


Human-Computer Interaction System: A Survey of Talking-Head Generation


Abstract
:1. Introduction
- We present a systematic framework for multimodal human–computer interaction, which provides a new idea for the application of talking-head generation models.
- We propose two taxonomies to group methods with important reference significance and analyze the strengths and weaknesses of representative methods and their potential connections.
- We summarize the datasets and evaluation metrics commonly used for talking-head generation models. Meanwhile, we highlight the significance of the consumption time to generate videos as a measure of model performance.
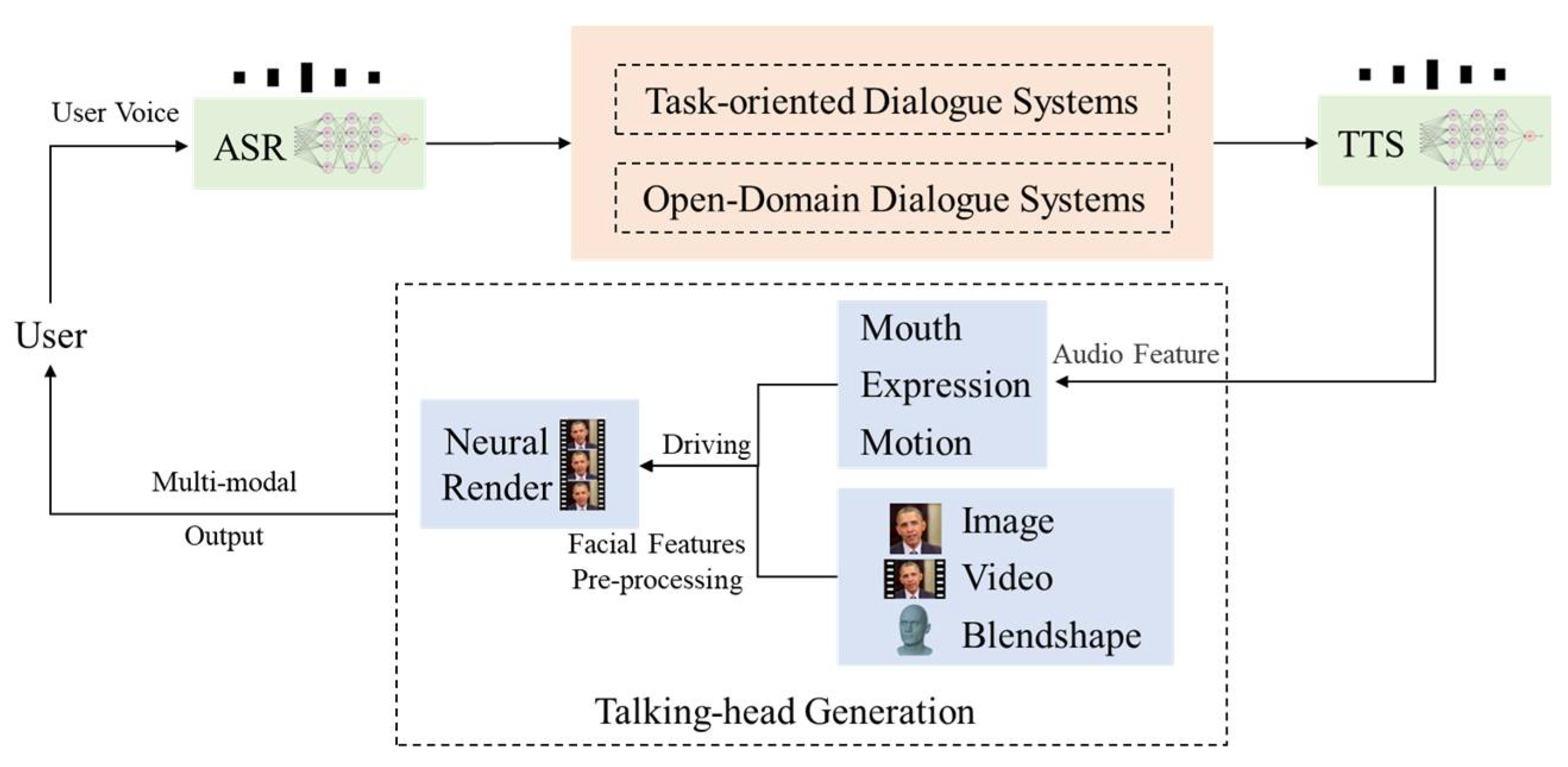
2. Human–Computer Interaction System Architecture
2.1. Speech Module
2.2. Dialogue System Module
2.3. Talking-Head Generation
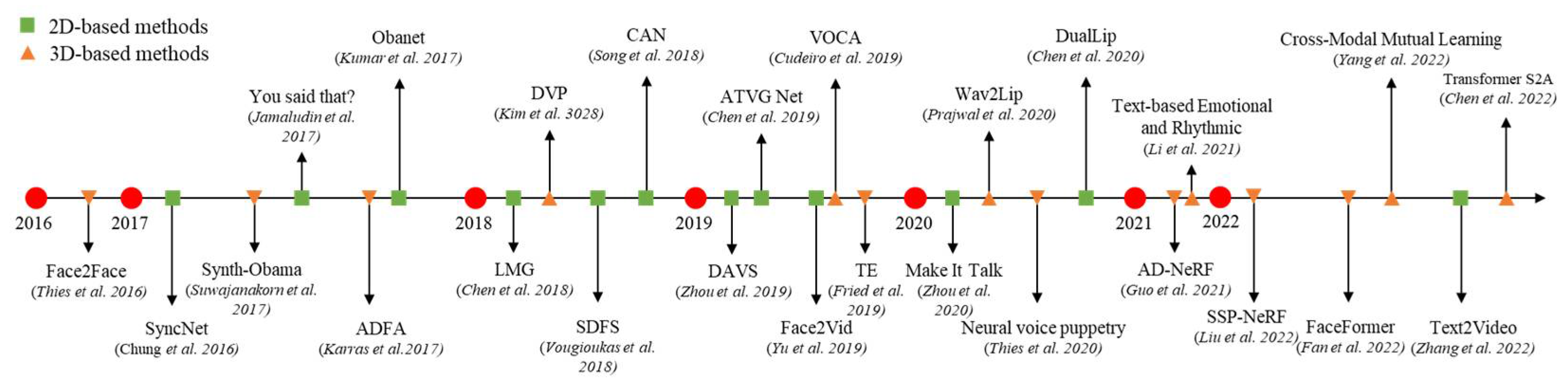
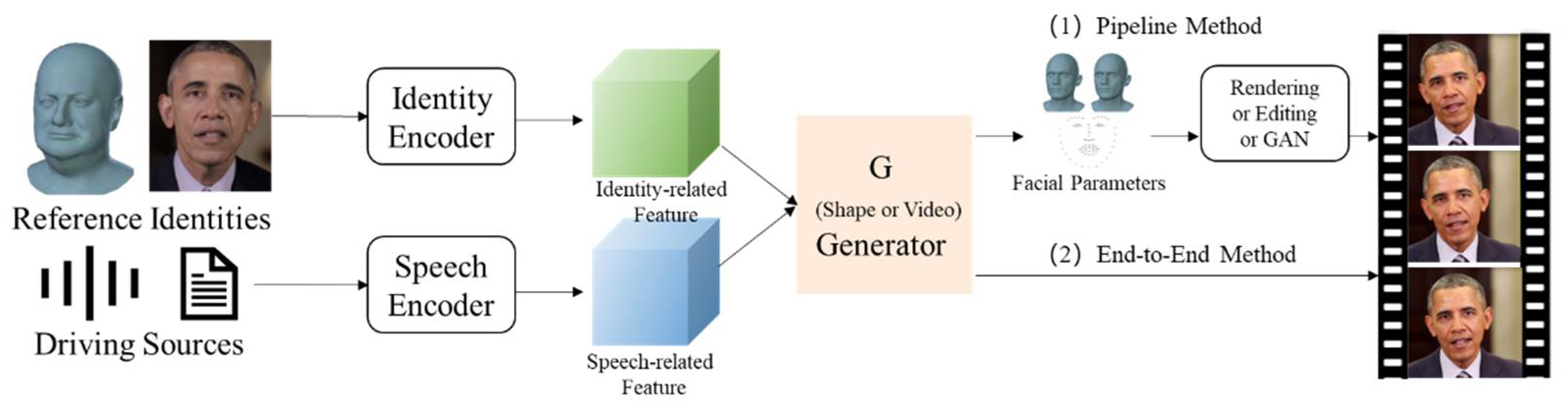
3. Talking-Head Generation
- (1)
- 2D-based methods.
