
A Hybrid and Hierarchical Approach for Spatial Exploration in Dynamic Environments


Abstract
:1. Introduction
2. Related Work
2.1. Autonomous Spatial Exploration
2.2. RL Based on Intrinsic Motivation
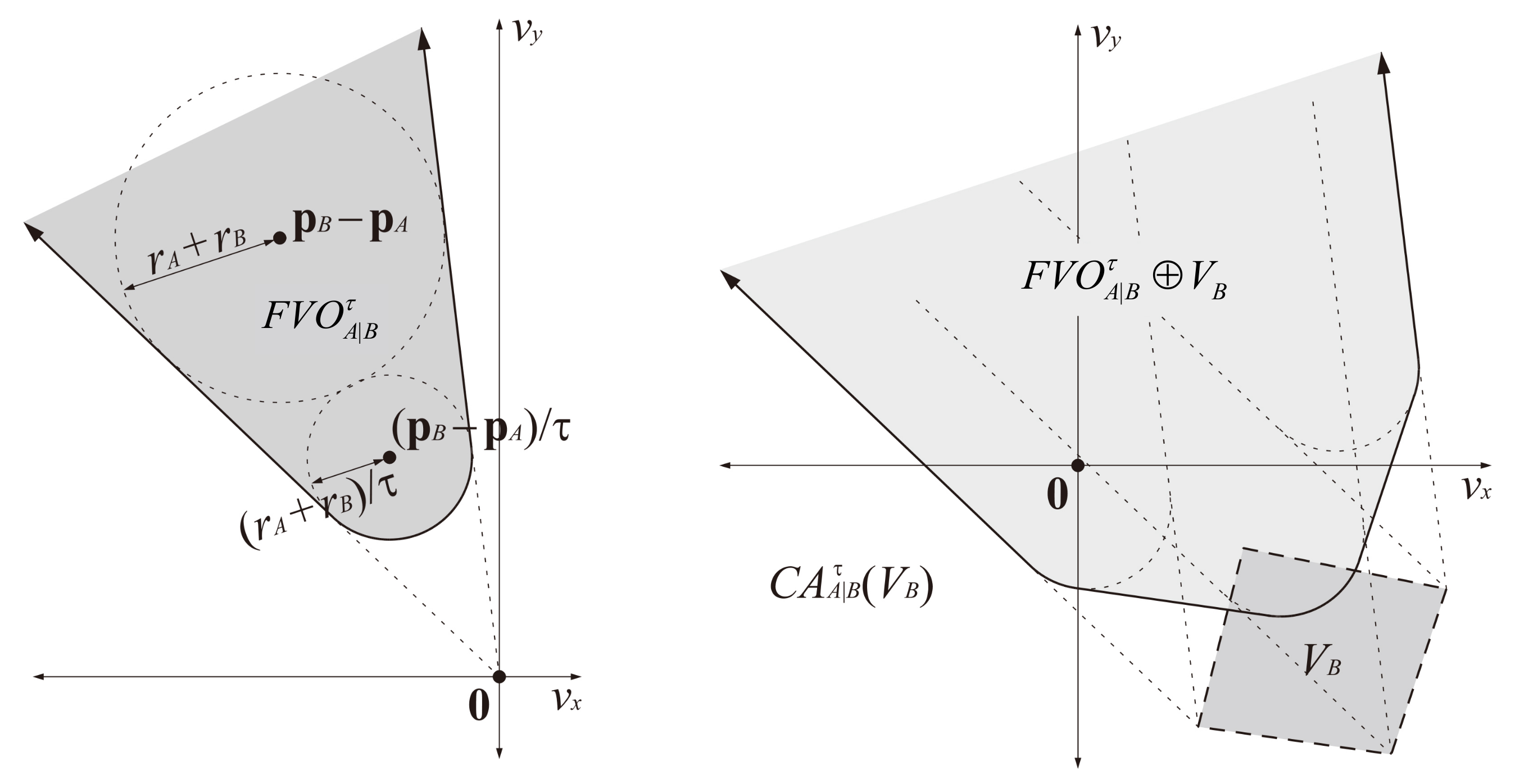
2.3. Velocity Obstacle
3. Problem Formulation
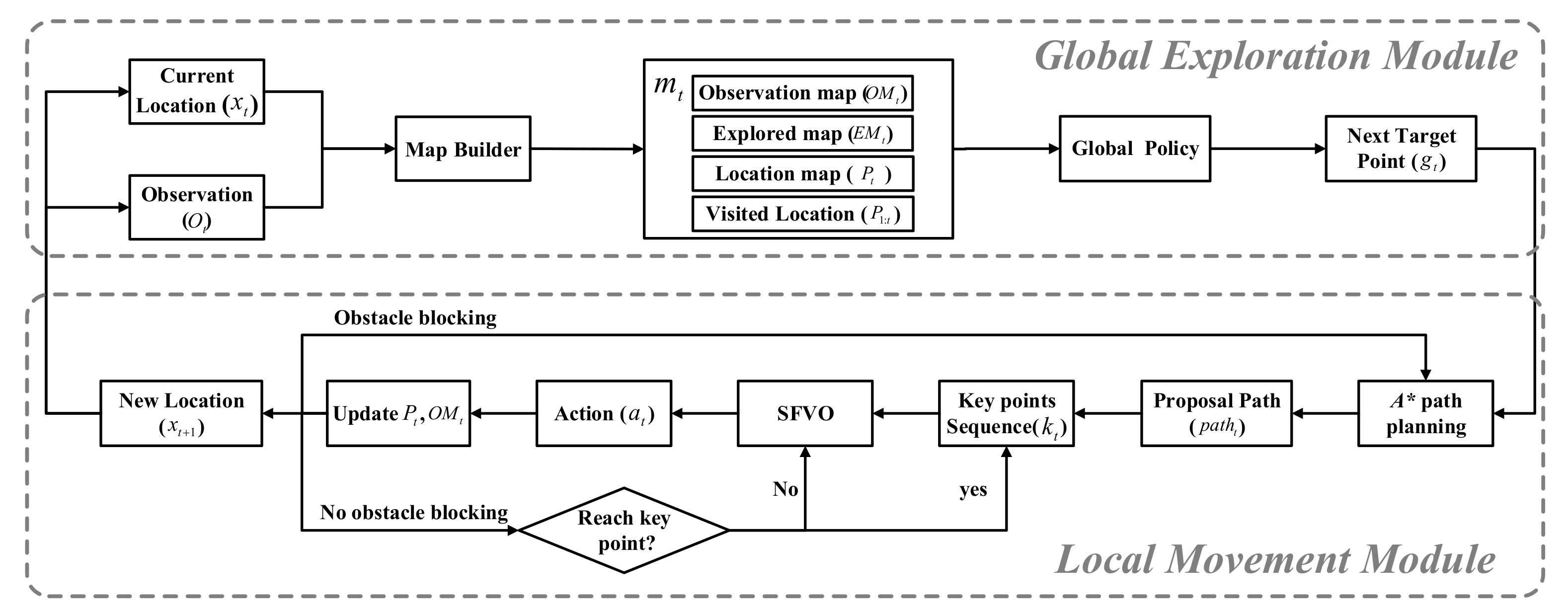
4. The Proposed Model
4.1. Global Exploration Module
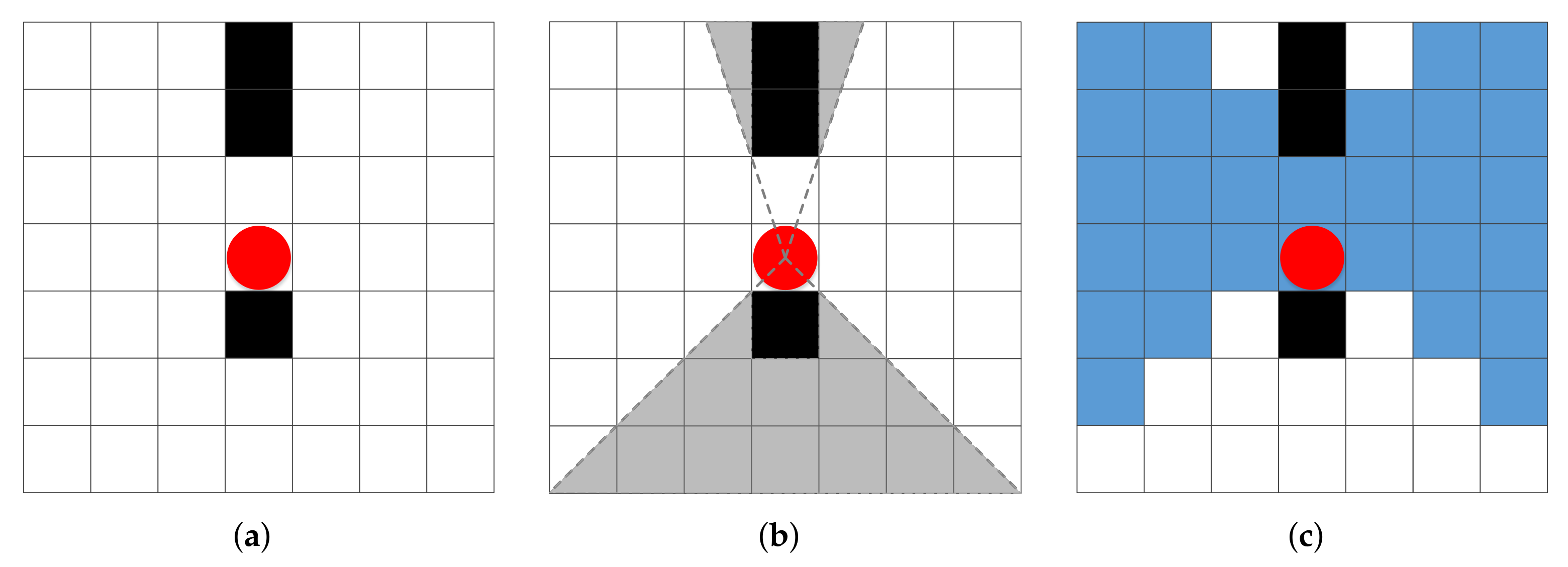
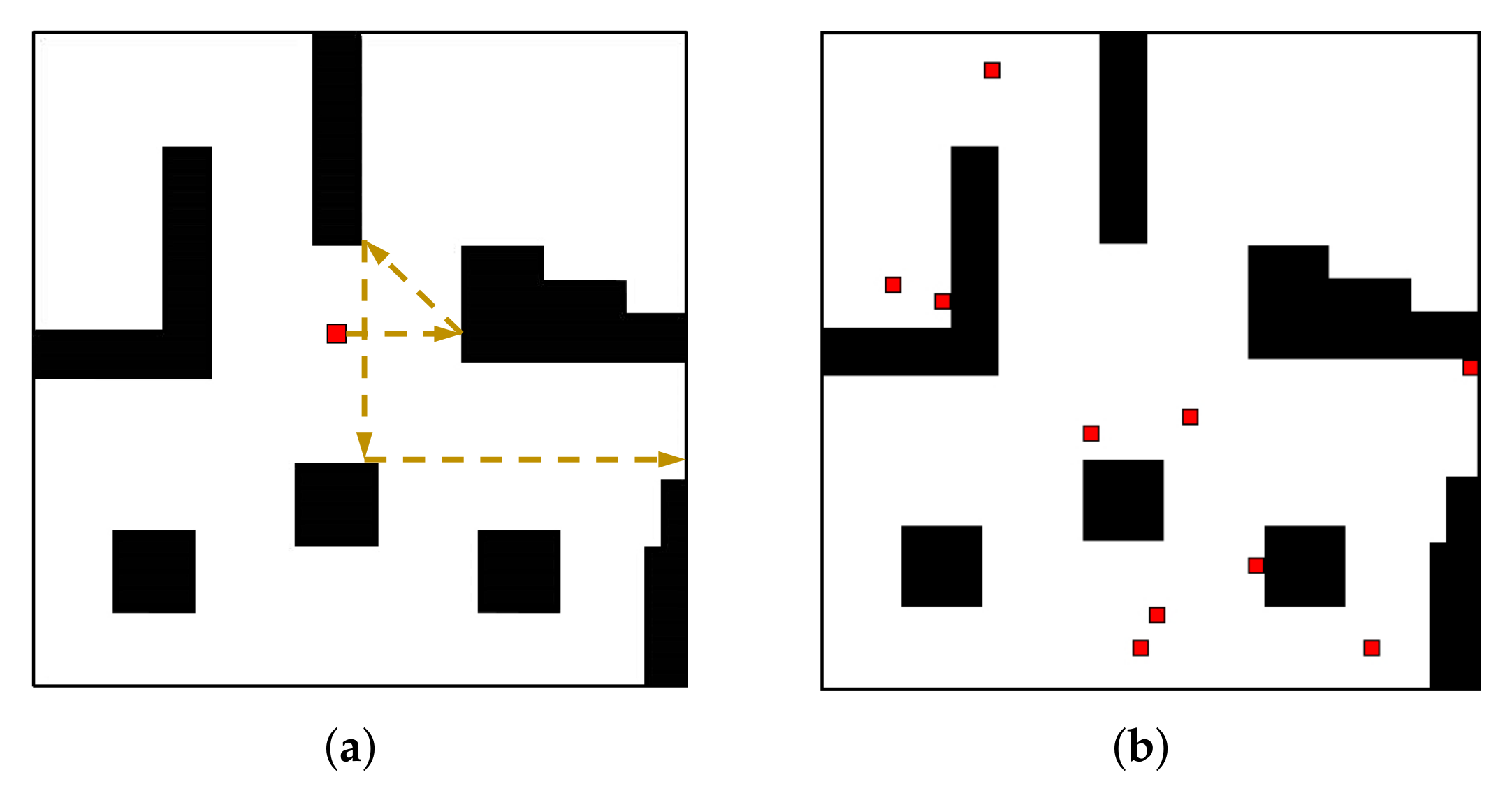
4.1.1. Spatial Map Representation
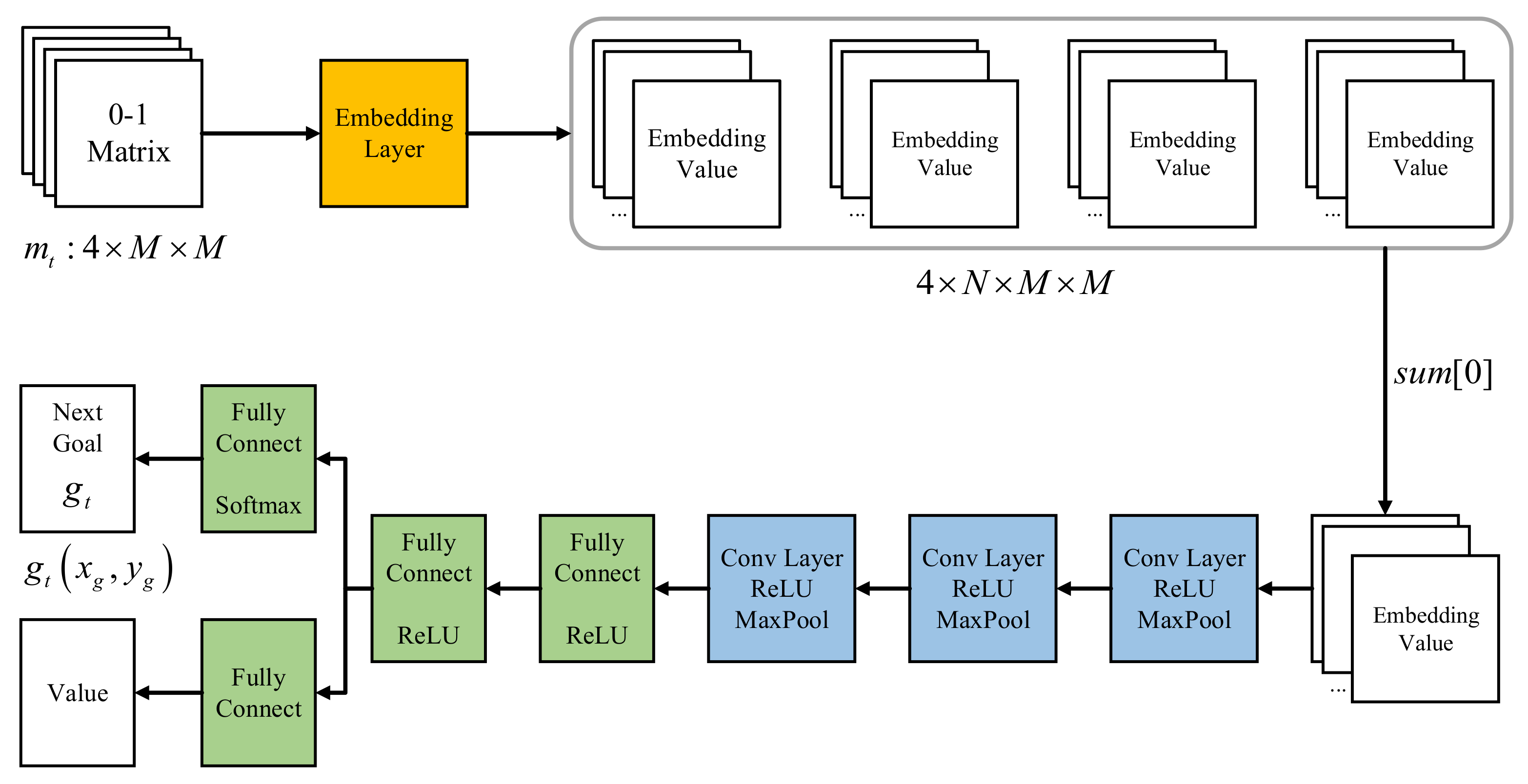
4.1.2. Network Architecture
4.1.3. Intrinsic Reward
4.2. Local Movement Module
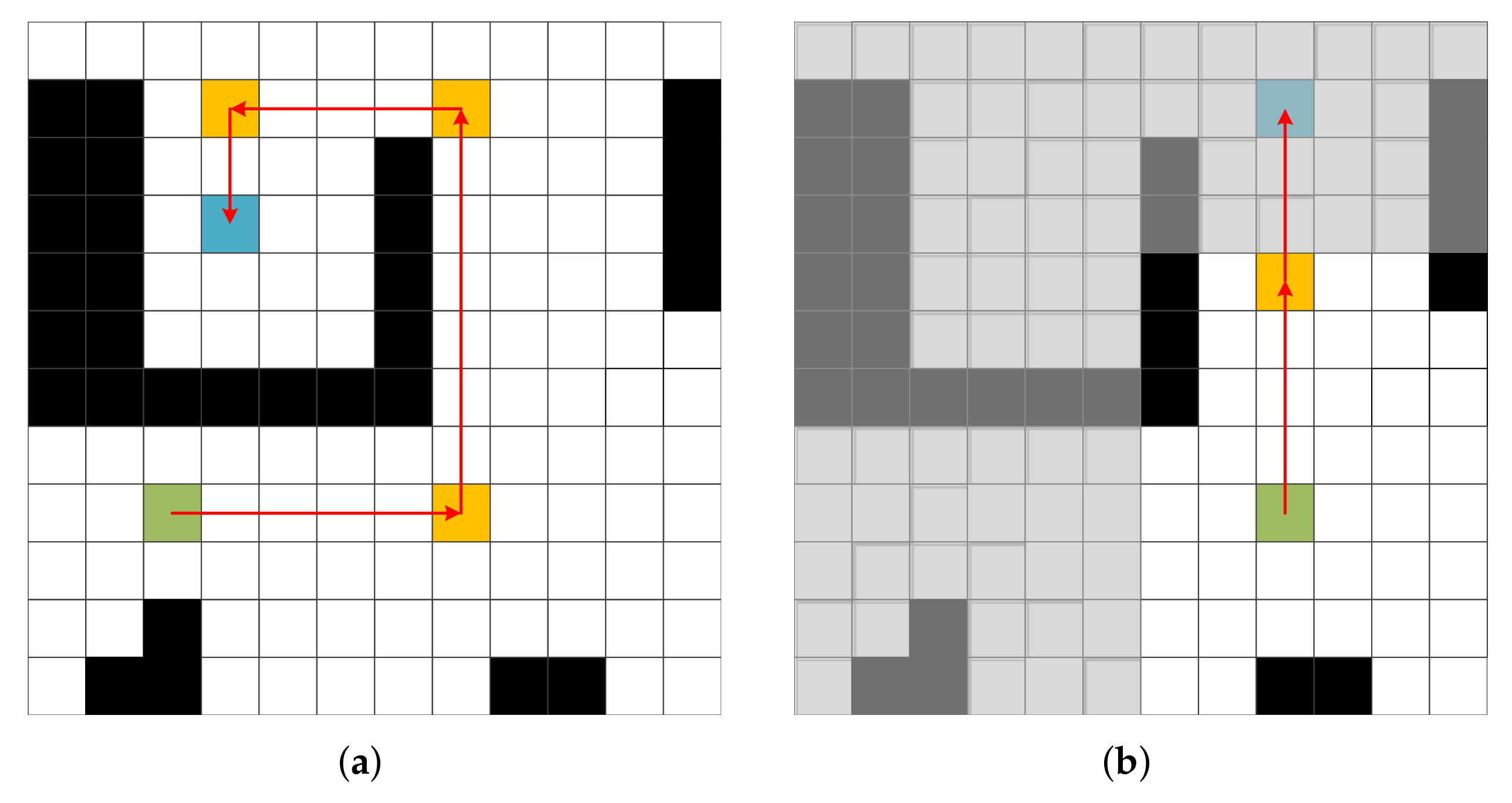
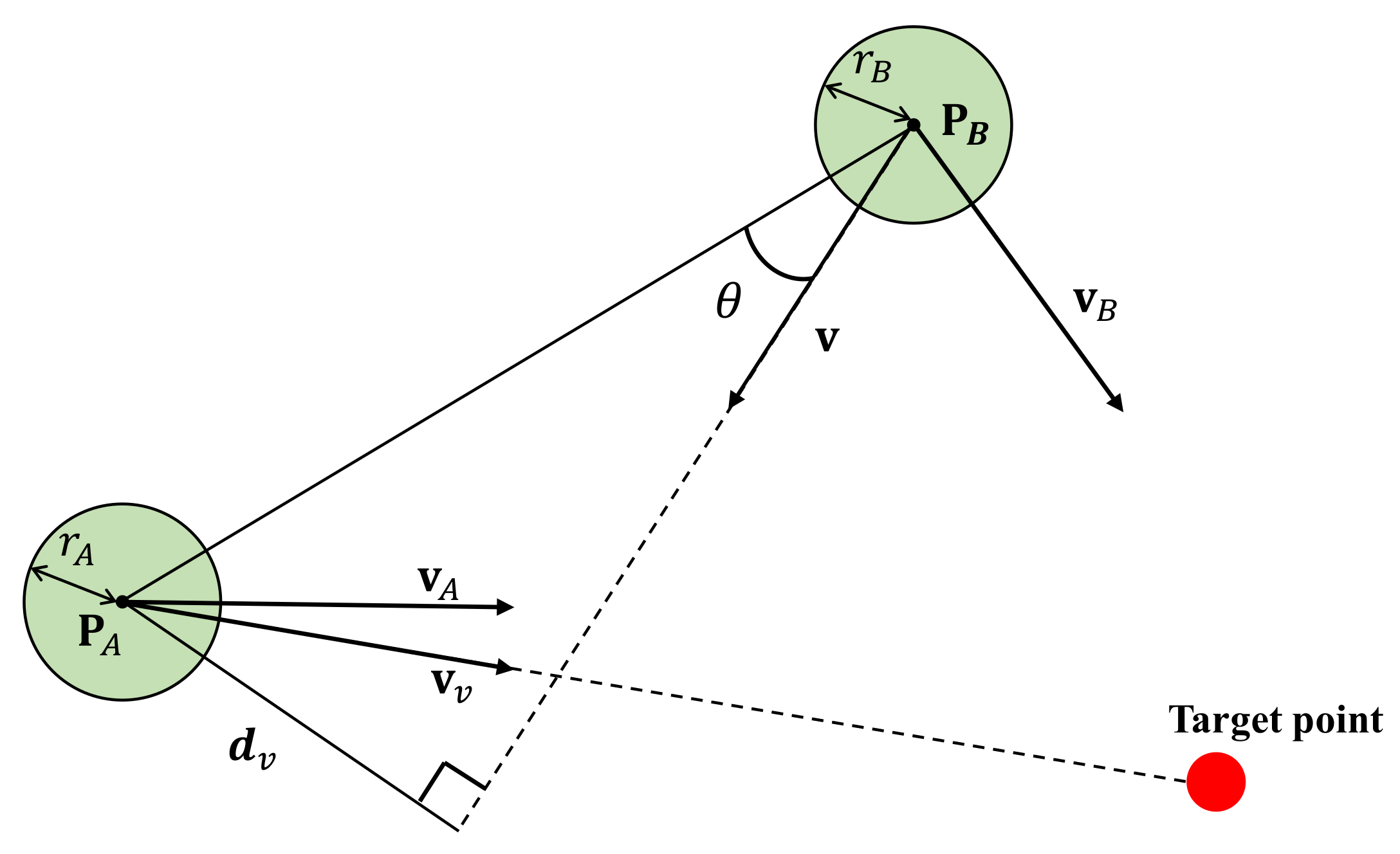
4.2.1. Planning Stage
4.2.2. Controlling Stage
| Algorithm 1 SFVO |
|
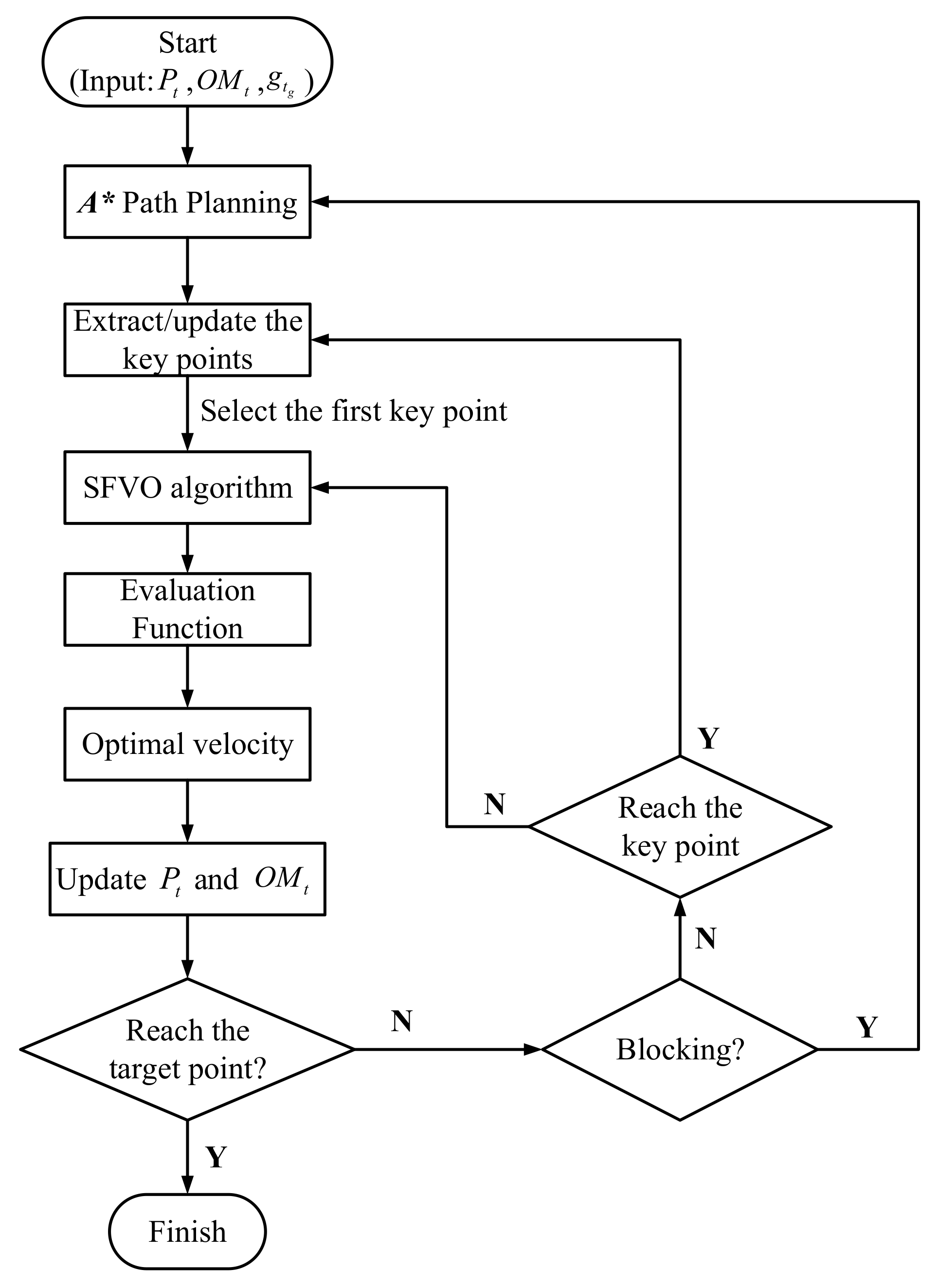
4.2.3. The Hybrid Algorithm
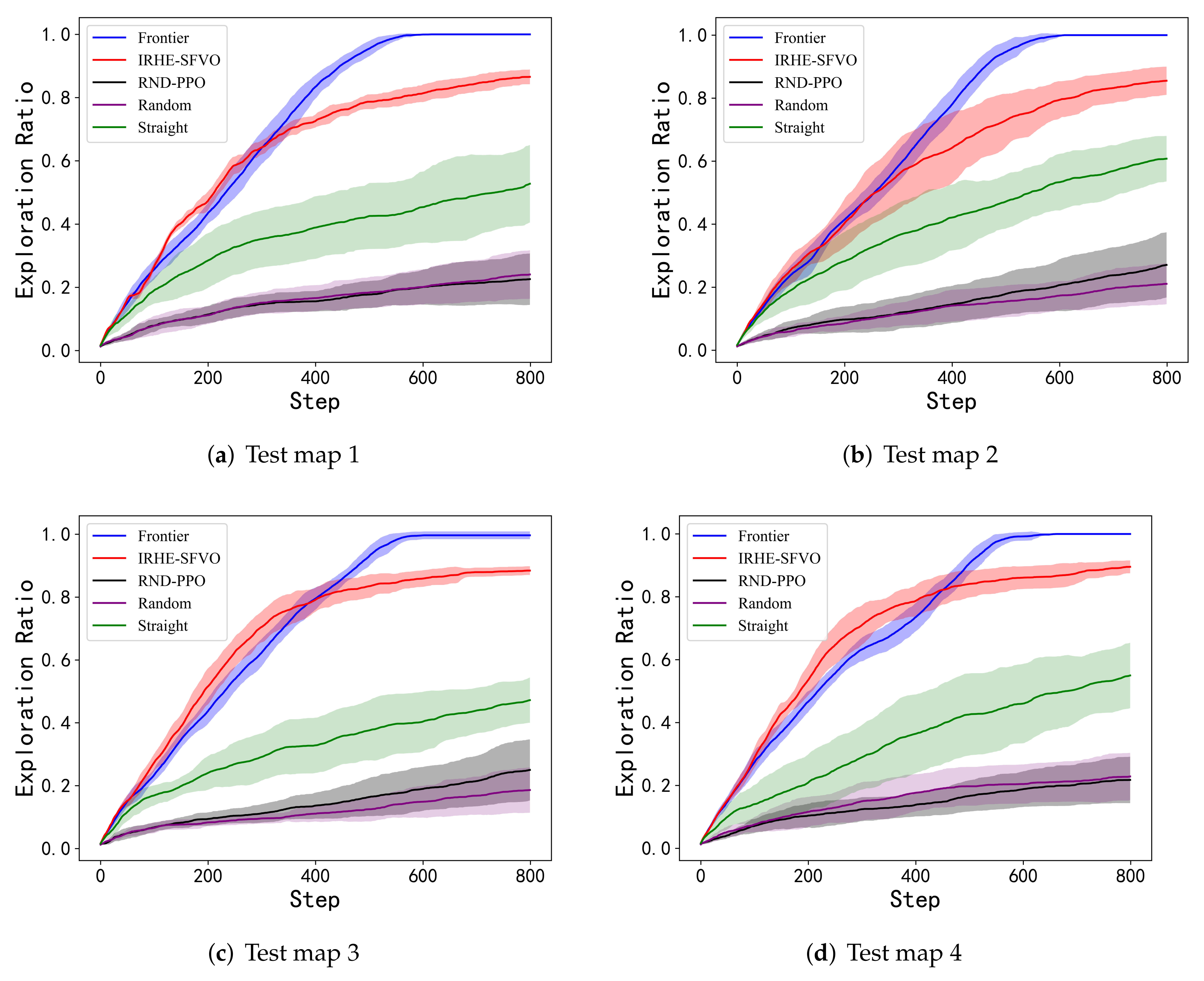
5. Empirical Evaluation
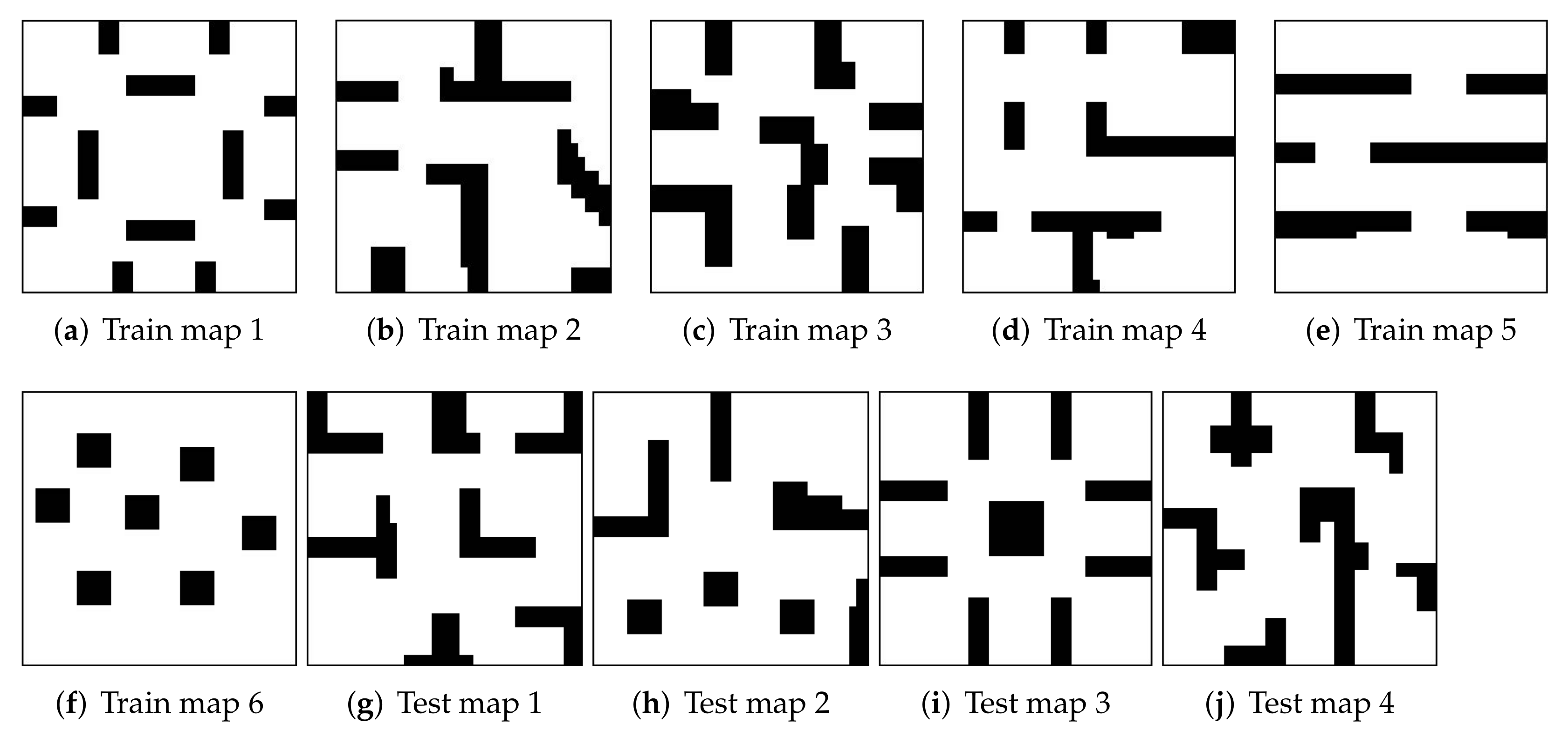
5.1. Experimental Setup
- RND-PPO: A popular IM based DRL approach. We adapt the source code from [3] to the problem settings in this paper. RND is a SOTA (state-of-the-art) DRL method based on prediction error, which has outstanding performance in Atari games. The network of PPO is similar to the proposed model, and an LSTM module [57] is added. The intrinsic discount factor and the other hyperparameters as the same as the proposed model. The target and prediction network consist of 3 fully connected layers and the learning rate of optimizing the prediction network . In addition, we design an external reward that is given a negative reward () when the agent collides with an obstacle or moves out of the map;
- Straight: This method is widely used in intelligent sweeping robots. It works by moving the agent in a straight line and performing a random turn when a collision will occur in next time step [58];
- Random: The agent takes a sequence of random actions to exploration.
- Frontier: A method which is based on geometric features to decided its next best frontier, drives the agent always goes to unknown spaces [59].
