
Cluster-Based Secure Aggregation for Federated Learning

Abstract
:1. Introduction
- We proposed a new cluster-based secure aggregation (CSA) strategy for federated learning with heterogeneous nodes that have different computing powers and different sizes of training data.
- The CSA technique clusters with similar response times. We introduced a processing score to represent the processing time of each node and proposed a new grid-based clustering algorithm to cluster nodes with processing score and GPS information. Consequently, since the server can determine a reasonable latency for a cluster, the CSA technique improves the overall throughput of federated learning while reducing false-positive dropouts.
- We proposed a novel additive sharing-based masking scheme robust to dropout nodes without using a (t, n) threshold secret sharing scheme. In particular, it allows nodes to verify the integrity and correctness of the masks received from other nodes for reliable aggregation. It also keeps local parameters private if each cluster has at least three nodes that are honest (no collusion with the server) nodes.
2. Related Work
3. A Cluster-Based Secure Aggregation Model
3.1. Background and Configuration
- (1)
- Federated learning
- (2)
- Communication
- (3)
- System parameters
- (4)
- Registration
3.2. Problem Definition
- Privacy of local datasets and updates: All the data that each node holds in its local device and all the local learning parameters that are shared over the network must be confidential not only to the other nodes but also to the FS. The FS only knows the aggregated sum of all the local updates provided by all nodes. In addition, even if a particular user’s update would be delivered to the FS after the aggregation, the FS and the other users cannot reconstruct the corresponding user’s local parameters with the delayed data.
- Tolerance to dropouts: User updates can be dropped out during the communication due to network conditions and device issues. The FS should be able to compute a correct aggregated sum of the current active users even if dropout users occur.
- Integrity of random masks: Users create random masks and share them with other users to hide their actual local model parameters. In addition, these masks must be correctly removed during the local update aggregation. Therefore, users should be able to validate the correctness and integrity of given masks. In other words, users can be sure that the masks are created to be necessarily removed during the aggregation and that the masks are not modified during the communication.
- (1)
- Quantization: The CSA exploits an additive secret sharing defined over a finite field for a prime p. Thus, all operations in the CSA are carried out over Zp*. Since the local parameters are real numbers, the nodes need to quantize the real values to integers. To achieve this, we exploited So et. al.’s stochastic quantization strategy [24].
- (2)
- Masking with additive secret sharing: The FS selects a random nonce for each cluster. Then, each node generates random masks for the other nodes in the same cluster and shares the encrypted masks with them. The random masks are created by an additive secret sharing method based on the cluster random nonce. Then, the nodes create their updates masked with those shares.
- (3)
- Aggregation: The updates of nodes are first aggregated on a cluster basis. When dropout users occur in a cluster, the currently available nodes in the cluster perform a recovery phase. They modify the cluster sum by removing the masks of dropout users from the aggregated sum. After the recovery phase, the cluster sums are finally aggregated.
