1. Introduction
Due to their exceptional performance, convolutional neural networks (CNNs) have emerged as the state of the art in recent years for image recognition, object detection, image segmentation and many other applications, rapidly replacing traditional computer vision methods [
1]. In brief, a CNN is a type of feedforward neural network that is distinguished by its ability to extract the most relevant features for the task to be solved from the data utilising convolutional structures [
1]. Due to the advantages they provide, such as local connection, weight sharing and dimensionality reduction by sampling, these types of networks have become extremely popular in research and industry scenarios. Nonetheless, despite their excellent performance, the high computational complexity associated with CNNs may pose a hindrance to their use in applications where power consumption or device size/weight are limiting factors. For example, for the inference of a small image (244 × 244), a large CNN may require around 40G of multiplication or addition operations [
2]. The most popular solution for handling such complexity is to employ graphics processing units (GPUs), and make use of the degree of parallelism they exhibit. GPUs have been widely employed for CNN training and inference, but they are power-hungry engines, which has led to many CNN-based applications being deployed on external servers (cloud computing).
As previously mentioned, there exists a significant niche of applications that necessitate edge computing. These applications typically rely on battery power (for instance, unmanned aerial vehicles, intelligent robotics) and/or the device’s size and weight are key factors (Internet of Things, implanted biomedical devices). In these scenarios, it is possible that GPUs may not be the best solution [
3]; therefore, other possibilities have been investigated, such as mobile GPUs [
4], tensor processing units (TPUs) [
5], field programmable gate arrays (FPGAs) [
6,
7], in-memory computing (iMC) [
8] and application specific integrated circuit (ASIC) [
9]. Similar to the GPU, TPU power consumption can be excessive for edge computing, with iMCs and ASICs being the most energy efficient alternatives. In contrast, due to their lack of reprogrammability, these two options present poor compatibility and scalability with CNN models, characterised by rapid evolution. FPGA offers reprogrammability and, when its hardware architecture is well designed, provides adequate energy efficiency [
10,
11]. FPGA can satisfy power and size constraints, emerging as a design alternative [
12]. It has both pipeline parallelism and data parallelism, so it provides lower latency for processing tasks, becoming a high-performance and flexible accelerator for CNN inference [
13]. Moreover, FPGA has nowadays been integrated into multi-processor system-on-chips (MPSoCs), in which computer and embedded logic elements are integrated (such as the Zynq-7000 SoC and Zynq Ultrascale+ MPSoC series of FPGA boards). In this way, these MPSoCs provide the FPGA with the ability to accelerate CNN inference and the computing capability to work as a stand-alone system without the need for interfacing to an external computer/controller.
Biometric identification over long distances and with people on the move is a complex challenge. In particular, the situation is complicated when the element used for identification is small, such as the iris, which is the highly textured, ring-shaped, externally visible tissue present in the eye. Each iris has a unique texture pattern that allows for unique identification of a person. This characteristic renders iris recognition identification a popular and widely applicable solution, especially in its version of iris identification at a distance (IAAD), which is utilised in various fields such as border control, surveillance, law enforcement, etc. [
14]. In our case, the idea is that the system can capture the iris of a moving subject about two metres away from the camera. Like previous systems, our system will be deployed to cover a partially controlled access point, where subjects must walk along a guideline and look directly into the camera. People will walk through this gateway at a normal pace and must avoid any behaviour that would impede the acquisition of the iris image. In this scenario, the camera position will be fixed and, to cover a field of view of a certain size, a 16 Mpixel sensor is used. There will be a single camera, which will capture the irises with a resolution of about 190 pixels per centimetre. With these systems, one of the big problems is that the depth of field is very limited (only about ten centimetres), so in order to capture at least a couple of images of the irises with the necessary quality of focus, it will be necessary to process many images per second (in our case, the maximum provided by the sensor (47 fps)). The problem is that, as the system has about 2–3 s of recording per user in which the eyes can be detected, the number of eye images that will have to be sent to the external computer for processing can exceed 250 images. As a normal case, the external computer cannot process this volume of information before the user has left the access point. One solution to this problem is to filter out the large number of images in which the iris is not in focus. This means discarding almost 97% of the eye images captured by the system [
15]. In this paper, we focus on one of the first steps of the iris recognition identification system: the detection of the eye/iris image. As reviewed in
Section 2, deep models have been intensively used for solving the eye detection task. To speed up the hardware description process, the CNN can be deployed on the FPGA using the Deep Learning Unit (DPU) proposed by AMD/Xilinx. DPU is a hardware engine dedicated to neural networks. Its strength lies in its ability to accelerate convolutional computation, maximum pooling, full connection and activation function calculation, with configurable parameters. DPU supports classical CNN structures, such as YOLO (You Only Look Once), VGG (Visual Geometry Group), ResNet or MobileNet. In this case, a CNN hardware and software platform for eye detection based on DPU accelerator is synthesised in a Zynq UltraScale+ MPSoC XCZU4EV. Tiny YOLO-v3 eye detection is deployed in the FPGA using DPU. The computational performance and acceleration effect of DPU are analysed. To ensure that only focused eyes are detected, use will be made of the CNN’s ability to support multi-channel inputs. Thus, in addition to the grey level image captured by the NIR sensor, a high-pass filtered image is introduced as a second input channel. The filter used is the one originally proposed by J. Daugman to evaluate whether or not a detected iris was affected by defocus blur [
16] With this input, the trained network discards practically all defocused eyes, which are not detected at all. In our scenario, this means that only 8–9 eyes per person are detected. The implemented system includes frame grabber and eye region detection on a single platform, and can process 87 fps, providing as output only regions containing focused eyes.
The rest of the paper is organised as follows: The state of the art in the topic of eye detection with deep models and of real-time object detection on FPGA-based devices is briefly revised in
Section 2.
Section 3 provides an overview of the whole proposed framework for image capture and eye detection and details about the DPU-based implementation. Experimental results are presented in
Section 4. Finally, conclusions and future work are presented in
Section 5.
2. Related Work
As in numerous other fields of signal processing, many of the basic tasks in computer vision and image processing are currently dominated by the use of deep CNNs. Data condensation and deep training aimed at enhancing the really essential information allow CNNs to extract abstract features, which then achieve excellent results in the classification phase [
17]. This is why, in the specific field of object detection, CNN has become the state of the art.
However, previous work has already glimpsed the potential of neural networks to solve this problem. In the early 1990s, Waite and Vincent [
18] designed a neural network for localising eyes. Briefly, they suggested that there exist eye micro-features (e.g., top and bottom eyelid, and left and right corners) that are invariant, and, therefore, micro-features near image regions can be used to generate a neural network separately. Based on this same scheme, Reinders et al. [
19] proposed the detection of facial features, such as eyes, nose or mouth, in a sequence of images using the magnitude and orientation of the gradient as inputs to the neural network. The proposal searches a target area using different neural networks to combine the results and locate the features. The final output of the neural network is post-processed using a probabilistic method that takes into account the geometric information of the micro-features.