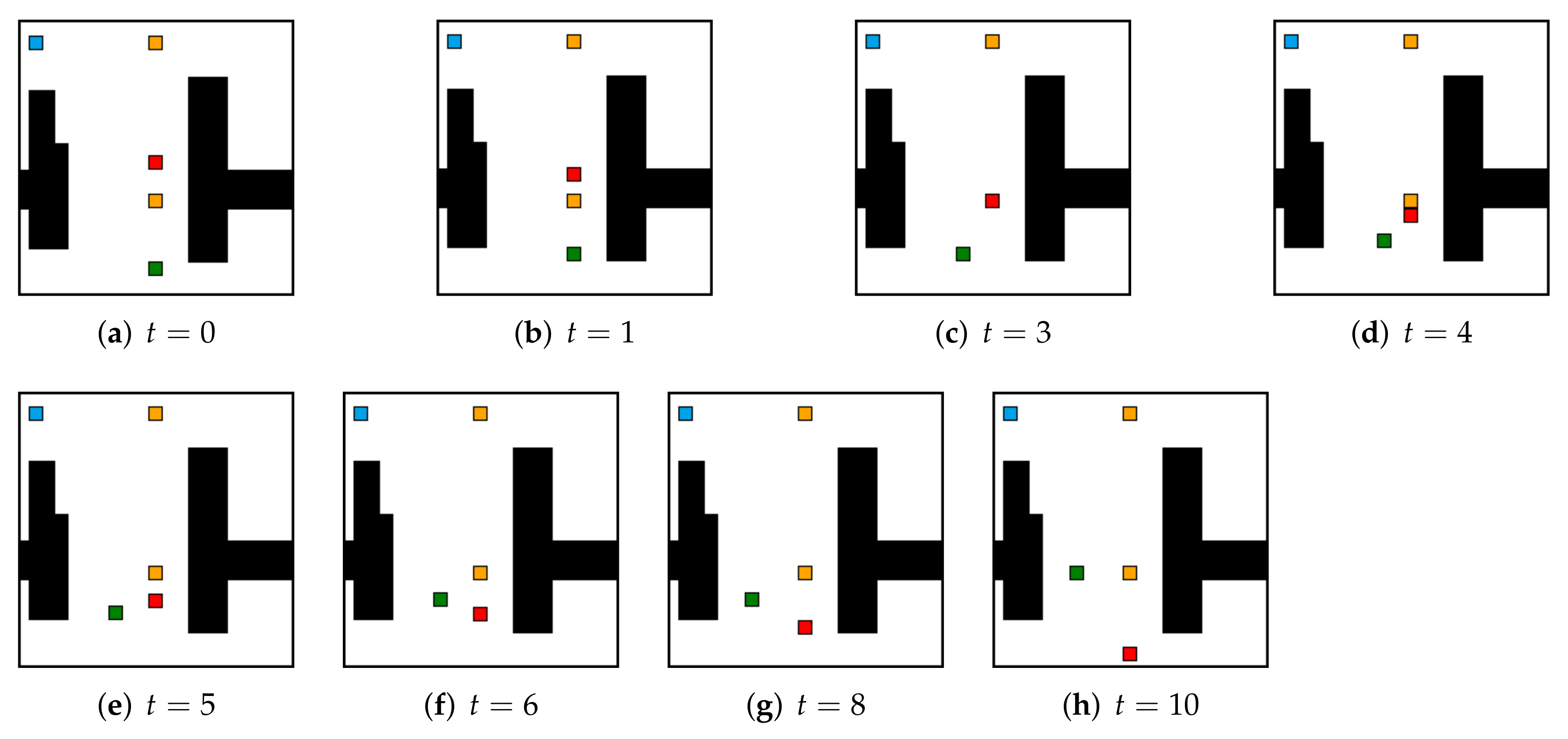
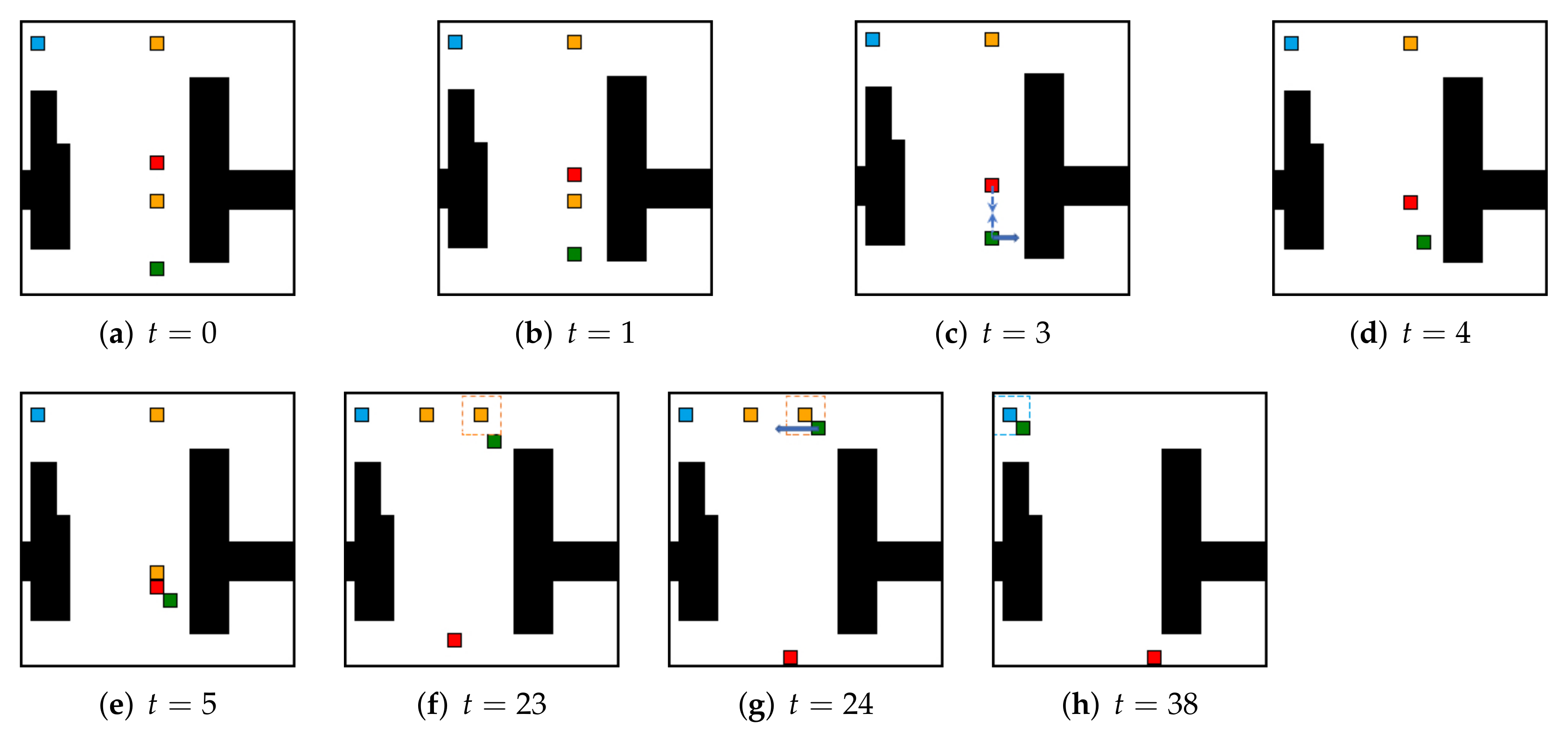
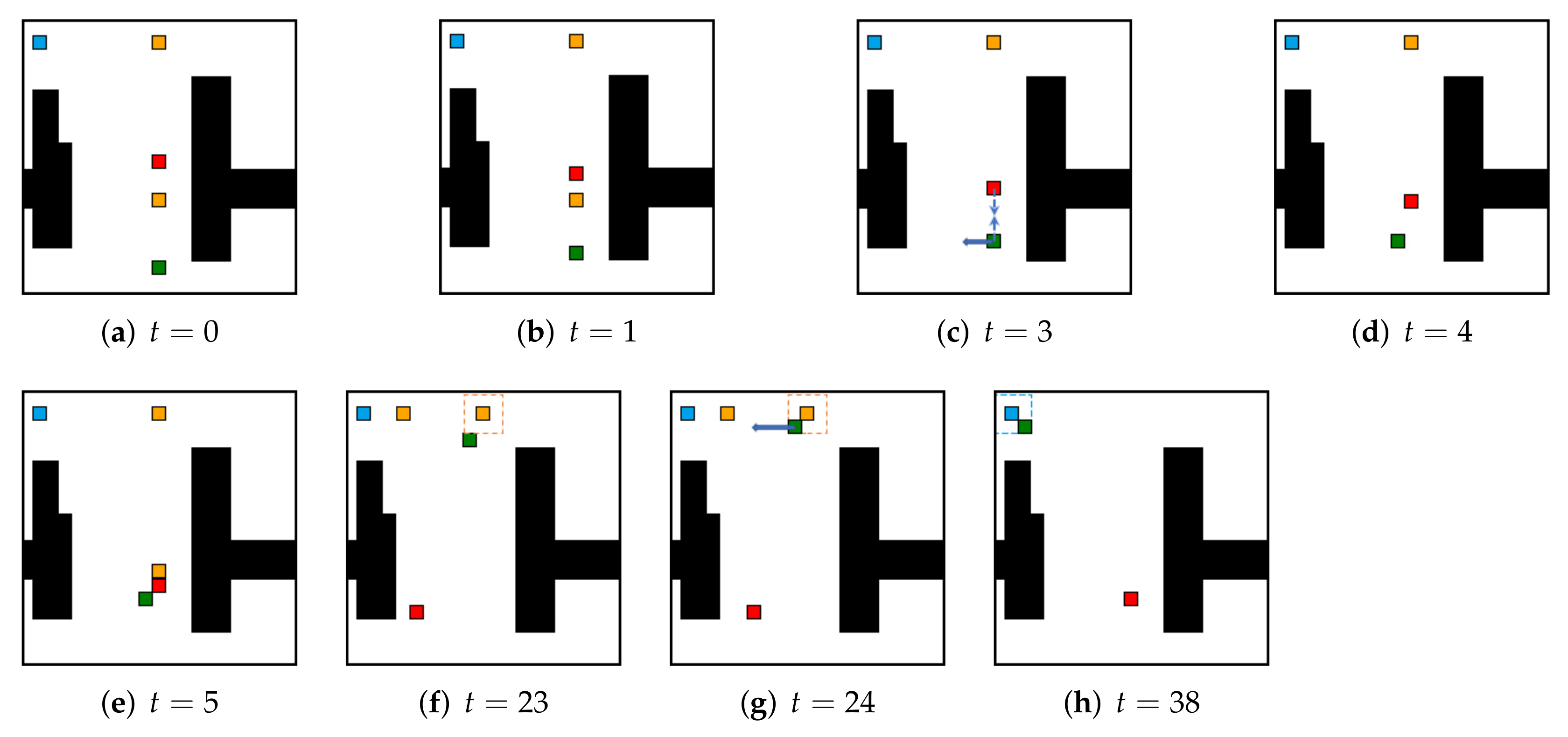
5.2. Local Real-Time Obstacle Avoidance
5.3. Comparison with Baselines on Spatial Exploration
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Yamauchi, B. A frontier-based approach for autonomous exploration. In Proceedings of the 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97. ‘Towards New Computational Principles for Robotics and Automation’, Monterey, CA, USA, 11–12 July 1997; pp. 146–151. [Google Scholar]
- Song, Y.; Hu, Y.; Zeng, J.; Hu, C.; Qin, L.; Yin, Q. Towards Efficient Exploration in Unknown Spaces: A Novel Hierarchical Approach Based on Intrinsic Rewards. In Proceedings of the 2021 6th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 15–17 July 2021; pp. 414–422. [Google Scholar]
- Burda, Y.; Edwards, H.; Storkey, A.; Klimov, O. Exploration by random network distillation. arXiv 2018, arXiv:1810.12894. [Google Scholar]
- Wirth, S.; Pellenz, J. Exploration transform: A stable exploring algorithm for robots in rescue environments. In Proceedings of the 2007 IEEE International Workshop on Safety, Security and Rescue Robotics, Rome, Italy, 27–29 September 2007; pp. 1–5. [Google Scholar]
- Mei, Y.; Lu, Y.H.; Lee, C.G.; Hu, Y.C. Energy-efficient mobile robot exploration. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, ICRA 2006, Orlando, FL, USA, 15–19 May 2006; pp. 505–511. [Google Scholar]
- Juliá, M.; Gil, A.; Reinoso, O. A comparison of path planning strategies for autonomous exploration and mapping of unknown environments. Auton. Robot. 2012, 33, 427–444. [Google Scholar] [CrossRef]
- Oßwald, S.; Bennewitz, M.; Burgard, W.; Stachniss, C. Speeding-up robot exploration by exploiting background information. IEEE Robot. Autom. Lett. 2016, 1, 716–723. [Google Scholar]
- Basilico, N.; Amigoni, F. Exploration strategies based on multi-criteria decision making for searching environments in rescue operations. Auton. Robot. 2011, 31, 401–417. [Google Scholar] [CrossRef]
