


WGM-dSAGA: Federated Learning Strategies with Byzantine Robustness Based on Weighted Geometric Median



Abstract
:1. Introduction
2. Related Works
2.1. Gradient Descent Algorithms
2.2. Byzantine-Robust Aggregation Rules
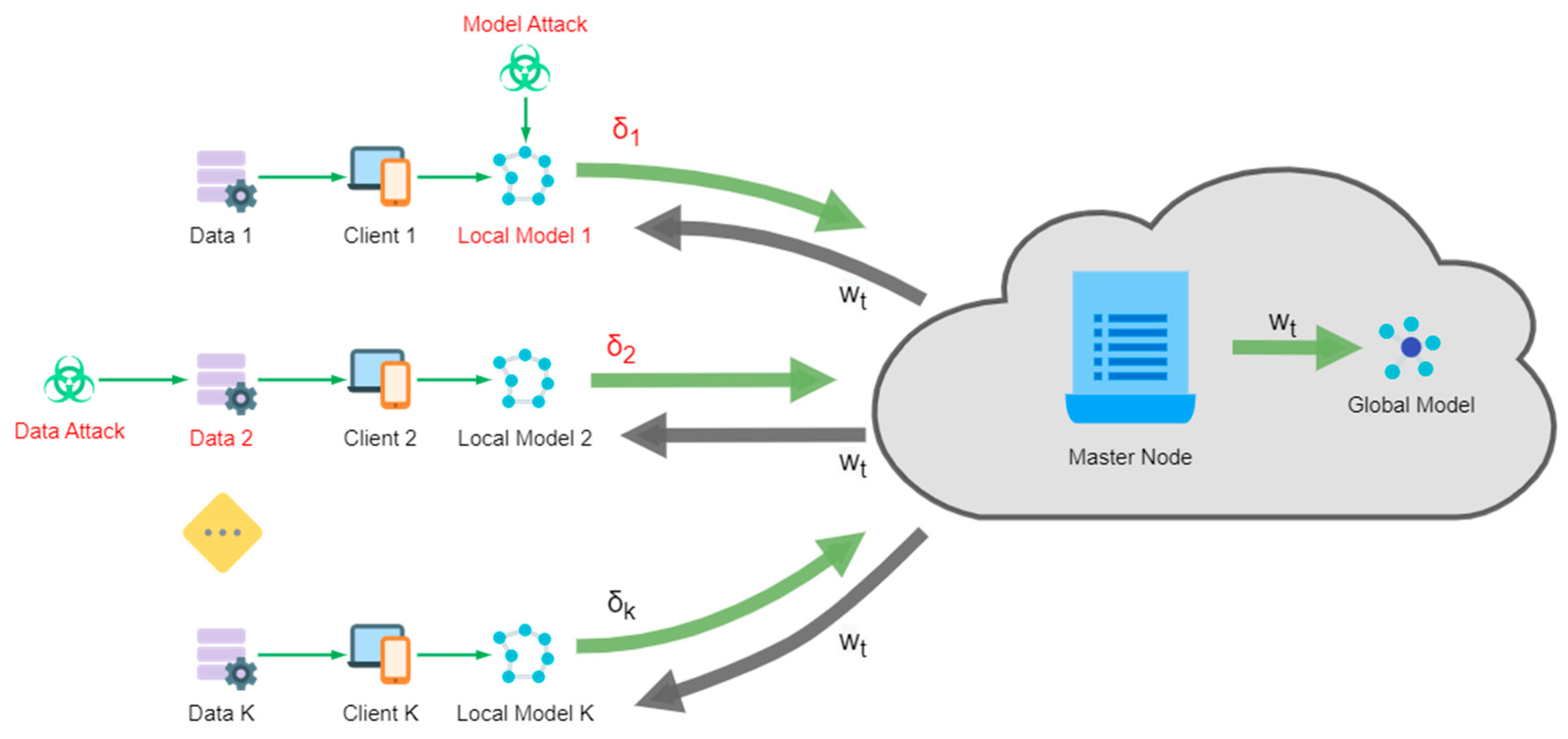
3. Proposed Methodology
| Algorithm 1: Robust aggregation rules based on weighted geometric medians |
| Require: learning rate ; number of clients ; number of data samples on every client ; number of iterations ; Master node and honest client initialize for all honest client do for do Initializes gradient storage end for Initializes