In the iTracker [
20], an end-to-end CNN is trained for eye tracking. They use as input to the model the image of the face and its location in the image (face grid), and the images of the eyes. The model then infers the head pose (relative to the camera) and the eye poses (relative to the head). The CNN is similar to the popular AlexNet [
21]. For real-time inference, additional knowledge is added (face and facial landmark eye detection). Thus, the model can run on an iPhone at 10–15 fps. Sun et al. [
22] described a facial landmark detector using a three-stage cascaded CNN. The first stage of the model provides a raw estimate of facial points, which are refined in the next two stages. Similarly, the model proposed by Huang et al. [
23] uses two-stage cascaded CNNs. The first stage performs eye landmark detection and eye state estimation. Multitask learning is employed to obtain good initial eye positions. The second stage refines the eye positions. The model proposed by Nsaif et al. [
17] also follows a multi-mission learning scheme, where Faster R-CNN (region-based CNN) is used to detect the initial eye regions, and Gabor filters and a naïve Bayes model is employed for fine-tuning these positions. The R-CNN was proposed as an accurate object detector by Girschick et al. [
24]. In summary, the R-CNN takes an input image and firstly obtains bottom-up region proposals via selective search (SS). The image region in each window is warped to a fixed size, and a pre-trained deep network is used to compute features for each window. Then, it classifies these regions using class-specific linear SVMs (Support Vector Machines) trained on these features. As a major disadvantage, it applies the deep CNN for feature extraction repeatedly to all windows in the image, which is a hard timing bottleneck [
17]. To reduce the cost of the R-CNN, convolutions can be shared across region proposals. For instance, adaptively sized pooling (Spatial Pyramid Pooling network) SPP-Net [
25] extracts the feature maps from the whole image only once, and then it applies the spatial pyramid pooling on each region proposal (of the feature maps) to pool a fixed-length representation of this proposal. Thus, the SSP-Net extracts features from regions of the feature maps and not directly from image regions. It only applies the time-consuming convolutions once. The Fast R-CNN conducts end-to-end training on shared convolutional features [
26]. It takes as input the whole image and a set of object proposals. The entire image is then processed with several convolutional and max-pooling layers to obtain the feature map. For each region proposal, a fixed-length feature vector is extracted from the feature map. These feature vectors are fed into a set of fully connected layers that finally branch into two output layers: one of them provides the probability estimate over the set of object classes, and the other one provides the refined bounding-box of the object. Surprisingly, these methods strive to speed up the feature extraction process but do not consider the problem of the initial proposal of regions, which is completely detached from the CNN. This causes the bottleneck to be in this initial phase. To avoid this problem, Faster R-CNN is proposed [
27]. Faster R-CNN consists of two modules: a deep CNN to propose regions (the Region Proposal Network, RPN), and a Fast R-CNN that uses these regions. Both modules are not independent, but are intimately tied together, as the whole system is a unified network for object detection. Faster R-CNN was implemented on AMD/Xilinx
® Zynq
®-based FPGA using Python productivity for Zynq (PYNQ) [
28]. The pre-trained model (Faster RCNN + Inception v2) was implemented using TensorFlow Application Programming Interface (API). Specifically, the model was implemented in an AMD/Xilinx
® Zynq
® ZCU104 FPGA (XCZU7EV-2FFVC1156 MPSoC), and the inference time was 58 ms (17 fps). The authors argue that this inference time is comparable to the one provided when testing in an i7 Intel
® core CPU [
28].
Other popular CNN-based object detectors do not consider the initial existence of a set of region proposals. In 2016, YOLO was proposed by Redmon et al. [
29]. The goal is to accomplish the detection procedure as well as to estimate class probabilities and bounding boxes from full images in only one evaluation. YOLO uses a straightforward scheme based on regression to predict the detection outputs [
29]. Since its creation, YOLO has evolved through many iterations (YOLOv1, YOLO9000, YOLOv3, PP-YOLO, etc.). The Single Shot MultiBox Detector (SSD) [
30] and the CornerNet [
31] are other examples of regression-based approaches. This single-shot scheme has been preferred for FPGA implementation. To reduce off-chip accesses, Nguyen et al. [
32] proposed to retrain and quantise the parameters of the YOLO CNN using binary weight and flexible low-bit activation. Using a Virtex-7 VC707 FPGA device and 416 × 416 size images, they are able to process 109.3 fps. Nakahara et al. [
33] proposed a light-weight YOLOv2, which includes a binarised CNN for feature extraction and parallel support vector regression (SVR) for predicting the detection outputs (class estimation and bounding box prediction). To reduce the computational complexity of SSD, Sandler et al. [
34] proposed to use as base network of SSD the MobileNetV2 mobile architecture, as well as to replace convolutions by lightweight depthwise separable convolutions. The so-called SSDLite was implemented on FPGA by Kim et al. [
35], achieving a relevant frame rate of 84.8 fps when implemented on Intel Arria 10 FPGA. Building on the Tiny YOLO, the proposal by Preußer et al. [
36] makes use of the computational opportunities provided by the Zynq UltraScale+ platform in the Programmable Logic (quantisation of the input and output layers to eight-bit fixed-point values and binarised input layers), but also in the Processing System (multi-threading and NEON vectorisation). Wang et al. [
37] designed and implemented a hardware accelerator based on the YOLOv3 network model. They make intensive use of Vitis AI to reduce the network scale and decrease the access time to off-chip memory. Using a Xilinx Zynq ZCU104, they reported a maximum frame rate of 206.37 fps (but they do not work with a video stream, but first read a large-size image into the memory). But one of the most widely used versions in its transfer to FPGA has been the Tiny-YOLOv3 [
38]. Li et al. [
39] improve this algorithm by increasing from two-scale to three-scale detection, and merging the batch normalisation layer with the convolution layer. Zhang et al. [
40] mapped the Tiny-YOLOv3 structure to the FPGA and optimised the accelerator architecture for Zedboard to make it run with very limited resources. To reduce the memory size and improve the speed, YOLOv3-tiny was compressed via a model quantisation method [
41]. Specifically, the trained model was quantised with 8-bit fixed-point and implemented on a Xilinx Ultrascale+MPSoC ZCU102 board. They showed that the memory size of the model decreased from 33.1 MB to 8.27 MB. The process can distinguish between two traffic signals in real time (104.17 fps). Velicheti et al. [
42] also evaluated multiple precision of Tiny-YOLOv3 (FIXED-8, FIXED-16, FLOAT32). As a comparison with the standard version of YOLOv3, Esen et al. [
43] reported a frame rate of 41.1 fps when running the model with images of size 224 × 224 on the ZCU102 board.
Instead of modifying the parameters/algorithm of the network models, another option is to codesign the model and hardware architecture together. Ma et al. [
44] proposed a hardware implementation of the SSD300 algorithm based on replacing dilated convolutions and convolutions associated with a stride of 2 with convolutions with a stride of 1, using fixed-point arithmetic, and employing dynamic quantisation to retain the detection accuracy of floating-point representation. Hardware/software codesign was employed to accelerate Tiny-YOLOv3 by designing a hardware accelerator for convolution [
45]. Suh et al. [
46] presented an energy-efficient accelerator on a resource-constrained FPGA. They trained the VGG-based SSD using a uniform/unified quantisation scheme (UniPOT) and optimised the DSP/memory utilisation employed dual-data rate DSP design to double the throughput, and reduced DDR latency aided by DMA descriptor buffer design.
3. Methodology
The proposed system for person identification via iris recognition consists of an iris image capture and processing unit that is located on a pole, facing an arch or access point. The optics and sensor employed by the system allow the capture of iris images focused at about 1.7 m from the pose location. The exposure time is very low and allows motion blur to be ruled out when the person walks at a normal speed (1–2 m per second). However, the depth of field is very shallow (only about 10–15 cm), so to ensure that a focused image is captured the system is forced to work at the maximum speed of the image sensor used (a Teledyne e2v EMERALD 16MP, which provides up to 47 fps).
