In the field of computer graphics, the optimization of GPU rendering performance has been one of the hot research topics. Through the analysis of workload characteristics at the instruction, thread, and memory levels, this paper is able to understand the impact of different levels of GPU workload on the performance of rendering programs. The comprehensive application of machine learning methods allows for a thorough evaluation of the contributions of various characteristics to rendering performance, thereby offering specific recommendations for optimizing the design of rendering GPUs. Moreover, a comparative analysis with the Rodinia and Parboil benchmark datasets can reveal differences between the rendering benchmark dataset and other non-rendering benchmark datasets, which helps further optimize GPU designs and promote the development of rendering technology.
4.1. Performance Analysis of Workload Characteristics
In this study, NVProf was utilized to collect workload characteristic data for the initial set of 100 GPU rendering benchmark programs, as well as the CUDA evaluation programs Rodinia and Parboil. The experiments were conducted on a Supermicro SYS-7048GR-TR tower server equipped with an Intel Xeon E5-2650 CPU and NVIDIA Pascal P100, A100, T4, and 2080Ti GPUs. The experimental environments for the different GPUs consisted of the following components: For the P100 GPU, we utilized Ubuntu 20.04, CUDA version 11.2, CUDA Driver version 495.29.05, Python version 3.6, and scikit-learn version 0.19. For the A100 GPU, our experimental setup included Ubuntu 20.04, CUDA version 11.6, and CUDA Driver version 510.73.08. The NVIDIA T4 GPU was operated in an environment with CUDA version 11.4 and CUDA Driver version 470.42.01, while the NVIDIA 2080Ti GPU was evaluated in an environment with CUDA version 11.4 and CUDA Driver version 510.47.03. These configurations were employed to ensure a consistent and reliable experimental setup across different GPU models.
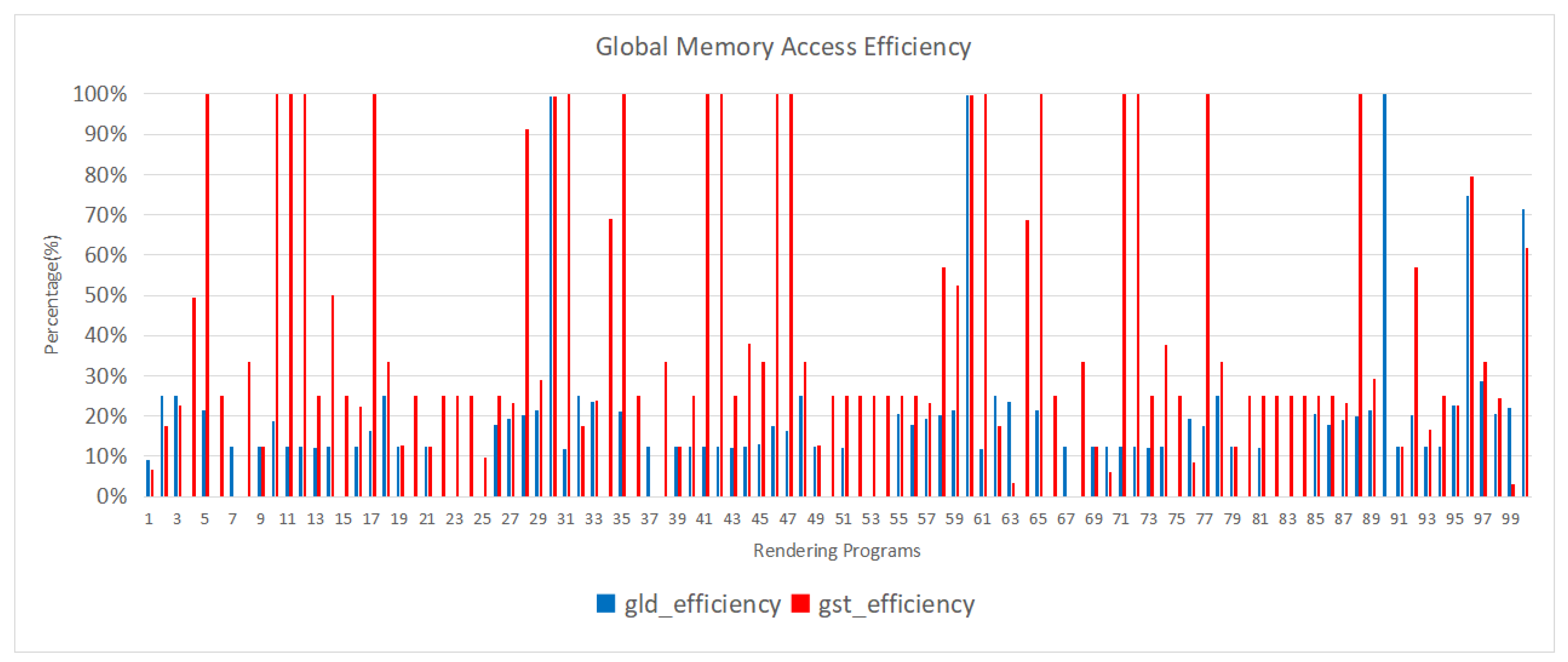
Figure 2 illustrates the global memory access efficiency of the 100 GPU rendering programs. Out of these programs, only six achieved an efficiency of 28% or higher for global memory load throughput, with an average of 16.45% and a median of 12.50%. In contrast, among the 21 Rodinia programs and 11 Parboil programs, 16 and 10 programs, respectively, achieved an efficiency of 28% or higher for global memory load throughput. They exhibited average values of 56.16% and 74.20%, with median values of 56.23% and 81.87%. This analysis reveals that both the Rodinia and Parboil programs have a significant number of programs with high global memory access efficiency, with the majority of them surpassing the 28% threshold. The average and median efficiencies for both sets of programs are notably higher compared to the GPU rendering programs, indicating their effectiveness in utilizing global memory resources efficiently. Backprop is one of the programs included in the Rodinia benchmark suite. It implements the backpropagation algorithm, which is a key component of training artificial neural networks. The backpropagation algorithm computes gradients to update the