

A Low-Complexity Fast CU Partitioning Decision Method Based on Texture Features and Decision Trees


Abstract
:1. Introduction
2. Background and Related Works
2.1. QTMT Partition Background of VVC
2.2. Related Work
2.2.1. Fast HEVC-Based CU Segmentation Method
2.2.2. Fast CU Classification Method Based on VVC
3. Proposed Methodology
3.1. Decision Analysis
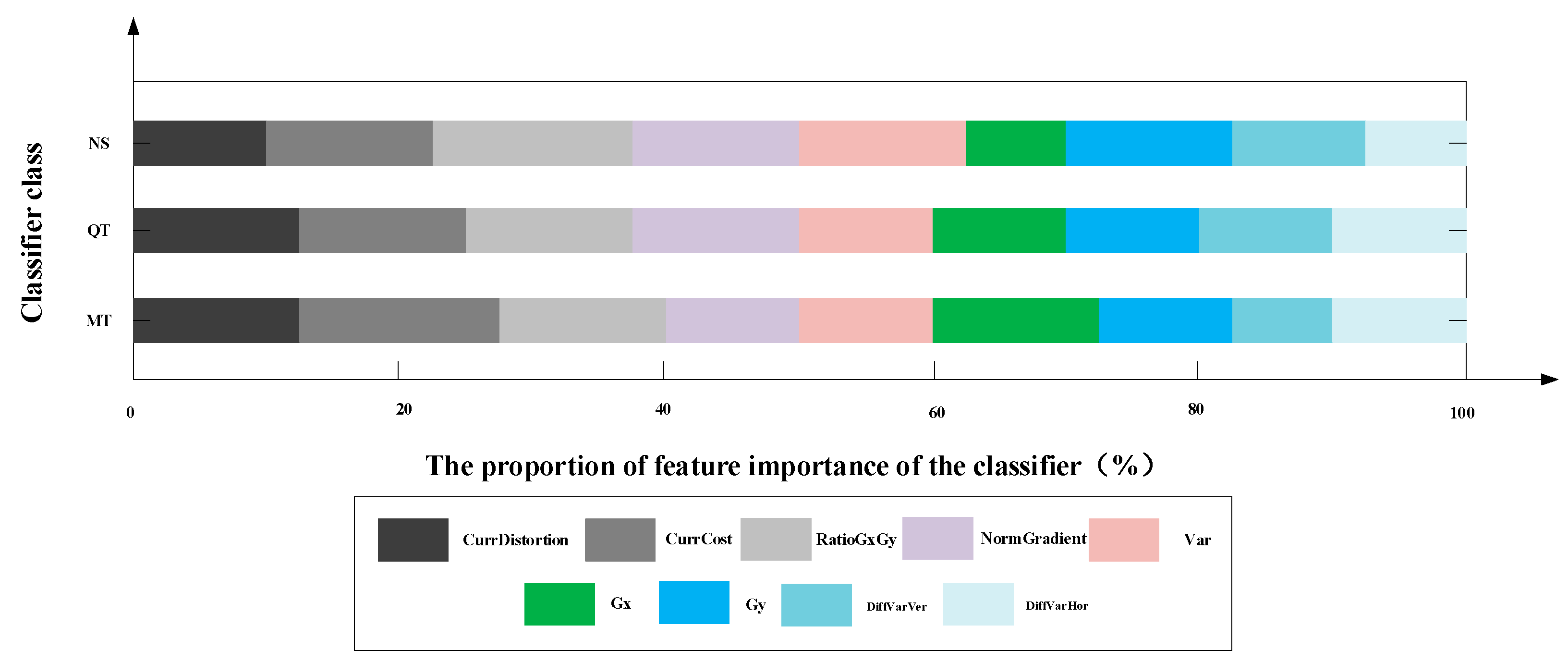
3.2. Analysis and Selection of Texture Features
- Can handle non-linear classification problems well;
- Have a built-in mechanism for handling missing values and outliers;
- Provide feature importance ranking;
- Can handle large datasets efficiently.
