
Solpen: An Accurate 6-DOF Positioning Tool for Vision-Guided Robotics



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
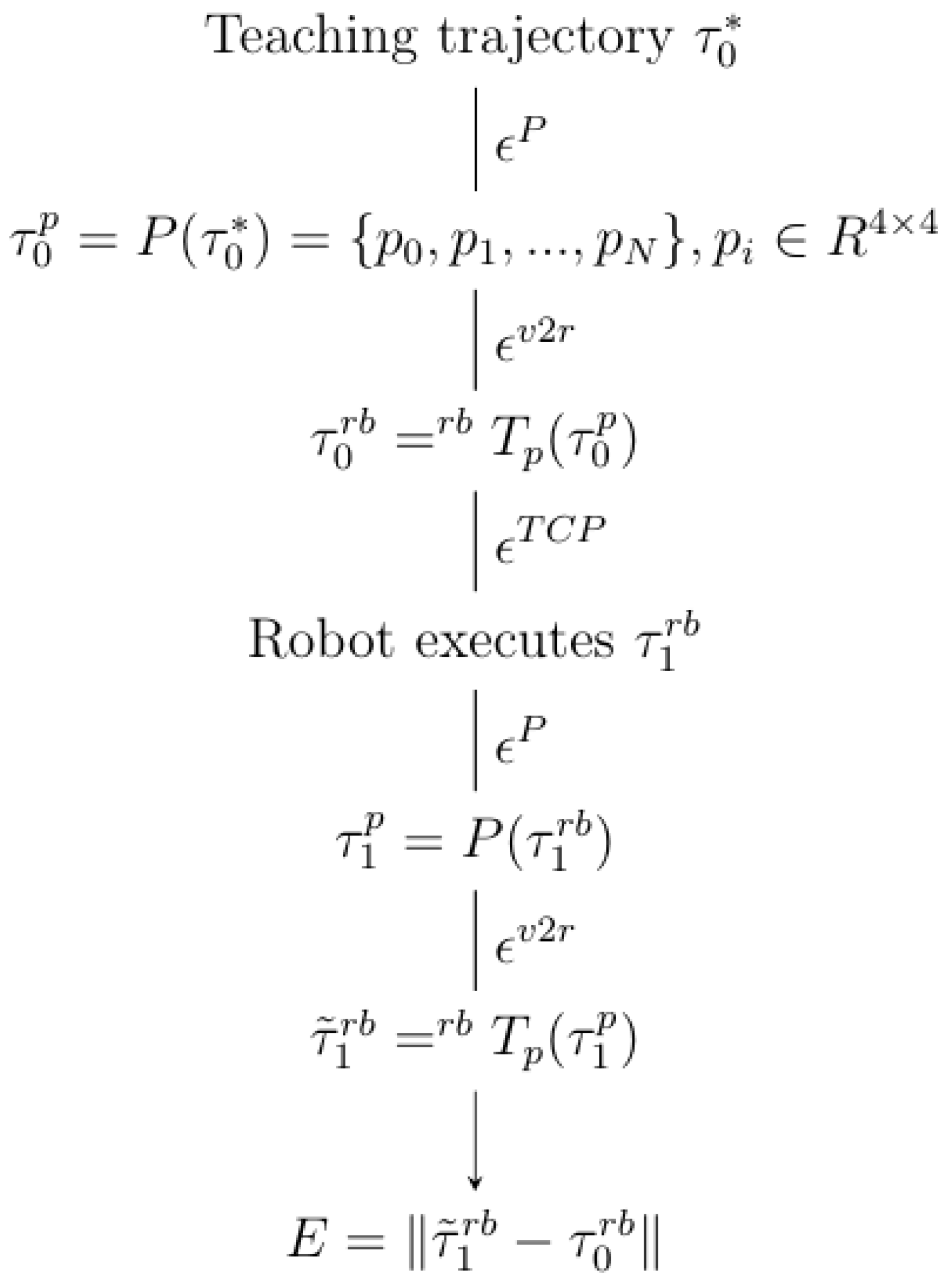{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
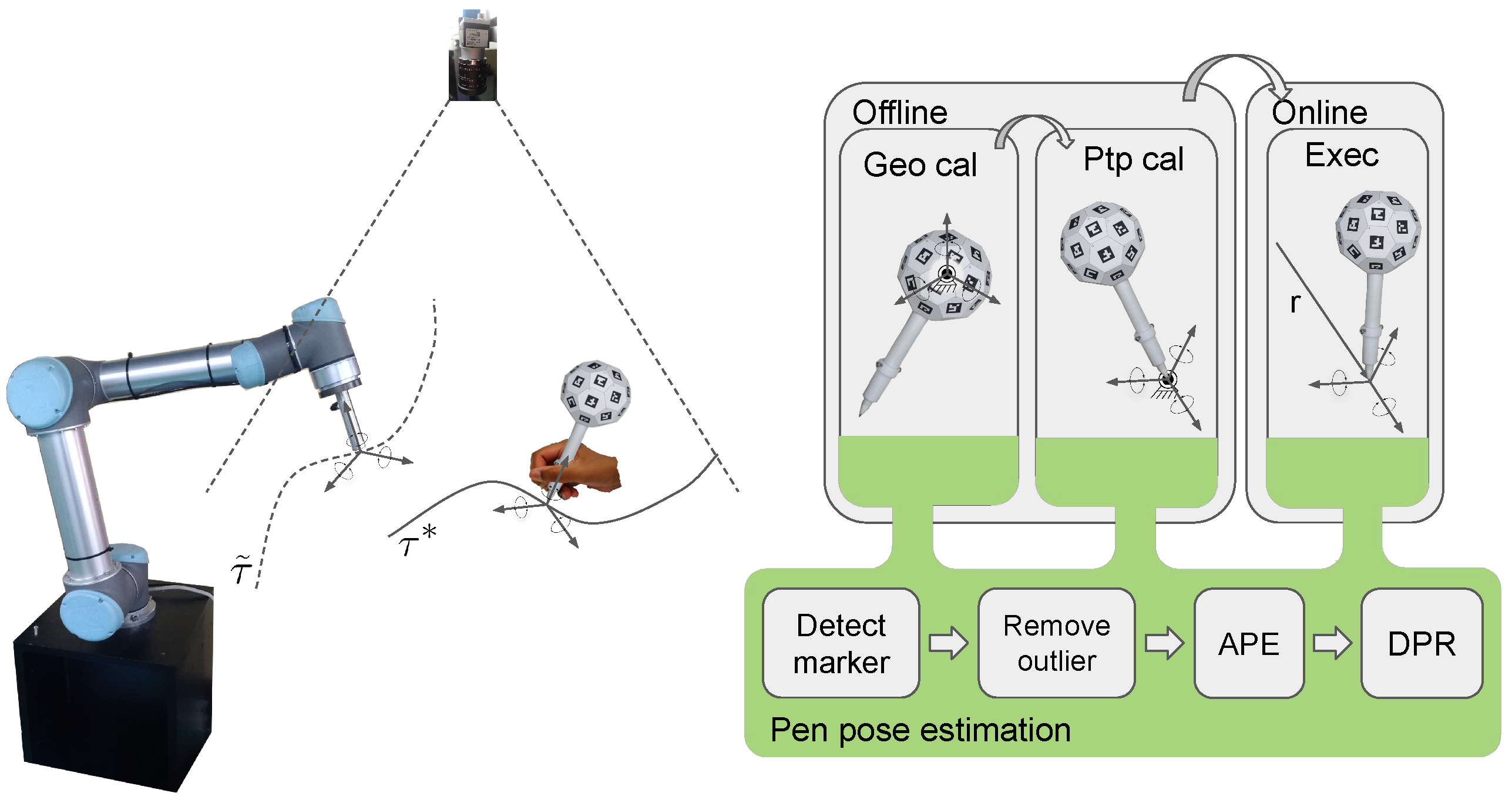
3. System Description
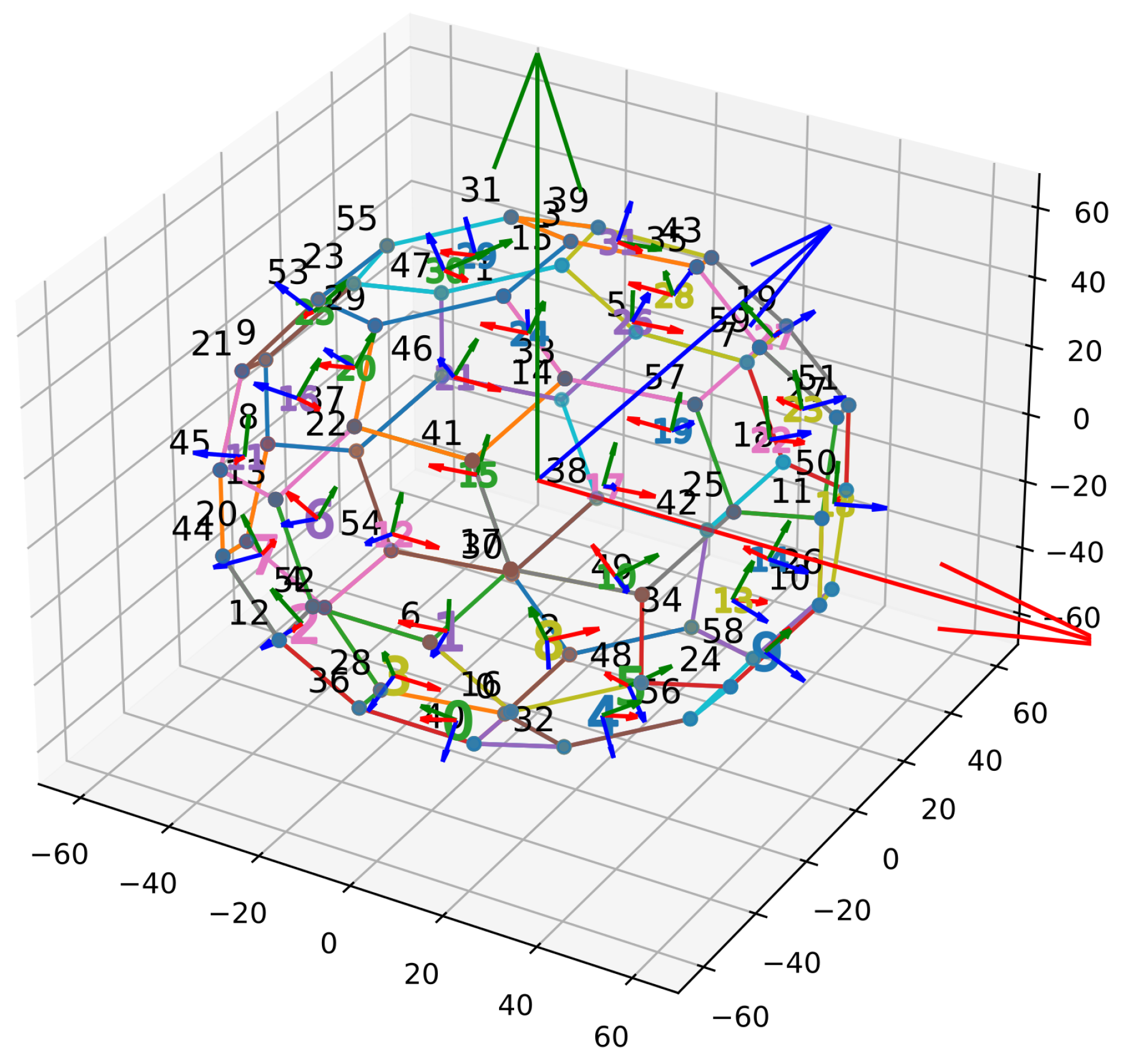
3.1. Bundle Adjustment
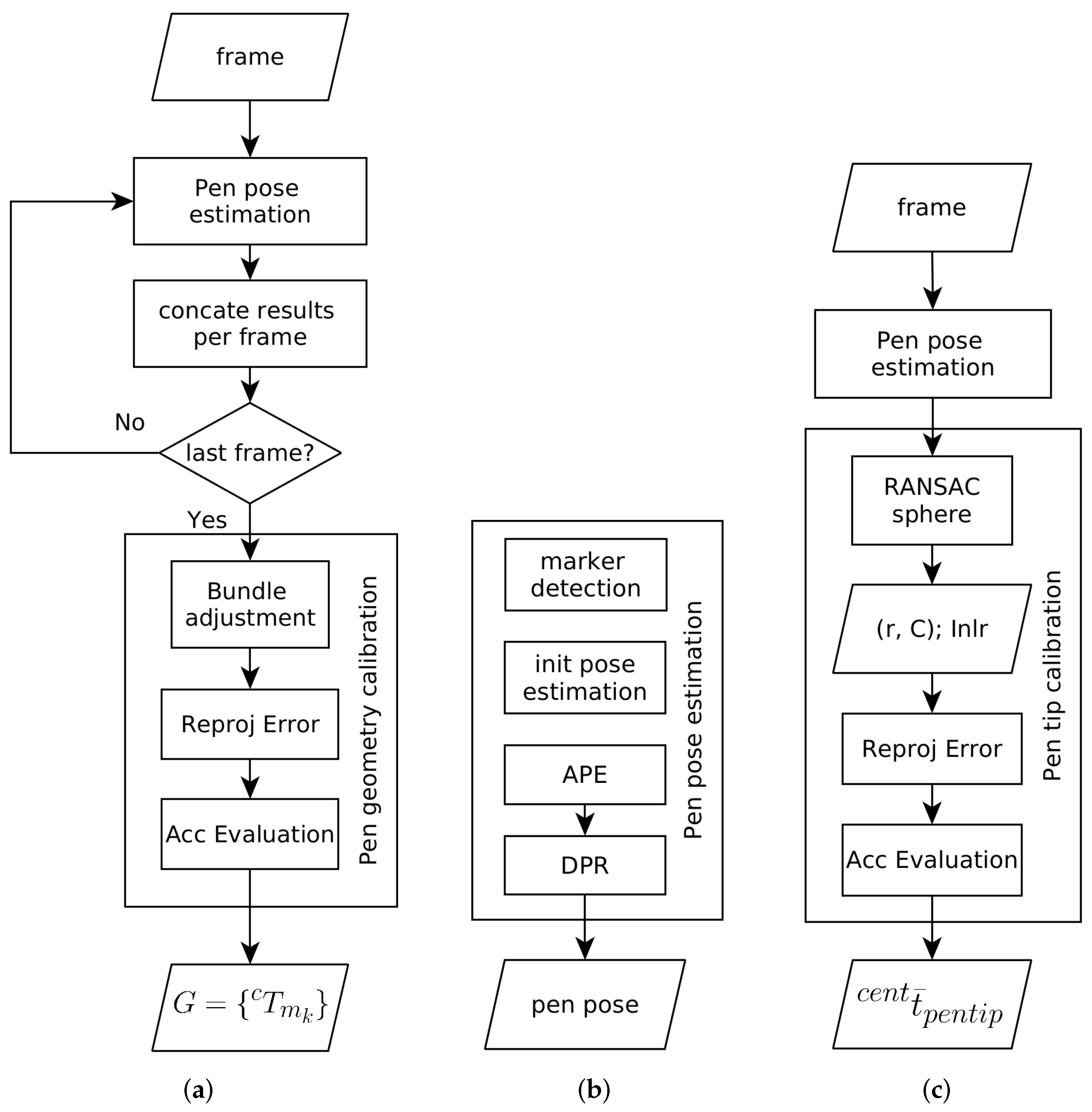
3.2. Workflow Overview
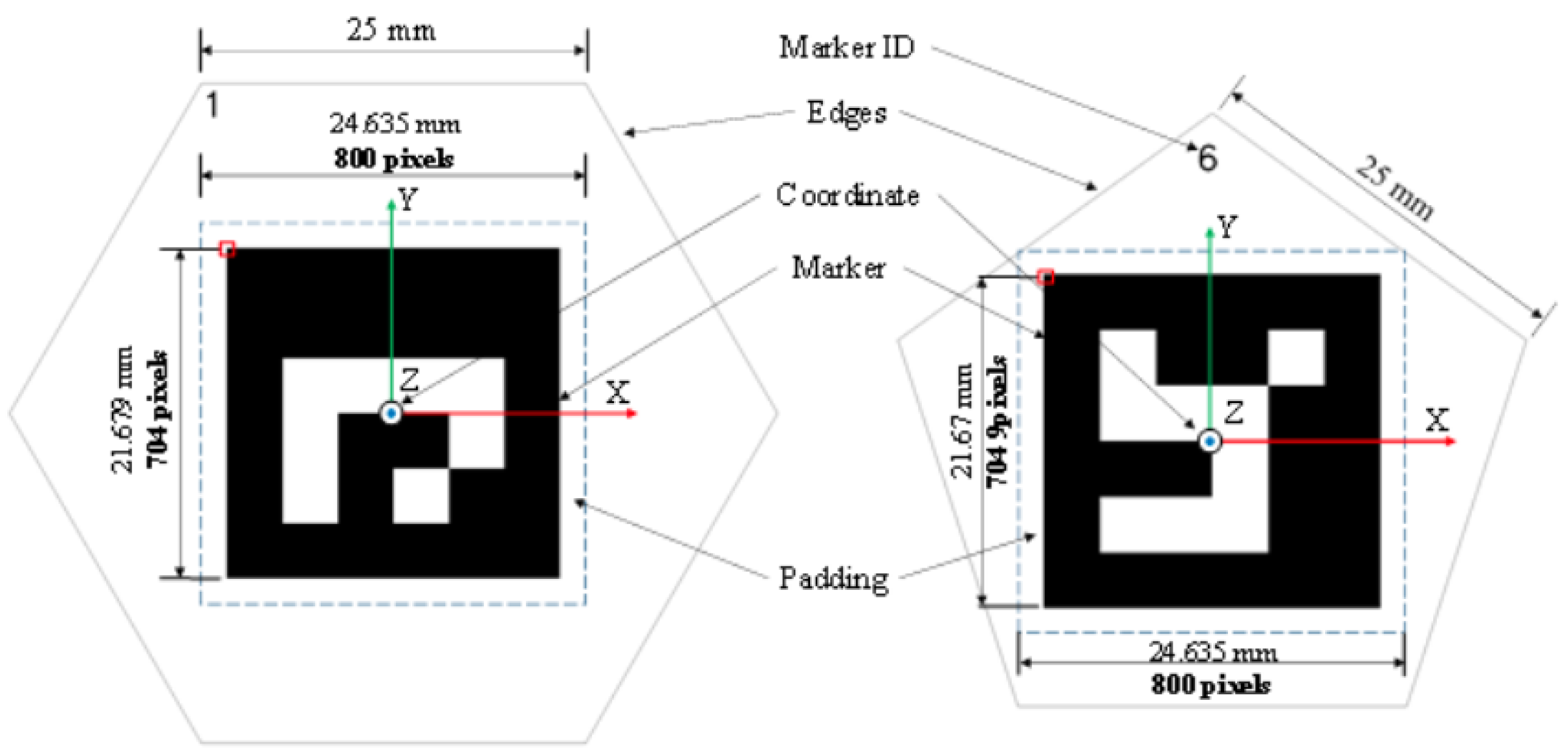
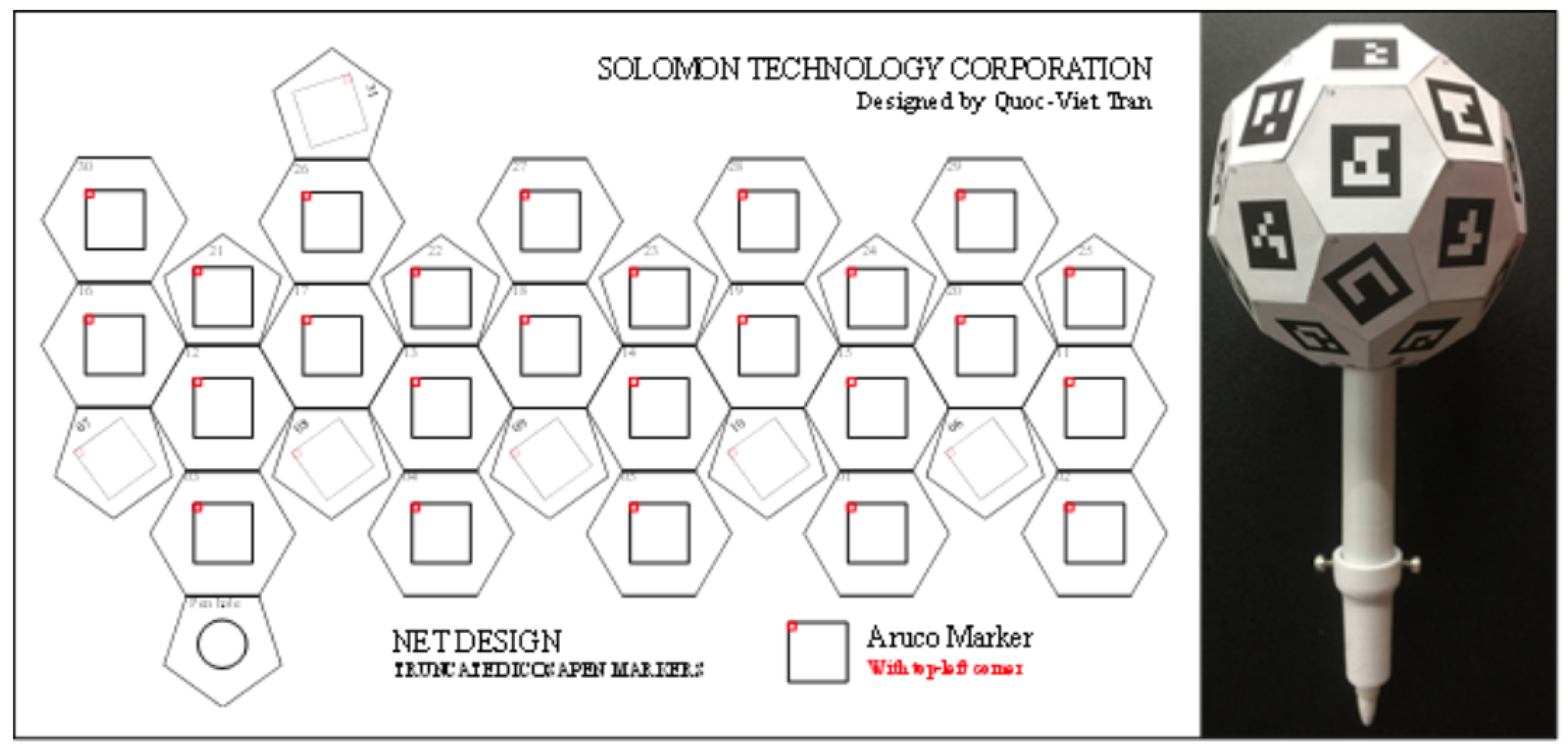
3.3. Icosahedron Design
3.4. Define Aruco Marker Poses in Penta and Hexa-Polygon
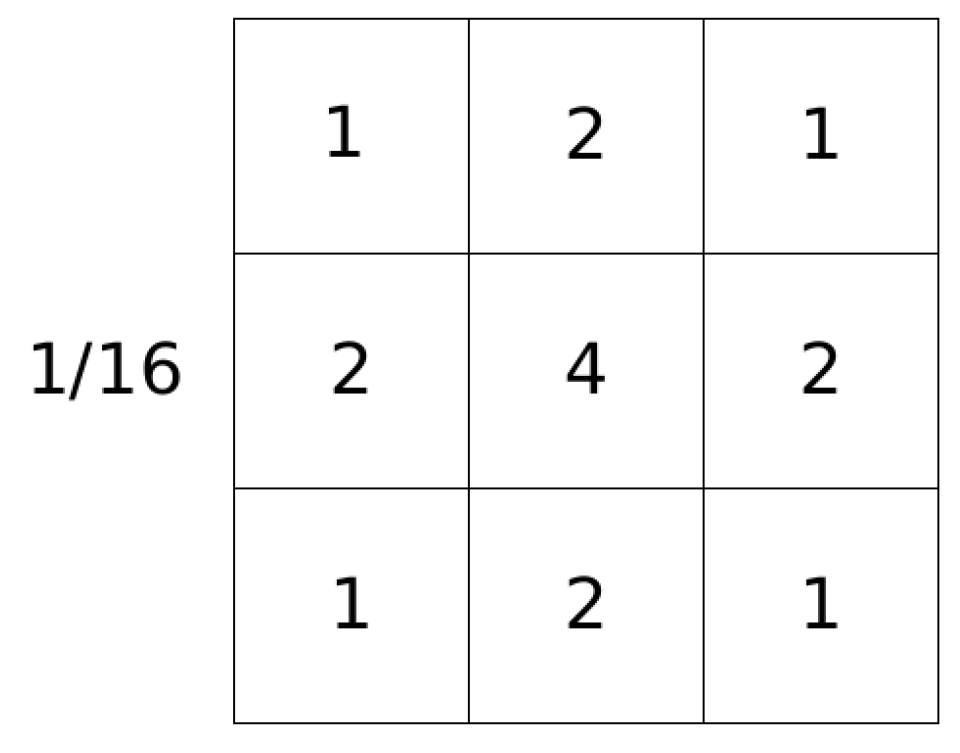
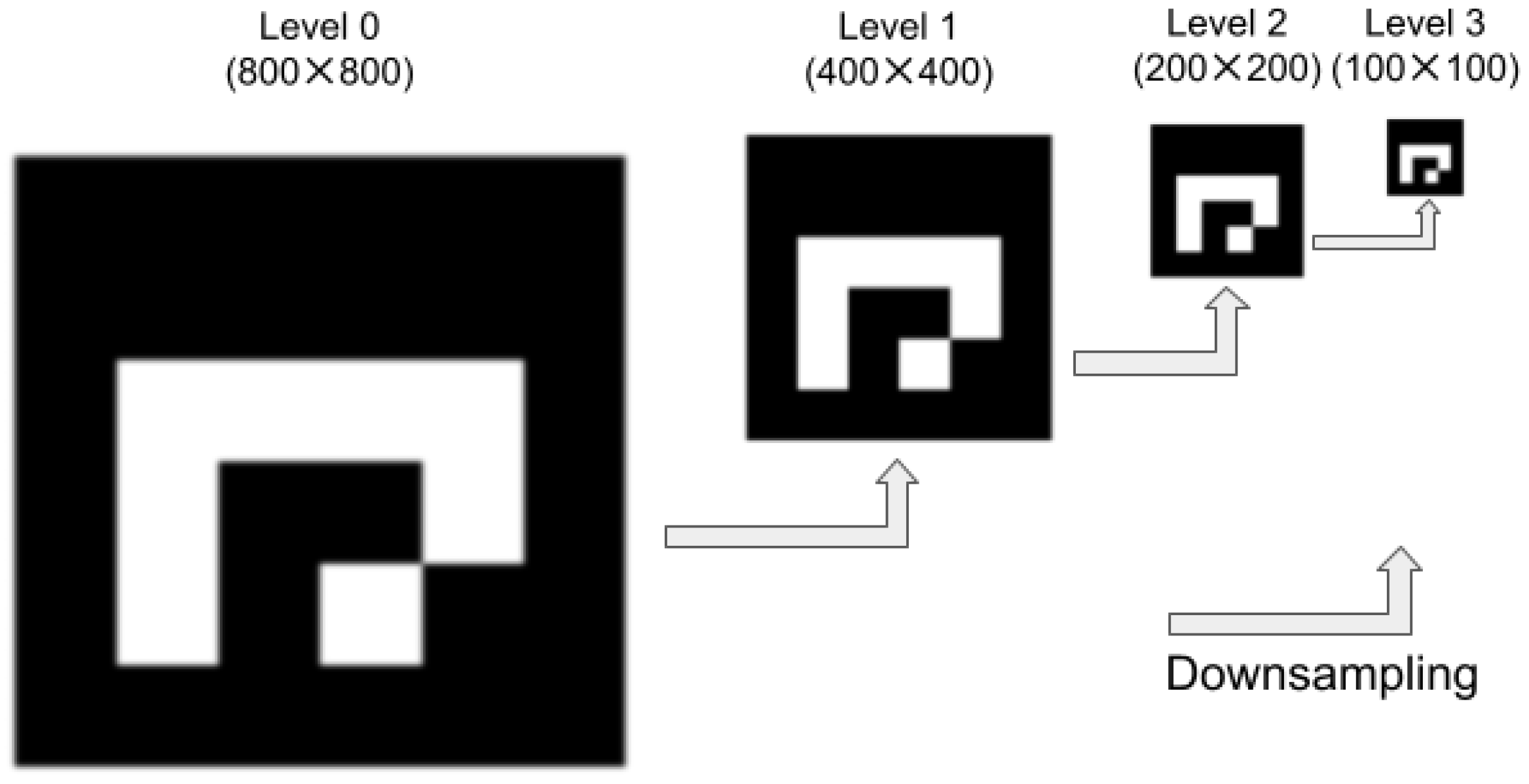
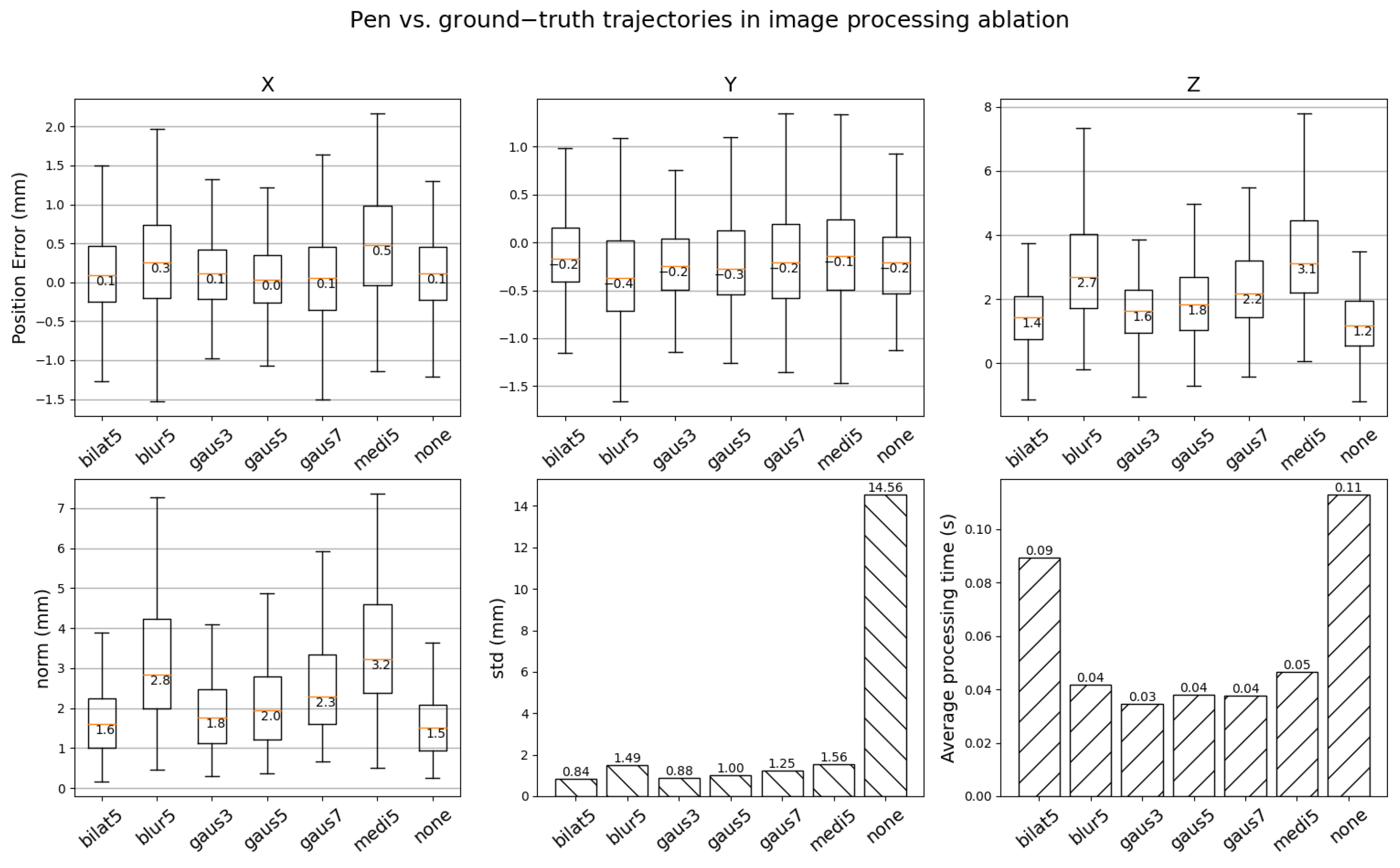
3.5. Image Enhancement/Processing Pipeline