- Niroui, F.; Sprenger, B.; Nejat, G. Robot exploration in unknown cluttered environments when dealing with uncertainty. In Proceedings of the 2017 IEEE International Symposium on Robotics and Intelligent Sensors (IRIS), Ottawa, ON, Canada, 5–7 October 2017; pp. 224–229. [Google Scholar]
- González-Banos, H.H.; Latombe, J.C. Navigation strategies for exploring indoor environments. Int. J. Robot. Res. 2002, 21, 829–848. [Google Scholar] [CrossRef]
- Whaite, P.; Ferrie, F.P. Autonomous exploration: Driven by uncertainty. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 193–205. [Google Scholar] [CrossRef] [Green Version]
- Julian, B.J.; Karaman, S.; Rus, D. On mutual information-based control of range sensing robots for mapping applications. Int. J. Robot. Res. 2014, 33, 1375–1392. [Google Scholar] [CrossRef]
- Tai, L.; Liu, M. A robot exploration strategy based on q-learning network. In Proceedings of the 2016 IEEE International Conference on Real-Time Computing and Robotics (RCAR), Angkor Wat, Cambodia, 6–10 June 2016; pp. 57–62. [Google Scholar]
- Zhang, J.; Tai, L.; Liu, M.; Boedecker, J.; Burgard, W. Neural slam: Learning to explore with external memory. arXiv 2017, arXiv:1706.09520. [Google Scholar]
- Zhu, D.; Li, T.; Ho, D.; Wang, C.; Meng, M.Q.H. Deep reinforcement learning supervised autonomous exploration in office environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7548–7555. [Google Scholar]
- Chen, T.; Gupta, S.; Gupta, A. Learning exploration policies for navigation. arXiv 2019, arXiv:1903.01959. [Google Scholar]
- Issa, R.B.; Rahman, M.S.; Das, M.; Barua, M.; Alam, M.G.R. Reinforcement Learning based Autonomous Vehicle for Exploration and Exploitation of Undiscovered Track. In Proceedings of the 2020 International Conference on Information Networking (ICOIN), Barcelona, Spain, 7–10 January 2020; pp. 276–281. [Google Scholar]
- Niroui, F.; Zhang, K.; Kashino, Z.; Nejat, G. Deep reinforcement learning robot for search and rescue applications: Exploration in unknown cluttered environments. IEEE Robot. Autom. Lett. 2019, 4, 610–617. [Google Scholar] [CrossRef]