Figure 1 (Left) illustrates the layout of the application scenario. The pole includes both the sensor and the capture and processing system, as well as the lighting (51 W using high-power LEDs). If the distance between the sensor and the subject is increased, or decreased, the optical parameters of the system (mainly the focal length of the lens) must be adjusted to maintain the capture resolution (a minimum of 200–250 pixels/centimetre) and to increase, as far as possible, the depth of field. The capture and processing system is connected by cable to a computer with an i9 Intel
® processor, which is responsible for extracting the normalised iris pattern and comparing it with the database to close the identification. These tasks are outside the scope of this article.
The design attempts to make the image available for processing as quickly as possible. Since the image capture is done with a custom frame grabber implemented in the logic part of the FPGA, the most optimal way to implement the image processing is for it to be carried out in the FPGA itself. Thus, as the image pixels are read, they can be processed. In cases in which a GPU is used for processing, a communication channel with the frame grabber would have to be defined to reduce latency. Options such as AMD’s DirectGMA or NVIDIA’s GPUDirect require a PCIe bus to which both devices are connected. In our case, the embedded device does not require a CPU or the existence of such a bus. Embedding the processing in the FPGA reduces weight and power consumption, and the computational power of the FPGA is comparable to that of the GPU as previous work has demonstrated [
33,
47,
48].
Figure 1 (Right) shows the capture and processing unit deployed on the pole. The purpose of this unit is to capture a video stream of the person passing the access point from which the focused images are filtered and the regions of interest (ROIs) are detected and cropped from the input image, those ROIs contain the eye images that will be sent to the external PC to be processed. The unit is built around a commercial AMD/Xilinx Ultrascale+ module (the TE0820-03-4DE21FA micromodule from Trenz) and the EMERALD 16MP from Teledyne e2v. The interface between these two modules is provided by two carrier boards. The main features of the TE0820-03-4DE21FA are summarised in
Table 1. The TE0820-03-4DE21FA is an industrial-grade MPSoC module integrating an AMD/Xilinx Zynq™ UltraScale+™ ZU4EV, 2 GByte DDR4 SDRAM, and 128 MByte Flash memory for configuration and operation.
The EMERALD 16MP features a small true global shutter pixel (2.8 µm) and a reduced DSNU (Dark Signal Non-Uniformity) value. Both features are adequate for our application scenario (low-light context due to a small exposure time and a reduced aperture).
Table 2 summarises the relevant features of the EMERALD 16MP sensor.
Previous work has solved the problem of real-time eye detection using a modified version of the popular algorithm proposed by Viola and Jones [
49]. This implementation is very fast, and allows the eye images to be obtained at the required speed [
50]. The problem is that the system provides many false positives, which saturate the subsequent recognition module. Many of these false positives contain out-of-focus eyes, which could be discarded by a blur estimation module [
15], but others are associated with regions that do not contain eyes. The biggest problem with this approach lies in scalability and adaptability. Any change involves rewriting the FPGA cores, which is time-consuming and unsuitable for scalability. On the other hand, the use of DPUs allows for faster development since, once the DPU is implemented in the design, it is easy to implement different models of CNNs. Furthermore, the system can be reused to detect different objects besides the eye, e.g., detecting the mouth to detect a yawn in a driver drowsiness detection scenario. It can be easily retrained if problems are detected at a late stage of development, and allows for model comparison, which helps to optimise and find the best solution.
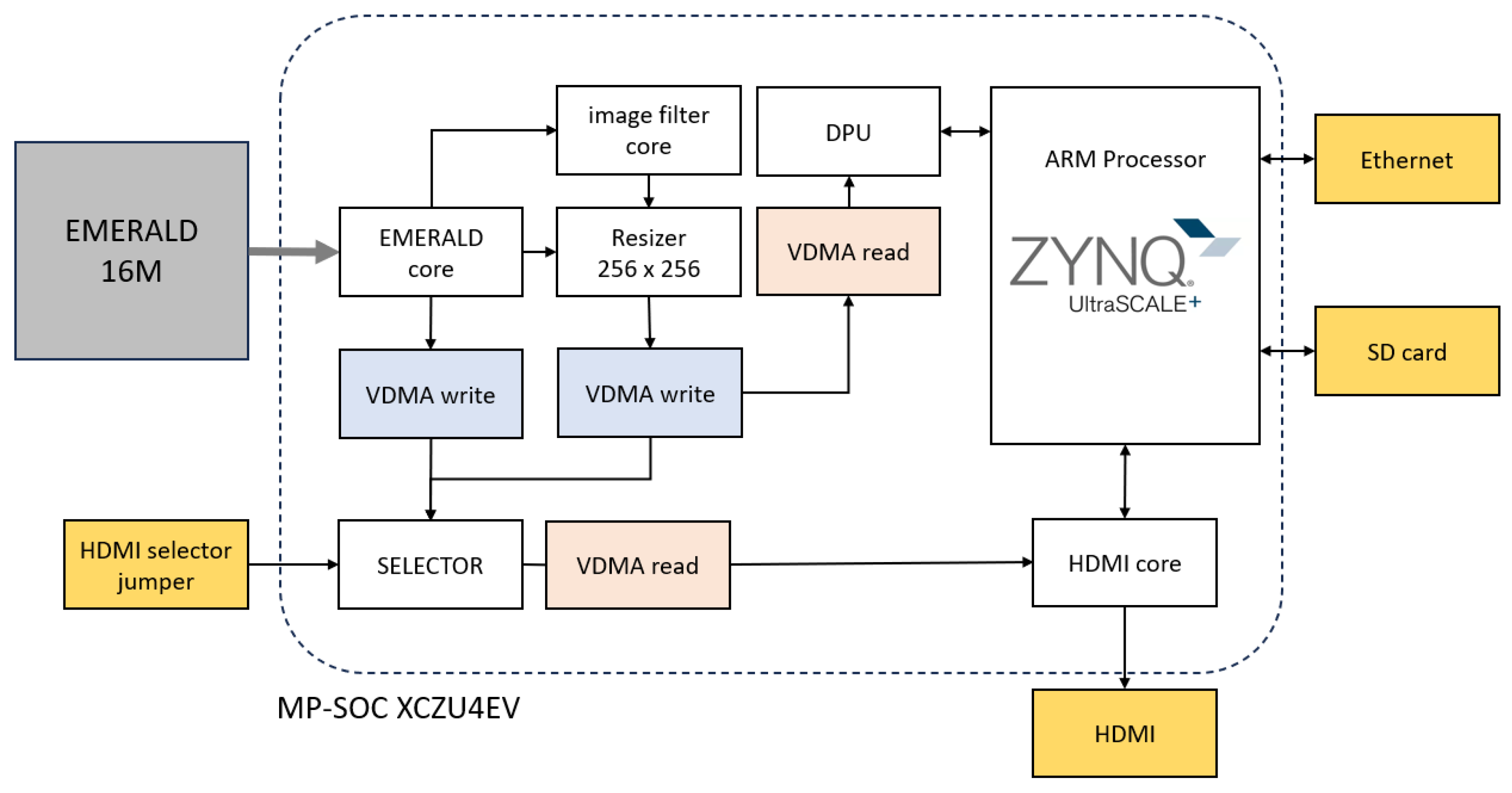
Figure 2 shows the architecture for deploying the CNN-based eye detection flow on an MPSoC-based platform. The input images come from the EMERALD 16M sensor. Although the images are captured, and stored in DDR memory, in their original size, for processing they are reduced to a size of 256 × 256 pixels. Previous work has shown that eyes are accurately detected despite this reduction in resolution [
15,
50]. These scaled images are made available to the DPU using VDMA. But the system will receive a multi-channel input, where in addition to the input image in grey levels, a second channel will include a high-pass filtered version.