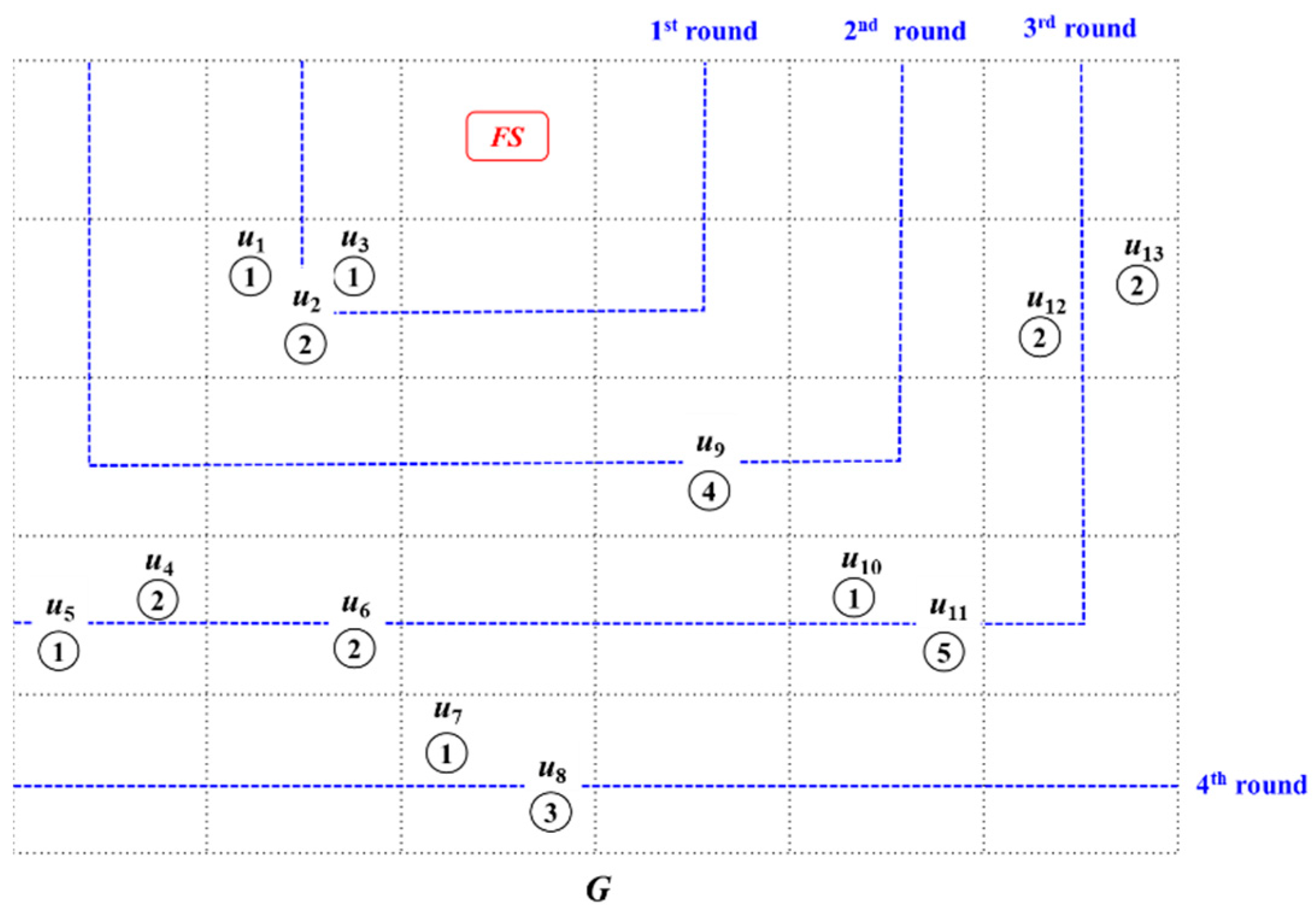
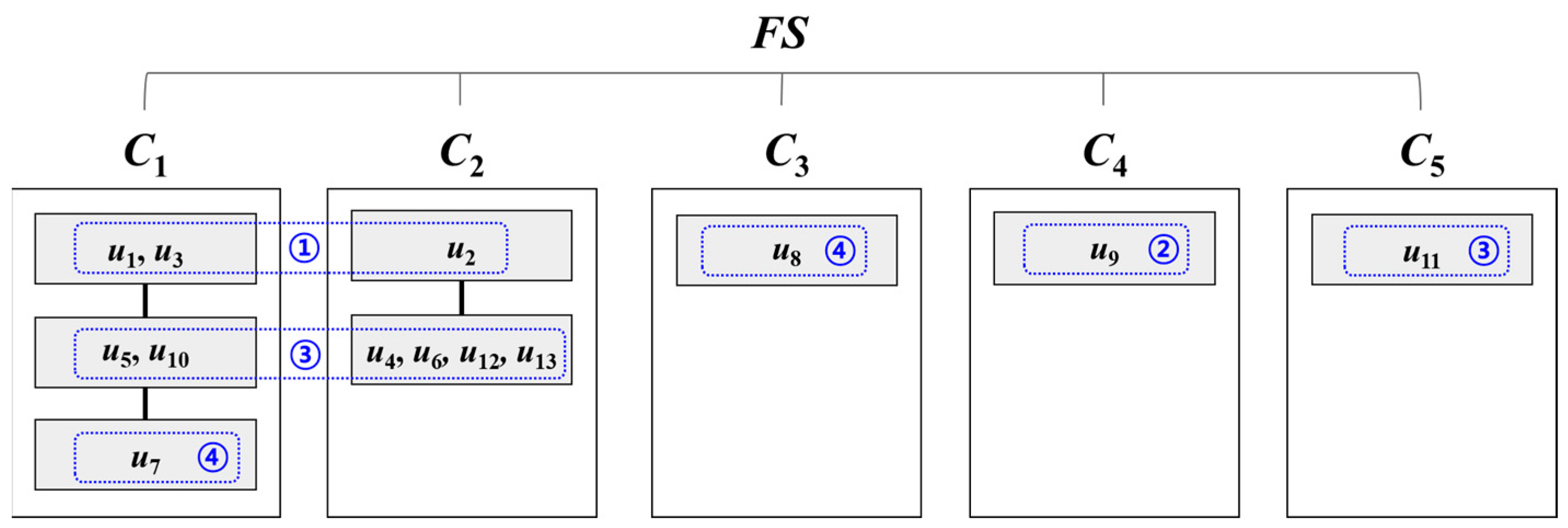
3.3. Node Clustering
PS = training data size (MB)/CC
- -
- Each cluster must contain at least four nodes (the minimum cluster size denoted as is four).
- -
- PS is divided into K levels (K is systemically predefined).
- -
- The entire area where all nodes are distributed is divided into an a b grid (a and b are systemically predefined), and the nodes are mapped to the grid by GPS information.
- -
- Node clustering starts with the nodes closest to the FS according to the PS level. This repeats sequentially for the next neighbor nodes around the FS until all nodes are clustered.
- -
- Clusters are finally rebalanced so that each cluster satisfies .
| Algorithm 1: Node Clustering |
| Input: G: a grid of nodes, mr: the maximum row index, mc: the maximum column index, rf: the row index of the server cell, cf: the column index of the server cell, U = {u1, …, uN} and each ui’s GPS information and PS level. Output: K clusters C1, …, CK |