- (2)
- 3D-based methods.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Key Idea | Driving Factor | ID D/I | 3D Model |
|---|---|---|---|---|
| Suwajanakorn [8] | Audio-to-mouth editing to video | A | D | 3D |
| Karras [10] | From audio and emotion-state to 3D vertices | A | D | 3D |
| Kumar [11] | Text-to-audio-to-mouth key-points to video | T | D | 2D |
| [9,12] | Joint embedding of audio and identity features | A | I | 2D |
| Kim [13] | DVP: parameter replacement and facial reenactment with cGAN to video | V | I | 3D |
| Vougioukas [14] | Audio-driven GAN | A | I | 2D |
| Zhou [16] | Joint embedding of person-id and word-id features | V or A | I | 2D |
| Chen [17] | From Audio to facial landmarks to video synthesis | A | I | 2D |
| Yu [18] | From text or audio feature to facial landmarks to video synthesis | A and T | I | 2D |
| Cudeiro [19] | VOCA: from audio to FLAME head model with facial motions | A | I | 3D |
| Fried [20] | 3D reconstruction and parameter recombination | T | D | 3D |
| Zhou [21] | Audio-driven landmark prediction | A | I | 2D |
| Prajwal [22] | Wav2Lip: audio-driven, based GAN lip-sync discriminator | A | I | 2D |
| Thies [23] | NVP: from the fusion of audio expression feature extraction and intermediate 3D model to video | A | H | 3D |
| Guo [25] | AD-NeRF: Audio-to-video generation via two individual neural radiance fields | A | D | 3D |
| Li [26] | TE: text-driven to video generation combine phoneme alignment, viseme search and parameter blending | T | D | 3D |
| Fan [28] | FaceFormer: Audio-to-3D Mesh to video | A | I | 3D |
| Yang [29] | A unified framework for visual-to-speech recognition and audio-to-video synthesis | A | I | 3D |
| Zhang [30] | Text2Video: GAN+phoneme-pose dictionary | T | I | 3D |
3.1. Problem Formulation
- In generating talking-head videos using GAN, wav2lip [22] proposes the expert lip-sync discriminator based on SyncNet, and the formula is as follows:
- 2.
- In generating talking-head videos using ViT, FaceFormer [28] propose a novel seq2seq architecture to autoregressively predict facial movements, and the formula is as follows:
- 3.