- Shrestha, R.; Tian, F.P.; Feng, W.; Tan, P.; Vaughan, R. Learned map prediction for enhanced mobile robot exploration. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 1197–1204. [Google Scholar]
- Li, H.; Zhang, Q.; Zhao, D. Deep reinforcement learning-based automatic exploration for navigation in unknown environment. IEEE Trans. Neural Net. Learn. Syst. 2019, 31, 2064–2076. [Google Scholar] [CrossRef] [PubMed]
- Chaplot, D.S.; Gandhi, D.; Gupta, S.; Gupta, A.; Salakhutdinov, R. Learning to explore using active neural slam. arXiv 2020, arXiv:2004.05155. [Google Scholar]
- Barto, A.; Mirolli, M.; Baldassarre, G. Novelty or surprise? Front. Psychol. 2013, 4, 907. [Google Scholar] [CrossRef] [PubMed]
- Bellemare, M.; Srinivasan, S.; Ostrovski, G.; Schaul, T.; Saxton, D.; Munos, R. Unifying count-based exploration and intrinsic motivation. Adv. Neural Inf. Process. Syst. 2016, 29, 1471–1479. [Google Scholar]
- Ostrovski, G.; Bellemare, M.G.; Oord, A.; Munos, R. Count-based exploration with neural density models. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 2721–2730. [Google Scholar]
- Tang, H.; Houthooft, R.; Foote, D.; Stooke, A.; Chen, X.; Duan, Y.; Schulman, J.; De Turck, F.; Abbeel, P. A study of count-based exploration for deep reinforcement learning. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 1–18. [Google Scholar]
- Fu, J.; Co-Reyes, J.D.; Levine, S. Ex2: Exploration with exemplar models for deep reinforcement learning. arXiv 2017, arXiv:1703.01260. [Google Scholar]
- Choi, J.; Guo, Y.; Moczulski, M.; Oh, J.; Wu, N.; Norouzi, M.; Lee, H. Contingency-aware exploration in reinforcement learning. arXiv 2018, arXiv:1811.01483. [Google Scholar]
- Machado, M.C.; Bellemare, M.G.; Bowling, M. Count-based exploration with the successor representation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 5125–5133. [Google Scholar]
- Choshen, L.; Fox, L.; Loewenstein, Y. Dora the explorer: Directed outreaching reinforcement action-selection. arXiv 2018, arXiv:1804.04012. [Google Scholar]
