


Saliency Guidance and Expansion Suppression on PuzzleCAM for Weakly Supervised Semantic Segmentation



Abstract
:1. Introduction
- (1)
- Finding the location of objects by classification model focuses on features that are well-defined and frequently appear on the same object. Mostly, the predictions are based on the well-localized and fine-grain regions, and hence the complete object may not be properly localized and segmented.
- (2)
- When the focus is on the scenes, such as the image of a boat on the water, an airplane in the air, etc., the background is sometimes misjudged as a single object in the mapping. This results in pseudo masks generated even beyond the object areas.
- (3)
- Smooth color regions in the object are hard to label using the general classifiers.
- The ideal Suppression Module (SUPM) is proposed and integrated to enlarge the object’s attention.
- Saliency Map Guided Module (SMGM) is developed to resolve the issues in smooth color regions.
- Multi-Task Learning framework is adopted to jointly train the model for classification and segmentation task.
2. Related Works
3. Proposed Method
4. Experiment Result
4.1. Datasets
4.1.1. PASCAL VOC 2012
4.1.2. Augmented Dataset
4.1.3. Saliency Map
4.2. Training
4.3. Ablation Test
4.3.1. Module Ablation Experiment
4.3.2. Loss Function
4.3.3. Backbone Selection
4.3.4. Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 3213–3223. [Google Scholar]
- Kolesnikov, A.; Lampert, C.H. Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2016; pp. 695–711. [Google Scholar]
- Ahn, J.; Kwak, S. Learning Pixel-Level Semantic Affinity with Image-Level Supervision for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4981–4990. [Google Scholar]
- Huang, Z.; Wang, X.; Wang, J.; Liu, W.; Wang, J. Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7014–7023. [Google Scholar]
- Jo, S.; Yu, I.-J. Puzzle-Cam: Improved Localization via Matching Partial and Full Features. In Proceedings of the International Conference on Image Processing (ICIP), Alaska, WA, USA, 19–22 September 2021; pp. 639–643. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 2921–2929. [Google Scholar]
- Papandreou, G.; Chen, L.-C.; Murphy, K.P.; Yuille, A.L. Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1742–1750. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Boxsup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1635–1643. [Google Scholar]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple Does It: Weakly Supervised Instance and Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 876–885. [Google Scholar]
- Vernaza, P.; Chandraker, M. Learning Random-Walk Label Propagation for Weakly-Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 7158–7166. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-Supervised Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 3159–3167. [Google Scholar]
- Hou, Q.; Jiang, P.; Wei, Y.; Cheng, M.-M. Self-Erasing Network for Integral Object Attention. arXiv 2018, arXiv:1810.09821v1. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.; Lee, J.; Shim, H. Railroad Is Not a Train: Saliency as Pseudo-Pixel Supervision for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5495–5505. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. Resnest: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. Ficklenet: Weakly and Semi-Supervised Semantic Image Segmentation Using Stochastic Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5267–5276. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected Crfs with Gaussian Edge Potentials. arXiv 2017, arXiv:1210.5644. [Google Scholar] [CrossRef]