- NeRF is a powerful and elegant 3D scene representation framework. It can encode the scene into a 3D volume space using MLP and then renders the 3D volume into an image by integrating color and densities along camera rays. The formula is as follows:
3.2. Pipeline
3.2.1. Landmark-Based Method
3.2.2. Coefficients-Based Method
3.2.3. Vertex-Based Method
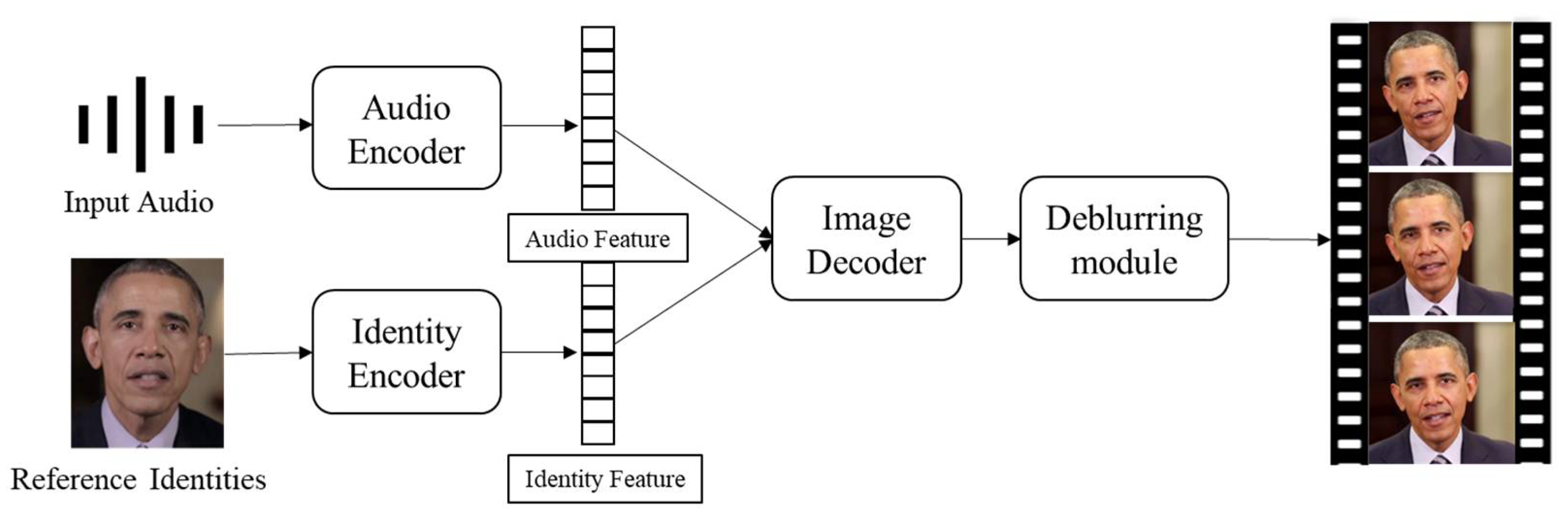
3.3. End-to-End
4. Datasets and Evaluation Metrics
4.1. Datasets
4.2. Evaluation Metrics
5. Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Garrido, P.; Valgaerts, L.; Sarmadi, H.; Steiner, I.; Varanasi, K.; Perez, P.; Theobalt, C. Vdub: Modifying face video of actors for plausible visual alignment to a dubbed audio track. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2015; Volume 34, pp. 193–204. [Google Scholar]
- Garrido, P.; Valgaerts, L.; Rehmsen, O.; Thormahlen, T.; Perez, P.; Theobalt, C. Automatic face reenactment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 4217–4224. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2387–2395. [Google Scholar]
- Bregler, C.; Covell, M.; Slaney, M. Video rewrite: Driving visual speech with audio. In Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 3–8 August 1997; pp. 353–360. [Google Scholar]
- Xie, L.; Liu, Z.Q. Realistic mouth-synching for speech-driven talking face using articulatory modelling. IEEE Trans. Multimed. 2007, 9, 500–510. [Google Scholar]
- Ye, Z.; Xia, M.; Yi, R.; Zhang, J.; Lai, Y.K.; Huang, X.; Zhang, G.; Liu, Y.J. Audio-driven talking face video generation with dynamic convolution kernels. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Out of time: Automated lip sync in the wild. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2017; pp. 251–263. [Google Scholar]
- Suwajanakorn, S.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Synthesizing obama: Learning lip sync from audio. ACM Trans. Graph. (ToG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Chung, J.S.; Jamaludin, A.; Zisserman, A. You said that? arXiv 2017, arXiv:1705.02966. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Herva, A.; Lehtinen, J. Audio-driven facial animation by joint end-to-end learning of pose and emotion. ACM Trans. Graph. (ToG) 2017, 36, 1–12. [Google Scholar] [CrossRef]
- Kumar, R.; Sotelo, J.; Kumar, K.; de Brébisson, A.; Bengio, Y. Obamanet: Photo-realistic lip-sync from text. arXiv 2017, arXiv:1801.01442. [Google Scholar]
- Chen, L.; Li, Z.; Maddox, R.K.; Duan, Z.; Xu, C. Lip movements generation at a glance. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 520–535. [Google Scholar]
- Kim, H.; Garrido, P.; Tewari, A.; Xu, W.; Thies, J.; Niessner, M.; Pérez, P.; Richardt, C.; Zollhöfer, M.; Theobalt, C. Deep video portraits. ACM Trans. Graph. (ToG) 2018, 37(4), 1–14. [Google Scholar] [CrossRef]
- Vougioukas, K.; Petridis, S.; Pantic, M. End-to-end speech-driven facial animation with temporal gans. arXiv 2018, arXiv:1805.09313. [Google Scholar]
- Song, Y.; Zhu, J.; Li, D.; Wang, X.; Qi, H. Talking face generation by conditional recurrent adversarial network. arXiv 2018, arXiv:1804.04786. [Google Scholar]
- Zhou, H.; Liu, Y.; Liu, Z.; Luo, P.; Wang, X. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 8–12 October 2019; 33, pp. 9299–9306. [Google Scholar]
