1. Introduction
Deep learning models emerged to surpass human performance on multiple vision tasks [
1,
2]. Artificial neural networks employ layers of biologically inspired neurons that are learned by different variants of gradient descent [
3,
4]. Despite their success, deep learning models are regarded as a black box because the process in which the individual neurons generate outputs is not interpretable [
5,
6]. Moreover, deep learning classifiers do not construct a hierarchy of concepts explicitly and use a fully connected layer for classification, which predicts a score for each of the existing classes, thus scaling as
with the number
K of classes. While this approach is reasonable for current datasets with up to
classes, it becomes cumbersome and computationally expensive when the number of classes increases to tens of thousands of classes or more.
On the other hand, humans can establish hierarchical semantic relations between categories, which are learned by much fewer samples than deep learning models. In this respect, [
7] stated that the human cognitive architecture is composed of substructures for hierarchical processing. Using this hierarchical representation, humans are capable of easily recognizing millions of classes of objects and can add new classes with just a few examples and no retraining.
Models like symbolic systems attempted to simulate the high-level reasoning processes of humans (classification logic and temporal logic). For example, ref. [
8] has proposed that rule-based hierarchical classification is biologically inherited by humans or other non-human mammals like baboons. Furthermore, ref. [
9] proposed a framework known as neural symbolic system artificial neural networks (ANNs). It provides the framework for parallel computation and robust learning while logic units provide interpretability. However, most symbolic systems often require problem-specific manual tuning features [
10], and are not able to learn features from raw input data [
11].
In this context, the research question that this paper tries to address is the following:
Can image classification models be organized hierarchically to speed-up per example classification from to or faster, where K is the number of classes?
To address this question, we introduce a hierarchical framework for object classification called Hierarchical PPCA, which is inspired by our understanding of human hierarchical cognition. In this work, a two-level taxonomy is used to model the semantic hierarchy of image classes, but more levels could also be used if desired. Image classes are conceptualized as Gaussian distributions with Probabilistic Principal Component Analysis (PPCA) models. Instead of standard neurons, the classifier is constructed using PPCA neurons. We assume that image classes with similar semantic information will cluster together, each semantic cluster being characterized by its centroid (a Gaussian), which we refer to as a super-class. For this purpose, we introduce a modified k-means clustering algorithm to explore underlying semantic relations between image classes and build the class hierarchy. In the classification stage, an image of a cat will first be assigned to a super-class like ‘animal’ and then classified among the image classes associated with the ‘animal’ super-class. This hierarchical scheme facilitates sparse neuron firing and requires considerably less computation resources than the traditional flat structure. If the dataset contains K classes, the hierarchical model can classify images in time instead of as in standard classification. Experiments have shown that Hierarchical PPCA can applied to large-scale datasets with superior accuracy and efficiency.
The main contributions of the proposed Hierarchical PPCA method are:
It introduces a hierarchical classification model for learning from datasets with a large number of classes, without hierarchical annotation. The image classes are modeled as Gaussian distributions based on Probabilistic PCA (PPCA). The model reduces the per-observation classification time for K classes from to , and potentially to when using more hierarchy levels.
It presents an efficient training procedure based on a generalization of k-means clustering that clusters image classes instead of features. This design can handle unbalanced data where the number of observations in each class differs widely.
It conducts experiments on large-scale datasets that show that indeed the hierarchical approach can speed-up classification without any loss in accuracy.
The paper is organized as follows.
Section 2 presents a review of the literature on hierarchical clustering and hierarchical models for vision.
Section 3 presents an overview of our Probabilistic PCA, which is the foundation on which the proposed Hierarchical PPCA is built.
Section 4 presents the proposed Hierarchical PPCA method that clusters the PPCA Gaussians into a smaller number of super-classes and uses the super-classes to speed-up classification for a given example.
Section 5 presents experiments on three datasets with 100, 1000 and 10,450 classes to evaluate the increase in speed and accuracy of the proposed method. Finally,
Section 6 finishes with conclusions and a discussion on future work.