- Global Texture Information
- Local texture information
- Coding information
3.3. Model Building and Training
- max_depth: This hyperparameter determines the maximum depth of the decision tree. By setting a suitable max_depth value, the complexity of the tree can be controlled and over-fitting can be prevented;
- min_samples_split: This hyperparameter sets the minimum number of samples required to further split the internal nodes. Adding min_samples_split regularizes the tree and prevents overfitting by ensuring that a minimum number of samples are present when the split occurs;
- min_samples_leaf: The minimum number of samples required for internal node subdivision. Adjusting min_samples_leaf can affect the generalization ability of the tree;
- The maximum number of features to consider for each split (max_features): The maximum number of features when looking for the best split in an internal node. By limiting the number of features, the risk of overfitting can be reduced;
- Criterion: This hyperparameter determines the metric used to split the nodes in the decision tree.
3.4. General Algorithmic Framework
4. Experimental Results and Analysis
4.1. Configuration and Setup
4.2. Performance Comparison with the VTM-10.0 Standard Algorithm
4.3. Framework Performance Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| VVC | Versatile Video Coding |
| HEVC | High-Efficiency Video Coding |
| CU | Coding Unit |
| CTU | Coding Tree Unit |
| MTT | Multi-Type Tree |
| QTMT | QuadTree with Nested Multi-type Tree |
| RDO | Rate Distortion Optimization |
| QT | QuadTree |
| BTH | Horizontal Binary Tree |
| BTV | Vertical Binary Tree |
| TTH | Horizontal Trinomial Tree |
| TTV | Vertical Trinomial Tree |
| QP | Quantization Parameter |
| TS | Time Saving |
| BDBR | Bjøntegaard Delta Bit-Rate |
| VTM | VVC Test Model |
| MPEG | Moving Picture Experts Group |
| VCEG | Video Coding Experts Group |
| BV | Vertical Binary Tree Partition |
| BH | Horizontal Binary Tree Splitting |
| TV | Vertical Ternary Tree Splitting |
| TH | Horizontal Ternary Tree Splitting |
| AMC | Affine Motion Compensation |
| MTS | Multiple Transform Selection |
| LFNST | Low-Frequency Non-Separable Transform |
| HM | HEVC Test Model |
| NS | No Splitting |
References
- Zhang, M.; Chu, R.; Dong, C.; Wei, J.; Lu, W.; Xiong, N. Residual Learning Diagnosis Detection: An advanced residual learning diagnosis detection system for COVID-19 in Industrial Internet of Things. IEEE Trans. Ind. Inform. 2021, 17, 6510–6518. [Google Scholar] [CrossRef]
- He, P.; Li, H.; Wang, H.; Wang, S.; Jiang, X.; Zhang, R. Frame-wise detection of double HEVC compression by learning deep spatio-temporal representations in compression domain. IEEE Trans. Multimed. 2020, 23, 3179–3192. [Google Scholar] [CrossRef]
- Bross, B.; Wang, Y.-K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.-R. Overview of the versatile video coding (VVC) standard and its applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Li, Y.; Yang, G.; Song, Y.; Zhang, H.; Ding, X.; Zhang, D. Early intra CU size decision for versatile video coding based on a tunable decision model. IEEE Trans. Broadcast. 2021, 67, 710–720. [Google Scholar] [CrossRef]