- Chen, L.; Maddox, R.K.; Duan, Z.; Xu, C. Hierarchical cross-modal talking face generation with dynamic pixel-wise loss. In Proceedings of the IEEE/CVF Conference on Cmputer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7832–7841. [Google Scholar]
- Yu, L.; Yu, J.; Ling, Q. Mining audio, text and visual information for talking face generation. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; IEEE: Manhattan, NY, USA, 2019; pp. 787–795. [Google Scholar]
- Cudeiro, D.; Bolkart, T.; Laidlaw, C.; Ranjan, A.; Black, M.J. Capture, learning, and synthesis of 3D speaking styles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10101–10111. [Google Scholar]
- Fried, O.; Tewari, A.; Zollhöfer, M.; Finkelstein, A.; Shechtman, E.; Goldman, D.B.; Genova, K.; Jin, Z.; Theobalt, C.; Agrawala, M. Text-based editing of talking-head video. ACM Trans. Graph. (ToG) 2019, 38, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Han, X.; Shechtman, E.; Echevarria, J.; Kalogerakis, E.; Li, D. Makelttalk: Speaker-aware talking-head animation. ACM Trans. Graph. (ToG) 2020, 39, 1–15. [Google Scholar] [CrossRef]
- Prajwal, K.R.; Mukhopadhyay, R.; Namboodiri, V.P.; Jawahar, C.V. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 484–492. [Google Scholar]
- Thies, J.; Elgharib, M.; Tewari, A.; Theobalt, C.; Nießner, M. Neural voice puppetry: Audio-driven facial reenactment. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 716–731. [Google Scholar]
- Chen, W.; Tan, X.; Xia, Y.; Qin, T.; Wang, Y.; Liu, T.Y. DualLip: A system for joint lip reading and generation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1985–1993. [Google Scholar]
- Guo, Y.; Chen, K.; Liang, S.; Liu, Y.J.; Bao, H.; Zhang, J. Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Li, L.; Wang, S.; Zhang, Z.; Ding, Y.; Zheng, Y.; Yu, X.; Fan, C. Write-a-speaker: Text-based emotional and rhythmic talking-head generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2–8 February 2021; pp. 1911–1920. [Google Scholar]
- Liu, X.; Xu, Y.; Wu, Q.; Zhou, H.; Wu, W.; Zhou, B. Semantic-aware implicit neural audio-driven video portrait generation. arXiv 2022, arXiv:2201.07786. [Google Scholar]
- Fan, Y.; Lin, Z.; Saito, J.; Wang, W.; Komura, T. FaceFormer: Speech-Driven 3D Facial Animation with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 18770–18780. [Google Scholar]
- Yang, C.C.; Fan, W.C.; Yang, C.F.; Wang, Y.C.F. Cross-Modal Mutual Learning for Audio-Visual Speech Recognition and Manipulation. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 22. [Google Scholar]
- Zhang, S.; Yuan, J.; Liao, M.; Zhang, L. Text2video: Text-Driven Talking-Head Video Synthesis with Personalized Phoneme-Pose Dictionary. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE: Manhattan, NY, USA, 2022; pp. 2659–2663. [Google Scholar]
- Chen, L.; Wu, Z.; Ling, J.; Li, R.; Tan, X.; Zhao, S. Transformer-S2A: Robust and Efficient Speech-to-Animation. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE: Manhattan, NY, USA, 2022; pp. 7247–7251. [Google Scholar]
- Zhang, H.; Yuan, T.; Chen, J.; Li, X.; Zheng, R.; Huang, Y.; Chen, X.; Gong, E.; Chen, Z.; Hu, X.; et al. PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit. arXiv 2022, arXiv:2205.12007. [Google Scholar]
