1. Introduction
In the field of manufacturing robotics, it is of the highest relevance to count with optical sensors able to provide the system with a sensory mechanism that feeds back the actions of one or more robotic arms that collaborate or interact with a human. Tasks such as welding, machining, painting, or simply clamping and assembly are common in this type of industry. That is why intelligent optical sensing systems are essential for carrying out these tasks. Furthermore, robotics vision allows for automatic learning to achieve fast and accurate object or pattern recognition, which is sometimes a complicated, dangerous, and strenuous task, and humans are usually not involved in the loop. Therefore, these automatic detection mechanisms must be precise when selecting the proper object, which is key to the success of the manufacturing process [
1].
In manufacturing cells, it is common for components or objects (e.g., screws, nuts, washers, motors, autoparts, assemblies, and fasteners) to approach the assembly area via conveyors. These objects are usually placed on the worktable of a different assembly robot. These objects are not necessarily approached with the same orientation in each assembly process, and it is even possible that, by some mistake, the part falls and rotates, thus changing the object configuration that was initially planned. It is a highly demanding process to ensure that parts arrive in a specific order and are aligned from the previous stage, so that the robot quickly decides the best way to take them through a deterministic process; this is called the bin-picking problem [
2,
3]. A robotic vision system must be able to recognize and discriminate parts or objects from any angle and indicate its position to the robot. These vision systems are either fixed to the manufacturing cell [
4] or the last end of the robotic arm [
5]. In the former, systems have the advantage that, regardless of the overall weight of the system (camera, communications, and computer), vision systems can be easily installed on tripods or the walls of the cell enclosure. Moreover, power consumption is not critical, although the price is usually high. In the case of vision systems being fixed on the wrist of the robotic arm, advantages appear not only as higher image resolution (closer proximity to the object, higher data quality), but also by offering the possibility of dynamically changing the camera angle. However, in order to not add more weight to the robot, embedded systems able to acquire the image, preprocess it, and make inferences are required. In the context of Industry 4.0, priority is given to low-power, stand-alone, low-cost, multimodal, digitally robust, intercommunicable, and, above all, compact systems [
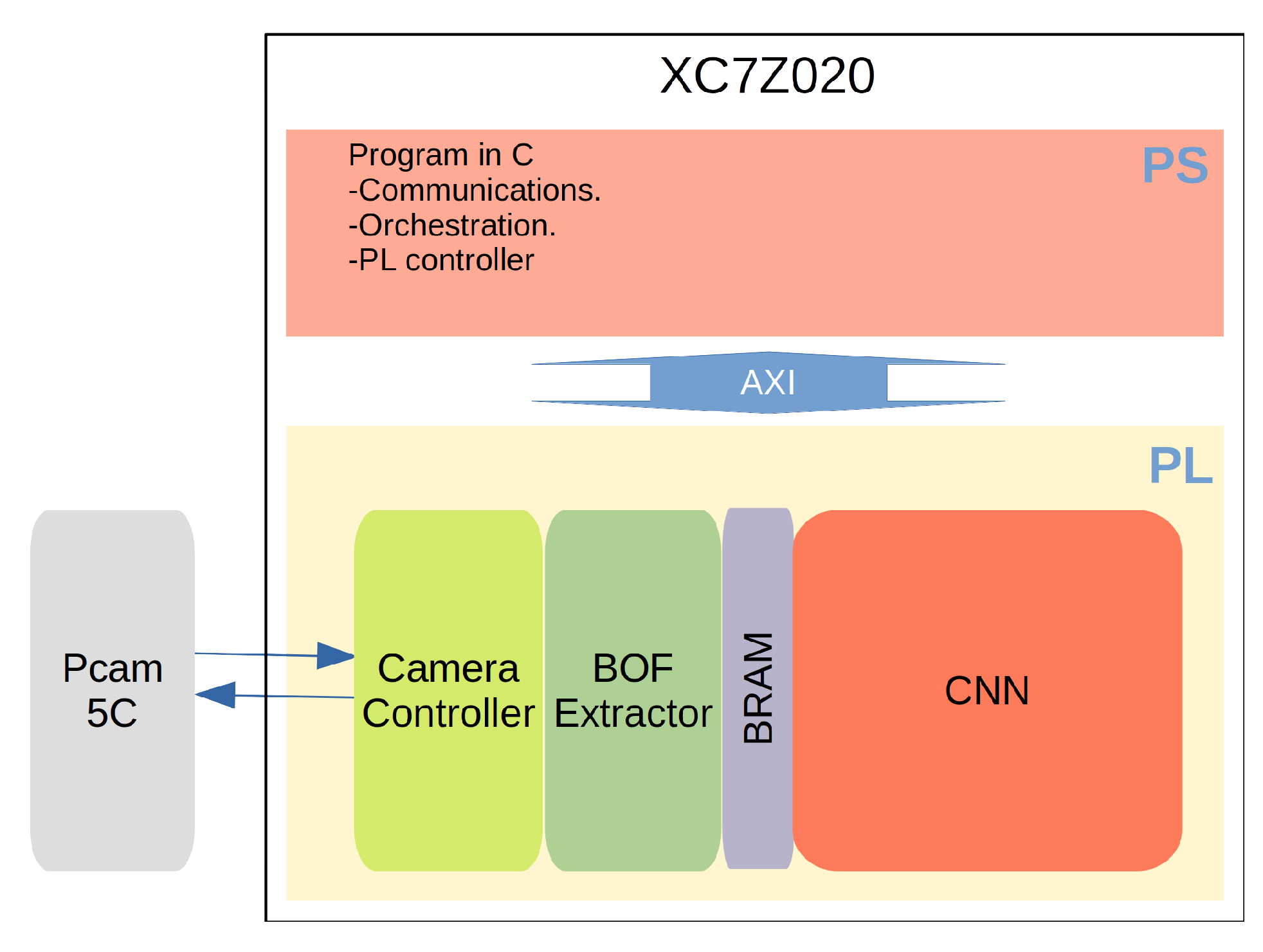
6]. This paper focuses on the second precept, that is, of vision systems attached to a robotic arm.
