it belongs to the β-CoV (
Corona Virus) genus-group of the coronavirus family that takes bats and rodents as hosts [
12,
14]. The virus is transmitted through airborne and physical contact and penetrates scraper cells by binding to Angiotensin-Converting Enzyme 2 (ACE2). Consequently, the most common symptoms of the virus are shortness of breath, fever, cough, loss of smell, taste, headache, and muscle pain [
14]. COVID-19 was first observed in Wuhan in, China in December 2019 [
15]; since then, it has spread worldwide, generating difficulties in different aspects of human life.
The virus has had variants such as Delta and Omicron that have caused different waves (high peaks) of infections and deaths worldwide [
16]. The Omicron variant, considered more transmissible but less lethal, was shown to have reached 61.5% of women that reported infections. As of 3 April 2022, more than 491 million confirmed cases, and more than 6.1 million deaths, had been reported under the current COVID-19 pandemic [
17,
18], and it was reported that the pandemic may end by 2022 and be fully controlled by 2024 [
19]. The scientific community is developing vaccines, techniques, and procedures using different technologies that use ICT tools and is investigating problems to improve the characterization of ML algorithms with better performance to perform survival analysis studies. These include appropriate variable selection techniques in studies related to datasets in the health area, among others [
20,
21].
For several years, mathematical models have been used to predict the behavior of epidemics [
22,
23], which help politicians and health authorities to adopt appropriate measures to curb pandemics. Much research has focused on modeling pandemic behavior, as seen in [
24,
25,
26]. Some examples are the use of ML techniques for timely decision-making to send patients with COVID-19 to the intensive care unit (ICU) and to prevent deaths [
27,
28] and to predict the level of mortality risk based on the ratio of patients with COVID-19 and comorbidities [
29,
30].
In the literature review, we found many papers that address the systematic literature reviews related to the subject matter of this work; however, we introduce a summary of the essential works below. In [
31], the authors limited themselves to presenting general aspects on four aspects (such as limitations, surveillance, pitfalls, and priorities). However, they still need to show details of algorithms, methodologies, datasets, or other tools to develop AI-based solutions for reliable disease diagnosis.
Ref. [
32] presents a relationship between IA and clinical decision support (CDS) review, highlighting the able and reliable datasets which access relevance for achieving better solutions to address COVID-19. However, it needs to present details of the technical characteristics of the composition of the available datasets or essential aspects that allow for determining the quality of a dataset.
Likewise, in [
33], there is an extensive study on the works that use blockchain and AI to develop solutions against COVID-19, but it does not show the performance of the solutions that perform “coronavirus detection”, where they include six works, and it only shows the performance of the “ResNet50 model. In [
34], ML algorithms for disease-related medicine using image processing are presented, concentrating on a review of the available literature on computer vision efforts against the COVID-19 pandemic. However, it only presents some of the algorithms used in the papers included in the review. In [
35], a review of imaging modalities and artificial intelligence approaches was applied to managing COVID-19. AI approaches are applied for the management of COVID-19, although they do not specify the data processing tools and image databases that are available for future studies.
Additionally, a review presents data-driven pandemic surveillance, modeling, and forecasting methods used for methodologies, algorithms, and applications in past or current epidemics. It also highlights effective data-driven methodologies that have proven successful in other contexts. This paper does not delve into the detailed characterization of methodologies, algorithms, and applications to combat COVID-19 [
36,
37]. Instead, it introduces a paper that addresses forecasting models based on machine learning methods for COVID-19 prediction, details forecasting techniques, and highlights the features most used in the studies and the databases used in the reviewed articles. However, this paper does not present the performance of the studies included in the review.
Ref. [
38], a summary of the papers that have used machine learning methods to predict the number of confirmed COVID-19 cases is presented, organized into four categories: traditional machine learning regression, deep learning regression, network analysis, and social media and search queries data-based methods. In contrast, this paper does not present information on the algorithms, techniques, datasets, tools, or platforms used in reviewed works.
A review shows a comprehensive application of AI in drug discovery for COVID-19 treatment [
39]. A review covers research on the application of AI in the management of critically ill patients with COVID-19 in [
40]. In [
41], a review paper presents a summary of research on deep learning applications for medical image processing in COVID-19 patients. It looks at deep learning and its applications in healthcare based on three use cases in countries such as China, Korea, and Canada. Additionally, in [
42], a recent work used neural networks (NN) and GHSOM training techniques to predict the risk of cardiovascular disease (CVD) accidents. Finally, we summarize literature review papers analyzing the relationship of COVID-19 with underlying disease (comorbidity) in
Table 1.
In contrast to the above, this paper stands out mainly because it concentrates on compiling and analyzing the works that predict mortality based on patients with COVID-19 and underlying disease (comorbidity).
- (1)
It presents the relationship of the importance of feature selection techniques to the performance of the algorithm used in prediction.
- (2)
It presents an analysis of the behavior of the algorithms related to the metric that obtained the best performance.
- (3)
It presents a summary of the AI tools used to implement the prediction methods from each study reviewed.
- (4)
It presents a brief bibliometric analysis of AI applications’ state-of-art research to predict mortality based on patients with COVID-19 with a baseline disease (comorbidity) area.
In the study, we analyzed research articles based on ML in the treatment of the pandemic; the study is based on PRISMA methodology to perform this systematic review and used VOSviewer, a bibliometric analysis software; 912 articles were identified from the primary collection in the SCOPUS bibliographic database during a period between 2020 and 2022, and 32 were used for the analysis of this work. The results of this review will contribute to policy directions, practice, and further research on pandemics, such as COVID-19, mainly on mortality risk.
The rest of the document is as follows. In
Section 2, the materials and methods used to perform the systematic review are introduced, as well as a summary of the search results.
Section 3 reviews the literature on the most used supervised machine learning for diagnosing and treating patients with COVID-19.
Section 4 presents a bibliometric analysis of the literature-reviewed characterization.
Section 5 summarizes the main findings and reflections found in the reviewed studies regarding ML algorithms to predict mortality risk in COVID-19 patients and comorbidities and a summary of the gaps, challenges, and research opportunities in the presented work area. Finally, we present conclusions in
Section 6.
3. Literature-Reviewed Analysis
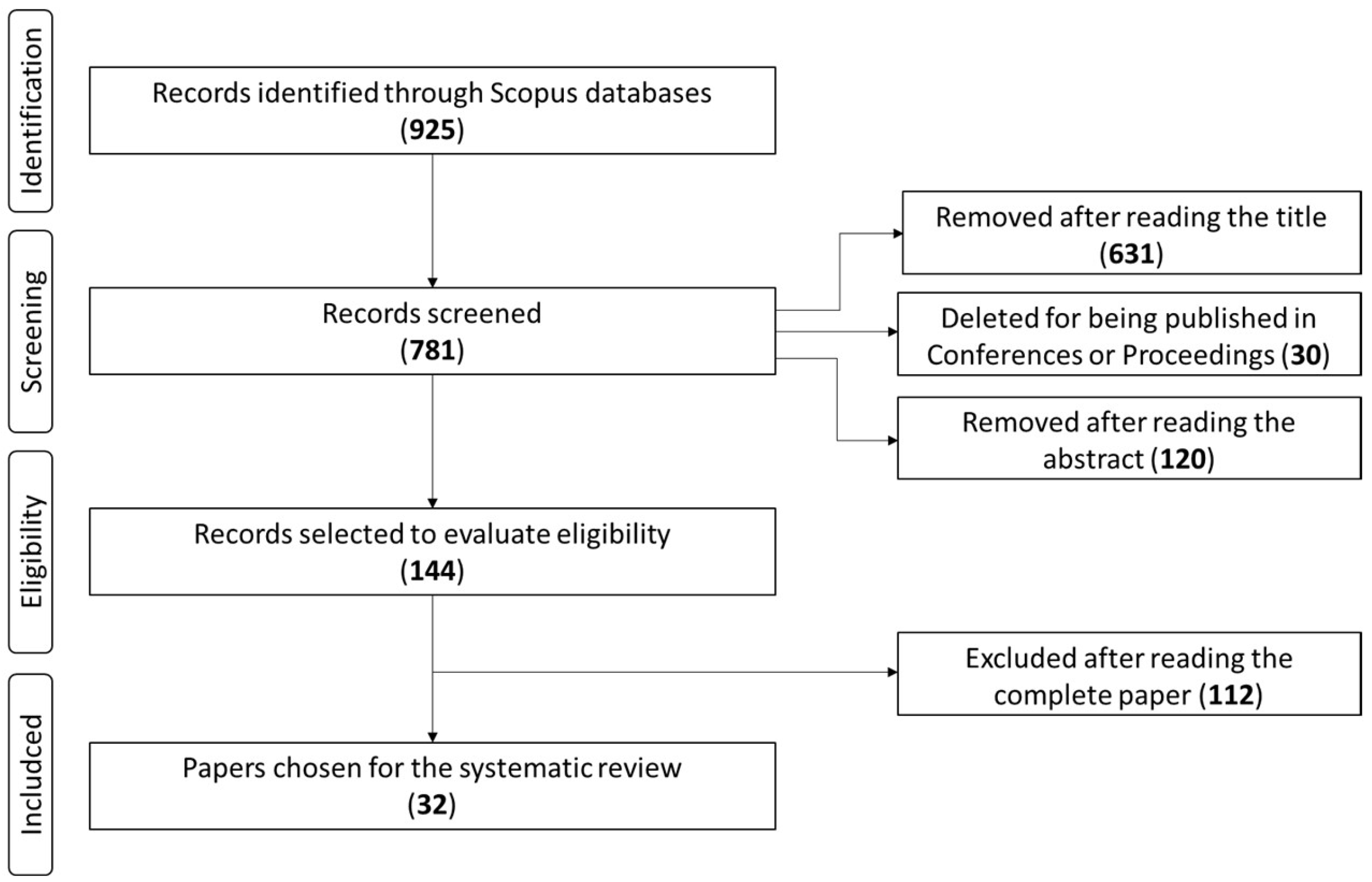
Because of the bibliographic search in the Scopus database and the PRISMA methodology, 925 articles were identified. Then, the first screening by title indicated that 631 articles did not meet the selection criteria for this review, resulting in 265 articles. Then, we applied the following screening for work published in conferences or proceedings, which allowed the elimination of 30 articles. Afterward, screening by abstract revealed that 120 studies did not meet the review’s objectives. Thus, the final screening by the full-text reading of the remaining papers revealed that 112 articles were related and did not apply to machine learning techniques concerning the keywords under study. Therefore, the final list excluded these articles. Finally, this work includes 32 articles regarding the application of ML algorithms to predict mortality risk in COVID-19 patients and comorbidities.