4. Proposed Method
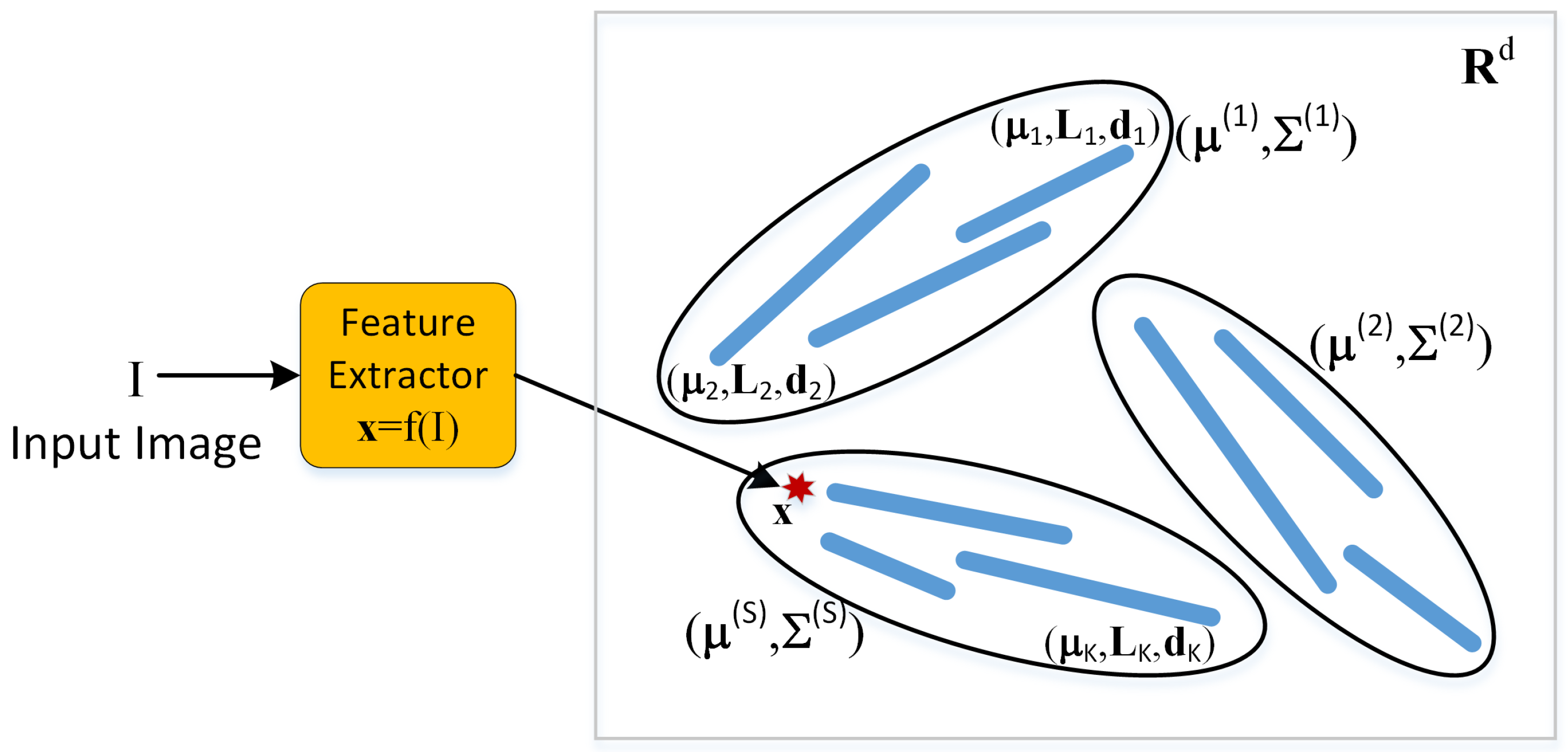
Inspired by our understanding of the human hierarchical representation of objects, this work proposes a hierarchical classification framework called Hierarchical PPCA that exploits the semantic information of image classes.
Figure 1 illustrates the hierarchical classification process, where an observation
is first classified and assigned to a super-class
and then classified and assigned to an image class from the image classes belonging to that super-class.
4.1. Hierarchical Classifier
In [
26], it was stated that the human cognitive architecture is built up of a hierarchy of multiple system levels. Humans, even babies, use the hierarchical cognition system to conduct categorization without training with huge numbers of images. Inspired by this finding about human hierarchical cognition, the classifier is modeled as a two-level taxonomy. It aims to organize the information with two levels of abstraction.
