4.1.2. Experimental Result
It is inappropriate to rely solely on accuracy as a performance measure in ML. When dealing with imbalanced datasets where positive samples are in the minority, a high accuracy may not necessarily indicate that the model’s actual performance is satisfactory. For instance, in a dataset where positive samples constitute only 2%, a model could achieve an accuracy of 98% by simply predicting all samples as negative. However, in reality, the model would not have made any meaningful predictions. Therefore, this study employs multiple metrics to assess the model’s performance.
Table 1 summarizes the algorithm hyperparameters used in this study for training XGBoost with different loss functions, including both the XGBoost algorithm hyperparameters and loss function hyperparameters.
The use of different loss functions for model training results in classifiers with varying classification performances, as shown in
Table 2. It can be observed that, except for a fault rate of 0.4, the classifier trained with Softmax performs better. However, for other fault rates, the classifiers trained with the TL show a significant improvement in accuracy. On the other hand, the model trained with the FL could perform better in terms of accuracy at various fault rates.
To further illustrate,
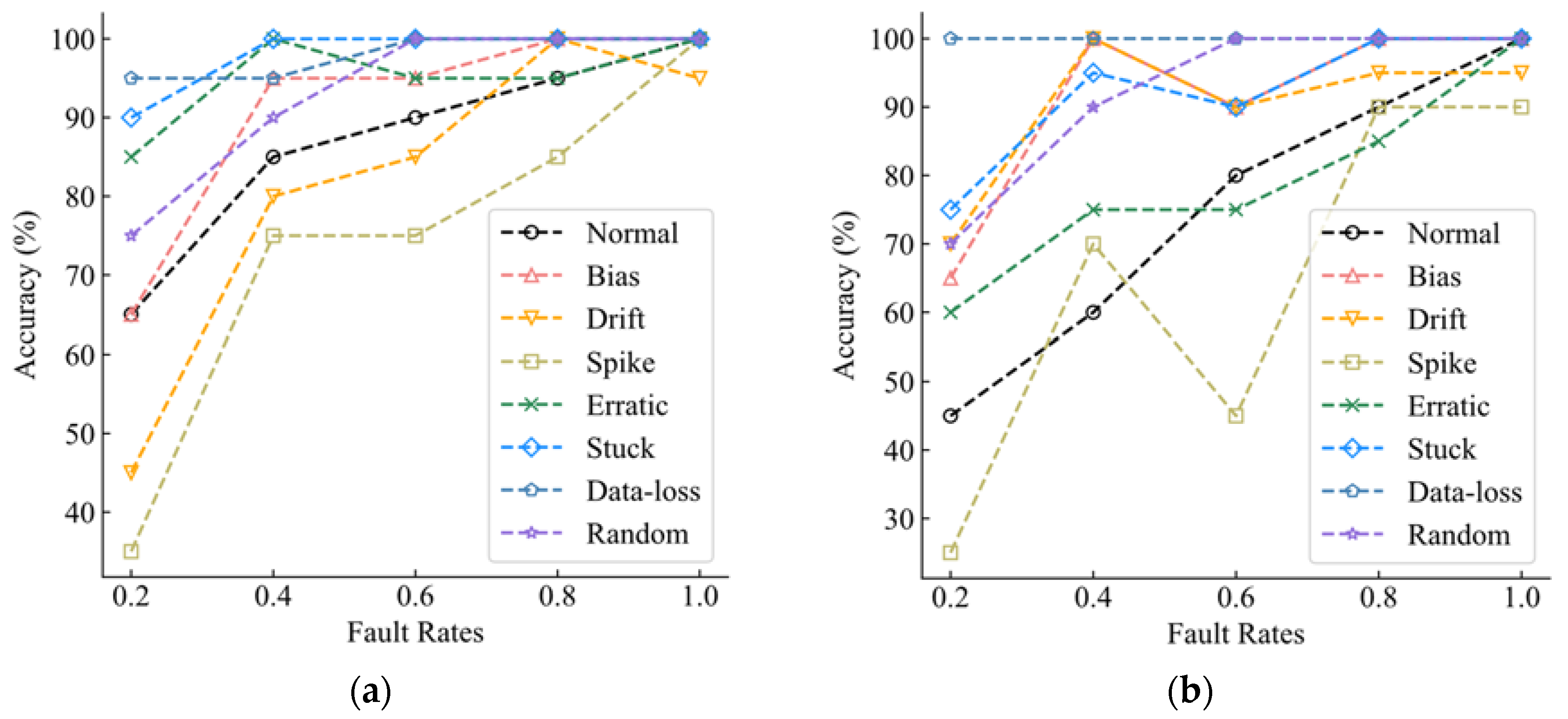
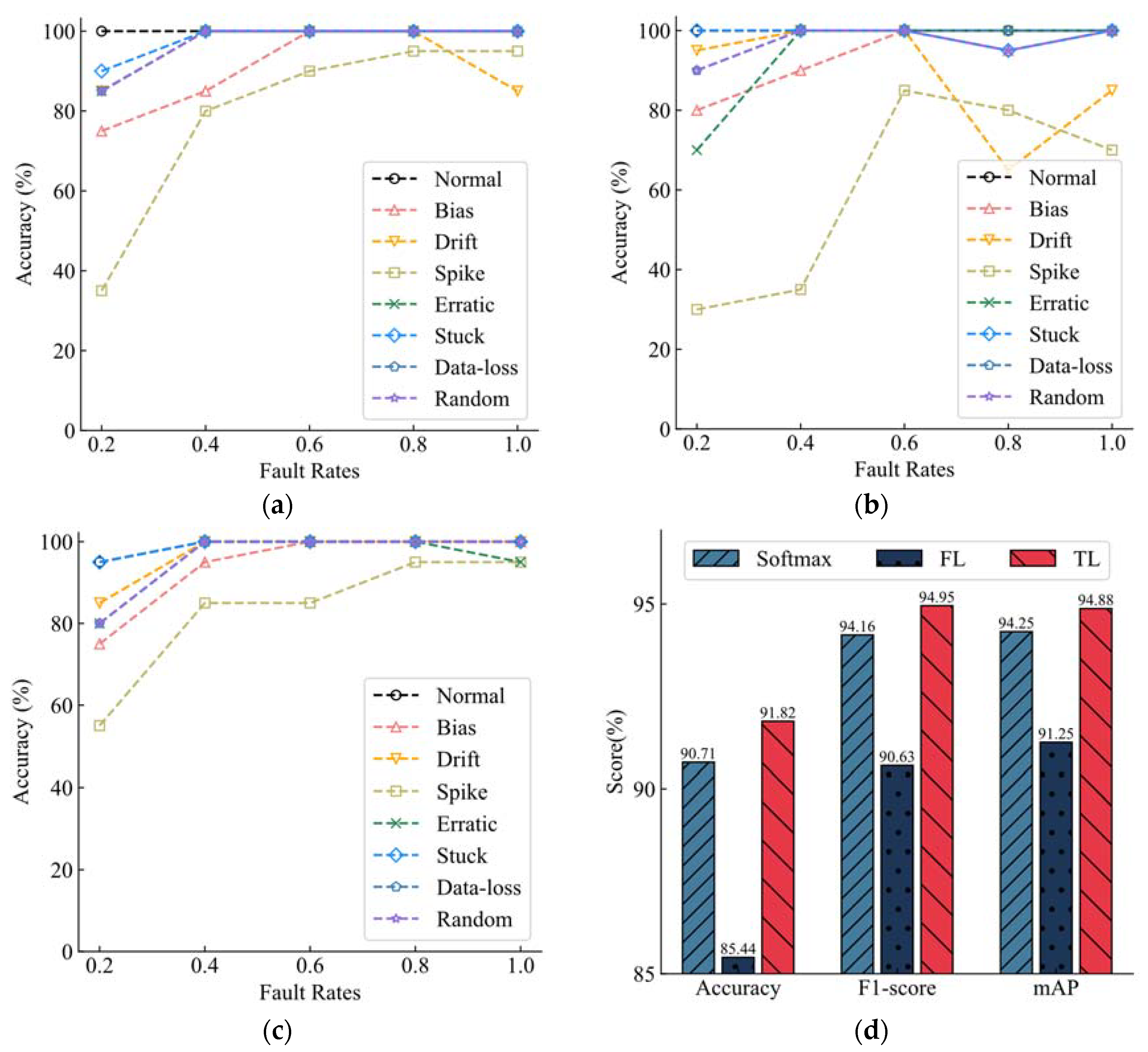
Figure 6a,b shows the recognition accuracy of the three classifiers for the eight categories under different fault rates. In order to better demonstrate the superiority of the proposed method,
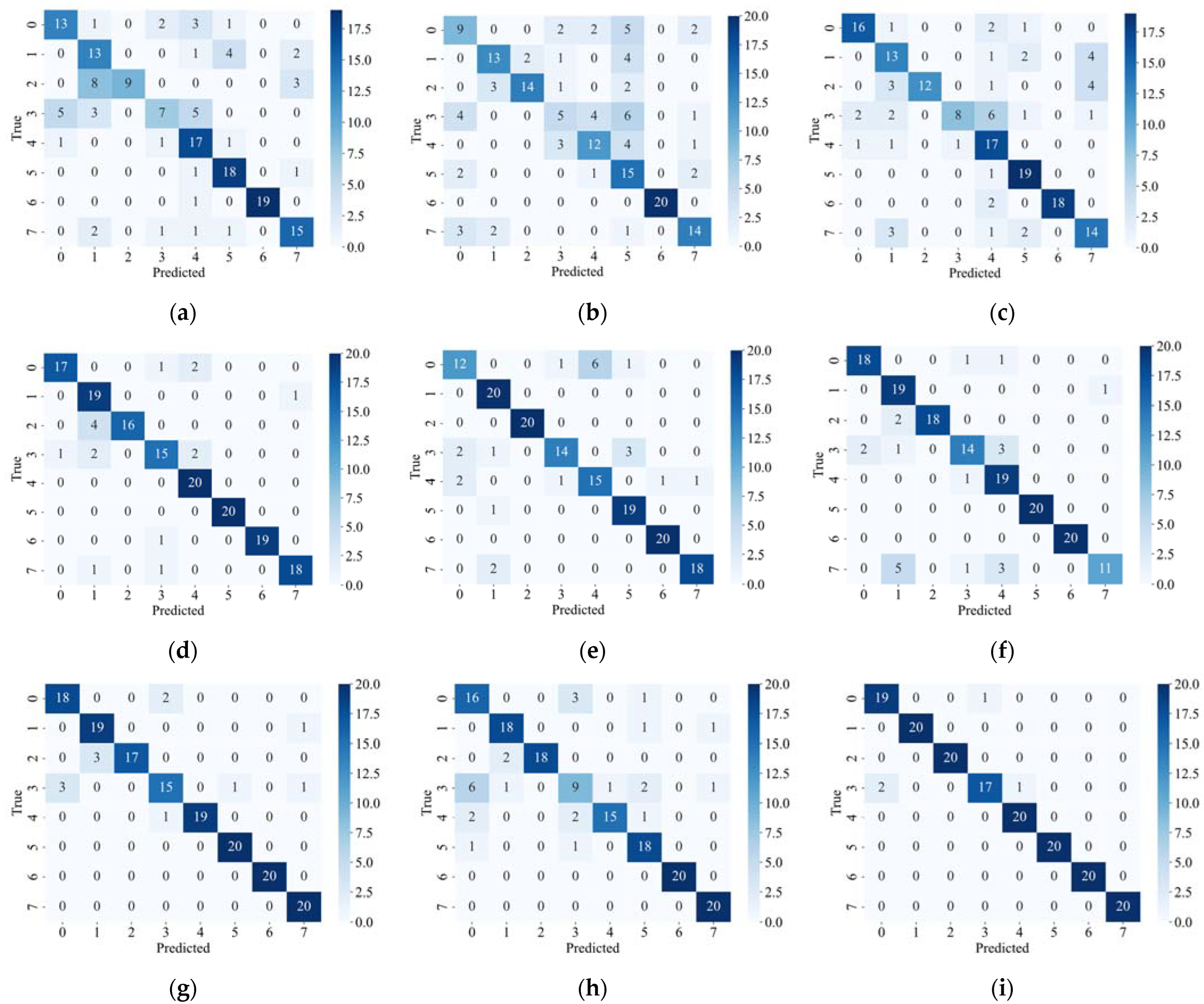
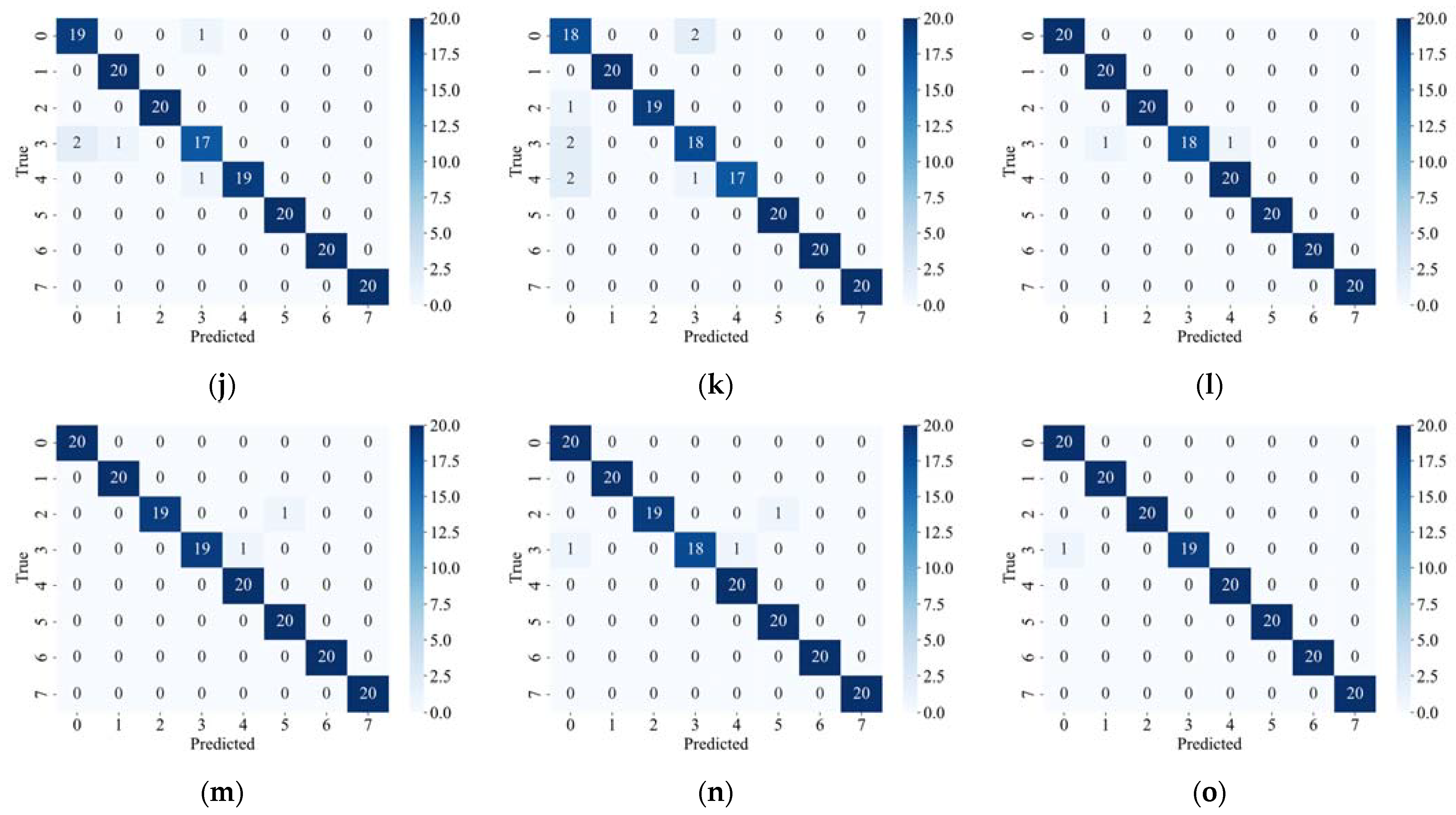
