
Robust Latent Common Subspace Learning for Transferable Feature Representation


Abstract
:1. Introduction
2. Related Works
3. Robust Latent Common Subspace Learning
3.1. Notation
3.2. Objective Function
3.3. Optimization Algorithm
3.4. Classification
| Algorithm 1: Solving RLCSL by LADMAP. |
Input: Data set matrix and ; Source domain data label indicator matrix F; Parameters , , , and the latent common subspace ; Initialization:; ; ; ; ; ; ; ; ; ; ; ; ; ; while not converged do 1. Fix the others and update Q by solving (9) orthogonal Q. 2. Fix the others and update P by solving (11). 3. Fix the others and update W by solving (13). 4. Fix the others and update Z by solving (15). 5. Fix the others and update H by solving (18). 6. Fix the others and update E by solving (21). 7. Update the multipliers as follows 8. Update the parameter follows 9. Check the convergence conditions where 10. Update k: . end while Output: W. |
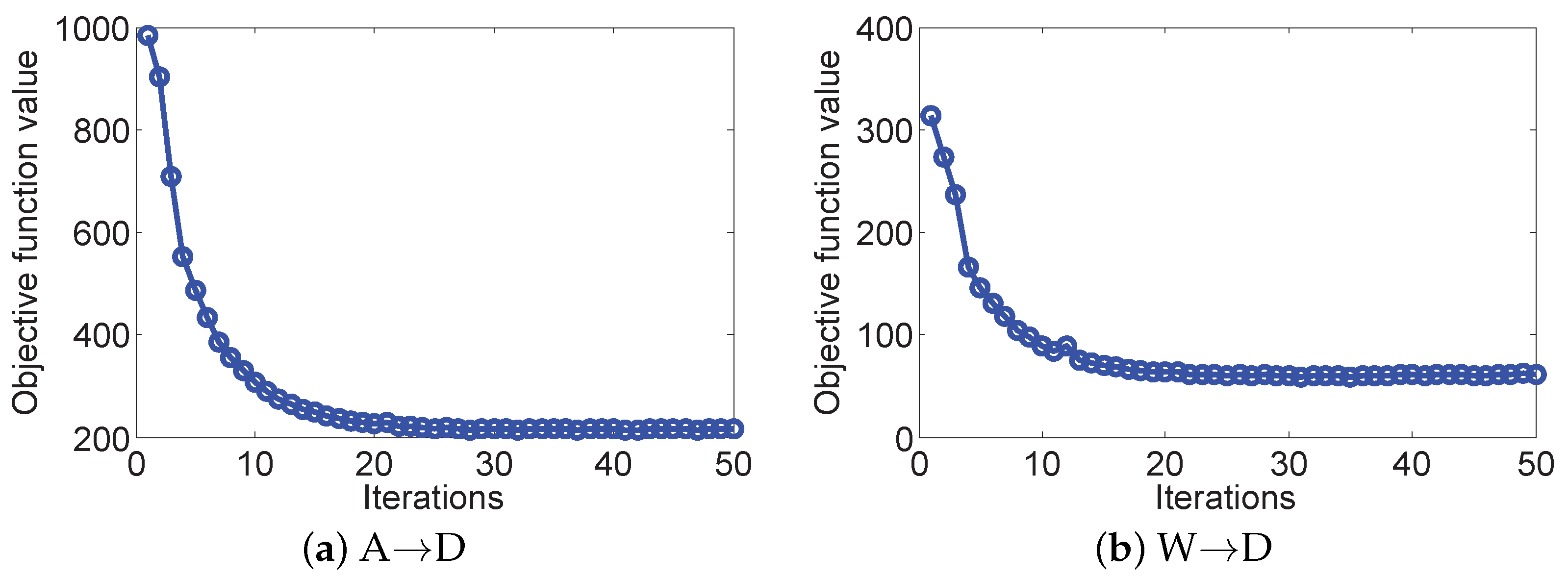
3.5. Computation Complexity, Memory Requirement, and Convergence
3.6. Connections to Existing Works
4. Experiments
4.1. Data Set Preparation
4.2. Comparison Methods
4.3. Experiments on the Office, Caltech-256 Data Sets
4.4. Experiments on the Reuters-21,578 Data Set
4.5. Experiments on the MSRC and VOC2007 Data Sets
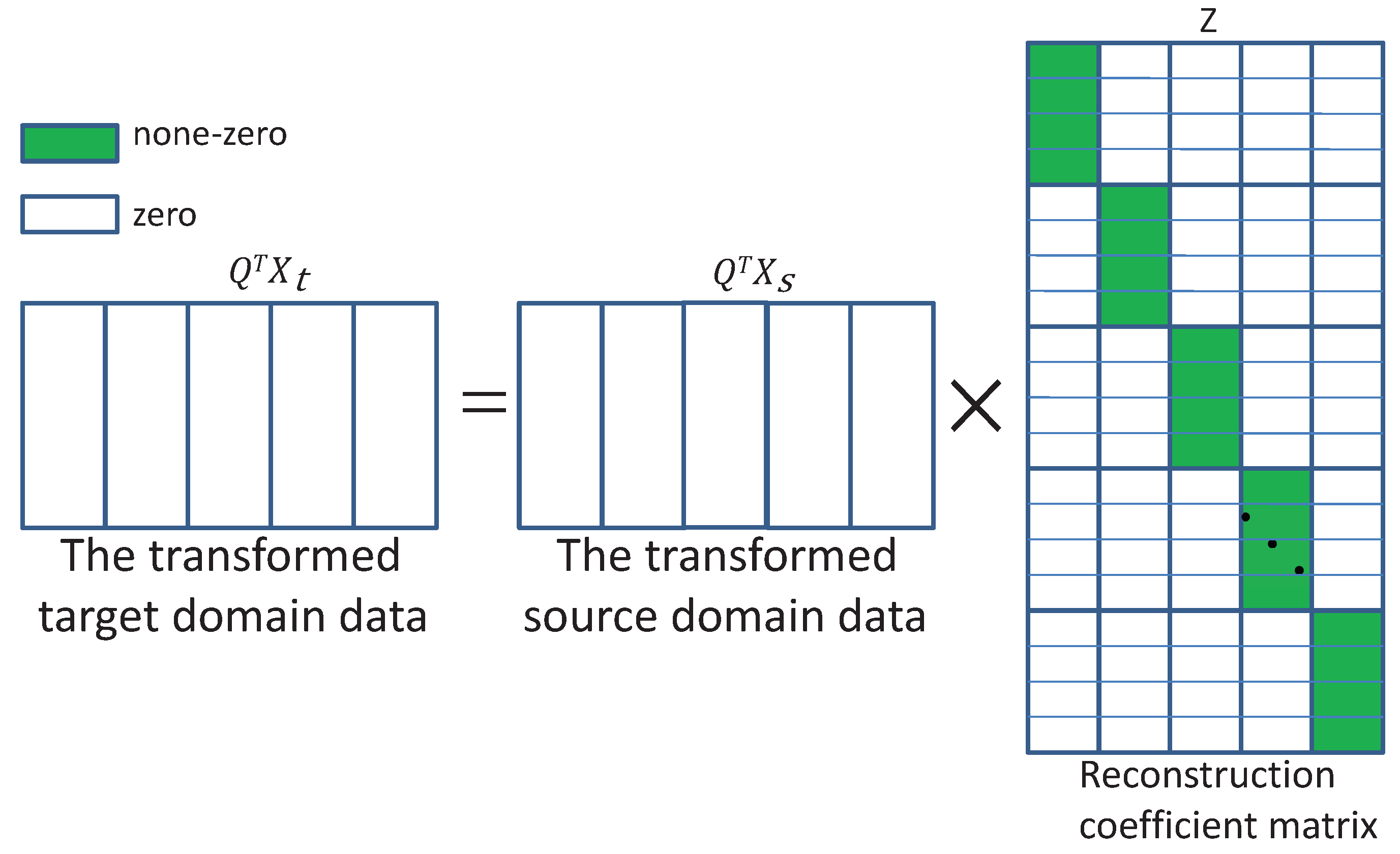
4.6. Visualization Analysis of Matrix Z
4.7. Parameter Sensitivity
4.8. Ablation Studies
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiao, M.; Guo, Y.H. Feature space independent semi-supervised domain adaptation via kernel matching. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 54–66. [Google Scholar] [CrossRef] [PubMed]
- Shao, M.; Kit, D.; Fu, Y. Generalized transfer subspace learning through low-rank constraint. Int. J. Comput. Vis. 2014, 109, 74–93. [Google Scholar] [CrossRef]
- Han, N.; Wu, J.; Fang, X.; Teng, S.; Zhou, G.; Xie, S.; Li, X. Projective Double Reconstructions Based Dictionary Learning Algorithm for Cross-Domain Recognition. IEEE Trans. Image Process. 2020, 29, 9220–9233. [Google Scholar] [CrossRef] [PubMed]
- Jhuo, I.H.; Liu, D.; Lee, D.T.; Chang, S.F. Robust visual domain adaptation with low-rank reconstruction. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2168–2175. [Google Scholar]