In the Hierarchical PPCA model, each image class is conceptualized as a Gaussian distribution by Probabilistic Principal Component Analysis (PPCA) [
25], as described in
Section 3.2.
The first level of the classifier consists of PPCA neurons representing super-classes. The second level of the classifier consists of PPCA neurons encoding information about image classes. The essential assumption is that image classes with similar semantic information cluster together. A cluster is characterized by its centroid, a PPCA Gaussian that we call a super-class. A super-class maintains the least distance to the image classes belonging to the same cluster. If there are
K image classes to be classified (e.g.,
for ImageNet), they are clustered into
S disjoint sets
such that:
In the framework of Hierarchical PPCA, the first level models (the super-classes) are represented as , with , where S is the number of super-classes. For a super-class , the corresponding image classes are represented as with .
4.2. Hierarchical Classification
Given an observation
(obtained from an image
using the feature extractor as
), the first level classifier aims to find the most likely super-class
s for the observation, a process called super-classification. After the sample
is assigned to a super-class
s, the second level of the classifier will find the most likely image class among image classes
associated with super-class
s. This process is called image classification. Since both level models are Gaussians, we will use the Mahalanobis distance,
to measure how well an observation
fits the Gaussian model
, where a smaller score is better. In practice, for classification involving high-dimensional features and PPCA models, we use Equation (
7) from Theorem 1 as a computation efficient score computation method.
However, any super-classification failure would result in the failure of the whole classifier. To minimize the impact of such failures, instead of considering a single most likely super-class, the hierarchical classifier will consider a number
T of the most likely super-classes, as described in Algorithm 1. In experiments,
T was taken in the range of
.
| Algorithm 1 Hierarchical classification |
| Input: Observation , super-class models , image class models , clusters such that |
| Output: Predicted class label |
- 1:
Compute the super-class scores - 2:
Find the indices of the T lowest scores - 3:
Compute the index set - 4:
Obtain the predicted class label
|
4.3. Computation Complexity
The computation demand of a model can be measured by the average number of neurons used in the classification. For an incoming sample feature, a flat classifier requires the computation of the scores for all K image classes to generate the classification output. In contrast, Hierarchical PPCA requires the score computation for all S super-classes and the score computation of the image classes corresponding to the top T super-classes. Let A denote the average number of image classes associated with one super-class. The computation cost for one classification in Hierarchical PPCA is therefore neurons (score computations).
We use two measures to evaluate the computational cost of Hierarchical PPCA compared with flat classification. The density is defined as
The inverse of the density measures the increase in speed of Hierarchical PPCA compared to flat classification:
Assuming the
K image classes are uniformly distributed for the
S clusters, then
and the density is
From an efficiency perspective, the density reaches a minimum when
, where the increase in speed reaches a maximum of
. The experimental results in
Section 5.6 match our theoretical derivation.
4.4. Training the Hierarchical Classifier
One important assumption is that image classes with similar semantic information form clusters in the feature space. With this assumption, we adopt a variant of the
k-means algorithm to explore the semantic structure of image classes and train the hierarchical classifier. The difference to the standard
k-means is that instead of clustering observations, the proposed algorithm clusters image classes encoded as Gaussian distributions. The advantage of this approach is that it only needs to cluster a small number of elements (e.g., 1000 Gaussian distributions for ImageNet) instead of millions of observations. Moreover, this kind of clustering is robust to data imbalances in the classes. The training algorithm is summarized in Algorithm 2.
| Algorithm 2 Hierarchical PPCA training |
| Input: Training observations , number S of super-classes, number q of PCs for the image class models, number r of PCs for the super-class models. |
| Output: Super-class models , image class models . |
- 1:
Train the image class Gaussian models using Equations ( 3) and ( 4). - 2:
Initialize S super-class models using k- means++ ( Section 4.4.1). - 3:
while not converged do - 4:
Assign the image classes to the super-classes using Equation ( 15) - 5:
Update the super-class models based on the image classes in the same clusters ( Section 4.4.3). - 6:
end while - 7:
Train the image class PPCA models ( Section 3.3). - 8:
Update the super-class PPCA models
|
The training procedure is a generalization of
k-means clustering. The clustering subjects are image classes encoded as Gaussian distributions
instead of vectors. The covariance matrices used for clustering the image classes are the full image covariances
from Equation (
4) instead of the PPCA covariances (
6).