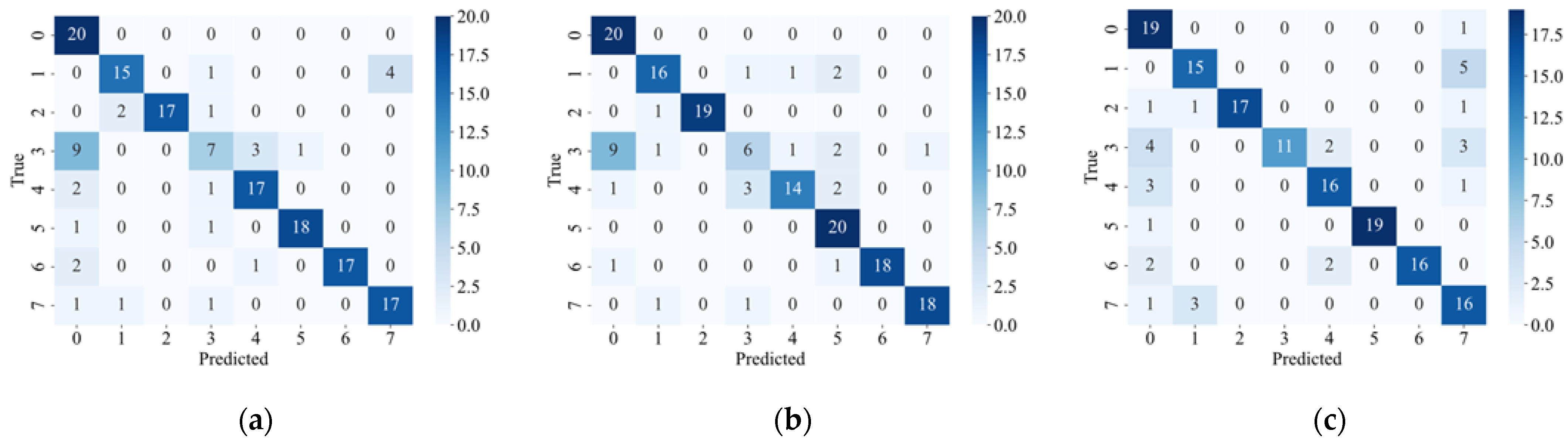
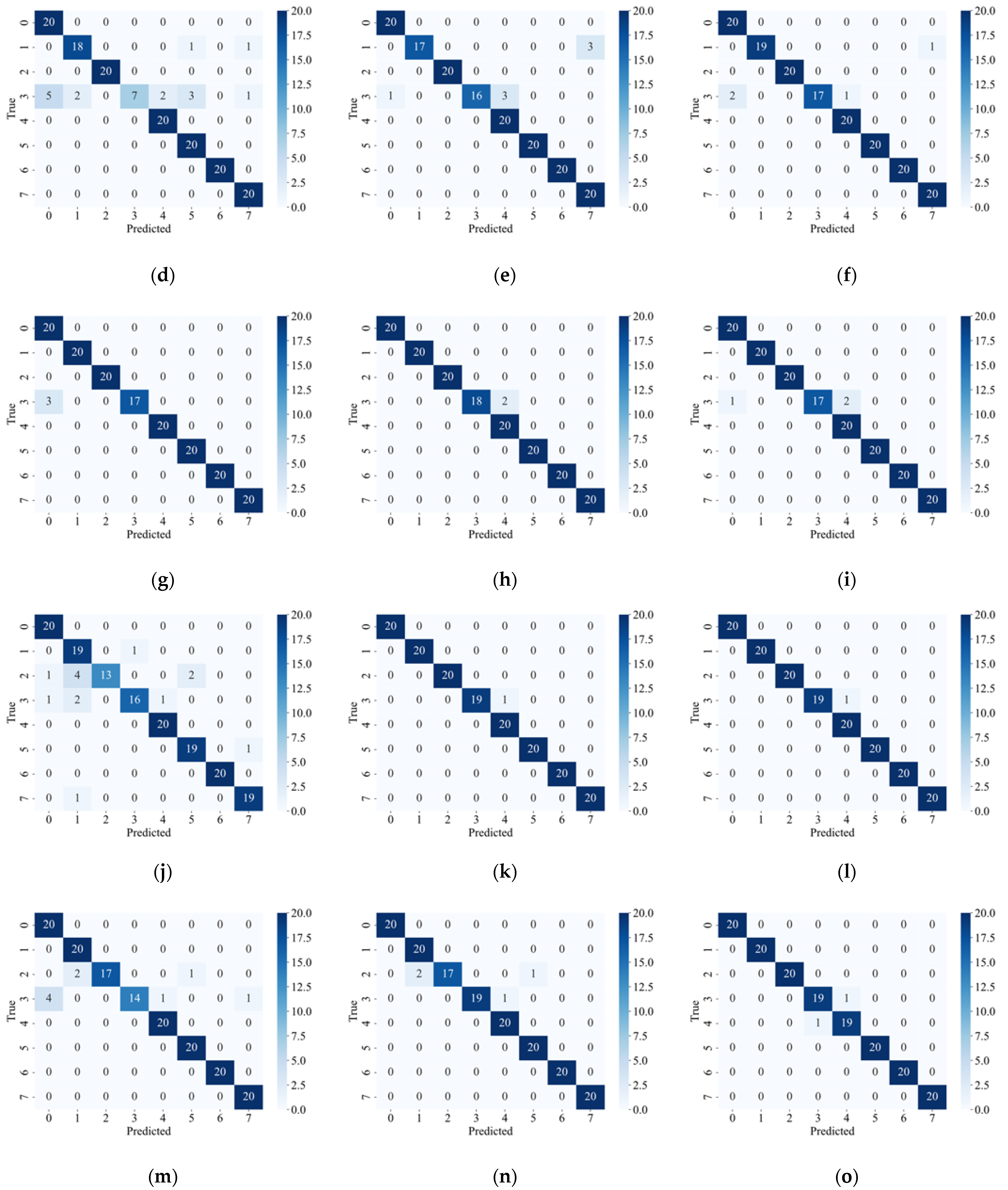
Figure 7 shows the confusion matrix of each model under different failure rates.
Figure 6a shows the classification accuracy of each fault type in data sets with fault rates of 0.2, 0.4, 0.6, 0.8, and 1 for the model trained using the XGBoost default loss function. It can be seen that the diagnostic accuracy of the model generally increases with the increase of the fault rate, except that the classification performance of the categories Erratic and Drift decreases when the fault rate is 0.6 and 1, respectively. When the fault rate of the model reaches 0.8, the recognition accuracy of all categories reaches more than 80%. When the fault rate reaches 1, the prediction accuracy of other categories of faults reaches 100%, except Drift faults.
