
Hardware Design and Implementation of a Lightweight Saber Algorithm Based on DRC Method


Abstract
:1. Introduction
2. Introduction to the Saber Algorithm
2.1. Symbolic Representation
2.2. Saber Algorithm Process
| Algorithm 1 Saber.PKE.KeyGen() |
| Algorithm 2 Saber.PKE.Enc (pk = (seedA, b), m ∈ R2; r) |
| Algorithm 3 Saber.PKE.Dec (sk = s, c = (cm, b’)) |
| Algorithm 4 Saber.KEM.KeyGen() |
| Algorithm 5 Saber.KEM.Encps(pk = (seedA, b)) |
| Algorithm 6 Saber.KEM.Decaps(sk = (z, pkh, pk, s) |
3. Hardware Implementation of Saber Algorithm
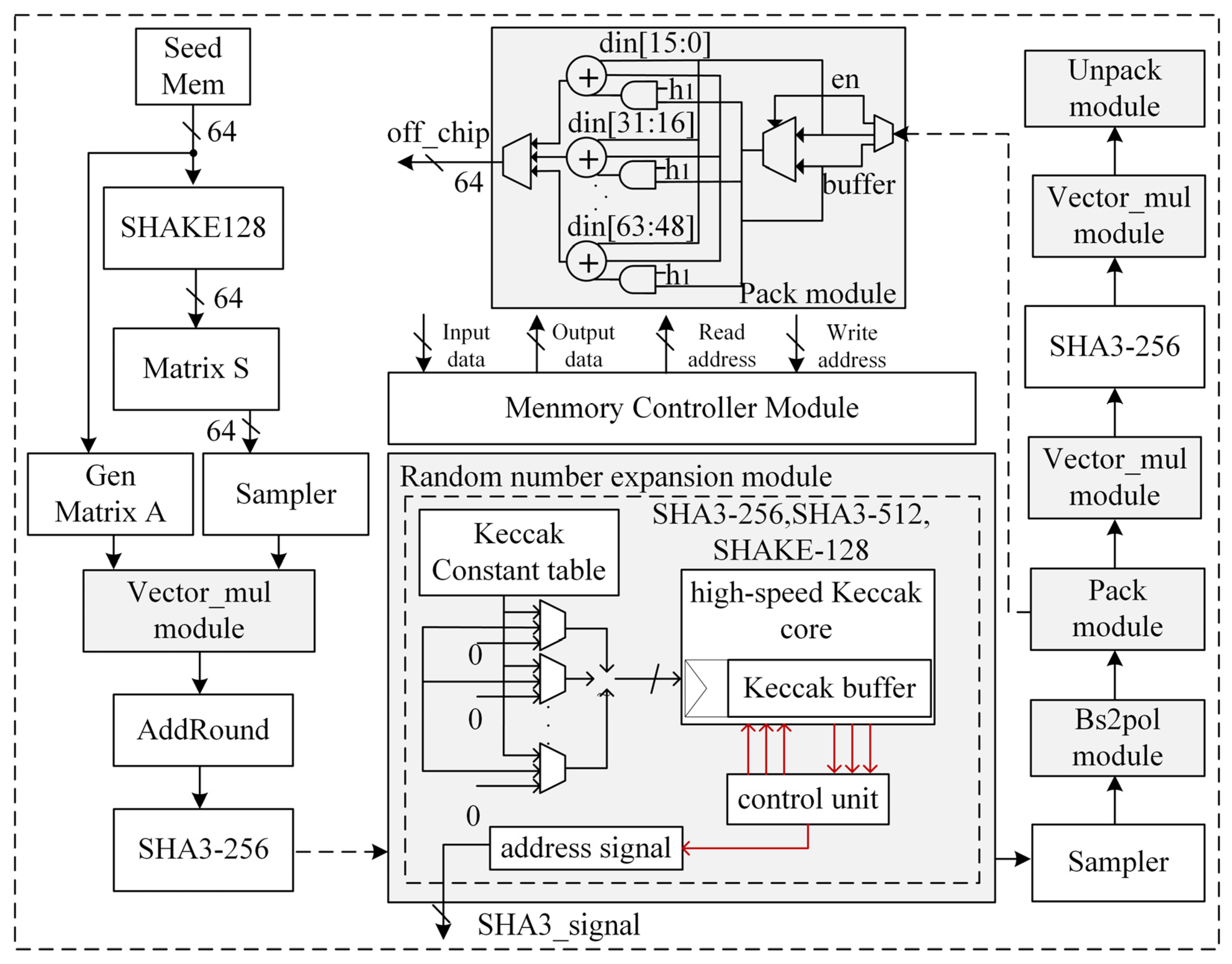
3.1. Saber Algorithm Hardware Architecture
3.2. Single-Cycle Double Data Reading and Storage Module Design
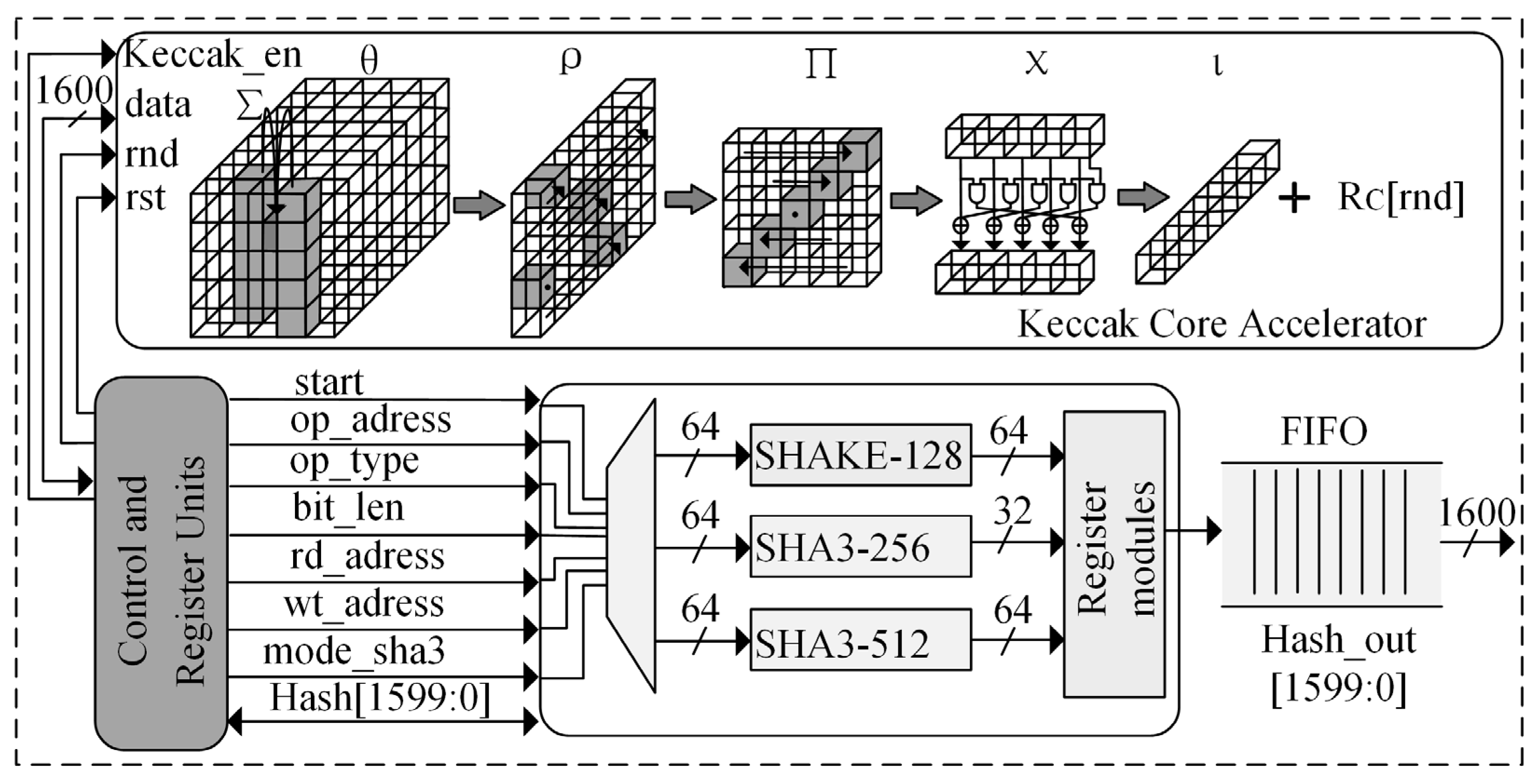
3.3. High-Speed Random Number Expansion Module Circuit Design
3.4. Lightweight Encryption and Decryption Hardware Module Design
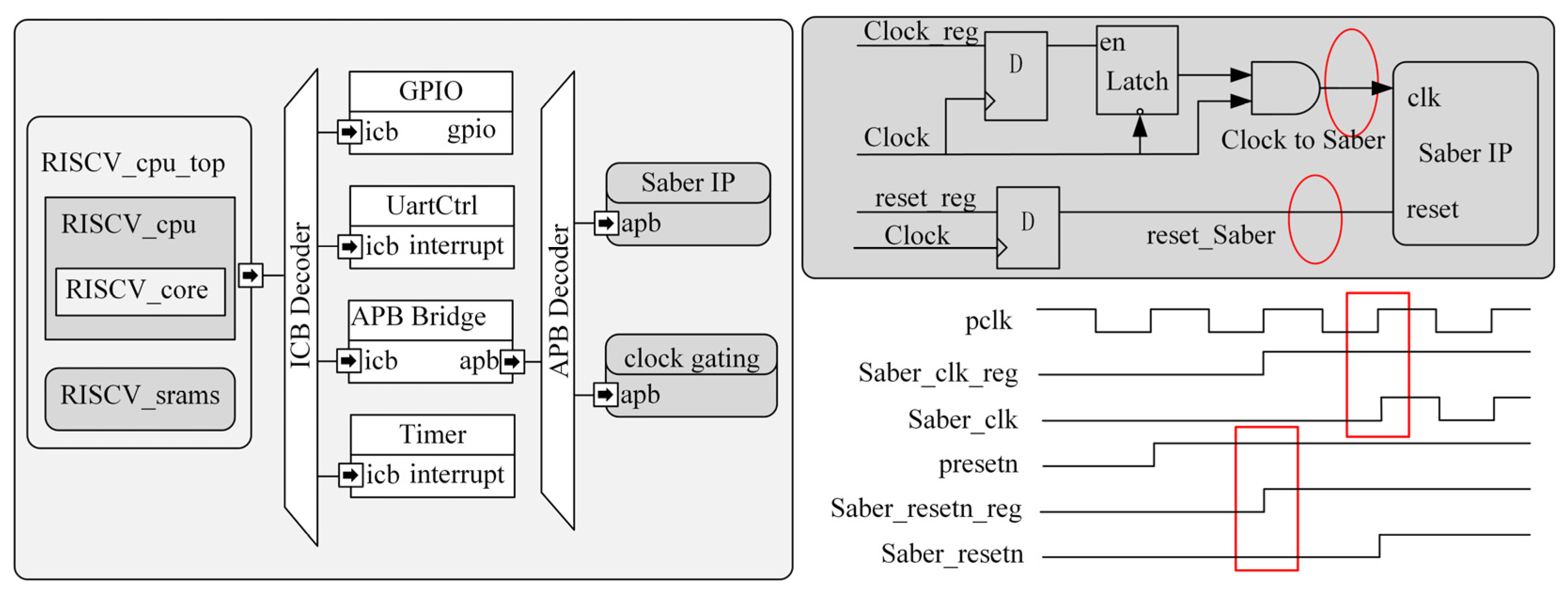
3.5. Processor-Level Low-Power Implementation of the Saber Algorithm IP Core
4. Experimental Results and Analysis
4.1. Algorithm Performance Results
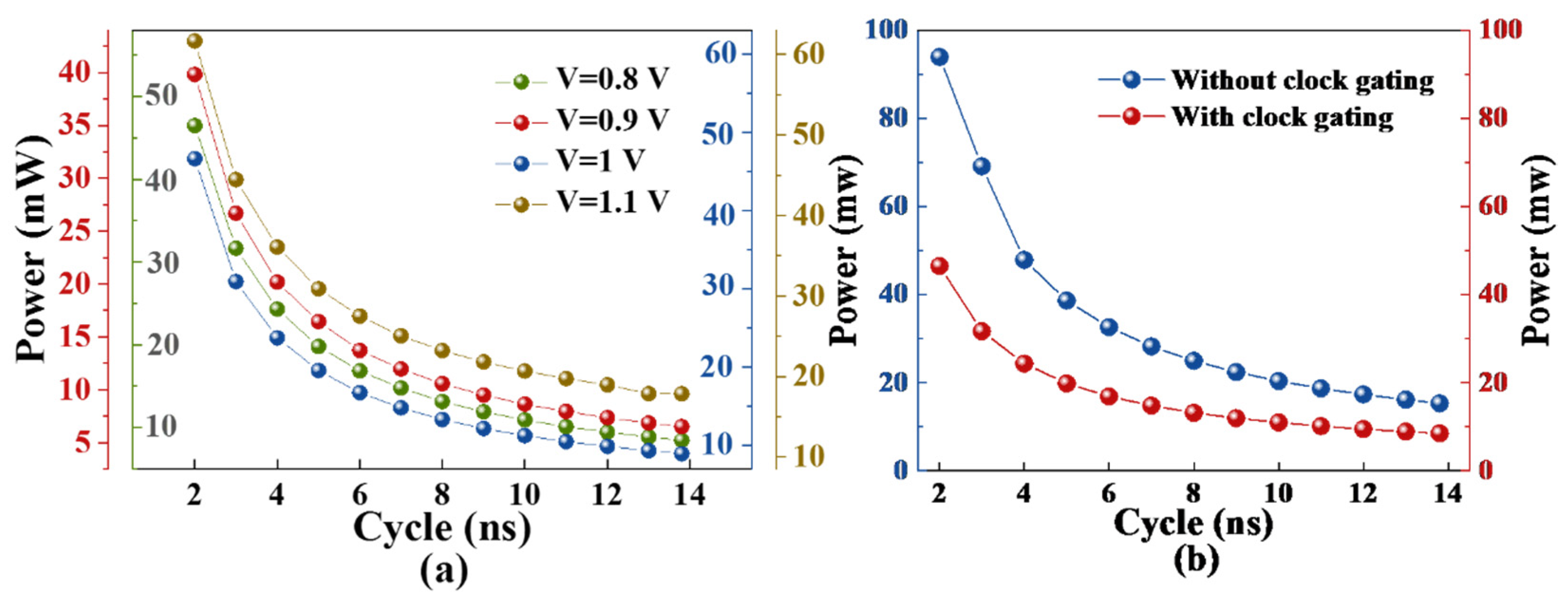
4.2. Power Area Analysis of IP Cores
4.3. Comparison with Related Literature
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.; Buell, D.A. Quantum supremacy using a programmable superconducting processor. Nature 2019, 574, 505–510. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhong, H.; Wang, H.; Deng, Y.; Chen, M.; Peng, L.; Luo, Y.; Qin, J.; Wu, D.; Ding, X.; Hu, Y. Quantum computational advantage using photons. Science 2020, 370, 1460–1463. [Google Scholar] [CrossRef] [PubMed]
- Shor, P.W. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, New Mexico, 20–24 November 1994; pp. 124–134. [Google Scholar]
