
Intelligent Pick-and-Place System Using MobileNet

Abstract
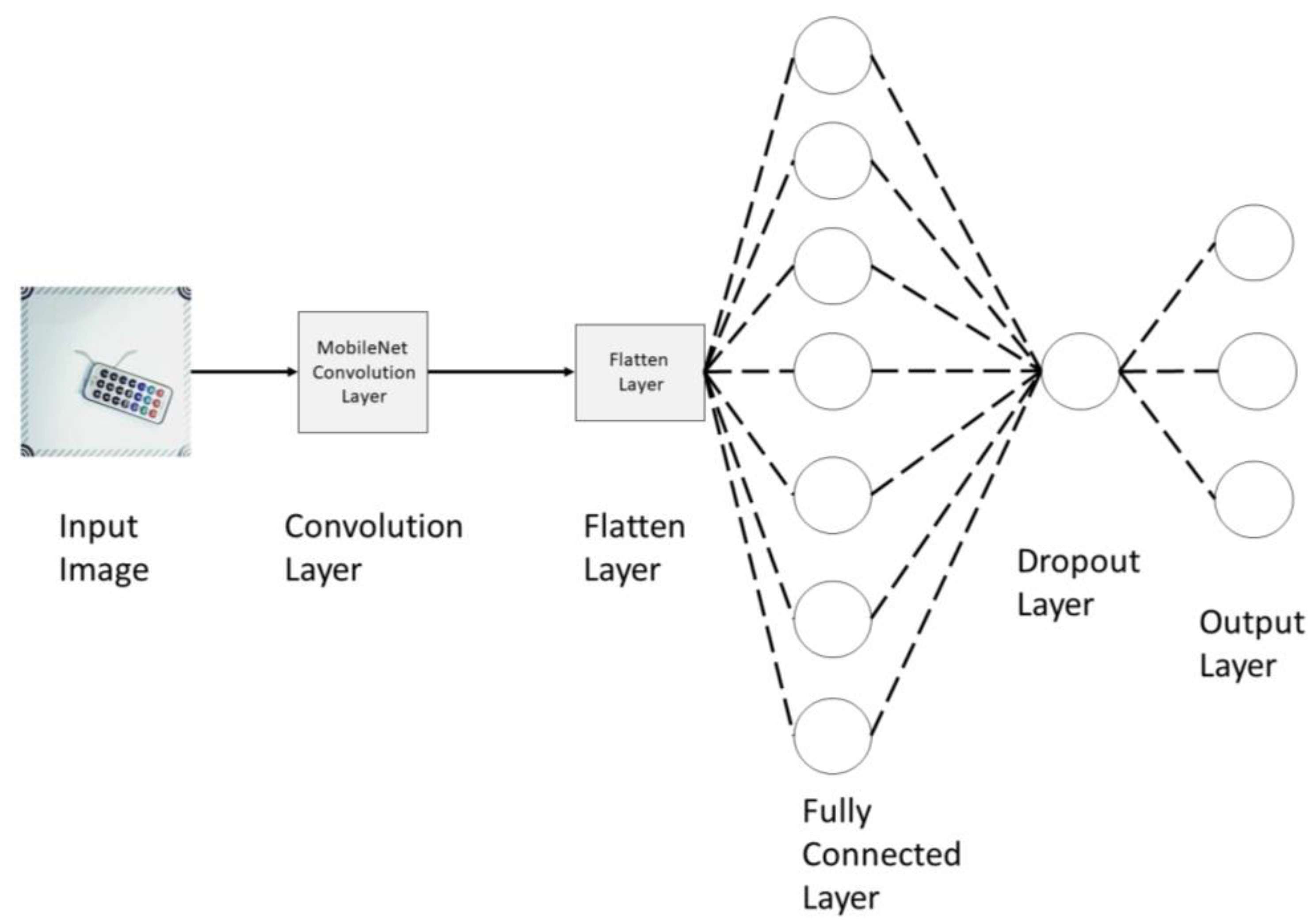
:1. Introduction
2. Problem Formulation and Methodology
3. Program and Code Structure
- Initialize variable “start_time” and pass current time to it.