weights of a neural network during the training process. The program involves a series of matrix operations, including matrix multiplications and element-wise operations. The BFS (Breadth-First Search) program from the Parboil suite is an implementation of the breadth-first search algorithm, commonly used in graph traversal. The BFS algorithm explores a graph data structure, starting from a specified source node and visiting all its neighbors before moving on to their neighbors. This program typically consists of data structures like adjacency lists or matrices and involves memory-intensive operations for managing the queue of nodes to visit. The relatively low efficiency in global memory load throughput for rendering programs can be attributed to their substantial requirements for loading and processing texture and geometry data. These data often exhibit large-scale and continuous characteristics and are distributed across different memory regions. When rendering programs need to access multiple textures, vertex data, and frame buffer data simultaneously, frequent data switching and jumping can introduce memory access latency and overhead, thereby reducing loading efficiency.
At the same time, out of the 100 GPU rendering programs, only 41 achieved an efficiency of 28% or higher for global memory storage throughput, with an average of 40.52% and a median of 25.00%. Among the 21 Rodinia programs and 14 Parboil programs, 16 and 8 programs, respectively, achieved an efficiency of 28% or higher for global memory storage throughput. They displayed average values of 60.00% and 68.31%, with median values of 69.57% and 93.84%. During the rendering process, spatial and temporal locality are commonly observed in the data. Spatial locality refers to the frequent access of neighboring pixels or vertices by the rendering algorithm, while temporal locality denotes the repeated access to the same pixel or vertex. The low efficiency in global memory storage throughput for GPU rendering programs can be attributed to the data dependencies that arise. In image rendering, the computation results from the previous frame are required for subsequent frames or, when calculating the value of a pixel, it relies on the values of surrounding pixels. This data dependency necessitates computational tasks to wait for data readiness in global memory before proceeding to the next step.
The GPU utilization and stream processor efficiency of the 100 GPU rendering programs are depicted in
Figure 3. The average and median values of GPU utilization for the 100 GPU rendering programs are 0.482 and 0.478, respectively. For the Rodinia programs and Parboil, the average GPU utilization values are 0.408 and 0.498, with corresponding median values of 0.425 and 0.553. This indicates that 50 rendering programs have a GPU utilization higher than 0.478, suggesting a relatively high overall GPU utilization for rendering programs. This is attributed to the presence of complex lighting computation algorithms in ray tracing-based rendering programs, which require extensive floating-point operations and vector manipulations. Such computationally intensive tasks lead to higher GPU utilization.
