

A Comprehensive Review on Multiple Instance Learning



Abstract
:1. Introduction
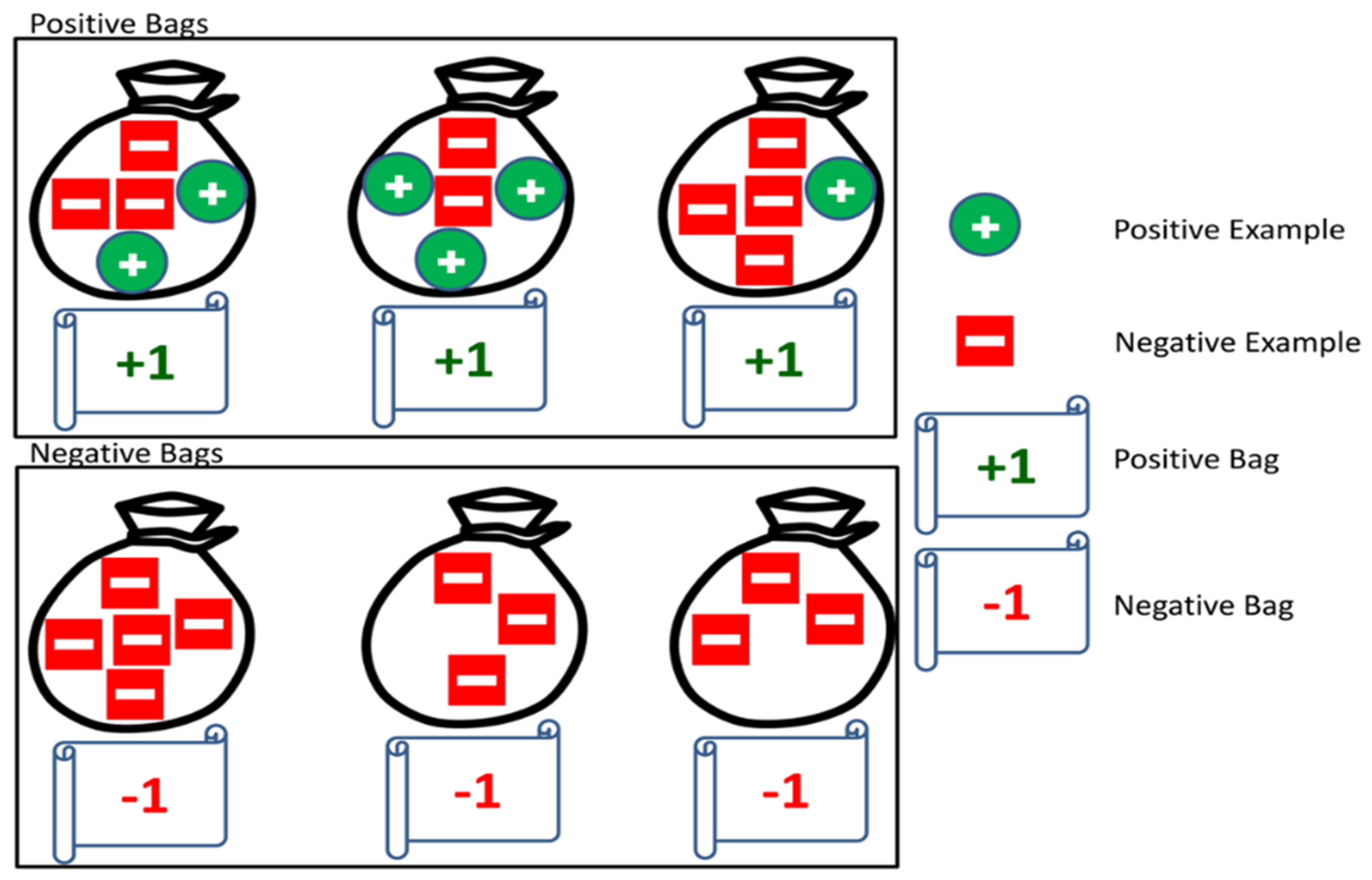
2. Background Knowledge
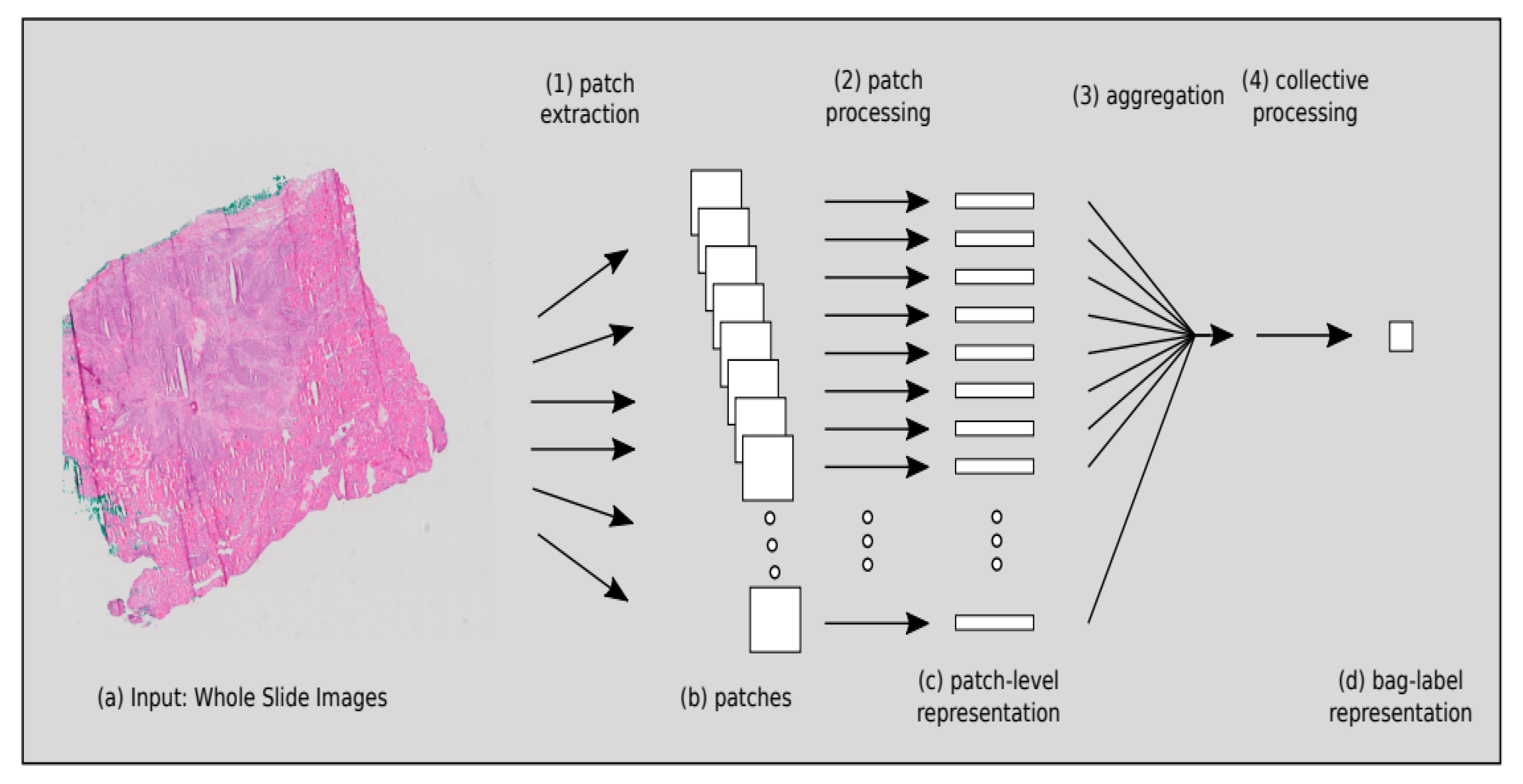
3. Multiple-Instance Learning (MIL) Methods
3.1. Instance Space Methods
3.1.1. MI-SVM (Multiple Instance Support Vector Machine) and mi-SVM (Mixture of Multiple Instance Support Vector Machines)
3.1.2. EM-DD (Expectation–Maximization Diverse Density)
3.1.3. RSIS (Random Subspace Instance Selection)
3.1.4. MIL-Boost
3.1.5. SI-SVM (Single Instance Support Vector Machine) and SI-kNN (Single Instance k-Nearest Neighbors)
3.1.6. mi-Net (Multiple Instance Neural Networks)
3.2. Bag-Space Methods
3.2.1. C-kNN (Citation-k-Nearest Neighbors)
3.2.2. MInD (Multiple Instance Learning with Bag Dissimilarities)
3.2.3. NSK-SVM (Normalized Set Kernel-SVM)
3.2.4. The miGraph
3.2.5. EMD-SVM (Earth Mover’s Distance-SVM)
3.3. Embedded Space Methods
3.3.1. CCE (Constructive-Clustering-Based Ensemble)
3.3.2. BoW-SVM (Bag-of-Words-SVM)
3.3.3. MILES (Multiple-Instance Learning via Embedded Instance Selection)
3.3.4. MI-Net (Multiple Instance Neural Network)
3.3.5. Adeep (Attention-based Deep)