- Shyam, P.; Jaśkowski, W.; Gomez, F. Model-based active exploration. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5779–5788. [Google Scholar]
- Pathak, D.; Gandhi, D.; Gupta, A. Self-supervised exploration via disagreement. In Proceedings of the International conference on Machine Learning, PMLR, Los Angeles, CA, USA, 9–15 June 2019; pp. 5062–5071. [Google Scholar]
- Ratzlaff, N.; Bai, Q.; Fuxin, L.; Xu, W. Implicit generative modeling for efficient exploration. In Proceedings of the International Conference on Machine Learning, PMLR, Vienne, Austria, 12–18 July 2020; pp. 7985–7995. [Google Scholar]
- Stadie, B.C.; Levine, S.; Abbeel, P. Incentivizing exploration in reinforcement learning with deep predictive models. arXiv 2015, arXiv:1507.00814. [Google Scholar]
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-driven exploration by self-supervised prediction. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–12 August 2017; pp. 2778–2787. [Google Scholar]
- Kim, H.; Kim, J.; Jeong, Y.; Levine, S.; Song, H.O. Emi: Exploration with mutual information. arXiv 2018, arXiv:1810.01176. [Google Scholar]
- Ermolov, A.; Sebe, N. Latent World Models For Intrinsically Motivated Exploration. arXiv 2020, arXiv:2010.02302. [Google Scholar]
- Lopes, M.; Lang, T.; Toussaint, M.; Oudeyer, P.Y. Exploration in Model-Based Reinforcement Learning by Empirically Estimating Learning Progress; Neural Information Processing Systems (NIPS): Lake Tahoe, NV, USA, 2012. [Google Scholar]
- Gregor, K.; Rezende, D.J.; Wierstra, D. Variational intrinsic control. arXiv 2016, arXiv:1611.07507. [Google Scholar]
- Houthooft, R.; Chen, X.; Duan, Y.; Schulman, J.; De Turck, F.; Abbeel, P. Vime: Variational information maximizing exploration. arXiv 2016, arXiv:1605.09674. [Google Scholar]