- Han, N.; Wu, J.; Fang, X.; Wen, J.; Zhan, S.; Xie, S.; Li, X. Transferable linear discriminant analysis. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5630–5638. [Google Scholar] [CrossRef]
- Wu, X.; Chen, J.; Yu, F.; Yao, M.; Luo, J. Joint Learning of Multiple Latent Domains and Deep Representations for Domain Adaptation. IEEE Trans. Cybern. 2021, 51, 2676–2687. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Long, M.S.; Wang, J.M.; Ding, G.G.; Shen, D.; Yang, Q. Transfer Learning with Graph Co-Regularization. IEEE Trans. Knowl. Data Eng. 2014, 26, 1805–1818. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Fan, Z.Z.; Xu, Y.; Zhang, D. Local linear discriminant analysis framework using sample neighbors. IEEE Trans. Neural Netw. 2011, 22, 1119–1132. [Google Scholar] [CrossRef]
- Fang, X.; Xu, Y.; Li, X.; Fan, Z.; Liu, H.; Chen, Y. Locality and similarity preserving embedding for feature selection. Neurocomputing 2014, 128, 304–315. [Google Scholar] [CrossRef]
- Pan, S.J.; Kwok, J.T.; Yang, Q. Transfer learning via dimensionality reduction. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008), Chicago, IL, USA, 13–17 July 2008; pp. 677–682. [Google Scholar]
- von Bünau, P.; Meinecke, F.C.; Kirúly, F.C.; Müller, K.R. Finding stationary subspaces in multivariate time series. Phys. Rev. Lett. 2009, 103, 214101. [Google Scholar] [CrossRef] [PubMed]
- Suykens, J. Data visualization and dimensionality reduction using kernel maps with a reference point. IEEE Trans. Neural Netw. 2008, 19, 1501–1517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Zhang, L.; Zuo, W.; Zhang, B. Class-specific reconstruction transfer learning for visual recognition across domains. IEEE Trans. Image Process. 2020, 29, 2424–2438. [Google Scholar] [CrossRef] [PubMed]
- Smeulders, A.W.M.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [Green Version]
- Cai, D.; He, X.F.; Han, J.W.; Huang, T. Graph Regularized Non-negative Matrix Factorization for Data Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1548–1560. [Google Scholar]
