1. Introduction
The detection of defects on a product’s surface is important underlying research in the area of intelligent production, and this paper investigates the detection of surface defects in strip steel during industrial production. The surface quality of strip steel is one of the most important indicators of strip steel quality and is linked to the quality of products downstream in areas such as automotive, household appliances and construction. The detection of surface defects in steel has therefore become an extremely significant task in the steel production sector.
The identification of productor surface defects is an important task for enterprise product lines. In the early days, the task was completed by human-eyes checking, and it was limited by the human limitations of the eyes. After the emergence of image processing technology, the task was then completed by the characteristics of the defect image. Zhou [
1] et al. applied the SIFT algorithm to the identification of defects on the surface of medium-thick plates and achieved a good accuracy of 95% for defects that occur continuously. Hu [
2] et al. extracted four visual features of the target image: geometry, shape, texture and greyscale and used a genetic algorithm to optimize a hybrid chromosome-based classification model for effective identification of image defects. However, the characteristics-based methods made it hard to check for tiny defects or other imperfections. In recent years, deep learning methods, such as the convolutional network, were proposed to be applied in certain fields.
Since the introduction of Alexnet [
3] convolutional neural networks in 2012, they have demonstrated high efficiency and accuracy in object recognition. Convolutional neural networks have gradually become an important research direction in detection and recognition, and the accurate, fast and contact-free recognition techniques are continuously investigated. Manzo [
4] et al. used some pre-trained convolutional neural networks to detect the COVID-19 disease in CT images and gained an accuracy of 96.5%. Jiang [
5] et al. used an improved VGG network to identify rice and wheat leaf disease simultaneously. Tao [
6] et al. accurately identified smaller flames using an improved GoogLeNet network. As a new research hotspot, deep convolutional neural networks have been used in a wide range of industries.
Convolutional neural networks have been extensively applied to product surface defect recognition. Vonnocc [
7] et al. used traditional machine learning methods and deep learning methods to classify surface defects in hot rolled strip steel, and they found that the deep learning approach worked better. Konovalenko [
8] et al. detected surface defects in strip steel based on the ResNet50 framework, with a precision of 96.91% in recognition. Xiang [
9] et al. used a small sample dataset to achieve an accurate recognition rate of 97.8% on an improved VGG-19 network. Feng [
10] et al. added FcaNet and CMAM modules based on Resnet, achieving an accuracy of 94.11% for the defect identification in hot-rolled strip steel. Tang [
11] et al. used multi-scale maximum pooling and an attention mechanism to detect surface defects, where the classification accuracy rate reaches 94.73%. Xing [
12] proposes a convolutional classification model with symmetric structure to achieve accurate recognition of surface defects. These studies have focused on accuracy design, ignoring the computational volume, complexity and real-time requirements of the models in real-world applications. Wang [
13] et al. designed the VGG-ADB model for defect recognition, which achieved 99.63% classification accuracy and 333 frame/s inference speed. The VGG-ADB model considered the inference speed of the network, but the model was ignored for the parametric design, where the model size reached 72.15 M. This constrained the application of the model on edge devices. In actual production, not only does the network require extremely high detection accuracy, but it also has high requirements for model size, detection speed and real-time detection.
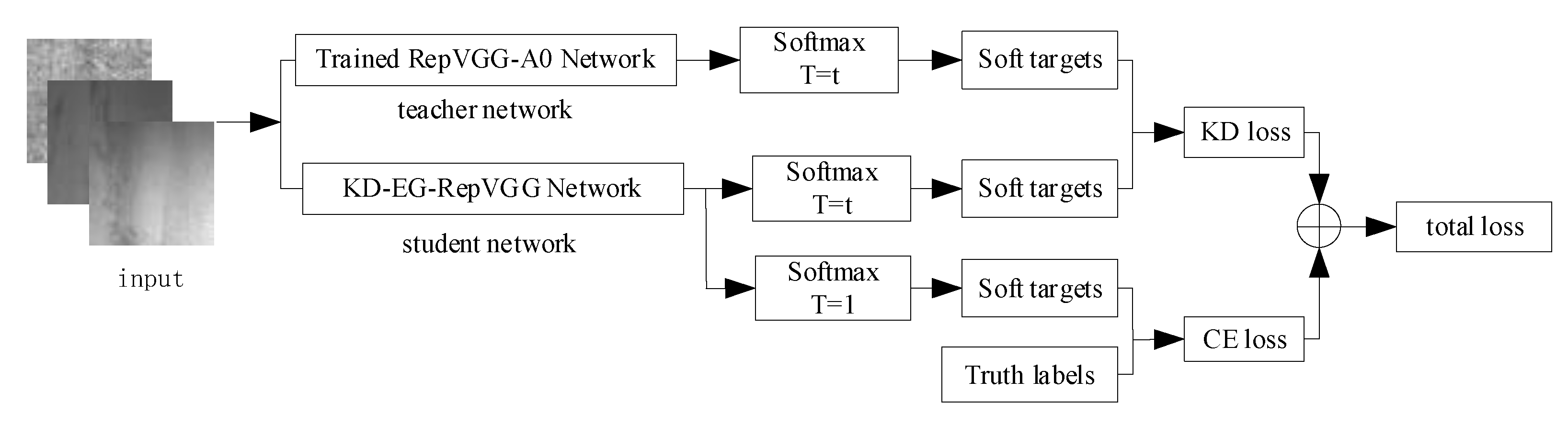
The KD-EG-RepVGG surface defect detection algorithm is designed using structural reparameterization, GELU, ECA networks and knowledge distillation for the task requirement of surface defects identification. Through experimental comparative analysis, the KD-EG-RepVGG network is characterized by a low number of parameters, low computational effort, high speed and high accuracy. The general idea of the method in the paper is illustrated in
Figure 1. The teacher network RepVGG-A0 guides the KD-EG-RepVGG network training. The structural re-parameterization technique loads the training weights into the KD-EG-RepVGG inference network to finally obtain the prediction results.