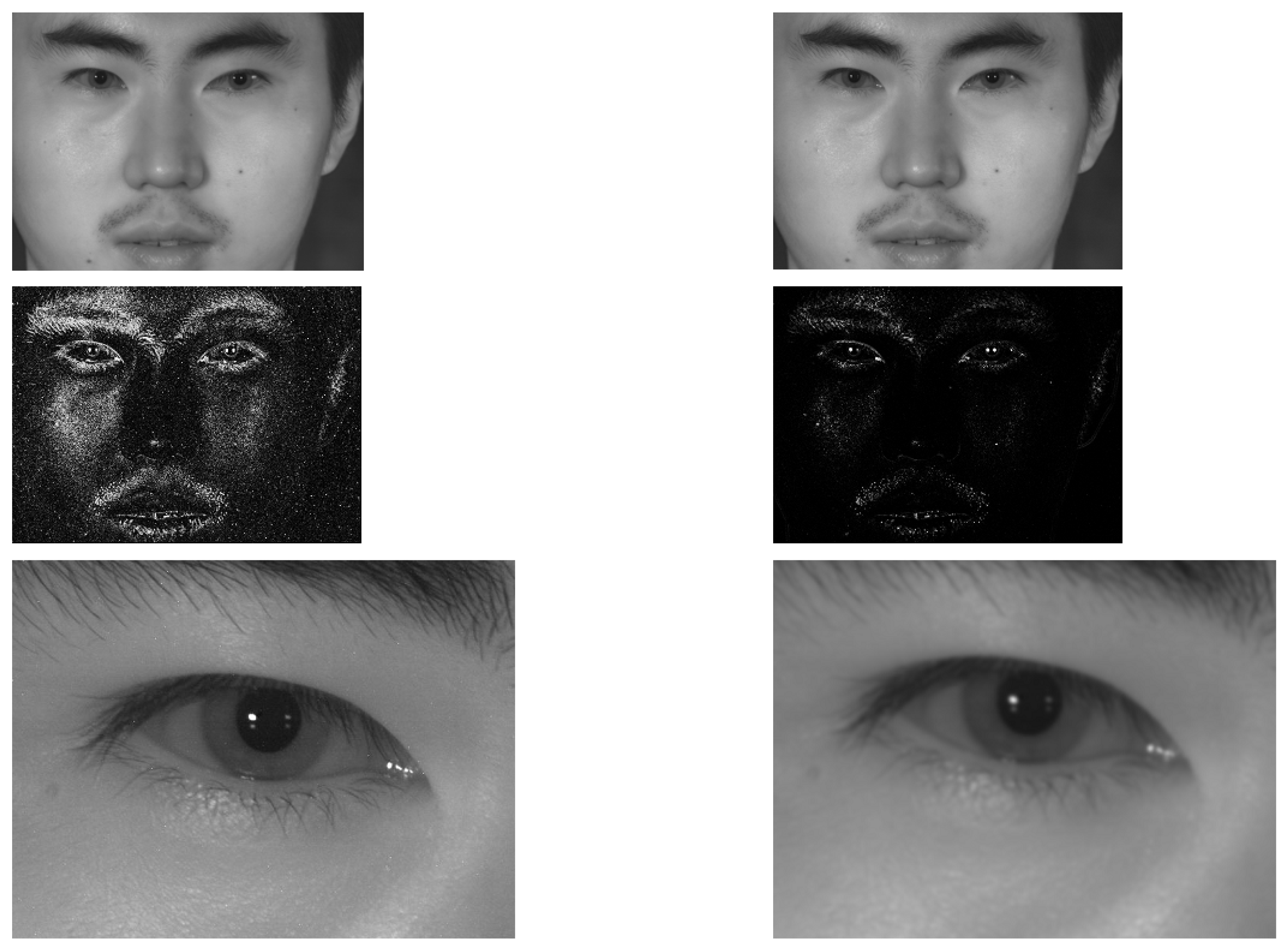
Figure 3 provides an example of what these filtered versions look like, both for a focused image and an out-of-focus image. The grey level images in the top row show little difference, so if you train the network with them, you will have an in-focus or out-of-focus eye detector. The purpose of adding the high-pass filtering features is to verify whether they allow out-of-focus eyes to go undetected. The DPU is in charge of deep learning acceleration. The DPU requires instructions to implement the network, which are prepared using the Deep Neural Network Compiler (DNNC) and Deep Neural Network Assembler (DNNAS) tools. The scaled image can be monitored via HDMI for verification. The detected eye regions are managed via the Processing System (PS) of the MPSoC. Briefly, the system must rescale the coordinates of the detected eyes to crop high-resolution versions of the original 4096 × 4096 pixel images.
3.1. The DPU IP Core
Parallelism and ease of programming are possibly the features that justify the use of FPGA to accelerate CNN inference [
51]. To synthesise the CNN on the FPGA, two options can be used: describe the hardware circuit directly using Hardware Description Language (HDL), or describe it using a high-level language (such as C/C++, System C or Matlab) and use the High Level Synthesis (HLS) tool to generate, from this high-level code, the HDL version. Possibly, the first option is more suitable, but it is also more time-consuming [
52]. HLS can help the designer, typically more familiar with the use of high-level languages, by allowing to speed up the writing of the code. Furthermore, apart from aiding development from a design, HLS allows the verification of this design to be more efficient as well, as it can be carried out with a high-level language simulator, rather than an HDL simulator. Unlike an HDL simulation, the high-level verification does not have to simulate every clock edge, so it is much faster. If the high-level verification is successful, the HLS tool ensures that the generated HDL version corresponds to this description and therefore its functionality will be equivalent. This tool has been used extensively in the design of the cores that make up our proposal.
Despite attempts to synthetise the functional layers of the CNNs into pure FPGAs, most current work advocates the design of heterogeneous architectures, which make use of the FPGA but also the CPU. These platforms, such as the Xilinx Zynq SoC, allow a balance to be struck between performance and the flexibility needed to handle the different layers of the CNN. In our case, our aim is to implement the CNN in the programmable logic (PL) of a XCZU4EV AMD/Xilinx Zynq UltraScale+ MPSoC. To further accelerate the process of designing and synthesising a CNN in the logic part of the MPSoC, use will be made of the AMD Deep Learning Processor Unit (DPU) [
11]. The DPU is a programmable engine, offered by AMD for Zynq-7000 SoC and Zynq Ultrascale+ MPSoC devices. It consists of a Computing Engine, an Instruction Scheduler, and an On-Chip Buffer Controller (see
Figure 4). After start-up, the DPU fetches instructions and decoders via the Fetcher and Decoder modules from the off-chip memory to control, using the Dispatcher, the operation of the Computing Engine [
51]. There is a specialised instruction set for DPU generated via the Vitis™ AI compiler, which enables DPU to work efficiently for many CNNs (VGG, ResNet, GoogLeNet, YOLO, SSD, MobileNet, FPN, etc.). The On-Chip Buffer Controller manages the on-chip memory to store data (buffer input activations, intermediate feature maps, and output meta-data). To reduce off-chip memory bandwidth, it reuses data as much as possible. The Computing Engine implements a deep pipelined design for convolution computation, where the PEs (Processing Elements) take full advantage of fine-grained building blocks in the AMD/Xilinx device for constructing multipliers, adders, etc. The DPU is implemented in the programmable logic (PL) and is integrated with the processing system (PS) using an AXI interconnect.