Preprocessing Images
4. Pen Calibration
4.1. Pen Geometry Calibration with Bundle Adjustment
4.1.1. Approximate Pose Estimation (APE)
4.1.2. Dense Pose Refinement (DPR)
4.2. Pen Tip Calibration
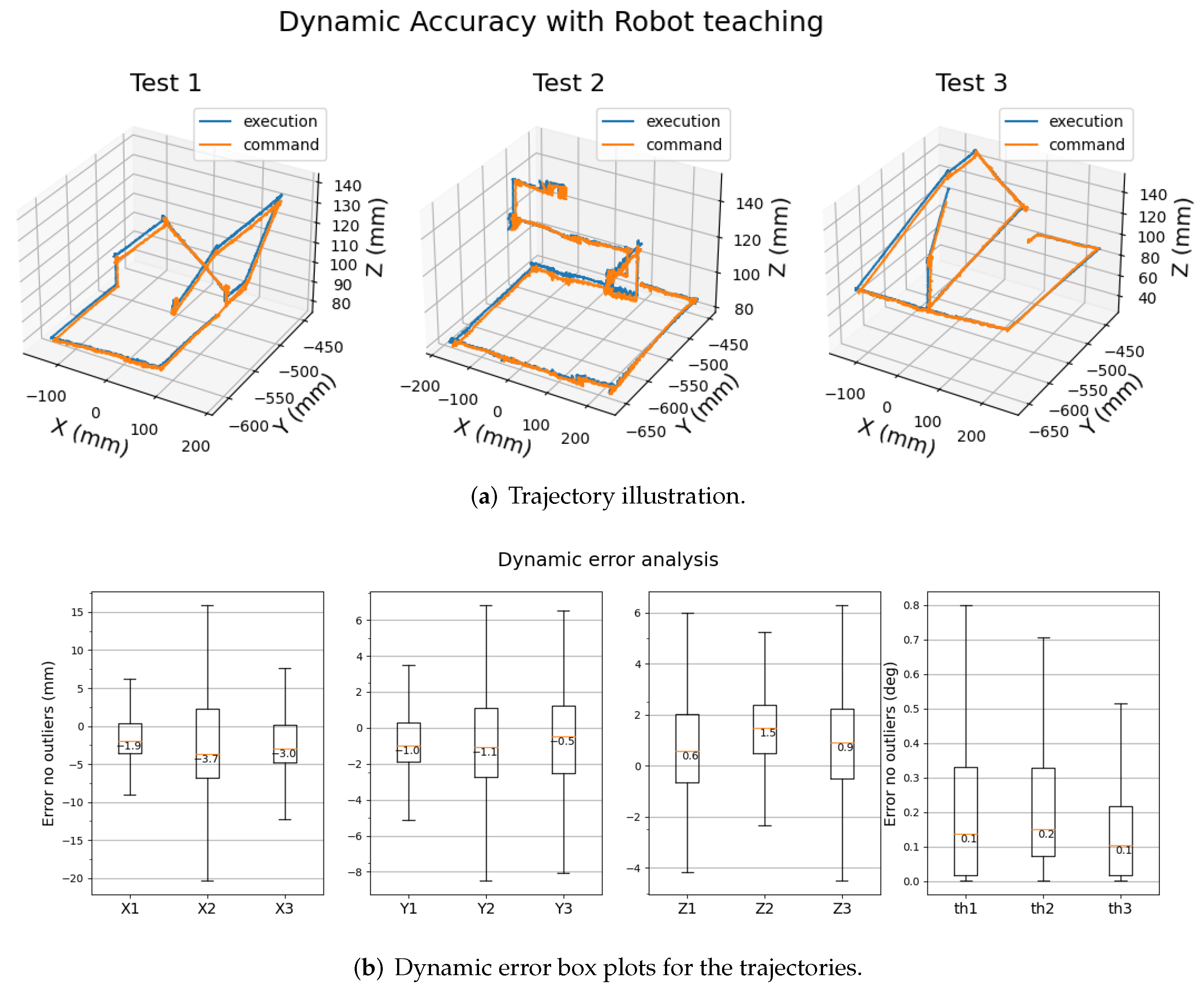
5. Evaluation of a Teaching Operation
6. Experiment Results
6.1. Vision to Robot Calibration
6.2. Accuracy Evaluation
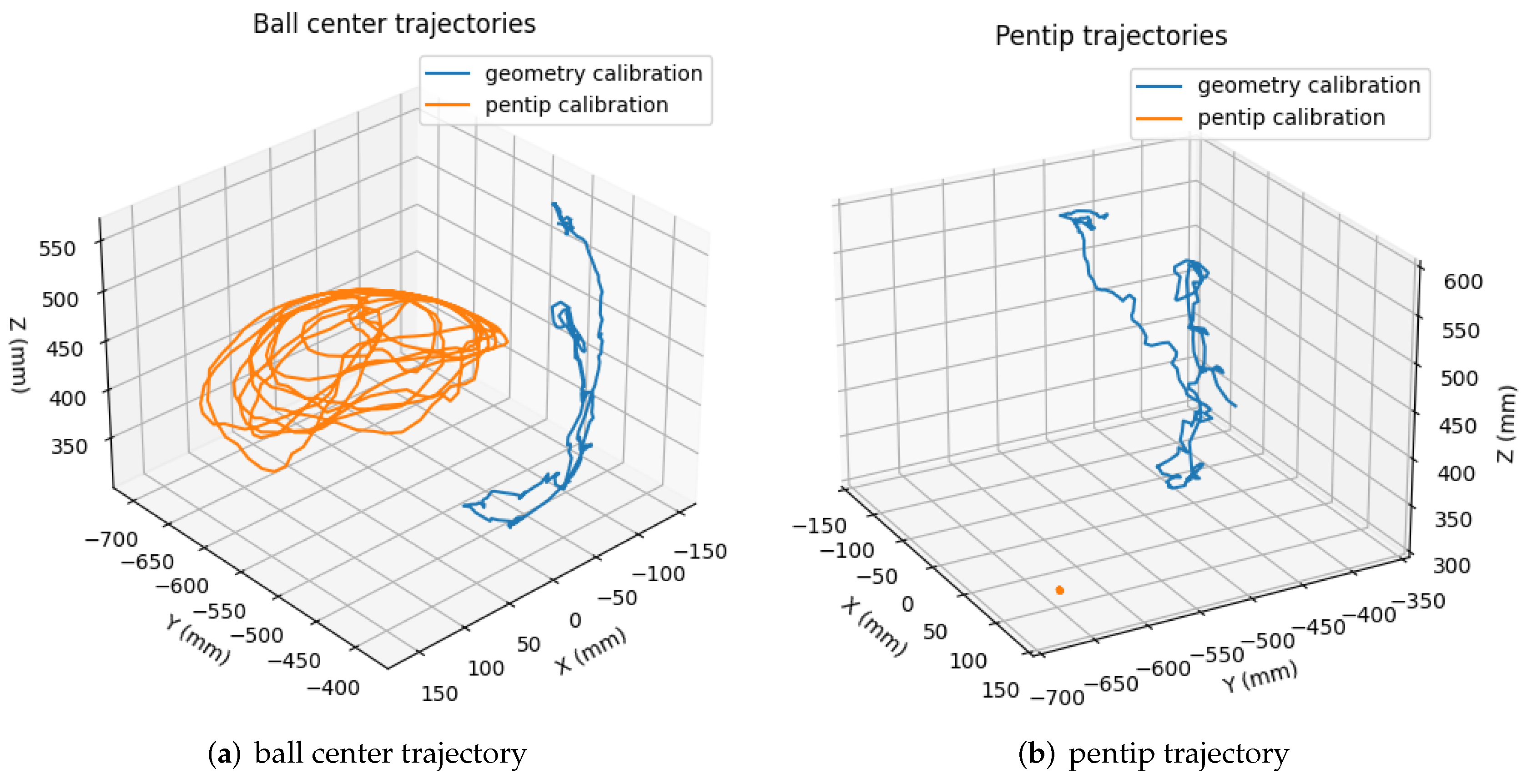
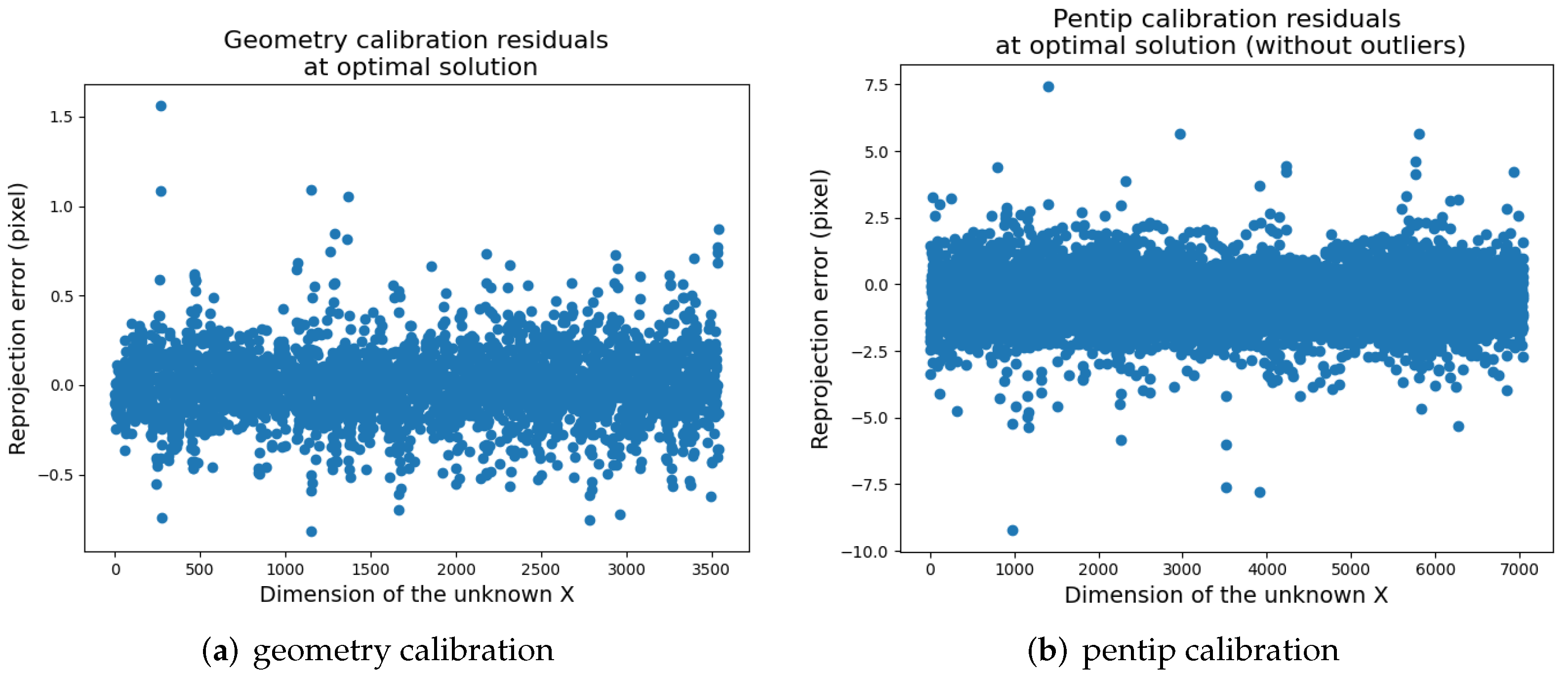
6.2.1. Calibration Accuracy
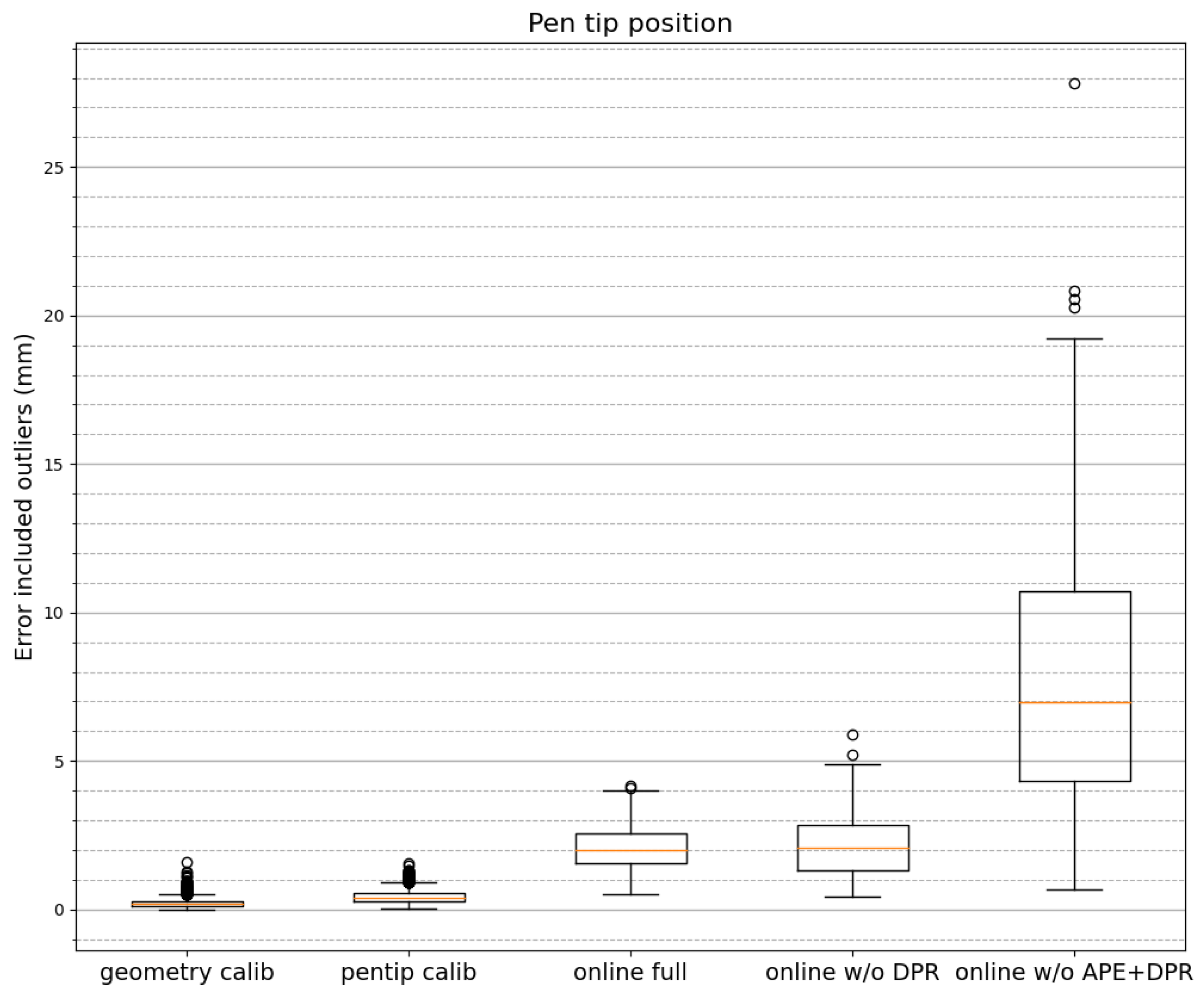
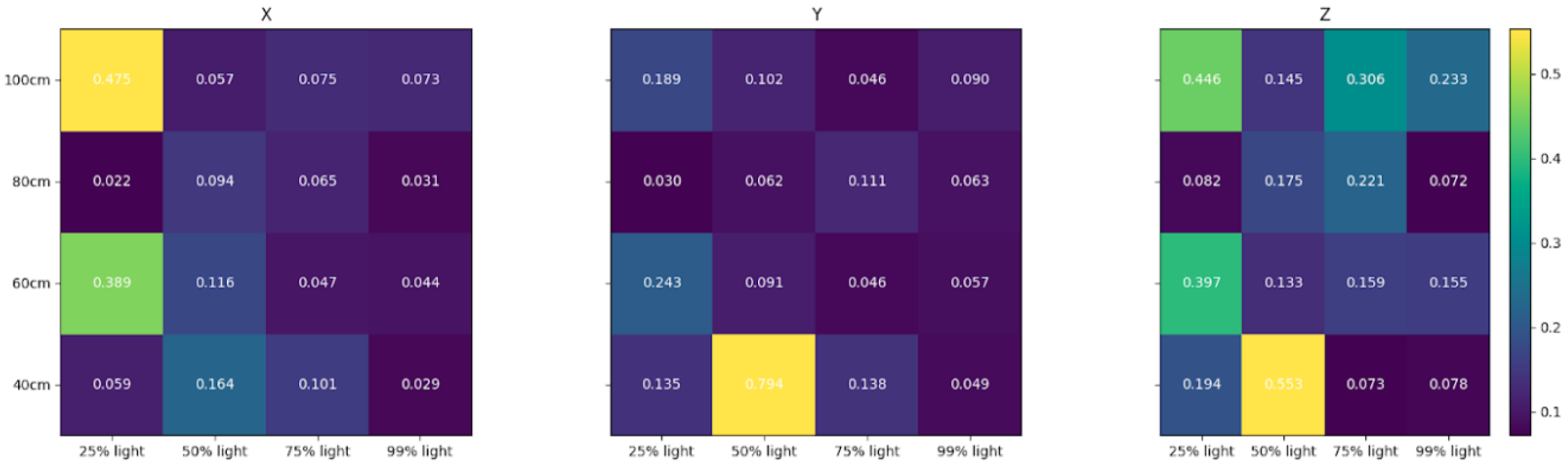
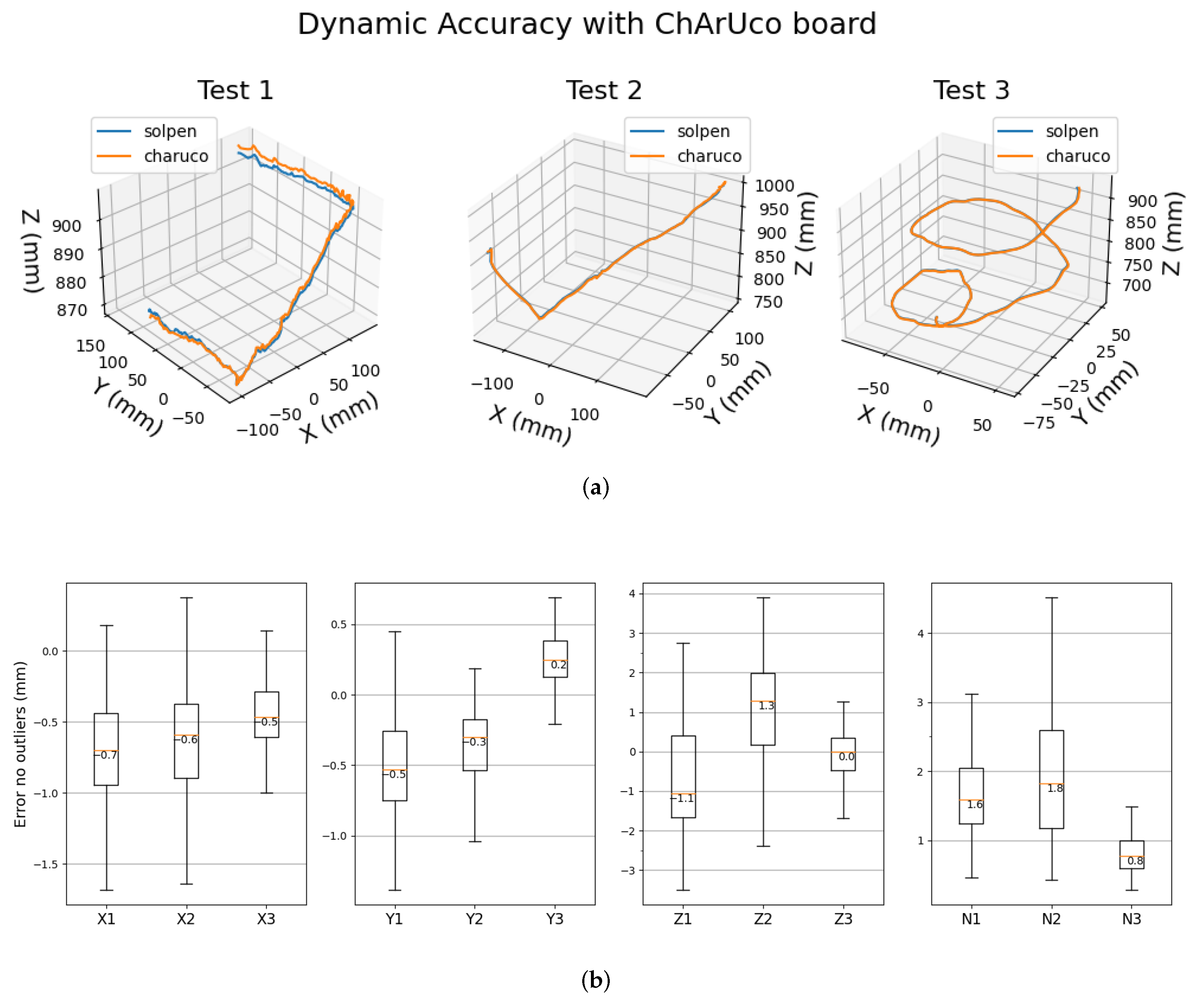
6.2.2. Inference Accuracy