This paper is structured as follows.
Section 2 describes in detail the KD-EG-RepVGG network framework.
Section 3 verifies the validity of the network from several perspectives, whereas
Section 4 is the conclusion of the paper.
2. The KD-EG-RepVGG Network
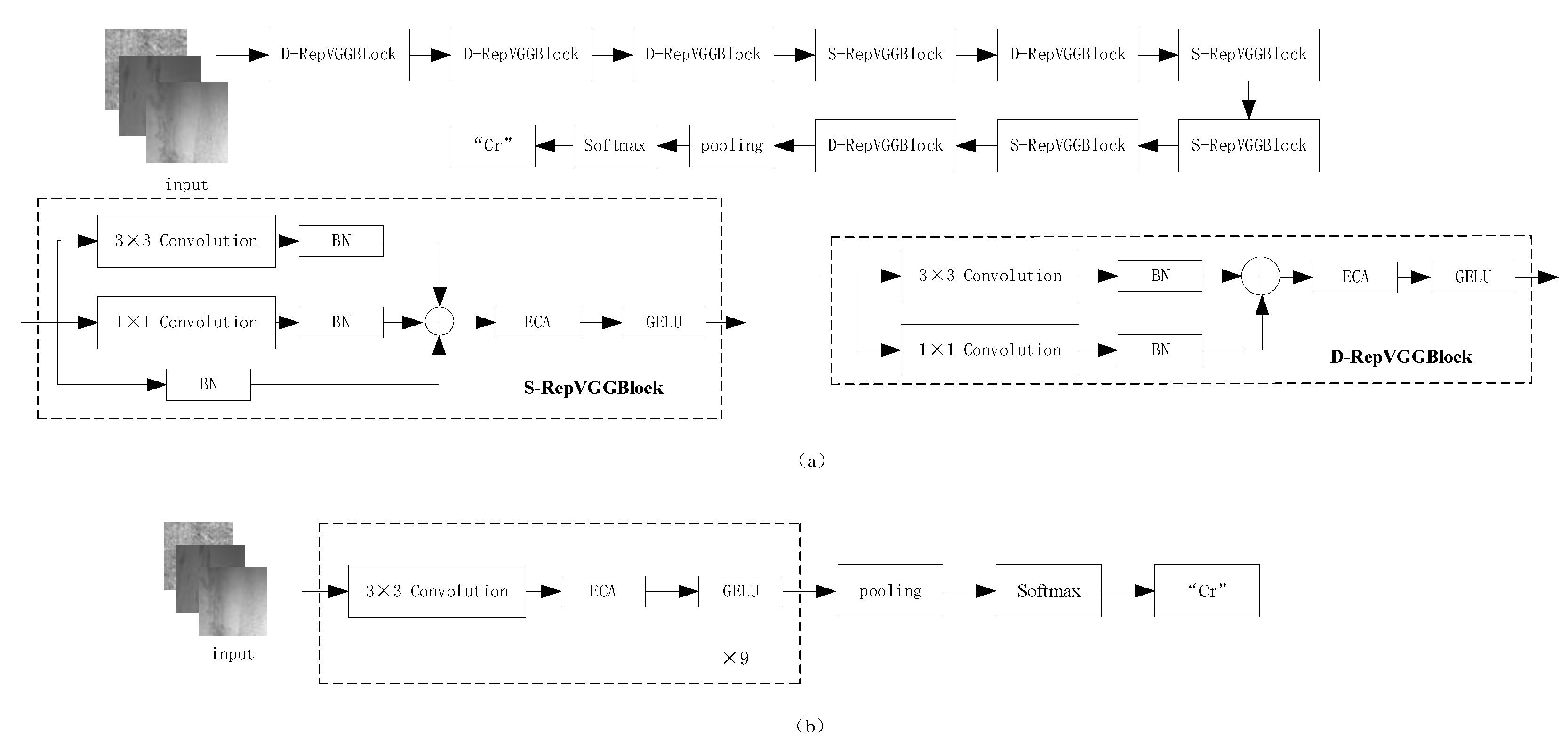
The EG-RepVGG network is based on structural reparameterization, incorporating a lightweight attention network while using GELU as the activation function in the improved network, stacking the S-RepVGG block module and D-RepVGG block module based on RepVGGBlock. The model is structured as shown in
Figure 2. The main function of the D-RepVGG block module is to extract features and adjust the space size and channel number of the feature map, whereas the main purpose of the S-RepVGG block is feature extraction. The S-RepVGG block has an additional directly connected structure compared to the D-RepVGG block, which mimics the residual connection in ResNet [
14] and improves the model’s ability to extract features. The output of D-RepVGG Block5 is made up of global average pooling and then a softmax classifier is appended. The global average pooling layer is used to downsample the output spatial resolution of the feature map to 1 × 1. The softmax layer is used to output the predicted categories. They together form the classification layer. With the aim of further improving the accuracy and generalization performance of the model, the RepVGG-A0 as a teacher model is used to guide the training of EG RepVGG model using knowledge distillation technology. The final result is a lightweight, fast and highly accurate strip steel surface defect recognition model, the KD-EG RepVGG model. The detailed structural information of the KD-EG-RepVGG model is shown in
Table 1.
