1. Introduction
In recent years, the robotics industry has experienced significant growth. Among different applications, unmanned aerial vehicles (UAVs), also known as drones, have emerged as a popular application area. A UAV is an autonomous or remotely controlled flying vehicle that does not require a human pilot onboard and has the capability to carry payloads. At first, UAVs found their primary use within the military, where they were employed for high-risk tasks like reconnaissance, attack operations, and supply missions, with the goal of minimizing the risk to human personnel. Nevertheless, progress in aerospace materials, inertial sensors, navigation technology, image processing, and data transmission has broadened the range of UAV applications, now extending into civilian fields.
UAVs find wide-ranging applications in civilian life. For example, remote-controlled aircraft are widely used for entertainment and recreational activities, and the emergence of first-person view (FPV) racing drones [
1] has created a popular sport. Furthermore, drones are utilized for aerial photography and videography, offering unique perspectives and camera angles from the sky. Additionally, some companies have begun utilizing drones for delivery services [
2], enabling faster and more efficient logistics. However, with the widespread adoption of drones, regulatory and safety concerns have arisen. To ensure safe operations, the Federal Aviation Administration (FAA) in the United States has established the “Operation and Certification of Small Unmanned Aircraft Systems” [
3], which categorizes quadcopter drones and sets standards and requirements for their operation and certification. During the development of UAVs, compatibility issues between different systems often arise. To address these challenges, the Robot Operating System (ROS), an open-source tool for robot operations, has emerged. The ROS provides a framework and tools for handling inter-system connections, enabling developers to establish, control, and monitor UAV systems more easily. It also offers numerous software modules and libraries for various functionalities, such as sensor data processing, motion control, and mission planning. The goal of this paper is to apply ROS technology to UAVs, allowing for a modular system design and simplifying the overall development process, making UAV development more accessible and efficient.
Many newly introduced drones on the market are equipped with tracking and following capabilities. Typically, this functionality is achieved through electronic devices worn by the target, utilizing GPS coordinates to track and follow the target. However, in environments where GPS signals are unavailable, such as tunnels or basements, GPS positioning becomes ineffective or even impossible. Therefore, image tracking serves as an auxiliary method to realize target tracking. One significant aspect of this research is to explore the feasibility of controlling UAV systems via detection and tracking techniques based on images. By utilizing detection and tracking techniques, drones can capture target images through cameras and perform real-time analysis to achieve precise detection and tracking of the position and orientation of the target. With the rapid development of deep learning, many deep learning-based models have been proposed to address the problem of object detection based on images. R-CNN [
4] applies high-capacity convolutional neural networks to bottom-up region proposals in order to localize and segment objects. SPP-Net [
5] utilizes spatial pyramid pooling to eliminate the requirement of fixed size input images. Faster R-CNN [
6] improves R-CNN and SPP-Net to reduce the training and testing speed while also increasing the detection accuracy. The Single Shot MultiBox Detector (SSD) [
7] utilizes multi-scale convolutional bounding box outputs attached to multiple feature maps at the top of the network to detect objects in images using a single deep neural network. Unlike prior works that treat detection as a classification problem, the work named You Only Look Once (YOLO) [
8] considers object detection as a regression problem to spatially separated bounding boxes and the associated class probabilities. A single neural network that can be optimized end-to-end is used to predict bounding boxes and class probabilities directly from full images in one evaluation. Therefore, YOLO has achieved great success. YOLO9000 and YOLOv2 [
9] improve the original YOLO by introducing the concepts of batch normalization [
10], high resolution classifier, convolution with anchor boxes [
6], dimension clusters, direct location prediction, fine-grained features, and multi-scale training. YOLOv3 [
11] made some little changes to update YOLO and to make it better. YOLOv4 [
12] performs extensive experiments on the techniques of weighted residual connections, cross-stage partial connections, cross mini-batch normalization, self-adversarial training, mish-activation, mosaic data augmentation, drop-block regularization, and CIoU loss, and it combines a subset of these techniques to achieve state-of-the-art results. Person detection is a specialized form of object detection designed to identify the specific class “person” within images or video frames. Therefore, we utilize YOLOv4 to perform the detection task for the drone. To further reduce the computation complexity of YOLOv4 so that it can be applied in the environment with very limited computational resources, we perform pruning on the original YOLOv4 model.