- Lee, D.H.; Seo, E.Y.; Kim, Y.S.; No, J.S. Rethinking on ciphertext equality check of decapsulation of nist pqc standardization 3rd round finalist candidate saber. In Proceedings of the 2022 13th International Conference on Information and Communication Technology Convergence (ICTC), Xi’an, China, 19–21 October 2022; pp. 1483–1486. [Google Scholar]
- Pöppelmann, T.; Güneysu, T. Towards practical lattice-based public-key encryption on reconfigurable hardware. In Proceedings of the Selected Areas in Cryptography—SAC 2013: 20th International Conference, Burnaby, BC, Canada, 14–16 August 2014; pp. 68–85. [Google Scholar]
- Roy, S.S.; Vercauteren, F.; Mentens, N.; Chen, D.D.; Verbauwhede, I. Compact ring-lwe cryptoprocessor. In Proceedings of the Cryptographic Hardware and Embedded Systems–CHES 2014: 16th International Workshop, Busan, South Korea, 23–26 September 2014; pp. 371–391. [Google Scholar]
- De Clercq, R.; Roy, S.S.; Vercauteren, F.; Verbauwhede, I. Efficient software implementation of ring-lwe encryption. In Proceedings of the Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 339–344. [Google Scholar]
- Knuth, D.E. The Art of Computer Programming; Pearson Education: Boston, MA, USA, 1997; Volume 3. [Google Scholar]
- Roy, S.S. Saberx4: High-throughput software implementation of saber key encapsulation mechanism. In Proceedings of the 2019 IEEE 37th International Conference on Computer Design (ICCD), Abu Dhabi, United Arab Emirates, 17–20 November 2019; pp. 321–324. [Google Scholar]