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Kruusamae, K.; Pryor, M. High-precision telerobot with human-centered variable perspective and scalable gestural interface. In Proceedings of the 2016 9th International Conference on Human System Interactions (HSI), Portsmouth, UK, 6–8 July 2016. [Google Scholar]
- Tsarouchi, P.; Athanasatos, A.; Makris, S.; Chatzigeorgiou, X.; Chryssolouris, G. High Level Robot Programming Using Body and Hand Gestures. Procedia CIRP 2016, 55, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Manou, E.; Vosniakos, G.C.; Matsas, E. Off-line programming of an industrial robot in a virtual reality environment. Int. J. Interact. Des. Manuf. (IJIDeM) 2019, 13, 507–519. [Google Scholar] [CrossRef]
- Lin, H.I.; Lin, Y.H. A novel teaching system for industrial robots. Sensors 2014, 14, 6012–6031. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lambrecht, J.; Kleinsorge, M.; Rosenstrauch, M.; Krüger, J. Spatial Programming for Industrial Robots through Task Demonstration. Int. J. Adv. Robot. Syst. 2013, 10, 254. [Google Scholar] [CrossRef]
- Lambrecht, J.; Krüger, J. Spatial Programming for Industrial Robots: Efficient, Effective and User-Optimised through Natural Communication and Augmented Reality. Adv. Mater. Res. 2014, 1018, 39–46. [Google Scholar] [CrossRef]
- Wacker, P.; Nowak, O.; Voelker, S.; Borchers, J. Evaluating Menu Techniques for Handheld AR with a Smartphone & Mid-Air Pen. In Proceedings of the 22nd International Conference on Human-Computer Interaction with Mobile Devices and Services, Oldenburg, Germany, 5–9 October 2020. [Google Scholar]
