
A Detailed Survey on Federated Learning Attacks and Defenses
Abstract
:1. Introduction
2. Overview of Federated Learning
3. Types of Federated Learning
- Horizontal FL (HFL): Horizontal FL is appropriate for datasets with the same feature but located on various devices. HFL is divided into horizontal FL to Horizontal to business (H2B) and horizontal FL to horizontal to consumers (H2C). Traditionally, H2B has a small group of members. They are often chosen throughout FL training. Participants often have high processing capacity and strong technical skills. hundreds or perhaps millions of potential participants under H2C. Only a subset of them gets trained in each cycle.
- Vertical FL (VFL): Different vertical federations employ different feature sets, the term vertical federated learning can also be abbreviated to heterogeneous federated learning. When two datasets have the same sample ID space but different feature spaces, a technique known as vertical federated learning or feature-based federated learning may be used. In deliberately vertical FL cases, datasets are identical but have distinct characteristics, as shown in [18]. VFL is primarily directed towards corporate players. Thus, VFL individuals have similarities to H2B participants [19].
- Federated Transfer Learning (FTL): Federated FTL is similar to classical machine learning by being used to augment a model that has been pre-trained with a new feature. However, the descriptions given for federated transfer learning are more involved, comprising intermediate learning to map to a common feature subspace, as opposed to the convolutional neural network transfer techniques, which are essentially dropping the last few layers from a network trained on big data, and then re-tuning the model to recognize labels on a small dataset [20]. The greatest example would be to expand vertical federated learning to additional sample cases not available in all partnering organizations.
- Cross-Silo FL: When the count of participating machines is constrained, they are available for all rounds, and cross-silo federated learning is employed. The training architecture for cross-silo FL differs significantly from the one used in an example-based context. Clients may trade certain intermediate outcomes rather than model parameters, depending on the details of the training process, to aid other parties’ gradient calculations, which may or may not include a central server as a neutral party [21]. The training data might be in FL format, either horizontal or vertical. Cross-silo is often utilized in circumstances involving corporations.
- Cross-Device FL: Cross-device FL is used in scenarios involving a large number of participating devices. Learning across several user devices using data generated by a single user is the focus of cross-device