
A Lightweight Model for Real-Time Monitoring of Ships



Abstract
:1. Introduction
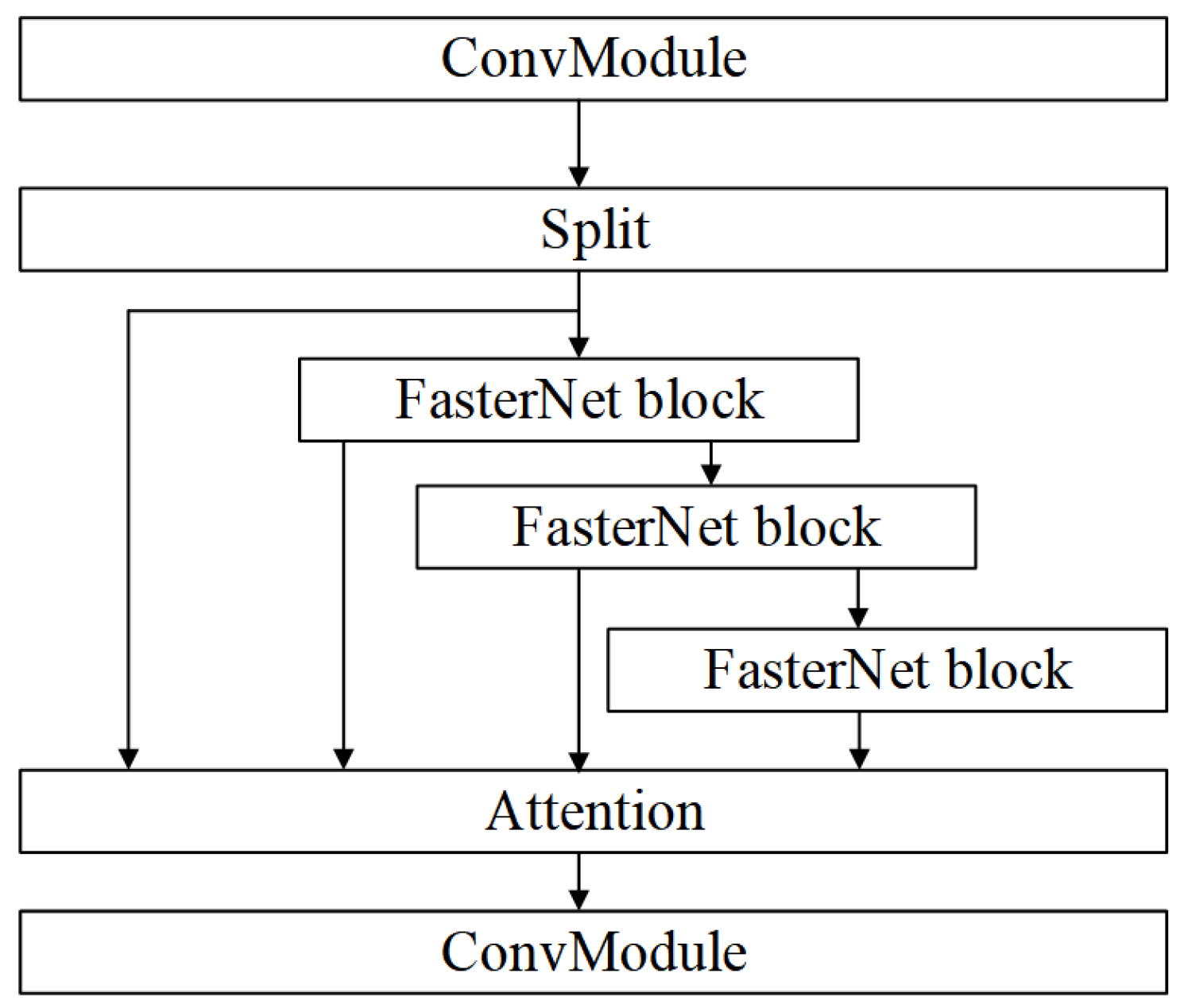
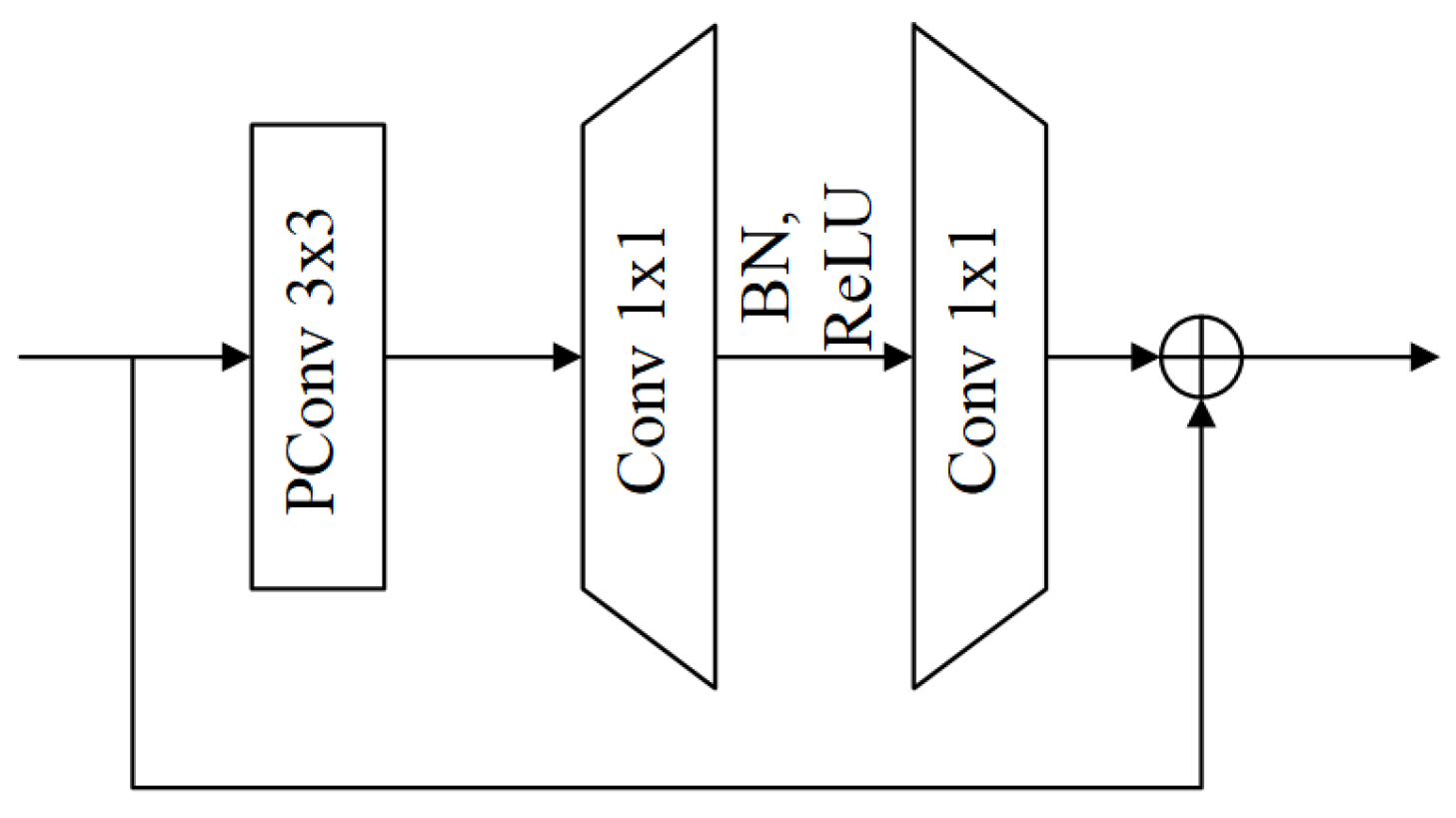
- Inspired by FasterNet, we integrate simple and effective FasterNet blocks into the backbone of YOLOv8n. Additionally, we fuse the attention mechanism into the FasterNet block, enhancing the backbone’s lightweight nature and feature extraction capabilities.