2.1. Structural Re-Parameterisation
The structural reparameterization was first proposed in RepVGG networks by Ding XiaoHan [
15] et al. The inference network is decoupled from the training network using structural reparameterization techniques. Decoupling the training network and inference network by using structure re-parameterization can not only obtain the full advantage of feature extraction brought by multi branch network training, but also obtain the high speed and low memory consumption of a single path model in inference deployment. The core component of the RepVGG network is the RepVGG Block. Its structure is shown in
Figure 3.
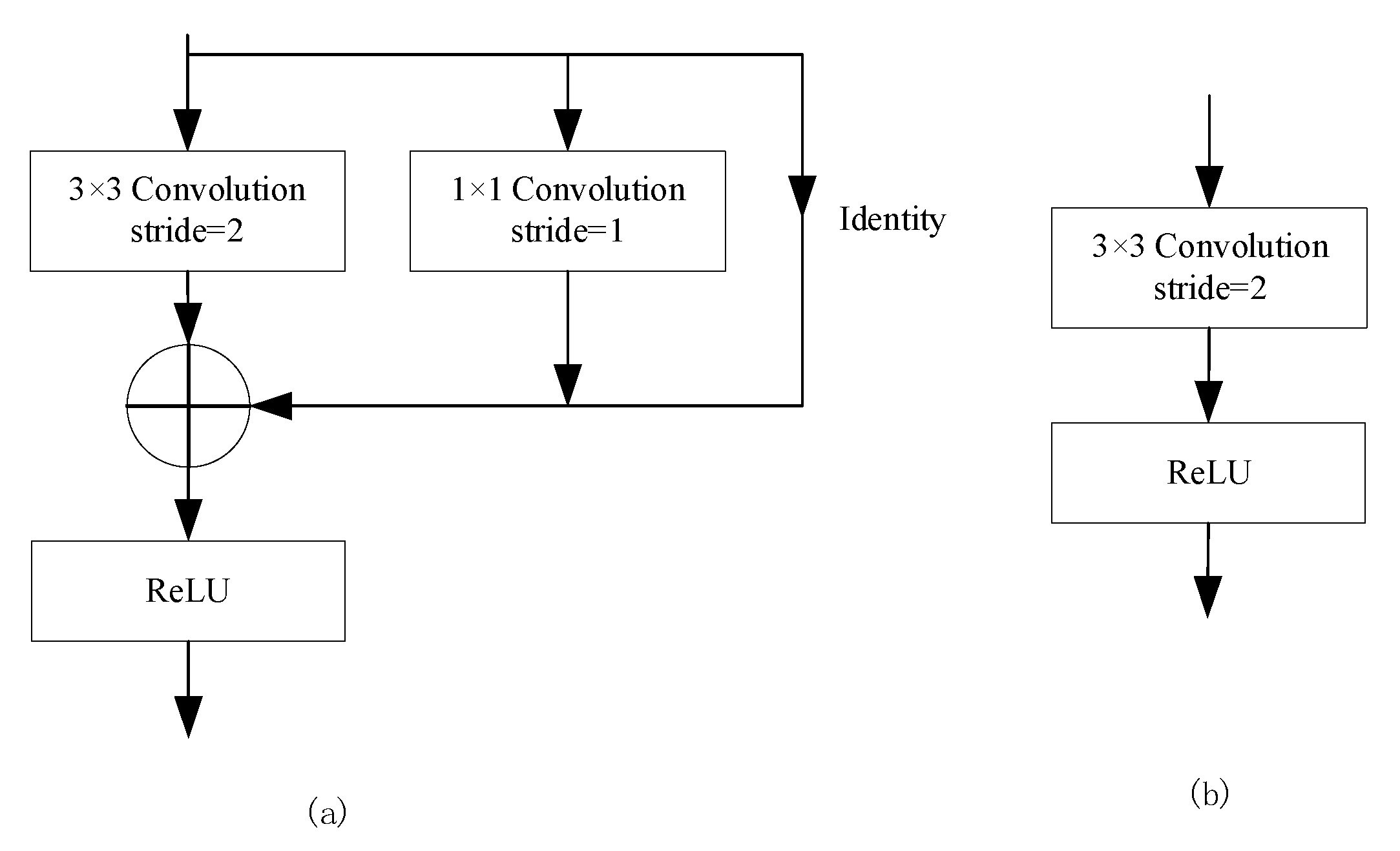
The structure of the network under training is illustrated in
Figure 3a. In the training phase, the RepVGG Block consists mainly of 3 × 3 convolutional kernels, 1 × 1 convolutional kernels and Identity branches. By adding Identities branches and 1 × 1 convolutional branches in parallel, information at different scales of the image can be extracted and fused, increasing the representational power of the model.
