


Toward Unified and Quantitative Cinematic Shot Attribute Analysis


Abstract
:1. Introduction
2. Related Work
2.1. Two-Stream Architecture
2.2. Shot Arrtibute Analysis
2.3. Movie Shot Dataset
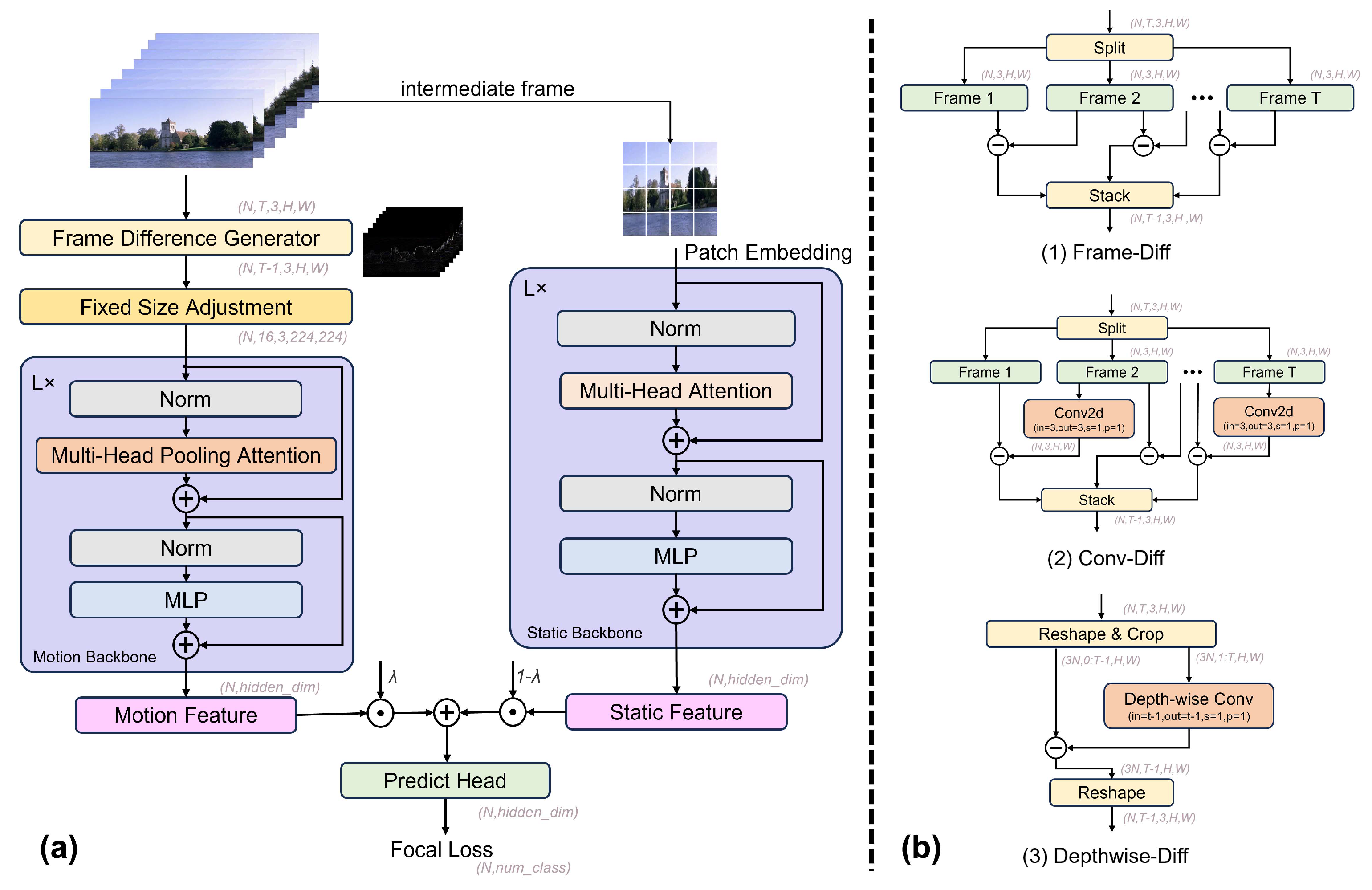
3. Approach
3.1. Problem Definition
3.2. Motion Branch
3.2.1. Drawbacks of Optical Flow
3.2.2. Frame Difference Generator
3.2.3. Motion Backbone
3.2.4. Fixed-Size Adjustment
3.3. Static Branch
3.4. Quantitative Feature Fusion
4. Experiment
4.1. Datasets
4.2. Experiment Setup
4.2.1. Data
4.2.2. Implementation Details
4.2.3. Evaluation Metrics
4.3. Overall Results
4.3.1. MovieShots
4.3.2. AVE
4.3.3. Analysis of Frame Difference Methods
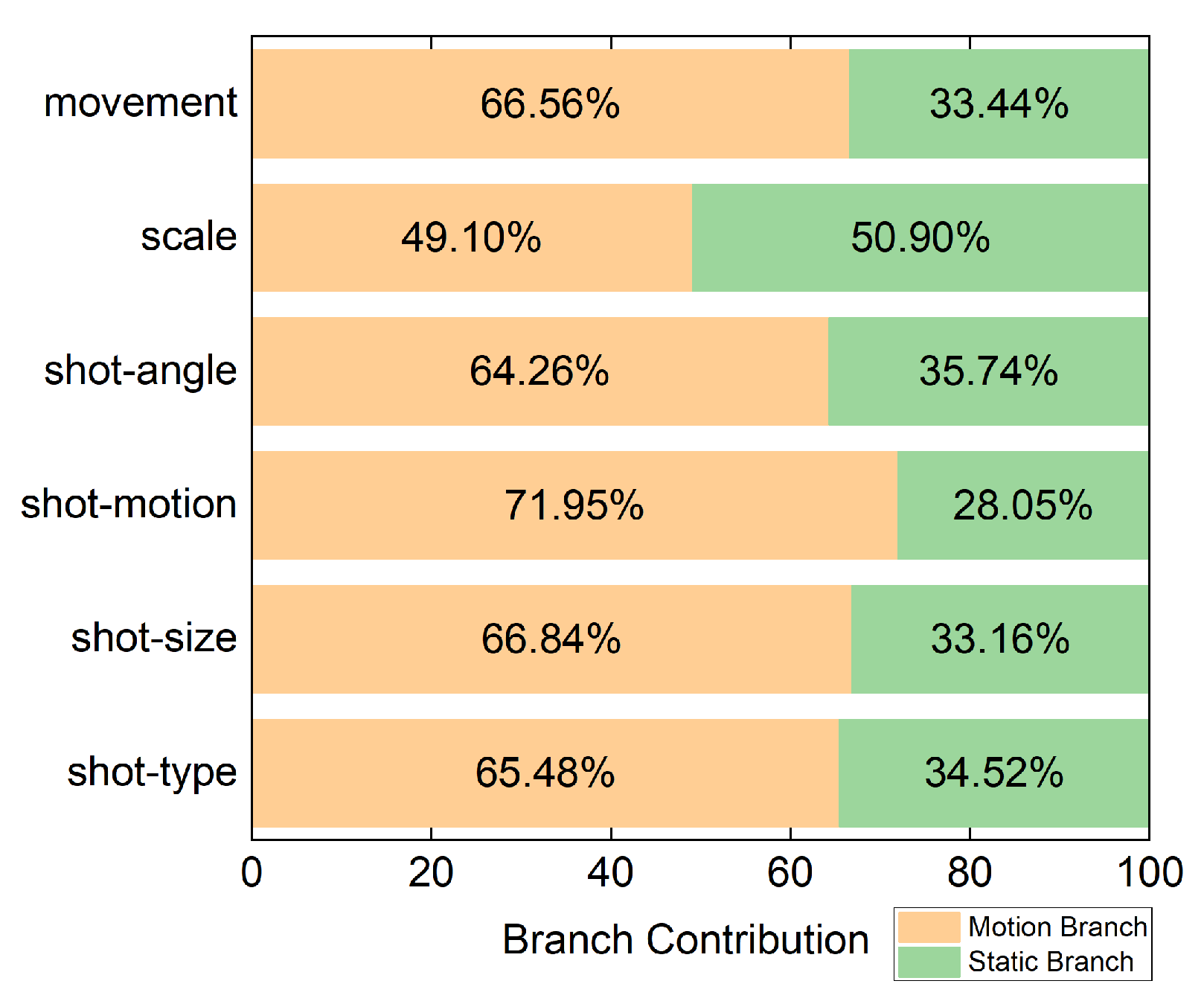
4.4. Quantitative Analysis
4.5. Ablation Study
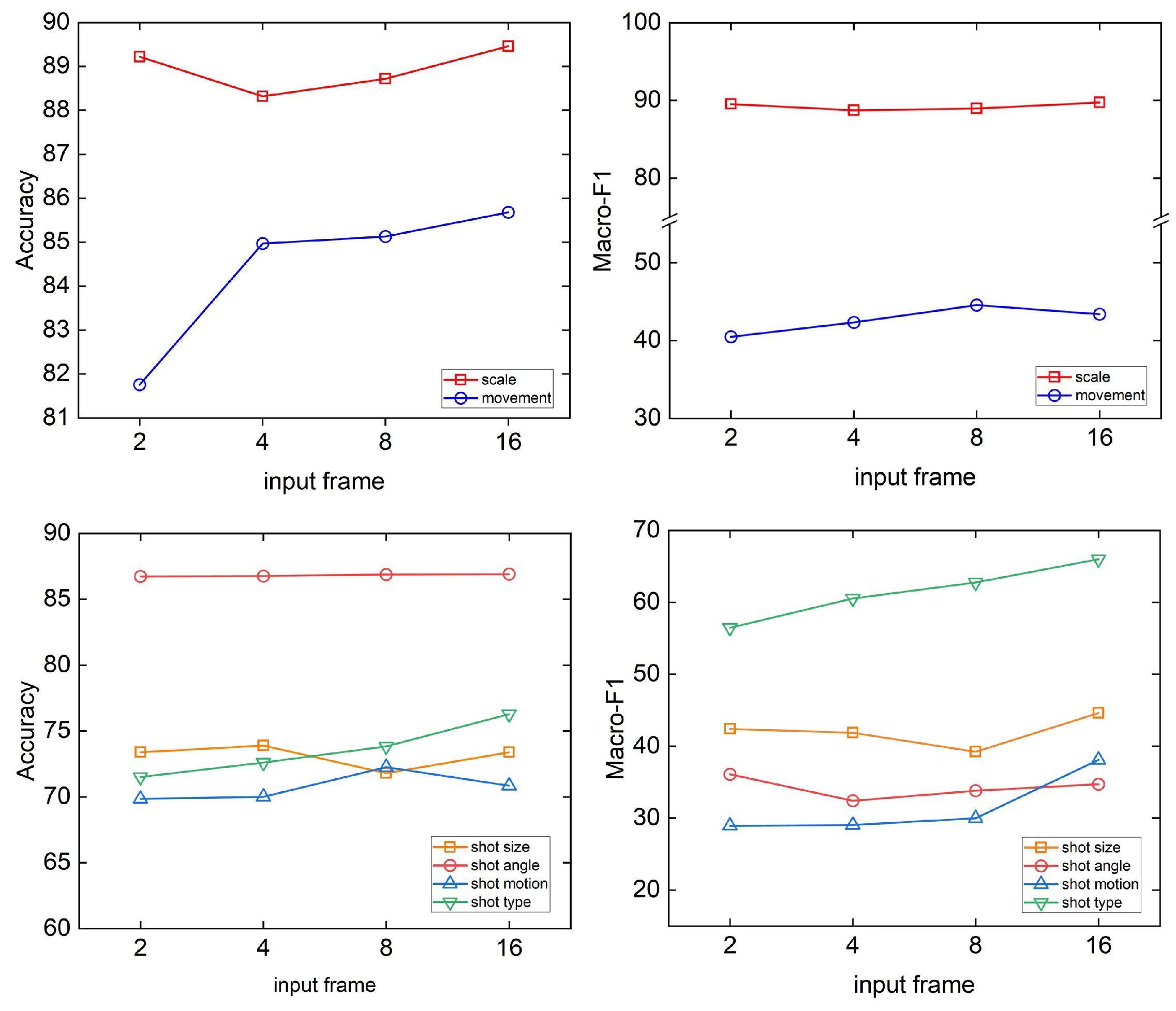
4.5.1. The Influence of Different Shot Input Duration
4.5.2. The Influence of Motion Branch and Static Branch
4.5.3. The Influence of Visual Backbones
4.5.4. The Influence of Pre-Trained Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rao, A.; Wang, J.; Xu, L.; Jiang, X.; Huang, Q.; Zhou, B.; Lin, D. A unified framework for shot type classification based on subject centric lens. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XI 16. pp. 17–34. [Google Scholar]
- Souček, T.; Lokoč, J. Transnet v2: An effective deep network architecture for fast shot transition detection. arXiv 2020, arXiv:2008.04838. [Google Scholar]
- Rao, A.; Xu, L.; Xiong, Y.; Xu, G.; Huang, Q.; Zhou, B.; Lin, D. A local-to-global approach to multi-modal movie scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10146–10155. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Liu, C.; Pei, M.; Wu, X.; Kong, Y.; Jia, Y. Learning a discriminative mid-level feature for action recognition. Sci. China Inf. Sci. 2014, 57, 1–13. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Chen, Z.; Zhang, Y.; Zhang, L.; Yang, C. RO-TextCNN Based MUL-MOVE-Net for Camera Motion Classification. In Proceedings of the 2021 IEEE/ACIS 20th International Fall Conference on Computer and Information Science (ICIS Fall), Xi’an, China, 26–28 October 2021; pp. 182–186. [Google Scholar]
- Chen, Z.; Zhang, Y.; Zhang, S.; Yang, C. Study on location bias of CNN for shot scale classification. Multimed. Tools Appl. 2022, 81, 40289–40309. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QU, Canada, 8–13 December 2014; p. 27. [Google Scholar]
- Hasan, M.A.; Xu, M.; He, X.; Xu, C. CAMHID: Camera motion histogram descriptor and its application to cinematographic shot classification. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1682–1695. [Google Scholar] [CrossRef]
- Prasertsakul, P.; Kondo, T.; Iida, H. Video shot classification using 2D motion histogram. In Proceedings of the 2017 14th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 27–30 June 2017; pp. 202–205. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Hui, T.-W.; Tang, X.; Loy, C.C. Liteflownet: A lightweight convolutional neural network for optical flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18-22 June 2018; pp. 8981–8989. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2462–2470. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Wang, X.; Zhang, S.; Qing, Z.; Gao, C.; Zhang, Y.; Zhao, D.; Sang, N. MoLo: Motion-augmented Long-short Contrastive Learning for Few-shot Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18011–18021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Bhattacharya, S.; Mehran, R.; Sukthankar, R.; Shah, M. Classification of cinematographic shots using lie algebra and its application to complex event recognition. IEEE Trans. Multimed. 2014, 16, 686–696. [Google Scholar] [CrossRef]