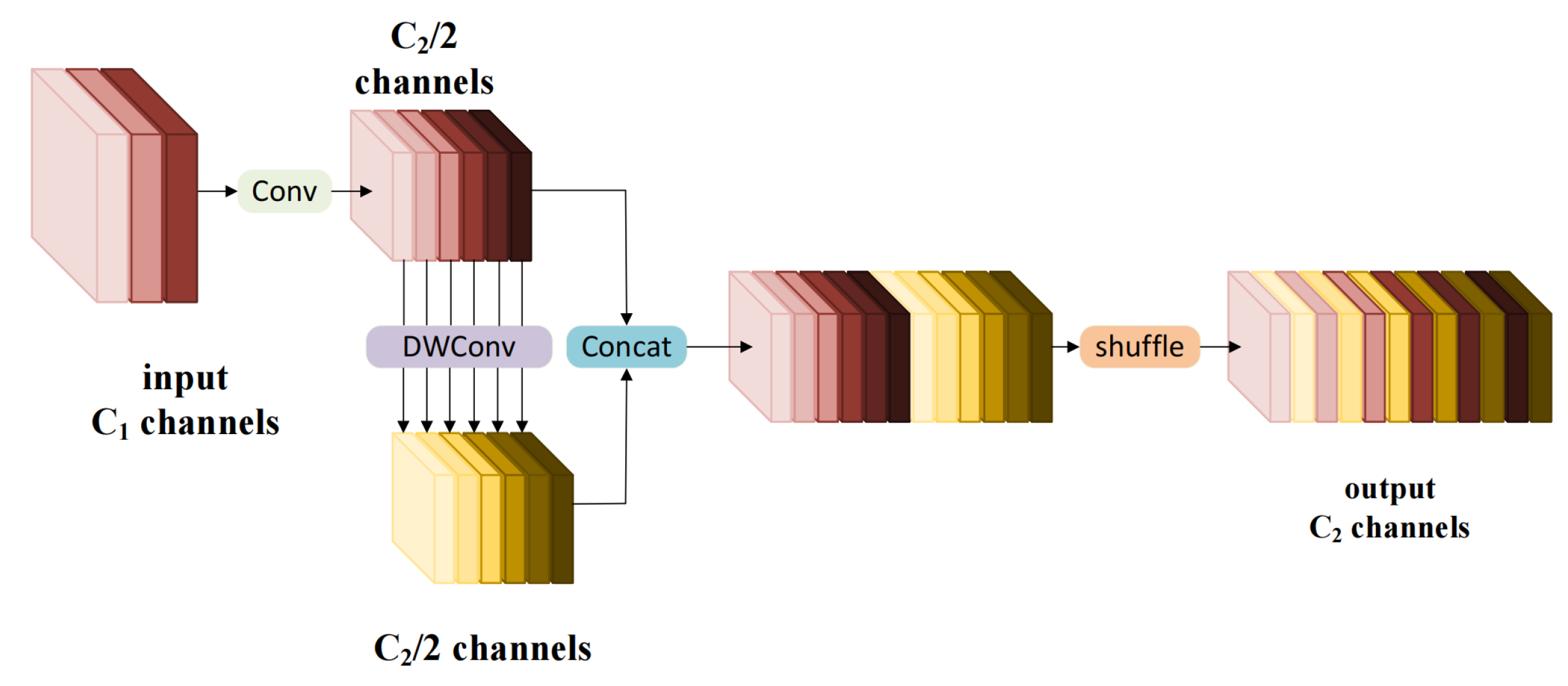
- We introduce a lightweight yet feature-rich neck network, and employ the lightweight GSConv convolution approach as a substitute for conventional convolution modules. Additionally, we replace the complex CSP module with a one-shot VoV-GSCSP aggregation module based on the GSConv design. Flexibly combining GSConv and VoV-GSCSP achieves an improved balance between computational costs and the performance of the feature fusion network.
- We introduce an IoU loss measure called MPDIoU based on the minimum points distance to address the limitations of existing loss functions, leading to faster convergence speed and more accurate regression results.
- We collected and processed surveillance images of waterborne ships in order to create a dataset designed explicitly for ship detection and tracking. This dataset includes various types of ships, making it suitable for real-time ship monitoring tasks.