We innovate with the following modification for the new clustering subjects:
The distance measure between the image classes, which is used for the
k-means++ initialization [
27], is replaced by the Bhattacharyya distance (instead of the Mahalanobis distance) between Gaussians (
Section 4.4.1).
The distance measure between an image class and a Gaussian super-class model is the KL divergence, described in
Section 4.4.2.
The Gaussian super-class models are parameterized to minimize the sum of the KL-divergences of the image class models, as described in
Section 4.4.3.
These steps will be presented in the following sections.
The second level of the Hierarchical PPCA model contains PPCA models representing information for the image classes. The PPCA neurons are trained by SVD decomposition separately for each class, as described in
Section 3.3. The same approach is used to obtain super-class PPCA models from the super-class covariance matrices.
4.4.1. Initialization by k-Means++
The performance of
k-means relies significantly on its initialization. In [
28], it was shown that the case with the worst running time of the
k-means algorithm is super-polynomial in the input size. We adopt the
k-means++ [
27] initialization method to accelerate the convergence speed and improve clustering performance. The process of
k-means++ is detailed in Algorithm 3.
The elements that are clustered are the image classes represented by Gaussian distributions. We adopt the Bhattacharyya distance to measure the pairwise distance between two distributions. For Gaussian distributions
and
, the Bhattacharyya distance is
where
.
| Algorithm 3 k-means++ centroid initialization |
| Input: Image classes represented as , number S of clusters |
| Output. Initial super-class models (centroids) , |
- 1:
Randomly pick the first centroid - 2:
for to S do - 3:
Compute the distance between all image classes and the newly selected centroid using Equation ( 14) - 4:
Generate the discrete distribution on image classes proportional to the distance from each image class to its closest centroid from - 5:
Sample the image class from the discrete distribution generated - 6:
Obtain initial centroid - 7:
end for
|
4.4.2. Assignment of Image Classes to Clusters
In the training process, the image classes are assigned to the nearest cluster. A distance measure is needed to measure the distance from image classes to the clusters, both of which are characterized by Gaussian distributions. We adopt the Kullback–Leibler (KL) divergence [
29], denoted by
, to measure the distance between image classes and super-classes.
Since all classes are encoded as Gaussian distributions, the KL divergence between a super-class
and an image class
is [
30]
4.4.3. Super-Class Model Update
By our assumption of image classes, the super-class model is the centroid of the corresponding cluster, i.e., the Gaussian distribution that has the smallest sum of the distances to the image classes within the same cluster.
The image classes within a cluster
C are normal distributions
. The corresponding super-class model is a normal distribution
so that the sum of the distances from the image classes to the super-class
is minimized, where
is defined in Equation (
15).
The following theorem gives a closed-form solution of the minimization.
Theorem 2. The Gaussian distribution that minimizes from Equation (16) has meanand covariance Proof. From [
30], the KL divergence between normal distributions
and
is
so the sum is
Setting the partial derivative of
with respect to
,
to zero, we obtain
.
can be written as
; thus, the third term of Equation (
20) can be written as
Thus, the distance (
20) can be written as
Therefore, the partial derivative of
with respect to
is
Setting
and multiplying the left and the right by
, we obtain
□
The super-class PPCA models can be computed by writing by SVD, and obtaining as the first q columns of and as the first q diagonal elements of .
5. Experiments
Experiments were conducted to compare the accuracy and computation efficiency of Hierarchical PPCA with the flat PPCA classifier, i.e., the one-level classifier containing the same PPCA image models but where the classification finds the minimum score for an observation among all classes . The experiments were designed to explore how some of the main parameters such as the number S of super-classes, the number of principal components, and the parameter T from Algorithm 1 influence accuracy and computation efficiency.
5.1. Datasets
Experiments were conducted on three standard datasets: ImageNet-100, ImageNet-1k (ILSVRC 2016) [
31], and ImageNet-10k. ImageNet-100 is a subset of ImageNet-1k with only 100 classes, randomly sampled from the original 1000 classes. ImageNet-10k is the subset of the whole ImageNet [
31] that contains all 10,450 classes with at least 450 training observations. They are standard image datasets that are adopted to prove the robustness and facilitate comparisons. All results are reported as averages of five independent runs for better reproducibility. Each of these datasets has a separate test set with 50 observations per class; thus, the ImageNet-1k has 50,000 test observations, and so on.