The coefficient of variation for GPU utilization among the 100 GPU rendering programs is 0.605, while for the Rodinia and Parboil programs, it is 0.773 and 0.540, respectively. The coefficient of variation is a statistical measure that indicates the degree of fluctuation in a dataset, with higher values indicating greater variability. The GPU utilization of the 100 GPU rendering programs exhibits relatively high variation, signifying significant differences in utilization rates. A coefficient of variation of 0.605 suggests a high degree of dispersion in utilization rates, which may be attributed to different task characteristics, algorithm implementations, or data access patterns among these rendering programs.
The average and median stream processor efficiency values for the 100 GPU rendering programs are 0.793 and 0.940, respectively. For the Rodinia programs and Parboil programs, the average stream processor efficiency values are 0.566 and 0.720, with corresponding median values of 0.747 and 0.888. This discrepancy in sm_efficiency indicates that the Rodinia and Parboil programs tend to utilize stream processors less efficiently on average than the GPU rendering programs. Lower sm_efficiency values indicate that stream processors in the Rodinia and Parboil programs experience underutilization or idle time more frequently, potentially due to differences in computational characteristics and memory access patterns. Rodinia benchmark programs are designed to represent various real-world scientific and engineering applications. These programs often involve complex data access patterns, including irregular memory access and data dependencies. Such patterns can lead to less efficient use of stream processors, resulting in lower sm_efficiency values. Through an analysis of the source code of rendering programs with low stream processor efficiency, this study revealed that certain ray-tracing rendering programs emit rays in a serial manner. This serial emission of rays introduces latency, as each ray has to wait for the intersection and computation of the previous ray to be completed. Consequently, the increase in latency diminishes image rendering performance. GPUs are purposefully designed for highly parallel computations and typically incorporate multiple stream processors to concurrently execute various computing tasks. Each stream processor is capable of handling intersection tests and lighting calculations for a ray, thereby enabling the simultaneous processing of multiple rays. However, in scenarios where only one ray is executing computations, the remaining stream processors remain idle, failing to fully exploit the parallel computing capabilities of the GPU and resulting in inefficient resource utilization.
The efficiency of stream processors in 100 GPU rendering programs is shown in
Figure 4. The average and median values of thread warp execution efficiency for the 100 GPU rendering programs are 72.79% and 91.91%, respectively. For the Rodinia programs and Parboil programs, the average thread warp execution efficiency values are 80.48% and 91.68%, with corresponding median values of 92.80% and 94.83%. The high thread warp execution efficiency values in both the Rodinia and Parboil programs reflect the efficient utilization of GPU parallelism, well-optimized GPU code, and the suitability of these applications for GPU acceleration. The specific programs within these suites may exhibit variations in efficiency, but the overall trend highlights the effectiveness of GPU programming in harnessing parallelism for a wide range of computational tasks. For instance, the K-Means program in Rodinia inherently involves a significant amount of repetitive and independent calculations. It operates by iteratively assigning data points to clusters and recalculating the cluster centroids. Each data point’s assignment and centroid recalculation can be performed independently, making it highly amenable to parallelization. When threads within a warp encounter branching statements and conditional evaluations during execution, each thread follows a different execution path based on the conditions. This leads to divergence among the threads within the warp, where some threads enter one branch while others enter another. This divergence significantly impacts the execution efficiency of the thread warp as the instruction streams of the different threads are no longer completely identical.
Rendering programs involve numerous branching statements due to the inherent irregularities in materials, lighting calculations, and geometry. These programs often require performing computations for different materials and lighting models, which necessitates the use of different branching logic. For instance, based on the material properties of an object, specific lighting computation methods or shading models must be selected. Moreover, rendering scenes may encompass various shapes, sizes, and complexities in terms of geometry, thereby demanding the handling of diverse branching scenarios during intersection tests between rays and objects. For instance, different algorithms or processing approaches may be employed to test intersections between surfaces and polygons.
