
Joint Optimization of Energy Efficiency and User Outage Using Multi-Agent Reinforcement Learning in Ultra-Dense Small Cell Networks



Abstract
:1. Introduction
1.1. Motivation and Related Works
1.2. Paper Organization
2. System Model
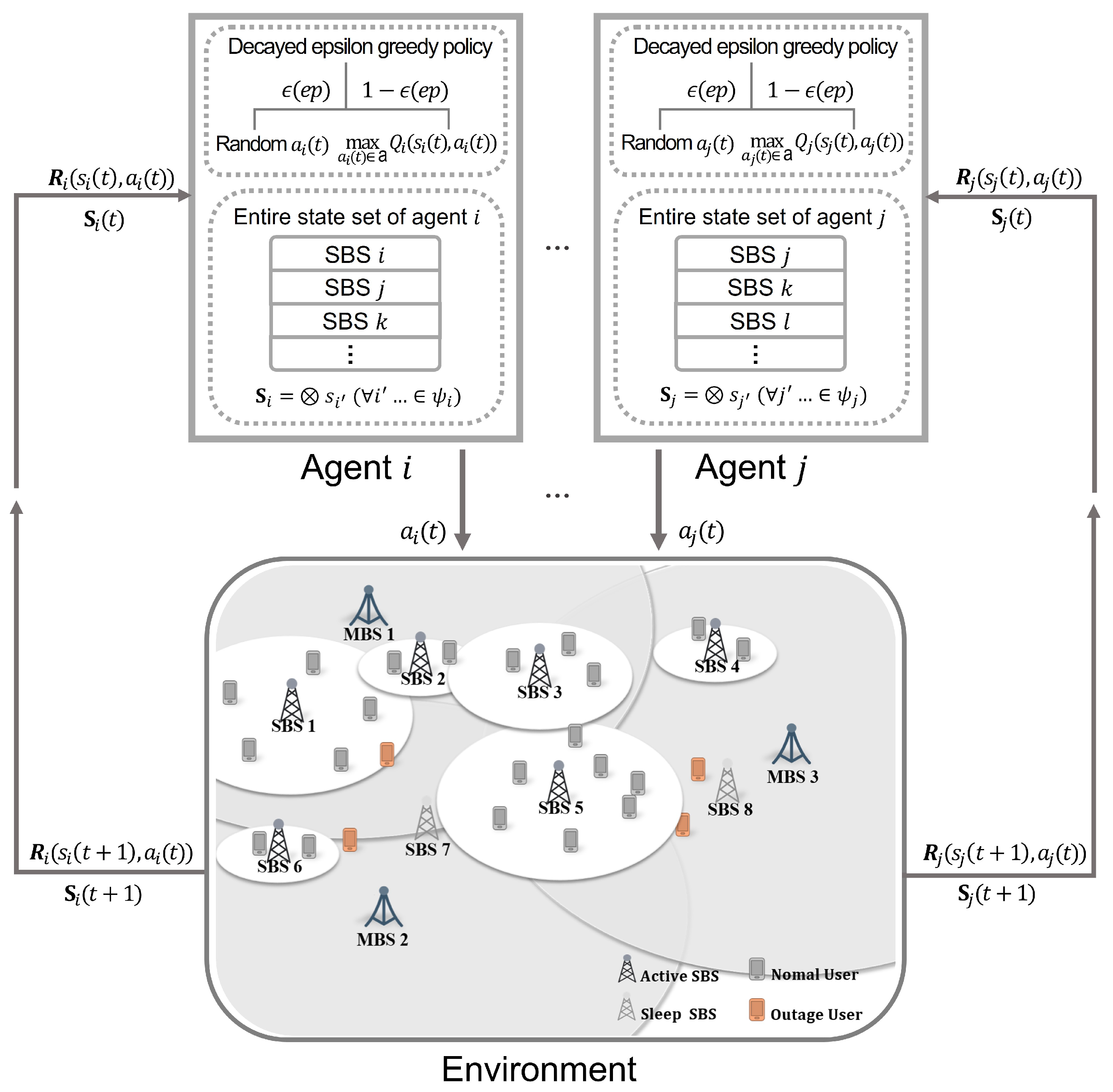
3. Joint Optimization of EE and User Outage Based on Multi-Agent Distributed Reinforcement Learning in Ultra-Dense Small Cell Networks
3.1. MAQ-OCB with SBS Collaboration
3.2. MAQ-OCB without SBS Collaboration
4. Simulation Results and Discussions
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| 6G | Sixth-generation |
| BS | Base station |
| C-OCB | Centralized Q-learning based outage-aware cell breathing |
| DNN | Deep neural network |
| DQL | Deep Q-learning |
| DQN | Deep Q-network |
| EE | Energy efficiency |
| IIR | Infinite impulse response |
| IoT | Internet of Things |
| KPI | Key performance indicator |
| MAQ-OCB | Multi-agent Q-learning based outage-aware cell breathing |
| MAQ-OCB w/ SC | MAQ-OCB with SBS collaboration |
| MAQ-OCB w/o SC | MAQ-OCB without SBS collaboration |
| MBS | Macro cell BS |
| MIMO | Multiple-input multiple-output |
| NB-IoT | Narrow-band Internet of Things |
| NOMA | Non-orthogonal multiple access |
| No TPC | No transmission power control |
| RSRP | Reference signal received power |
| SBS | Small cell BS |
| SE | Spectral efficiency |
| SEE | Spectral and energy efficiency |
| SINR | Signal-to-interference-plus-noise ratio |
| XR | Extended reality |
References
- Samsung Research. 6G: The Next Hyper-Connected Experience for All, White Paper. July 2020.
- Tariq, F.; Khandaker, M.R.A.; Wong, K.-K.; Imran, M.A.; Bennis, M.; Debbah, M. A Speculative Study on 6G. IEEE Wirel. Commun. 2020, 27, 118–125. [Google Scholar] [CrossRef]
- Yu, H.; Lee, H.; Jeon, H. What is 5G? Emerging 5G Mobile Services and Network Requirements. Sustainability 2017, 9, 1848. [Google Scholar] [CrossRef] [Green Version]
- Slalmi, A.; Chaibi, H.; Chehri, A.; Saadane, R.; Jeon, G. Toward 6G: Understanding Network Requirements and Key Performance Indicators. Wiley Trans. Emerg. Telecommun. Technol. 2020, 32, e4201. [Google Scholar] [CrossRef]