- Oudeyer, P.Y.; Kaplan, F. What is intrinsic motivation? A typology of computational approaches. Front. Neurorobotics 2009, 1, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Badia, A.P.; Piot, B.; Kapturowski, S.; Sprechmann, P.; Vitvitskyi, A.; Guo, Z.D.; Blundell, C. Agent57: Outperforming the atari human benchmark. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 12–18 July 2020; pp. 507–517. [Google Scholar]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. In Autonomous Robot Vehicles; Springer: Berlin/Heidelberg, Germany, 1986; pp. 396–404. [Google Scholar]
- Fox, D.; Burgard, W.; Thrun, S. The dynamic window approach to collision avoidance. IEEE Robot. Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef] [Green Version]
- Rezaee, H.; Abdollahi, F. A decentralized cooperative control scheme with obstacle avoidance for a team of mobile robots. IEEE Trans. Ind. Electron. 2013, 61, 347–354. [Google Scholar] [CrossRef]
- Ali, F.; Kim, E.K.; Kim, Y.G. Type-2 fuzzy ontology-based semantic knowledge for collision avoidance of autonomous underwater vehicles. Inf. Sci. 2015, 295, 441–464. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhang, W. Concise deep reinforcement learning obstacle avoidance for underactuated unmanned marine vessels. Neurocomputing 2018, 272, 63–73. [Google Scholar] [CrossRef]
- Celsi, L.R.; Celsi, M.R. On Edge-Lazy RRT Collision Checking in Sampling-Based Motion Planning. Int. J. Robot. Autom. 2021, 36. [Google Scholar] [CrossRef]
- Fiorini, P.; Shiller, Z. Motion planning in dynamic environments using velocity obstacles. Int. J. Robot. Res. 1998, 17, 760–772. [Google Scholar] [CrossRef]
- Van den Berg, J.; Lin, M.; Manocha, D. Reciprocal velocity obstacles for real-time multi-agent navigation. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 1928–1935. [Google Scholar]
- Abe, Y.; Yoshiki, M. Collision avoidance method for multiple autonomous mobile agents by implicit cooperation. In Proceedings of the 2001 IEEE/RSJ International Conference on Intelligent Robots and Systems, Expanding the Societal Role of Robotics in the the Next Millennium (Cat. No. 01CH37180), IEEE, Maui, HI, USA, 29 October–3 November 2001; pp. 1207–1212. [Google Scholar]