configurations. Cross-device federated learning was first used when Google used GBoard user data to build next-word prediction models [22]. Client selection and incentive design are two significant strategies facilitating this sort of FL.
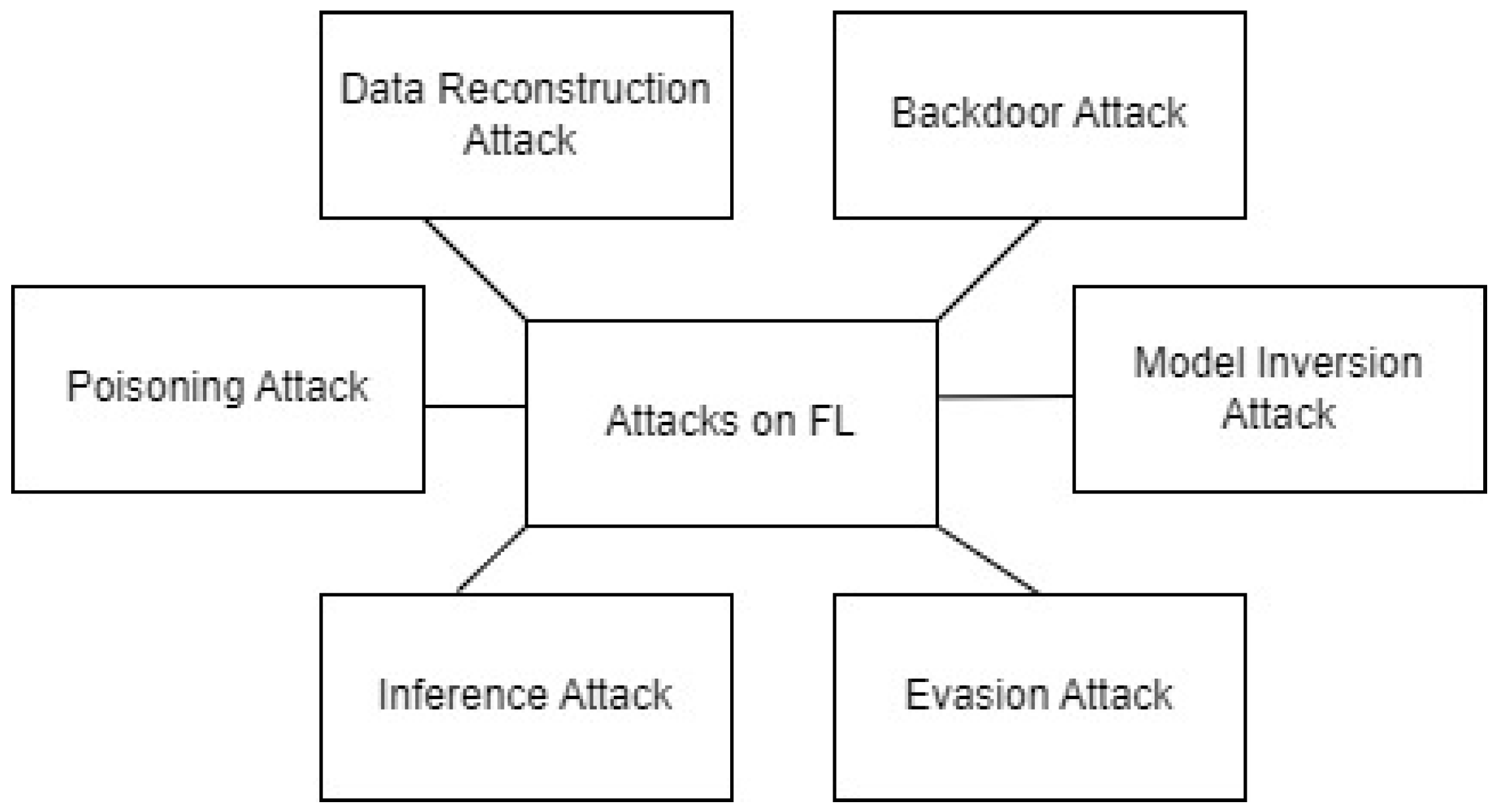
4. FL Attacks and Their Defenses
4.1. Poisoning Attacks and Defenses
4.1.1. Data Poisoning Attacks and Defenses

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
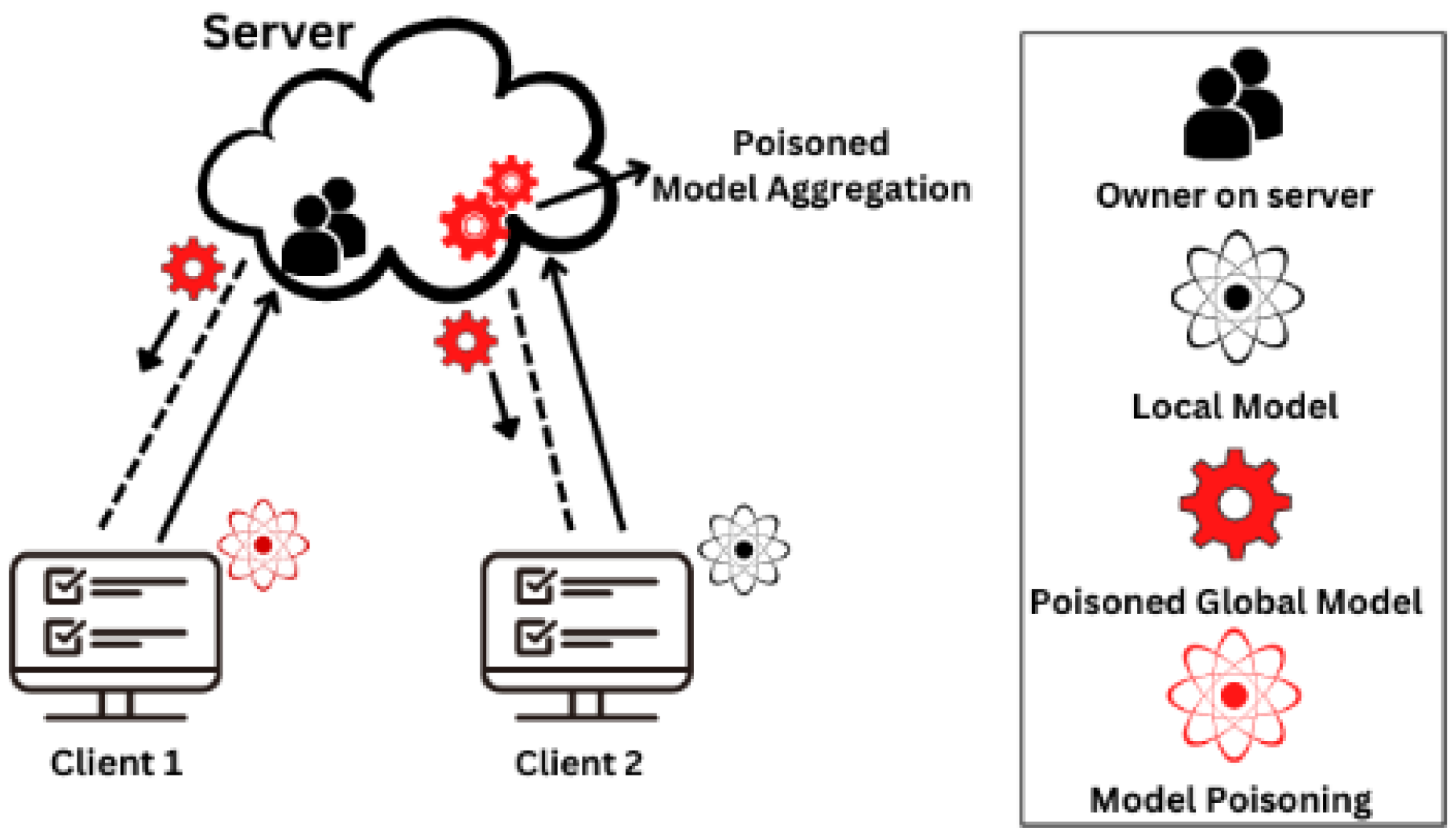
4.1.2. Model Poisoning Attacks and Defenses
4.2. Inference Attacks and Defenses
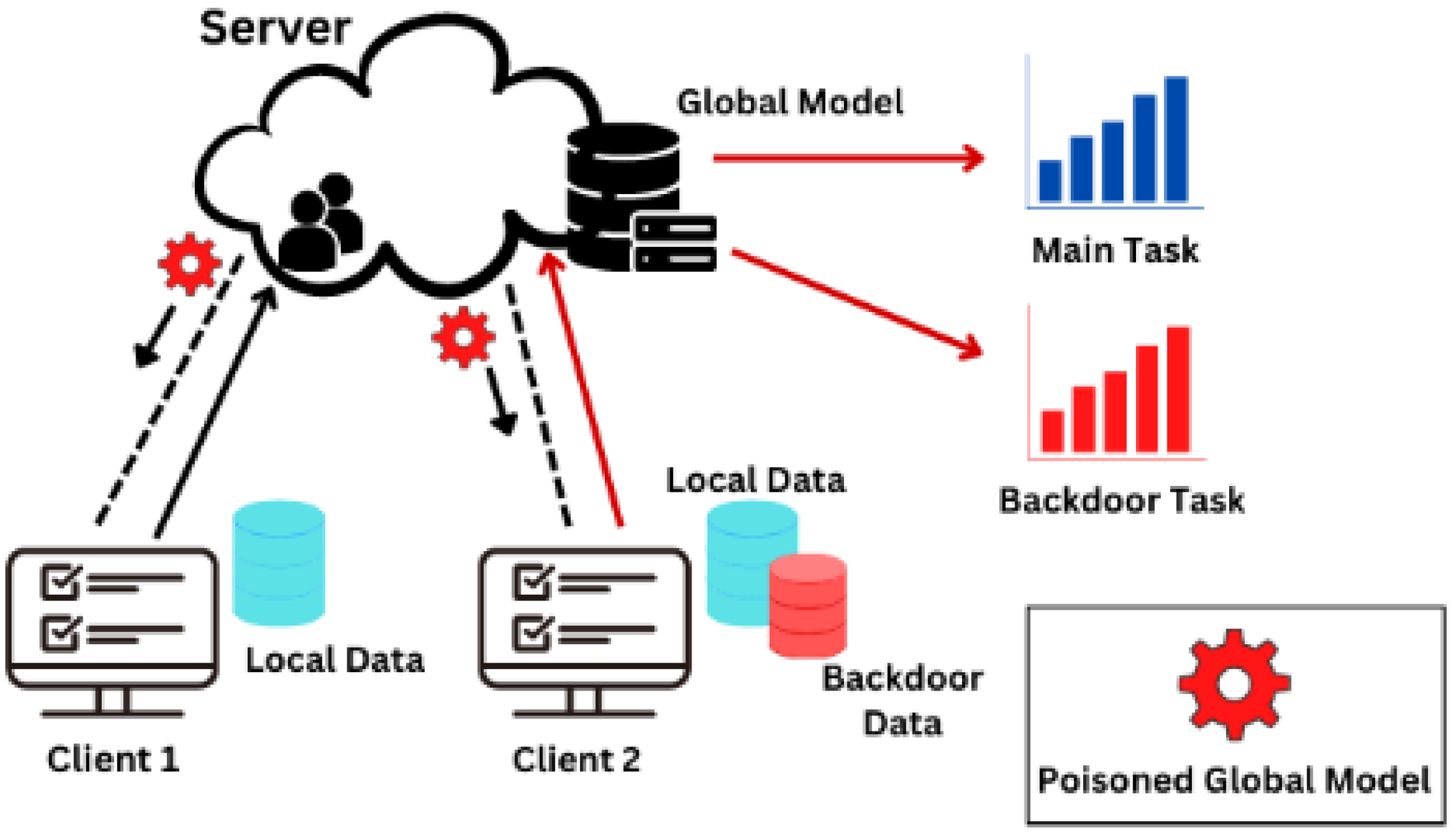
4.3. Backdoor Attacks and Defenses
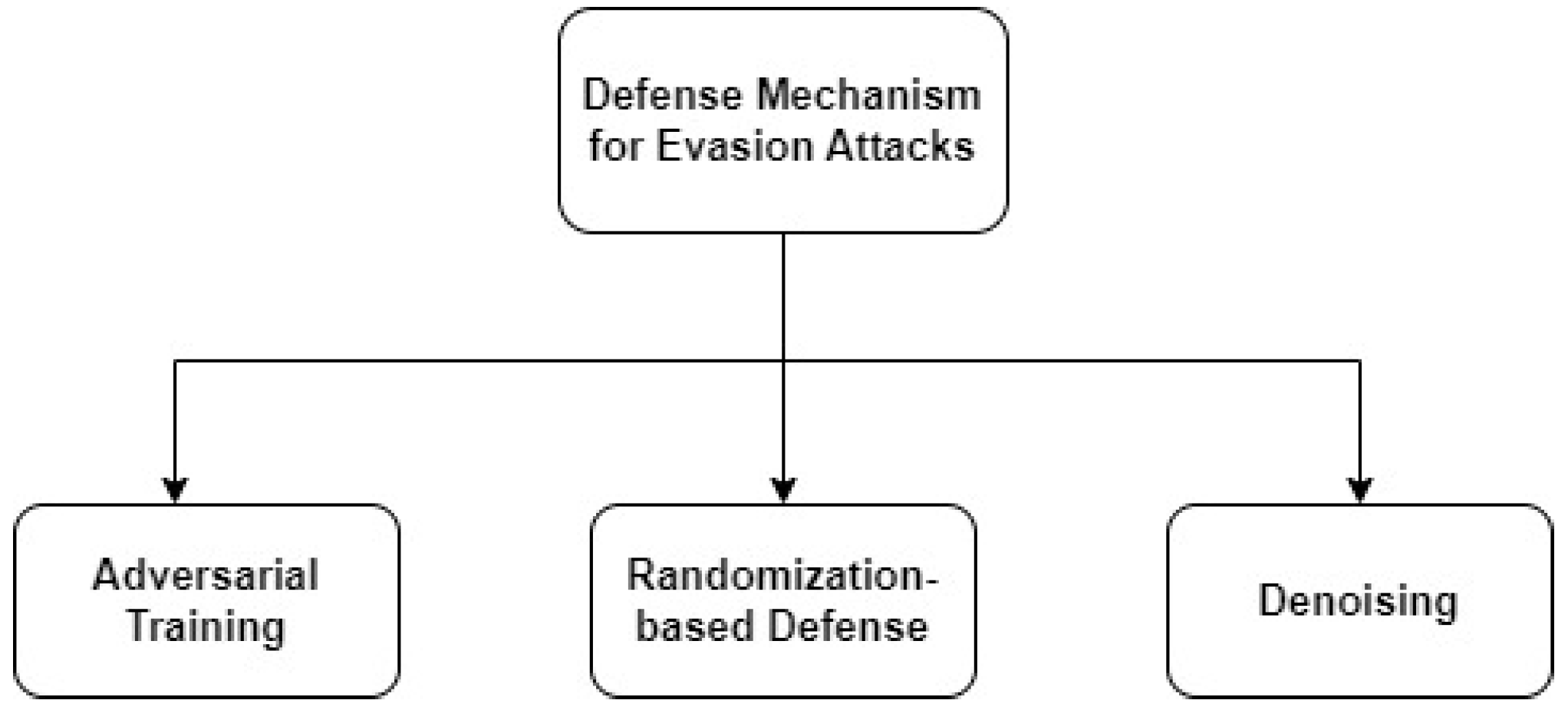
4.4. Evasion Attacks and Defenses
| Defense Mechanism | Accuracy | |
|---|---|---|
| Adversarial training | FGSM adversarial training [56] | Model accuracy up to 83% |
| PGD Adversarial training [56] | Model accuracy up to 88.56% under white-box attacks | |
| Adversarial Logit pairing [57] | Accuracy goes from 1% to 27.9% under white-box | |
| Randomization | Random input transformation [58] | Accuracy is 60% for gray-box and 90% for black-box attacks |
| Random noising [59] | Model accuracy up to 86 % | |
| Random feature pruning [60] | Accuracy increases to 16% depending on perturbation size | |
| Denoising | GAN-based input cleansing [61] | Error rate evaluated up to 0.9% |
| Feature denoising | 50% model accuracy under white-box attacks | |
4.5. Model Inversion Attacks and Defenses
4.6. Reconstruction Attacks and Defenses
5. Discussion and Open Research Directions
- Communication Costs and Variations in the System: Due to the high number of devices, local processing is significantly slower in federated networks [65] (e.g., millions of smartphones). Communication to cross the distortion could be significantly more expensive than it is in conventional data centers. To fit a model to data provided by the federated network, it is crucial to develop communication-efficient algorithms that repeatedly transmit brief messages or model changes as part of the training process rather than sending the entire dataset across the network.Due to variances in hardware (CPU, RAM), network connection (3G, 4G, 5G, WiFi), and power (battery level), each device in a federated network may have varied storage, computation, and communication capabilities [3]. Due to network capacity and system-related restrictions, it is also typical to only observe a small portion of the network’s devices active at any given moment. In a network of a million devices, it is feasible that only a few hundred are actually active [30]. Any active device may become inactive at any time for a variety of reasons. These system-level characteristics account for why issues such as stragglers and fault tolerance are more important than in typical data centers [65].