3.1. General Analysis
The study was able to provide evidence from the reference list of the 32 studies used in this review in
Table 3. The literature review shows 32 articles focused on four main areas: (1) detection of COVID-19 using ML techniques, (2) prediction of risk of dying based on COVID-19 comorbidity using ML techniques, (3) prediction of COVID-19 using ML techniques, and (4) improvement of COVID-19 prediction using ML techniques. The highest proportion 47.6% of the studies focus on “Predicting the risk of dying in COVID-19 patients and with comorbidity using ML techniques”. Additionally, 33.33% of the reviewed papers are oriented towards “Predicting COVID-19 using ML techniques”. With less relevance appear the studies related to “Detection of COVID-19 using ML techniques” and “Improvement of COVID-19 prediction using ML techniques”, with 9.5% respectively.
3.2. Algorithms
Table 4 shows the group of 22 algorithms applied in the 32 papers and the number of papers that adopted the methods. The review revealed that the most used ML algorithm was random forest (RF) (n = 11, 24%), followed by eXtreme Gradient Boosting (XGBoost) (n = 6, 13%), logistic regression (LR), and K-nearest neighbor (KNN), with (n = 3, 7%). Other algorithms, such as convolutional neural network (CNN), decision tree (DT), CatBoost, and artificial neural network (ANN), were implemented twice (n = 2, 4%) within the 32 studies reviewed. We found that 13 algorithms were implemented once within the reviewed papers (n = 1, 2%). Finally, we found that all the studies employed multiple algorithms; however, they highlighted that all are supervised ML algorithms, and it is possible to assume that, in mortality risk prediction in COVID-19 and comorbidity patients and related areas, the tendency is not to use only “Unsupervised” ML algorithms.
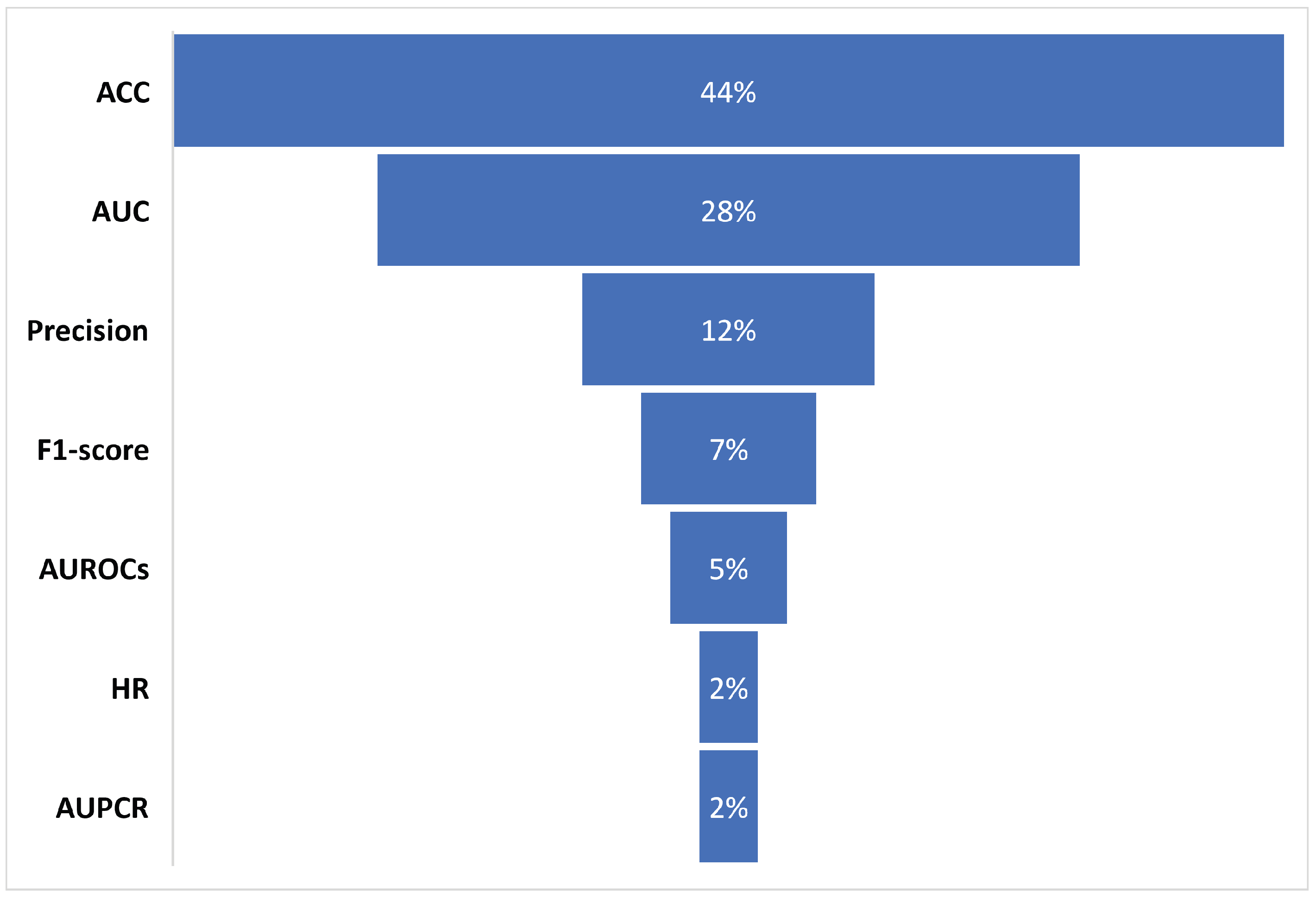
This review considered all reported algorithms from reviewed studies. Concerning the performance of the prediction models, the essential process is the evaluation of the ML algorithms used in the model, which is based on a series of performance metrics. The most used metrics for the 32 included studies were HR, ACC, AUC, F1-score, precision, AUPCR, and AUROCs. As a result,
Table 5 shows that the most used metrics by the 32 studies to evaluate the performance of the algorithms used in the prediction models were ACC and AUC, with 19 and 12 times, respectively. Finally,
Figure 2 shows the percentages of use of the metrics in the articles reviewed in this work.
Regarding the performance of the algorithms used in the prediction models, many studies evaluate and compare two or more metrics (we found in the study papers that they evaluated at least five algorithms [
59,
60,
67,
76,
77,
86]), and to facilitate the understanding of the results, this analysis selected the metrics that reported the best performance within each study. Consequently,
Table 6 contains the average of the best values presented by the metric in each study. The research found that ACC and AUC were the most used metrics to evaluate performance within the 32 reviewed studies.
3.3. Algorithm Metrics Performance
Every prediction method uses different algorithms to evaluate its performance, depending on the type of prediction, the use of clinical data, and the scope of the study; the results between one metric and another may differ depending on the algorithm used in the model. The study found that the ACC and AUC metrics have the worst record, with RF algorithms at 65% and 78%. In addition, RF obtains better performance with the ACC metric of 97%, while with AUC, it only reached 89%. The XGBoost algorithm, which is of greater use to ACC, obtains a maximum 98% performance, superior to the best performance of ACC with RF. The LR algorithm received its best performance with the ACC metric (94%), the lowest with AUC (78%), and the FM algorithm evaluates using ACC, F1-S, PREC, and AUC metrics at a performance higher than 90%. Finally, metrics such as HR and AUPCR, which presented a performance below 83%, and F1-S with AUROCs, were evaluated by two algorithms and showed a maximum performance of 92% and 97%, respectively.
Additionally, it is known a priori that “the higher the accuracy of an algorithm, the greater the possibility of making an accurate prediction.”