- Huang, Y.-W.; Hsu, C.-W.; Chen, C.-Y.; Chuang, T.-D.; Hsiang, S.-T.; Chen, C.-C.; Chiang, M.-S.; Lai, C.-Y.; Tsai, C.-M.; Su, Y.-C. A VVC proposal with quaternary tree plus binary-ternary tree coding block structure and advanced coding techniques. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1311–1325. [Google Scholar] [CrossRef]
- Zhao, X.; Kim, S.-H.; Zhao, Y.; Egilmez, H.E.; Koo, M.; Liu, S.; Lainema, J.; Karczewicz, M. Transform coding in the VVC standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3878–3890. [Google Scholar] [CrossRef]
- Huang, Y.-W.; An, J.; Huang, H.; Li, X.; Hsiang, S.-T.; Zhang, K.; Gao, H.; Ma, J.; Chubach, O. Block partitioning structure in the VVC standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3818–3833. [Google Scholar] [CrossRef]
- Zhou, M.; Wei, X.; Jia, W.; Kwong, S. Joint Decision Tree and Visual Feature Rate Control Optimization for VVC UHD Coding. IEEE Trans. Image Process. 2022, 32, 219–234. [Google Scholar] [CrossRef]
- Bossen, F.; Sühring, K.; Wieckowski, A.; Liu, S. VVC complexity and software implementation analysis. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3765–3778. [Google Scholar] [CrossRef]
- Chen, F.; Ren, Y.; Peng, Z.; Jiang, G.; Cui, X. A fast CU size decision algorithm for VVC intra prediction based on support vector machine. Multimed. Tools Appl. 2020, 79, 27923–27939. [Google Scholar] [CrossRef]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Fast transform decision scheme for VVC intra-frame prediction using decision trees. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 1948–1952. [Google Scholar]
- Wieckowski, A.; Brandenburg, J.; Bross, B.; Marpe, D. VVC search space analysis including an open, optimized implementation. IEEE Trans. Consum. Electron. 2022, 68, 127–138. [Google Scholar] [CrossRef]
- da Silva, R.C.C.; Camargo, M.P.O.; Quessada, M.S.; Lopes, A.C.; Ernesto, J.D.M.; da Costa, K.A.P. An Intrusion Detection System for Web-Based Attacks Using IBM Watson. IEEE Lat. Am. Trans. 2021, 20, 191–197. [Google Scholar] [CrossRef]
- Jiang, W.; Ma, H.; Chen, Y. Gradient based fast mode decision algorithm for intra prediction in HEVC. In Proceedings of the 2012 2nd International Conference on Consumer Electronics, Communications and Networks (CECNet), Yichang, China, 21–23 April 2012; pp. 1836–1840. [Google Scholar]
- Wang, L.-L.; Siu, W.-C. Novel adaptive algorithm for intra prediction with compromised modes skipping and signaling processes in HEVC. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1686–1694. [Google Scholar] [CrossRef]
- Liu, X.; Li, Y.; Liu, D.; Wang, P.; Yang, L.T. An adaptive CU size decision algorithm for HEVC intra prediction based on complexity classification using machine learning. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 144–155. [Google Scholar] [CrossRef]
- Kim, H.-S.; Park, R.-H. Fast CU partitioning algorithm for HEVC using an online-learning-based Bayesian decision rule. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 130–138. [Google Scholar] [CrossRef]
- Zhang, T.; Sun, M.-T.; Zhao, D.; Gao, W. Fast intra-mode and CU size decision for HEVC. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1714–1726. [Google Scholar] [CrossRef]
- Kuo, Y.-T.; Chen, P.-Y.; Lin, H.-C. A spatiotemporal content-based CU size decision algorithm for HEVC. IEEE Trans. Broadcast. 2020, 66, 100–112. [Google Scholar] [CrossRef]