- Ma, Z.G.; Yang, Y.; Sebe, N.; Hauptmann, A. Knowledge adaptation with partially shared features for event detection using few examplars. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1789–1802. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Ling, S.; Zhu, F.; Li, L.X. Transfer learning for visual categorization: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 1019–1034. [Google Scholar] [CrossRef]
- Long, M.S.; Wan, J.M.; Ding, G.G.; Pan, S.J.; Yu, P.S. Adaptation Regularization: A General Framework for Transfer Learning. IEEE Trans. Knowl. Data Eng. 2014, 26, 1076–1089. [Google Scholar] [CrossRef]
- Jiang, J.; Zhai, C.X. Instance weighting for domain adaptation in NLP. In Proceedings of the 45th Annual Meeting of the Association Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 264–271. [Google Scholar]
- Mihalkova, L.; Huynh, T.; Mooney, R. Mapping and revising markov logic networks for transfer learning. In Proceedings of the 22nd National Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007; pp. 608–614. [Google Scholar]
- Raina, R.; Battle, A.; Lee, H.; Packer, B.; Ng, A. Self-taught learning: Transfer learning from unlabeled data. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 759–766. [Google Scholar]
- Andreas, A.; Evgeniou, T.; Pontil, M. Convex multi-task feature learning. Mach. Learn. 2008, 73, 243–272. [Google Scholar]
- Kouw, W.; Loog, M. A Review of Domain Adaptation without Target Labels. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 766–785. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gopalan, R.; Li, R.; Chellappa, R. Domain adaptation for object recognition: An unsupervised approach. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 18–21 July 2011; pp. 999–1006. [Google Scholar]
- Hoffman, J.; Rodner, E.; Donahue, J.; Darrell, T.; Saenko, K. Efficient learning of domain-invariant image representation. arXiv 2013, arXiv:1301.3224. [Google Scholar]
- Wang, Z.; Song, Y.; Zhang, C. Transferred dimensionality reduction. In Machine Learning and Knowledge Discovery in Databases; Springer: New York, NY, USA, 2008. [Google Scholar]
- Yang, J.; Yan, R.; Hauptmann, A.G. Cross-domain video concept detection using adaptive svms. In Proceedings of the 15th ACM International Conference on Multimedia, New York, NY, USA, 25–29 September 2007; pp. 188–197. [Google Scholar]