- Guy, S.J.; Chhugani, J.; Kim, C.; Satish, N.; Lin, M.; Manocha, D.; Dubey, P. Clearpath: Highly parallel collision avoidance for multi-agent simulation. In Proceedings of the 2009 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, New Orleans, LA, USA, 1–2 August 2009; pp. 177–187. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Conti, E.; Madhavan, V.; Such, F.P.; Lehman, J.; Stanley, K.O.; Clune, J. Improving exploration in evolution strategies for deep reinforcement learning via a population of novelty-seeking agents. arXiv 2017, arXiv:1712.06560. [Google Scholar]
- Celsi, L.R.; Di Giorgio, A.; Gambuti, R.; Tortorelli, A.; Priscoli, F.D. On the many-to-many carpooling problem in the context of multi-modal trip planning. In Proceedings of the 2017 25th Mediterranean Conference on Control and Automation (MED), Valletta, Malta, 3–6 July 2017; pp. 303–309. [Google Scholar]
- Kim, M.; Oh, J.H. Study on optimal velocity selection using velocity obstacle (OVVO) in dynamic and crowded environment. Auton. Robot. 2016, 40, 1459–1470. [Google Scholar] [CrossRef]
- Hu, Y.; Subagdja, B.; Tan, A.H.; Yin, Q. Vision-Based Topological Mapping and Navigation with Self-Organizing Neural Networks. IEEE Trans. Neural Net. Learn. Syst. 2021. Available online: https://ieeexplore.ieee.org/document/9459468 (accessed on 20 December 2021). [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9339–9347. [Google Scholar]
- Mobarhani, A.; Nazari, S.; Tamjidi, A.H.; Taghirad, H.D. Histogram based frontier exploration. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1128–1133. [Google Scholar]
- Baldassarre, G. What are intrinsic motivations? A biological perspective. In Proceedings of the 2011 IEEE International Conference on Development and Learning (ICDL), Frankfurt am Main, Germany, 24–27 August 2011; Volume 2, pp. 1–8. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| The weight/height of grid maps (M) | 40 |
| Number of moving obstacles (i) | 10 |
| Observation range of the agent (n) | 5 |
| Exploration range of the agent (m) | 2 |
| Physical radius of the agent () | 0.5 |
