
Signature and Log-Signature for the Study of Empirical Distributions Generated with GANs





Abstract
:1. Introduction
2. Overview and Related Work
3. Generative Adversarial Networks
3.1. GAN Architecture
3.2. GAN Training
3.3. GAN Convergence
- LPIPS (Learned Perceptual Image Patch Similarity) is a perceptual similarity metric introduced in [69]. It computes the similarity between two images by comparing their feature representations in a deep neural network (typically pretrained on a large-scale image classification task). The metric has been shown to correlate well with human perceptual judgments of image similarity, and it has been used in various image synthesis and image quality assessment tasks.
- PSNR (Peak Signal-to-Noise Ratio) is a widely-used metric for image quality assessment, particularly in the field of image compression. It is a simple, easy-to-compute measure that compares the maximum possible power of a signal (in this case, an image) to the power of the corrupting noise (differences between the reference and distorted images). It is calculated as the logarithmic ratio of the maximum possible pixel value squared to the mean squared error (MSE) between the reference and distorted images. Although PSNR is widely used, it has been criticized for not always correlating well with human perception of image quality, as it is based on pixel-wise differences and does not consider higher-level semantic or structural features.
3.4. Stylegan2-ADA
3.5. Fréchet Inception Distance (FID)
3.6. Inception Score (IS)
4. Non-Parametric Statistical Analysis: Kruskal–Wallis
Kruskal–Wallis
- Non-parametric nature: Kruskal–Wallis is a non-parametric test, meaning it does not rely on any assumptions about the underlying distribution of the data. This is particularly important when dealing with GAN-generated images, as the distributions of the generated samples may not necessarily follow a known parametric form, especially during the early stages of training. The non-parametric nature allows us to compare the goodness of fit between the generated and target distributions without making restrictive assumptions about their forms.
- Robustness: Kruskal–Wallis is robust against outliers and deviations from normality, which can be a common occurrence in the context of GAN-generated images. As the test is based on the ranks of the data rather than the raw values, it is less sensitive to extreme values that may arise from the generative process.