- Bruzzone, L.; Marconcini, M. Domain adaptation problems: Adasvm classification technique and a circular validation strategy. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 770–787. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Wang, G.; Dong, S. Learning with progressive transductive support vector machine. Pattern Recognit. Lett. 2003, 24, 1845–1855. [Google Scholar] [CrossRef]
- Xue, Y.; Liao, X.; Carin, L.; Krishnapuram, B. Multi-task learning for classification with dirichlet process priors. J. Mach. Res. 2007, 8, 35–63. [Google Scholar]
- He, X.; Yan, S.; Hu, Y.; Niyogi, P.; Zhang, H. Face recognition using Laplacian faces. IEEE Trans. Pattern Anal. Mach. 2005, 27, 328–340. [Google Scholar]
- He, X.; Cai, D.; Yan, S.; Zhang, H.J. Neighborhood preserving embedding. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; pp. 1208–1213. [Google Scholar]
- Cai, D.; He, X.; Han, J. Isometric projection. In Proceedings of the 22nd National Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007; pp. 528–533. [Google Scholar]
- Chen, H.T.; Chang, H.W.; Liu, T.L. Local discriminant embedding and its variants. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 846–853. [Google Scholar]
- Liu, F.; Zhang, G.; Zhou, J. Heterogeneous Domain Adaptation: An Unsupervised Approach. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5588–5602. [Google Scholar] [CrossRef] [Green Version]
- Ding, Z.; Fu, Y. Robust transfer metric learning for image classification. IEEE Trans. Image Process. 2017, 26, 660–670. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 171–184. [Google Scholar] [CrossRef] [Green Version]
- Si, S.; Tao, D.C.; Geng, B. Bregman divergence-based regularization fro transfer subsapce learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 929–942. [Google Scholar] [CrossRef]
- Eckstein, J.; Bertsekas, D.P. On the Douglas Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 1992, 55, 293–318. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.C.; Liu, R.S.; Su, Z.X. Linearized alternating direction method with adaptive penalty for low rank representation. Adv. Neural Inf. Process. Syst. 2011, 24, 612–620. [Google Scholar]
- Li, X.; Guo, Y.H. Latent semantic representation learning for scence classification. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 532–540. [Google Scholar]