- Call function “load_dataset()” and pass the return values to the variables “data_set” and “objects_names”.
- Call the shuffle function and pass the return values to variables “objects_list”, “labels_list”, and “files_names”.
- If there are no objects in “objects_list”, print “cannot train without a data set of 0”.
- Otherwise, convert the “objects_list” and “labels_list” to NumPy arrays.
- Create a Train Test Split and pass the return values to variables “trainX”, “testX”, “trainY” and “testY”.
- Call function “ImageDataGenerator()” and pass it to a variable called “datagen”, which creates a function to augment data.
- Fit the data augmenter “datagen” to the training data “trainX”, which augments the training data and creates more training data.
- Create a variable called “model” and pass an instance of the MobileNet model into it.
- Print the model summary.
- Train the MobileNet Model by calling the function model.fit().
- Create a variable “prediction”, which is used to predict all of the test images “testX” and return the highest predicted value for each image.
- Print the confusion matrix by calling the function “classification_report()”.
- Save the MobileNet Model.
- Create a variable “end_time” and pass the difference between the current time and the “start_time”.
- Print “end_time”.
- Return the MobileNet model.
- Create a list called “objects_names” and add all the names of the folder in the list.
- Prints all the names in the “objects_names” list.
- Create “objects_list”, “labels_list” and “files_names”, which are used to store object images, object labels, and object names respectively.
- Try to make a data mask directory. If it already exists, go to the next line of code.
- Iterate over all the names in the “object_names” list:
- a.
- Create a variable called “list_dir”, which stores the address of the folder where the images are stored.
- b.
- Print the name of the folder and the number of images in the folder.
- c.
- Try to make a “data_mask/object name” directory. If it exists, go to the next line of code.
- d.
- Iterate through all the images in “list_dir”:
- i.
- Create a variable called “img” which is used to read the image.
- ii.
- Call “utils.standardize_img()”. This function originates from Niryo One’s library and is used to normalize the color of “img”.
- iii.
- Call “utils.objs_mask()” and pass the image “img” to it. This function is from Niryo One’s library and is used to create extract regions of interest from images. The returned result is passed to the variable “mask”.
- iv.
- Call “utils.extract_objs()” and pass “img” and “mask” to it. This function comes from Niryo One’s library and is used to find shapes in an image. If an object is found from an image, the code will create a rectangle around the object, make the image in a vertical orientation and return the image. The returned image is passed to the variable “objs”.
- v.
- Iterate through all pixel in the image “objs”:
- (1)
- Save image “img” in folder “data_mask/object Name/number/file_name”.
- (2)
- Resize the image to (64,64) pixel.
- (3)
- Create a NumPy array called “img_float” full of zeros with arguments (64, 64, 3), np.float32. This indicates that the pixel size is 64 by 64, and the number of colour channels is 3, i.e., Red, Green, and Blue in this case.
- (4)
- Scale the colour of the image “img” between 0 and 1 and pass it to the NumPy array “img_float”.
- (5)
- Create a NumPy array called “label” full of zeros with the size of “object_names”.
- (6)
- Set label[obj_id] to 1, which changes the label names to binary form. Each index will represent a class name.
- (7)
- Add the NumPy array “img_float” which contains the images to “object_list”.
- (8)
- Add the NumPy array “label” which contains the label index to “label_list”.
- (9)
- Add the total number of images and file name to the list “files_names”.
- vi.
- Print the number of objects detected, which can inform the user how many objects that function “utils.extract_objs()” has detected.
- vii.
- Print “|”, which informs the user that the algorithm is running the next loop.
- e.
- Print “” this creates a new line. This is to indicate that the algorithm is performing object extraction for the next class name.
- f.
- Increment the variable “obj_id”, which is used to indicate the index of the labels.
- Return “objects_list”, “labels_list”, files_names”, and “objects_names”.