In our case, the DPU targeted reference design provided by Vitis AI 3.0 was implemented with AMD Vitis for the TE0820-03-4DE21FA board. The B1600 configuration of the DPU was synthetised with default settings (Low RAM Usage, Channel augmentation disabled, Save argmax enabled).
Table 3 shows the resource utilisation. The operating frequency of the DPU was 150 MHz. Petalinux 2021.2 was used to generate a Linux OS image for the TE0820-03-4DE21FA. The CNN application running on the DPU was generated as described in
Section 3.2.2.
3.2. Generation of the CNN Model
3.2.1. YOLO Version 3 Tiny
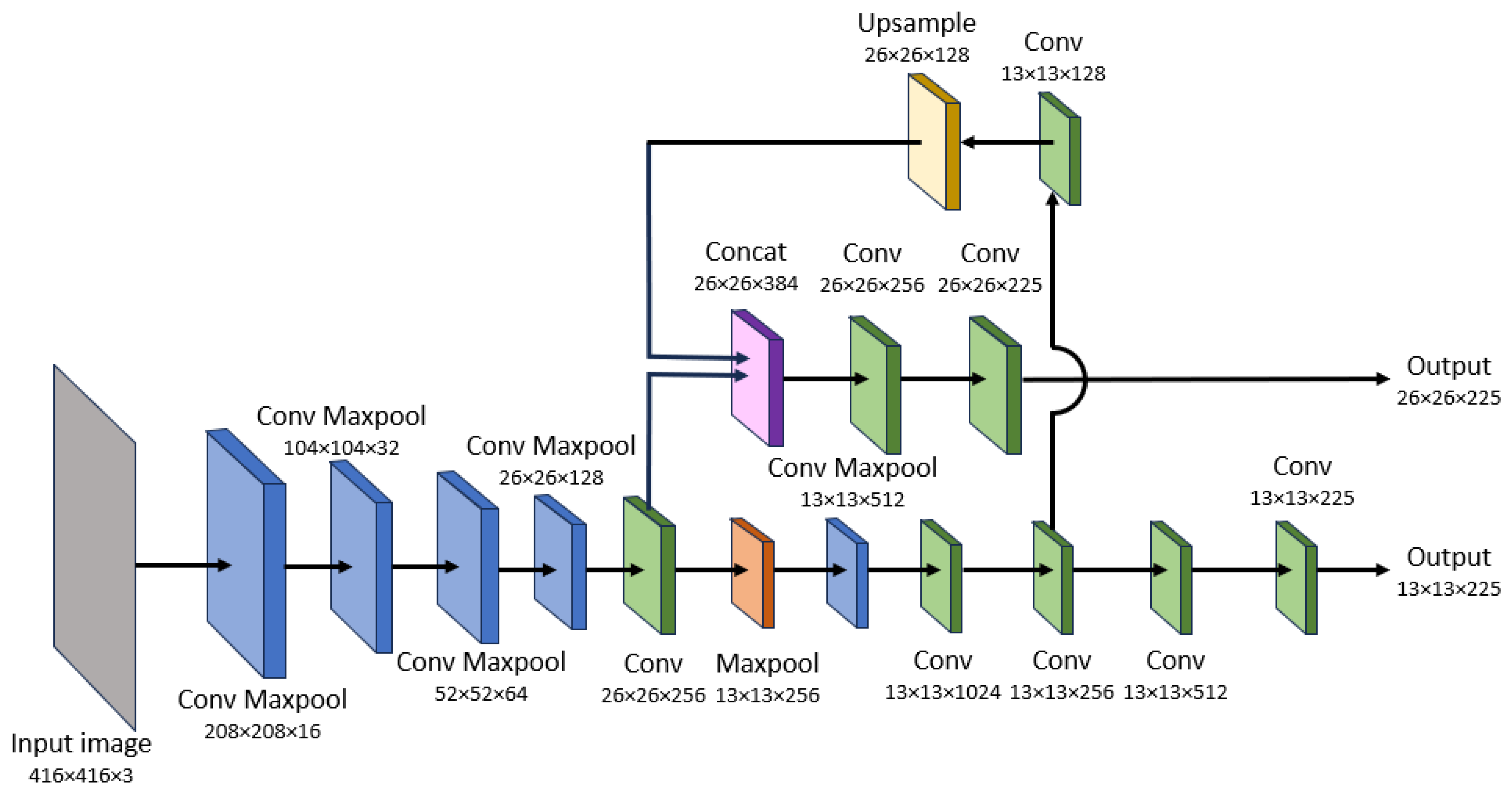
The Tiny YOLO-v3 was proposed by Joseph Redmon to reduce the complex network (107 layers) of YOLO-v3 [
53]. The aim is to increase the detection speed, providing a network that can be executed in real-time when running in an embedded board. Briefly, the Tiny YOLO-v3 divides up the image into a grid. Then, it predicts a three-dimensional tensor containing objectness score, bounding box and class prediction at two different scales (dividing the image into a 13 × 13 grid and a 26 × 26 grid). Bounding boxes without the best objectness scores are ignored for final detections.
Figure 5 shows the complete architecture of the network. Instead of using Darknet-53 as YOLO-v3 does [
53], the architecture is based on a seven-layer standard convolution structure. In its original version, the input image is 416 × 416 pixels in size. After ten convolutions and six max-pooling operations, the output feature maps have a size of 13 × 13 units. In addition, the feature map after the eighth convolution is convolved and upsampled to obtain a size of 26 × 26 units. This map is concatenated with the result of the fifth convolution and convolved to obtain a second output of size 26 × 26 units. Both output feature maps, at two different scales, contain the prediction information about objects. The reduction in FLOPS and model size with respect to YOLO-v3 is very significant [
40,
41,
54], allowing it to run on embedded devices. Although some authors point out that this structure cannot extract higher-level semantic features, so its accuracy is lower [
41], in our application framework, in which only complete eyes of a certain size are to be detected under the same lighting conditions, the network has proven to be efficient and accurate.
3.2.2. Neural Network Training
Darknet [
53] is an open source framework created by Joseph Redmon, used primarily for the implementation and creation of convolutional neural networks. Darknet makes use of CUDA to take full advantage of the power of GPUs to accelerate the required computations. The CUDA architecture allows C/C++ developers to interface directly with Nvidia GPUs. This allows them to take advantage of the massive parallelism and computational power of these platforms, performing complex tasks in less time and processing large volumes of data more efficiently. In addition, this framework is responsible for doing all the image pre-processing, rescaling the images to the size of the neural network input and normalising the pixels to have a smaller scale ([0, 1] instead of [0, 255]) and thus achieving greater numerical stability that will lead to greater convergence. Once Darknet is installed, the weights of the Tiny YOLO-v3 neural network are downloaded, the configuration file is modified so that it can be trained with Darknet and the network is trained using a training and validation dataset.
CASIA-Iris-Distance v4 images were used to train the network. These images show a frontal image of the person’s face with lighting conditions that are very similar to those in our scenario (see
Figure 6). Images were captured indoors, with a distance close to 2 m, and using a self-developed long-range multi-modal biometric image acquisition and recognition system (LMBS). The illumination used is near-infrared. The eyes present in the 2567 images were manually labelled. All these eyes are correctly focused, in order to condition the subsequent operation of the detection process, and not to detect unfocused eyes.