- Ling, X.; Dai, W.; Xue, G.-R.; Yang, Q.; Yu, Y. Spectral domain-transfer learning. In Proceedings of the 14th ACM SIGKDD International Conference on KNOWLEDGE Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Wang, C.; Mahadevan, S. Heterogeneous domain adaptation using manifold alignment. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Shi, X.; Liu, Q.; Fan, W.; Yu, P.S. Transfer across completely different feature spaces via spectral embedding. IEEE Trans. Knowl. Data Eng. 2013, 25, 906–918. [Google Scholar] [CrossRef]
- Long, M.S.; Wang, J.M.; Sun, J.G.; Yu, P.S. Domain Invariant Transfer Kernel Learning. IEEE Trans. Knowl. Data Eng. 2015, 27, 1519–1532. [Google Scholar] [CrossRef]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic Flow Kernel for Unsupervised Domain Adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Long, M.S.; Wang, J.M.; Ding, G.G.; Sun, J.G.; Yu, S. Transfer Joint Matching for Unsupervised Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1410–1417. [Google Scholar]
- Long, M.S.; Wang, J.M.; Ding, G.G.; Sun, J.G.; Yu, P.S. Transfer Feature Learning with Joint Distribution Adaptation. In Proceedings of the IEEE International Conference on COMPUTER Vision, Sydney, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Ghifary, M.; Balduzzi, D.; Kleijn, W.; Zhang, M. Scatter Component Analysis: A Unified Framework for Domain Adaptation and Domain Generalization. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1414–1430. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Fang, X.; Wu, J.; Li, X.; Zhang, D. Discriminative transfer subspace learning via low-rank and sparse representation. IEEE Trans. Image Process. 2016, 25, 850–863. [Google Scholar] [CrossRef]
- Gu, Q.; Li, Z.; Han, J. Joint feature selection and subspace learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Shoeibi, A.; Khodatars, M.; Jafari, M.; Moridian, P.; Rezaei, M.; Alizadehsani, R.; Khozeimeh, F.; Gorriz, J.M.; Heras, J.; Panahiazar, M.; et al. Applications of Deep Learning Techniques for Automated Multiple Sclerosis Detection Using Magnetic Resonance Imaging: A Review. Comput. Biol. Med. 2021, 136, 104697. [Google Scholar] [CrossRef]