2. Related Works
2.1. Object Detection
2.2. Lightweight Object Detection Models
2.3. Attention Mechanism
2.4. Loss Function
2.5. Multiple Object Tracking
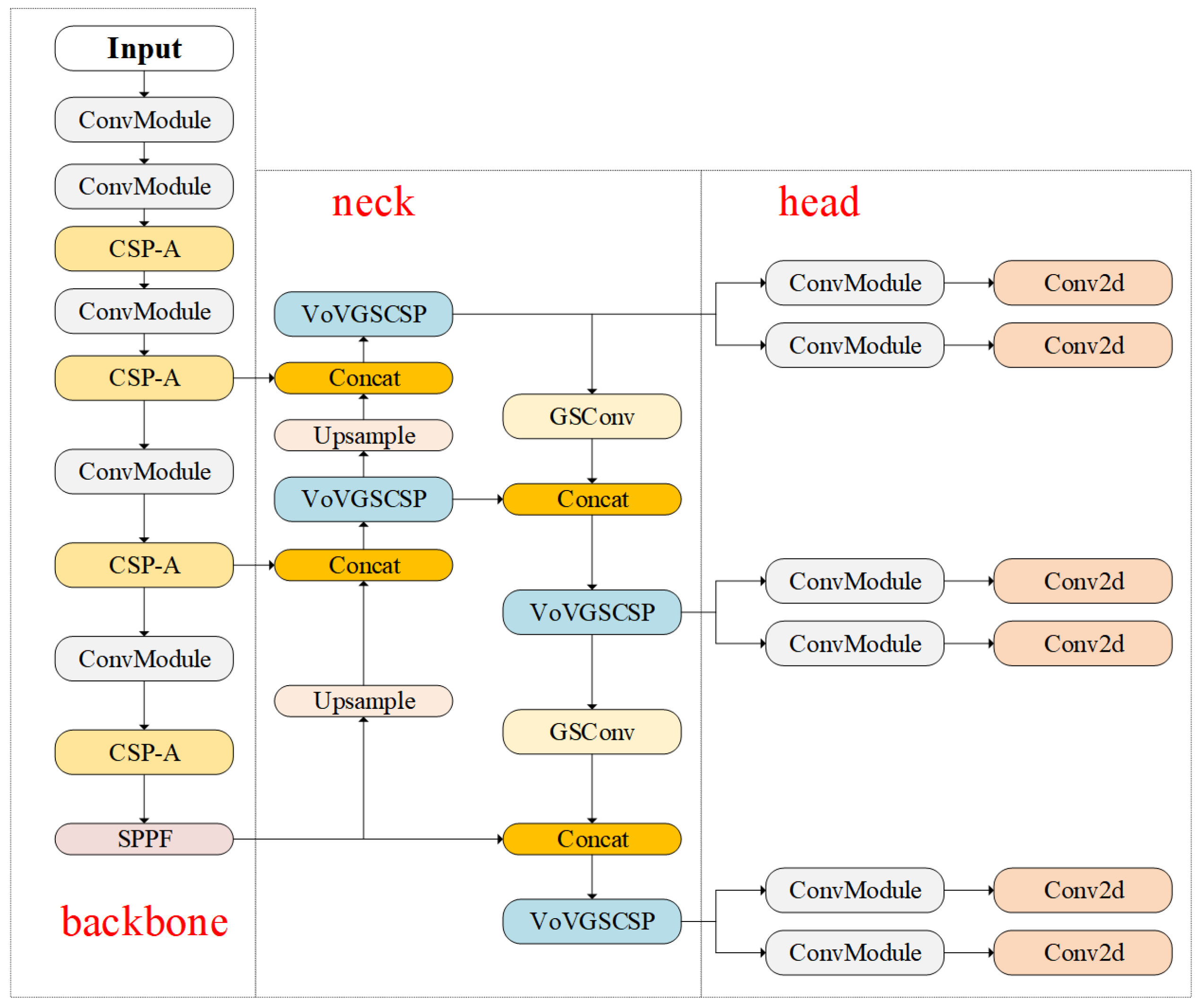
3. Methodology
3.1. Backbone
3.2. Neck
3.3. Loss Function
3.4. Ship Tracking
4. Experiments
4.1. Evaluation Metrics
4.2. Experimental Platform
4.3. Dataset
- (1)
- The picture backgrounds are highly complex and disturbed, including but not limited to nearshore buildings;
- (2)
- The size difference between the ship targets in the images is significant, and it is difficult to identify small targets;
- (3)
- The appearance of similar ships is quite different, with the bulk carrier ship being the most complex.