5.2. Feature Extractor
The feature extractor
used in this work is the ResNet50x4 from CLIP (Contrastive Language-Image Pre-Training) [
32]. CLIP models are pairs of image embedding and language embedding models, trained on 400 million pairs of images and their corresponding captions. They are trained on a wide variety of images with a wide variety of natural language supervision that is abundantly available on the internet. By design, the network can be instructed in natural language to perform a great variety of classification benchmarks, without directly optimizing for the benchmark’s performance. As such, it was not trained or fine-tuned on the three evaluation datasets. CLIP models with different numbers of parameters were also used in [
23] for classification using a simple
k-nearest neighbor classifier.
The choice of the feature extractor is important for the validity of the assumption made for Hierarchical PPCA, which is that semantically similar classes cluster together.
5.3. Evaluation Measures
Efficiency Measure. There are two efficiency measures: density and speed increase. The density evaluates how much less computation is required for classification using Hierarchical PPCA compared to flat classification. The theoretical definition and analysis were presented in
Section 4.3. In practice, density is defined as
where
A is the average number of image classes used,
S is the number of super-classes, and
K is the total number of classes. The speed increase is the inverse of density and measures the computational efficiency of Hierarchical PPCA. The theoretical analysis from
Section 4.3 indicates that the density reaches a minimum and the speed increase is at a maximum when
.
Super-class accuracy. The super-classes are constructed without human annotation, using k-means clustering, by exploring the semantic relations between the image classes. Classifying an observation to the wrong super-class would result in a failure in the overall classification of this observation. The super-class accuracy measures the top-T classification accuracy of the level 1 (super-class) classifier.
5.4. Raw Data Clustering
In Hierarchical PPCA, the super-classes are learned by clustering the image classes, which are parameterized as Gaussian distributions. Another hierarchical method that will be evaluated is raw data clustering, which is similar to Hierarchical PPCA, but the super-class models are obtained from clustering a subsample of observations from the image classes instead of clustering the Gaussian models of image classes.
In this experiment, 20 images are randomly sampled from each image class, obtaining a sample of
images, where
K is the number of image classes. The images are clustered in
S clusters using the standard
k-means clustering algorithm. Then, each image class is assigned to the cluster containing the maximum number of its images. The super-class models are updated for each cluster as described in
Section 4.4.3.
5.5. Main Results
For completeness, we will also evaluate a standard linear projection head, which is a fully connected layer trained to predict the class label from the same feature vector
as the Hierarchical PPCA classifiers for an image
. These linear projection classifiers were trained using the Adam optimizer [
33] and the cross-entropy loss, starting with a learning rate of 0.03. The models on ImageNet-100 and ImageNet-1k were trained for 300 epochs and the learning rate was reduced by 5 every 50 epochs, while the model on ImageNet-10k was trained for 100 epochs and the learning rate was reduced by 5 every 15 epochs.
The main comparison of the Hierarchical PPCA, Hierarchical PPCA with raw data clustering, flat PPCA and the linear projection head in terms of test accuracy and computational efficiency is shown in
Table 1. The results are averages of five independent runs with the standard deviation shown in parentheses. The flat PPCA classifier is deterministic (being obtained by SVD from the observations of each class independently), so only the ImageNet-100 accuracy has non-zero variance, due to the random subsampling of the 100 classes out of 1000.
From
Table 1, we see that for ImageNet-1k and ImageNet-10k datasets, when
, the Hierarchical PPCA surpasses the linear projection classifier both in terms of accuracy and computational efficiency. Compared to flat PPCA, the Hierarchical PPCA results are slightly inferior.
Table 2 shows detailed results on Hierarchical PPCA with raw data and with Gaussians with
. It indicates that clustering Gaussians is usually better than clustering raw data. On ImageNet-1k, the performance of clustering from raw data is slightly inferior to Hierarchical PPCA for
. On ImageNet-10k, clustering raw data is consistently inferior to clustering Gaussians.