- Diversity in statistics: Devices on the network frequently produce and gather non-identically scattered data [65,72]. For instance, mobile phone users may utilize a range of slang and jargon when asked to predict the next phrase [30]. More significantly, there might be a foundational structure that depicts the connection between devices and the dispersion of data points between them. It is possible that distributed optimization will experience hiccups as a result of this data production paradigm, and modeling, analysis, and evaluation will all be more challenging.
- Robustness to adversarial attacks: It has been shown that neural networks are vulnerable to a wide variety of adversarial attacks, such as undetected adversarial samples [3]. As neural networks are more frequently employed in federated settings, more people will be exposed to them. While the issue of adversarial robustness [30] is still under investigation, there are a few recommendations to address it, including the following: (1) developing newer robustness metrics for images, text, and audio; (2) including robustness audits in the deployment process; and (3) continuously testing deployed models against unidentified adversaries. Federated learning is still in its infancy, but it will be a popular topic in research for a very long time. As the game goes on, FL’s attack strategies will alter [8,73]. Designers of FL systems should be aware of current assaults so that they may take protective measures when developing new systems. This survey offers a concise and easily readable analysis of this subject to better comprehend the threat situation in FL. Global cooperation on FL is being promoted via an increasing number of seminars at significant AI conferences [66]. A multidisciplinary effort spanning the entire research community will be necessary to develop a general-purpose defensive mechanism that can withstand a wide range of assaults without degrading model performance.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Lyu, L.; Liu, J. Data Poisoning Attacks on Federated Machine Learning. IEEE Internet Things J. 2021, 9, 11365–11375. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Ma, X.; Chen, C.; Sun, L.; Zhao, J.; Yang, Q.; Yu, P.S. Privacy and Robustness in Federated Learning: Attacks and Defenses. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Jere, M.; Farnan, T.; Koushanfar, F. A Taxonomy of Attacks on Federated Learning. IEEE Secur. Priv. 2021, 19, 20–28. [Google Scholar] [CrossRef]
- Tolpegin, V.; Truex, S.; Gursoy, M.; Liu, L. Data Poisoning Attacks Against Federated Learning Systems. Comput.-Secur. Esorics 2020, 2020, 480–501. [Google Scholar] [CrossRef]
- Fung, C.; Yoon, C.; Beschastnikh, I. Mitigating sybils in federated learning poisoning. arXiv 2018, arXiv:1808.04866. [Google Scholar]
- Alfeld, S.; Zhu, X.; Barford, P. Data Poisoning Attacks against Autoregressive Models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Huang, Y.; Gupta, S.; Song, Z.; Li, K.; Arora, S. Evaluating gradient inversion attacks and defenses in Federated learning. arXiv 2021, arXiv:2112.00059. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to Byzantine-robust federated learning. arXiv 2019, arXiv:1911.11815. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning. Acm Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Huang, L.; Joseph, A.; Nelson, B.; Rubinstein, B.; Tygar, J. Adversarial machine learning. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence—AISec ’11, Chicago, IL, USA, 21 October 2011. [Google Scholar] [CrossRef]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [Green Version]
- Federated Learning: A Step by Step Implementation in Tensorflow, Medium. 2022. Available online: https://towardsdatascience.com/federated-learning-a-step-by-step-implementation-in-tensorflow-aac568283399 (accessed on 18 January 2022).