- Grellert, M.; Zatt, B.; Bampi, S.; da Silva Cruz, L.A. Fast coding unit partition decision for HEVC using support vector machines. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1741–1753. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, Y.; Kwong, S.; Wang, X.; Zhao, T. Fuzzy SVM-based coding unit decision in HEVC. IEEE Trans. Broadcast. 2017, 64, 681–694. [Google Scholar] [CrossRef]
- Bakkouri, S.; Elyousfi, A. Early termination of CU partition based on boosting neural network for 3D-HEVC inter-coding. IEEE Access 2022, 10, 13870–13883. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhao, Y.; Jiang, B.; Huang, L.; Wei, T. Fast CU partition decision method based on texture characteristics for H. 266/VVC. IEEE Access 2020, 8, 203516–203524. [Google Scholar] [CrossRef]
- Ni, C.-T.; Lin, S.-H.; Chen, P.-Y.; Chu, Y.-T. High Efficiency Intra CU Partition and Mode Decision Method for VVC. IEEE Access 2022, 10, 77759–77771. [Google Scholar] [CrossRef]
- Li, T.; Xu, M.; Tang, R.; Chen, Y.; Xing, Q. DeepQTMT: A deep learning approach for fast QTMT-based CU partition of intra-mode VVC. IEEE Trans. Image Process. 2021, 30, 5377–5390. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Shi, J.; Chen, Z. HG-FCN: Hierarchical grid fully convolutional network for fast VVC intra coding. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5638–5649. [Google Scholar] [CrossRef]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Configurable fast block partitioning for VVC intra coding using light gradient boosting machine. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3947–3960. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, Y.; Huang, L.; Jiang, B. Fast CU partition and intra mode decision method for H. 266/VVC. IEEE Access 2020, 8, 117539–117550. [Google Scholar] [CrossRef]
- Zhao, J.; Wu, A.; Jiang, B.; Zhang, Q. ResNet-Based Fast CU Partition Decision Algorithm for VVC. IEEE Access 2022, 10, 100337–100347. [Google Scholar] [CrossRef]
- Shen, X.; Yu, L. CU splitting early termination based on weighted SVM. EURASIP J. Image Video Process. 2013, 2013, 4. [Google Scholar] [CrossRef]
- Zhang, Y.; Kwong, S.; Wang, X.; Yuan, H.; Pan, Z.; Xu, L. Machine learning-based coding unit depth decisions for flexible complexity allocation in high efficiency video coding. IEEE Trans. Image Process. 2015, 24, 2225–2238. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Zhang, J.; Wang, S.; Ma, S. Effective quadtree plus binary tree block partition decision for future video coding. In Proceedings of the 2017 Data Compression Conference (DCC), Snowbird, UT, USA, 4–7 April 2017; pp. 23–32. [Google Scholar]
- Li, H.; Zhang, P.; Jin, B.; Zhang, Q. Fast CU Decision Algorithm Based on Texture Complexity and CNN for VVC. IEEE Access 2023, 11, 35808–35817. [Google Scholar] [CrossRef]
- Pan, Z.; Zhang, P.; Peng, B.; Ling, N.; Lei, J. A CNN-based fast inter coding method for VVC. IEEE Signal Process. Lett. 2021, 28, 1260–1264. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, W.; Zhang, Q. Fast CU Division Pattern Decision Based on the Combination of Spatio-Temporal Information. Electronics 2023, 12, 1967. [Google Scholar] [CrossRef]
- Zhao, S.; Shang, X.; Wang, G.; Zhao, H. A Fast Algorithm for Intra-Frame Versatile Video Coding Based on Edge Features. Sensors 2023, 23, 6244. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.; Jun, D. Fast Mode Decision Method of Multiple Weighted Bi-Predictions Using Lightweight Multilayer Perceptron in Versatile Video Coding. Electronics 2023, 12, 2685. [Google Scholar] [CrossRef]