| ; for each node u in U generate Ui,j using each u’s GPS information and G; for (D = 0; (rf + D <= mr||cf + D <= mc); D++) for each cluster Ci ) and add B to Ci as a leaf bucket; r0 = max(rf – D, 1); c0 = max(cf – D, 1); r1 = min(rf + D, mr); c1 = min(cf + D, mc); for (r = r0; r <= r1; r++) for (c = c0; c <= c1; c++) if(|r − rf| == D|||c − cf| == D) for each node u in Ur,c l = u’s PS level; Bl = the leaf bucket of Cl; Bl u; return C1, …,CK; |
| Algorithm 2: Merge Clusters |
| while K > 1 l − |CK|; l nodes at the highest level in CK−1’s node structure are merged to CK; else CK−1 = CK−1 ∪ CK; remove CK; K = K − 1; Cn = the next-order cluster of C1; C1 = Cn ∪ C1; remove Cn; |
3.4. BCSA: A Basic Cluster-Based Secure Aggregation Model
3.5. FCSA: A Fully Secure Cluster-Based Aggregation Model
4. Security and Efficiency Analysis
- (1)
- Robustness to dropouts: FCSA is robust against dropout users. (There is no constraint for the number of active users.)
- (2)
- Privacy of local parameters: FCSA guarantees the privacy of local parameters on each node if there are at least three honest active users in each cluster with a cluster size greater than or equal to four.
- (3)
- Efficiency of secure aggregation: Let be the average cluster size. The computation cost of a node is , and the FS’s cost is O(N). The communication cost of node is , and the FS’s cost is .