4. Applications of MIL
4.1. Drug Activity Prediction
4.2. Bioinformatics
4.3. Computer Vision
4.3.1. Object Tracking
4.3.2. Video Classification
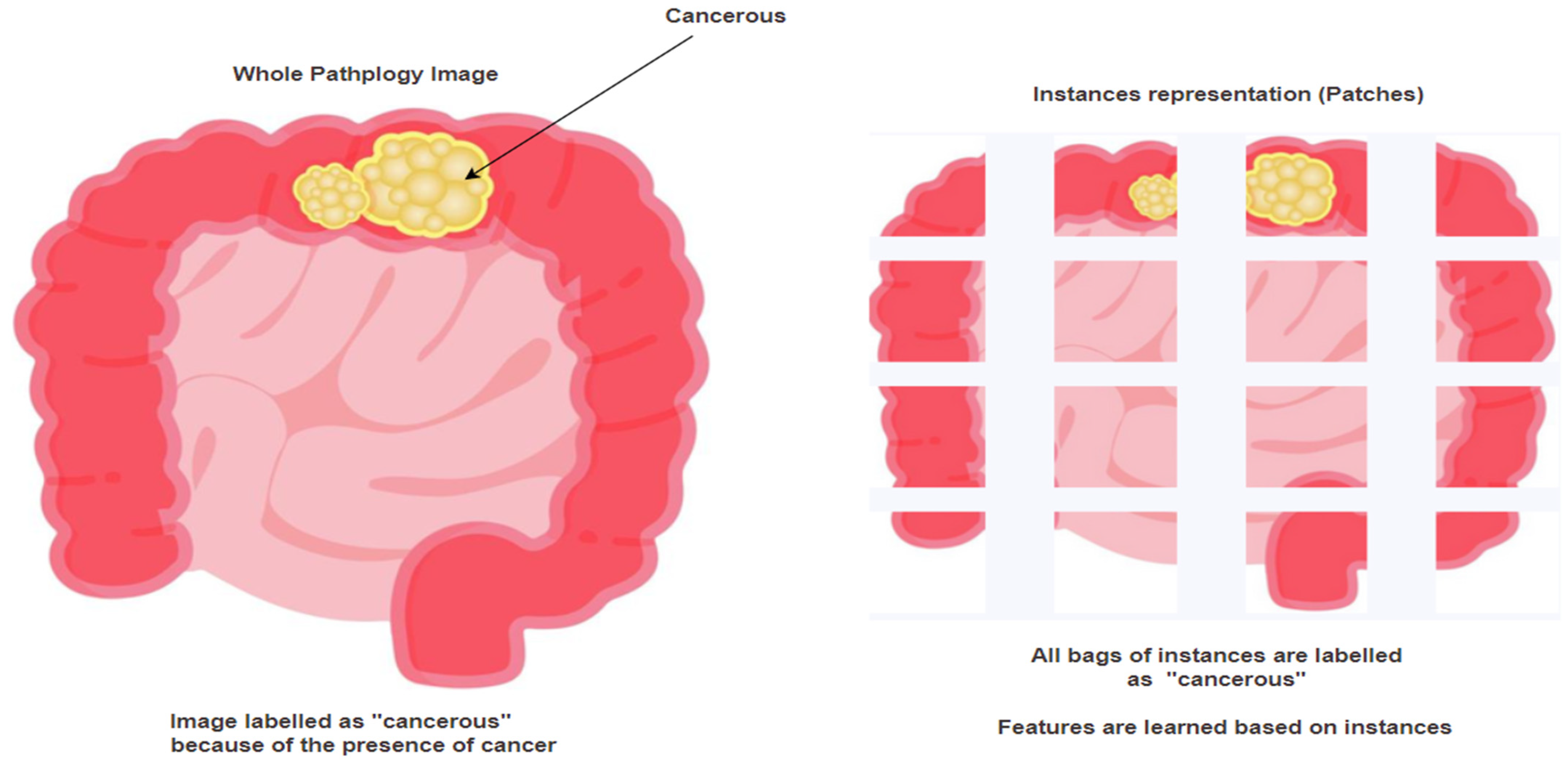
4.4. Computer-Aided Diagnosis and Detection
4.5. Document and Text Classification
4.6. Computer Audition
4.7. Sentiment Analysis
4.8. Web Page Classification
4.9. Intrusion Detection
5. Challenges while Deploying MIL
- Ambiguity in Instance Labels: One of the main problems with MIL is the difficulty in deciding which labels to provide for the different instances that make up a bag. The precise labeling of individual instances is still unknown because the bag is labeled according to whether or not there are positive instances. The learning task may become more difficult as a result of this ambiguity, and robust algorithms are needed to handle it correctly [93].
- Bag-level labeling: MIL requires bag-level labels, whereas conventional machine learning techniques work at the instance level. Due to this distinction, specific algorithms that can use bag-level data to anticipate the future must be created. For accurate multiple-instance learning deployment, it is essential to design efficient bag-level labeling mechanisms [82].
- Feature representation: The selection and depiction of features from the bags of instances presents another difficulty. MIL algorithms typically work with the instances in each bag’s aggregated features. Achieving good performance depends on selecting the right features that capture the bag-level information while maintaining relevant instance-level properties [33].
- Complexity of Computation: The necessity to evaluate bags with several instances makes MIL methods computationally demanding. As the quantity of instances per bag rises, complexity also rises. It is difficult to deploy large-scale MIL issues without first developing effective algorithms and optimization strategies [29].
- Lack of Labeled Bags: In many practical applications, getting labeled bags might be expensive or difficult. The lack of readily available labeled bags makes it difficult to train and test MIL algorithms. The performance of MIL models must be enhanced using strategies like active learning, semi-supervised learning, or utilizing additional data to address a lack of labeled bags [3].