- Mera, J.; Turan, F.; Karmakar, A.; Roy, S.S.; Verbauwhede, I.M. Compact domain-specific co-processor for accelerating module lattice-based kem. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Dang, V.B.; Farahmand, F.; Andrzejczak, M.; Gaj, K. Implementing and benchmarking three lattice-based post-quantum cryptography algorithms using software/hardware codesign. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019; pp. 206–214. [Google Scholar]
- Roy, S.S.; Basso, A. High-speed instruction-set coprocessor for lattice-based key encapsulation mechanism: Saber in hardware. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 443–466. Available online: https://tches.iacr.org/index.php/TCHES/article/view/8690 (accessed on 26 August 2020). [CrossRef]
- Karmakar, A.; Mera, J.M.B.; Roy, S.S.; Verbauwhede, I.J.C.e.A. Saber on arm: Cca-secure module lattice-based key encapsulation on arm. Cryptogr. Hardw. Embed. Syst. 2018, 243–266. Available online: https://eprint.iacr.org/2018/682 (accessed on 14 August 2018). [CrossRef]
- Kannwischer, M.J.; Rijneveld, J.; Schwabe, P. Faster multiplication in z2m [x] on cortex-m4 to speed up nist pqc candidates. In Proceedings of the Applied Cryptography and Network Security: 17th International Conference, Bogota, Colombia, 5–7 June 2019; pp. 281–301. [Google Scholar]
- Liu, W.; Fan, S.; Khalid, A.; Rafferty, C.; O’Neill, M. Optimized schoolbook polynomial multiplication for compact lattice-based cryptography on fpga. Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2459–2463. [Google Scholar] [CrossRef] [Green Version]
- Paksoy, I.K.; Cenk, M. Tmvp-based multiplication for polynomial quotient rings and application to saber on arm cortex-m4. Cryptol. ePrint Arch. 2020. Available online: https://eprint.iacr.org/2020/1302 (accessed on 19 October 2020).