Pruning methods have been proposed to reduce the complexity of CNN models [
13,
14,
15,
16,
17]. Channel pruning intends to exploit the redundancy of feature maps between channels and remove channels with the minimal performance loss [
13]. Li et al. [
14] proposed pruning deep learning models using both channel-level and layer-level compression techniques. Liu et al. [
16] designed a pruning method that can be directly applied to existing modern CNN architectures by enforcing channel-level sparsity in the network to reduce the model size, decrease the run-time memory footprint and lower the number of computing operations while maintaining the accuracy of the model. In [
17], the authors demonstrate how to prune YOLOv3 and YOLOv4 models and then deployed them on OpenVINO with an increased frame rate and little accuracy loss. Since we utilize YOLOv4 for detection in the framework, we refer to the pruning methods described in [
16,
17].
Tracking algorithms based on Siamese Networks have become mainstream for visual tracking recently [
18]. Bertinetto et al. [
19] utilized a fully convolutional Siamese network that can be trained end-to-end for tracking applications. Zhu et al. [
20] designed a distractor-aware module to perform incremental learning, which is able to transfer the general embedding to the current video domain effectively. Li et al. [
21] proposed a tracker based on a Siamese region proposal network that is trained offline with large-scale image pairs. A ResNet-driven Siamese tracker is trained in [
22]. SiamMask [
23] improves the offline training procedure of popular fully convolutional Siamese methods for visual tracking by augmenting their loss with a binary segmentation task.
In this work, we utilize the ROS [
24] (Robot Operating System) to implement image detection and tracking for controlling UAVs. Due to hardware constraints on the laptop, lightweight models are required. Therefore, for the object detector, we train a convolutional neural network based on the YOLOv4 architecture and prune it accordingly. In this work, the target object for detection is a person. We employ the pruned version of the YOLOv4 object detector and the SiamMask [