Challenges within the Realm of Machine Learning, Large Language Models, and XAI
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Abbreviations | Description |
| MIL | Multiple Instance Learning |
| RL | Reinforcement Learning |
| AI | Artificial Intelligence |
| WSI | Whole Slide Images |
| KNN | K Nearest Neighbors |
| APR | Axis-Parallel Hyper-Rectangle |
| TCR-Sequence | T-cell Receptor-Sequence |
| EDUs | Elemental Discourse Units |
| EB | Embedded-Space |
| IS | Instance-Space |
| BS | Bag-Space |
| MI-SVM | Multiple Instance Support Vector Machine |
| EM-DD | Expectation–Maximization Diverse Density |
| RSIS | Random Subspace Instance Selection |
| BoW | Bag of words |
| mi-SVM | Mixture of Multiple Instance Support Vector Machines |
| SI-SVM | Single Instance Support Vector Machine |
| SI-kNN | Single instance k-Nearest 353 Neighbors |
| mi-Net | Multiple instance Neural Networks |
| FC layer | Fully Connected Layer |
| CKNN | Citation-kNN |
| MInD | Multiple Instance Learning with Bag Dissimilarities |
| NSK-SVM | Normalized Set Kernel-SVM |
| EMD-SVM | Earth Mover’s Distance-SVM |
| CCE | Constructive clustering based Ensemble |
| MILES | Multiple-Instance Learning via Embedded Instance Selection |
| DNA | Deoxyribonucleic Acid |
| CT | Computerized Tomography |
| GPS | Global Positioning System |
| MRI | Magnetic Resonance Imaging |
| XAI | Explainable Artificial Intelligence |
| Mathematical symbols | |
| Symbols | Description |
| C | Citer |
| R | Reference |
| L layers | Number of layers |
| (j, j’) | Pair of Instances |
References
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Ray, S. A quick review of machine learning algorithms. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 35–39. [Google Scholar]
- Carbonneau, M.-A.; Cheplygina, V.; Granger, E.; Gagnon, G. Multiple instance learning: A survey of problem characteristics and applications. Pattern Recognit. 2018, 77, 329–353. [Google Scholar] [CrossRef]
- Brand, L.; Seo, H.; Baker, L.Z.; Ellefsen, C.; Sargent, J.; Wang, H. A linear primal–dual multi-instance SVM for big data classifications. Knowl. Inf. Syst. 2023, 34, 1–32. [Google Scholar] [CrossRef]
- Afsar Minhas, F.u.A.; Ross, E.D.; Ben-Hur, A. Amino acid composition predicts prion activity. PLoS Comput. Biol. 2017, 13, e1005465. [Google Scholar] [CrossRef]
- Yang, J. Review of Multi-Instance Learning and Its Applications; Technical Report; School of Computer Science, Carnegie Mellon University: Pittsburgh, PA, USA, 2005. [Google Scholar]
- Zhou, Z.-H. Multi-Instance Learning: A Survey; Technical Report; Department of Computer Science & Technology, Nanjing University: Nanjing, China, 2004; p. 1. [Google Scholar]
- Babenko, B. Multiple Instance Learning: Algorithms and Applications; University of California: San Diego, CA, USA, 2008; Volume 19. [Google Scholar]
- Maia, P. An Introduction to Multiple Instance Learning; NILG.AI: Porto, Portugal, 2021. [Google Scholar]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef]
- Wang, J.; Zucker, J.-D. Solving Multiple-Instance Problem: A Lazy Learning Approach; University of Southampton: Southampton, UK, 2000. [Google Scholar]
- Wang, Q.; Yuan, Y.; Yan, P.; Li, X. Saliency detection by multiple-instance learning. IEEE Trans. Cybern. 2013, 43, 660–672. [Google Scholar] [CrossRef]
- Sudharshan, P.; Petitjean, C.; Spanhol, F.; Oliveira, L.E.; Heutte, L.; Honeine, P. Multiple instance learning for histopathological breast cancer image classification. Expert Syst. Appl. 2019, 117, 103–111. [Google Scholar] [CrossRef]
- Maron, O.; Lozano-Pérez, T. A framework for multiple-instance learning. Adv. Neural Inf. Process. Syst. 1997, 10. Available online: https://proceedings.neurips.cc/paper_files/paper/1997/file/82965d4ed8150294d4330ace00821d77-Paper.pdf (accessed on 1 October 2023).