5. Experimental Results
5.1. Simulation Setup
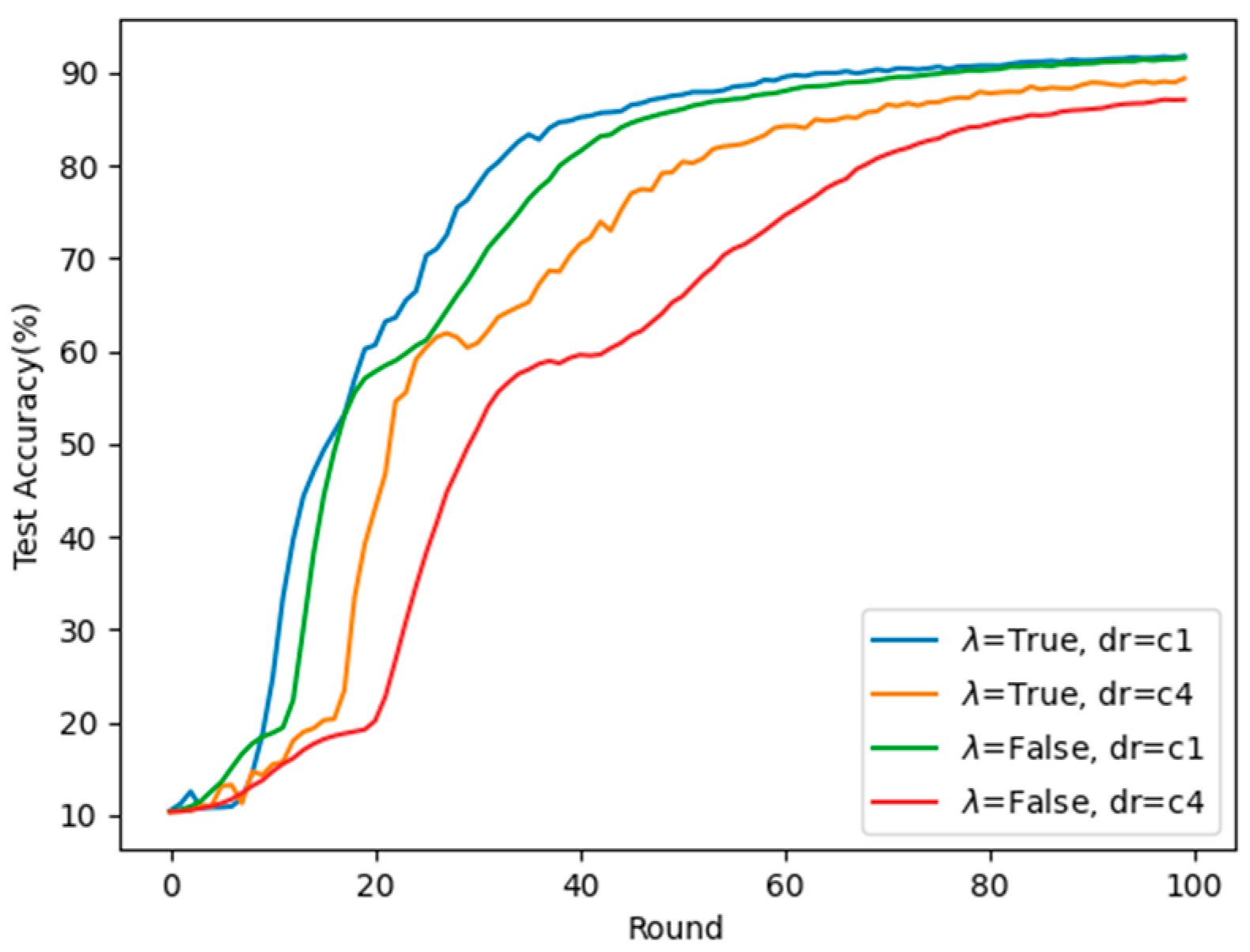
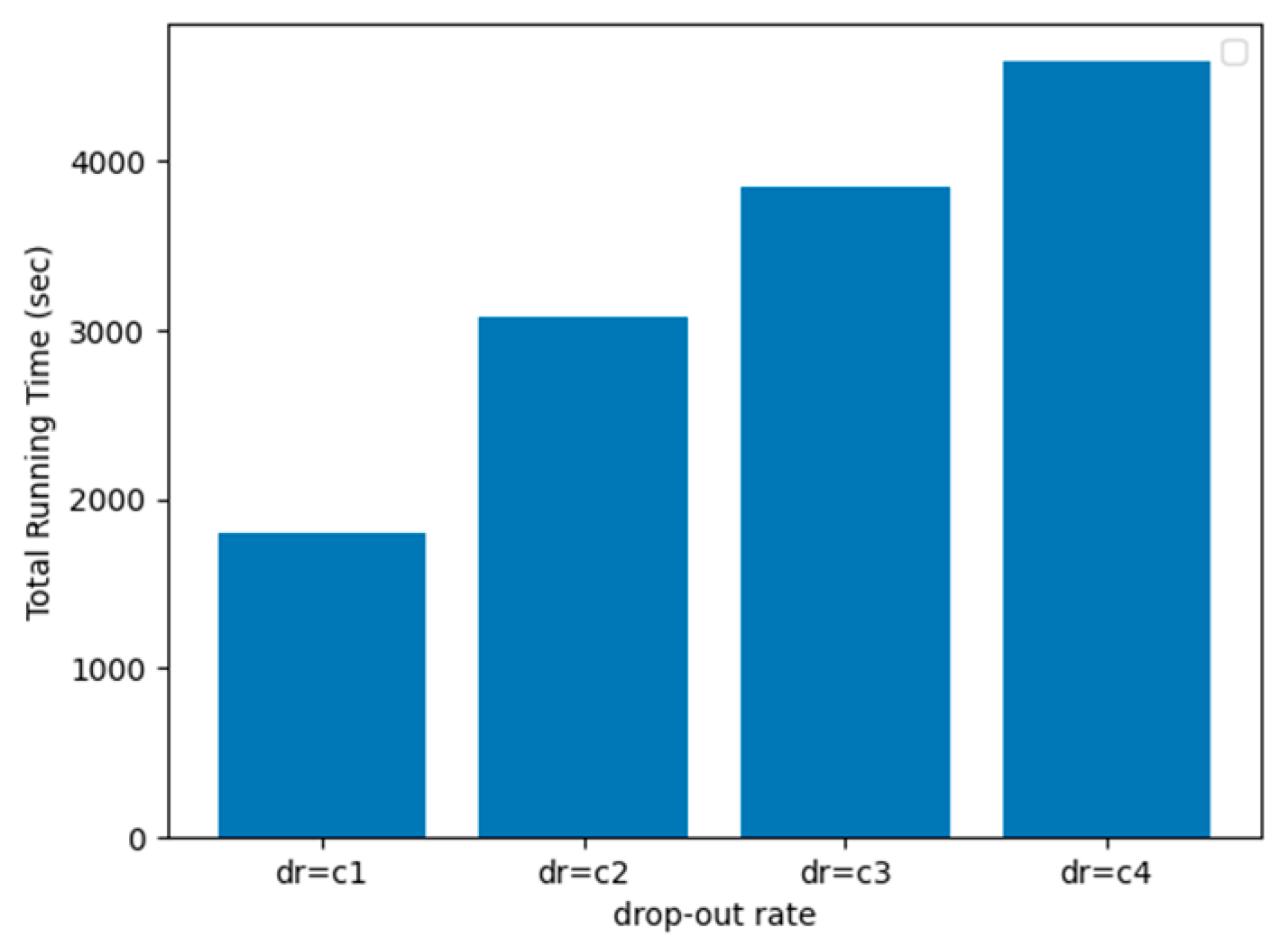
5.2. Simulated Performance
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 9–11 May 2017; Volume 54. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. arXiv 2019, 14774–14784. [Google Scholar] [CrossRef]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond inferring class representatives: User-level privacy leakage from federated learning. In Proceedings of the IEEE INFOCOM, Paris, France, 29 April–2 May 2019; pp. 2512–2520. [Google Scholar] [CrossRef]
- Geiping, J.; Bauermeister, H.; Dröge, H.; Moeller, M. Inverting gradients—How easy is it to break privacy in federated learning? In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Online, 6–12 December 2020. [Google Scholar] [CrossRef]
- Yao, A.C. Protocols for secure computations. In Proceedings of the 23rd IEEE Annual Symposium on Foundations of Computer Sciecne (sfcs 1982), Chicago, IL, USA, 3–5 November 1982; pp. 160–164. [Google Scholar] [CrossRef]
- Shamir, A. How to share a secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Leontiadis, I.; Elkhiyaoui, K.; Molva, R. Private and dynamic timeseries data aggregation with trust relaxation. In Proceedings of the International Conferences on Cryptology and Network Security (CANS 2014), Seoul, Korea, 1–3 December 2010; Springer: Berlin/Heidelberg, Germany, 2014; pp. 305–320. [Google Scholar] [CrossRef]
- Rastogi, V.; Nath, S. Differentially private aggregation of distributed time-series with transformation and encryption. In Proceedings of the ACM SIGMOD International Conference on Management of data (SIGMOD 10), Indianapolis, IN, USA, 6–10 June 2010; pp. 735–746. [Google Scholar] [CrossRef]
- Halevi, S.; Lindell, Y.; Pinkas, B. Secure computation on the Web: Computing without simultaneous interaction. In Advances in Cryptology—CRYPTO 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 132–150. [Google Scholar] [CrossRef]