- Khodatars, M.; Shoeibi, A.; Sadeghi, D.; Ghaasemi, N.; Jafari, M.; Moridian, P.; Khadem, A.; Alizadehsani, R.; Zare, A.; Kong, Y.; et al. Deep Learning for Neuroimaging-based Diagnosis and Rehabilitation of Autism Spectrum Disorder: A Review. Comput. Biol. Med. 2021, 139, 104949. [Google Scholar] [CrossRef]
- Shoeibi, A.; Sadeghi, D.; Moridian, P.; Ghassemi, N.; Heras, J.; Alizadehsani, R.; Gorriz, J.M. Automatic Diagnosis of Schizophrenia Using EEG signals and CNN-LSTM Models. arXiv 2021, arXiv:2109.01120. [Google Scholar] [CrossRef] [PubMed]
- Sadeghi, D.; Shoeibi, A.; Ghassemi, N.; Moridian, P.; Khadem, A.; Alizadehsani, R.; Teshnehlab, M.; Gorriz, J.M.; Nahavandi, S. An Overview on Artificial Intelligence Techniques for Diagnosis of Schizophrenia Based on Magnetic Resonance Imaging Modalities: Methods, Challenges, and Future Works. arXiv 2021, arXiv:2103.03081. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
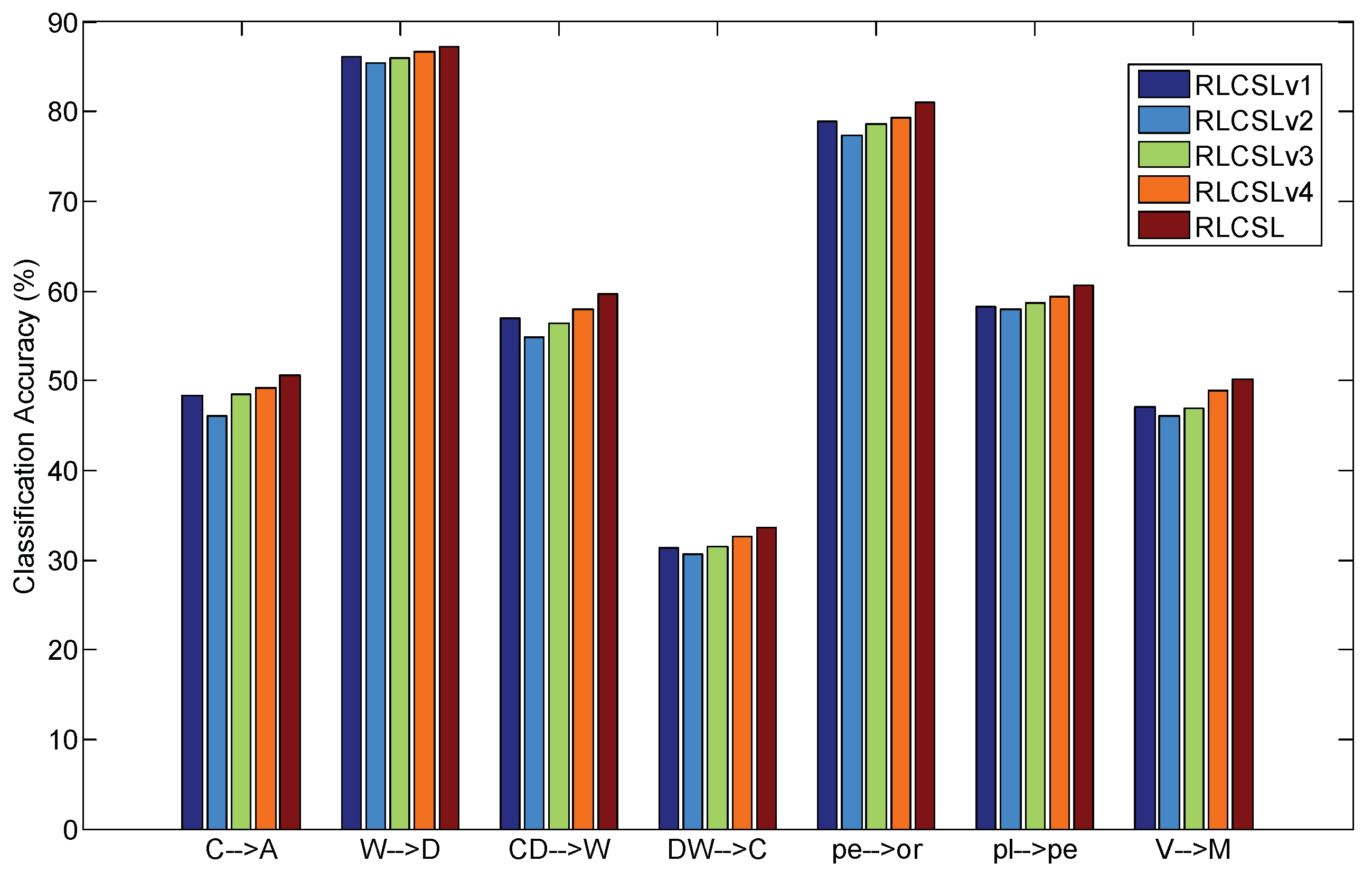{kind=link}
| Variable | Description |
|---|---|
| target domain data matrix | |
| source domain data matrix | |
| binary label matrix | |
| reconstruction coefficient matrix | |
| noise matrix | |
| transformation matrix for label space | |
| transformation matrix for latent common subspace | |
| m | dimension of data |
| number of source domain data | |
| number of target domain data | |
| dimension of latent common subspace |
| Variable | Type | Memory Requirement |
|---|---|---|
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B | |
| Double | 8B |
| Data Set | Subset | Abbr. | #Images | Features | # Classes |
|---|---|---|---|---|---|
| Office-Caltech256 | Amazon Caltech DSLR Webcam | A C D W | 958 1123 157 295 | SURF(800) DeCAF7(4096) | 10 |
| Reuters-21,578 | orgs people place | or pe pl | 1237 1208 1016 | Pixel(4771) | 2 |
| MSRC-VOC2007 | MSRC VOC2007 | M V | 1269 1530 | DSIFT(240) | 6 |
| Dataset | NN | PCA | GFK | TSL | TCA | RDALR | LTSL | SCA | DTSL | JDA | RLCSL |
|---|---|---|---|---|---|---|---|---|---|---|---|
| C→A | 23.70 | 36.95 | 41.02 | 44.47 | 37.89 | 38.20 | 25.26 | 43.74 | 51.25 | 44.78 | 50.52 |
| C→W | 25.76 | 32.54 | 40.68 | 34.24 | 26.78 | 38.64 | 19.32 | 33.56 | 38.64 | 41.69 | 42.71 |
| C→D | 25.48 | 38.22 | 38.85 | 43.31 | 39.49 | 41.40 | 21.02 | 39.49 | 47.13 | 44.59 | 47.13 |