- Xiong, D.; Zhang, Z.; Wang, T.; Wang, X. A comparative study of multiple instance learning methods for cancer detection using T-cell receptor sequences. Comput. Struct. Biotechnol. J. 2021, 19, 3255–3268. [Google Scholar] [CrossRef]
- Xu, Y.; Zhu, J.-Y.; Eric, I.; Chang, C.; Lai, M.; Tu, Z. Weakly supervised histopathology cancer image segmentation and classification. Med. Image Anal. 2014, 18, 591–604. [Google Scholar] [CrossRef] [PubMed]
- Fraz, M.M.; Barman, S.A. Computer vision algorithms applied to retinal vessel segmentation and quantification of vessel caliber. Image Anal. Model. Ophthalmol. 2014, 49, 49–84. [Google Scholar]
- Combalia, M.; Vilaplana, V. Monte-Carlo sampling applied to multiple instance learning for histological image classification. In Proceedings of the International Workshop on Deep Learning in Medical Image Analysis, Granada, Spain, 20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 274–281. [Google Scholar]
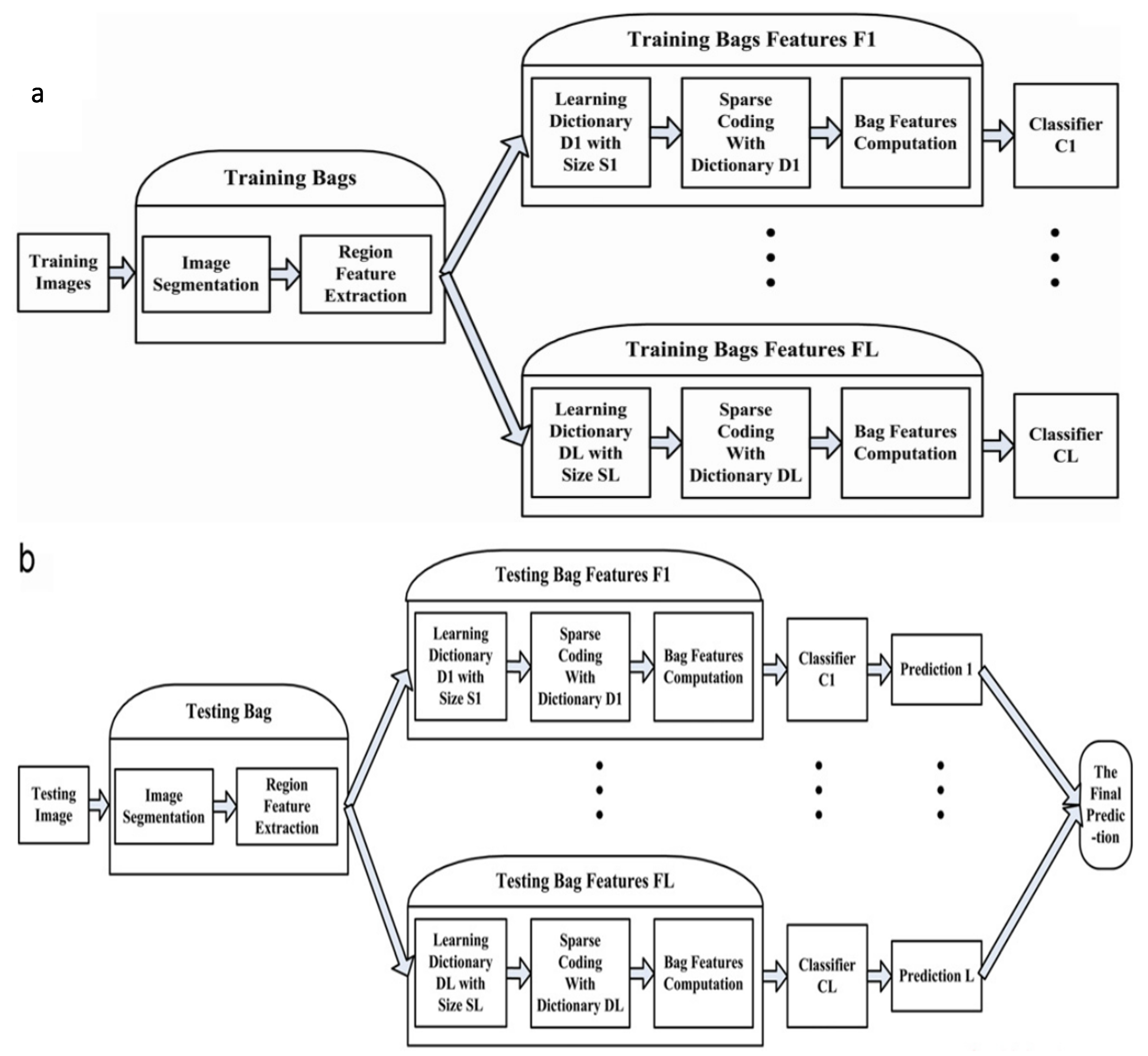
- Qiao, M.; Liu, L.; Yu, J.; Xu, C.; Tao, D. Diversified dictionaries for multi-instance learning. Pattern Recognit. 2017, 64, 407–416. [Google Scholar] [CrossRef]
- Angelidis, S.; Lapata, M. Multiple instance learning networks for fine-grained sentiment analysis. Trans. Assoc. Comput. Linguist. 2018, 6, 17–31. [Google Scholar] [CrossRef]
- Gadermayr, M.; Tschuchnig, M. Multiple instance learning for digital pathology: A review on the state-of-the-art, limitations & future potential. arXiv 2022, arXiv:2206.04425. [Google Scholar]
- Boschman, J. Multiple-Instance Learning—One Minute Introduction; Medium: San Francisco, CA, USA, 2021. [Google Scholar]
- Song, X.; Jiao, L.; Yang, S.; Zhang, X.; Shang, F. Sparse coding and classifier ensemble based multi-instance learning for image categorization. Signal Process. 2013, 93, 1–11. [Google Scholar] [CrossRef]
- Astorino, A.; Fuduli, A.; Gaudioso, M.; Vocaturo, E. A multiple instance learning algorithm for color images classification. In Proceedings of the 22nd International Database Engineering & Applications Symposium, Villa San Giovanni, Italy, 18–20 June 2018; pp. 262–266. [Google Scholar]
- Weiss, G.M.; Hirsh, H. Learning to predict rare events in event sequences. In Proceedings of the KDD—4th International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998; pp. 359–363. [Google Scholar]
- Moniz, N.; Branco, P.; Torgo, L. Resampling strategies for imbalanced time series. In Proceedings of the 2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 282–291. [Google Scholar]
- Gunetti, D.; Ruffo, G. Intrusion detection through behavioral data. In Proceedings of the International Symposium on Intelligent Data Analysis, Amsterdam, The Netherlands, 9–11 August 1999. [Google Scholar]
- Zhou, Z.-H.; Zhang, M.-L. Solving multi-instance problems with classifier ensemble based on constructive clustering. Knowl. Inf. Syst. 2007, 11, 155–170. [Google Scholar] [CrossRef]
- Amores, J. Multiple instance classification: Review, taxonomy and comparative study. Artif. Intell. 2013, 201, 81–105. [Google Scholar] [CrossRef]
- Ray, S.; Craven, M. Supervised versus multiple instance learning: An empirical comparison. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2022; pp. 697–704. [Google Scholar]
- Alpaydın, E.; Cheplygina, V.; Loog, M.; Tax, D.M. Single vs. multiple-instance classification. Pattern Recognit. 2015, 48, 2831–2838. [Google Scholar] [CrossRef]
- Bunescu, R.C.; Mooney, R.J. Multiple instance learning for sparse positive bags. In Proceedings of the 24th International Conference on Machine Learning 2007, Corvalis, OR, USA, 20–24 June 2007; pp. 105–112. [Google Scholar]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. Adv. Neural Inf. Process. Syst. 2002, 15. [Google Scholar]
- Zhang, Q.; Goldman, S. EM-DD: An improved multiple-instance learning technique. Adv. Neural Inf. Process. Syst. 2001, 14. Available online: https://proceedings.neurips.cc/paper_files/paper/2001/file/e4dd5528f7596dcdf871aa55cfccc53c-Paper.pdf (accessed on 1 October 2023).