Meanwhile, the average and median values of thread warp non-conditional execution efficiency for the 100 GPU rendering programs are 67.31% and 81.31%, respectively. For the Rodinia and Parboil programs, the average thread warp non-conditional execution efficiency values are 76.56% and 85.35%, with corresponding median values of 87.17% and 86.27%. Many programs within the Rodinia and Parboil suites rely on parallel execution patterns that do not involve complex conditional branching. This is especially true for applications like scientific simulations, image processing, and data analytics, where computations often involve straightforward, data-parallel operations. The benchmarks in these suites often deal with regular and predictable workloads, where the same operations are applied to multiple data elements in a uniform manner. This regularity enables efficient pipelining and execution of instructions across threads and warps. The thread warp non-conditional execution efficiency of the 100 GPU rendering programs is relatively low. This is primarily attributed to the prevalence of branching and conditional evaluations required in common lighting calculations and texture sampling operations during the rendering process. Branching operations involve selecting different code branches for execution based on specific conditions. For instance, in lighting calculations, the intensity and color of light are determined based on the relationship between the light source and objects. This necessitates conditional evaluations to choose different lighting models or computation methods. Similarly, texture sampling may involve different filtering techniques and boundary handling, requiring conditional evaluations to select appropriate sampling methods.
The complexity of branching operations depends on the number and complexity of conditions involved. If the branching conditions are intricate or numerous, threads within the warp may diverge during execution. Consequently, some threads within the warp have to wait for the results of other threads executing different branches, thereby reducing non-conditional execution efficiency. The underlying reason behind this situation lies in the dependency and data correlation in parallel computations. Within a thread warp, all threads must execute along the same code path to ensure result consistency. However, when branching operations are present, threads within the warp choose different branches to execute based on the conditions, but only a subset of threads actually satisfy the conditions while others remain in a waiting state. Due to the inherent nature of GPUs, threads within a warp must synchronize their execution, meaning that all threads need to wait for the slowest thread to complete. Consequently, when threads within the thread warp need to wait for the execution results of other threads after branching evaluations, it leads to performance bottlenecks and diminishes non-conditional execution efficiency.
The utilization of bandwidth and shared memory in the 100 GPU rendering programs is depicted in
Figure 5. The average and median values of bandwidth utilization for the 100 GPU rendering programs are 17.94% and 4.19%, respectively. For the Rodinia programs and Parboil programs, the average bandwidth utilization values are 13.54% and 13.11%, respectively. The lower bandwidth utilization in Rodinia programs could be attributed to the nature of their workloads. Many Rodinia benchmarks involve scientific simulations and computations that primarily rely on computations performed in registers and shared memory, resulting in fewer memory accesses. Parboil benchmarks encompass a variety of data-intensive workloads, including image processing and data compression, which involve memory accesses for large datasets. However, the optimizations in these programs seem to mitigate excessive memory bandwidth usage. Rendering programs demonstrate relatively high bandwidth utilization primarily due to the implementation of data caching and reuse techniques, which minimize frequent memory accesses and data transfers to the main memory, thereby enhancing bandwidth utilization. Textures serve as frequently used image data in rendering programs, such as textures for mapping or surface patterns. Transferring texture data typically requires substantial bandwidth and time. To minimize the frequency of data transfers, texture data is stored in the texture cache of the GPU and reused when necessary. The texture cache, located within the GPU, offers high bandwidth and low latency access, facilitating swift delivery of texture data to the rendering pipeline. Caching texture data on the GPU device helps avoid unnecessary data transfers and frequent accesses to the main memory, thus enhancing bandwidth utilization and overall rendering performance.
In rendering programs, vertex data describes the geometric structure and attributes of objects. Vertex data is often reused multiple times during the rendering process, for operations such as transformations, lighting calculations, and clipping. Storing vertex data in the vertex cache of the GPU and reusing it when needed reduces memory accesses and data transfers to the main memory. The vertex cache possesses high bandwidth and low latency characteristics, enabling rapid provision of vertex data to the rendering pipeline, thereby enhancing bandwidth utilization and rendering performance. By utilizing the vertex cache, rendering programs can prevent unnecessary transfers of vertex data, reduce frequent accesses to the main memory, and improve efficiency.