5.6. Hyperparameter Analysis
A hyperparameter analysis investigates the importance of the number S of super-classes, the parameter T of Algorithm 1, and the number of PCA directions of the PPCA models in the speed and accuracy of the Hierarchical PPCA method.
5.6.1. Number S of Super-Classes
The super-classes represent the general concepts in the Hierarchical PPCA approach, which are used to speed up classification. The number of super-classes S is an important factor for computation efficiency and overall accuracy.
Table 3 shows an evaluation of the test accuracy and speed increases for different numbers of super-classes for the three datasets.
ImageNet-100 contains 100 image classes. The experiment adopts three values for S, namely, . The density does not decrease monotonically with increasing S. The speed increase reaches a maximum of 2.0 when . The super-class test accuracy for the three values of S is larger than the flat accuracy, indicating unsupervised generated super-classes are interpretable for classification. The super accuracy decreases monotonically with an increase in S. The result indicates that the overall accuracy has a negative correlation with the speed increase coefficient.
For ImageNet-1k, we adopted seven values for
S,
, since
. From the perspective of efficiency, the speed increase coefficient reaches a maximum when
, which is higher than
, the theoretical optimum derived in
Section 4.3. The efficiency approximately conforms to the theoretical derivation. The accuracy and super accuracy reach their maximum when
and are negatively correlated with
S. The result follows a similar pattern to the result of ImageNet-100.
For ImageNet-10k, considering that K = 10,450, we consider the following S values: . From the perspective of efficiency, the speed increase coefficient reaches the optimum of 20 when , which is approximately . The Hierarchical PPCA reaches the best accuracy of 0.379 when with a speed increase of .
In summary, the S experiments indicate that the efficiency of the Hierarchical PPCA for reaches an optimum when . Overall, the accuracy and super accuracy have a negative correlation with S. The overall accuracy of Hierarchical PPCA is slightly inferior to flat classification. The super accuracy results indicate that super-classes are interpretable for classification.
5.6.2. Improving the Super Accuracy
Hierarchical PPCA assigns the samples to the T most likely super-classes. Super-classification failure significantly damages the overall classification accuracy. The overall error is composed of errors from image classification and errors from super-class classification. The Hierarchical PPCA can increase its super-class accuracy by considering samples from multiple most likely clusters. Experiments aim to explore whether increasing T benefits the overall accuracy and the impact on the classification speed.
Table 4 shows the effectiveness of this strategy. The overall accuracy increases monotonically with
T. For ImageNet-100, Hierarchical PPCA reaches the flat classification accuracy when
. Meanwhile, the super-class accuracy increases significantly, from 0.95 to 0.999. Compared to flat classification, Hierarchical PPCA can reach a similar accuracy while only using
of the PPCA neurons.
Table 4 also indicates that the density increases linearly with
T.
The results on ImageNet-1k with follow a similar pattern. The accuracy and super accuracy follow a positive correlation with T. The overall accuracy increased from 0.672 to 0.718 as T increased to 2. The Hierarchical PPCA achieves a performance close to that of flat classification when T reaches 5 while the density is 0.212. Hierarchical PPCA can achieve a similar performance with less than of neurons.
The experiment on ImageNet-10k was conducted with . The overall accuracy increased from 0.319 to 0.376 as T increased to 5. The density increases linearly with T.
In summary, the strategy of increasing T elevates the super-class accuracy and overall accuracy by sacrificing some computational efficiency. The experimental results indicate that for medium datasets like ImageNet-100 and ImageNet-1k, Hierarchical PPCA can achieve equivalent results with no more than of the neurons used. The computational cost increases approximately linearly with increasing T.