- Canini, L.; Benini, S.; Leonardi, R. Classifying cinematographic shot types. Multimed. Tools Appl. 2013, 62, 51–73. [Google Scholar] [CrossRef]
- Wang, H.L.; Cheong, L.-F. Taxonomy of directing semantics for film shot classification. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 1529–1542. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Hasan, M.A.; He, X.; Xu, C.; Lu, H.; Jin, J.S. Using context saliency for movie shot classification. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 3653–3656. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Argaw, D.M.; Heilbron, F.C.; Lee, J.-Y.; Woodson, M.; Kweon, I.S. The anatomy of video editing: A dataset and benchmark suite for AI-assisted video editing. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 201–218. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Liu, W.; Qian, J.; Yao, Z.; Jiao, X.; Pan, J. Convolutional two-stream network using multi-facial feature fusion for driver fatigue detection. Future Internet 2019, 11, 115. [Google Scholar] [CrossRef]
- Bagheri-Khaligh, A.; Raziperchikolaei, R.; Moghaddam, M.E. A new method for shot classification in soccer sports video based on SVM classifier. In Proceedings of the 2012 IEEE Southwest Symposium on Image Analysis and Interpretation, Santa Fe, NM, USA, 22–24 April 2012; pp. 109–112. [Google Scholar]
- Benini, S.; Canini, L.; Leonardi, R. Estimating cinematographic scene depth in movie shots. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo, Singapore, 19–23 July 2010; pp. 855–860. [Google Scholar]
- Jiang, X.; Jin, L.; Rao, A.; Xu, L.; Lin, D. Jointly learning the attributes and composition of shots for boundary detection in videos. IEEE Trans. Multimed. 2021, 24, 3049–3059. [Google Scholar] [CrossRef]
- Bak, H.-Y.; Park, S.-B. Comparative study of movie shot classification based on semantic segmentation. Appl. Sci. 2020, 10, 3390. [Google Scholar] [CrossRef]