- Shen, T.; Zuo, J.; Shi, F.; Zhang, J.; Jiang, L.; Chen, M.; Zhang, Z.; Zhang, W.; He, X.; Mei, T. ViDA-MAN: Visual Dialog with Digital Humans. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 2789–2791. [Google Scholar]
- Sheng, C.; Kuang, G.; Bai, L.; Hou, C.; Guo, Y.; Xu, X.; Pietikäinen, M.; Liu, L. Deep Learning for Visual Speech Analysis: A Survey. arXiv 2022, arXiv:2205.10839. [Google Scholar]
- Jamaludin, A.; Chung, J.S.; Zisserman, A. You said that? Synthesising talking faces from audio. Int. J. Comput. Vis. 2019, 127, 1767–1779. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Bolkart, T.; Black, M.J.; Li, H.; Romero, J. Learning a model of facial shape and expression from 4D scans. ACM Trans. Graph. 2017, 36, 194-1. [Google Scholar] [CrossRef] [Green Version]
- Richard, A.; Zollhöfer, M.; Wen, Y.; De la Torre, F.; Sheikh, Y. Meshtalk: 3d face animation from speech using cross-modality disentanglement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1173–1182. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Garbin, S.J.; Kowalski, M.; Johnson, M.; Shotton, J.; Valentin, J. Fastnerf: High-fidelity neural rendering at 200fps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14346–14355. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. arXiv 2022, arXiv:2201.05989. [Google Scholar] [CrossRef]
- Li, R.; Tancik, M.; Kanazawa, A. NerfAcc: A General NeRF Acceleration Toolbo. arXiv 2022, arXiv:2210.04847. [Google Scholar]
- KR, P.; Mukhopadhyay, R.; Philip, J.; Jha, A.; Namboodiri, V.; Jawahar, C.V. Towards automatic face-to-face translation. In Proceedings of the 27th ACM international conference on multimedia, Nice, France, 21–25 October 2019; pp. 1428–1436. [Google Scholar]
- Song, L.; Wu, W.; Qian, C.; He, R.; Loy, C.C. Everybody’s talkin’: Let me talk as you want. IEEE Trans. Inf. Forensics Secur. 2022, 17, 585–598. [Google Scholar] [CrossRef]
- Wang, K.; Wu, Q.; Song, L.; Yang, Z.; Wu, W.; Qian, C.; He, R.; Qiao, Y.; Loy, C.C. Mead: A large-scale audio-visual dataset for emotional talking-face generation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 700–717. [Google Scholar]
- Jalalifar, S.A.; Hasani, H.; Aghajan, H. Speech-driven facial reenactment using conditional generative adversarial networks. arXiv 2018, arXiv:1803.07461. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Fan, B.; Wang, L.; Soong, F.K.; Xie, L. Photo-real talking head with deep bidirectional LSTM. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE: Manhattan, NY, USA, 2015; pp. 4884–4888. [Google Scholar]
- Pham, H.X.; Cheung, S.; Pavlovic, V. Speech-driven 3D facial animation with implicit emotional awareness: A deep learning approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 80–88. [Google Scholar]
- Tzirakis, P.; Papaioannou, A.; Lattas, A.; Tarasiou, M.; Schuller, B.; Zafeiriou, S. Synthesising 3D facial motion from “in-the-wild” speech. In 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020); IEEE: Manhattan, NY, USA, 2020; pp. 265–272. [Google Scholar]
- Deng, Y.; Yang, J.; Xu, S.; Chen, D.; Jia, Y.; Tong, X. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, Z.; Li, L.; Ding, Y.; Fan, C. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. pp. 3661–3670. [Google Scholar]
- Ji, X.; Zhou, H.; Wang, K.; Wu, W.; Loy, C.C.; Cao, X.; Xu, F. Audio-driven emotional video portraits. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14080–14089. [Google Scholar]