In contrast to what is commonly found in automatic object recognition in other fields, in intelligent manufacturing, the attributes of the components are perfectly known in advance. Features such as color, geometry, texture, and dimensions are greatly relevant to the system so that it can act on the basis of those descriptions. Hence, it is necessary to use customized procedures since those used in pretrained machine-learning models with a large dataset with hundreds of objects are not functional.
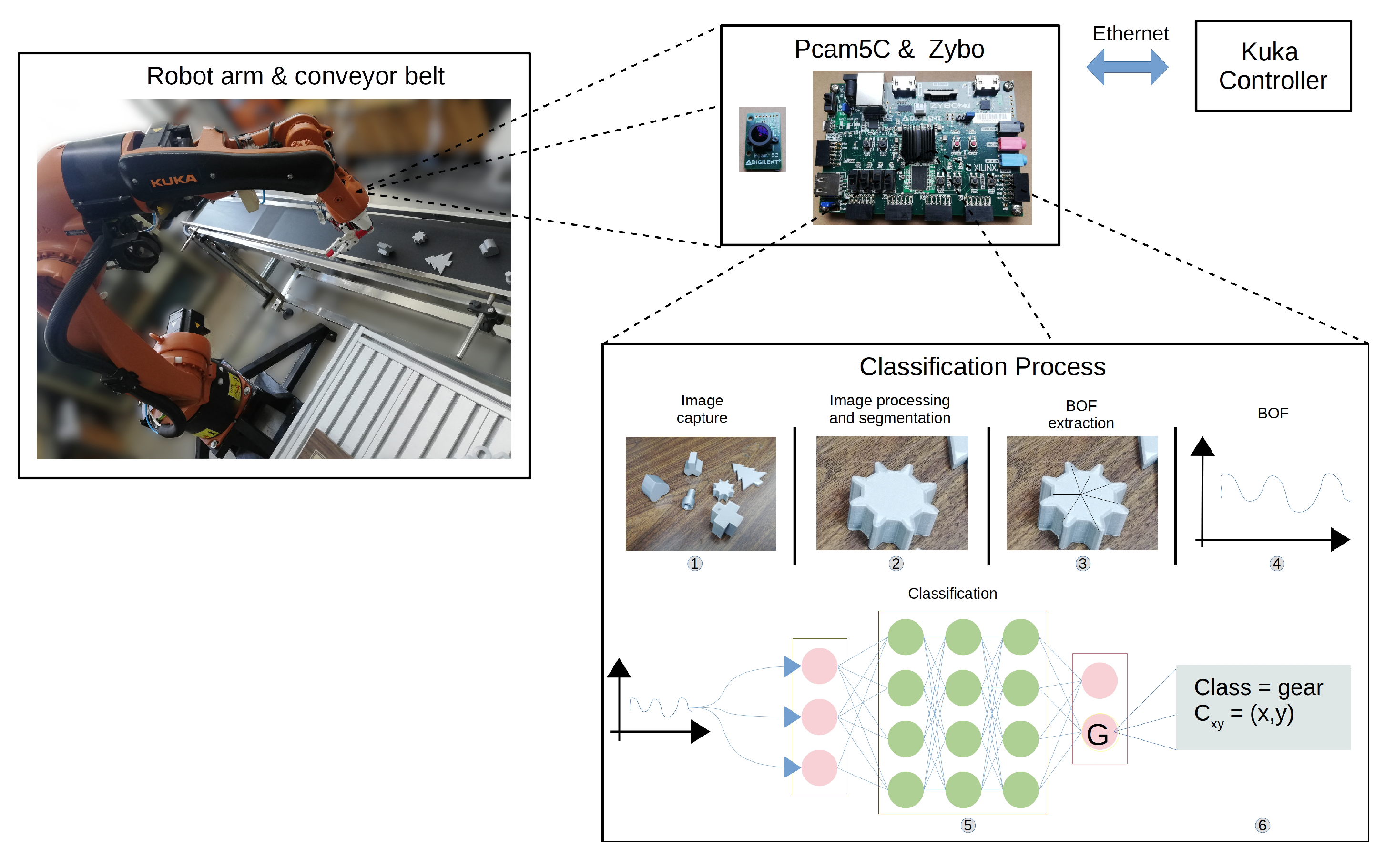
In this contribution, we propose an object recognition method implemented in an FPGA in which tasks such as image capture and preprocessing are automated, and at a further stage, an object classification process is conducted. All these tasks are circumscribed in an embedded system placed on the wrist of a robotic arm. Previous pattern recognition works implemented in FPGA can be divided between those based on feature extraction and those based on artificial neural networks (ANNs). In the former, there is work on the Speed-Up Robust Features (SURF) algorithm [
7] and its implementation on FPGA [
8], and on Features from Accelerated Segment Test [
9] and Binary Robust Independent Elementary Features [
10] (FAST + BRIEF) [
11]. The ANN approach counts with relevant contributions such as the work described in [
12], where it is described as an improved version of YOLOv2 implemented in a ZYNQ FPGA. Convolutional neural networks, CNNs such as VGG16 and MobilenetV2 were implemented in hardware [
13] using mixed-precision processors. In [
14], several CNN model networks (VGG16, MobilenetV2, MobilenetV3, and ShufflenetV2) were produced in hardware using a hybrid vision processing unit (Hybrid VPU).