23] monocular object tracker to detect and track the target person captured by the camera of the drone. Our system consists of four main components: (1) object detection, (2) target tracking, (3) Proportional Integral Derivative (PID) control, and (4) the UAV driver package. We utilize the Tello drone for implementing the object detection and tracking system. During the tracking process, the UAV control parameters include the roll, pitch, yaw, and altitude, all of which are controlled using PID controllers. These PID controllers take the position and distance of the target object as inputs. The position and distance are calculated using the monocular front-facing camera of the UAV.
2. Approach
The details of the methods used in the proposed framework, including object detection, model pruning, and visual tracking, are elaborated in this section.
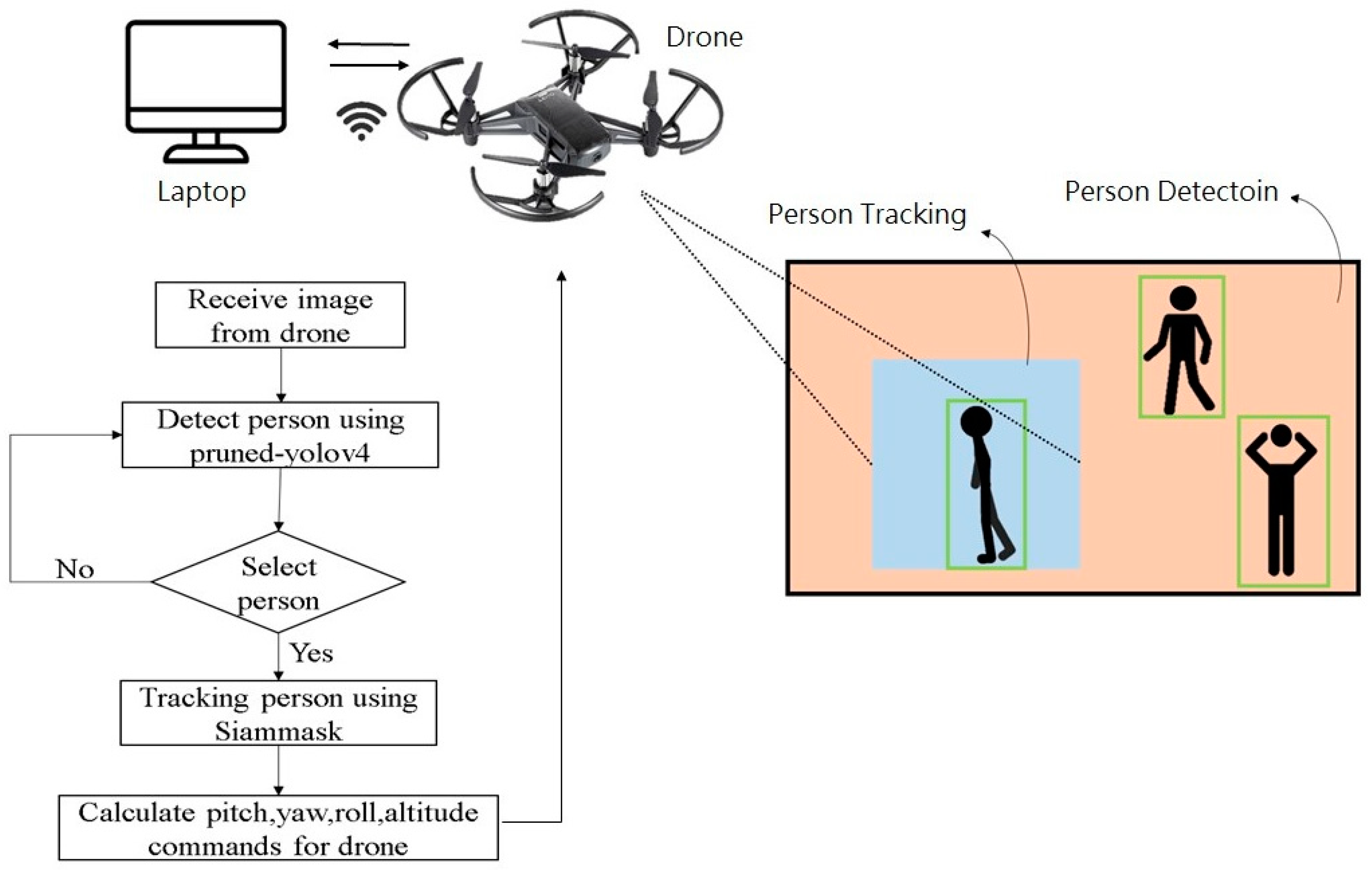
Figure 1 illustrates the system framework. A laptop computer (PC) is connected to the Tello drone via Wi-Fi for communication. The drone transmits images at a constant frequency of 30 Hz, which is preconfigured in the drone’s driver software. These images are processed on the PC using a pruned version of the YOLOv4 algorithm for object detection. Users have the ability to select bounding boxes based on their requirements. The system utilizes the Siamese network, called SiamMask, for object tracking. Based on the tracked object’s position and distance, a tracking algorithm based on a PID controller is employed to calculate estimates of the roll, pitch, yaw, and altitude. These estimated values for the roll, pitch, yaw, and altitude are then sent back to the drone to initiate the tracking process and to utilize the texture information of the background to enhance the final results.
The overall flowchart of the system architecture is shown in
Figure 1. The drone sends the image feed to the PC, where the received images are processed using Pruned-YOLOv4 for person detection. If a person is detected in the image, their bounding box is displayed on the screen. The green boxes in
Figure 1 represent the human detection results. If the user selects a specific object of interest by clicking on its bounding box, the system extracts the person within that bounding box as a template frame for the SiamMask network, enabling subsequent tracking. The tracking algorithm calculates the error between the target and the center of the frame. This error serves as the input for the PID controller, which generates flight commands for the yaw, roll, and altitude. As for the fourth flight command, pitch, it is calculated based on the relative distance of the tracked object using its position data. If no target is detected in the image, the drone maintains its position until a target appears.