- Si, S.; Wang, J.; Qu, X.; Cheng, N.; Wei, W.; Zhu, X.; Xiao, J. Speech2video: Cross-modal distillation for speech to video generation. arXiv 2021, arXiv:2107.04806. [Google Scholar]
- Sun, Y.; Zhou, H.; Liu, Z.; Koike, H. Speech2Talking-Face: Inferring and Driving a Face with Synchronized Audio-Visual Representation. IJCAI 2021, 2, 4. [Google Scholar]
- Vougioukas, K.; Petridis, S.; Pantic, M. End-to-End Speech-Driven Realistic Facial Animation with Temporal GANs. In CVPR Workshops; CVF: New York, NY, USA, 2019; pp. 37–40. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, Y.; Huang, Y.; Zeng, M.; Ni, S.; Budagavi, M.; Guo, X. Facial: Synthesizing dynamic talking face with implicit attribute learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3867–3876. [Google Scholar]
- Sadoughi, N.; Busso, C. Speech-driven expressive talking lips with conditional sequential generative adversarial networks. IEEE Trans. Affect. Comput. 2019, 12, 1031–1044. [Google Scholar] [CrossRef] [Green Version]
- Eskimez, S.E.; Zhang, Y.; Duan, Z. Speech driven talking face generation from a single image and an emotion condition. IEEE Trans. Multimed. 2022, 24, 3480–3490. [Google Scholar] [CrossRef]
- Zhou, H.; Sun, Y.; Wu, W.; Loy, C.C.; Wang, X.; Liu, Z. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4176–4186. [Google Scholar]
- Ji, X.; Zhou, H.; Wang, K.; Wu, Q.; Wu, W.; Xu, F.; Cao, X. EAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model. arXiv 2022, arXiv:2205.15278. [Google Scholar]
- Biswas, S.; Sinha, S.; Das, D.; Bhowmick, B. Realistic talking face animation with speech-induced head motion. In Proceedings of the Twelfth Indian Conference on Computer Vision, Graphics and Image Processing, Jodhpur, India, 19–22 December 2021; pp. 1–9. [Google Scholar]
- Waibel, A.; Behr, M.; Eyiokur, F.I.; Yaman, D.; Nguyen, T.N.; Mullov, C.; Demirtas, M.A.; Kantarcı, A.; Constantin, H.; Ekenel, H.K. Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos. arXiv 2022, arXiv:2206.04523. [Google Scholar]
- Hong, Y.; Peng, B.; Xiao, H.; Liu, L.; Zhang, J. Headnerf: A real-time nerf-based parametric head model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 20374–20384. [Google Scholar]
- Neff, T.; Stadlbauer, P.; Parger, M.; Kurz, A.; Mueller, J.H.; Chaitanya, C.R.A.; Kaplanyan, A.; Steinberger, M. DONeRF: Towards Real-Time Rendering of Compact Neural Radiance Fields using Depth Oracle Networks. In Computer Graphics Forum; Wiley-Blackwell: Hoboken, NJ, USA, 2021; Volume 40, pp. 45–59. [Google Scholar]
- Yu, A.; Li, R.; Tancik, M.; Li, H.; Ng, R.; Kanazawa, A. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5752–5761. [Google Scholar]
- Yao, S.; Zhong, R.; Yan, Y.; Zhai, G.; Yang, X. DFA-NeRF: Personalized Talking Head Generation via Disentangled Face Attributes Neural Rendering. arXiv 2022, arXiv:2201.00791. [Google Scholar]
- Cooke, M.; Barker, J.; Cunningham, S.; Shao, X. An audio-visual corpus for speech perception and automatic speech recognition. J. Acoust. Soc. Am. 2006, 120, 2421–2424. [Google Scholar] [CrossRef] [Green Version]
- Chung, J.S.; Zisserman, A. Lip reading in the wild. In Asian conference on computer vision. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2017; pp. 87–103. [Google Scholar]