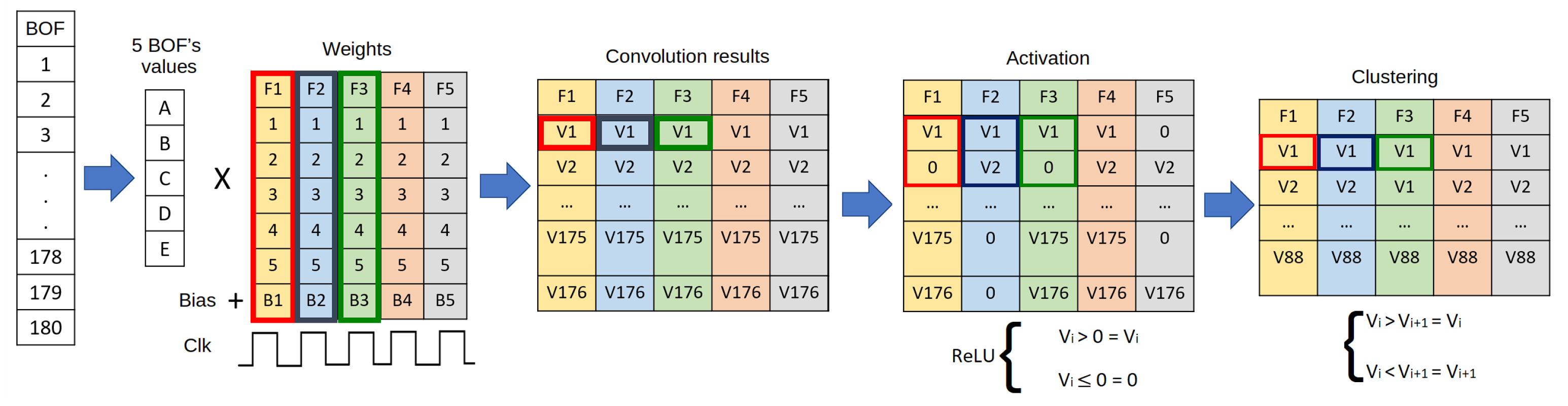
The boundary object function (BOF) [
15] descriptor vector, which is a formalism that characterizes an object by extracting some attributes, as detailed in the following sections, demonstrated potential in terms of being invariant to rotation, scale, and displacement, and being able to condense the information coming from a 2D image to a one-dimensional array. In [
16], the BOF and a classifier based on the fuzzy ARTMAP neural network were implemented on an FPGA [
17] with very favorable results. However, complications are detected when the object angle on the
z-axis exceeds 15 degrees. Therefore, object recognition is complicated if the capture angle is different from the considered angle during network training.
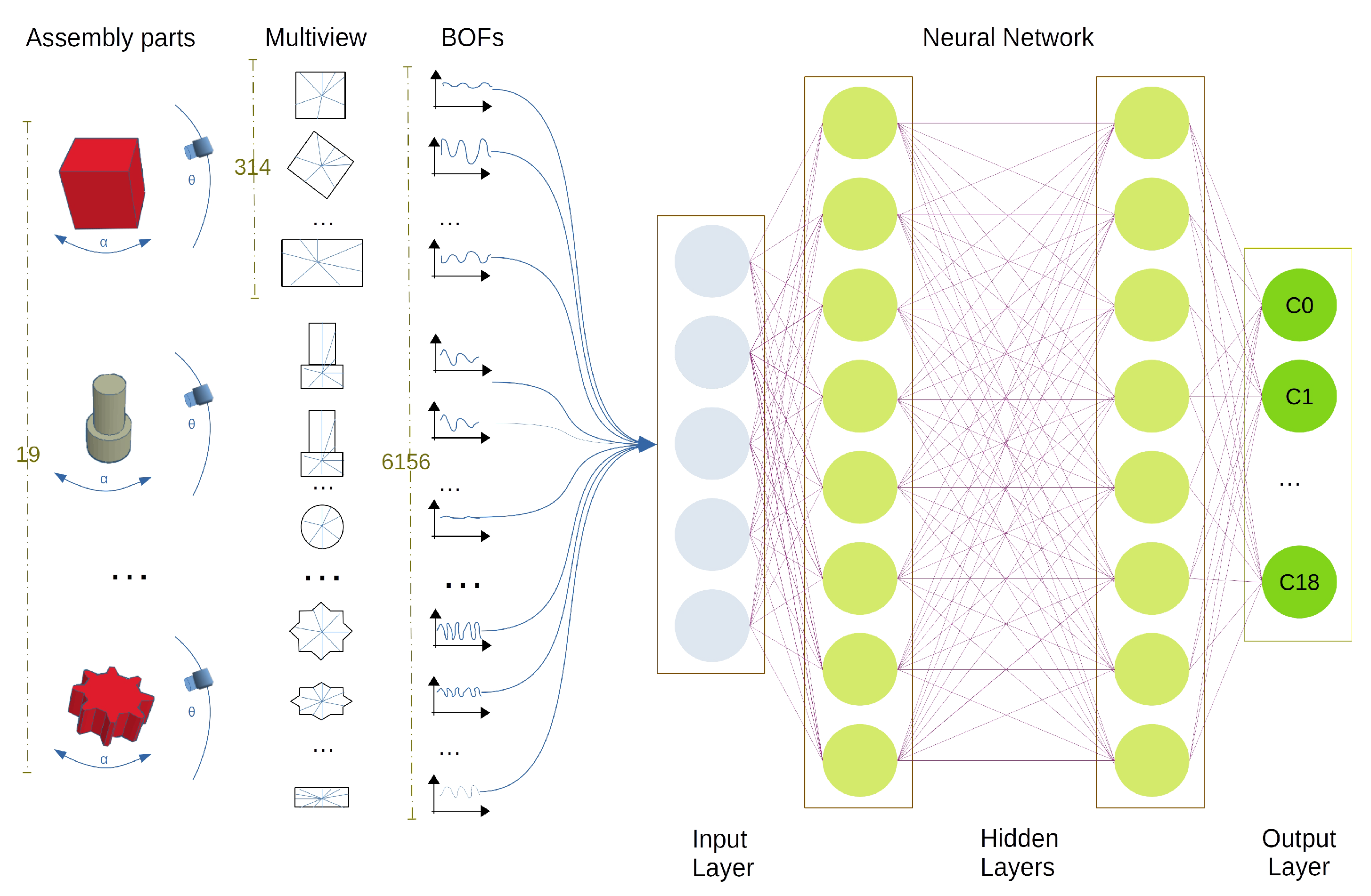
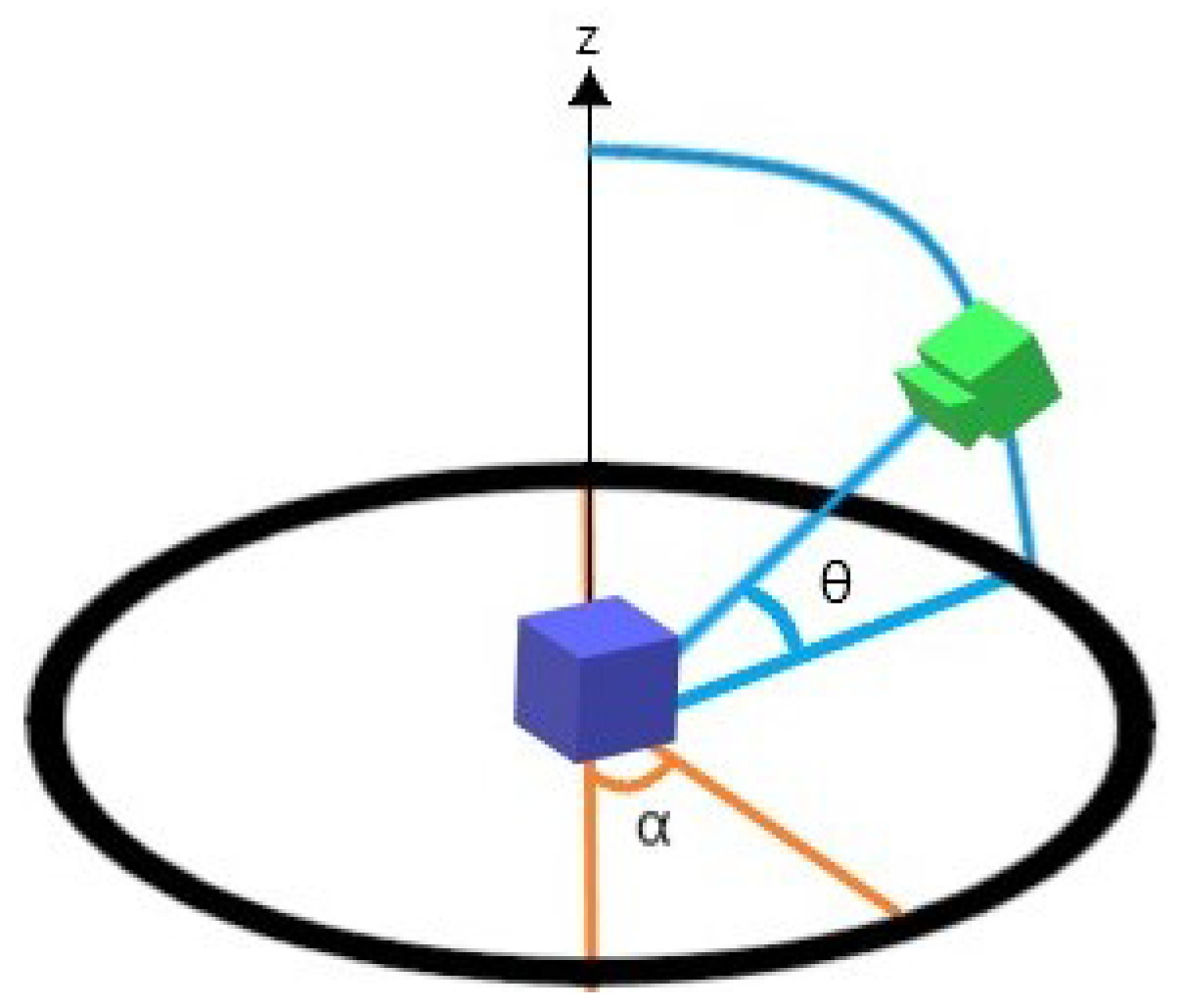
We constructed our dataset by joining the descriptors of all objects. First, a family of BOF vectors linked to a given object was obtained by systematically rotating the camera plane around a surrounding sphere centered on the object. Then, a BOF was obtained from each rotation angle, and the family of BOFs could be tuned by setting the list of rotation angles. Lastly, all objects of interest were characterized in the same form, and the family of BOFs associated with each constituted the complete dataset, as shown in
Figure 1.
Although CNNs were originally designed for digital image processing, they were successfully applied in several other contexts. Applications in other areas include, for example, genomic data processing [
18], text classification [
19], and sentiment analysis [
20].
In our contribution, the challenge was to find a CNN model that could classify BOF vector families of different objects.