- Vacchetti, B.; Cerquitelli, T.; Antonino, R. Cinematographic shot classification through deep learning. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 345–350. [Google Scholar]
- Vacchetti, B.; Cerquitelli, T. Cinematographic shot classification with deep ensemble learning. Electronics 2022, 11, 1570. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the ICML, Virtual Event, 18–24 July 2021; p. 4. [Google Scholar]
- Neimark, D.; Bar, O.; Zohar, M.; Asselmann, D. Video transformer network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3163–3172. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6836–6846. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6824–6835. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 203–213. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Li, L.; Zhang, X.; Hu, W.; Li, W.; Zhu, P. Soccer video shot classification based on color characterization using dominant sets clustering. In Proceedings of the Advances in Multimedia Information Processing-PCM 2009: 10th Pacific Rim Conference on Multimedia, Bangkok, Thailand, 15–18 December 2009; pp. 923–929. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Val | Test | Total | Avg. Duration of Shots (s) | |
|---|---|---|---|---|---|---|
| Movieshots | Num. of movies | 4843 | 1062 | 1953 | 7858 | —— |
| Num. of shots | 32,720 | 4610 | 9527 | 46,857 | 3.95 | |
| AVE | Num. of scenes | 3914 | 559 | 1118 | 5591 | —— |
| Num. of shots | 151,053 | 15,040 | 30,083 | 196,176 | 3.81 |
| Scale | Movement | ||||
|---|---|---|---|---|---|
| Models | Accuracy | Macro-F1 | Accuracy | Macro-F1 | GFLOPs |
| DCR [45] | 51.53 | —— | 33.20 | —— | —— |
| CAMHID [10] | 52.37 | —— | 40.19 | —— | —— |
| 2DHM [11] | 52.35 | —— | 40.34 | —— | —— |
| I3D-Resnet50 [4] | 76.79 | —— | 78.45 | —— | —— |
| TSN-ResNet50 [6] | 84.08 | —— | 70.46 | —— | —— |