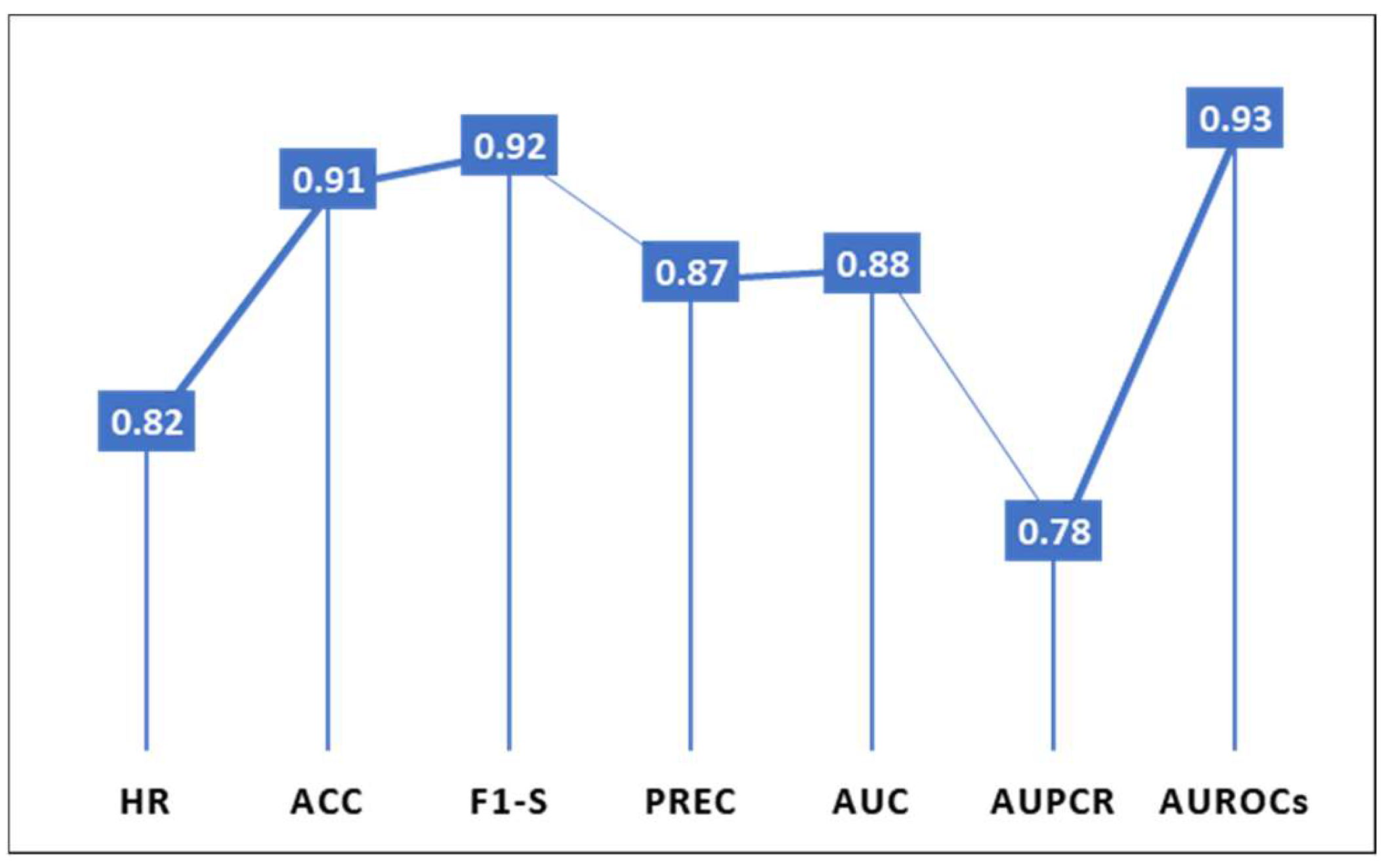
Figure 3 presents the overall average performances of the metrics used in the studies analyzed, where the metrics with the best prediction rate were AUROCs (93%), followed by F1-S (92%) and ACC (91%). The rest of the metrics had a 78% and 87% prediction rate.
The above implies that, in mortality risk prediction in COVID-19 and comorbidity patients and related areas, the preferred metric for assessing prediction accuracy is ACC, followed by AUC, where F1-S also stands out, offering pressure greater than 90%.
3.4. Average Performance of the Algorithms Based on the Feature Selection Technique Metric Performance
Data are the essential components of dataset prediction models, containing independent and predictive features. However, identifying the most important features of a model is a complex and crucial step to ensure the robustness and accuracy of models based on AI algorithms [
89,
90,
91]. Therefore, this paper presents
Table 7, the classification of the feature selection techniques used by the prediction methods of the reviewed studies.
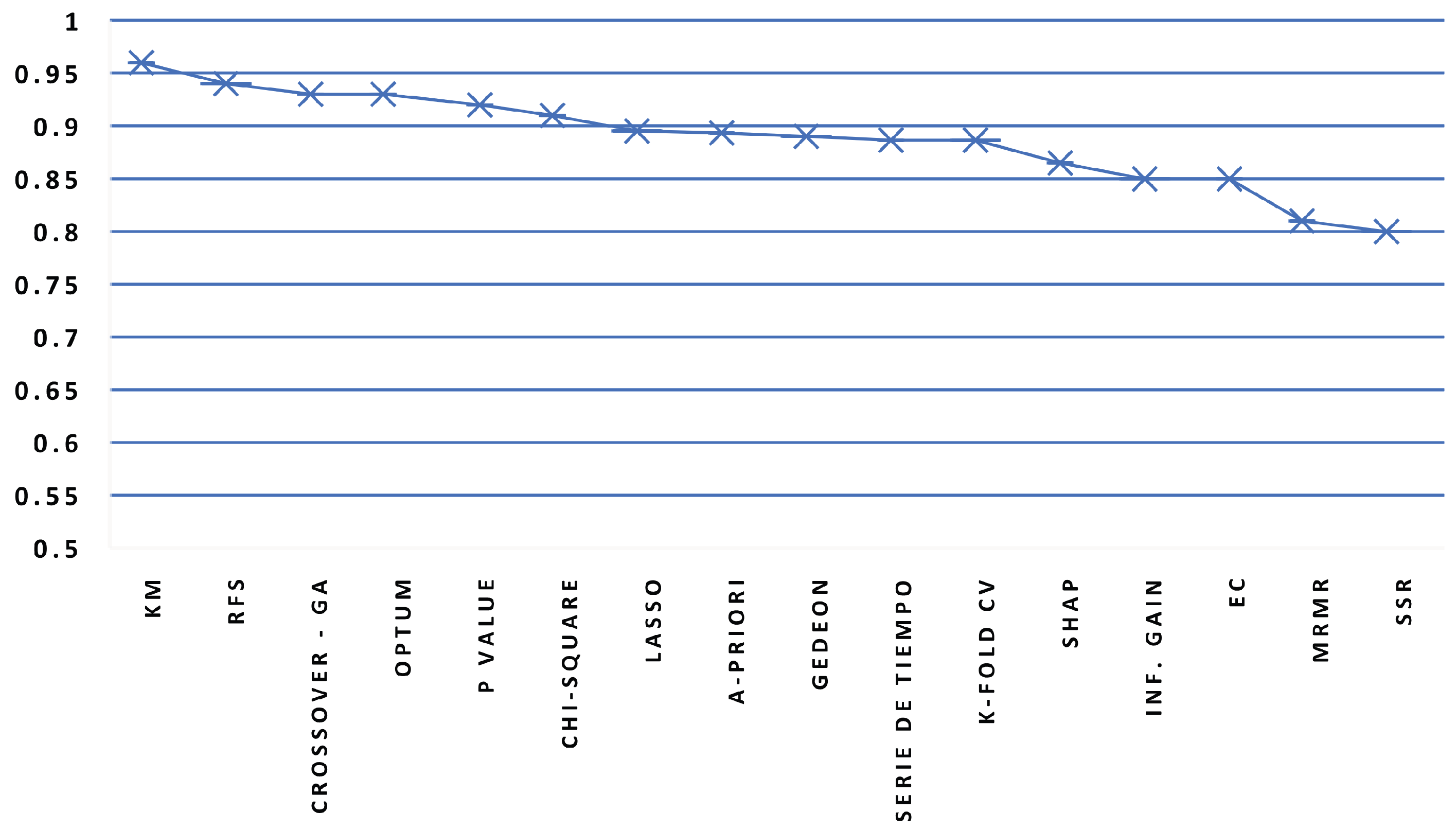
The feature selection technique most used was reduced feature set (RFS), followed by time series, A-priori (They do not use any in particular), and K-fold cross validation (K-fold CV). The rest of the techniques were used a maximum of two times. The method with the lowest performance was time series, with 65% for the RF algorithm, followed by SHapley Additive exPlanations (SHAP), with 78% for XGBoost (with a minimum performance of 94%). Chi-square (CNN, Bagging), Kaplan Meier (KM) (XGBoost), RFS (LR, KNN, XGBoost, DT), and SHAP (RF) techniques were all used, and the rest of the techniques were lower than 93%.