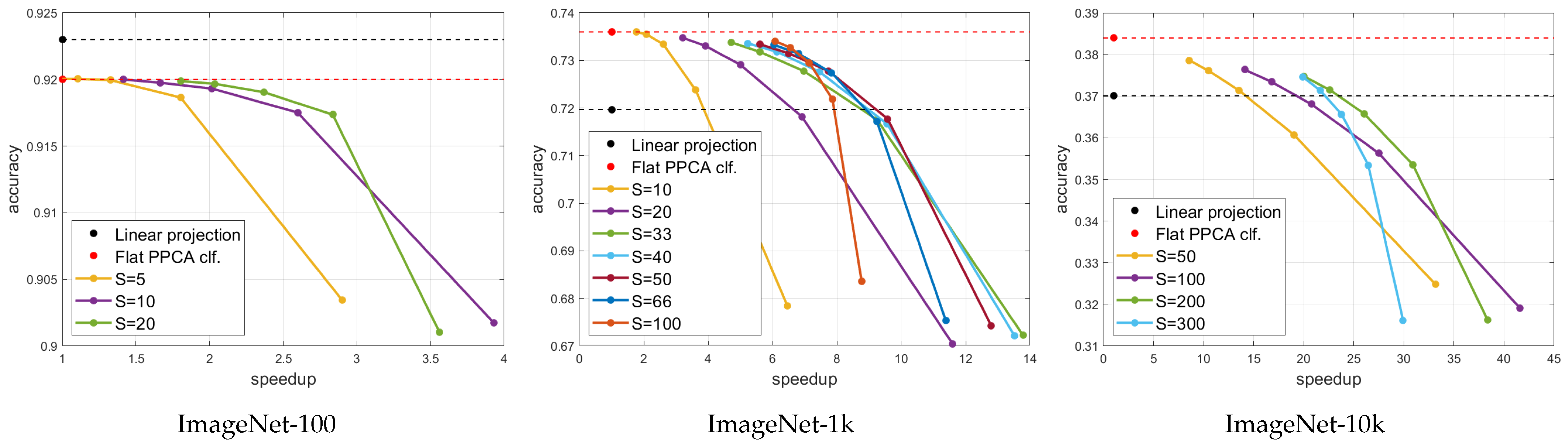
Figure 2 reveals the relationship between the accuracy and speed increase for different numbers
S of super-classes, where each curve represents the accuracy vs. speedup for one value of
S and for
. The relationship between the accuracy and speed increase coefficient follows a negative logarithmic trend. Compared to flat classification, hierarchical classification can obtain a comparable accuracy with between a 2-fold and 20-fold speed increase, depending on the dataset. Compared to the standard linear projection classifier, Hierarchical PPCA has a superior accuracy for large datasets, with an 8–20-fild speed increase.
5.6.3. Number of Principal Components
The number of principal components (PCs) is an essential hyperparameter. Theoretically,
q represents the dimension of the (linear) manifold to the observations of each class. Furthermore, the case considered is
, in which the PPCA neurons will degenerate into radial basis function (RBF) neurons [
34]:
where classification is based on the nearest Euclidean distance to the mean
instead of the Mahalanobis distance (
2). The experiment aims to explore how the number of principal components influences accuracy.
Actually, there are two PC parameters: the number q of PCs in the image class PPCA models and the number r of PCs in the super-class PPCA models.
Experiment 1, r = q. In the first experiment, we set
(same number of PCs for classes and super-classes) and varied
q.
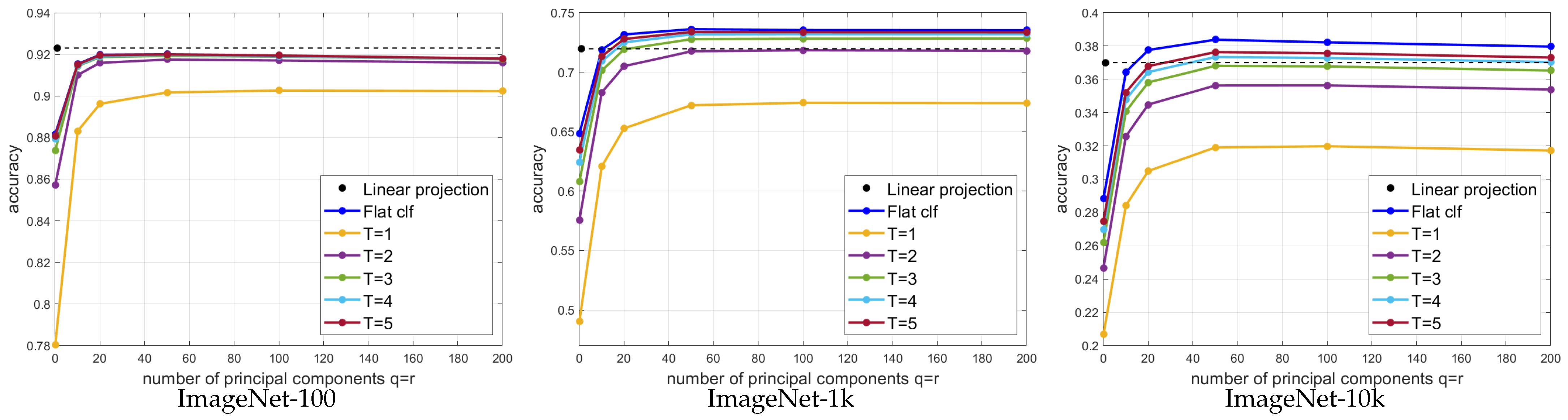
Table 5 and
Figure 3 present the accuracy for different numbers
q of PCs used in both the image class and the super-class models (
). The overall accuracy of Hierarchical PPCA and flat classification does not increase with
q monotonically. There is an optimum number of principal components where the overall accuracy reaches a maximum. This optimum point indicates the classifier’s capacity of utilizing variation to improve the classification. The optimum point for flat classification is
and for Hierarchical PPCA, the optimum point is
.