2.1. Hardware Specifications
The DJI Tello [
25] drone is a small and easy-to-control consumer-grade drone. It has dimensions of approximately 98 × 92 cm and weighs around 80 g. The design of this drone allows for its usage in both indoor and outdoor environments. In terms of its features, it is equipped with a front-facing camera, a 3-axis gyroscope, a 3-axis accelerometer, a 3-axis magnetometer, a pressure sensor, and an ultrasonic altitude sensor. The resolution of the front-facing camera is 1280 × 720, capturing video at 30 frames per second. The Tello drone can communicate with other devices, such as smartphones or laptops, through a Wi-Fi network. In this particular study, a PC was used for communication with the drone.
2.2. Detection Model Pruning and Object Detection
During the object detection process, we first need to train the model. Our training process is illustrated in
Figure 2. The yellow part in
Figure 2 represents the modules for the Darknet framework. The light blue part in
Figure 2 represents the modules for the pruning stage. Firstly, we employ the Darknet framework to train the YOLOv4 base model. Then, during the pruning stage, we perform sparse training, channel pruning, layer pruning, and fine-tuning on the base model using the Darknet framework. Once the pruning stage is complete, the model undergoes fine-tuning training on the Darknet framework. Finally, we deploy the model on a laptop for detection.
- A.
Darknet Training
We use the Darknet framework to train the YOLOv4 model [
26] and adjust several hyperparameters during the initial training phase to improve the accuracy and performance of the model. One of the first hyperparameters to adjust is the input size of the network. Increasing the input size helps in detecting small objects, although it may also slow down the model’s inference speed and consume more GPU memory. It is important to note that the YOLOv4 network downsamples the input size by a factor of 32 in both the vertical and horizontal directions, so the input width and height must be multiples of 32. To achieve this, we decided to use 416 × 416 as the input size.
The second and third hyperparameters to adjust are the batch size and subdivisions. These settings are adjusted based on the GPU’s performance. The batch size hyperparameter represents the number of images to load during training, with a default value of 64. However, if the GPU’s memory size is insufficient, it will not be able to load 64 images at once. To address this issue, each batch is further subdivided into multiple sub-batches. Each sub-batch is fed into the GPU one by one until the batch is completed. In this study, we set the batch size and subdivisions to 64 and 8, respectively. The fourth hyperparameter to adjust is the number of iterations (note that in the Darknet framework, training is measured in iterations, not epochs). According to the Darknet framework’s guidelines, each object class should have at least 2000 iterations. Since we have only one class, the number of iterations should exceed 2000. We set the number of iterations to 2200 to achieve higher accuracy.
- B.
Pruning Stage
Due to the hardware limitations of the laptop, a lightweight model needs to be used. Therefore, after training the model using the Darknet framework, it needs to be pruned to achieve the goal of lightweighting. We use the metrics of accuracy (
[email protected]) and inference speed (BFLOPs) to evaluate the pruned model. However, it is important to note that there is a trade-off between accuracy and inference speed. Assuming the hardware configuration is fixed, when the model is pruned to a very small size, its inference speed may increase but its accuracy is typically reduced.
Before pruning, the weights from the Darknet framework undergo a basic training process. Once the basic training is completed, the obtained model is pruned using the pruning strategy from [
27]. This strategy involves first conducting sparse training on the model, where the channel sparsity in deep models helps with channel pruning. To facilitate channel pruning, each channel in the convolutional layers is associated with a scaling factor. During training, L1 regularization is applied to these scaling factors to automatically identify unimportant channels. Channels with smaller scaling factor values (orange color) are pruned (left side). After pruning, we obtain a compact model (right side), which is then fine-tuned to achieve comparable (or even higher) accuracy with the fully trained network. The pruning process is illustrated in
Figure 3.
- C.
Sparsity Training
We add a Batch Normalization (BN) layer after each convolutional layer in YOLOv4 to accelerate convergence and improve generalization. The BN layer utilizes batch statistics to normalize the convolutional features as:
Here,
and
represent the mean and variance of the input features in the mini-batch, respectively.
and
represent the trainable scale factor and bias in the BN layer. In this study, we directly use the scale factor in the BN layer as an indicator of channel importance. To effectively distinguish between important and unimportant channels, we apply L1 regularization to γ, enabling channel-level sparse training. The loss function for sparse training is shown as:
The function represents the L1 norm applied to γ, which is widely used in the sparsification step. represents the penalty factor that balances the two loss terms.