Table 1 shows the pixel input dimensions for the most common CNN models and the BOF and CNN combination introduced in this work. The input dimensions for this case were defined as a 180 × (nbytes fixed point) since the BOF consisted of 180 values, that is, 180 angles of rotation represented as a fixed point.
As stated earlier, in this contribution, we describe a method to classify objects using their BOF vector family as features. The external label or class is given by the object type, such as screws or gears. A deep learning neural network then approximates a function between BOF family vector and object class. The main contributions are:
we designed a manufacturing part recognition method capable of classifying multiple part views from their unique descriptors (BOF);
we designed a CNN from an existing model, but instead of directly using images, we trained the network with the unique descriptors of each part view; and
we implemented a CNN model on a field-programmable gate array (FPGA).
In this contribution, the hypothesis we aimed to prove is that objects of interest in automatic manufacturing can be recognized by their BOF description instead of relying on their images. Since BOFs are vectors representing objects, and BOFs have lower dimensions than images do, we aimed to successfully train a CNN as a classifier on the basis of BOFs. At the same time and equally relevant, we wanted to verify whether training based on BOFs is faster. The third relevant aspect we investigate is the method’s speed gain when implemented in an FPGA (
Figure 2).
Related works [
13,
14] relied on an image detection algorithm based on a CNN. However, the size of the networks is described by its more than 2 million parameters (Mobilenet V2), which consumes 279,000 LUTs and 3600 DSP, and 146,000 LUTs and 212 DSP, respectively. Instead, our model consumes only 31,336 LUTs and 116 DSP. As an additional advantage of our proposal, as is shown in the next sections, it is faster.
The rest of this study is organized as follows.
Section 2 describes the entire process of building the dataset, the design of the CNN, and its implementation on the FPGA.