- Zhu, Y.; Zhu, M.; Yang, B.; Zhu, W.; Deng, C.; Chen, C.; Wei, S.; Liu, L. Lwrpro: An energy-efficient configurable crypto-processor for module-lwr. Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1146–1159. [Google Scholar] [CrossRef]
- Alagic, G.; Apon, D.; Cooper, D.; Dang, Q.; Dang, T.; Kelsey, J.; Lichtinger, J.; Miller, C.; Moody, D.; Peralta, R. Status Report on the Third Round of the Nist Post-Quantum Cryptography Standardization Process; US Department of Commerce: Washington, DC, USA, 2022.
- Fritzmann, T.; Sigl, G.; Sepúlveda, J. Risq-v: Tightly coupled risc-v accelerators for post-quantum cryptography. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2020, 239–280. [Google Scholar] [CrossRef]
- Howe, J.; Oder, T.; Krausz, M.; Güneysu, T. Standard lattice-based key encapsulation on embedded devices. Cryptol. ePrint Arch. 2018, 2018, 372–393. [Google Scholar] [CrossRef]
- Oder, T.; Güneysu, T. Implementing the newhope-simple key exchange on low-cost fpgas. In Proceedings of the Progress in Cryptology–LATINCRYPT 2017: 5th International Conference on Cryptology and Information Security in Latin America, Havana, Cuba, 20–22 September 2017; pp. 128–142. [Google Scholar]
- Banerjee, U.; Ukyab, T.S.; Chandrakasan, A.P. Sapphire: A configurable crypto-processor for post-quantum lattice-based protocols. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2019, 17–61. [Google Scholar] [CrossRef]
- Kuo, P.; Chen, Y.; Hsu, Y.; Cheng, C.; Li, W.; Yang, B. High performance post-quantum key exchange on fpgas. Cryptol. ePrint Arch. 2017, 37, 1211–1229. [Google Scholar]