- Leontiadis, I.; Elkhiyaoui, K.; Önen, M.; Molva, R. PUDA—Privacy and Unforgeability for Data Aggregation. In Cryptology and Network Security. CANS 2015; Springer: Cham, Switzerland, 2015; pp. 3–18. [Google Scholar] [CrossRef] [Green Version]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially private federated learning: A client level perspective. In Proceedings of the NIPS 2017 Workshop: Machine Learning on the Phone and other Consumer Devices, Long Beach, CA, USA, 8 December 2017. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.S.; Poor, H.V. Federated Learning with Differential Privacy: Algorithms and Performance Analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedoney, A.; McMahan, H.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical Secure Aggregation for Federated Learning on User-Held Data. arXiv 2016. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the ACM SIGSAC Conferences on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar] [CrossRef]
- Ács, G.; Castelluccia, C. I have a DREAM! (DiffeRentially privatE smArt Metering). In Information Hiding. IH 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 118–132. [Google Scholar] [CrossRef]
- Goryczka, S.; Xiong, L. A comprehensive comparison of multiparty secure additions with differential privacy. IEEE Trans. Dependable Secur. Comput. 2017, 14, 463–477. [Google Scholar] [CrossRef]
- Elahi, T.; Danezis, G.; Goldberg, I. Privex: Private collection of traffic statistics for anonymous communication networks. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1068–1079. [Google Scholar] [CrossRef]
- Jansen, R.; Johnson, A. Safely Measuring Tor. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1553–1567. [Google Scholar] [CrossRef]
- So, J.; Güler, B.; Avestimehr, A.S. Turbo-Aggregate: Breaking the Quadratic Aggregation Barrier in Secure Federated Learning. arXiv 2020, arXiv:2002.04156. [Google Scholar] [CrossRef]
- Elkordy, A.R.; Avestimehr, A.S. HeteroSAg: Secure Aggregation with Heterogeneous Quantization in Federated Learning. IEEE Trans. Commun. 2022, 70, 3151126. [Google Scholar] [CrossRef]