| A→C | 26.00 | 34.73 | 40.25 | 37.58 | 34.73 | 37.76 | 16.92 | 38.29 | 43.37 | 39.36 | 43.37 |
| A→W | 29.83 | 35.59 | 38.98 | 33.90 | 28.47 | 37.63 | 14.58 | 33.90 | 36.61 | 37.97 | 38.98 |
| A→D | 25.48 | 27.39 | 36.31 | 26.11 | 34.39 | 33.12 | 21.02 | 34.21 | 38.85 | 39.49 | 42.67 |
| W→C | 19.86 | 26.36 | 30.72 | 29.83 | 26.36 | 29.30 | 34.64 | 30.63 | 29.83 | 31.17 | 30.45 |
| W→A | 22.96 | 31.00 | 29.75 | 30.27 | 31.00 | 30.06 | 39.56 | 30.48 | 34.13 | 32.78 | 35.69 |
| W→D | 59.24 | 77.07 | 80.89 | 87.26 | 83.44 | 87.26 | 72.61 | 92.36 | 82.80 | 89.17 | 87.26 |
| D→C | 26.27 | 29.65 | 30.28 | 28.50 | 30.28 | 31.70 | 35.08 | 32.32 | 30.11 | 31.70 | 31.70 |
| D→A | 28.50 | 32.05 | 32.05 | 27.56 | 30.90 | 32.15 | 39.67 | 33.72 | 32.05 | 32.15 | 32.67 |
| D→W | 63.39 | 75.93 | 75.59 | 85.42 | 73.22 | 86.10 | 74.92 | 88.81 | 72.20 | 86.10 | 77.29 |
| Average | 31.37 | 39.79 | 42.95 | 42.37 | 39.75 | 43.61 | 34.55 | 44.30 | 44.74 | 45.91 | 46.70 |
| Dataset | NN | PCA | GFK | TSL | RDALR | LTSL | RLCSL |
|---|---|---|---|---|---|---|---|
| A,C→D | 33.76 | 40.13 | 45.86 | 46.50 | 35.67 | 34.39 | 52.23 |
| A,C→W | 31.19 | 37.97 | 39.32 | 33.56 | 28.47 | 27.46 | 42.37 |
| A,D→C | 28.50 | 37.22 | 39.89 | 41.67 | 36.33 | 21.73 | 45.41 |
| A,D→W | 49.15 | 55.25 | 66.78 | 54.24 | 66.78 | 26.78 | 62.71 |
| A,W→C | 27.60 | 35.62 | 37.40 | 42.03 | 36.60 | 26.98 | 45.06 |
| A,W→D | 64.33 | 73.25 | 81.53 | 63.06 | 77.07 | 41.40 | 73.24 |
| C,D→A | 24.32 | 34.55 | 37.27 | 45.20 | 39.56 | 26.30 | 53.86 |
| C,D→W | 34.92 | 48.14 | 65.76 | 50.85 | 60.34 | 29.83 | 59.66 |
| C,W→A | 24.43 | 35.70 | 39.25 | 45.20 | 41.02 | 30.06 | 52.40 |
| C,W→D | 47.13 | 66.24 | 78.98 | 52.23 | 73.89 | 38.22 | 68.78 |
| D,W→A | 29.23 | 35.80 | 38.10 | 34.24 | 32.99 | 37.89 | 38.41 |
| D,W→C | 25.47 | 28.58 | 30.45 | 31.26 | 29.92 | 33.57 | 33.57 |
| Average | 35.00 | 44.04 | 50.05 | 45.00 | 46.55 | 31.22 | 52.30 |
| Dataset | NN | PCA | GFK | TSL | RDALR | LTSL | RLCSL |
|---|---|---|---|---|---|---|---|
| or→pe | 72.85 | 70.53 | 75.00 | 72.52 | 72.85 | / | 76.15 |
| pe→or | 72.03 | 71.22 | 75.91 | 74.54 | 72.03 | / | 81.08 |
| or→pl | 67.50 | 64.43 | 69.80 | 69.51 | 67.50 | / | 73.72 |
| pl→or | 61.12 | 63.29 | 68.21 | 65.35 | 61.12 | / | 69.98 |