Among the 100 GPU rendering programs, only two exhibit non-zero values for shared memory utilization. For the Rodinia programs and Parboil programs, 13 and 8 programs, respectively, show non-zero values for shared memory utilization. The average values for shared memory utilization in these programs are 31.69% and 24.29%, respectively. Shared memory is commonly used in Rodinia benchmarks to facilitate inter-thread communication and data sharing. For instance, the “BFS” (Breadth-First Search) benchmark frequently accesses shared memory to coordinate parallel traversal of graph structures. Shared memory utilization in Parboil programs is often related to optimizing data access patterns and facilitating communication among parallel threads. For example, the “mri-gridding” benchmark involves shared memory utilization to manage data for image reconstruction tasks. In the rendering process, most operations involve independent calculations for different pixels or vertices. This implies that the data required by each thread is typically not shared with other threads, making the use of shared memory for data sharing unnecessary. Rendering programs often prioritize parallel computation over data sharing, leading to relatively low utilization of shared memory. Modern GPU devices are generally characterized by multi-level memory hierarchies, including global memory, shared memory, and registers. Shared memory represents a relatively small but fast memory in the GPU, whereas global memory usually offers larger capacity. Due to the limited capacity of shared memory, rendering programs tend to store data in global memory rather than shared memory. Additionally, rendering programs employ optimization strategies such as texture caching, vertex caching, and parallel computation to enhance performance. These optimization techniques can improve rendering program performance without heavily relying on shared memory, thereby resulting in lower utilization of shared memory.
Figure 6 illustrates the Pearson correlation analysis of the GPU rendering program benchmark dataset. The dataset comprises 100 GPU rendering programs, with 160 GPU characteristics that were standardized before conducting the correlation analysis. To ensure the dataset’s comprehensiveness and diversity, rendering programs with non-significant correlation coefficients and those exhibiting correlation coefficients above 0.85 were excluded. Ultimately, a representative GPU rendering benchmark dataset consisting of 16 programs was selected (
Table 5).
4.2. Workload Characteristics Ranking Analysis
A rendering program typically comprises multiple tasks or threads, such as rendering threads, physics simulation threads, lighting calculation threads, and others. Conducting workload characteristic ranking analysis provides valuable insights into the relative importance and priority of each task, facilitating effective task scheduling and parallel processing to maximize computational resource utilization. Moreover, workload characteristic ranking analysis of a rendering program helps identify potential performance bottlenecks and their underlying causes. By comprehending computational workloads, memory bandwidth requirements, and other task-specific characteristics, potential bottlenecks can be accurately identified. For instance, if a particular task exhibits significant computational demands but low memory bandwidth requirements, the bottleneck is likely to stem from computational resources rather than memory bandwidth limitations. This understanding of workload characteristics enables targeted optimization and adjustment of rendering algorithms and hardware configurations, ultimately enhancing performance.
Additionally, workload characteristic ranking aids in analyzing the utilization of various resources by a rendering program. By understanding the program’s demands for bandwidth, memory, storage, and other resources, one can assess resource utilization and perform corresponding resource management and optimization to enhance overall resource efficiency. In this study, principal component analysis was applied to 160 GPU workload characteristics of 100 rendering programs running on four GPUs. The analysis revealed that “sm_efficiency” was the most significant characteristic across all four GPUs, serving as the dependent variable, while the remaining 159 GPU characteristics were treated as independent variables for Random Forest importance ranking. The Random Forest importance ranking results of the 100 GPU rendering programs on the four GPUs are depicted in
Figure 7, where higher-ranked characteristics indicate greater importance across different rendering programs, exerting a more significant impact on performance. Conversely, lower-ranked characteristics may have a lesser impact on performance or could even be negligible. By delving into the underlying principles, this study provides a deeper understanding of the relationship between rendering performance and various metrics, including thread execution efficiency, instruction execution counts, GPU utilization, and memory usage. Ranking the characteristics by their importance enables the identification of metrics that contribute significantly to performance.
Table 6 presents the comprehensive ranking of 10 Random Forest characteristic importance measures across four GPUs. Firstly, consideration is given to characteristic frequency, indicating the occurrence of a particular characteristic in the ranking across all four GPUs, which suggests its suitability as a performance indicator for rendering programs. Secondly, relative characteristic ranking scores are considered, where characteristics appearing in the ranking across four or three GPUs with higher relative scores are given higher positions in the comprehensive ranking. Lastly, average characteristic scores are considered, based on characteristics appearing in the ranking across two or three GPUs, and with closely aligned relative characteristic rankings. Characteristics with higher average scores are given higher positions in the comprehensive ranking. The Random Rorest importance ranking aids in optimizing the rendering process. Researchers can focus on key indicators that significantly impact performance, allowing for the optimization of corresponding algorithms or resource allocation strategies, thereby enhancing overall rendering performance.