- Multiple group comparison: Kruskal–Wallis allows us to compare more than two groups simultaneously, which is useful when evaluating multiple GAN models or different categories within a dataset. This capability makes the test a versatile choice for our study, as it enables us to compare the performance of various GAN models on different datasets in a single analysis.
- Scalability: Kruskal–Wallis is computationally efficient, making it suitable for the large-scale datasets that are often encountered in GAN research. Its computational efficiency allows for the rapid evaluation of GAN-generated images and their convergence, which is a key advantage of our proposed methodology.
5. The Signature Transform
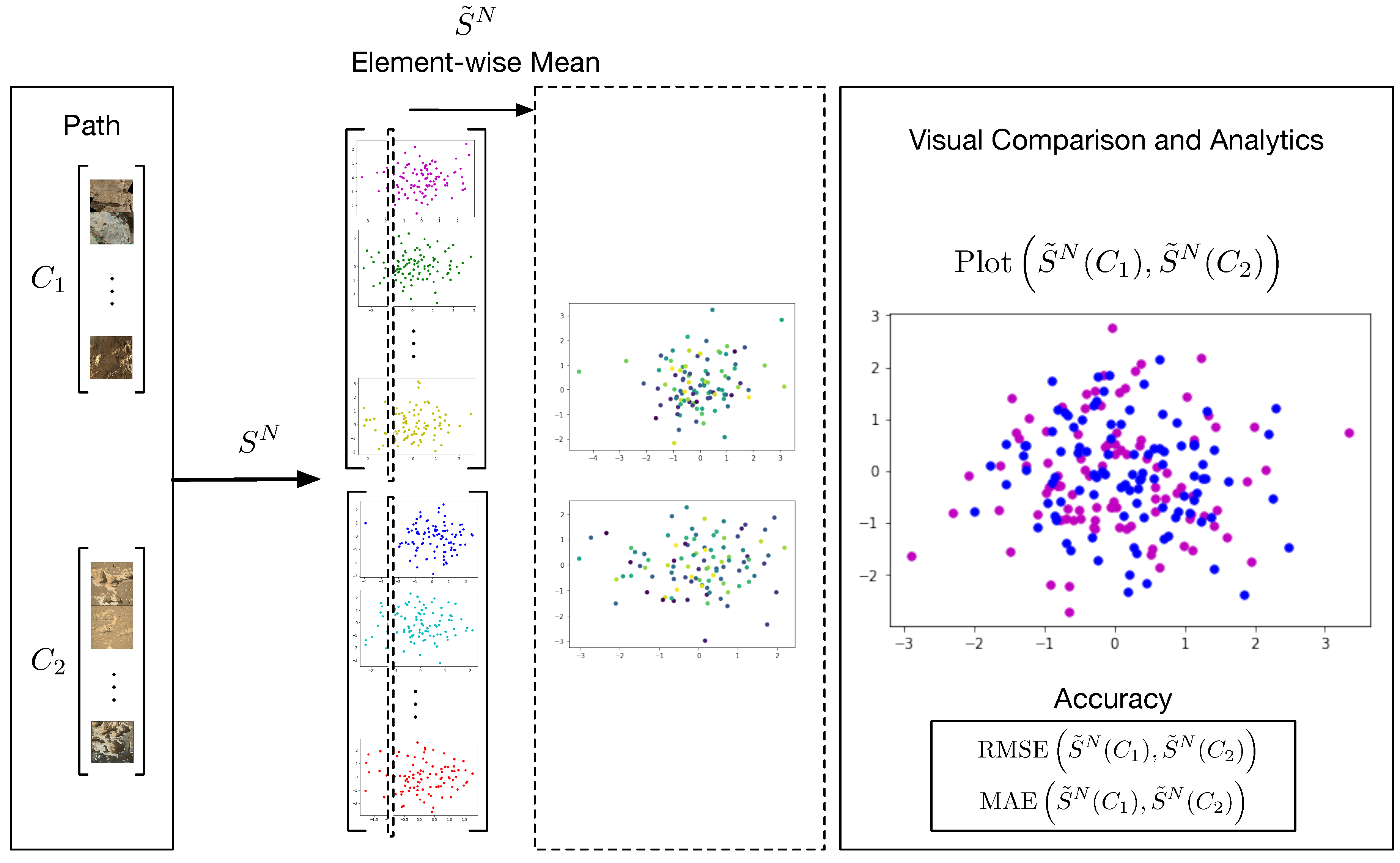
6. Methodology
6.1. Statistical Analysis of the Generated Distribution
- (a)
- Necessary condition but not sufficient to assert that both populations originate from the same distribution.
- (b)
- There is not enough statistical evidence to attest both populations’ samples originate from the same distribution.
- (c)
- With high probability the synthetic distribution generated is still close enough to the initial distribution of noise from the GAN architecture. The samples may not show enough fidelity, and there is probably bad generalization behavior.
- (d)
- The synthetic distribution is far from the initial distribution of noise and has deviated from the original Normal, and may be close to the target distribution.
- (e)
- If (a) then there is enough statistical evidence to confirm that both populations originate from the same distribution given this image descriptor. If (a) is not fulfilled, then we can only ascertain that the synthetic population is a good approximation.
- (f)
- There is not enough statistical evidence to attest both populations are from the same distribution.
6.2. RMSE and MAE Signature and Log-Signature
7. Evaluation
7.1. Computational Complexity
- Element-wise mean of the Signatures: The computation of the Signature Transform has a time complexity of , where L is the length of the path and M is the order of the signature. However, since we are computing the element-wise mean of the Signatures, the complexity becomes , where N is the number of samples. In practice, the Signature Transform can be efficiently computed using recursive algorithms, which keeps the computational cost low.
- Kruskal–Wallis has a time complexity of for sorting the samples, followed by for computing the test statistic, resulting in an overall complexity of . This complexity is relatively low, especially when compared to more computationally demanding metrics such as FID and MS-SSIM.