- Create a Zip the input dataset and convert it to a list. After that pass it to a variable “c”.
- Shuffle the list c.
- Zip the list c and return the list.
- When the class is called, the arguments for learning rate, Epoch, Batch_size, and Num_objectNames must be filled. The class will then initialize these values as variables under the same name.
- The bottom layer of MobileNet will first be created (“Bottom_model”). The bottom layer is important as it acts as the convolutional layer. This layer performs feature extraction.
- The Top Layer of MobileNet is then created using the output of the bottom layer (“Bottom_model”).
- A flatten layer is added to convert the output map from the bottom layer to a one-dimensional array of numbers and vectors.
- A dense hidden layer of 128 neurons with activation function of “ReLU” is added. The “ReLU” function is added in the hidden layers as its less susceptible to vanishing gradient problems and performs calculations faster compared with other activation functions.
- A dropout layer is added to prevent overfitting in the model.
- The final output layer is then added with an activation function of “SoftMax”. The “SoftMax” activation function is always used as it converts the output to a normalized probability distribution.
- The bottom and the top layers are then combined.
- The bottom layers are frozen as the convolutional layer does not need to be trained.
- An optimizer variable is created using the Adam function. Adam optimizer is a gradient descent optimizer and its widely used as its more efficient and consumes lesser memory.
- The MobileNet Model is then compiled.
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Executive Summary World Robotics 2021 Industrial Robots. Available online: https://ifr.org/img/worldrobotics/Executive_Summary_WR_Industrial_Robots_2021.pdf (accessed on 20 November 2021).
- Ott, C. Cartesian Impedance Control of Redundant and Flexible-Joint Robots. Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Nabat, V.; Pierrot, F.; De La O’Rodriguez-Mijangos, M.; Azcoitia Arteche, J.M.; Bueno Zabalo, R.; Company, O.; Florentino Perez De Armentia, K. High-Speed Parallel Robot with Four Degrees of Freedom. U.S. Patent US20090019960A1, 15 June 2010. [Google Scholar]
- Stock, M.; Miller, K. Optimal kinematic design of spatial parallel manipulators: Application to linear delta robot. J. Mech. Des. 2003, 125, 292–301. [Google Scholar] [CrossRef] [Green Version]
- Østergaard, E.H. The Role of Cobots in Industry 4.0; White Paper; Universal Robots: Odense, Denmark, 2017. [Google Scholar]
- Lightstead, A. What is a Pick and Place Robot and How Does it Work? Available online: https://www.pwrpack.com/what-is-a-pick-and-place-robot (accessed on 19 April 2022).
- Riordan, A.D.O.; Toal, D.; Newe, T.; Dooly, G. Object recognition within smart manufacturing. Procedia Manuf. 2019, 38, 408–414. [Google Scholar] [CrossRef]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; MIT Press: Cambridge, MA, USA, 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef] [PubMed]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Niryo One, a 6 Axis Robot Arm Designed for Education and Research. Available online: https://niryo.com/robotic-solution-education-research/niryo-one (accessed on 28 February 2022).
- Visual Picking with Artificial Intelligence—Niryo. Available online: https://niryo.com/docs/niryo-one/niryo-one-industrial-demonstrators/visual-picking-with-artificial-intelligence (accessed on 24 May 2021).
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Into Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, S.A.; Meitei, T.G.; Majumder, S. Short PCG classification based on deep learning. In Deep Learning Techniques for Biomedical and Health Informatics; Agarwal, B., Balas, V.E., Jain, L.C., Eds.; Elsevier: Amsterdam, Netherlands, 2020; pp. 141–164. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; Volume 27, pp. 807–814. [Google Scholar]
- Ranjan, C. Understanding Dropout with the Simplified Math behind It. In Towards Data Science; Connaissance Publishing: Paris, France, 2020; Available online: https://towardsdatascience.com/simplified-math-behind-dropout-in-deep-learning-6d50f3f47275 (accessed on 8 May 2019).