- Melis, L.; Song, C.; Cristofaro, E.D.; Shmatikov, V. Exploiting Unintended Feature Leakage in Collaborative Learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 691–706. [Google Scholar] [CrossRef] [Green Version]
- Goldblum, M.; Tsipras, D.; Xie, C.; Chen, X.; Schwarzschild, A.; Song, D.; Madry, A.; Li, B.; Goldstein, T. Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses. arXiv 2020, arXiv:2012.10544. [Google Scholar] [CrossRef]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated Optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Abdulrahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Beyond. IEEE Internet Things J. 2021, 8, 5476–5497. [Google Scholar] [CrossRef]
- Exclusive: What Is Data Poisoning and Why Should We Be Concerned?—International Security Journal (ISJ), International Security Journal (ISJ). 2022. Available online: https://internationalsecurityjournal.com/what-is-data-poisoning/ (accessed on 26 January 2022).
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 19–35. [Google Scholar] [CrossRef] [Green Version]
- Awan, S.; Luo, B.; Li, F. CONTRA: Defending Against Poisoning Attacks in Federated Learning. Comput. Secur. Esorics 2021, 2021, 455–475. [Google Scholar] [CrossRef]
- Phong, L.; Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1333–1345. [Google Scholar] [CrossRef]
- Su, L.; Xu, J. Securing Distributed Gradient Descent in High Dimensional Statistical Learning. Acm Meas. Anal. Comput. Syst. 2019, 3, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. BadNets: Identifying vulnerabilities in the machine learning model supply chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Analyzing federated learning through an adversarial lens. arXiv 2018, arXiv:1811.12470. [Google Scholar]
- Cretu, G.F.; Stavrou, A.; Locasto, M.E.; Stolfo, S.J.; Keromytis, A.D. Casting out Demons: Sanitizing Training Data for Anomaly Sensors. In Proceedings of the 2008 IEEE Symposium on Security and Privacy (sp 2008), Oakland, CA, USA, 18–21 May 2008; pp. 81–95. [Google Scholar] [CrossRef] [Green Version]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified defenses for data poisoning attacks. arXiv 2017, arXiv:1706.03691. [Google Scholar]
- Seetharaman, S.; Malaviya, S.; Kv, R.; Shukla, M.; Lodha, S. Influence based defense against data poisoning attacks in online learning. arXiv 2021, arXiv:2104.13230. [Google Scholar]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Wang, Y.; Mianjy, P.; Arora, R. Robust Learning for Data poisoning attacks. In Proceedings of the Machine Learning Research, Virtual, 18–24 July 2021. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statististics, Online, 26–28 August 2020; pp. 2938–2948. [Google Scholar]
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison frogs! Targeted clean-label poisoning attacks on neural networks. arXiv 2018, arXiv:1804.00792. [Google Scholar]
- Muñoz-González, L.; Biggio, B.; Demontis, A.; Paudice, A.; Wongrassamee, V.; Lupu, E.C.; Roli, F. Towards Poisoning of Deep Learning Algorithms with Back-gradient Optimization. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017. [Google Scholar] [CrossRef] [Green Version]
- Turner, A.; Tsipras, D.; Madry, A. Clean-Label Backdoor Attacks, OpenReview. 2022. Available online: https://openreview.net/forum?id=HJg6e2CcK7 (accessed on 31 January 2022).
- Hitaj, B.; Ateniese, G.; Perez-Cruz, F. Deep Models Under the GAN. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar] [CrossRef] [Green Version]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, Z.; Han, S. Deep Leakage from gradients. arXiv 2019, arXiv:1906.08935. [Google Scholar]
- Zhao, B.; Mopuri, K.; Bilen, H. IDLG: Improved Deep Leakage from gradients. arXiv 2020, arXiv:2001.02610. [Google Scholar]
- Geyer, R.; Klein, T.; Nabi, M. Differentially private federated learning: A client level perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar]
- Mo, F.; Haddadi, H. Efficient and private federated learning using tee. In Proceedings of the EuroSys, Dresden, Germany, 25–28 March 2019. [Google Scholar]
- Mammen, P. Federated learning: Opportunities and challenges. arXiv 2021, arXiv:2101.05428. [Google Scholar]
- Miao, C.; Li, Q.; Xiao, H.; Jiang, W.; Huai, M.; Su, L. Towards data poisoning attacks in crowd sensing systems. In Proceedings of the Eighteenth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Los Angeles, CA, USA, 26–29 June 2018; pp. 111–120. [Google Scholar]
- Bouacida, N.; Mohapatra, P. Vulnerabilities in Federated Learning. IEEE Access 2021, 9, 63229–63249. [Google Scholar] [CrossRef]
- Peri, N.; Gupta, N.; Huang, W.R.; Fowl, L.; Zhu, C.; Feizi, S.; Goldstein, T.; Dickerson, J.P. Deep k-NN Defense Against Clean-Label Data Poisoning Attacks. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; pp. 55–70. [Google Scholar] [CrossRef]
- A Study of Defenses against Poisoning Attacks in a Distributed Learning Environment—F-Secure Blog, F-Secure Blog. 2022. Available online: https://blog.f-secure.com/poisoning-attacks-in-a-distributed-learning-environment/ (accessed on 26 January 2022).