The effectiveness of pruning depends on the sparsity of the model. Prior to sparse training, the distribution of γ in the BN layer of YOLOv4 is expected to be uniform. After sparse training, most of the γ values in the BN layer are compressed toward zero. This brings two benefits:
- (1)
Achieving network pruning and compression to improve model efficiency: The weights in the BN layer are typically used for standardizing and scaling each input sample in the network. When the weights are close to zero, the corresponding standardization and scaling operations are reduced, thereby reducing the computational complexity.
- (2)
By sparsifying the weights of the BN layer close to zero, it becomes possible to identify parameters that have minimal impact on network performance and prune them.
Once sparse training is completed, channel cutting can be performed. Here is an explanation of how to proceed with channel cutting. First, the total number of channels in the backbone is computed. Once the number of channels is determined, the corresponding γ values are stored in a variable and sorted in ascending order. The next step is to decide which channels to keep and which ones to prune. This can be achieved by setting a pruning rate, which represents the proportion of channels to be pruned. The pruning rate is typically a value between 0 and 1, where a higher value indicates a greater degree of pruning. By following these steps, the channel-cutting process can be carried out to selectively retain or remove channels based on the specified pruning rate.
- E.
Layer cutting
Within the YOLOv4 backbone, there are multiple CSPX modules, where each CSPX module consists of three CBL layers and X ResUnit modules. The resulting features of these modules are concatenated together, as depicted in
Figure 4a. For layer cutting, we mainly prune the ResUnit within YOLOv4. The architecture of the ResUnit is illustrated in
Figure 4b, which consists of two CBL layers and a shortcut connection. The CBL layer comprises a Conv layer, a BN layer, and a Leaky ReLU activation function, as shown in
Figure 4c. In layer cutting, the mean values of γ for each layer are first sorted, and by evaluating the previous CBL layer of each shortcut, the minimum value can be selected for layer pruning. To ensure the structural integrity of YOLOv4, when pruning one ResUnit, both the shortcut layer and the preceding CBL layer are simultaneously pruned, resulting in the pruning of three layers in total.
- F.
Fine-tuning
Different pruning strategies and threshold settings yield different effects on the pruned model. Sometimes, the accuracy of the pruned model may even increase, although in most cases, pruning can have a negative impact on model accuracy. In such cases, it is necessary to perform fine-tuning on the pruned model to compensate for the accuracy loss caused by pruning. Fine-tuning is crucial for restoring the accuracy of the pruned model. In our experiments, we directly retrained the Pruned-YOLOv4 using the same training hyperparameters as the normal training process for YOLOv4.
2.3. Object Tracking and Drone Control
The laptop performs the real-time detection of drones, allowing users to track the detected targets until the tracking is completed. The objects detected using Pruned-YOLOv4 are represented by bounding boxes, each containing four coordinates (x, y, w, h). Here, x and y represent the coordinates of the top left corner of the bounding box, while w and h represent the width and height of the bounding box, respectively. Once the coordinates are obtained, we continuously detect the user’s mouse position. If the mouse click falls within a bounding box, the four coordinates of the bounding box are passed to the object tracking module, which utilizes SiamMask [
23]. SiamMask is a target-tracking algorithm based on Siamese Neural Networks [
28]. Siamese Neural Networks were initially proposed by Bromley and LeCun to address signature verification problems [
29] and have since been widely applied in various fields, such as image matching and target tracking.
In the task of target tracking, Siamese Neural Networks employ two identical subnetworks with shared parameters and weights. The tracking template is fed into the network, and the output weights are obtained. These weights are then matched with the output weights of the search region to calculate the similarity score. The target’s location to be tracked is determined by computing the response score map. Building upon the traditional Siamese network, SiamMask incorporates target segmentation computation, which allows for the extraction of the target’s contour. This helps mitigate the effects of target feature variations caused by rotation and deformation.