- Wu, P.C.; Wang, R.; Kin, K.; Twigg, C.; Han, S.; Yang, M.H.; Chien, S.Y. DodecaPen. In Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology, Quebec City, QC, Canada, 22–25 October 2017. [Google Scholar]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle Adjustment—A Modern Synthesis. In Vision Algorithms: Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2000; pp. 298–372. [Google Scholar]
- Förstner, W.; Wrobel, B.P. Photogrammetric Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.J.; Marín-Jiménez, M.J. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Corke, P. Robotics, Vision and Control; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Tsai, R.Y.; Lenz, R.K. A new technique for fully autonomous and efficient 3D robotics hand/eye calibration. IEEE Trans. Robot. Autom. 1989, 5, 345–358. [Google Scholar] [CrossRef] [Green Version]
- Horaud, R.; Dornaika, F. Hand-Eye Calibration. Int. J. Robot. Res. 1995, 14, 195–210. [Google Scholar] [CrossRef]
- Andreff, N.; Horaud, R.; Espiau, B. On-line hand-eye calibration. In Proceedings of the Second International Conference on 3-D Digital Imaging and Modeling (Cat. No. PR00062), Ottawa, ON, Canada, 8 October 1999. [Google Scholar]
- Daniilidis, K. Hand-Eye Calibration Using Dual Quaternions. Int. J. Robot. Res. 1999, 18, 286–298. [Google Scholar] [CrossRef]