- Carbonneau, M.-A.; Granger, E.; Raymond, A.J.; Gagnon, G. Robust multiple-instance learning ensembles using random subspace instance selection. Pattern Recognit. 2016, 58, 83–99. [Google Scholar] [CrossRef]
- Carbonneau, M.-A.; Granger, E.; Gagnon, G. Witness identification in multiple instance learning using random subspaces. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3639–3644. [Google Scholar]
- Viola, P.; Platt, J.C.; Zhang, C. Multiple instance boosting for object recognition. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 4 December 2006. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Wang, X.; Yan, Y.; Tang, P.; Bai, X.; Liu, W. Revisiting multiple instance neural networks. Pattern Recognit. 2018, 74, 15–24. [Google Scholar] [CrossRef]
- Zhou, Z.-H.; Xue, X.-B.; Jiang, Y. Locating regions of interest in CBIR with multi-instance learning techniques. In Proceedings of the AI 2005: Advances in Artificial Intelligence: 18th Australian Joint Conference on Artificial Intelligence, Sydney, Australia, 5–9 December 2005; Proceedings 18. Springer: Berlin/Heidelberg, Germany, 2005; pp. 92–101. [Google Scholar]
- Cheplygina, V.; Tax, D.M.; Loog, M. Multiple instance learning with bag dissimilarities. Pattern Recognit. 2015, 48, 264–275. [Google Scholar] [CrossRef]
- Gärtner, T.; Flach, P.A.; Kowalczyk, A.; Smola, A.J. Multi-instance kernels. ICML 2002, 2, 7. [Google Scholar]
- Zhou, Z.-H.; Sun, Y.-Y.; Li, Y.-F. Multi-instance learning by treating instances as non-iid samples. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1249–1256. [Google Scholar]
- Zhang, J.; Marszałek, M.; Lazebnik, S.; Schmid, C. Local features and kernels for classification of texture and object categories: A comprehensive study. Int. J. Comput. Vis. 2007, 73, 213–238. [Google Scholar] [CrossRef]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Chen, Y.; Bi, J.; Wang, J.Z. MILES: Multiple-instance learning via embedded instance selection. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1931–1947. [Google Scholar] [CrossRef]
- Zhu, J.; Rosset, S.; Tibshirani, R.; Hastie, T. 1-norm support vector machines. Adv. Neural Inf. Process. Syst. 2003, 16. Available online: https://proceedings.neurips.cc/paper_files/paper/2003/file/49d4b2faeb4b7b9e745775793141e2b2-Paper.pdf (accessed on 1 October 2023).
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Proceedings of the Artificial Intelligence and Statistics 2015, San Diego, CA, USA, 9–12 May 2015; pp. 562–570. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ilse, M.; Tomczak, J.; Welling, M. Attention-based deep multiple instance learning. In Proceedings of the International Conference on Machine Learning 2018, Stockholm, Sweden, 10–15 July 2018; pp. 2127–2136. [Google Scholar]
- Raffel, C.; Ellis, D.P. Feed-forward networks with attention can solve some long-term memory problems. arXiv 2015, arXiv:1512.08756. [Google Scholar]
- Zhang, Y.; Chen, Y.; Ji, X. Motif discovery as a multiple-instance problem. In Proceedings of the 2006 18th IEEE International Conference on Tools with Artificial Intelligence (ICTAI’06), Arlington, VA, USA, 13–15 November 2006; pp. 805–809. [Google Scholar]
- Yang, C.; Dong, M.; Hua, J. Region-based image annotation using asymmetrical support vector machine-based multiple-instance learning. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06) IEEE, New York, NY, USA, 17–22 June 2006; pp. 2057–2063. [Google Scholar]
- Chen, Y.; Wang, J.Z. Image categorization by learning and reasoning with regions. J. Mach. Learn. Res. 2004, 5, 913–939. [Google Scholar]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV 2004, Prague, Czech Republic, 10–14 May 2004; pp. 1–2. [Google Scholar]
- Xu, H.; Venugopalan, S.; Ramanishka, V.; Rohrbach, M.; Saenko, K. A multi-scale multiple instance video description network. arXiv 2015, arXiv:1505.05914. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollár, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C. From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Zhu, J.-Y.; Wu, J.; Xu, Y.; Chang, E.; Tu, Z. Unsupervised object class discovery via saliency-guided multiple class learning. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 862–875. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Yu, Y.; Huang, C.; Yu, K. Deep multiple instance learning for image classification and auto-annotation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 3460–3469. [Google Scholar]
- Yang, X.; Li, C.; Zeng, Q.; Pan, X.; Yang, J.; Xu, H. Vehicle re-identification via spatio-temporal multi-instance learning. In Proceedings of the International Conference on Neural Computing for Advanced Applications, Hefei, China, 7–9 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 482–493. [Google Scholar]
- Varga, D.; Szirányi, T. Person re-identification based on deep multi-instance learning. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 1559–1563. [Google Scholar]
- Liu, X.; Bi, S.; Ma, X.; Wang, J. Multi-Instance Convolutional Neural Network for multi-shot person re-identification. Neurocomputing 2019, 337, 303–314. [Google Scholar] [CrossRef]
- Wang, J.; Li, B.; Hu, W.; Wu, O. Horror video scene recognition via multiple-instance learning. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1325–1328. [Google Scholar]