- Yang, S.; Zhang, Y.; Feng, D.; Yang, M.; Wang, C.; Xiao, J.; Long, K.; Shan, S.; Chen, X. LRW-1000: A naturally-distributed large-scale benchmark for lip reading in the wild. In 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019); IEEE: Manhattan, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. Voxceleb2: Deep speaker recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Chen, L.; Cui, G.; Kou, Z.; Zheng, H.; Xu, C. What comprises a good talking-head video generation? A survey and benchmar. arXiv 2020, arXiv:2005.03201. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6626–6637. [Google Scholar]
- Lu, Y.; Chai, J.; Cao, X. Live speech portraits: Real-time photorealistic talking-head animation. ACM Trans. Graph. (TOG) 2021, 40, 1–17. [Google Scholar] [CrossRef]
- Zhen, R.; Song, W.; Cao, J. Research on the Application of Virtual Human Synthesis Technology in Human-Computer Interaction. In 2022 IEEE/ACIS 22nd International Conference on Computer and Information Science (ICIS); IEEE: Manhattan, NY, USA, 2022; pp. 199–204. [Google Scholar]
- Wiles, O.; Koepke, A.; Zisserman, A. X2face: A network for controlling face generation using images, audio, and pose codes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–17 September 2018; pp. 670–686. [Google Scholar]
- Liu, L.; Xu, W.; Zollhoefer, M.; Kim, H.; Bernard, F.; Habermann, M.; Wang, W.; Theobalt, C. Neural animation and reenactment of human actor videos. arXiv 2018, arXiv:1809.03658. [Google Scholar]
- Martin-Brualla, R.; Radwan, N.; Sajjadi, M.S.; Barron, J.T.; Dosovitskiy, A.; Duckworth, D. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7210–7219. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE: Manhattan, NY, USA, 2016; pp. 4960–4964. [Google Scholar]




| Dataset Name | Year | Hours | Image Size FPS | Speaker | Sentence | Head Movement | Envir. |
|---|---|---|---|---|---|---|---|
| GRID | 2006 | 27.5 | 720 × 576, 25 | 33 | 33 k | N | Lab |
| LRW | 2017 | 173 | 256 × 256, 25 | 1 k+ | 539 K | N | TV |
| ObamaSet | 2017 | 14 | N/A | 1 | N/A | Y | TV |
| VoxCeleb2 | 2018 | 2.4 k | N/A, 25 | 6.1 k+ | 153.5 K | Y | TV |
| LRW-1000 | 2019 | 57 | N/A | 2 K+ | 718 K | Y | TV |
| VOCASET | 2019 | N/A | 5023 vertices, 60 | 12 | 255 | Y | Lab |
| MEAD | 2020 | 39 | 1920 × 1080, 30 | 60 | 20 | Y | Lab |
| HDTF | 2021 | 15.8 | N/A | 362 | 10 K | Y | TV |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhen, R.; Song, W.; He, Q.; Cao, J.; Shi, L.; Luo, J. Human-Computer Interaction System: A Survey of Talking-Head Generation. Electronics 2023, 12, 218. https://doi.org/10.3390/electronics12010218
Zhen R, Song W, He Q, Cao J, Shi L, Luo J. Human-Computer Interaction System: A Survey of Talking-Head Generation. Electronics. 2023; 12(1):218. https://doi.org/10.3390/electronics12010218
Chicago/Turabian StyleZhen, Rui, Wenchao Song, Qiang He, Juan Cao, Lei Shi, and Jia Luo. 2023. "Human-Computer Interaction System: A Survey of Talking-Head Generation" Electronics 12, no. 1: 218. https://doi.org/10.3390/electronics12010218
APA StyleZhen, R., Song, W., He, Q., Cao, J., Shi, L., & Luo, J. (2023). Human-Computer Interaction System: A Survey of Talking-Head Generation. Electronics, 12(1), 218. https://doi.org/10.3390/electronics12010218