| R3D [42] | 69.35 | 69.76 | 83.73 | 42.48 | 163.417 |
| X3D [43] | 75.55 | 75.88 | 67.15 | 20.09 | 5.091 |
| SlowFast-Resnet50 [44] | 70.43 | 70.99 | 68.59 | 32.90 | 6.998 |
| SGNet (img) [1] | 87.21 | —— | 71.30 | —— | —— |
| SGNet (img + flow) [1] * | 87.50 | —— | 80.65 | ||
| MUL-MOVE-Net [7] | —— | —— | 82.85 | —— | —— |
| Bias CNN [8] | 87.19 | —— | —— | —— | —— |
| TimeSformer [36] | 89.15 | 89.39 | 84.21 | 41.38 | 380.053 |
| ViViT [38] | 74.67 | 75.05 | 75.96 | 35.32 | 136.078 |
| MViT [40] | 87.54 | 87.84 | 86.24 | 43.13 | 56.333 |
| Ours (depthwise-diff) | 89.46 | 89.73 | 85.68 | 43.40 | 66.570 |
| Ours (conv-diff) | 89.00 | 89.28 | 86.46 | 43.18 | 66.610 |
| Ours (frame-diff) | 89.11 | 89.39 | 86.25 | 44.02 | 66.549 |
| Shot Size | Shot Angle | Shot Motion | Shot Type | |||||
|---|---|---|---|---|---|---|---|---|
| Models | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 |
| Naive (V+A) [24] | 39.1 | —— | 28.9 | —— | 31.2 | —— | 62.3 | —— |
| Logit adj. (V+A) [24] | 67.6 | —— | 49.8 | —— | 43.7 | —— | 66.7 | —— |
| R3D [42] * | 67.45 | 24.97 | 85.37 | 19.05 | 70.18 | 29.02 | 55.19 | 34.43 |
| X3D [43] | 65.44 | 15.82 | 85.44 | 18.43 | 69.41 | 28.74 | 46.39 | 10.56 |
| SlowFast-Resnet50 [44] | 66.10 | 20.38 | 81.13 | 19.72 | 68.17 | 29.40 | 52.25 | 33.55 |
| TimeSformer [36] | 72.94 | 44.52 | 87.35 | 40.70 | 71.16 | 33.04 | 75.94 | 65.42 |
| ViViT [38] | 69.30 | 28.95 | 85.44 | 18.43 | 70.11 | 28.91 | 57.96 | 40.27 |
| MViT [40] | 73.54 | 41.27 | 87.19 | 33.04 | 71.63 | 36.62 | 75.82 | 65.15 |
| Ours(depthwise-diff) | 73.39 | 44.61 | 86.91 | 34.72 | 70.85 | 38.11 | 76.28 | 66.00 |
| Ours(conv-diff) | 73.09 | 40.77 | 86.55 | 35.42 | 70.64 | 31.93 | 76.29 | 66.80 |
| Ours(frame-diff) | 73.34 | 41.32 | 86.86 | 30.85 | 71.35 | 31.11 | 74.06 | 63.52 |