- The FID calculation involves computing the Inception features for each sample, which requires a forward pass through a deep neural network, followed by computing the mean and covariance of these features. The complexity of the forward pass depends on the architecture of the Inception network, but it is generally much higher than the complexity of the Signature Transform and the Kruskal–Wallis. Additionally, FID requires GPU resources to perform these calculations efficiently, further increasing its computational cost.
- MS-SSIM involves computing the structural similarity index at multiple scales, which requires computing the mean, variance, and covariance for each scale. The complexity of MS-SSIM is , where W and H are the width and height of the images, respectively, whereas this complexity is not as high as FID, it is still higher than the complexities of the proposed methods.
- LPIPS metric computes the distance between image features extracted from a pretrained deep neural network (e.g., AlexNet or VGG). The complexity of LPIPS is primarily determined by the forward pass through the chosen deep neural network. The complexity of the forward pass depends on the architecture of the network, but in general, it is higher than the complexity of the Signature Transform and the Kruskal–Wallis. Similar to FID, LPIPS also typically requires GPU resources for efficient computation.
- PSNR is a simple and widely used metric for image quality assessment. It is computed as the ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation. The complexity of PSNR is , where W and H are the width and height of the images, respectively. Although the complexity of PSNR is similar to that of MS-SSIM, it is still higher than the complexities of the proposed methods (element-wise mean of the Signatures and Kruskal–Wallis).
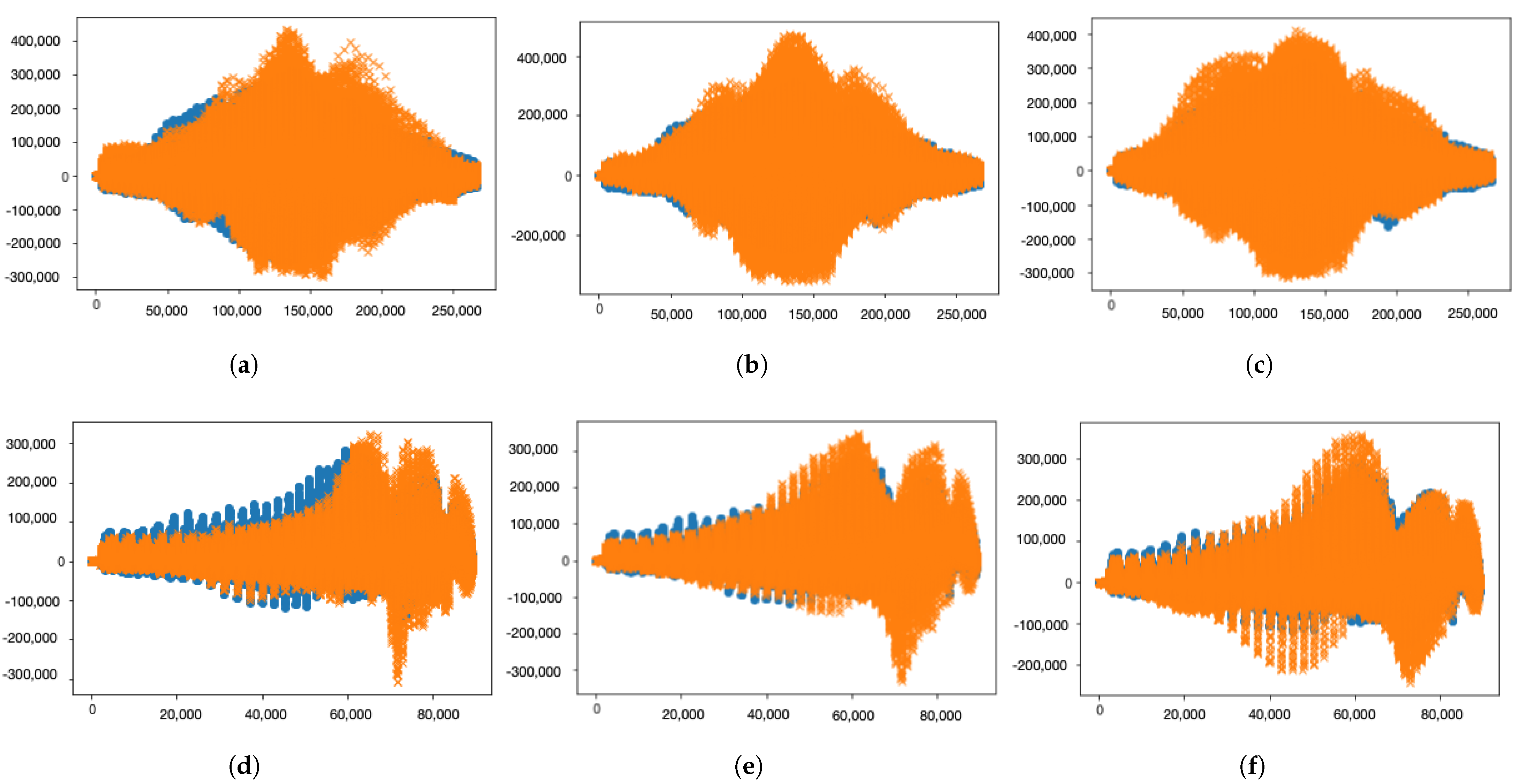
7.2. Visualization
8. Conclusions
- The proposed RMSE and MAE Signature and Log-Signature metrics are based on the Signature Transform, which inherently captures information about the underlying distribution. However, these metrics may not be sensitive to certain aspects of the generated images, such as fine-grained details or specific structures, which could be essential for certain applications.
- Although our proposed method significantly reduces computation time and resource usage compared to existing GAN evaluation methods, it might still be computationally expensive for extremely large datasets or high-resolution images. Further optimization of the computation process may be necessary to address these challenges.
- The evaluation of GAN performance based on our proposed metrics assumes that the original and synthetic image distributions are stationary. In cases where the data exhibit non-stationary behavior, the effectiveness of our approach might be compromised, and additional methods or adaptations may be required.
- The goodness-of-fit methodology proposed in this study relies on statistical methods, which might not always provide definitive conclusions on the quality of the generated samples. In some cases, additional qualitative assessments or domain-specific evaluations may be necessary to obtain a comprehensive understanding of the GAN’s performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DNN | Deep Neural Networks |
| DL | Deep Learning |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| RMSE | Root Mean Squared Error |
| MAE | Mean Absolute Error |
| GAN | Generative Adversarial Networks |
| ADA | Adaptive Discriminator Augmentation |