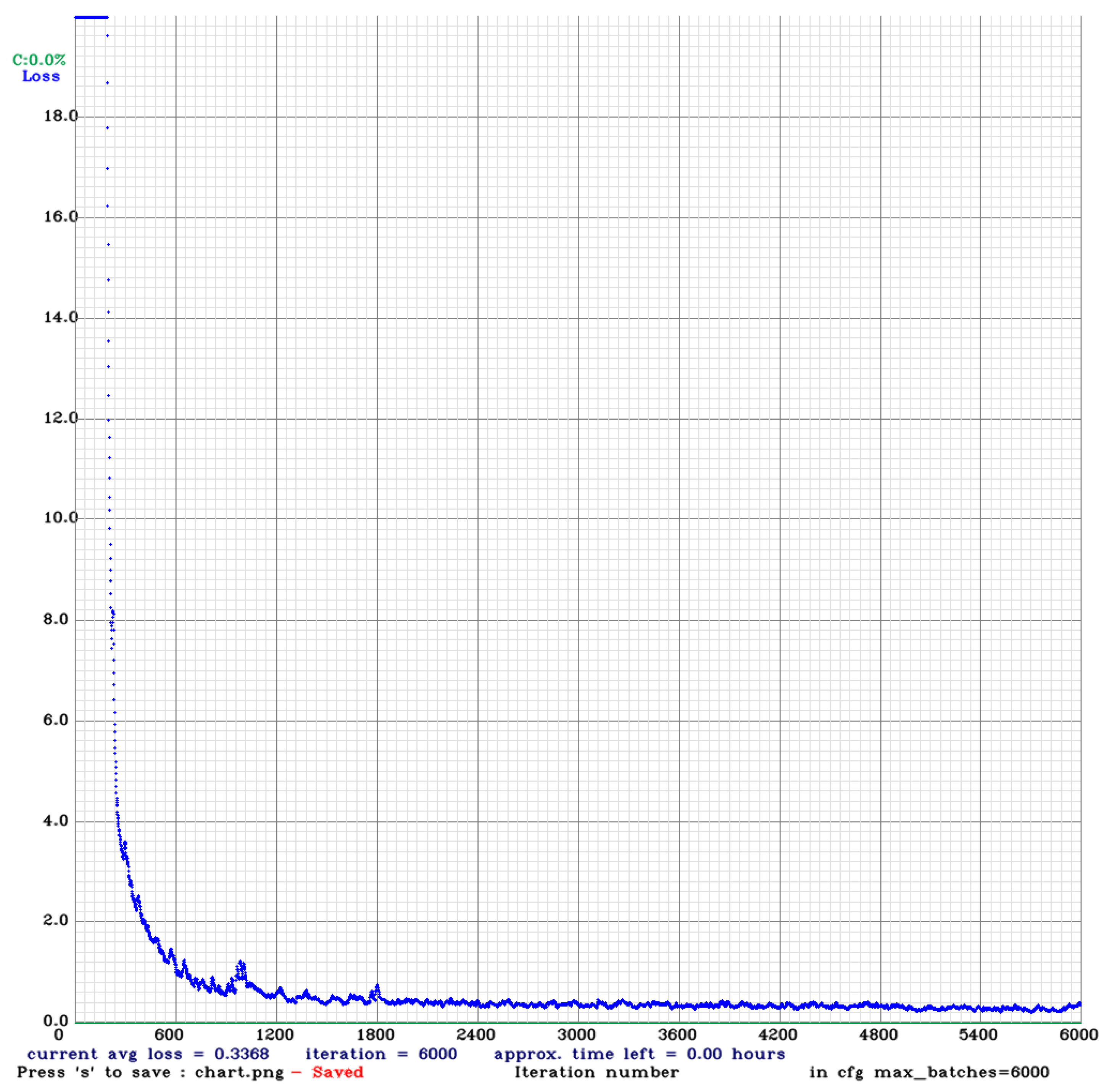
The neural network was trained over 6000 iterations. This value is the minimum set by the YOLO-v3 guidance since there is only one class to be detected (2000 iterations for each type of object to be detected with a minimum total of 6000). The training loss curve is shown in
Figure 7.
Once the network was trained, several inference tests were performed on images that were not taken into account during training. In all cases, eyes that were in focus were correctly detected. This point is significant: the network does not detect out-of-focus eyes. As intended by this proposal, this allows it not only to detect eyes, but also to discard those that are not in focus. In a system that works with moving people, where up to 250 eye images can be captured in 2–3 s, being able to discard invalid eye images is really necessary [
15]. In this implementation, it will therefore not be necessary to include a defocus blur estimation module in the system.
Because the Vitis AI toolchain only supports TensorFlow and PyTorch models, once the network had been trained, the set of weights was converted to TensorFlow files using the keras-YOLOv3-model-set software (
https://github.com/david8862/keras-YOLOv3-model-set (accessed on 3 September 2023)). This converter takes the Darknet weights and configuration file to create the equivalent TensorFlow network from the provided data. Finally, once we have the weights in Tensorflow format we must define the network graph in a single file (freeze_graph,
https://github.com/tensorflow/tensorflow/tree/master (accessed on 10 September 2023)). The model is not ready yet since it uses float values which are not suitable for the DPU; therefore, a quantisation process is carried out to convert those 32-bit floating-point arithmetic values with 8-bit fixed-point; this is achieved by means of the vitis AI tools via a quantisation process.
The DPU cores are flexible with the implementation; there are many options such as the multiply–accumulate operations, memory usage, activation functions and softmax core, among others. This means that the model must be compiled taking into account the implementation details of the deployed DPU core. In Vitis AI, both the architecture of the machine learning model and the weights and parameters needed to perform inference on the hardware platform are encapsulated in an xmodel file extension. To generate it, the steps of the Vitis AI workflow must be followed. Specifically, the deployed DPU has an identification code denominated fingerprint in the form of a file arch.json, which is generated via the Vivado synthesising tool. This file is used to encode all the properties of the deployed DPU so the compile model can make use of all the available resources within the core, resulting in a highly optimised DPU instruction sequence and any operation that is not available on the DPU is carried out by the CPU.
4. Inference Results
The entire framework was validated with images captured in a real-life scenario in order to assess its ability to detect focused eye images. When the input image size of 416 × 416 is maintained, the system detects eye regions in focus, discarding most of the regions containing out-of-focus eyes (at a rate of close to 100%). However, the processing rate is relatively low (29 fps). In any case, it is lower than the fps provided by of the EMERALD sensor (47 fps). To increase this frame rate, the size of the input image of the YOLO network can be decreased. For a size of 352 × 352 the speed increases up to 39 fps. If we decrease this size to 320 × 320, the system is able to process 44 fps, a value very close to the frames per second provided by the sensor. In previous work, the sensor input image was rescaled to a size of 256 × 256 pixels [
15,
50]. With this size, for example, these previous implementations using a modified Viola Jones classifier achieved 100% positive detections in the CASIA-Iris-Distance v4 database. When the size of the input image is rescaled to this size, the YOLO processing speed increases to 87 fps. The system correctly detects regions with in-focus eyes, but discards regions with out-of-focus eyes to a much lesser extent (see
Figure 8). It must be noted that, in order to compare the results obtained when using one or the other input image size, the sequences were recorded and then all the frames were processed one by one to obtain the detections.