- Basu, K.; Soni, D.; Nabeel, M.; Karri, R. Nist post-quantum cryptography-a hardware evaluation study. Cryptol. ePrint Arch. 2019. Available online: https://eprint.iacr.org/2019/047 (accessed on 25 January 2019).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Register Definition | Offset Address | Read and Write Permissions |
|---|---|---|
| SABER_CLK_ADDR | 00 | Only write |
| SABER_RESETN_ADDR | 04 | Only write |
| START_ADDR | 08 | Only write |
| MODE_ADDR | 0C | Only write |
| OFF_CHIP_DONE_ADDR | 10 | Only read |
| Instruction | Keygen | Encapsulation | Decapsulation |
|---|---|---|---|
| Cycle (ns) | 3304 | 4702 | 1240 |
| Times (us) | 44.09 | 122.41 | 19.89 |
| Plaintext [0,255] | Ciphertext [0,511] | Ciphertext [512,1024] | |||
|---|---|---|---|---|---|
| [0] | 8016_8f9b_2748_fb2f | [0] | a49c_7f6f_c0e7_6e42 | [8] | 2228_ef65_aeb3_2aac |
| [1] | 929d_ef22_2b56_9fda | [1] | 2700_7850_7870_3409 | [9] | f603_fd1b_12d6_104e |
| [2] | 4e91_9dab_35c4_0884 | [2] | 1f7a_caa5_c53e_1659 | [10] | 8ff8_4044_277e_d3f7 |
| [3] | baf4_f48b_4929_b385 | [3] | 9066_2771_c1e3_5f47 | [11] | a632_b681_316d_3b42 |
| [4] | 4f1a_1573_b02f_fb4c | [12] | dea4_d1b2_9047_f26d | ||
| [5] | 8ea5_ffbe_c8a5_1d19 | [13] | 00a5_9136_fedc_c541 | ||
| [6] | 0004_0fe3_34e1_2f4b | [14] | d24f_2810_29a0_2c61 | ||
| [7] | c134_797a_646f_deb5 | [15] | 701c_41a4_727e_dc1a |
| Paper | Saber [10] | Saber [11] | Frodo [20] | NewHope [21] | Kyber [22] | NewHope [23] | Dilithium-II [24] | This Work | |
|---|---|---|---|---|---|---|---|---|---|
| Technology | Artix-7 (HW/SW) | UltraScale+ (HW/SW) | Artix-7 | Artix-7 | ASIC [TSMC 40 nm] | Artix-7 | ASIC [TSMC 65 nm] | ASIC [TSMC 65 nm] | |
| Times in us | Keygen | 3273 | - | 45,454 | 988 | 1548 | 51.9 | 980.6 | 44.1 |