- Enthoven, D.; Al-Ars, Z. An Overview of Federated Deep Learning Privacy Attacks and Defensive Strategies. In Federated Learning Systems; Springer: Cham, Switzerland, 2021; pp. 173–196. [Google Scholar] [CrossRef]
- Carminati, M.; Santini, L.; Polino, M.; Zanero, S. Evasion attacks against banking fraud detection systems. In Proceedings of the 23rd International Symposium on Research in Attacks, Intrusions and Defenses, San Sebastian, Spain, 14–15 October 2020; pp. 285–300. [Google Scholar]
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Srndic, N.; Laskov, P.; Giacinto, G.; Roli, F. Evasion Attacks against Machine Learning at Test Time. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, 2013; pp. 387–402. [Google Scholar] [CrossRef]
- “How to Attack Machine Learning (Evasion, Poisoning, Inference, Trojans, Backdoors)”, Medium. 2022. Available online: https://towardsdatascience.com/how-to-attack-machine-learning-evasion-poisoning-inference-trojans-backdoors-a7cb5832595c (accessed on 26 January 2022).
- Demontis, A.; Melis, M.; Pintor, M.; Jagielski, M.; Biggio, B.; Oprea, A.; NitaRotaru, C.; Roli, F. Why do adversarial attacks transfer? Explaining transferability of evasion and poisoning attacks. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 321–338. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Xie, C.; Wu, Y.; Maaten, L.; Yuille, A.; He, K. Feature Denoising for Improving Adversarial Robustness. arXiv 2019, arXiv:1812.03411. [Google Scholar]
- Carlini, N.; Katz, G.; Barrett, C.; Dill, D. “Ground-Truth Adversarial Examples”, OpenReview. 2022. Available online: https://openreview.net/forum?id=Hki-ZlbA- (accessed on 31 January 2022).
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing robust adversarial examples. arXiv 2017, arXiv:1707.07397. [Google Scholar]
- Mao, Y.; Yuan, X.; Zhao, X.; Zhong, S. Romoa: Robust Model Aggregation for the Resistance of Federated Learning to Model Poisoning Attacks. In European Symposium on Research in Computer Security; Lecture Notes in Computer Science; Bertino, E., Shulman, H., Waidner, M., Eds.; Springer: Cham, Switzerland, 2021; Volume 12972. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kannan, H.; Kurakin, A.; Goodfellow, I. Adversarial Logit Pairing. arXiv 2018, arXiv:1803.06373. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; Maaten, L.v. Countering Adversarial Images using Input Transformations. arXiv 2017, arXiv:1711.00117. [Google Scholar]
- Liu, X.; Cheng, M.; Zhang, H.; Hsieh, C.-J. Towards robust neural networks via random self-ensemble. In Computer Vision – ECCV 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 381–397. [Google Scholar]
- Dhillon, G.S.; Azizzadenesheli, K.; Lipton, Z.C.; Bernstein, J.; Kossaifi, J.; Khanna, A.; Anandkumar, A. Stochastic Activation Pruning for robust adversarial defense. arXiv 2018, arXiv:1803.01442. [Google Scholar]
- Shen, S.; Jin, G.; Gao, K.; Zhang, Y. APE-GAN: Adversarial perturbation elimination with GAN. arXiv 2017, arXiv:1707.0547. [Google Scholar]
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks. Res. Attacks Intrusions Defenses 2018, 11050, 273–294. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, S.; Valls, V.; Ko, B.J.; Lee, W.; Leung, K.K.; Tassiulas, L. Model pruning enables efficient federated learning on edge devices. arXiv 2019, arXiv:1909.12326. [Google Scholar] [CrossRef]
- Gao, Y.; Doan, B.G.; Zhang, Z.; Ma, S.; Zhang, J.; Fu, A.; Nepal, S.; Kim, H. Backdoor attacks and countermeasures on deep learning: A comprehensive review. arXiv 2020, arXiv:2007.10760. [Google Scholar]
- Li, T. “Federated Learning: Challenges, Methods, and Future Directions”, Machine Learning Blog | ML@CMU | Carnegie Mellon University. 2022. Available online: https://blog.ml.cmu.edu/2019/11/12/federated-learning-challenges-methods-and-future-directions/ (accessed on 31 January 2022).