Section 3 shows the nature of the data and is divided into two sections: results of the CNN implemented in Python to ensure network efficiency and the results of FPGA implementation.
Section 4 shows the main results by comparing the results achieved by our contribution with those of similar works. Lastly,
Section 5 presents some concluding remarks.
The method presented in this paper aims to answer these questions.
4. Discussion
Counting with fast, accurate, and reliable systems is of paramount relevance in the manufacturing industry. In this contribution, we described a method that fulfils those three attributes with acceptable performance. The presented method and its implementation in an FPGA could lead to an advanced manufacturing cell that is able to capture video, preprocessing, and postprocessing video frames, and allows for the classification of objects commonly involved in a production line with real-time processing, low cost, low power consumption, small size, and being light enough to be attached to the tip of a robotic arm.
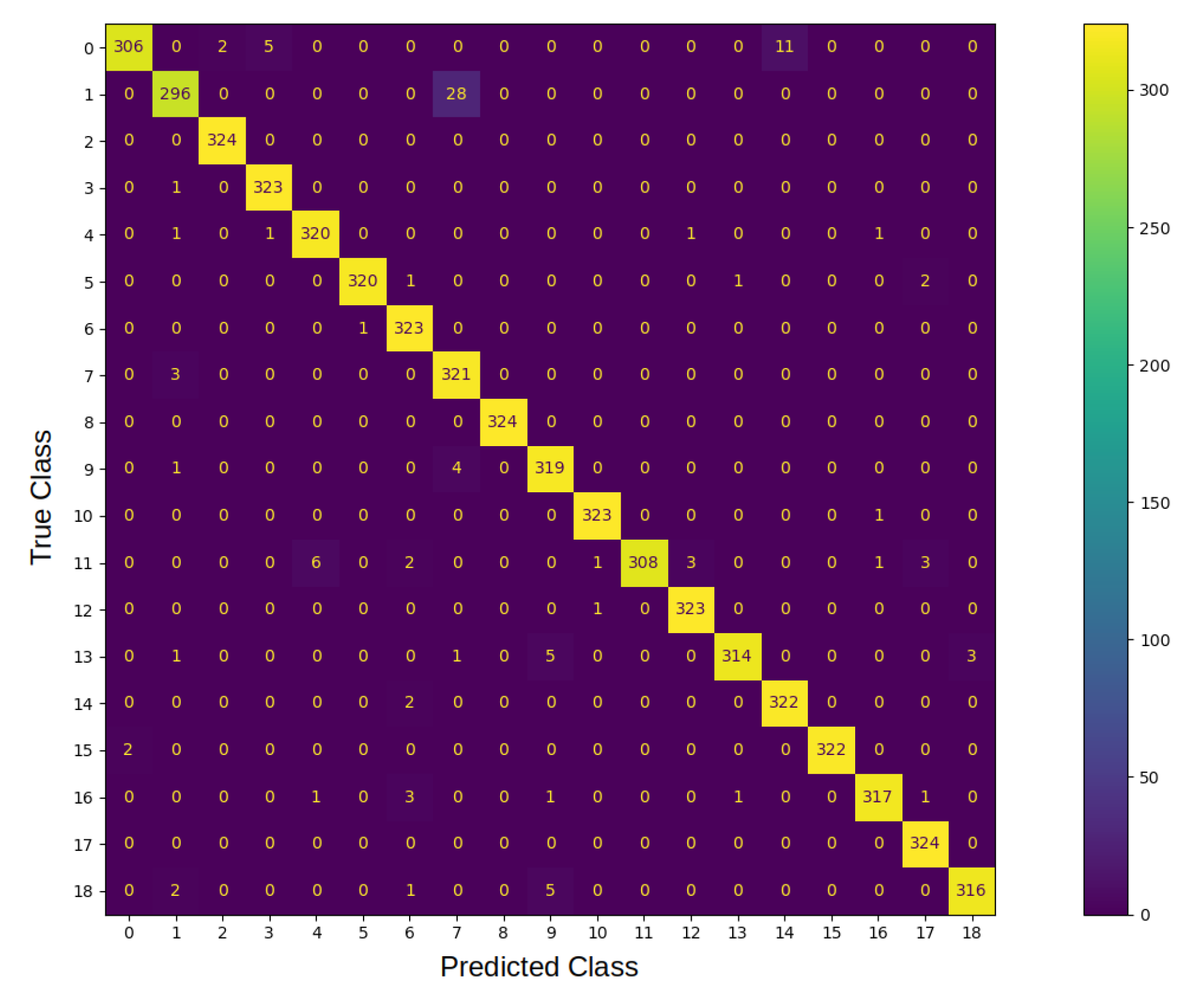
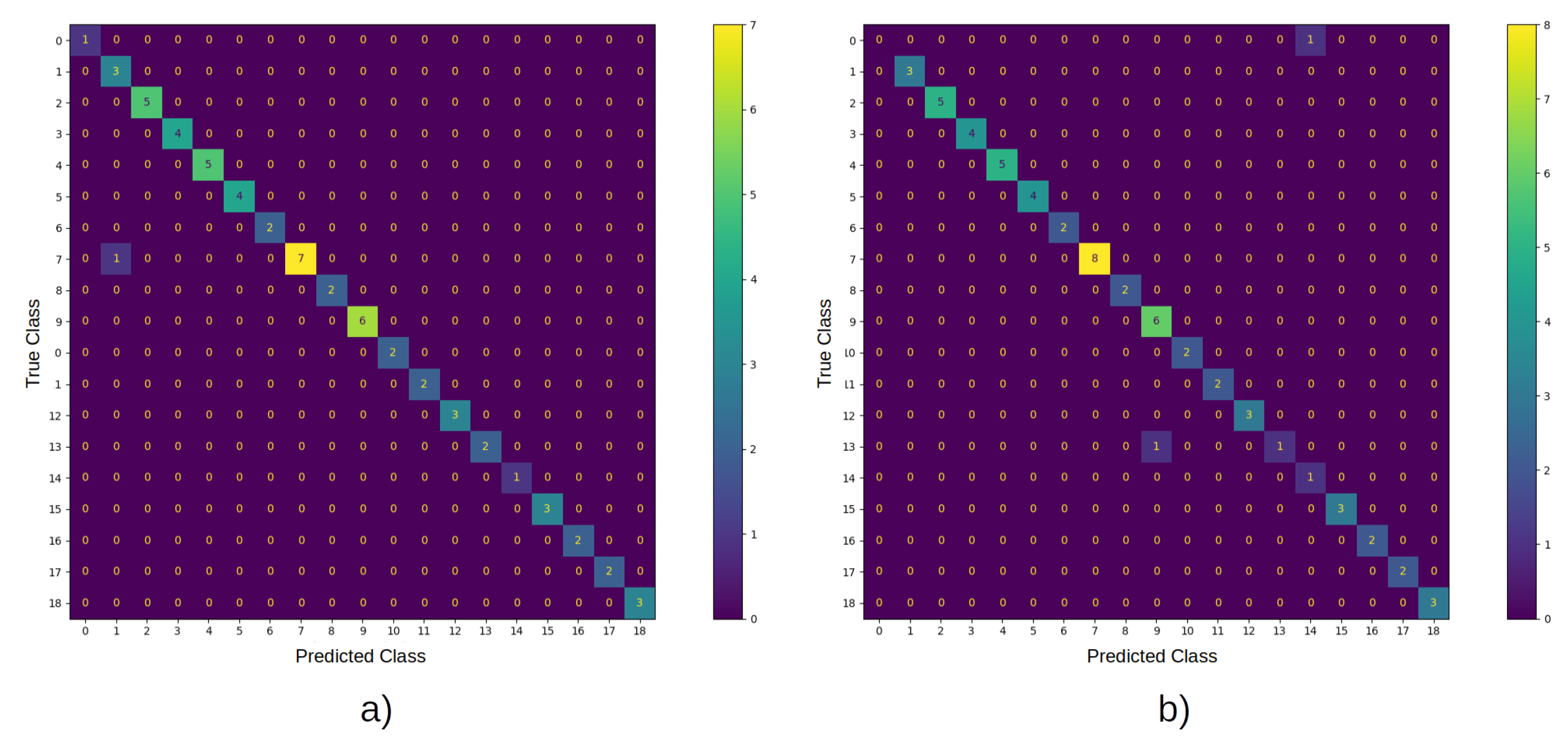
Analysis of the confusion matrix of the system implemented in Python (see
Figure 8) showed that the classification errors of classes 0 and 1 were caused by the similarity of those objects in the computed view when
. In addition, the system on the FPGA had accuracy loss of 2%, which is quite acceptable in manufacturing; moreover, it is more than 655 times faster than its implementation on a PC.
The BOF has not been used before to extract information from an object from different angles and train a neural network. To validate this, we conducted a series of tests from which we demonstrated that using BOF instead of the image itself is a significant contribution.
In order to conduct a fair comparison between our proposal and state-of-the-art CNN models, we trained the latter with the image dataset that we had constructed for the case under study by feeding those CNN models with the images and their rotations in two described axes and .