- Sutton, C.; McCallum, A. An Introduction to Conditional Random Fields. Found. Trends® Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Kim, B.; Han, S.; Kim, J. Discriminative Region Suppression for Weakly-Supervised Semantic Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 1754–1761. [Google Scholar]
- Jiang, P.-T.; Yang, Y.; Hou, Q.; Wei, Y. L2G: A Simple Local-to-Global Knowledge Transfer Framework for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16886–16896. [Google Scholar]
- Jo, S.H.; Yu, I.J.; Kim, K.-S. RecurSeed and CertainMix for Weakly Supervised Semantic Segmentation. arXiv 2022, arXiv:2204.06754. [Google Scholar]
- Yao, Q.; Gong, X. Saliency Guided Self-Attention Network for Weakly and Semi-Supervised Semantic Segmentation. IEEE Access 2020, 8, 14413–14423. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Ahn, J.; Cho, S.; Kwak, S. Weakly Supervised Learning of Instance Segmentation with Inter-Pixel Relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2209–2218. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (Voc) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic Contours from Inverse Detectors. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]







{kind=link}
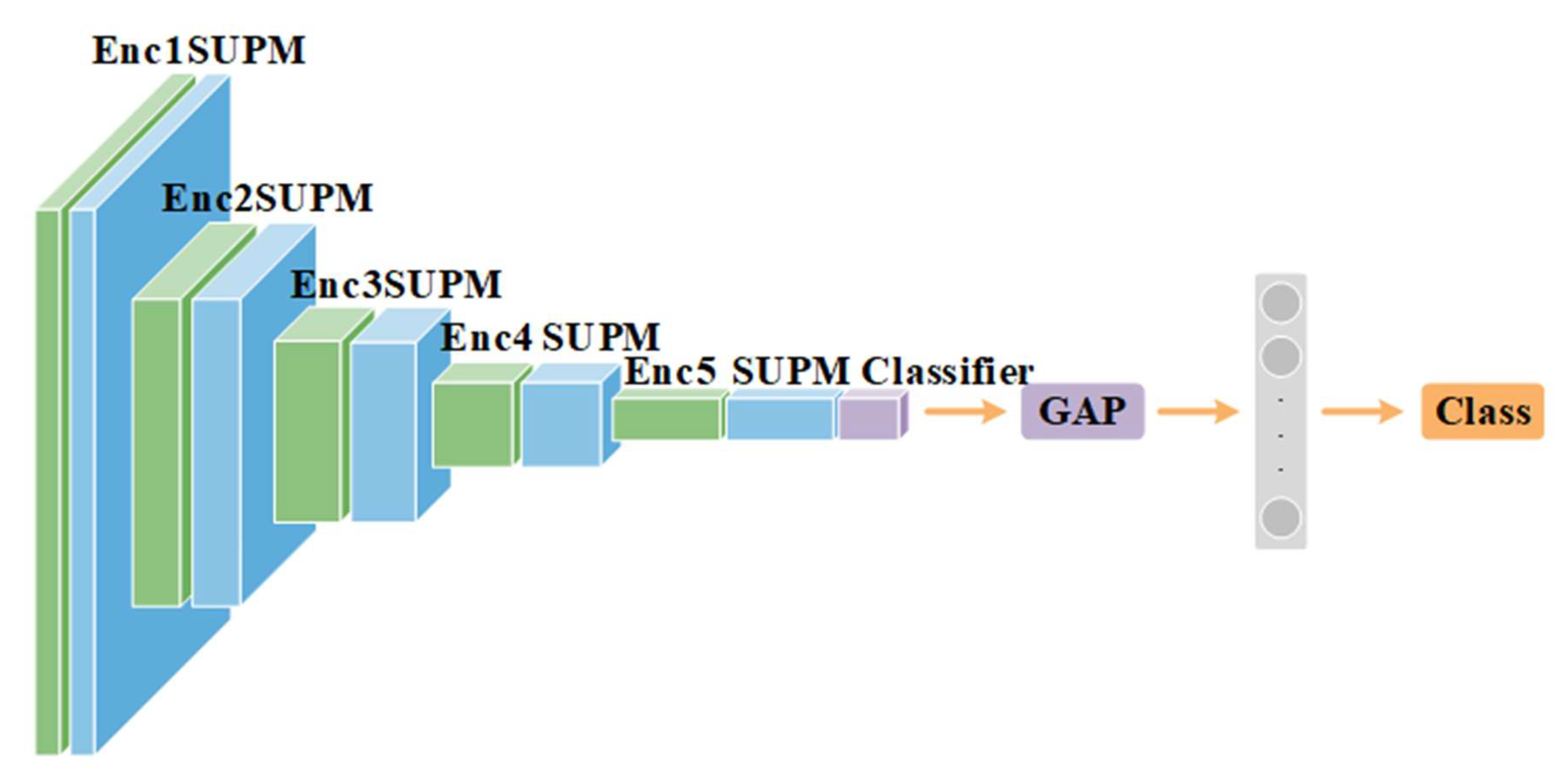{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Methodology | Limitations |
|---|---|---|
| G. Papandreou et al. [9] | In this work, weakly annotated data or image-level labels are used for training. The method is based on Expectation-Maximization (EM) strategy and can learn from a few strongly labelled and many weakly labelled data. | Performs with limited accuracy in case of images with overlapping class objects. |
| D. Lin et al. [13] | An alternate approach is proposed, which can significantly reduce the annotation time using only scribbles. A graphical model is proposed to learn from scribbled pixels and then propagate to the unmarked pixels. | Though the approach reduces manual annotation time, it cannot be completely eliminated. |
| A. Khoreva et al. [11] | The method involves recursive training of convnets and tools like GrabCut to generate the training label from the bounding boxes. | Limited to fully and semi-supervised approaches, and weakly supervised cannot be performed. |
| P. Vernaza et al. [12] | In this work, a label-propagation algorithm is proposed using random walk-hitting probabilities. The method can be trained using sparse image labeling. | The approach is tested on VOC2012 and is not applicable to the bounding box and weakly supervised training. |
| S. Jo et al. [7] | A new approach to generated pseudo-labels is proposed using the puzzle module, and two regularization terms termed Puzzle-CAM. | The method has problems such as the entire object may not be properly segmented, and sometimes the background pixels are considered as foreground. |
| J. Lee et al. [17] | The Fickle-Net explores the multiple combinations of the feature map locations and uses them to obtain the activation scores for superior image classification. | Though the method produces accurate segmentation, the detected object boundaries are slightly eroded compared to the ground truth. |