| FID | Fréchet Inception Distance |
| MS-SSIM | Structural Similarity Index Measure |
| LPIPS | Learned Perceptual Image Patch Similarity |
| PSNR | Peak Signal-to-Noise Ratio |
| PCA | Principal Component Analysis |
| KL | Kullback–Leibler |
| GPU | Graphics Processing Unit |
| t-SNE | t-Distributed Stochastic Neighbor Embedding |
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Kang, M.; Zhu, J.-Y.; Zhang, R.; Park, J.; Shechtman, E.; Paris, S.; Park, T. Scaling up GANs for Text-to-Image Synthesis. arXiv 2023, arXiv:2303.05511. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 4217–4228. [Google Scholar] [CrossRef]
- Chan, E.R.; Lin, C.Z.; Chan, M.A.; Nagano, K.; Pan, B.; Mello, S.D.; Gallo, O.; Guibas, L.J.; Tremblay, J.; Khamis, S.; et al. Efficient geometry-aware 3D generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16123–16133. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale gan training for high fidelity natural image synthesis. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2019. [Google Scholar]
- Zhao, L.; Zhang, Z.; Chen, T.; Metaxas, D.N.; Zhang, H. Improved transformer for high-resolution gans. In Proceedings of the Annual Conference on Neural Information Processing Systems NIPS, Virtual, 6–14 December 2021. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November; 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Bonnier, P.; Kidger, P.; Arribas, I.P.; Salvi, C.; Lyons, T. Deep signature transforms. In Proceedings of the Annual Conference on Neural Information Processing Systems NIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- de Curtò, J.; de Zarzà, I.; Roig, G.; Calafate, C.T. Summarization of Videos with the Signature Transform. Electronics 2023, 12, 1735. [Google Scholar] [CrossRef]
- Chen, K.-T. Iterated path integrals. Bull. Am. Math. Soc. 1977, 83, 831–879. [Google Scholar] [CrossRef]
- Lyons, T.; Caruana, M.; Levin, T. Differential Equations Driven by Rough Paths, Proceedings of the 34th Summer School on Probability Theory, Saint-Flour, France, 6–24 July 2004; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Lyons, T. Rough paths, signatures and the modelling of functions on streams. In Proceedings of the International Congress of Mathematicians, Madrid, Spain, 22–30 August 2014. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. JMLR 2008, 9, 2579–2605. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, Q.; Koltun, V. Photographic image synthesis with cascaded refinement networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-time 3D object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the 35th International Conference on Machine Learning, ICML, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing scenes as neural radiance fields for view synthesis. In Proceedings of the ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J. Contrastive learning for unpaired image-to-image translation. In Proceedings of the ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Gatys, L.A.; Bethge, M.; Hertzmann, A.; Shechtman, E. Preserving color in neural artistic style transfer. arXiv 2016, arXiv:1606.05897. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. In Proceedings of the 6th ICLR International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, T.; Liu, M.; Zhu, J.; Liu, G.; Tao, A.; Kautz, J.; Catanzaro, B. Video-to-video synthesis. In Proceedings of the Annual Conference on Neural Information Processing Systems, NeurIPS, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- de Zarzà, I.; de Curtò, J.; Calafate, C.T. Detection of glaucoma using three-stage training with EfficientNet. Intell. Syst. Appl. 2022, 16, 200140. [Google Scholar] [CrossRef]