- Babenko, B.; Yang, M.-H.; Belongie, S. Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1619–1632. [Google Scholar] [CrossRef]
- Zhang, K.; Song, H. Real-time visual tracking via online weighted multiple instance learning. Pattern Recognit. 2013, 46, 397–411. [Google Scholar] [CrossRef]
- Lu, H.; Zhou, Q.; Wang, D.; Xiang, R. A co-training framework for visual tracking with multiple instance learning. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa Barbara, CA, USA, 21–23 March 2011; pp. 539–544. [Google Scholar]
- Zhang, M.-L.; Zhou, Z.-H. Multi-instance clustering with applications to multi-instance prediction. Appl. Intell. 2009, 31, 47–68. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, F.; Si, L.; Li, T. Maximum margin multiple instance clustering with applications to image and text clustering. IEEE Trans. Neural Netw. 2011, 22, 739–751. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, B.; Yang, X.; Zhang, W.; Tu, Z. Action recognition with actons. In Proceedings of the IEEE International Conference on Computer Vision 2013, Sydney, Australia, 1–8 December 2013; pp. 3559–3566. [Google Scholar]
- Quellec, G.; Lamard, M.; Abràmoff, M.D.; Decencière, E.; Lay, B.; Erginay, A.; Cochener, B.; Cazuguel, G. A multiple-instance learning framework for diabetic retinopathy screening. Med. Image Anal. 2012, 16, 1228–1240. [Google Scholar] [CrossRef]
- Tong, T.; Wolz, R.; Gao, Q.; Guerrero, R.; Hajnal, J.V.; Rueckert, D.; Alzheimer’s Disease Neuroimaging Initiative. Multiple instance learning for classification of dementia in brain MRI. Med. Image Anal. 2014, 18, 808–818. [Google Scholar] [CrossRef]
- Melendez, J.; Van Ginneken, B.; Maduskar, P.; Philipsen, R.H.; Reither, K.; Breuninger, M.; Adetifa, I.M.; Maane, R.; Ayles, H.; Sánchez, C.I. A novel multiple-instance learning-based approach to computer-aided detection of tuberculosis on chest X-rays. IEEE Trans. Med. Imaging 2014, 34, 179–192. [Google Scholar] [CrossRef]
- Cheplygina, V.; Sørensen, L.; Tax, D.M.; Pedersen, J.H.; Loog, M.; De Bruijne, M. Classification of COPD with multiple instance learning. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Washington, DC, USA, 24–28 August 2014; pp. 1508–1513. [Google Scholar]
- Harris, Z.S. Distributional Structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Pappas, N.; Popescu-Belis, A. Explaining the stars: Weighted multiple-instance learning for aspect-based sentiment analysis. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 455–466. [Google Scholar]
- Zhang, Y.; Surendran, A.C.; Platt, J.C.; Narasimhan, M. Learning from multi-topic web documents for contextual advertisement. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 1051–1059. [Google Scholar]
- Zhang, D.; He, J.; Lawrence, R. Mi2ls: Multi-instance learning from multiple informationsources. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 149–157. [Google Scholar]
- Tian, Y.; Shi, J.; Li, B.; Duan, Z.; Xu, C. Audio-visual event localization in unconstrained videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 247–263. [Google Scholar]
- Briggs, F.; Fern, X.Z.; Raich, R. Rank-loss support instance machines for MIML instance annotation. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2012; pp. 534–542. [Google Scholar]
- Zafra, A.; Ventura, S.; Herrera-Viedma, E.; Romero, C. Multiple instance learning with genetic programming for web mining. In Proceedings of the International Work-Conference on Artificial Neural Networks, San Sebastián, Spain, 20–22 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 919–927. [Google Scholar]
- Zhou, Z.-H.; Zhou, Z.-H. Semi-supervised learning. In Machine Learning; Springer: Singapore, 2021; pp. 315–341. [Google Scholar]
- Birk, A. Robot learning and self-sufficiency: What the energy-level can tell us about a robot’s performance. In Proceedings of the European Workshop on Learning Robots, Brighton, UK, 1–2 August 1997; Springer: Berlin/Heidelberg, Germany, 1997; pp. 109–125. [Google Scholar]
- Weon, I.-Y.; Song, D.-H.; Ko, S.-B.; Lee, C.-H. A multiple instance learning problem approach model to anomaly network intrusion detection. J. Inf. Process. Syst. 2005, 1, 14–21. [Google Scholar] [CrossRef]
- Mandel, M.I.; Ellis, D.P. Multiple-instance learning for music information retrieval. In Proceedings of the ISMIR 2008: Proceedings of the 9th International Conference of Music Information Retrieval, Philadelphia, PA, USA, 14–18 September 2008. [Google Scholar]
- Carbonneau, M.-A.; Granger, E.; Attabi, Y.; Gagnon, G. Feature learning from spectrograms for assessment of personality traits. IEEE Trans. Affect. Comput. 2017, 11, 25–31. [Google Scholar] [CrossRef]
- Guan, X.; Raich, R.; Wong, W.-K. Efficient multi-instance learning for activity recognition from time series data using an auto-regressive hidden markov model. In Proceedings of the International Conference on Machine Learning 2016, New York, NY, USA, 19–24 June 2016; pp. 2330–2339. [Google Scholar]
- Stikic, M.; Larlus, D.; Ebert, S.; Schiele, B. Weakly supervised recognition of daily life activities with wearable sensors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2521–2537. [Google Scholar] [CrossRef]