Figure 4 shows the average performance values of the algorithms as a function of the feature selection technique, such as time series, SSR, and MRMR. At the same time, we identified that KM and SHAP have the best performance.
Finally, we identified that, in mortality risk prediction in COVID-19 and comorbidity patients and related areas, the feature selection techniques which allow the achievement of a probability greater than or equal to 95% of obtaining more accurate prediction models are KM and SHAP.
3.5. Algorithms Performance Average
Table 8 introduces the average performance of the metric with the best accuracy of the algorithms found in each of the 32 papers and shows that the algorithms RF, CNN, CAIM, XGBoost, and DT have the highest performance, with a minimum of 96% accuracy for the prediction model. The RNN, KNN, CoxSA, CovRNNN, and GB-ADAM algorithms stand out, whose performance is between (90–95%). At the last level, there are algorithms, such as EC, LR, KM, Bagging, EC, NBS, and CatBoost, with a performance between (89–76%).
A detailed review shows the performance algorithm in [
86], which evaluates seven algorithms, e.g., CatBoost obtained the best performance, with 76% for the PREC metric. The study shows that the optimization of the features classified in an inferential way the values for each feature with three levels (high, medium, and low). The over-parameterization of features is a factor that could influence the quality of the accuracy metrics evaluated in each algorithm. However, ref. [
80] evaluated LR, SVM, KNN, RF, and XGBoost algorithms. For optimization of the samples (features) used, two techniques (SMOTE, ADASYN) were applied, which allowed the prioritization of two features (age, exposure) for the training of the algorithm, which resulted in 97% accuracy for the ACC metric. The above may mean that the techniques and the number of feature optimization techniques applied in the model impact the final performance.
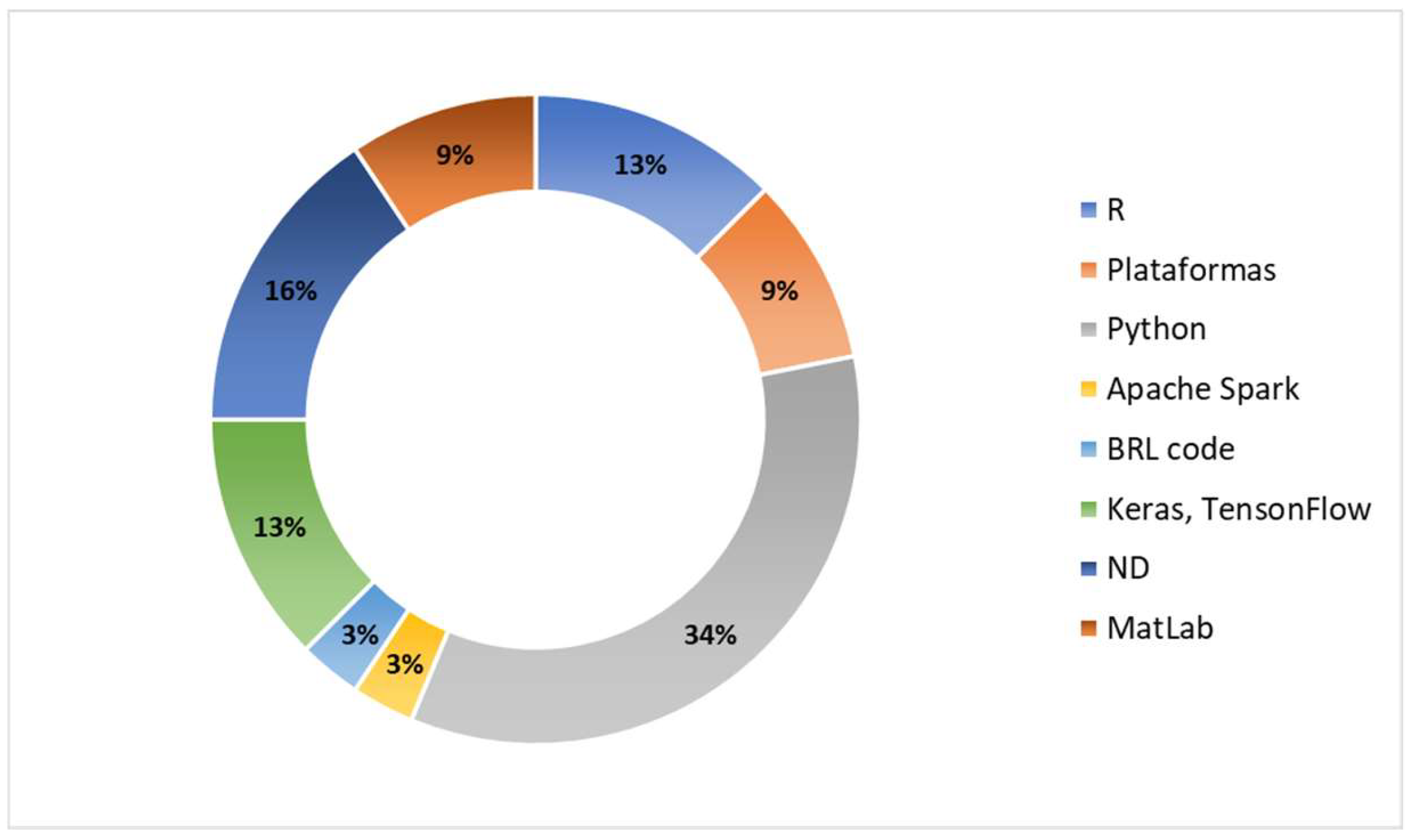
3.6. Platforms or Tools Used for Mortality Risk Prediction in COVID-19 Patients and Comorbidity
The review allowed found that Python was the most used tool for the implementation of mortality risk prediction models in COVID-19 patients with comorbidity, with 34% (11/32). The reviewed studies evidence the strengths of the tool for several aspects, such as open-source, multiplatform, a large number of libraries, reusable code, easy to learn, using high-level language for coding, and an extensive community of collaborators around the world. However, they are characterized by being slow in specific processes due to memory consumption.
The study demonstrated that 13% (4/32) of the R language includes linear and non-linear models, easy-to-create graphics, multiplatform, and open-source material. However, it can be challenging to learn and slow to function with regards to many programming languages. Keras-TensorFlow appears with 13% (4/32) of participation in the reviewed works, which has, as a differentiating character, the use of neural network algorithms and its compatibility with Python. However, it adds a layer of complexity to the processing because it uses dependencies. Regarding MatLab, only 9% (3/32) of studies used it, although it offers high precision in its calculations, comprehensive support, fast prototyping, and an extensive community. However, it is necessary to pay a license fee for its use. For more details, see
Table 9.
On the other hand, 9% (3/32) of the papers use various (online, web-based) specific platforms to implement the prediction method. Finally, one work used Apache Spark and BRL code tools.
Figure 5 illustrates the percentage of participation of each tool among the reviewed papers. Finally, it is important to mention that, based on many essential features, the researchers of the scanned documents rely on the Python tool to implement the designed prediction models.