- de Curtò, J.; de Zarzà, I.; Calafate, C.T. Semantic scene understanding with large language models on unmanned aerial vehicles. Drones 2023, 7, 114. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Brox, T. Generating Images with Perceptual Similarity Metrics Based on Deep Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2017; pp. 658–666. [Google Scholar]
- Ratner, A.; Sa, C.D.; Wu, S.; Selsam, D.; Ré, C. Data Programming: Creating Large Training Sets, Quickly. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2017; pp. 3567–3575. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the CML’17: 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. In Proceedings of the Annual Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Mescheder, L.; Nowozin, S.; Geiger, A. The numerics of GANs. In Proceedings of the Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Mescheder, L.; Geiger, A.; Nowozin, S. Which training methods for GANs do actually converge? In Proceedings of the International Conference on Machine Learning PMLR, Beijing, China, 14–16 November 2018. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. In Proceedings of the 7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-free generative adversarial networks. In Proceedings of the Annual Conference on Neural Information Processing Systems NIPS, Virtual, 6–14 December 2021. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial networks. In Proceedings of the 5th International Conference on Learning Representations ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Wei, X.; Gong, B.; Liu, Z.; Lu, W.; Wang, L. Improving the improved training of wasserstein gans: A consistency term and its dual effect. In Proceedings of the 6th International Conference on Learning Representations ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Arora, S.; Ge, R.; Liang, Y.; Ma, T.; Zhang, Y. Generalization and Equilibrium in Generative Adversarial Nets (GANs). In Proceedings of the 34th International Conference on Machine Learning, PMLR, Seoul, Republic of Korea, 15–17 November 2017; pp. 224–232. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the Difficulty of Training Recurrent Neural Networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Flynn, J.; Neulander, I.; Philbin, J.; Snavely, N. DeepStereo: Learning to Predict New Views from the World’s Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5515–5524. [Google Scholar]
- Song, Y.; Ermon, S. Generative modeling by estimating gradients of the data distribution. In Proceedings of the Annual Conference on Neural Information Processing Systems NIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Roberts, G.O.; Tweedie, R.L. Exponential convergence of Langevin distributions and their discrete approximations. Bernoulli 1996, 2, 341–363. [Google Scholar] [CrossRef]
- Welling, M.; Teh, Y.W. Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the 28th International Conference on Machine Learning ICML, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Song, Y.; Ermon, S. Improved techniques for training score-based generative models. In Proceedings of the Annual Conference on Neural Information Processing Systems NIPS, Virtual, 6–12 December 2020. [Google Scholar]
- Goyal, A.; Ke, N.R.; Ganguli, S.; Bengio, Y. Variational walkback: Learning a transition operator as a stochastic recurrent net. In Proceedings of the Annual Conference on Neural Information Processing Systems NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the Annual Conference on Neural Information Processing Systems NIPS, Virtual, 6–12 December 2020. [Google Scholar]