- Hu, C.; Liang, H.; Han, X.; Liu, B.; Cheng, D.; Wang, D. Spread: Decentralized Model Aggregation for Scalable Federated Learning. In Proceedings of the 51st International Conference on Parallel Processing (ICPP’22), Bordeaux, France, 29 August–1 September 2022; pp. 1–12. [Google Scholar] [CrossRef]
- Lu, S.; Li, R.; Liu, W.; Guan, C.; Yang, X. Top-k sparsification with secure aggregation for privacy-preserving federated learning. Comput. Secur. 2023, 124, 102993. [Google Scholar] [CrossRef]
- He, L.; Karimireddy, S.; Jaggi, M. Secure byzantine robust machine learning. arXiv 2020, arXiv:2006.04747. [Google Scholar] [CrossRef]
- So, J.; Güler, B.; Avestimehr, A.S. Byzantine-Resilient Secure Federated Learning. IEEE J. Sel. Areas Commun. 2021, 39, 2168–2181. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, L.; Ma, C.; Li, J.; Wang, J.; Wang, Q.; Yu, S. LSFL: A Lightweight and Secure Federated Learning Scheme for Edge Computing. IEEE Trans. Inf. Forensics Secur. 2023, 18, 365–379. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, M.; Yu, H.; Sinnott, R.O.; Liu, H. Efficient and Secure Federated Learning With Verifiable Weighted Average Aggregation. IEEE Trans. Netw. Sci. Eng. 2023, 10, 205–222. [Google Scholar] [CrossRef]
- Hahn, C.; Kim, H.; Kim, M.; Hur, J. VerSA: Verifiable Secure Aggregation for Cross-Device Federated Learning. IEEE Trans. Dependable Secur. Comput. 2023, 20, 36–52. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C.; Burges, C.J. MNIST Handwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist (accessed on 6 January 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| ui, U | The i-th node, where U is a set of all nodes |
| N | The total number of mobile nodes |
| ni, n | |
| PSi | The processing score of ui |
| The global model parameter at iteration t | |
| Gi,j, G | The grid of row i and column j, where G is a set of all grids. |
| Ui,j | A set of nodes mapped to the grid Gi,j |
| Ci, C | The i-th cluster, where C is a set of all clusters. |
| ri | |
| mj,k | |
| Si | The share of ui for secure aggregation |
| The intermediate sum of Ci |