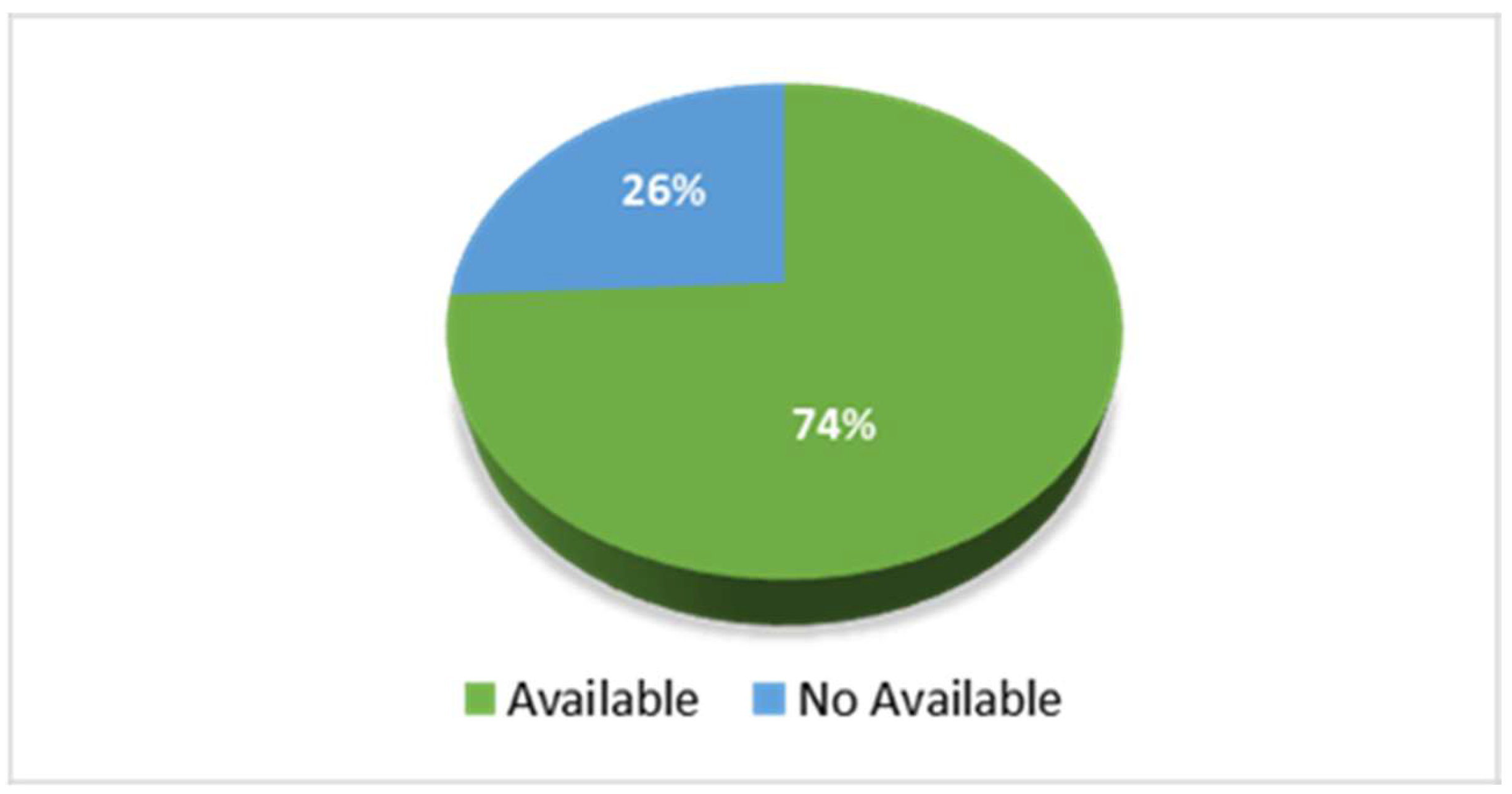
3.7. Datasets Found in the Reviewed Studies
The analysis of the 32 selected works revealed that only seven papers have available databases. Some works need to request the dataset from a specific author (at the author’s discretion), and others explicitly stated that the dataset was unavailable. In summary,
Figure 6 presents a distribution of the findings. Studies have shown web-based systems implementations for mortality risk prediction in COVID-19 and comorbid patients. You can view available datasets and platforms in
Table 10.
4. Bibliometrics Analysis
This section presents a brief bibliometric analysis to introduce the trend of rapidly emerging topics in mortality risk prediction in COVID-19 and comorbidity patients research based on ML algorithms, where significant applied research activity has been extensively initiated since the beginning of the final phase of the pandemic. We focus on the methodology used in the bibliometric analysis, allowing traceability of the state of research applied in the different aspects of mortality risk prediction in COVID-19 patients and related research that can be found in the literature analysis. Therefore, we present the bibliographic articulation between various articles on machine learning to combat COVID-19, diagrammed by links between clusters representing networks and correlations, built based on the relationship between the number of publications, citations, countries, standard references, co-citations, organizations, and journals.
To achieve the above, 925 articles from the primary collection were identified in the SCOPUS Bibliographic Database between 2019 and 2022 and the VOSviewer bibliometric analysis software was used to analyze the selected information.
4.1. Prolifics Authors
Figure 7 shows the bibliographic coupling between authors with at least one citation and four published papers (resulting in 22 authors with this coincidence), where the clusters, in red, blue, and green represent the authors who had developed similar works related to the prediction of mortality risk in COVID-19 patients and patients with comorbidity, based on ML algorithms, and who cite the same source in their reference lists. The similarity in the color of the authors’ clusters also implies a more significant overlap between the reference lists of these authors’ publications. Additionally, shows visible names which may not be included in the map structure.
4.2. Keywords
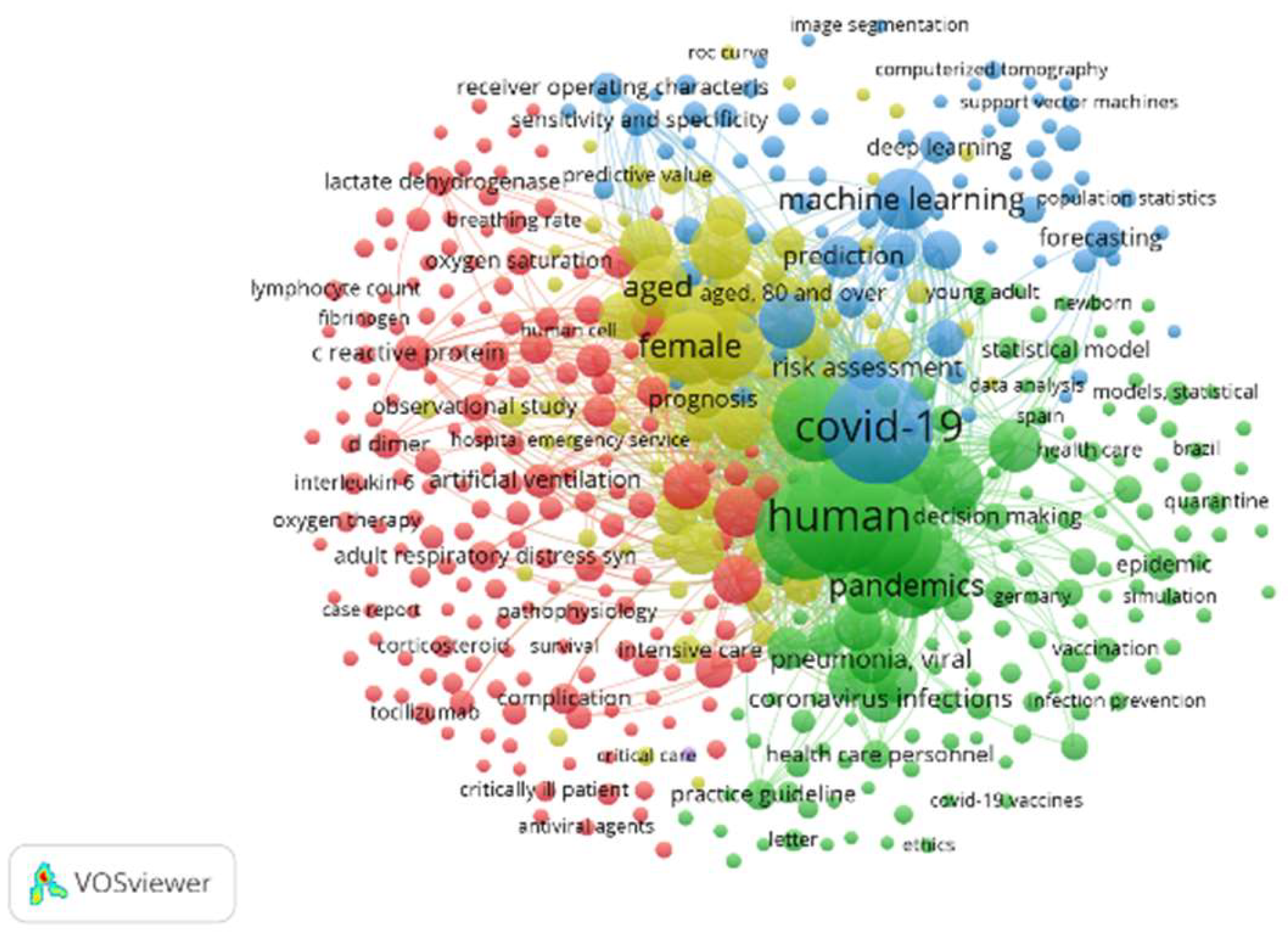
Figure 8 highlights two clusters. First, the largest cluster (blue color) shows the appearance of the keyword “COVID-19” 660 times, which, in turn, is related to research using the keywords “Machine learning” and “Deep learning,” which appear 203 and 61 times, respectively. This indicates interest in research that applies artificial intelligence tools or techniques to “COVID-19” topics. Secondly, the green clusters, with the keywords “algorithm” and “algorithms”, have between 372 and 191 occurrences, respectively, and show developed methods or procedures addressing to topic related to “COVID-19.”