- Jolicoeur-Martineau, A.; Piché-Taillefer, R.; Combes, R.T.; Mitliagkas, I. Adversarial score matching and improved sampling for image generation. In Proceedings of the International Conference on Learning Representations ICLR, Vienna, Austria, 4 May 2021. [Google Scholar]
- Zhao, Z.; Kunar, A.; Birke, R.; Chen, L.Y. Ctab-gan: Effective table data synthesizing. In Proceedings of the Machine Learning in Computational Biology Meeting, PMLR, Online, 22–23 November 2021; pp. 97–112. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations ICLR, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.A.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the 7th Asian Conference on Machine Learning, Hong Kong, China, 20–22 November 2015; pp. 2256–2265. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Ho, J.; Saharia, C.; Chan, W.; Fleet, D.J.; Norouzi, M.; Salimans, T. Cascaded Diffusion Models for High Fidelity Image Generation. J. Mach. Learn. Res. 2022, 23, 1–33. [Google Scholar]
- Luo, Z.; Chen, D.; Zhang, Y.; Huang, Y.; Wang, L.; Shen, Y.; Zhao, D.; Zhou, J.; Tan, T. VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 20–22 June 2023. [Google Scholar]
- Wu, J.Z.; Ge, Y.; Wang, X.; Lei, S.W.; Gu, Y.; Hsu, W.; Shan, Y.; Qie, X.; Shou, M.Z. Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation. arXiv 2022, arXiv:2212.11565. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. arXiv 2022, arXiv:2208.12242. [Google Scholar]
- Hua, T.; Tian, Y.; Ren, S.; Zhao, H.; Sigal, L. Self-supervision through random segments with autoregressive coding (randsac). arXiv 2022, arXiv:2203.12054. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training generative adversarial networks with limited data. In Proceedings of the Annual Conference on Neural Information Processing Systems NIPS, Virtual, 6–12 December 2020. [Google Scholar]
- Kruskal, W.H.; Wallis, W.A. Use of ranks in one-criterion variance analysis. J. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kidger, P.; Lyons, T. Signatory: Differentiable computations of the signature and logsignature transforms, on both CPU and GPU. In Proceedings of the International Conference on Learning Representations ICLR, Vienna, Austria, 4 May 2021. [Google Scholar]
- Chevyrev, I.; Kormilitzin, A. A primer on the signature method in machine learning. arXiv 2016, arXiv:1603.03788. [Google Scholar]
- Liao, S.; Lyons, T.J.; Yang, W.; Ni, H. Learning stochastic differential equations using RNN with log signature features. arXiv 2019, arXiv:1908.08286. [Google Scholar]
- Morrill, J.; Kidger, P.; Salvi, C.; Foster, J.; Lyons, T.J. Neural CDEs for long time series via the log-ode method. In Proceedings of the 38th International Conference on Machine Learning ICML, Virtual, 18–24 July 2021. [Google Scholar]
- Kiraly, F.J.; Oberhauser, H. Kernels for sequentially ordered data. J. Mach. Learn. Res. 2019, 20, 1–45. [Google Scholar]
- Graham, B. Sparse arrays of signatures for online character recognition. arXiv 2013, arXiv:1308.0371. [Google Scholar]
- Chang, J.; Lyons, T. Insertion algorithm for inverting the signature of a path. arXiv 2019, arXiv:1907.08423. [Google Scholar]
- Fermanian, A. Learning Time-Dependent Data with the Signature Transform. Ph.D. Thesis, Sorbonne Université, Paris, France, 2021. Available online: https://tel.archives-ouvertes.fr/tel-03507274 (accessed on 1 November 2022).