Figure 3 indicates that Hierarchical PPCA with
starts to surpass the linear projection head on accuracy when
q reaches 20. With more variation, Hierarchical PPCA performs better than the linear projection head. When
, the PPCA neurons degrade to RBF neurons.
Table 5 shows that PPCA neurons are superior to RBF neurons for both flat and hierarchical classifiers.
Experiment 2, changing r when q = 50. Super-classes represent more general concepts in Hierarchical PPCA. They are generated by the minimization of the sum of the distance to the image classes. In Experiment 1 above, we explored the relationship between the number of principal components for all PPCA neurons () and the overall accuracy. However, the super-classes may have different semantic properties than image classes. This experiment is designed to explore how the amount of variation encoded for super-classes influences the overall accuracy. We restrict the number of PCs q for the image classes to , which is the optimum point for flat classifiers, while changing the number r of PCs for the super-classes.
Table 6 indicates that the overall accuracy does not change significantly with the number
r of PCs for the super-classes as long as
. In comparison with the other experiment and with flat classification, we can conclude that changing the variation encoded for super-classes does not influence the classification much. Super-classes have a different semantic property from image classes and the super classification is not sensitive to changing the number of principal components like image classes.
To reveal the semantic characteristics of PPCA neurons, we explore the overall accuracy when a small amount of variation is encoded for super-classes, i.e., , keeping and .
Table 7 reveals that the performance of the PPCA neurons is better than RBF neurons for super classification. For all three datasets, but especially large-scale datasets like ImageNet-1k and ImageNet-10k, more encoded information facilitates the super classification, thus improving the overall accuracy.
6. Conclusions and Future Work
This paper introduced a method for fast image classification called Hierarchical PPCA, aimed at classifying data with a large number of classes. The framework adopts probabilistic PCA as a class model for the classifier and clusters the image classes using a modified
k-means approach into a small number of super-classes. During classification, the hierarchical model first classifies the data into a small number of super-classes, then only activates the corresponding image class models after super-classification. For large-scale datasets without hierarchical annotation, Hierarchical PPCA can achieve superior accuracy with a fraction of the computational cost. The proposed Hierarchical PPCA therefore gives a positive answer to the research question from
Section 1, since the hierarchical organization speeds up classification for
K classes from
to
, while still outperforming a standard linear projection classifier.
Compared with RBF neurons, the PPCA neurons are capable of modeling the complexity of semantic variation to gain a superior classification accuracy. Hierarchical PPCA has a stronger capacity to utilize variation to aid in classification and computation efficiency. We have noticed that, with fewer training samples, Hierarchical PPCA can achieve a considerable performance for large-scale datasets.
Finally, we want to point out some of the limitations of the proposed Hierarchical PPCA method. First, since it depends on a self-trained feature extractor, it can only be as good as the feature extractor allows. A better feature extractor would allow for obtaining even better classification results. Second, it might fail to separate very similar classes such as “male” vs. “female”, where a special classifier would need to be trained to separate them.
In the future, we plan to further expand the Hierarchical PPCA model to handle more than 100,000 classes with a large range of sizes, from between two and ten observations per class to thousands of observations per class.








{kind=link}
{kind=link}
{kind=link}