| Encaps | 4147 | 60 | 45,454 | 1413 | 2456 | 78.6 | 122.4 | ||
| Decaps | 3844 | 65 | 47,619 | 473 | 1646 | 21.1 | 18.8 | ||
| Frequency (MHz) | 125 | 322 | 167 | 167 | 72 | 131 | 158 | 72 | |
| LUT | 7.4 K | 12.5 K | 7.7 K | 5.1 K | - | 20 K | - | - | |
| FF | 7.3 K | 11.6 K | 3.5 K | 4.4 K | - | 9.9 K | - | - | |
| DSP | 28 | 256 | 1 | 2 | - | 8 | - | - | |
| BRAM | 2 | 4 | 24 | 4 | - | 14 | - | - | |
| Area (mm2) | - | - | - | - | 0.28 | - | 4.7 | 0.99 | |
| VDD (V) | - | - | - | - | 1.1 | - | 1.2 | 1 | |
| Area (K GATE) | - | - | - | - | 106 | - | 1603 | 451 | |
| Power (mW) | - | - | - | - | 12.8 | - | 50.42 | 8.4 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, W.; Zhang, H.; Zhang, Y.; Wen, Y.; Lv, J.; Ni, L.; Li, Z. Hardware Design and Implementation of a Lightweight Saber Algorithm Based on DRC Method. Electronics 2023, 12, 2525. https://doi.org/10.3390/electronics12112525
Zheng W, Zhang H, Zhang Y, Wen Y, Lv J, Ni L, Li Z. Hardware Design and Implementation of a Lightweight Saber Algorithm Based on DRC Method. Electronics. 2023; 12(11):2525. https://doi.org/10.3390/electronics12112525
Chicago/Turabian StyleZheng, Weifang, Huihong Zhang, Yuejun Zhang, Yongzhong Wen, Jie Lv, Lei Ni, and Zhiyi Li. 2023. "Hardware Design and Implementation of a Lightweight Saber Algorithm Based on DRC Method" Electronics 12, no. 11: 2525. https://doi.org/10.3390/electronics12112525
APA StyleZheng, W., Zhang, H., Zhang, Y., Wen, Y., Lv, J., Ni, L., & Li, Z. (2023). Hardware Design and Implementation of a Lightweight Saber Algorithm Based on DRC Method. Electronics, 12(11), 2525. https://doi.org/10.3390/electronics12112525