| pe→pl | 52.65 | 58.22 | 60.63 | 58.22 | 52.65 | / | 64.81 |
| pl→pe | 53.39 | 58.22 | 59.05 | 57.66 | 53.39 | / | 60.63 |
| Average | 63.26 | 64.32 | 68.10 | 66.30 | 63.25 | / | 71.06 |
| Dataset | NN | PCA | GFK | TSL | RDALR | SCA | DTSL | FSSL | TJM | RLCSL |
|---|---|---|---|---|---|---|---|---|---|---|
| M→V | 28.63 | 28.82 | 28.76 | 30.92 | 28.95 | 32.75 | 34.71 | 29.74 | 32.75 | 35.36 |
| V→M | 48.94 | 49.09 | 48.86 | 47.44 | 48.94 | 48.94 | 53.82 | 37.93 | 49.41 | 50.11 |
| Average | 38.78 | 38.95 | 38.81 | 39.18 | 38.94 | 40.85 | 44.27 | 33.83 | 41.08 | 42.73 |
| Dataset | LTSL | GFK | RDALR | TSL | DTSL | RLCSL |
|---|---|---|---|---|---|---|
| M→V | 413.61 | 6.95 | 51.97 | 459.59 | 355.84 | 375.42 |
| A→D | 32.27 | 9.74 | 7.40 | 59.60 | 51.60 | 10.38 |
| C→W | 37.23 | 10.71 | 5.37 | 61.44 | 62.08 | 17.80 |
| A→D(CNN) | 301.13 | 290.12 | 101.23 | 424.23 | 436.65 | 118.37 |
| C→W(CNN) | 293.46 | 302.34 | 104.37 | 461.28 | 472.59 | 109.18 |
| Average | 215.54 | 123.97 | 54.06 | 293.22 | 275.75 | 126.23 |
| Comparison Perspective | JDA | TCA | RDALR | LTSL | DTSL | RLCSL |
|---|---|---|---|---|---|---|
| Data Reconstruction | √ | √ | √ | √ | √ | |
| Low-Rank Constraint | √ | √ | √ | √ | ||
| Sparse Constraint | √ | √ | ||||
| Low-Rank and Sparse Constraints | √ | √ | ||||
| Subspace Learning | √ | √ | √ | √ | √ | √ |
| Convex Optimization | √ | √ | ||||
| Classifier Learning | √ | √ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, S.; Sun, W.; Kang, P. Robust Latent Common Subspace Learning for Transferable Feature Representation. Electronics 2022, 11, 810. https://doi.org/10.3390/electronics11050810
Zhan S, Sun W, Kang P. Robust Latent Common Subspace Learning for Transferable Feature Representation. Electronics. 2022; 11(5):810. https://doi.org/10.3390/electronics11050810
Chicago/Turabian StyleZhan, Shanhua, Weijun Sun, and Peipei Kang. 2022. "Robust Latent Common Subspace Learning for Transferable Feature Representation" Electronics 11, no. 5: 810. https://doi.org/10.3390/electronics11050810
APA StyleZhan, S., Sun, W., & Kang, P. (2022). Robust Latent Common Subspace Learning for Transferable Feature Representation. Electronics, 11(5), 810. https://doi.org/10.3390/electronics11050810