- Murray, J.F.; Hughes, G.F.; Kreutz-Delgado, K.; Schuurmans, D. Machine Learning Methods for Predicting Failures in Hard Drives: A Multiple-Instance Application. J. Mach. Learn. Res. 2005, 6, 783–816. [Google Scholar]
- Manandhar, A.; Morton, K.D., Jr.; Collins, L.M.; Torrione, P.A. Multiple instance learning for landmine detection using ground penetrating radar. In Proceedings of the Detection and Sensing of Mines, Explosive Objects, and Obscured Targets XVII, Baltimore, MD, USA, 23–27 April 2012; SPIE: Bellingham, WA, USA, 2012; pp. 668–678. [Google Scholar]
- Karem, A.; Frigui, H. A multiple instance learning approach for landmine detection using ground penetrating radar. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 878–881. [Google Scholar]
- McGovern, A.; Jensen, D. Identifying predictive structures in relational data using multiple instance learning. In Proceedings of the 20th International Conference on Machine Learning (ICML-03) 2003, Washington, DC, USA, 21–24 August 2003; pp. 528–535. [Google Scholar]
- Maron, O.; Ratan, A.L. Multiple-instance learning for natural scene classification. In Proceedings of the ICML—International Conference on Machine Learning 1998, Madison, WI, USA, 24–27 July 1998; pp. 341–349. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application of MIL | Author Name | Description |
|---|---|---|
| Sound Classification | M. I. Mandel, D. P. W. Ellis [85]. | It is possible to cast some sound classification tasks as MIL. The goal of [85] is to automatically identify the genre of musical snippets. Labels are given in training for complete albums or artists but not for each snippet. The bags are collections of single-artist or album snippets. Because numerous musical genres might be included on the same album or by the same singer, the bags might include both positive and negative instances. |
| Recognition of different bird songs | F. Briggs, X. Z. Fern, R [80]. | MIL is used in [80] to detect bird songs in recordings made using microphones. Various bird species and other noises can be heard in sound sequences. The goal is to recognize each bird song independently while restricting training to sound files with inadequate labeling. |
| Determining Personality traits using audio signals | M.-A. Carbonneau, E. Granger, Y. Attabi, G. Gagnon [86]. | According to [86], a BoW (Bag-of-words) framework is used for determining personality qualities from audio signals represented as spectrograms. In that situation, the spectrogram’s discrete regions are instances, and the complete voice signals are bags. |
| Human activity sensors | X. Guan, R. Raich, W.-K. Wong [87] and M. Stikic, D. Larlus, S. Ebert, B. Schiele [88]. | In [87,88], Wearable body sensors are used with MIL to identify human activity. The users’ declaration of the actions that were carried out during a specific time period results in weak supervision. Activities typically do not last the entire period, and each period could have a distinct set of activities. In this configuration, instances are sub-periods, while full periods are bags. |
| Prediction of hard drive failure | J. F. Murray, G. F. Hughes, K. Kreutz-Delgado [89]. | Time series are a collection of measurements on hard drives taken at regular intervals, and they are used alongside MIL to predict hard drive failure [89]. The objective is to predict when a product will fail. Time series suggest the underlying structure of bags that should not be disregarded. |
| Detection of buried landmines | Manandhar, K. D. Morton, L. M. Collins, P. A. Torrione [90]. A. Karem, H. Frigui [91]. | MIL classifiers in [90,91] use ground-penetrating radar signals to find buried landmines. At different depths in the soil, measurements are taken when a detection takes place at a specific GPS position. The feature vectors for various depths are contained in a bag at each detection location. |
| Predicting the performance of stocks | O. Maron, T. Lozano-P’erez [14]. | MIL is employed to choose stocks in [14]. The 100 best-performing stocks are gathered into positive bags each month, while the five worst-performing stocks are placed in negative bags. Based on these bags, an instance classifier chooses the best stocks. |
| Prediction for film nominations | A. Mcgovern, D. Jensen [92] | A strategy for predicting which films will be nominated for an award is described in [92]. A graph is created that represents a movie’s relationships to stars, studios, genre, release date, etc. In order to assess whether test cases were successful, the MIL algorithm determines which sub-graph explains the nomination. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fatima, S.; Ali, S.; Kim, H.-C. A Comprehensive Review on Multiple Instance Learning. Electronics 2023, 12, 4323. https://doi.org/10.3390/electronics12204323
Fatima S, Ali S, Kim H-C. A Comprehensive Review on Multiple Instance Learning. Electronics. 2023; 12(20):4323. https://doi.org/10.3390/electronics12204323
Chicago/Turabian StyleFatima, Samman, Sikandar Ali, and Hee-Cheol Kim. 2023. "A Comprehensive Review on Multiple Instance Learning" Electronics 12, no. 20: 4323. https://doi.org/10.3390/electronics12204323
APA StyleFatima, S., Ali, S., & Kim, H. -C. (2023). A Comprehensive Review on Multiple Instance Learning. Electronics, 12(20), 4323. https://doi.org/10.3390/electronics12204323