| Physical radius of the moving obstacles () | 0.5 |
| The maximum of finite time in SFVO () | 2 |
| The reduction of finite time in SFVO () | 1 |
| Total steps the agent moves (T) | 800 |
| Hyperparameter | Value |
|---|---|
| Number of parallel environment | 6 |
| Number of minibatches | 12 |
| Number of episodes | 100,000 |
| Number of optimization epochs | 4 |
| Learning rate | 0.0001 |
| Optimization algorithm | Adam |
| Entropy coefficient | 0.001 |
| Value loss oefficient | 0.5 |
| 0.95 | |
| 0.99 | |
| /Clip range | 0.1/ |
| Max norm of gradients | 0.5 |
| Layer | Parameters |
|---|---|
| Embedding | Size of embedding vector |
| Conv1 | Output, Kernel, Stride, Padding |
| Conv2 | Output, Kernel, Stride, Padding |
| Conv3 | Output, Kernel, Stride, Padding |
| MaxPool | Kernel size |
| Linear1 | Output size |
| Linear2 | Output size |
| IRHE-SFVO | RND-PPO | Random | Straight | Fronteir | |
|---|---|---|---|---|---|
| Test map 1 | 0.8656 | 0.2258 | 0.2406 | 0.5276 | 0.9943 (4.53) |
| Test map 2 | 0.8552 | 0.2707 | 0.2107 | 0.6078 | 0.9992 (3.06) |
| Test map 3 | 0.8842 | 0.2501 | 0.1861 | 0.4721 | 0.9966 (5.13) |
| Test map 4 | 0.8953 | 0.2177 | 0.2287 | 0.5498 | 0.9997 (4.13) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Song, Y.; Jiao, P.; Hu, Y. A Hybrid and Hierarchical Approach for Spatial Exploration in Dynamic Environments. Electronics 2022, 11, 574. https://doi.org/10.3390/electronics11040574
Zhang Q, Song Y, Jiao P, Hu Y. A Hybrid and Hierarchical Approach for Spatial Exploration in Dynamic Environments. Electronics. 2022; 11(4):574. https://doi.org/10.3390/electronics11040574
Chicago/Turabian StyleZhang, Qi, Yukai Song, Peng Jiao, and Yue Hu. 2022. "A Hybrid and Hierarchical Approach for Spatial Exploration in Dynamic Environments" Electronics 11, no. 4: 574. https://doi.org/10.3390/electronics11040574
APA StyleZhang, Q., Song, Y., Jiao, P., & Hu, Y. (2022). A Hybrid and Hierarchical Approach for Spatial Exploration in Dynamic Environments. Electronics, 11(4), 574. https://doi.org/10.3390/electronics11040574