In the inference stage, the 1 × 1 convolution and Identity branch from the training are fused into the 3 × 3 convolution, and the inference structure is shown in
Figure 3b. RepVGG Block takes the training network and re-parameterizes it structurally, turning the network into a single linear structure consisting mainly of 3 × 3 convolutions without any branches. The inference structure both gains the parameter weights obtained from multi-branch training and allows the use of the single linear structure to speed up the inference of the model during the deployment inference phase. At the same time, deep optimization of the 3 × 3 convolution based on NVIDIA cuDNN’s computational library accelerates the model’s detection speed in the inference phase.
The structural reparameterization in the inference phase mainly consists of the fusion of the convolution kernel and the Batch Normalization (BN) layer [
16], the integration of 1 × 1 convolution into 3 × 3 convolution and the integration of Identity branches into 3 × 3 convolution. The formula for the fusion of the convolution and BN layers in the model is as follows:
where
denotes the mean of the BN layer and
denotes the BN layer variance;
and
are obtained statistically in the training dataset;
is a constant to prevent the denominator from being zero;
is the scale factor of the BN layer;
is the offset of the BN layer and the values of both
and
are obtained in the training.
For convolution, the formula is as it is in (2):
where
and
are the input and output of the convolution;
denotes the matrix weight of the convolution calculation; and
is the bias of the convolution layer calculation.
The input to the BN layer is the output of the convolution into it. This is equivalent to taking Equation (2) and bringing it into Equation (1), resulting in a calculation such as Equation (3):
The following can be obtained by sorting and simplifying:
From the calculation results, we can obtain a new convolution by incorporating the weight information calculated by Batch Normalization layer into the convolution layer, where the convolution weight is , and the bias of the convolution is.
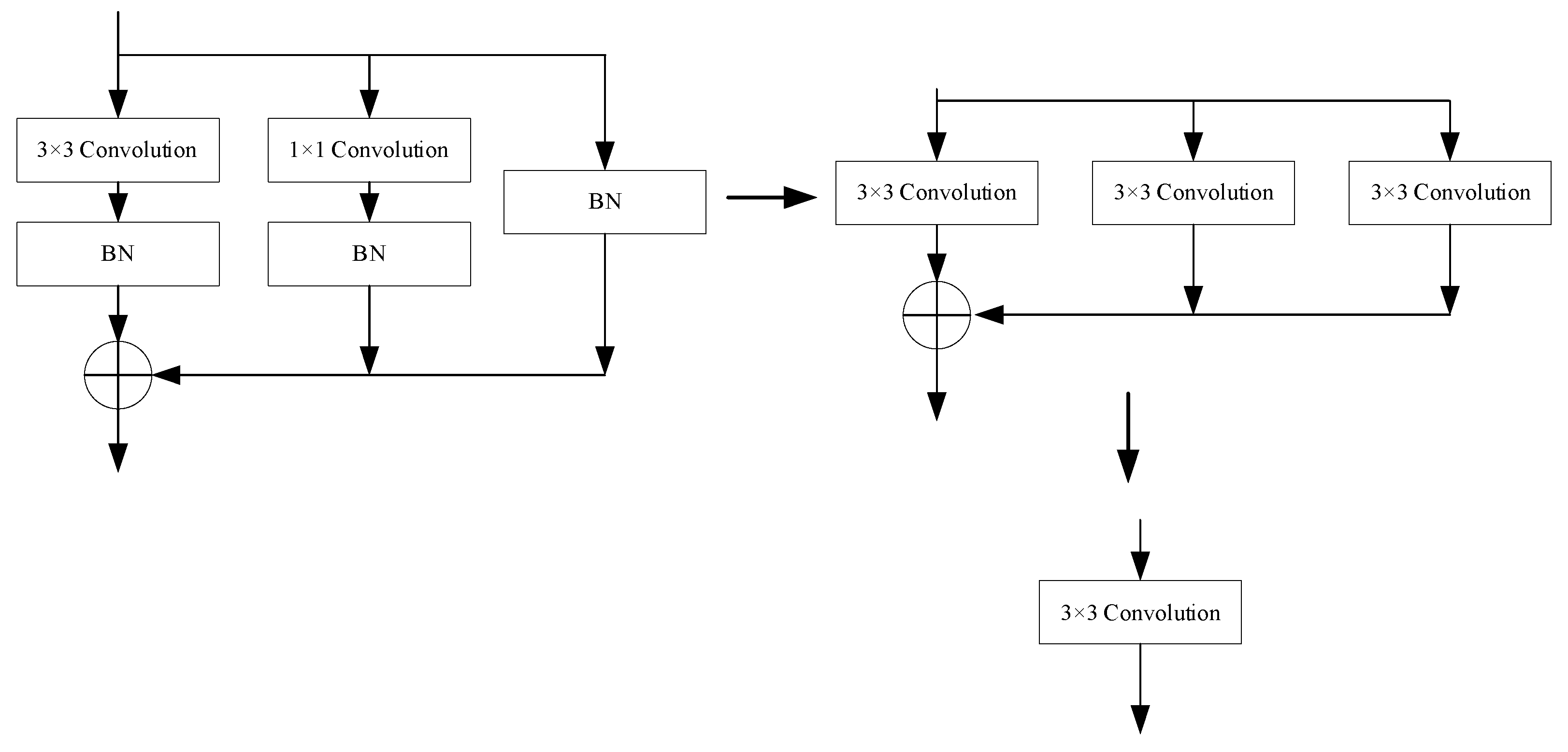
For the Identity branch in the RepVGG Block, a 1 × 1 convolution kernel with a weight of 1 is used to construct a 1×1 convolution, and then a 3 × 3 convolution kernel is set to perform identity mapping on the input features. Keep the output of the Identity layer unchanged before and after the transformation. For a 1 × 1 convolution branch, a complementary zero operation is performed around the 1 × 1 convolution kernel so that it becomes a 3 × 3 convolution. At this point, both the 1 × 1 convolution and Identity are converted into a 3 × 3 convolution, and based on the additivity of the convolution operation, the three branches can then be incorporated into a single 3 × 3 convolution. The process is shown in
Figure 4.