A measure of Mean Average Precision (mAP) can be used to evaluate the neural network. The mAP provides a quantitative measure of the detection accuracy, considering both the localisation accuracy and the classification accuracy of the detected objects. In our case, using frontal face images with correctly focused eye regions as a validation database, the mAP is 100% for input images of 256 × 256 pixels (
Figure 9). That is, in these images, all eyes are correctly detected. It is important to note that we only have one class, that the correctly focused eyes in our scenario are always the same size, and that the lighting conditions are always the same. For input images of 416 × 416 pixels, the mAP is reduced to 95.31%.
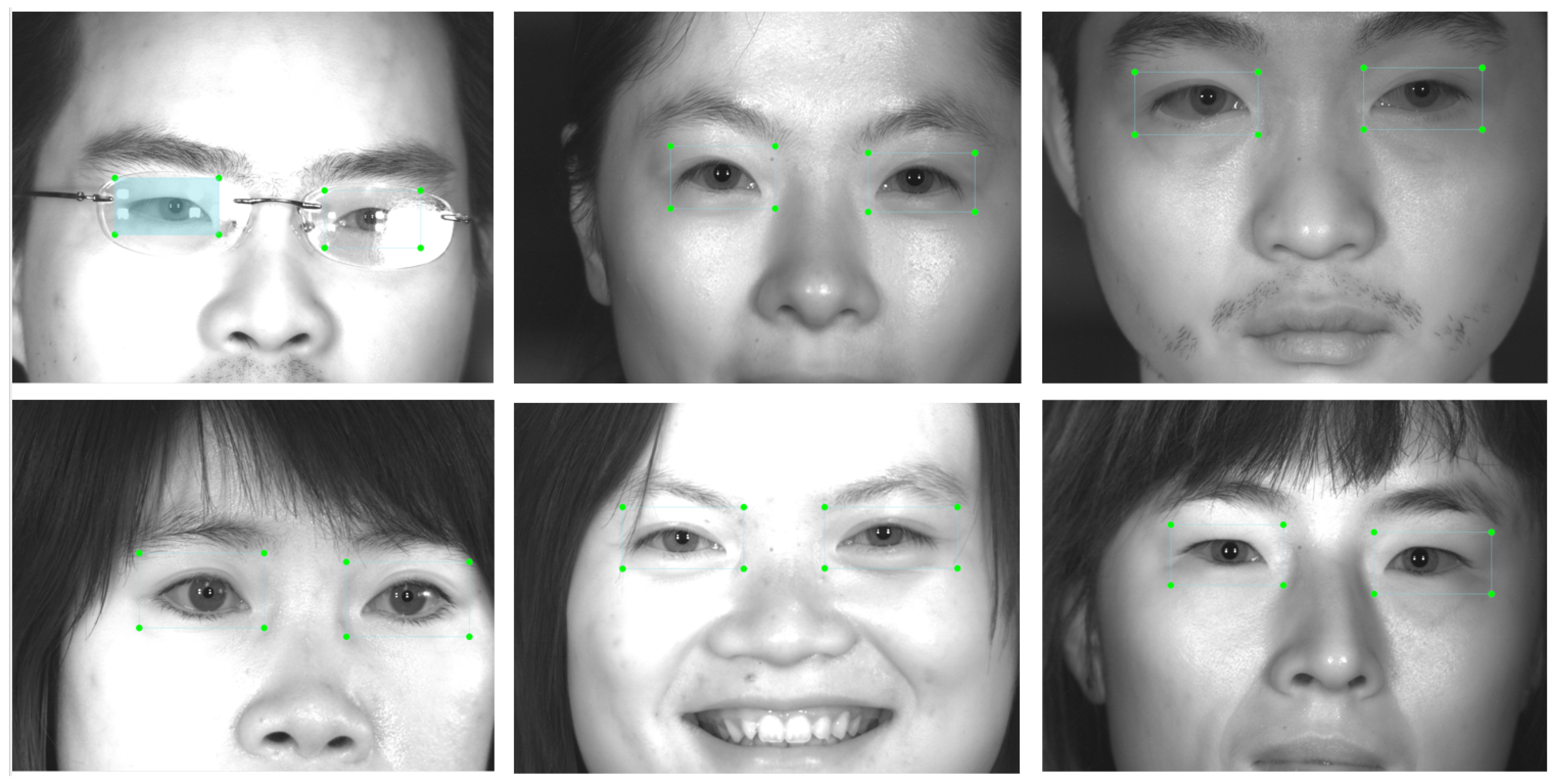
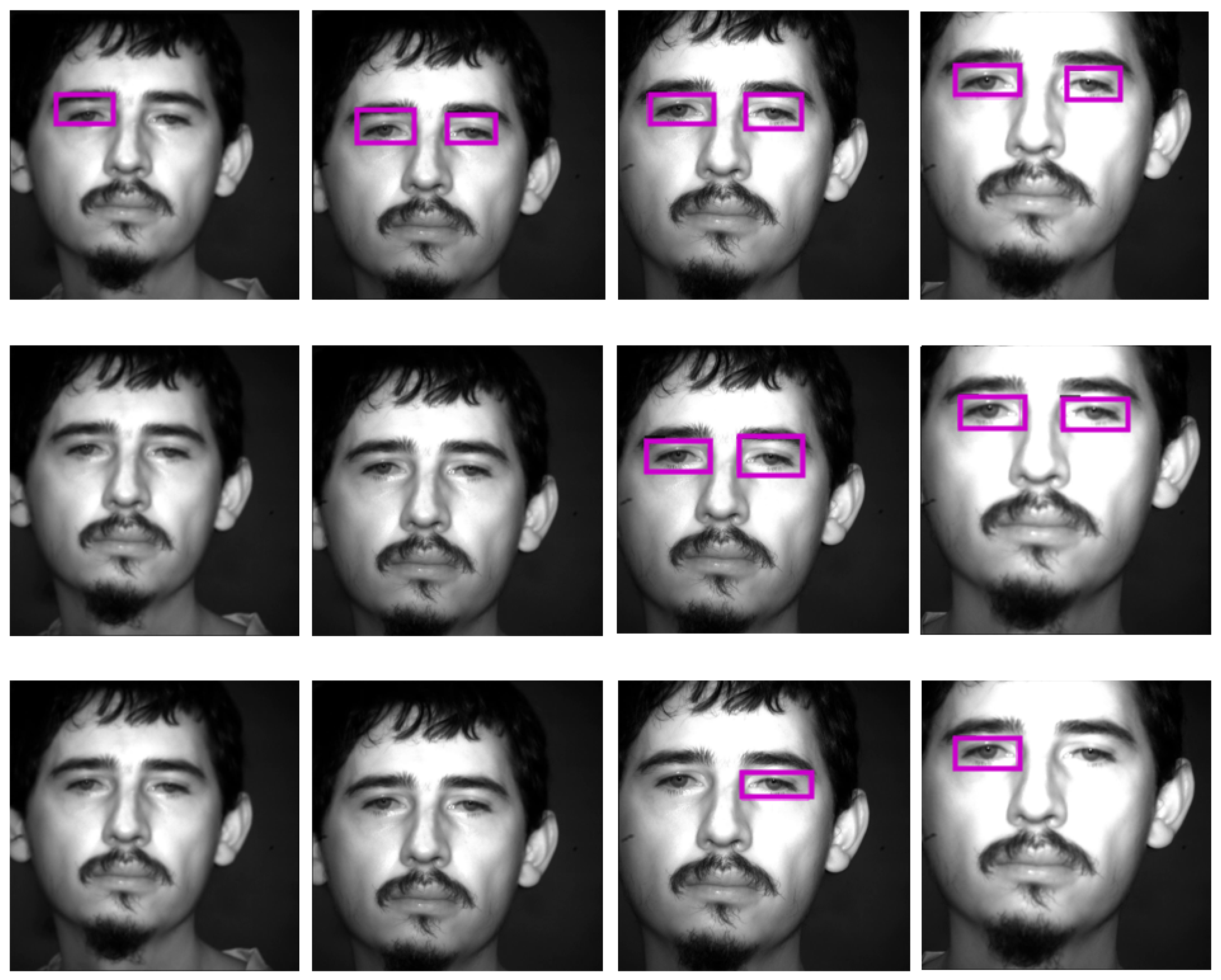
Finally, the proposal’s ability to handle faces of individuals of diverse races and ages was evaluated using the Flickr database [
55]. The detected eyes are not valid for recognition, and the images are not NIR but have been captured in visible light. However, the method is able to detect the eyes without problem.