- Jing, Z.; Zhu, W.; Zhang, Q. A Fast VVC Intra Prediction Based on Gradient Analysis and Multi-Feature Fusion CNN. Electronics 2023, 12, 1963. [Google Scholar] [CrossRef]
- Li, M.; Li, Z.; Zhang, Z. A VVC Video Steganography Based on Coding Units in Chroma Components with a Deep Learning Network. Symmetry 2022, 15, 116. [Google Scholar] [CrossRef]
- Tsai, Y.-H.; Lu, C.-R.; Chen, M.-J.; Hsieh, M.-C.; Yang, C.-M.; Yeh, C.-H. Visual Perception Based Intra Coding Algorithm for H. 266/VVC. Electronics 2023, 12, 2079. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CU Size | NS | QT | BT_H | BT_V | TT_H | TT_V |
|---|---|---|---|---|---|---|
| 64 × 64 | 0.17 | 0.83 | 0 | 0 | 0 | 0 |
| 32 × 32 | 0.18 | 0.35 | 0.18 | 0.17 | 0.07 | 0.06 |
| 32 × 16 | 0.41 | 0 | 0.18 | 0.23 | 0.09 | 0.09 |
| 32 × 8 | 0.48 | 0 | 0.18 | 0.22 | 0 | 0.12 |
| 32 × 4 | 0.77 | 0 | 0 | 0.13 | 0 | 0.10 |
| 16 × 32 | 0.41 | 0 | 0.25 | 0.17 | 0.09 | 0.07 |
| 8 × 32 | 0.47 | 0 | 0.25 | 0.14 | 0.14 | 0 |
| 4 × 32 | 0.72 | 0 | 0.15 | 0 | 0.13 | 0 |
| 16 × 16 | 0.23 | 0.11 | 0.23 | 0.24 | 0.09 | 0.09 |
| 16 × 8 | 0.50 | 0 | 0.18 | 0.22 | 0 | 0.09 |
| 16 × 4 | 0.61 | 0 | 0 | 0.24 | 0 | 0.15 |
| 8 × 16 | 0.49 | 0 | 0.24 | 0.18 | 0.09 | 0 |
| 4 × 16 | 0.60 | 0 | 0.24 | 0 | 0.16 | 0 |
| 8 × 8 | 0.54 | 0 | 0.23 | 0.23 | 0 | 0 |
| 8 × 4 | 0.66 | 0 | 0 | 0.34 | 0 | 0 |
| 4 × 8 | 0.66 | 0 | 0.34 | 0 | 0 | 0 |
| Parameter Name | Parameter Settings |
|---|---|
| Number of feature attributes | 10 |
| Number of decision trees | 15 |
| The maximum depth of the decision tree | 20 |
| Minimum number of samples to divide a node | 25 |
| Class | Sequence Name | Resolution | Frame Count | Frame Rate | Bit Depth |
|---|---|---|---|---|---|
| A1 | Tango2 | 3840 × 2160 | 294 | 60 fps | 10 |
| FoodMarket4 | 300 | 60 fps | 10 | ||
| Campfire | 300 | 30 fps | 10 | ||
| A2 | CatRobot | 3840 × 2160 | 300 | 60 fps | 10 |
| DaylightRoad2 | 300 | 60 fps | 10 | ||
| ParkRunning3 | 300 | 50 fps | 10 | ||
| B | MarketPlace | 1920 × 1080 | 240 | 24 fps | 8 |
| RitualDance | 240 | 24 fps | 8 | ||
| Cactus | 500 | 50 fps | 8 | ||
| BasketballDrive | 500 | 50 fps | 8 | ||
| BQTerrace | 600 | 60 fps | 8 | ||
| C | BasketballDrill | 832 × 480 | 500 | 50 fps | 8 |
| BQMall | 600 | 60 fps | 8 | ||
| PartyScene | 500 | 50 fps | 8 | ||
| RaceHorses | 300 | 30 fps | 8 | ||
| D | BasketballPass | 416 × 240 | 500 | 50 fps | 8 |
| BQSquare | 600 | 60 fps | 8 | ||
| BlowingBubbles | 500 | 50 fps | 8 | ||
| RaceHorese | 300 | 30 fps | 8 | ||
| E | FourPeople | 1280 × 720 | 600 | 60 fps | 8 |
| Johnny | 600 | 60 fps | 8 | ||
| KristenAndSara | 600 | 60 fps | 8 |
| Class | Sequence | OUR | ||
|---|---|---|---|---|
| BDBR | ||||
| A1 | Tango2 | 1.70 | 67.72 | 39.84 |
| FoodMarket4 | 1.61 | 52.19 | 32.42 | |
| Campfire | 1.79 | 61.77 | 34.51 | |
| A2 | CatRobot | 2.13 | 64.04 | 30.07 |
| DaylightRoad2 | 1.69 | 69.88 | 41.35 | |
| ParkRunning3 | 1.36 | 58.42 | 42.96 | |
| B | MarketPlace | 1.14 | 70.08 | 61.47 |
| RitualDance | 2.01 | 52.23 | 25.99 | |
| Cactus | 1.52 | 63.08 | 41.50 | |
| BasketballDrive | 1.59 | 65.34 | 41.09 | |
| BQTerrace | 1.79 | 53.45 | 29.86 | |