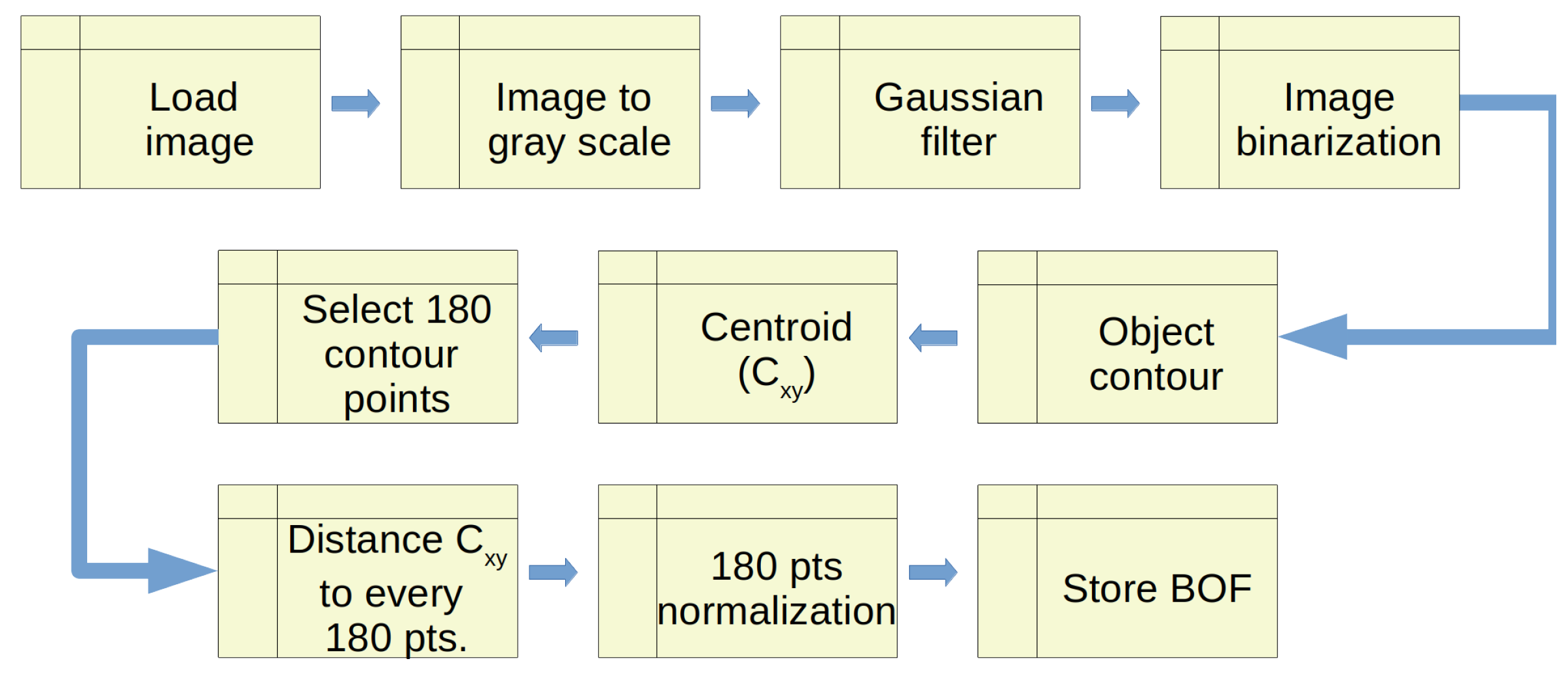
CNNs are usually trained with datasets containing standard object classes (people, animals, vehicles, among others). In this contribution, however, we used the images obtained in Step 2 of the methodology (
Section 2); we called it 3D Images Objects Dataset (3DIOD). Briefly, each image was segmented by selecting the region of interest of the object, scaled, and transformed into grayscale. With this, we formed the image dataset. Lastly, we trained two CNN models (ResNET50 [
24] and MobileNetV2 [
25]) with the image dataset. It was necessary to modify the output layer of one of them because the number of the classes changed to 19. The reason for choosing this CNN model was its relatively small size compared with that of. another CNN.
Table 13 shows the number of parameters, number of layers, average latency for classification, and accuracy for different known CNN models. This experiment was only programmed in Python and Keras.
From the results shown in the previous table, we can affirm that our hypothesis is valid. That is, our proposal (Modified LeNet-5 and BOF dataset) is faster and requires fewer parameters than those needed in ResNET50 or MobileNetV2 CNN models, which take raw images as their input data.
Table 14 and
Table 15 shows the comparison of our FPGA implementation with the state-of-the-art models. We split the comparison because, in
Table 14, the consumed time only shows the results for the classification process assuming that the image had been loaded on the FPGA. Meanwhile, in
Table 15, the comparison is focused on fully implemented systems; the image was captured by a 60 FPS sensor and then transferred to the FPGA for inference.
Even though the cited works use images as input, the comparison is valid in contrast with our approach in which we feed BOF input as inputs. The reason for this is that the transfer of knowledge from the trained CNN models (shown in
Table 13) to this FPGA implementation do not degrade the hardware performance.
The cited works in
Table 14, Refs. [
13,
14], refer to an FPGA architecture for the MobilenetV2 and Tiny YoloV3 (modified YOLOV3 [
26]) CNN models. The MobilNet V2 implemented in the first cited work is faster than the one implemented in the second, but at the cost of more consumed resources. Compared to these two systems, our work is faster and at the same time, requires far less parameters ti be trained.
Continuing with
Table 15, the first of the cited works, Ref. [
27], implemented a CNN model (YOLOv2 Tiny) directly in hardware. The second case listed in
Table 15 is an implementation of BOF and Fuzzy ARTMAP in hardware. The same board was used, Zybo Z7-20. The dataset for this model consisted of 100 images of the objects of interest, one per category.