| Scale | Movement | Shot Size | Shot Angle | Shot Motion | Shot Type | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Branch | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 |
| motion | 86.88 | 87.13 | 86.14 | 42.82 | 72.82 | 34.87 | 86.32 | 35.05 | 71.68 | 34.37 | 74.65 | 63.97 |
| static | 89.12 | 89.42 | 71.91 | 32.41 | 73.43 | 40.62 | 86.54 | 32.47 | 58.19 | 22.65 | 72.50 | 60.88 |
| Scale | Movement | Shot Size | Shot Angle | Shot Motion | Shot Type | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Motion Backbone | Static Backbone | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 |
| MViT | ResNet50 | 86.81 | 87.02 | 87.20 | 43.79 | 72.98 | 39.90 | 87.04 | 31.08 | 71.86 | 31.91 | 76.05 | 65.02 |
| R3D | ResNet50 | 73.89 | 74.13 | 80.69 | 39.14 | 68.43 | 29.46 | 84.84 | 18.93 | 63.50 | 26.32 | 50.11 | 27.71 |
| R3D | ViT | 89.30 | 89.60 | 80.79 | 39.84 | 73.11 | 35.35 | 86.51 | 31.44 | 68.38 | 28.23 | 70.67 | 57.77 |
| Scale | Movement | |||
|---|---|---|---|---|
| Accuracy | Macro-F1 | Accuracy | Macro-F1 | |
| With Pretrain (10 epoch) | 89.46 | 89.73 | 85.68 | 43.40 |
| From scratch (60 epoch) | 66.26 | 66.76 | 82.99 | 40.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Tian, F.; Xu, H.; Lu, T. Toward Unified and Quantitative Cinematic Shot Attribute Analysis. Electronics 2023, 12, 4174. https://doi.org/10.3390/electronics12194174
Li Y, Tian F, Xu H, Lu T. Toward Unified and Quantitative Cinematic Shot Attribute Analysis. Electronics. 2023; 12(19):4174. https://doi.org/10.3390/electronics12194174
Chicago/Turabian StyleLi, Yuzhi, Feng Tian, Haojun Xu, and Tianfeng Lu. 2023. "Toward Unified and Quantitative Cinematic Shot Attribute Analysis" Electronics 12, no. 19: 4174. https://doi.org/10.3390/electronics12194174
APA StyleLi, Y., Tian, F., Xu, H., & Lu, T. (2023). Toward Unified and Quantitative Cinematic Shot Attribute Analysis. Electronics, 12(19), 4174. https://doi.org/10.3390/electronics12194174