| C | BasketballDrill | 1.65 | 44.61 | 27.04 |
| BQMall | 1.62 | 54.03 | 33.35 | |
| PartyScene | 1.45 | 47.78 | 32.95 | |
| RaceHorses | 1.15 | 47.77 | 41.54 | |
| D | BasketballPass | 1.53 | 46.92 | 30.67 |
| BQSquare | 1.98 | 41.63 | 21.03 | |
| BlowingBubbles | 1.16 | 45.66 | 39.36 | |
| RaceHorese | 1.82 | 49.78 | 27.35 | |
| E | FourPeople | 1.67 | 53.34 | 31.94 |
| Johnny | 1.69 | 48.85 | 28.91 | |
| KristenAndSara | 1.96 | 55.61 | 28.37 | |
| Average | 1.64 | 55.19 | 33.65 | |
| Class | Sequence | LI [33] | PAN [34] | ZHANG [35] | OUR | ||||
|---|---|---|---|---|---|---|---|---|---|
| BDBR | BDBR | BDBR | BDBR | ||||||
| A1 | Tango2 | 1.55 | 50.59 | 3.68 | 34.05 | 2.07 | 65.06 | 1.70 | 67.72 |
| FoodMarket4 | 1.61 | 50.11 | 1.59 | 42.90 | 1.95 | 51.77 | 1.61 | 52.19 | |
| Campfire | 1.59 | 51.85 | 2.80 | 30.08 | 1.81 | 55.92 | 1.79 | 61.77 | |
| A2 | CatRobot | 1.77 | 47.92 | 5.59 | 30.62 | 2.33 | 61.22 | 2.13 | 64.04 |
| DaylightRoad2 | 1.39 | 54.33 | 4.43 | 29.20 | 1.77 | 61.48 | 1.69 | 69.88 | |
| ParkRunning3 | 1.46 | 48.11 | 1.61 | 21.30 | 1.71 | 57.88 | 1.36 | 58.42 | |
| B | MarketPlace | / | / | 3.22 | 36.47 | / | / | 1.14 | 70.08 |
| RitualDance | / | / | 2.97 | 31.23 | / | / | 2.01 | 52.23 | |
| Cactus | 1.31 | 44.95 | 5.20 | 25.42 | 1.73 | 61.26 | 1.52 | 63.08 | |
| BasketballDrive | 1.49 | 46.16 | 2.96 | 32.39 | 1.92 | 58.63 | 1.59 | 65.34 | |
| BQTerrace | 0.94 | 48.33 | 0.98 | 13.80 | 1.50 | 54.55 | 1.79 | 53.45 | |
| C | BasketballDrill | 1.49 | 46.16 | 1.59 | 24.38 | 1.79 | 47.27 | 1.65 | 44.61 |
| BQMall | 1.24 | 48.33 | 2.35 | 22.41 | 1.52 | 49.5 | 1.62 | 54.03 | |
| PartyScene | 0.83 | 45.88 | 1.84 | 14.94 | 1.18 | 48.22 | 1.45 | 47.78 | |
| RaceHorses | 0.81 | 46.95 | 2.23 | 22.55 | 1.35 | 48.26 | 1.15 | 47.77 | |
| D | BasketballPass | 1.41 | 40.04 | 1.56 | 21.18 | 1.76 | 41.98 | 1.53 | 46.92 |
| BQSquare | 0.89 | 46.68 | 0.84 | 9.69 | 1.34 | 43.67 | 1.98 | 41.63 | |
| BlowingBubbles | 0.99 | 43.86 | 2.29 | 16.97 | 1.46 | 38.02 | 1.16 | 45.66 | |
| RaceHorese | 1.27 | 39.21 | 2.24 | 20.33 | 1.76 | 47.21 | 1.82 | 49.78 | |
| E | FourPeople | 1.55 | 52.64 | 1.76 | 25.26 | 1.77 | 56.81 | 1.67 | 53.34 |
| Johnny | 1.58 | 50.67 | 1.69 | 24.92 | 2.30 | 57.65 | 1.69 | 48.85 | |
| KristenAndSara | 1.63 | 49.82 | 2.11 | 26.21 | 1.98 | 56.57 | 1.96 | 55.61 | |
| Average | 1.34 | 47.63 | 2.52 | 24.83 | 1.75 | 53.15 | 1.64 | 55.19 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Liu, Y.; Zhao, J.; Zhang, Q. A Low-Complexity Fast CU Partitioning Decision Method Based on Texture Features and Decision Trees. Electronics 2023, 12, 3314. https://doi.org/10.3390/electronics12153314
Wang Y, Liu Y, Zhao J, Zhang Q. A Low-Complexity Fast CU Partitioning Decision Method Based on Texture Features and Decision Trees. Electronics. 2023; 12(15):3314. https://doi.org/10.3390/electronics12153314
Chicago/Turabian StyleWang, Yanjun, Yong Liu, Jinchao Zhao, and Qiuwen Zhang. 2023. "A Low-Complexity Fast CU Partitioning Decision Method Based on Texture Features and Decision Trees" Electronics 12, no. 15: 3314. https://doi.org/10.3390/electronics12153314
APA StyleWang, Y., Liu, Y., Zhao, J., & Zhang, Q. (2023). A Low-Complexity Fast CU Partitioning Decision Method Based on Texture Features and Decision Trees. Electronics, 12(15), 3314. https://doi.org/10.3390/electronics12153314