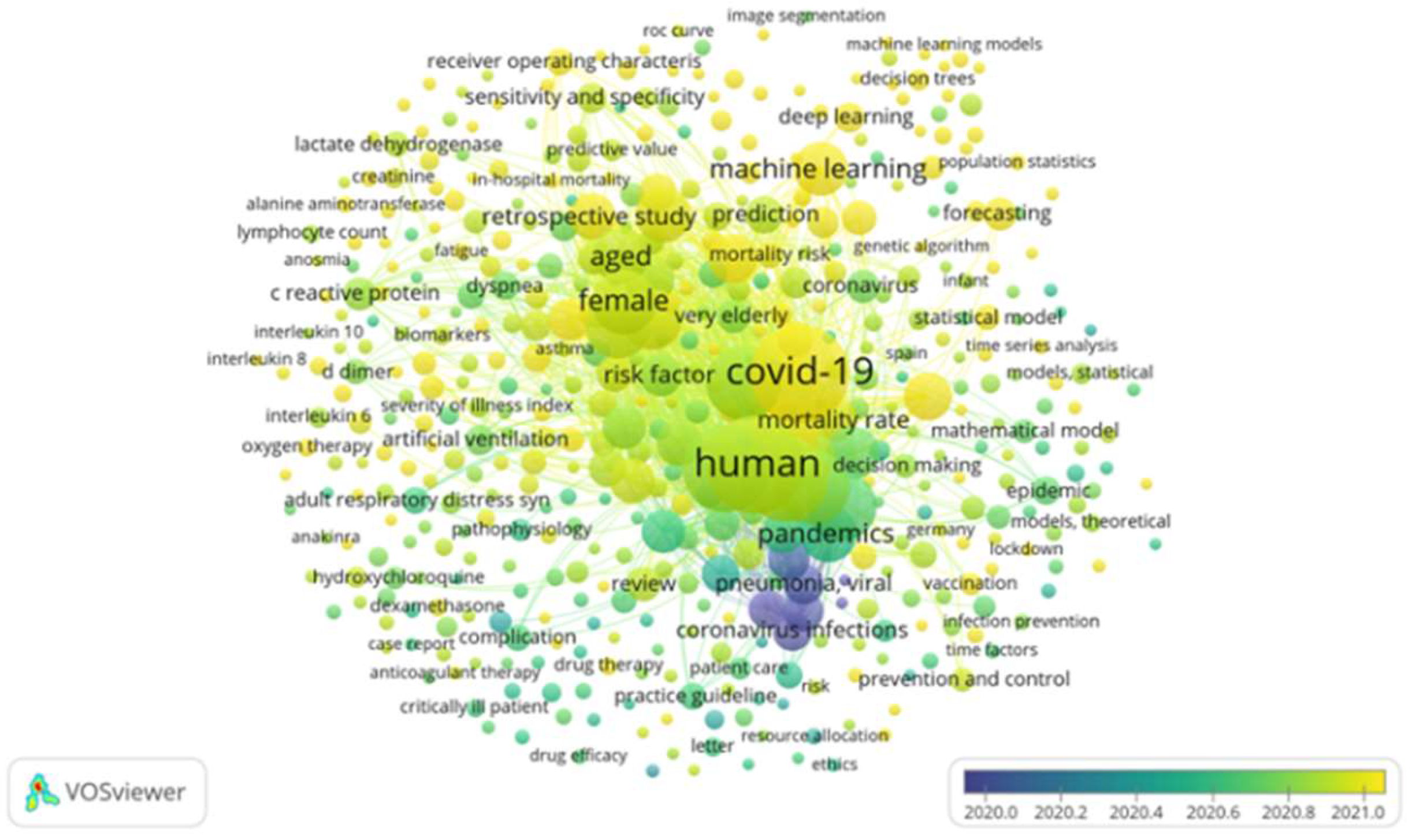
Figure 9 shows that the topics covered in the studies reviewed (between 2020 and 2021) are concentrated in small visualization of the co-word network in the research topic “AI applied to COVID-19”. Note: the visualization of the co-word network was based on occurrences.
Clusters (lilac and dark green) represent the beginning of the pandemic in 2020, where general topics, such as coronavirus infections, pneumonia virus, c-reactive protein levels, and pneumonia virus, among others, were covered. Then, in the mid-late 2020 (lemon-green clusters), they represented topics even closer to the subject of this work, where the mathematical model, comorbidity, and risk factor stand out. Finally, the yellow-colored clusters represent papers that address specific concepts directly related to the topic of study of this work, where we can highlight COVID-19, SARS-CoV-2, hospital mortality, machine learning, artificial intelligence, algorithm, hospital mortality, artificial neural networks (ANN), diabetes mellitus, coronavirus, as well as others with lower correlation index, such as deep learning, forecasting, diagnosis, statistical model, diabetes, blood sugar levels, and decision trees.
4.3. Co-Authorship and Authors
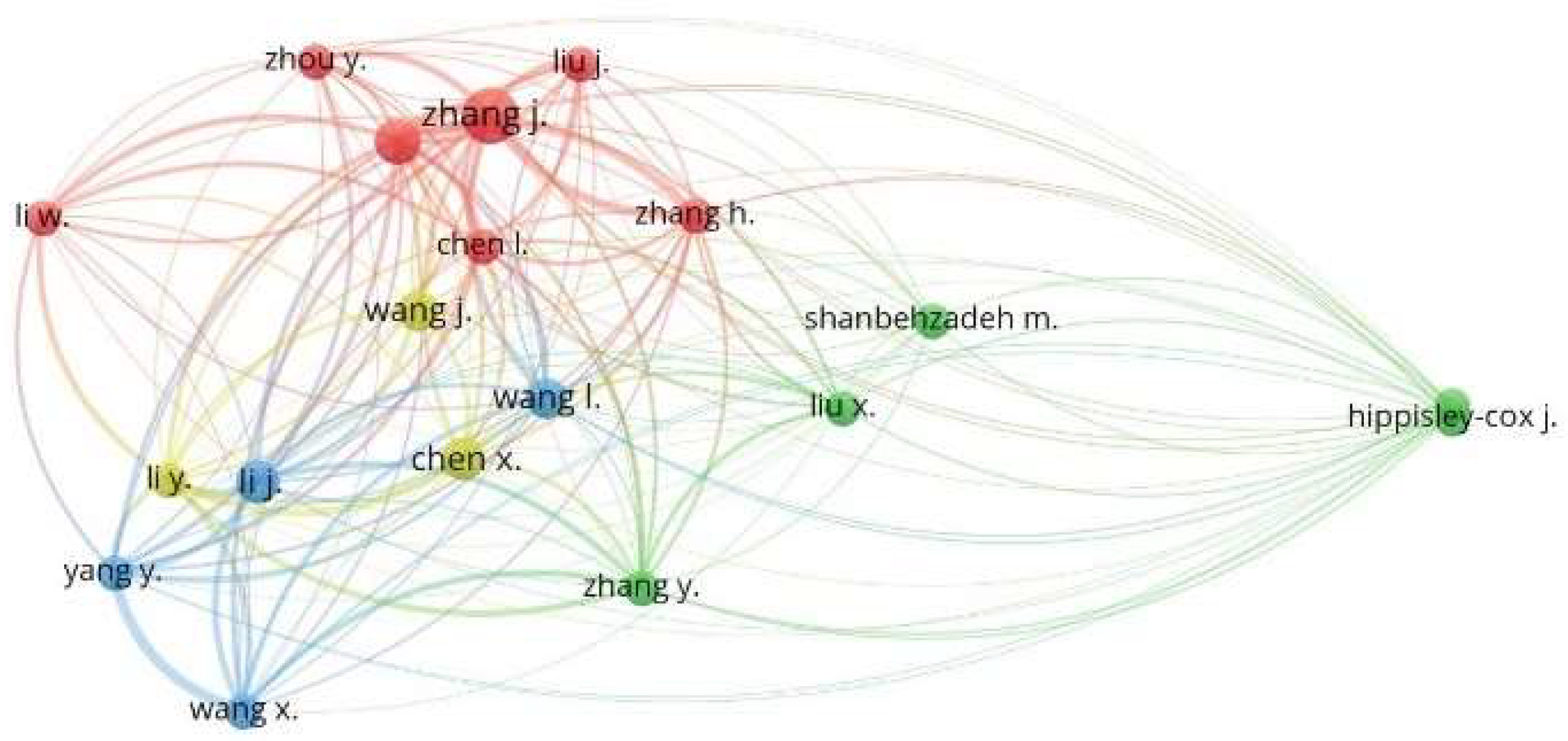
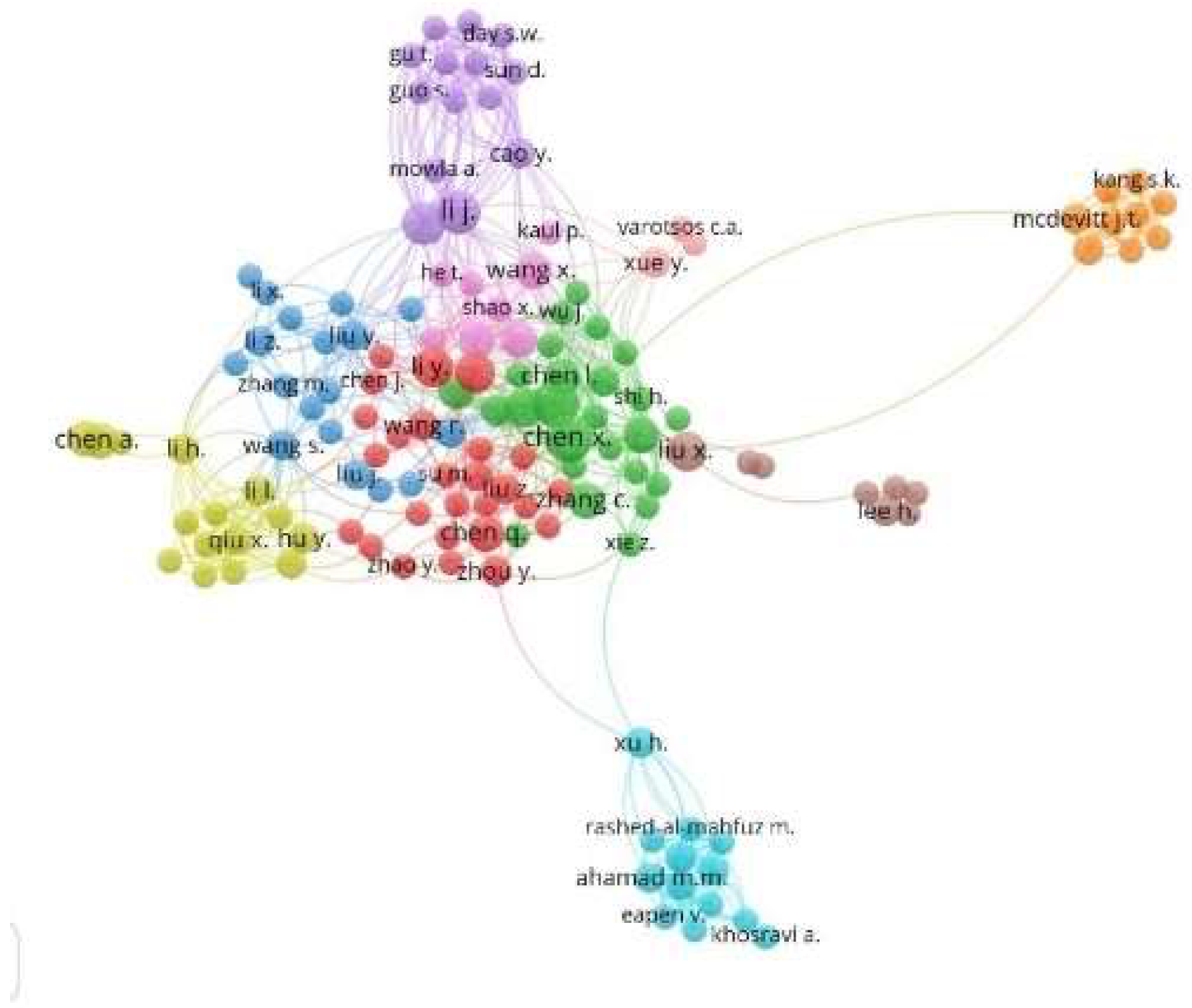
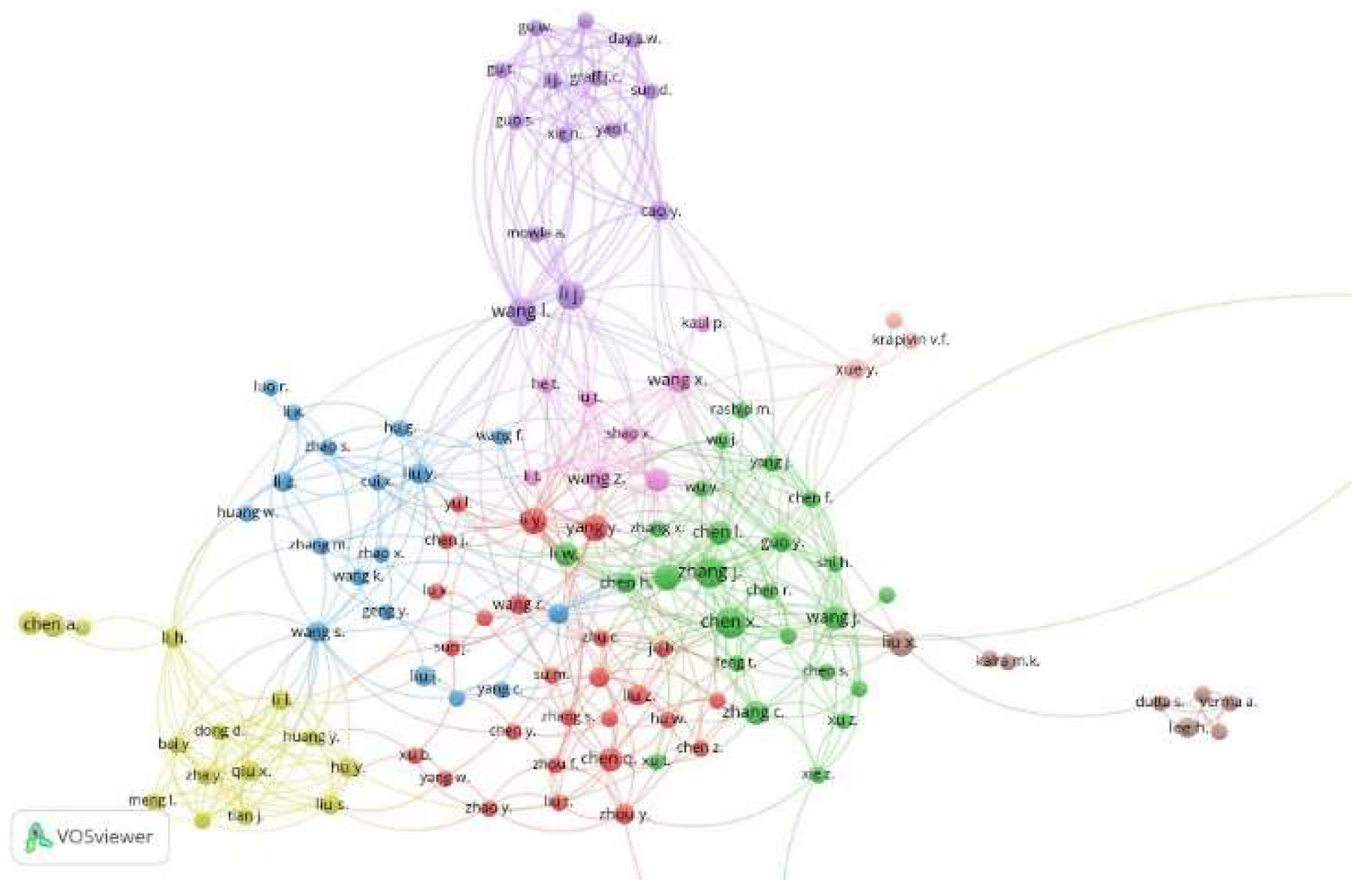