4.4. Ablation Experiments
4.5. Validation of the Improved Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bauwens, J. Datasharing in Inland Navigation. In PIANC Smart Rivers 2022: Green Waterways and Sustainable Navigations; Springer Nature: Singapore, 2023; pp. 1353–1356. [Google Scholar]
- Wu, Z.; Woo, S.H.; Lai, P.L.; Chen, X. The economic impact of inland ports on regional development: Evidence from the Yangtze River region. Transp. Policy 2022, 127, 80–91. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, W.; Wu, J. Strategies for High Quality Development of Smart Inland Shipping in Zhejiang Province Based on “Four-Port Linkage”. In PIANC Smart Rivers 2022: Green Waterways and Sustainable Navigations; Springer Nature: Singapore, 2023; pp. 1409–1418. [Google Scholar]
- Zhang, J.; Wan, C.; He, A.; Zhang, D.; Soares, C.G. A two-stage black-spot identification model for inland waterway transportation. Reliab. Eng. Syst. Saf. 2021, 213, 107677. [Google Scholar] [CrossRef]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 28–23 June 2018; pp. 1468–1476. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, H.; Xu, C.; Lv, Y.; Fu, C.; Xiao, H.; He, Y. A Lightweight Feature Optimizing Network for Ship Detection in SAR Image. IEEE Access 2019, 7, 141662–141678. [Google Scholar] [CrossRef]
- Jie, Y.; Leonidas, L.; Mumtaz, F.; Ali, M. Ship Detection and Tracking in Inland Waterways Using Improved YOLOv3 and Deep SORT. Symmetry 2021, 13, 308. [Google Scholar] [CrossRef]
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep learning for SAR ship detection: Past, present and future. Remote. Sens. 2022, 14, 2712. [Google Scholar] [CrossRef]
- Xing, Z.; Ren, J.; Fan, X.; Zhang, Y. S-DETR: A Transformer Model for Real-Time Detection of Marine Ships. J. Mar. Sci. Eng. 2023, 11, 696. [Google Scholar] [CrossRef]
- Er, M.J.; Zhang, Y.; Chen, J.; Gao, W. Ship detection with deep learning: A survey. Artif. Intell. Rev. 2023, 56, 11825–11865. [Google Scholar] [CrossRef]
- Yun, J.; Jiang, D.; Liu, Y.; Sun, Y.; Tao, B.; Kong, J.; Tian, J.; Tong, X.; Xu, M.; Fang, Z. Real-time target detection method based on lightweight convolutional neural network. Front. Bioeng. Biotechnol. 2022, 10, 861286. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. Fighting against COVID-19: A novel deep learning model based on YOLO-v2 with ResNet-50 for medical face mask detection. Sustain. Cities Soc. 2020, 65, 102600. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D.; et al. Ultralytics/Yolov5: V7. 0-Yolov5 Sota Realtime Instance Segmentation. Zenodo. 2022. Available online: https://ui.adsabs.harvard.edu/abs/2022zndo...7347926J/abstract (accessed on 22 November 2022).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Wey, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Siliang, M.; Yong, X. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. Seaships: A large-scale precisely annotated dataset for ship detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Improvement | Parameters | FLOPs | mAP0.5 | ||
|---|---|---|---|---|---|---|
| Backbone | Slimneck | MDPIoU | / | / | /% | |
| YOLOv8 | 3.0 | 8.1 | 97.6 | |||
| YOLOv8-FA | + | 2.6 | 7.1 | 98.0 | ||
| YOLOv8-S | + | 2.8 | 7.3 | 97.8 | ||
| YOLOv8-I | + | 3.0 | 8.1 | 97.8 | ||
| YOLOv8-FAS | + | + | + | 2.4 | 6.3 | 98.5 |
| Detection Network | FLOPs | Parameters | Precision/% | Recall/% | mAP0.5/% | mAP0.5:0.95/% |
|---|---|---|---|---|---|---|
| YOLOv8 | 98.0 | 94.4 | 97.6 | 81.2 | ||
| YOLOv8-FAS | 98.4 | 95.8 | 98.5 | 84.9 |
| Class | Precision/% | Recall/% | mAP0.5/% | mAP0.5:0.95/% |
|---|---|---|---|---|
| all | 97.6 | 97.5 | 98.9 | 78.8 |
| ore carrler | 100 | 96.8 | 99.4 | 81.0 |
| passenger ship | 94.4 | 96.7 | 97.9 | 74.2 |
| general cargo ship | 96.5 | 96.7 | 98.3 | 74.6 |
| bulk cargo carrier | 97.6 | 98.7 | 99.5 | 81.4 |
| container ship | 99.2 | 100 | 99.5 | 85.2 |
| fishing boat | 97.8 | 95.9 | 99.0 | 76.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, B.; Wang, W.; Qian, J.; Pan, C.; Le, Q. A Lightweight Model for Real-Time Monitoring of Ships. Electronics 2023, 12, 3804. https://doi.org/10.3390/electronics12183804
Xing B, Wang W, Qian J, Pan C, Le Q. A Lightweight Model for Real-Time Monitoring of Ships. Electronics. 2023; 12(18):3804. https://doi.org/10.3390/electronics12183804
Chicago/Turabian StyleXing, Bowen, Wei Wang, Jingyi Qian, Chengwu Pan, and Qibo Le. 2023. "A Lightweight Model for Real-Time Monitoring of Ships" Electronics 12, no. 18: 3804. https://doi.org/10.3390/electronics12183804
APA StyleXing, B., Wang, W., Qian, J., Pan, C., & Le, Q. (2023). A Lightweight Model for Real-Time Monitoring of Ships. Electronics, 12(18), 3804. https://doi.org/10.3390/electronics12183804