Figure 10 shows several eye detections in images from this database. It is important to note that the proposed method has problems detecting eyes in non-frontal faces, or in faces where hair partially covers the iris. In both cases, even if the eyes were detected, it would be difficult to use them for recognition.
Comparison with Prior Work on Eye Detection
In order to compare the results provided by this proposal with respect to other approaches in the literature, only 20% of the CASIA-Iris-Distance v4.0 database has been used to retrain the network and the remaining 80% as a test set. The scheme is similar to that used in previous proposals, which allows for comparison of the results.
Table 4 shows the results obtained via different methods using this same database for training and evaluation. Except for our previous proposal [
50] (which also runs on a Ultrascale+ XCZU4EV micromodule), all these proposals run on an Intel i7-7700 CPU at 3.6 GHz, using an NVIDIA GeForce GTX 1070 (1920 CUDA cores and 8 GB of memory) and 16 GB of memory [
17] In the table, we compare methods that are not based on Deep Learning techniques, such as Uhl and Wild’s proposal [
56], which detects faces and eyes, and Ruiz-Beltran et al. [
50], which focuses only on eye detection, both based on the original proposals by Viola and Jones [
49] and Lienhart and Maydt [
57]. The other three methods in
Table 4 are CNN-based proposals. As described in
Section 2, these approaches implement algorithms that propose initial regions in which to locate the eyes. Faster R-CNN [
27] introduces a Region Proposal Network (RPN) that shares the convolutional features of the full image with the detection network, allowing them to perform region proposals at almost no cost. Briefly, this RPN component informs the network where to look. This attention scheme is also found in FR-CNN-NB and FR-CNN-GNB [
17]. The FR-CNNN-NB employs Faster R-CNN to extract the features and obtain a first estimate of the position of the eyes, which is then enhanced using a Bayesian model. The FR-CNN-GNB complements the previous proposal with the use of Gaussian filters (FR-CNNN-GNB).
To conduct these tests, our design must read the images from the SD card present in the hardware design. As described in Ruiz-Beltran et al. [
50], the loading of the image into the frame buffer is carried out by the ARM (PS part), which is also responsible for managing the execution. The frame rate that can be processed per second is computed by adding specific video analysis cores in the design. As proposed by Ruiz-Beltran et al., the video channel rescales the image to a size of 256 × 256 pixels. It is important to note that all other methods work with the original size of the input images (2352 × 1728 pixels).
The results obtained (100% success rate) may indicate that the model is too complex for the problem we are solving (overfitting). The success rate in the CASIA v4 Distance dataset is very high, but it should be noted that it is the same as that obtained in the real scenario. In the dataset images, all the eyes present are correctly focused and therefore detected. In the tests carried out with the system deployed in the real environment, not a single focused eye image was not detected. However, the system has an error rate associated with the detection of eye images that, because they are out of focus, are not useful for recognition. This is a low rate (5–6 eye images per person passing through the system) and totally acceptable. As mentioned above, in this system, it is not possible to fail to detect eye images that are in focus. Significantly, the results are very similar to those obtained by Ruiz-Beltrán et al. [
50], with the advantage that the use of current deep learning techniques allows for greater ease of training and the possibility of extending the system, if necessary, to detect facial features other than the eyes. In addition, the eye detection process is more robust.
Figure 11 shows in its top row the detections using the first method. False detections, caused in part by artefacts created by the normalisation in brightness, can be seen, which should be discarded by the iris extraction system. The method detects all eyes that appear in the input sequence. The bottom row shows the results obtained via the proposed method. The eyes are correctly detected and there are no false positives.
5. Conclusions and Future Work
To facilitate the deployment of a remote identification system based on iris recognition, it is important to minimise the weight and power consumption of the devices, while preserving efficiency in terms of processing speed and performance. Furthermore, given the large number of eyes that can be detected, and in order not to saturate later stages of the system, it is important that the device only detects, as far as possible, those images that contain focused eyes. This paper describes the implementation of a complete framework for detecting correctly focused eyes, synthesised in an MPSoC and designed to meet the constraints of remote iris recognition. The framework includes all hardware cores for image resizing, eye detection based on the Tiny-YOLO v3 network and final cropping of the eye images from the original input image. In order for the system to discard images of eyes that are not correctly focused, a simple but effective scheme has been proposed. Basically, the idea is to use as input to the system not only the captured image, but also a high-pass filtered version of it. As pointed out by J. Daugman [
16], the effect of defocusing is mainly to attenuate the higher frequencies of the image. Tests show that, when this information is considered in the training and classification steps, the designed system detects only focused eye images. Like the rest of the system, the proposal has been correctly integrated into the hardware synthesised in the MPSoC.
The proposal has been extensively evaluated in a real working environment, with hardware selected (or custom designed) for this scenario. The system has demonstrated its ability to capture at a distance the eye images of moving people, discarding those affected by defocus blur. In the original input images captured by the sensor, the eye is relatively large, allowing the system to behave correctly when the input image is reduced to 256 × 256 pixel size. In fact, when both accuracy and speed are used as key factors in determining system parameters, the 256 × 256 input image size provides the best results. Thus, this size provides an accuracy of 100 percent on the validation database (images captured by the system itself) and a processing speed of 87 fps. While it is true that the system occasionally detects eyes that are not correctly focused, the set of unfocused images that are discarded exceeds 95% of the eyes that appear in the input images. Since not a single focused eye should be missed, it is preferable that the system admits a certain amount of false positives (unfocused eyes) but maintains the referred 100% detection of true positives (focused eyes). In summary, the proposed device functions as a smart camera, returning as output images of 640 × 480 pixels that include captures of the eyes in correct focus.
Future work aims to embed the later stages of the iris recognition system (iris segmentation and normalisation) in the MPSoC. Regarding the eye region detection system, the next steps will involve training the network using images captured by the system itself, and evaluating the possibility of using a DPU that processes more multiply–accumulate operations (MACs) per clock cycle (B2304 or B3136), for a faster network, which could work with image sensors that provide more images per second than the one currently deployed in the system. In addition, we are currently addressing the problem of detecting the presence of textured contact lenses using binarised statistical image features (BSIFs) and a set of three support vector machine (SVM)-based classifiers [
58]. For integration into the MPSoC, we are testing the possibility of estimating the three required BSIF features for the entire image (we can achieve this simultaneously with image capture) and then implementing the SVM classification on the dual-core ARM Cortex-R5 MPCore available on the XCZU4EV-1SFVC784I.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}