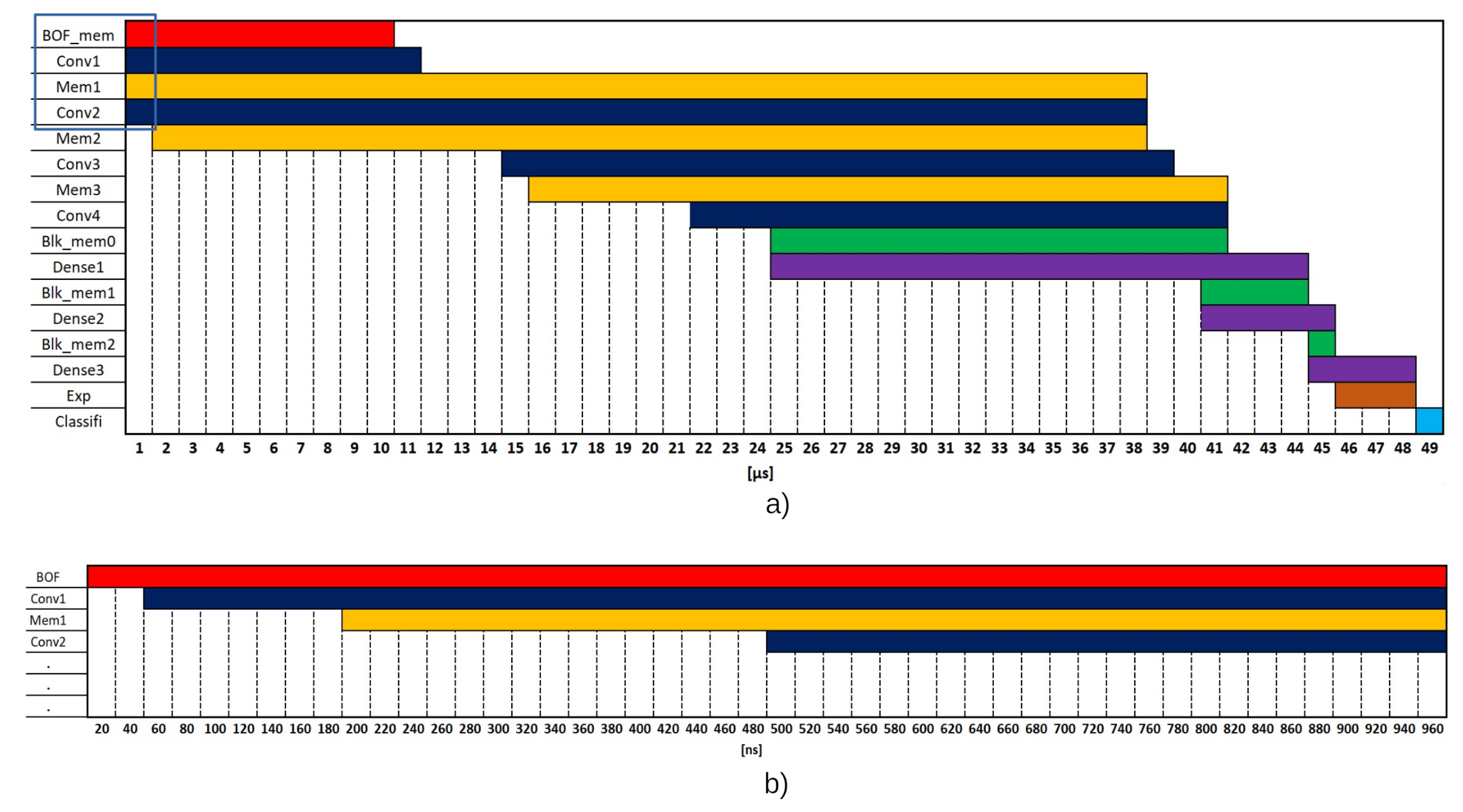
The latency in our model for classification is 0.04995 [ms]; however, loading the image in the FPGA takes 6.152 [ms]. Therefore, the total latency is 6.2 [ms] and 161.23 FPS. This result is 2.25X faster than [
27]. The logic resources consumed in each project are remarkable; ours uses fewer LUTs, BRAMs and DSPs. The same is true for power consumption criteria and board price. Almost half of the XC7Z020 logic resources were used (LUTs, 58.90%; DSPs, 52.73%), so increasing the categories and image number is feasible.
5. Conclusions
Manufacturing requires adaptable systems that are able to cope with several configurations and orientations of components to be assembled. Real-time responses are a critical attribute in manufacturing systems, and conducting efforts to efficiently implement classifiers in hardware is, beyond doubt, a path that offers stable and reliable results. In this contribution, we described such a system and showed that results are encouraging and competitive compared to state-of-the-art solutions.
In this contribution, we proved that, in the robotic assembly context, the use of families of BOFs serving as input to convolutional neural networks leads to a faster and computationally more efficient training than the counterpart of using input multiview images as input to the vision system. We based our findings on a modified LeNet-5 CNN model. The results for the BOF case led to a latency of 37.97 ms for one inference and required 27,354 parameters, versus 57.14 ms and 2 million parameters for the multiple-view images. For the study case of interest in this contribution, both cases considered 19 classes of objects.
Continuing in the path of computational efficiency, the convolutional neural network implemented in FPGA could recognize relevant objects with high accuracy several times faster than its implementation in a general-purpose computer running Python, which is 655 times faster.
Compared with the literature on the state of the art, the latency for only one inference was 0.049 ms in our proposal (modified LeNet-5 trained with 3DBOFD) versus 0.34 ms in the cited work [
13]. The latency for the entire process (capture the image and transfer the image to classify in the FPGA) took 6.2 ms, and in the cited work [
27], it was 14 ms.
We opened a path to further investigate the impact of reliable hardware for implementing complex classifiers, such as convolutional neural networks, and achieve competitive results. We plan to extend the number of classes, and adjust and improve a larger CNN model as future work. We also plan to build a more comprehensive dataset for additional experiments with the most representative objects in assembly tasks.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}