| B. Kim et al. [21] | In the Discriminative Region Suppression (DRS) [21] architecture, the focus points with high values on the feature map are directly suppressed. This increases the training burden and extracts deep features. The mechanism targets the prominent feature and then the extent to other feature areas to obtain a broader perspective of objects. | The methods [21,26] failure cases are in long-range connected objects such as bird wings. Some object regions may get eroded, and the segmented objects have too many missing pixel. |
| J. Ahn [26] | The method initially aims to obtain pseudo-instance segmentation labels, which can be used for supervised model training. In addition, a new model based on inter-pixel relationship (IRNet) can detect approximate individual instances and detects boundary between different object classes. | |
| S. H. Jo [23] | In the latest, an improved method termed RecurSeed is proposed, which recursively reduces non and false-detections. A novel data augmentation technique termed EdgePredictMix is also proposed to find optimal edge junctions which can minimize boundary errors. | There is a scope for improvement in terms of object boundaries and reducing the detection of unwanted background regions. |
| Backbone | SUPM | SMGM | mIoU (%) |
|---|---|---|---|
| ResNet50 | 47.63 | ||
| V | 50.52 | ||
| V | 49.57 | ||
| V | V | 52.32 |
| 1 | 2 | 3 | 4 | ||
|---|---|---|---|---|---|
| 1 | 51.74 | 52.42 | 52.90 | 52.81 | |
| 2 | 52.30 | 53.20 | 53.29 | 52.95 | |
| 3 | 51.82 | 52.87 | 52.99 | 52.82 | |
| Method | Backbone | CAM | CAM + RW | CAM + RW + dCRF |
|---|---|---|---|---|
| PuzzleCAM [7] | ResNeSt101 | 61.85 | 71.92 | 72.46 |
| Proposed Method | ResNet50 | 53.29 | 64.01 | 64.38 |
| ResNeSt50 | 60.09 | 68.50 | 68.75 | |
| ResNeSt101 | 64.19 | 75.67 | 76.00 |
| Method | Backbone | Sup. | mIoU (%) |
|---|---|---|---|
| EPS [17] (2021) | ResNet38 | I, S | 71.6 |
| PuzzleCAM [7] (2021) | ResNeSt269 | I | 74.7 |
| L2G [22] (2022) | ResNet38 | I, S | 71.9 |
| RSCM [23] (2022-SOTA) | ResNet50 | I | 75.5 |
| Proposed Method | ResNeSt101 | I, S | 76.0 |
| Method | Backbone | Sup. | Val | Test |
|---|---|---|---|---|
| SG-SAN [26] (2019) | ResNet101 | I, S | 67.1 | 67.2 |
| DRS [21] (2021) | ResNet101 | I, S | 71.2 | 71.4 |
| PuzzleCAM [7] (2021) | ResNeSt269 | I | 71.9 | 72.2 |
| RSCM [23] (2022-SOTA) | ResNet101 | I | 72.4 | 73.2 |
| Proposed Method | ResNeSt101 | I, S | 73.3 | 73.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, R.-H.; Guo, J.-M.; Seshathiri, S. Saliency Guidance and Expansion Suppression on PuzzleCAM for Weakly Supervised Semantic Segmentation. Electronics 2022, 11, 4068. https://doi.org/10.3390/electronics11244068
Chang R-H, Guo J-M, Seshathiri S. Saliency Guidance and Expansion Suppression on PuzzleCAM for Weakly Supervised Semantic Segmentation. Electronics. 2022; 11(24):4068. https://doi.org/10.3390/electronics11244068
Chicago/Turabian StyleChang, Rong-Hsuan, Jing-Ming Guo, and Sankarasrinivasan Seshathiri. 2022. "Saliency Guidance and Expansion Suppression on PuzzleCAM for Weakly Supervised Semantic Segmentation" Electronics 11, no. 24: 4068. https://doi.org/10.3390/electronics11244068
APA StyleChang, R. -H., Guo, J. -M., & Seshathiri, S. (2022). Saliency Guidance and Expansion Suppression on PuzzleCAM for Weakly Supervised Semantic Segmentation. Electronics, 11(24), 4068. https://doi.org/10.3390/electronics11244068