- Huang, T.; Yang, W.; Wu, J.; Ma, J.; Zhang, X.; Zhang, D. A Survey on Green 6G Network: Architecture and Technologies. IEEE Access 2019, 7, 175758–175768. [Google Scholar] [CrossRef]
- Lee, S.; Yu, H.; Lee, H. Multi-Agent Q-Learning Based Multi-UAV Wireless Networks for Maximizing Energy Efficiency: Deployment and Power Control Strategy Design. IEEE Internet Things J. 2021; early access. [Google Scholar] [CrossRef]
- Su, L.; Yang, C.; Chih-Lin, I. Energy Spectr. Effic. Freq. Reuse Ultra Dense Networks. IEEE Tran. Wirel. Commun. 2016, 15, 5384–5398. [Google Scholar]
- Lee, W.; Jung, B.C.; Lee, H. DeCoNet: Density Clust.-Based Base Stn. Control Energy-Effic. Cell. IoT Networks. IEEE Access 2020, 8, 120881–120891. [Google Scholar] [CrossRef]
- Çelebi, H.; Yapıcı, Y.; Güvenç, İ.; Schulzrinne, H. Load-Based On/Off Scheduling for Energy-Efficient Delay-Tolerant 5G Networks. IEEE Tran. Green Commun. Netw. 2019, 3, 955–970. [Google Scholar] [CrossRef] [Green Version]
- Shi, D.; Tian, F.; Wu, S. Energy Efficiency Optimization in Heterogeneous Networks Based on Deep Reinforcement Learning. IEEE Inter. Conf. Commun. Work. 2020, 1–6. [Google Scholar] [CrossRef]
- Spantideas, S.T.; Giannopoulos, A.E.; Kapsalis, N.C.; Kalafatelis, A.; Capsalis, C.N.; Trakadas, P. Joint Energy-efficient and Throughput-sufficient Transmissions in 5G Cells with Deep Q-Learning. In Proceedings of the 2021 IEEE International Mediterranean Conference on Communications and Networking (MeditCom), Athens, Greece, 7–10 September 2021; pp. 265–270. [Google Scholar]
- Ye, J.; Zhang, Y.-J.A. DRAG: Deep Reinforcement Learning Based Base Station Activation in Heterogeneous Networks. IEEE Tran. Mob. Comp. 2020, 19, 2076–2087. [Google Scholar] [CrossRef] [Green Version]
- Giannopoulos, A.; Spantideas, S.; Kapsalis, N.; Karkazis, P.; Trakadas, P. Deep Reinforcement Learning for Energy-Efficient Multi-Channel Transmissions in 5G Cognitive HetNets: Centralized, Decentralized and Transfer Learning Based Solutions. IEEE Access 2021, 9, 129358–129374. [Google Scholar] [CrossRef]
- Iqbal, A.; Tham, M.-L.; Chang, Y.C. Double Deep Q-Network-Based Energy-Efficient Resource Allocation in Cloud Radio Access Network. IEEE Access 2021, 9, 20440–20449. [Google Scholar] [CrossRef]