Figure 6b shows the model trained with FL as a loss function and the classification accuracy of each fault type in data sets with fault rates of 0.2, 0.4, 0.6, 0.8, and 1, respectively. With the increase in the fault rate, the overall identification accuracy of the model is gradually improved. However, when the fault rate is 0.6, the performance of the model decreases obviously, and the identification accuracy of Spike, Erratic, Stuck, and Drift decreases somewhat, among which the identification accuracy of Spike declines most seriously. This makes the overall recognition of the model decline even less than the model’s recognition accuracy when the fault rate is 0.4, but when the fault rate reaches 0.8, the accuracy of various categories can still reach more than 80%, but the overall classification accuracy of the model is not high. In general, the overall performance of the model trained with FL as a loss function is not as good as that of the model trained with the default loss function, especially when the fault rate is below 0.6. The gap between the two is obvious, and when the fault rate reaches 0.8 and 1, the performance gap between the two is reduced.
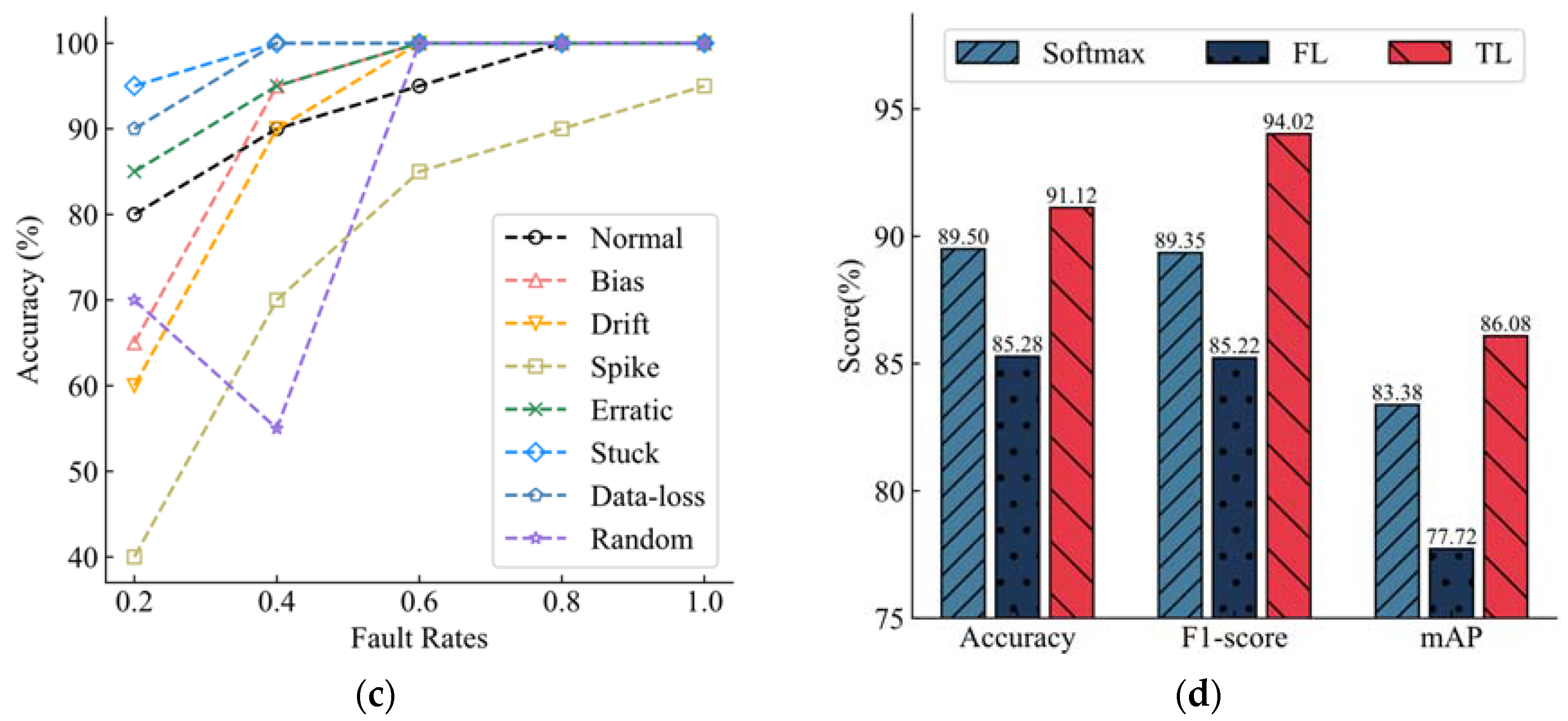
Figure 6c shows the classification accuracy of each fault type in data sets with fault rates of 0.2, 0.4, 0.6, 0.8, and 1 for the model trained with TL. With the increase in the fault rate, the overall recognition accuracy of the model still increases. When the fault rate is 0.4, the classification performance of the model Random decreases, which is also the main factor restricting the recognition accuracy of the model. However, when the fault rate reaches 0.6, the model shows good classification performance, and the accuracy rate of all categories reaches more than 80%. Except for Normal and Spike, the accuracy rate of other categories reaches 100%. When the fault rate reaches 1, in addition to the classification accuracy of Spike faults (but also up to 95%), the identification accuracy of other categories reaches 100%. It can be seen that TL makes the model have higher precision.
The classification of spike faults is a difficult task for XGBoost models, and in this regard, the models do not always do a good job of classifying spike faults, whether they are trained with default loss functions, FL training models, or TL training as loss functions. However, TL-trained models generally have the best performance in identifying spike faults. For the model trained