Figure 10 shows four main clusters, namely: green (center-right), red (center), blue (left), and purple (top), where they coincide with the principal co-authors and authors who publish together or who work in similar research fields of the IA research topic applied to COVID-19, where the purple cluster stands out as containing the most significant number of authors with the highest rate of participation as co-authors. It also shows the network of co-authors and leads authors who publish together or work in similar research fields. We used the co-authorship and mentor analyzers as characteristics, where the minimum limits of two (2) documents and one (1) citation per author were defined, which selected 5315 authors, and only 341 authors complied with the established limits.
On the other hand, we evidenced that a smaller group of authors consists of 39 authors, as presented in
Figure 11, where Li, J. and Whan, I., in the purple clusters, represent the authors with the strongest co-authorship links.
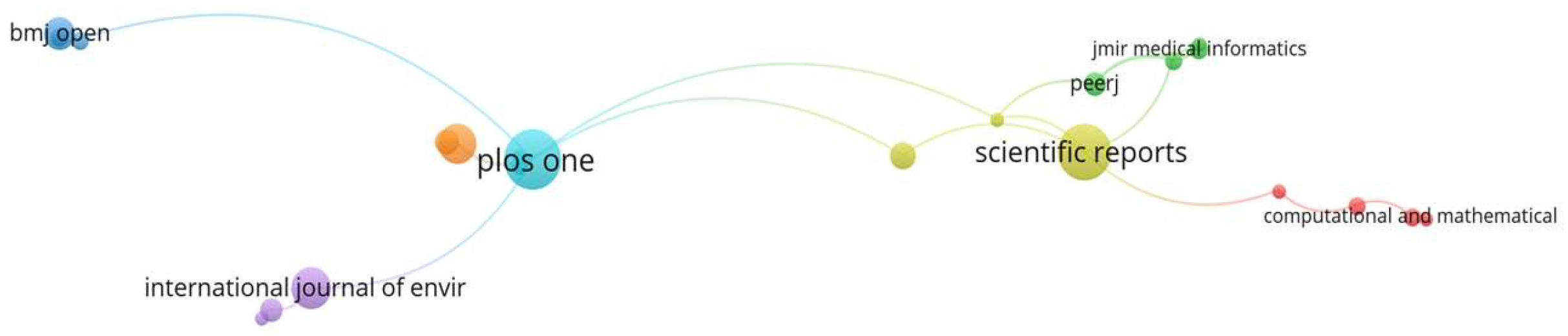
Figure 12 shows two main clusters, yellow (right) and cyan (left), as the most cited journal sources according to the authors’ publications, which indicates the strong citation between the journals “
Plos one” (32) and “
Scientific reports” (28), due to having the highest number of published papers. The journals “
Bmj open,” “International journal of environmental research and public health,” and “Journal of medical internet research” are highlighted. However, they have a low number of published papers (7), but a strong link regarding co-citation. This analysis was limited to include only journals with at least two (2) documents and two (2) citations; as a result, 538 matched journals for the analysis, and only 108 met the defined limits.