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–26 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.-C.; Fu, Y.; Li, K.; Khisti, A.; Zemel, R.; Makhzani, A. Variational Model Inversion Attacks. Advances in Neural Information Processing Systems. Adv. Neural Inf. Process. Syst. 2022, 34, 9706–9719. [Google Scholar]
- Khosravy, M.; Nakamura, K.; Hirose, Y.; Nitta, N.; Babaguchi, N. Model Inversion Attack by Integration of Deep Generative Models: Privacy-Sensitive Face Generation from a Face Recognition System. IEEE Trans. Inf. Forensics Secur. 2022, 67, 9074–9719. [Google Scholar] [CrossRef]
- Garfinkel, S.; Abowd, J.M.; Martindale, C. Understanding database reconstruction attacks on public data. Commun. ACM 2019, 62, 46–53. [Google Scholar] [CrossRef]
- Lyu, L.; Chen, C. A novel attribute reconstruction attack in federated learning. arXiv 2021, arXiv:2108.06910. [Google Scholar]
- Xie, C.; Huang, K.; Chen, P.; Li, B. Dba: Distributed backdoor attacks against federated learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wei, W.; Liu, L.; Loper, M.; Chow, K.; Gursoy, M.; Truex, S.; Wu, Y. A framework for evaluating gradient leakage attacks in federated learning. arXiv 2020, arXiv:2004.10397. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against Support Vector Machines. arXiv 2012, arXiv:1206.6389. [Google Scholar]










| Related Papers | Defense Mechanism | Model Accuracy |
|---|---|---|
| Krum | Krum + ERR | 38% |
| Krum + LFR | 42% | |
| Krum + union (ERR+LFR) | 52% | |
| Trimmed mean | Trimmed mean + ERR | 83% |
| Trimmed mean + LFR | 82 % | |
| Trimmed mean + union (ERR+LFR) | 82% | |
| Median | Median + ERR | 79% |
| Median + LFR | 80% | |
| Median + union (ERR+LFR) | 81 % | |
| Romoa | Romoa + similarity + union | 93% |
| Related Papers | Defense Mechanism | Model Accuracy |
|---|---|---|
| RONI [18] | With 12% | 3% |
| With 20% | 6% | |
| TRIM [18] | With 12% | 0% |
| With 20% | 0% |
| Defense Mechanism | Attack | ||
|---|---|---|---|
| Differential privacy | SMC | Homomorphic encryption | |
| Effective | Ineffective | Effective | Loss function |
| Effective | Limited effectiveness | Effective | Deep leakage gradient |
| Context-dependent effectiveness | Effective | Effective | mGAN |
| Effective | Ineffective | Ineffective | GAN |
| Effective | Ineffective | Ineffective | Adversarial example |
| Domain | Work | Model Access | Poisoned Data Access |
|---|---|---|---|
| Blind backdoor removal | Fine pruning | White-box | Inapplicable |
| Suppression | Black-box | Inapplicable | |
| RAB | White-box | Applicable | |
| Offline data inspection | Activation clustering | White-box | Applicable |
| Gradient clustering | White-box | Applicable | |
| Differential privacy | White-box | Applicable | |
| Offline model inspection | DeepInspect | Black-box | Inapplicable |
| Meta classifier | Black-box | Inapplicable | |
| Online input inspection | STRIP | Black-box | Inapplicable |
| Epistemic classifier | White-box | Inapplicable | |
| NNoculation | White-box | Inapplicable | |
| Online model inspection | ABS | White-box | Inapplicable |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sikandar, H.S.; Waheed, H.; Tahir, S.; Malik, S.U.R.; Rafique, W. A Detailed Survey on Federated Learning Attacks and Defenses. Electronics 2023, 12, 260. https://doi.org/10.3390/electronics12020260
Sikandar HS, Waheed H, Tahir S, Malik SUR, Rafique W. A Detailed Survey on Federated Learning Attacks and Defenses. Electronics. 2023; 12(2):260. https://doi.org/10.3390/electronics12020260
Chicago/Turabian StyleSikandar, Hira Shahzadi, Huda Waheed, Sibgha Tahir, Saif U. R. Malik, and Waqas Rafique. 2023. "A Detailed Survey on Federated Learning Attacks and Defenses" Electronics 12, no. 2: 260. https://doi.org/10.3390/electronics12020260
APA StyleSikandar, H. S., Waheed, H., Tahir, S., Malik, S. U. R., & Rafique, W. (2023). A Detailed Survey on Federated Learning Attacks and Defenses. Electronics, 12(2), 260. https://doi.org/10.3390/electronics12020260