- Tabb, A.; Ahmad Yousef, K.M. Solving the robot-world hand-eye(s) calibration problem with iterative methods. Mach. Vis. Appl. 2017, 28, 569–590. [Google Scholar] [CrossRef]
- Ali, I.; Suominen, O.; Gotchev, A.; Morales, E.R. Methods for Simultaneous Robot-World-Hand–Eye Calibration: A Comparative Study. Sensors 2019, 19, 2837. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Umeyama, S. Least-squares estimation of transformation parameters between two point patterns. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 376–380. [Google Scholar] [CrossRef] [Green Version]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]


















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, T.-S.; Tran, Q.-V.; Nguyen, X.-L.; Lin, C.-Y. Solpen: An Accurate 6-DOF Positioning Tool for Vision-Guided Robotics. Electronics 2022, 11, 618. https://doi.org/10.3390/electronics11040618
Le T-S, Tran Q-V, Nguyen X-L, Lin C-Y. Solpen: An Accurate 6-DOF Positioning Tool for Vision-Guided Robotics. Electronics. 2022; 11(4):618. https://doi.org/10.3390/electronics11040618
Chicago/Turabian StyleLe, Trung-Son, Quoc-Viet Tran, Xuan-Loc Nguyen, and Chyi-Yeu Lin. 2022. "Solpen: An Accurate 6-DOF Positioning Tool for Vision-Guided Robotics" Electronics 11, no. 4: 618. https://doi.org/10.3390/electronics11040618
APA StyleLe, T.-S., Tran, Q.-V., Nguyen, X.-L., & Lin, C.-Y. (2022). Solpen: An Accurate 6-DOF Positioning Tool for Vision-Guided Robotics. Electronics, 11(4), 618. https://doi.org/10.3390/electronics11040618