While performing tracking, SiamMask simultaneously returns an image with the bounding box of the tracked object. This bounding box contains information about the object’s position in the image. The bounding box of the tracked object consists of four points: (, ), (, ), (, ), and (, ).
We can use these four points to calculate the center of the object’s position, which is computed as:
In order to track an object accurately, it is necessary to know the exact center position of the drone’s screen. This is because the detected object’s center should always align with the center of the drone’s screen for proper tracking. The calculation of the disparity between the center of the drone’s screen and the object’s center is performed as:
and should always be equal to or close to zero to achieve effective tracking.
The drone has a total of four control parameters: roll, yaw, altitude, and pitch. Roll controls the drone’s lateral movement, yaw controls the drone’s clockwise or counterclockwise rotation, altitude controls the drone’s vertical movement, and pitch controls the drone’s forward or backward movement.
Figure 5 illustrates the basic flight maneuvers of the drone.
Next, we will explain how PID controls drone flight. It is evident that by using the center point of the tracked object and the center point of the screen, we can obtain the error in the
X-axis. This error is related to the drone’s roll for lateral movement and yaw for clockwise or counterclockwise rotation. If the drone detects that the object is moving left or right, we can choose to adjust the drone’s heading to face the object or perform lateral movements to keep up with it. Additionally, there is the pitch axis, which involves forward and backward movements. By subtracting the distance between the drone and the real object from the desired ideal distance, we can calculate the distance error and control the drone’s forward or backward movements accordingly. Finally, regarding altitude, by subtracting the Y-coordinate of the tracked object from the Y-coordinate of the screen center, we can obtain the error in the
Y-axis. This allows us to calculate the necessary altitude for the drone’s vertical ascent or descent. The specific control methods are illustrated in
Figure 6.
When it comes to the error in the
X-axis, the choice between roll and yaw is designed to be dependent on the derivative term (D) of the PID controller. The D term represents the rate of change of the error. If the error changes rapidly, the drone needs to increase its power to keep up with the object’s movements. However, if the object continues to move along the
X-axis, as shown in
Figure 7a, a stronger control is required to track the target quickly. The red rectangle represents the bounding box of the subject. Therefore, we choose the roll option, which means performing lateral movements to the right in order to follow the object, represented by the green arrow illustrated in
Figure 7a. On the other hand, if the tracked object does not exhibit significant movement, the yaw option is selected, which only requires adjusting the drone’s heading to follow the target, represented by the green arrow illustrated in
Figure 7b.
4. Conclusions
In this paper, we propose an implementation method for an object detection and target tracking system based on the Robot Operating System (ROS) and apply it to the Tello drone. The system achieves efficient object detection and target-tracking capabilities in real-time environments. We utilize the pruned YOLOv4 architecture as the detection model and select SiamMask as the tracking model. Additionally, we introduce a PID module to calculate the errors and determine the flight attitude and action. For the detection module, we choose the pruned YOLOv4 architecture, which provides a faster execution speed while maintaining the detection accuracy. By reducing the redundant parameters and computations in the model, we achieve lightweight and accelerated performance. This allows our system to efficiently perform object detection tasks in real-time environments. For the tracking module, we adopt the SiamMask model. SiamMask is a single-object tracking method capable of real-time target tracking. In our system, SiamMask is used to track the objects detected by YOLOv4, enabling continuous object tracking and positioning. Furthermore, we introduce the PID module to calculate the errors and adjust the flight attitudes. PID is a classical control algorithm that computes control signals based on the current error, accumulated error, and rate of error change, aiming to bring the system output closer to the desired value. In our system, the PID module calculates errors based on the target object’s position and the drone’s current state, and adjusts the drone’s attitude control signals to stably track the target object. Through flight experiments, we validate the feasibility of applying this system in everyday environments. The pruned YOLOv4 model provides efficient object detection capabilities, enabling fast target detection in real-time environments. SiamMask is used for tracking the target object, and the PID module accurately calculates the errors and adapts to different flight situations, allowing the drone to stably track the target object.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}