- Lyons, T. Differential equations driven by rough signals. Rev. Mat. Iberoam. 1998, 14, 215–310. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test | Population | Result | Interpretation |
|---|---|---|---|
| 1 | and | √ | (a) |
| x | (b) | ||
| 2 | √ | (c) | |
| x | (d) | ||
| 3 | and | √ | (e) |
| x | (f) |
| Model | Dataset | T1 | T2 | T3 | |
|---|---|---|---|---|---|
| Stylegan2-ADA | NASA Perseverance | x | √ | x | |
| AFHQ | Cat | x | x | √ | |
| Dog | x | √ | x | ||
| Wild | x | x | √ | ||
| MetFaces | x | x | x | ||
| r-Stylegan3-ADA | x | x | x | ||
| t-Stylegan3-ADA | x | x | x | ||
| Iteration Stylegan2-ADA | 193 | 371 | 596 | 798 | 983 |
|---|---|---|---|---|---|
| RMSE Signature | 15,617 | 13,336 | 12,353 | 11,601 | 25,699 |
| MAE Signature | 11,072 | 10,686 | 9801 | 9086 | 19,481 |
| RMSE Log-Signature | 9882 | 7563 | 7354 | 7397 | 15,621 |
| MAE Log-Signature | 6467 | 5955 | 5724 | 5717 | 12,063 |
| Model | Dataset | RMSE | MAE | RMSE | MAE | |
|---|---|---|---|---|---|---|
| Stylegan2-ADA | AFHQ | Cat | 61,450 | 45,968 | 29,201 | 22,297 |
| Dog | 38,861 | 30,441 | 31,686 | 24,612 | ||
| Wild | 33,306 | 25,578 | 26,622 | 20,359 | ||
| MetFaces | 33,247 | 23,428 | 25,685 | 18,071 | ||
| r-Stylegan3-ADA | 34,977 | 22,799 | 24,707 | 16,539 | ||
| t-Stylegan3-ADA | 30,894 | 19,872 | 21,560 | 13,761 | ||
| Model | FID | RMSE |
|---|---|---|
| Stylegan2-ADA | 15.22 | 33,247 |
| r-Stylegan3-ADA | 15.33 | 34,977 |
| t-Stylegan3-ADA | 15.11 | 30,894 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Curtò, J.; de Zarzà, I.; Roig, G.; Calafate, C.T. Signature and Log-Signature for the Study of Empirical Distributions Generated with GANs. Electronics 2023, 12, 2192. https://doi.org/10.3390/electronics12102192
de Curtò J, de Zarzà I, Roig G, Calafate CT. Signature and Log-Signature for the Study of Empirical Distributions Generated with GANs. Electronics. 2023; 12(10):2192. https://doi.org/10.3390/electronics12102192
Chicago/Turabian Stylede Curtò, J., I. de Zarzà, Gemma Roig, and Carlos T. Calafate. 2023. "Signature and Log-Signature for the Study of Empirical Distributions Generated with GANs" Electronics 12, no. 10: 2192. https://doi.org/10.3390/electronics12102192
APA Stylede Curtò, J., de Zarzà, I., Roig, G., & Calafate, C. T. (2023). Signature and Log-Signature for the Study of Empirical Distributions Generated with GANs. Electronics, 12(10), 2192. https://doi.org/10.3390/electronics12102192