Finally,
Figure 13 shows two clusters, red (left) and green (right), with the red clusters being the most representative, with the highest number of citations from authors from three (3) institutions located in the United Kingdom, followed by the green clusters representing institutions in the United States of America. For this analysis, only institutions with a minimum of two (2) published documents and one (1) citation were included, which selected 3741 institutions, and only 77 complied with the defined limits.
5. Challenges
This work reviewed 925 papers about using AI algorithms to predict mortality risk in “COVID-19” patients and comorbidity; after careful analysis, we found that only 32 studies linked the application of ML algorithms to predict mortality risk in “COVID-19” patients and comorbidity. Then, from the 32 papers, we found information about evaluated techniques, the best-performing feature selection techniques applied to the prediction models, the data set used, and the software used for the analysis.
Regarding the type of algorithms, the study found that 100% of the papers reviewed used algorithms based on supervised machine learning classification. RF, XGBoost, LR, and KNN algorithms were the most used in the prediction of mortality risk in “COVID-19” patients and comorbidity, followed by CoxSA, CNN, DT, CatBoost, and ANN algorithms, where the emerging algorithm XGBoost stands out and shows higher performance than other well-known ML algorithms. Finally, algorithms such as SV, GB, CAIM, FM, NBS, AE, GRU-D, RNNs, GB-ADAM, KM, EC, CovRNN, and bagging are not usually attractive to predict mortality risk.
The review also revealed that, for experimental work, the studies evaluated and compared at least five (5) algorithms (e.g., [
57,
67,
76,
77,
92]). It can be recommended that a prediction model use a single algorithm and that, although many algorithms are evaluated, the research community still has much work to evaluate state-of-the-art algorithms that are out of existing studies. Applying state-of-the-art ML algorithms in mortality risk prediction in COVID-19 and comorbid patients still has issues to be addressed and resolved.
The top performing ML algorithms for mortality risk prediction in “COVID-19” patients and comorbidity identified seven (7) performance metrics for the evaluation of the prediction models evaluated in the studies, such as ACC, AUC, accuracy, F1 score, AUROCs, HR, and AUPCR, with ACC and AUC being the most used, representing 44% and 28% of the studies, respectively. Within the 22 algorithms used by the reviewed studies, those with the highest accuracy performance for predicting mortality risk in COVID-19 patients and with comorbidity were RF, CNN, DT, RF, CAIM, CNN, ANN, and XGBoost, which achieved a performance between 95% and 97%. The findings show the predictive potential of ML algorithms for mortality risk prediction in COVID-19 patients and patients with comorbidity, especially algorithms such as RF and XGBoost. However, the studies reviewed do not establish the minimum performance threshold for the ACC metric (to be considered accepted), but they set it at 95% for AUC. Finally, several studies are being addressed directions towards research (predictions or other applications) based on clinical data taken from X-rays, computed tomography (CT), and magnetic resonance imaging (MRI), as well as the use of the CNN algorithm [
69,
80,
88] based on neural networks.
On the other hand, the study established that the variable selection technique most used by the studies reviewed was RFS, followed by time series, A-priori, and K-fold CV. Additionally, the method with the lowest performance was time series, with 65% for the RF algorithm, followed by SHAP, with 78% for XGBoost. However, the Chi-square, KM, RFS, and SHAP techniques showed the best, with 94% minimum performance. The rest of the techniques obtained lower performance (maximum 93%). It was confirmed that to implement ML algorithms to predict mortality risk in “COVID-19” patients, as well as comorbidity, it is necessary to not use one technique to design the prediction model only This is because the performance may change between one or another algorithm. Depending on the variable selection technique used.
Finally, this study showed that, after 32 studies reviewed, only seven (7) used primary clinical datasets that are available online ([
59,
67,
75,
79,
80,
83]). We recommended that clinical datasets be used in future studies to increase the interest in mortality risk prediction in “COVID-19” patients with comorbidity to help have more accurate prediction models trained in real scenarios.
Four (4) works are web-based platforms focusing on mortality risk predictions in “COVID-19” patients and comorbidity areas. They are not general solutions because they use characteristics prevalent only in specific geographical contexts, such as India ([
77]) or Italy ([
78]). The rest of the platforms are more generic ([
62,
72]).
In general, studies do not use software platforms. However, using data mining library software, such as R and Python, allows predictive performance in terms of accuracy score of the algorithms (RF, XGBoost), which can be better with R and Python, even when using the same dataset.
Finally, the run-time of each algorithm is essential and depends on the solution context. A system to predict mortality risk in “COVID-19” patients’ comorbidity is used in intensive healthcare units. The speed of getting information to decide can mean the difference between the life and death of a patient.
5.1. Future Directions
This work represents the first systematic review of mortality risk predictions based on machine learning in patients with COVID-19 and comorbidity. Mortality prediction can be helpful to the medical team to facilitate decision-making to minimize mortality in patients with this clinical condition, maximizing the resources available in the ICU and being directed to those with the highest probability of death. This study offers the opportunity to improve prediction models based on the discussions and conclusions that researchers should follow in future research.
More studies evaluating the XGBoost algorithm are required due to the relevance of the algorithm.
It is suggested that researchers should focus on applying neural network-based algorithms to prediction studies using digital images (e.g., X-ray, CT scans, among others).
More studies suggest that one should employ ensemble algorithms, such as logistic regression (LR) ensemble and support vector machines (SVM), to improve prediction.
The research topic concentrates on publication and citation in the United States and the United Kingdom, with little participation from Latin American countries, where only Brazil stands out with 26 publications; this indicates that more efforts are needed in South American countries to contribute to solutions to this topic.
Most of the studies reviewed focused on evaluating the performance of prediction models using AUC and ACC metrics, indicating a priori that these are the best metrics to measure the accuracy of the predictors. However, for non-balanced datasets, there are better options than AUC and ACC; they can create problems for ML algorithms. Therefore, we recommend carefully selecting and applying sampling techniques to the datasets [
93,
94,
95].
It is essential to unbalance datasets, adding a challenge to ML for training and evaluating the algorithms. Therefore, to improve the algorithm performances, we recommend considering the sensitivity of the algorithms when having an unbalanced dataset or when obtaining a small number of samples [
96]
The sensitivity and privacy of patient data are obstacles for researchers to access real and reliable databases.
It is crucial that more medical research centers collect, systematize, and publish patient data that contribute to the consolidation of robust datasets for studies that offer more reliability.
More work is needed to address prediction methodologies, but algorithms using the same performance metrics for each algorithm were compared.
5.2. Lessons Learned
To carry out this study, the team had to define situations and solve challenges typical of research work, which leads to the achievement of the proposed objectives. The following are some of the main lessons learned from the execution of the research work.
The team initially identified that completing phase 3 of the PRISMA “Eligibility” methodology could take one month; however, the results showed that it should take an additional six weeks to read the completed papers and present the results.
To complete the project, the team extended three months beyond the initial schedule (six months); in other words, the project took nine months to complete.
For the bibliometric analysis, the team should have scheduled more time to deliver the results in the last month. The delay was due to the team’s researchers taking more time to graph and analyze the results in the VOSviewer tool.
6. Conclusions
Currently, the prediction of mortality risk in “COVID-19” patients and comorbidity using machine learning applications has become of great interest to researchers in the area; however, there are still gaps to be resolved. This analysis has some limitations. First, this study includes articles from scientifically valid multidisciplinary databases; however, it excludes works published in proceedings, theses, or book chapters.
This study used PRISMA as the systematic literature review methodology to investigate ML algorithms, the variable selection techniques used, the ML algorithms implemented with the best performance, the type of dataset used, and the software or platform used for the analysis and implementation of models for the prediction of mortality risk in COVID-19 patients and patients with comorbidity. Algorithms are being used to predict mortality risk. However, it is evident that 100% of all algorithms are based on supervised learning; of the 32 papers, only seven (7) use published data, and four (4) implemented the prediction model in a web-based solution. The best-performing algorithms were the RF, CNN, DT, CAIM, and XGBoost. We found that the R tool obtained better prediction performance than Apache Spark, even better than implementations made with libraries such as TensorFlow, Keras, and those developed with Python language. Finally, it is essential to highlight that Keras software libraries facilitate the design and development of models based on ANN algorithms.
The analysis showed that the RF algorithm was the most used (in 11 studies), followed by the XGBoost method (in 6 studies), and was among the top five best performers. However, the CNN, DT, and CAIM algorithms also obtained high performance. Similarly, RF presented the highest accuracy, reaching an average of 89% (evaluated 11 times in the 32 reviewed), followed by XGBoost, with 88% (evaluated six times in the 32 reviewed), highlighting that this algorithm is one of those with the highest potential to deliver better performance in prediction issues in the clinical area.
Additionally, we can apply this work to predicting mortality in patients with inadequate health habits, such as smokers, those with nutritional issues, those suffering from alcoholism, drug addicts, and COVID-19 patients.
Finally, COVID-19 is now an endemic disease and is being suffered in patients with comorbidity, raising mortality risks in humans. Knowing new and better algorithms and more powerful and effective software environments is necessary to predict these patients’ mortality risks. This serves as the first line of medical care for decision-making that impacts two aspects. First, to save human lives; second, to maximize the resources available for the timely maintenance of patients with these clinical conditions.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}