using TL, when the fault rate is 0.4, the recognition accuracy of random faults has a huge decline, which is also the reason why the accuracy of the model trained using TL is not improved but decreased compared with the model trained using the default loss function at this fault rate. Data loss faults and stuck faults are relatively easy tasks for models, and models trained with TL and default loss functions can maintain an at least 90% recognition accuracy. In general, the TL-trained model can improve the accuracy of XGBoost. In addition to the recognition of random faults with a fault rate of 0.4, the model has been improved to varying degrees in other cases.
In addition to accuracy, this study also evaluated the performance of the models using Precision, Recall, F1-score, and mAP metrics.
Table 3 and
Table 4 present the Precision, Recall, F1-score, and mAP of the models trained with three different loss functions at fault rates of 0.2, 0.4, 0.6, 0.8, and 1, respectively. It can be observed that the model trained with TL outperforms the models trained with the default loss function and focal loss in terms of Precision, Recall, F1-score, and mAP, except for the case where the fault rate is 0.4. This indicates that the model trained with TL exhibits a superior performance.
By comparing trained models with the default loss functions and FL, it can be seen that the models trained with TL showed average improvements of 6.73% and 1.81% in classification accuracy, 6.80% and 1.86% in the F1-score, and 10.75% and 3.24% in mAP, respectively, across five different fault rates. The maximum improvements observed at these five fault rates were 16.41% and 5.4% in classification accuracy, 16.83% and 5.45% in the F1-score, and 28.78% and 9.87% in mAP, respectively.
The overall performance of the model is shown in
Figure 6d. The average level of the three loss training models under different fault rates is compared. The TL training model has the best performance, and both Accuracy, the F1-score, and mAP have achieved the highest scores. The default loss function training model shows good improvement compared to the FL training model, which improved significantly. XGBoost is a mature algorithm, and using TL as a loss function can still make the model perform better. In order to achieve higher classification accuracy and a better performance of the model, it is recommended to use TL as a loss function to train the model.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}