Table 7 presents the comprehensive ranking of 10 characteristic importance measures obtained from the XGBoost, Adaboost, GBDT, and ExtraTrees algorithms. Rendering programs involve complex computations and data processing, as they transform three-dimensional scenes into two-dimensional images. When optimizing the performance and quality of rendering programs, understanding the importance of characteristics is crucial for identifying the most influential factors during the rendering process. Each machine learning method has unique advantages and characteristics. By employing multiple methods for characteristic ranking, we can obtain a comprehensive evaluation of characteristic importance from different perspectives and dimensions. This holistic assessment helps reveal the relationship between characteristics and rendering performance more comprehensively. Different machine learning methods employ distinct strategies and algorithms for characteristic ranking, providing robustness and stability when confronted with diverse data distributions and characteristic relationships. By comparing the results of multiple methods, potential biases or errors inherent to a single method can be reduced, thereby enhancing the reliability of the results. In rendering programs, the importance of different characteristics may vary depending on the scene, model, or rendering settings. Therefore, employing multiple machine learning methods for characteristic ranking enables a better capture of the overall importance of characteristics while mitigating potential biases introduced by specific methods, thus enhancing the robustness of the results.
Table 8 presents the final ranking of characteristic importance in rendering programs by integrating the results from the aforementioned five algorithms. This ranking takes into account evaluations from different algorithms to provide a more comprehensive assessment of characteristic importance. Considerations for each characteristic include characteristic frequency, relative ranking results, and the average rank across different rankings. These criteria are combined to generate the final comprehensive ranking of characteristic importance. The benefit of this integrated ranking is the reduction in biases introduced by individual algorithms, resulting in a more objective evaluation of characteristic importance. The GPU, as a core component in rendering, significantly influences the execution speed and quality of rendering programs. For example, GPU utilization represents the extent to which GPU cores utilize thread bundles during computation tasks. Higher utilization implies that GPU cores can make more efficient use of thread bundles and maintain a greater number of active thread bundles per computing cycle. This enhances the GPU’s parallel computing capabilities, thereby accelerating rendering program execution. During the rendering process, higher thread bundle utilization can better handle rendering tasks such as geometric computations and lighting calculations, leading to improved rendering speed and quality.
The characteristic “single-precision floating-point instruction execution count” indicates the number of single-precision floating-point multiply–accumulate operations executed by GPU cores. In rendering, single-precision floating-point operations are commonly used for lighting calculations, texture sampling, and geometric transformations, which are computationally intensive operations. A higher count indicates that GPU cores perform more floating-point computations, enhancing the accuracy and realism of rendering programs. However, it is important to consider the trade-off between computation precision and performance, as excessive floating-point computations may exhaust computational resources.
The characteristic “integer instruction execution count” represents the number of integer instructions executed by GPU cores. In rendering programs, integer instructions are used for geometric computations, texture indexing, and other operations. A higher count may indicate complex geometric computations and texture indexing operations, which are crucial for handling complex scenes and large-scale textures. Efficient execution of integer instructions can improve the performance and quality of rendering programs.
The characteristic “global memory request execution count” represents the total number of global memory requests issued by multiprocessors, excluding atomic requests. In the rendering process, global memory requests are used to write computation results back to global memory, including render target buffers and texture caches, among others. A higher count may indicate frequent reads and writes to global memory, which can lead to memory access bottlenecks and latency. Therefore, when optimizing rendering programs, it is essential to consider reducing the number of global memory requests and optimizing memory access patterns to improve rendering performance.
In conclusion, these GPU characteristics have diverse impacts on rendering programs. Higher GPU utilization and thread bundle utilization can enhance parallel computing capabilities and rendering speed. Higher counts of single-precision floating-point operations and integer instructions may improve the precision and realism of rendering programs. However, a high count of global memory requests may lead to memory access bottlenecks and latency, necessitating optimization. Therefore, during the optimization process of rendering programs, it is necessary to comprehensively consider these characteristics and make appropriate adjustments and trade-offs to achieve the best rendering performance and quality.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}