2.2. Efficient Channel Attention Network
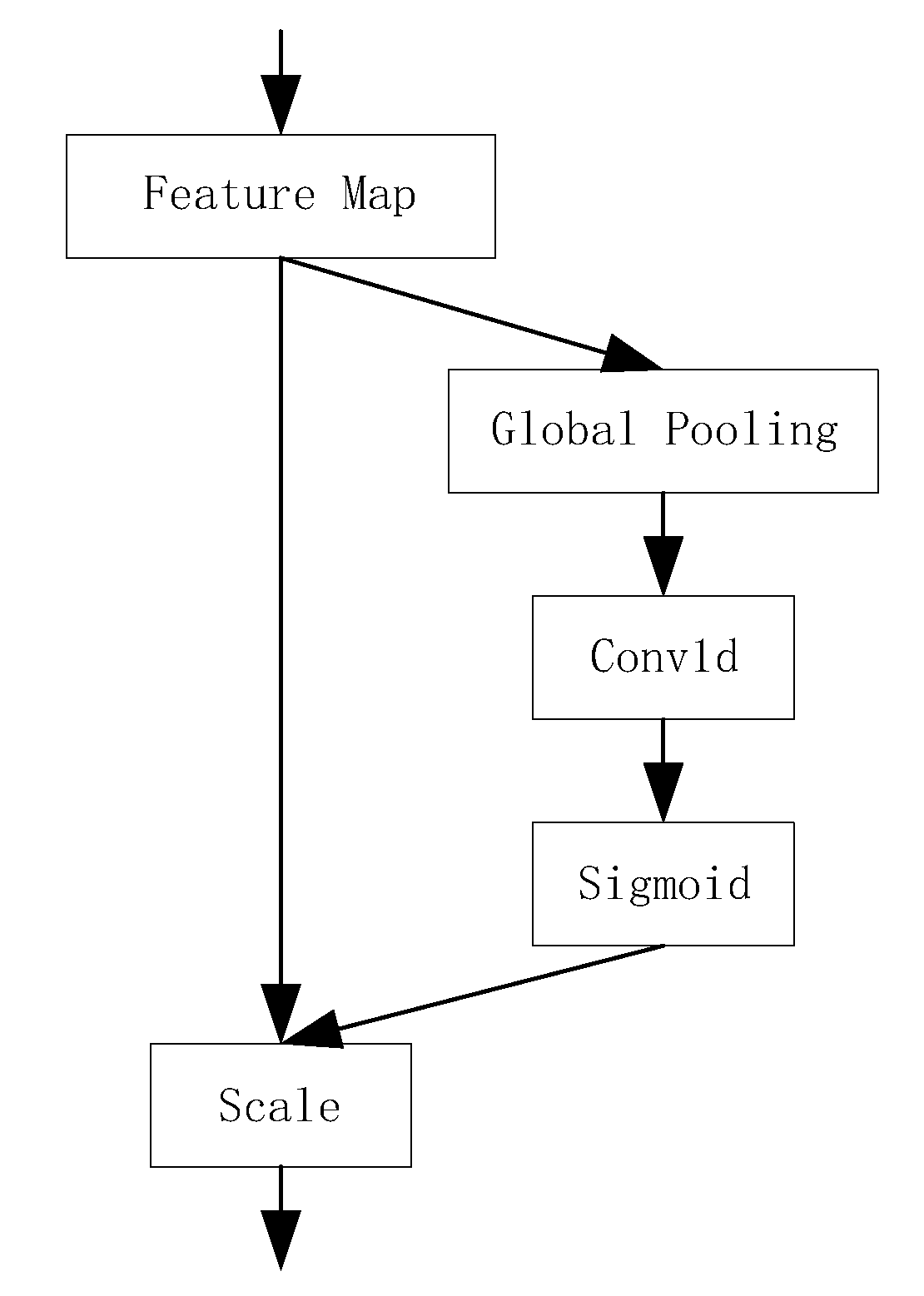
The Efficient Channel Attention network [
17] was added to the RepVGG Block to form the E-RepVGG network. The feature information can be obtained efficiently and without increasing the number of parameters of the model at the same time. The structure of ECA is shown in
Figure 5. The feature map
output from the convolution is pooled and globally averaged (Global Pooling) over the spatial dimension to output a feature vector
of size
, as is shown in Equation (5):
where
and
are the width and height of the feature map, respectively; and
is the number of channels in the feature map. Channel weighting coefficient obtained after the ECA network can be calculated by the following equation:
where
is the sigmoid activation function; Ψ is the weight of the ECA network on the channel; and
is the parameter matrix for calculating the channel attention in ECA networks. The mathematical model is represented as follows:
It is clear from
that the weight value of
is determined only by the
channels in the immediate vicinity of
. This can be expressed as a 1-dimensional convolution (
with a kernel of size
. Bringing in the simplification yields:
where
denotes a 1-dimensional convolution of convolution kernel size k. In this paper, considering the model parameters and inference speed, the size of all 1-dimensional convolution kernels is set to 3.