- Huang, H.; Yang, Y.; Ding, Z.; Wang, H.; Sari, H.; Adachi, F. Deep Learning-Based Sum Data Rate and Energy Efficiency Optimization for MIMO-NOMA Systems. IEEE Trans. Wirel. Commun. 2020, 19, 5373–5388. [Google Scholar] [CrossRef]
- Guo, Y.; Xiang, M. Multi-Agent Reinforcement Learning Based Energy Efficiency Optimization in NB-IoT Networks. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Tesema, F.B.; Awada, A.; Viering, I.; Simsek, M.; Fettweis, G.P. Evaluation of Adaptive Active Set Management for Multi-Connectivity in Intra-Frequency 5G Networks. IEEE Wirel. Commun. Netw. Conf. 2016, 1–6. Available online: https://cdn.codeground.org/nsr/downloads/researchareas/20201201_6G_Vision_web.pdf (accessed on 10 January 2022). [CrossRef]
- Srinivasan, M.; Kotagi, V.J.; Murthy, C.S.R. A Q-Learning Framework for User QoE Enhanced Self-Organizing Spectrally Efficient Network Using a Novel Inter-Operator Proximal Spectrum Sharing. IEEE Sel. Areas Commun. 2016, 34, 2887–2901. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 3 | |||
| 20 ∼ 60 | 150 m ∼ 450 m | ||
| W | 10 MHz | ||
| dBm | W | ||
| W | 3 | ||
| 0.99 | 330 | ||
| W | 0 dB |
| Algorithm | EE-Optimal, Reward-Optimal | C-OCB | MAQ-OCB w/o SC | MAQ-OCB w/ SC |
|---|---|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, E.; Jung, B.C.; Park, C.Y.; Lee, H. Joint Optimization of Energy Efficiency and User Outage Using Multi-Agent Reinforcement Learning in Ultra-Dense Small Cell Networks. Electronics 2022, 11, 599. https://doi.org/10.3390/electronics11040599
Kim E, Jung BC, Park CY, Lee H. Joint Optimization of Energy Efficiency and User Outage Using Multi-Agent Reinforcement Learning in Ultra-Dense Small Cell Networks. Electronics. 2022; 11(4):599. https://doi.org/10.3390/electronics11040599
Chicago/Turabian StyleKim, Eunjin, Bang Chul Jung, Chan Yi Park, and Howon Lee. 2022. "Joint Optimization of Energy Efficiency and User Outage Using Multi-Agent Reinforcement Learning in Ultra-Dense Small Cell Networks" Electronics 11, no. 4: 599. https://doi.org/10.3390/electronics11040599
APA StyleKim, E., Jung, B. C., Park, C. Y., & Lee, H. (2022). Joint Optimization of Energy Efficiency and User Outage Using Multi-Agent Reinforcement Learning in Ultra-Dense Small Cell Networks. Electronics, 11(4), 599. https://doi.org/10.3390/electronics11040599