| Operation | Computational Costs | Communicational Overheads | |||
|---|---|---|---|---|---|
| Node | Server | Node to FS | FS to Nodes | ||
| Node clustering | O(1) | O(N) | O(1) | - | |
| Setup for aggregation—random nonce & training weight distribution to nodes | - | O(N) | - | O(N) | |
| Local update generation | Share of masks | - | |||
| Secure update generation | - | O(1) | - | ||
| Aggregation | All active nodes (no dropouts) | - | O(N) | O(1) | - |
| Recovery phase | O(N) | O(1) | - | ||
| Total cost for aggregation | O(N) | ||||
| Parameters | Values |
|---|---|
| The total number of nodes/ the number of nodes per each cluster | 100/ 25 |
| The number of clusters (C) | 1, 4 |
| Quantization level (qLevel) | 30, 100, 300 |
| Dropout rate (dr) | 0%, 30%, 50% |
| The size of prime p | 15 bits |
| PS level (PSL) | 1 ~ 4 |
| Training data ratio according to PS level | PSL1: 4.5%, PSL2: 18%, PSL3: 32%, PSL4: 45.5% |
| The number of iterations for federated learning | 100 |
| Dropout Rate (dr) | FCSA with C = 4 | FCSA with C = 1 | ||
|---|---|---|---|---|
| 50 Round Accuracy (%) | 100 Round Accuracy (%) | 50 Round Accuracy (%) | 100 Round Accuracy (%) | |
| dr = 0% | 86.22 | 91.08 | 80.13 | 87 |
| dr = 30% | 86.35 | 91.54 | 75.7 | 86.12 |
| dr = 50% | 85.02 | 91.25 | 72.08 | 79.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Park, G.; Kim, M.; Park, S. Cluster-Based Secure Aggregation for Federated Learning. Electronics 2023, 12, 870. https://doi.org/10.3390/electronics12040870
Kim J, Park G, Kim M, Park S. Cluster-Based Secure Aggregation for Federated Learning. Electronics. 2023; 12(4):870. https://doi.org/10.3390/electronics12040870
Chicago/Turabian StyleKim, Jien, Gunryeong Park, Miseung Kim, and Soyoung Park. 2023. "Cluster-Based Secure Aggregation for Federated Learning" Electronics 12, no. 4: 870. https://doi.org/10.3390/electronics12040870
APA StyleKim, J., Park, G., Kim, M., & Park, S. (2023). Cluster-Based Secure Aggregation for Federated Learning. Electronics, 12(4), 870. https://doi.org/10.3390/electronics12040870