The weight coefficients of each channel calculated by the efficient attention network are multiplied by the channel weights of the input feature map
to obtain the output:
where
is the output of the ECA network.
2.3. Gaussian Linear Units
The rectified linear units (ReLU) activation function is used in the RepVGG Block, which effectively solved the problem of disappearing or exploding gradients as the neural network deepens. However, the ReLU activation function also has some problems. When the input is less than zero, the ReLU output will be directly zeroed, and the neuron will be permanently zeroed, which is detrimental to the convergence of the network model and feature extraction. Therefore, Gaussian Error Linear Units [
18] (GELU) are selected as the activation function in this paper to form the EG-RepVGG network. The GELU activation function is applied as a non-linear unit after the ECA network. The GELU activation function is differentiable at the origin, and the idea of stochastic regularity is introduced into the function. The activation operation will establish a stochastic connection between the input and output, effectively avoiding the situation where the neurons are set to zero and enhancing the learning speed and stability of the network.
2.4. Knowledge Distillation
The knowledge distillation is a novel technique for model compression proposed by Geoffrey Hinton [
19] et al. A complex, highly generalizable large model is used to guide the training of a lightweight small model, allowing the small model to achieve the same accuracy as the large model at a smaller cost. At the heart of the knowledge distillation network is the fact that the different classes of confidence in the output of the teacher network define a rich similarity structure at the data level and can provide more inter- class knowledge for small networks to guide the training of small networks. The characteristic distillation is calculated by:
The activation operation will establish a stochastic connection between the input and output, effectively avoiding the situation where the neurons are set to zero and enhancing the learning speed and stability of the network. The hyperparameter
softens the output categories of the large and small networks to find the distillation loss of the two networks’ outputs and the direct training output loss of the small network. The two losses are weighted and summed to obtain the training losses of the networks. The entire knowledge distillation network training process is shown in
Figure 6. In this paper, the KD-EG-RepVGG network was obtained by using RepVGG-A0 as the teacher network and instructing the training of the EG-RepVGG network.
The loss function used in the training phase is the
scatter loss and the cross-entropy loss weighted sum is used as the final loss for training and the loss formula is as in (11)
where
is the number of categories of defects;
represents the information about the features of the teacher network after the distillation temperature;
represents the information about the features of the student network after the distillation temperature;
is the scatter loss, an asymmetry measure of the difference between the probability distributions of
and
. This is shown in Equation (12).
is the cross-entropy loss, which indicates how close the predicted output value is to the true sample label, as shown in Equation (13). In this paper, the distillation temperature
. α is the default value, which in this paper is 0.3 by default.