- Mahmood, H. The Softmax Function, Simplified—How a Regression Formula Improves Accuracy of Deep Learning. In Towards Data Science; Connaissance Publishing: Paris, France, 2020; Available online: https://towardsdatascience.com/softmax-function-simplified-714068bf8156 (accessed on 26 November 2018).
- Google Developers. Multi-Class Neural Networks: Softmax. In Machine Learning Crash Course. Available online: https://developers.google.com/machine-learning/crash-course/multi-class-neural-networks/softmax (accessed on 19 July 2022).
- Madjarov, G.; Kocev, D.; Gjorgjevikj, D.; Deroski, S. An extensive experimental comparison of methods for multi-label learning. Pattern Recogn. 2012, 45, 3084–3104. [Google Scholar] [CrossRef]
- Narkhede, S. Understanding Confusion Matrix. In Towards Data Science; Connaissance Publishing: Paris, France, 2020; Available online: https://towardsdatascience.com/understanding-confusion-matrix-a9ad42dcfd62 (accessed on 9 May 2018).
- Niryo One Demonstrator’s Source Code. Available online: https://github.com/NiryoRobotics/niryo_one_industrial_demonstrators/tree/master/Visual_Picking_Artificial_Intelligence (accessed on 19 November 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MobileNet Model |
|---|
| Total Time Taken: 21.0 s |
| 1/1 [==============================]—ls 656 ms/step |
| len 1 3 |
| [‘Circle_wafer’, “IC_Chip”, “Square_Wafer”] |
| Circle_Wafer 32 |
| 1|1|1|1|1|1|1|1|1|1|1|1|1|1|0|1|1|1|1|1|2|1|1|2|2|1|1|1|1|1|1|1| |
| IC_Chip 38 |
| 1|1|1|1|1|1|1|1|2|1|1|2|1|1|1|1|1|1|1|1|2|1|1|1|1|1|1|1|1|1|2|1|1|0|1|1|1|1| |
| Square_Wafer 38 |
| 1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1|1| |
| Precision | Recall | f1-Score | Support | |
|---|---|---|---|---|
| Circle_wafer | 1.00 | 0.71 | 0.83 | 7 |
| IC_Chip | 0.80 | 1.00 | 0.89 | 8 |
| Square_wafer | 1.00 | 1.00 | 1.00 | 8 |
| accuracy | 0.91 | 23 | ||
| macro avg | 0.93 | 0.90 | 0.91 | 23 |
| weighted avg | 0.93 | 0.91 | 0.91 | 23 |
| MobleNet model | ||||
| Total Time Taken: 19.362 s | ||||
| Precision | Recall | f1-Score | Support | |
|---|---|---|---|---|
| Circle_wafer | 1.00 | 0.71 | 0.83 | 7 |
| IC_Chip | 0.80 | 1.00 | 0.89 | 8 |
| Square_wafer | 1.00 | 1.00 | 1.00 | 8 |
| accuracy | 0.91 | 23 | ||
| macro avg | 0.93 | 0.90 | 0.91 | 23 |
| weighted avg | 0.93 | 0.91 | 0.91 | 23 |
| Niryo One Sequential model | ||||
| Total Time Taken: 7.191 s | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, F.; Tay, D.W.L.; Ang, A. Intelligent Pick-and-Place System Using MobileNet. Electronics 2023, 12, 621. https://doi.org/10.3390/electronics12030621
Hong F, Tay DWL, Ang A. Intelligent Pick-and-Place System Using MobileNet. Electronics. 2023; 12(3):621. https://doi.org/10.3390/electronics12030621
Chicago/Turabian StyleHong, Fan, Donavan Wei Liang Tay, and Alfred Ang. 2023. "Intelligent Pick-and-Place System Using MobileNet" Electronics 12, no. 3: 621. https://doi.org/10.3390/electronics12030621
APA StyleHong, F., Tay, D. W. L., & Ang, A. (2023). Intelligent Pick-and-Place System Using MobileNet. Electronics, 12(3), 621. https://doi.org/10.3390/electronics12030621