4. Conclusions
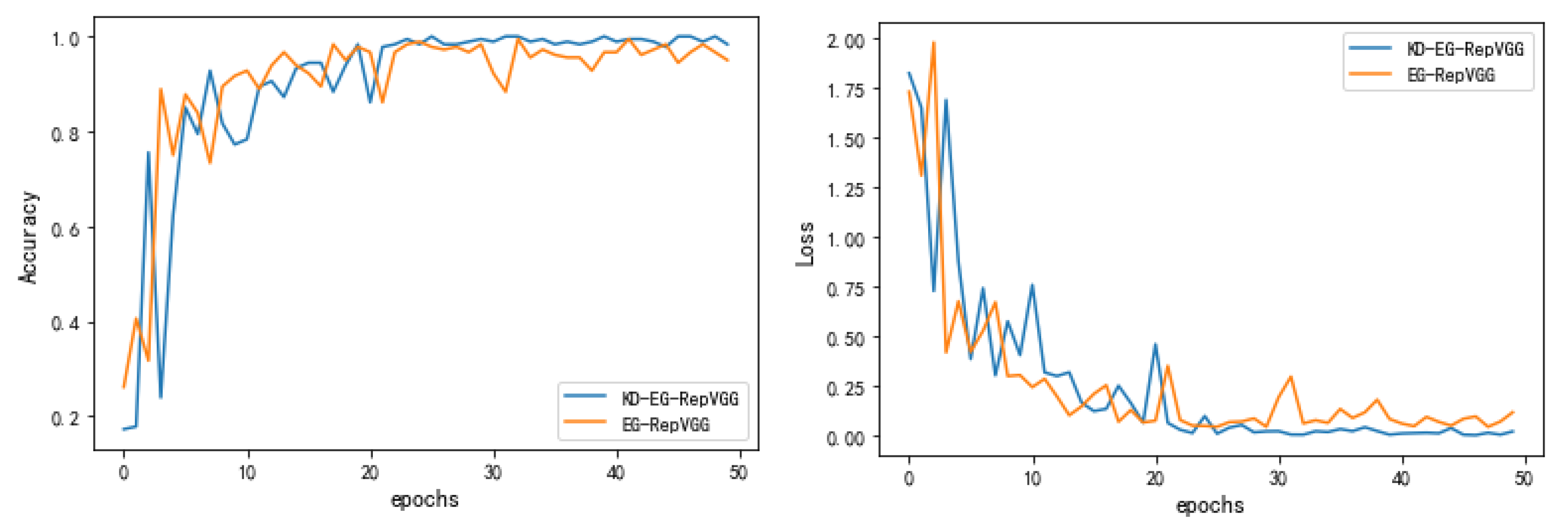
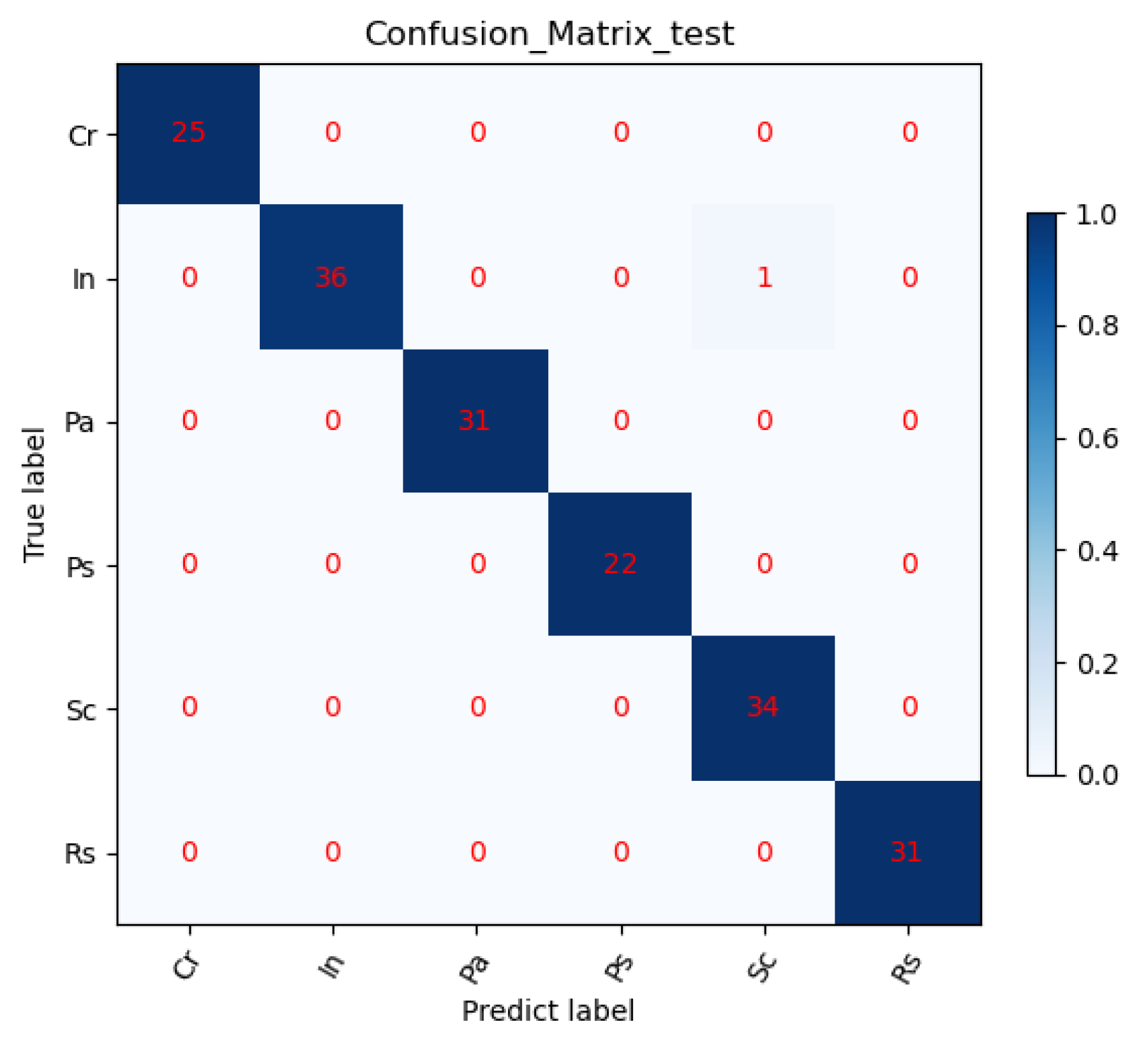
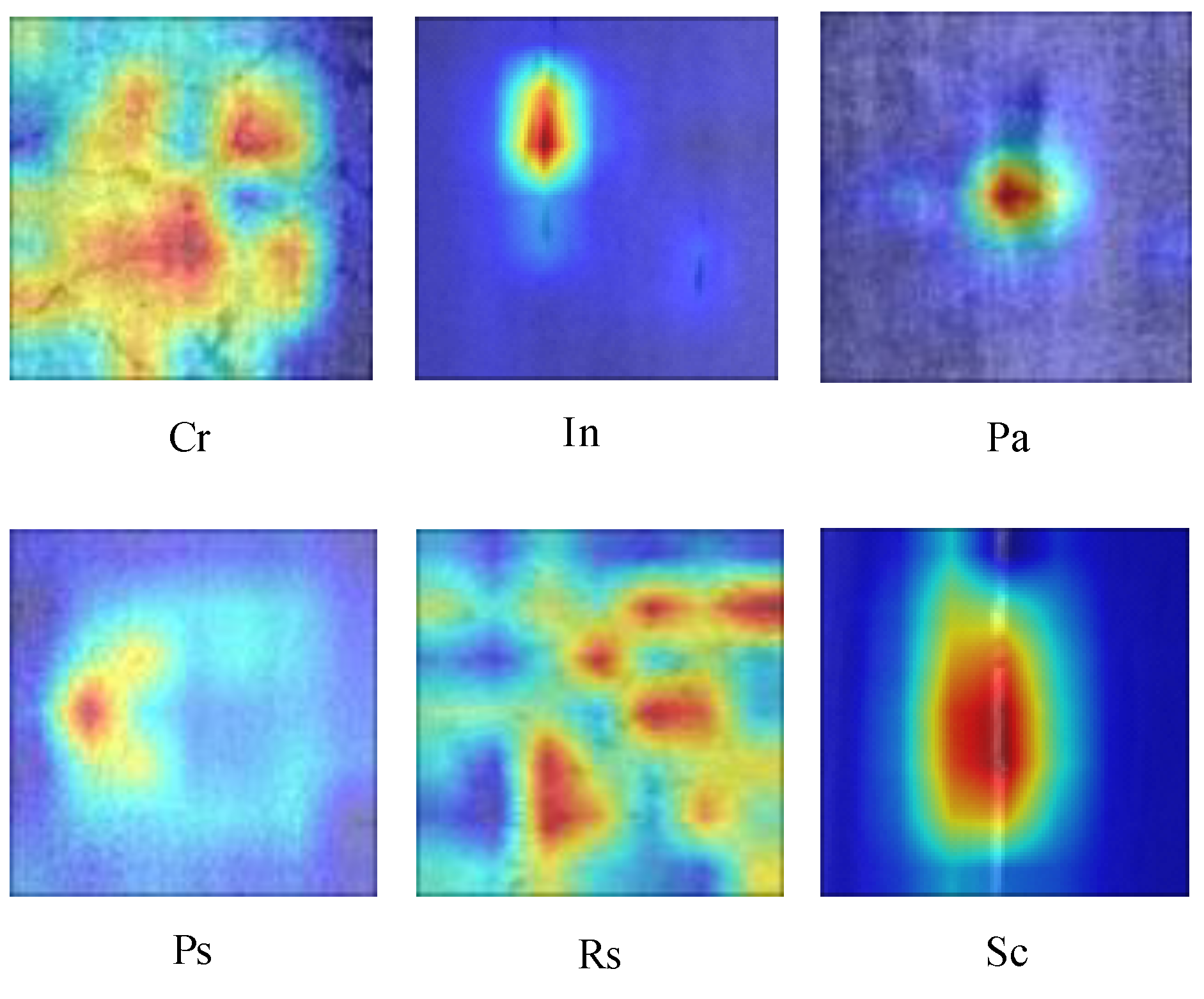
Aiming at the requirement of strip surface defect detection in actual production, a strip defect recognition method based on a structural re-parameterized KD-EG-RepVGG network is proposed. In RepVGG Block, the ECA network and GELU activation functions are added. Among them, the ECA network improves the accuracy of the KD-EG-RepVGG network while increasing the convergence speed of KD-EG-RepVGG. The GELU activation function avoids neuron necrosis caused by zeroing. Through knowledge distillation technology, the KD-EG-RepVGG model obtains the knowledge of RepVGG-A0, which improves the accuracy and robustness of the model. Through ablation experiments and comparative analysis with other models, it can be seen that the lightweight KD-EG RepVGG network takes up very little memory resources and computing resources without affecting the accuracy, and has a faster detection speed. It is more suitable for deployment and uses in real production.
The future work involves many directions. Firstly, the research in this paper will be used as a basis to study the accurate localization of defects and to analyze the size of defects accurately. Then, the model will be deployed on edge equipment and applied in the production environment within plants.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}