average gradient Sends to master node end for Mater node updates for all do Master node broadcasts to all clients for all honest client node do Samples from uniformly at random Updates Sends to master node Updates Stores gradient end for for do Master node updates Master node updates Master node updates Master node updates Master node updates end for Master node updates end for |
3.1. Distributed SAGA with Mean Aggregation
3.2. Client Weights Based on the COPOD Outlier Detection
3.3. Robust Aggregation Rules Based on Weighted Geometric Medians
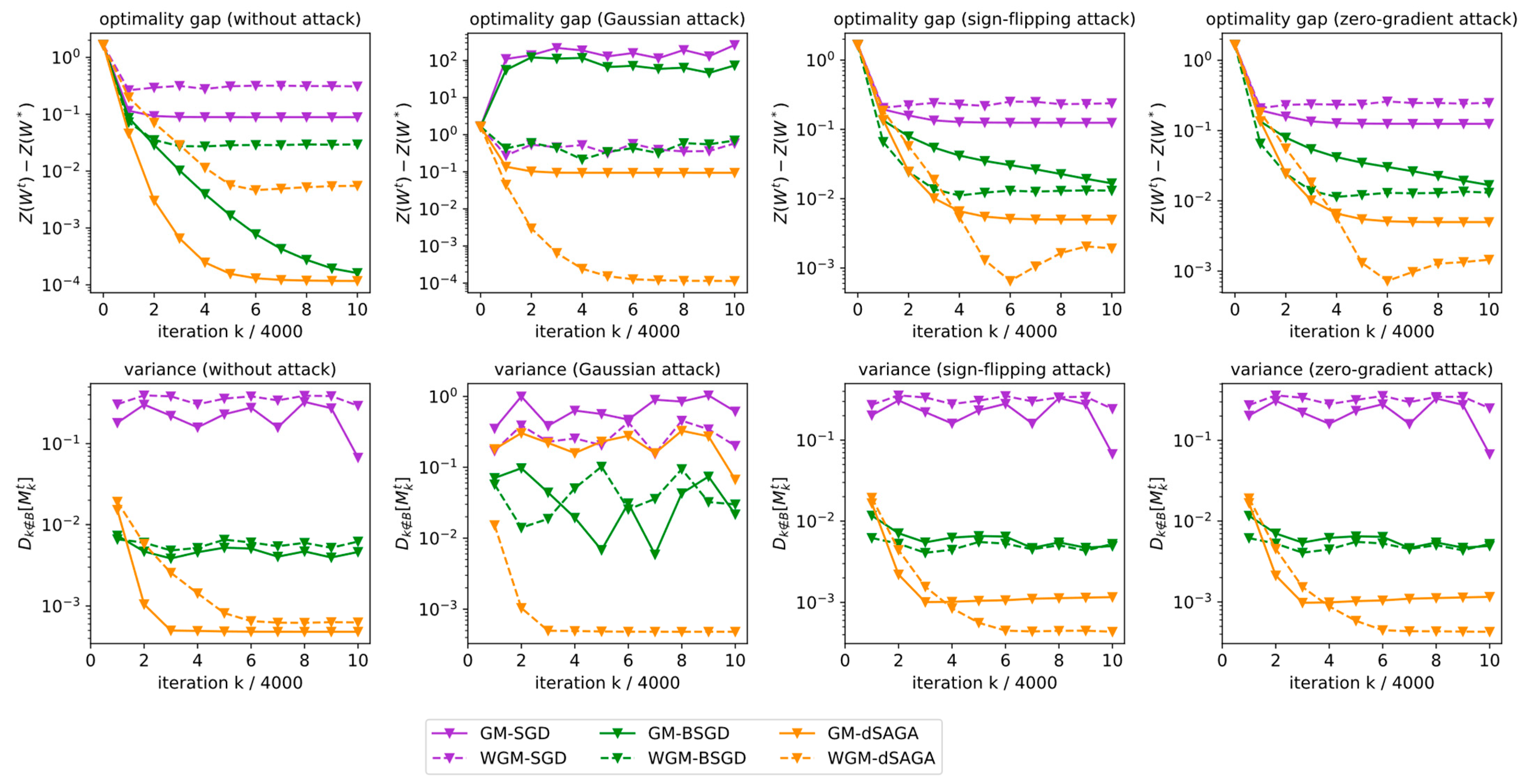
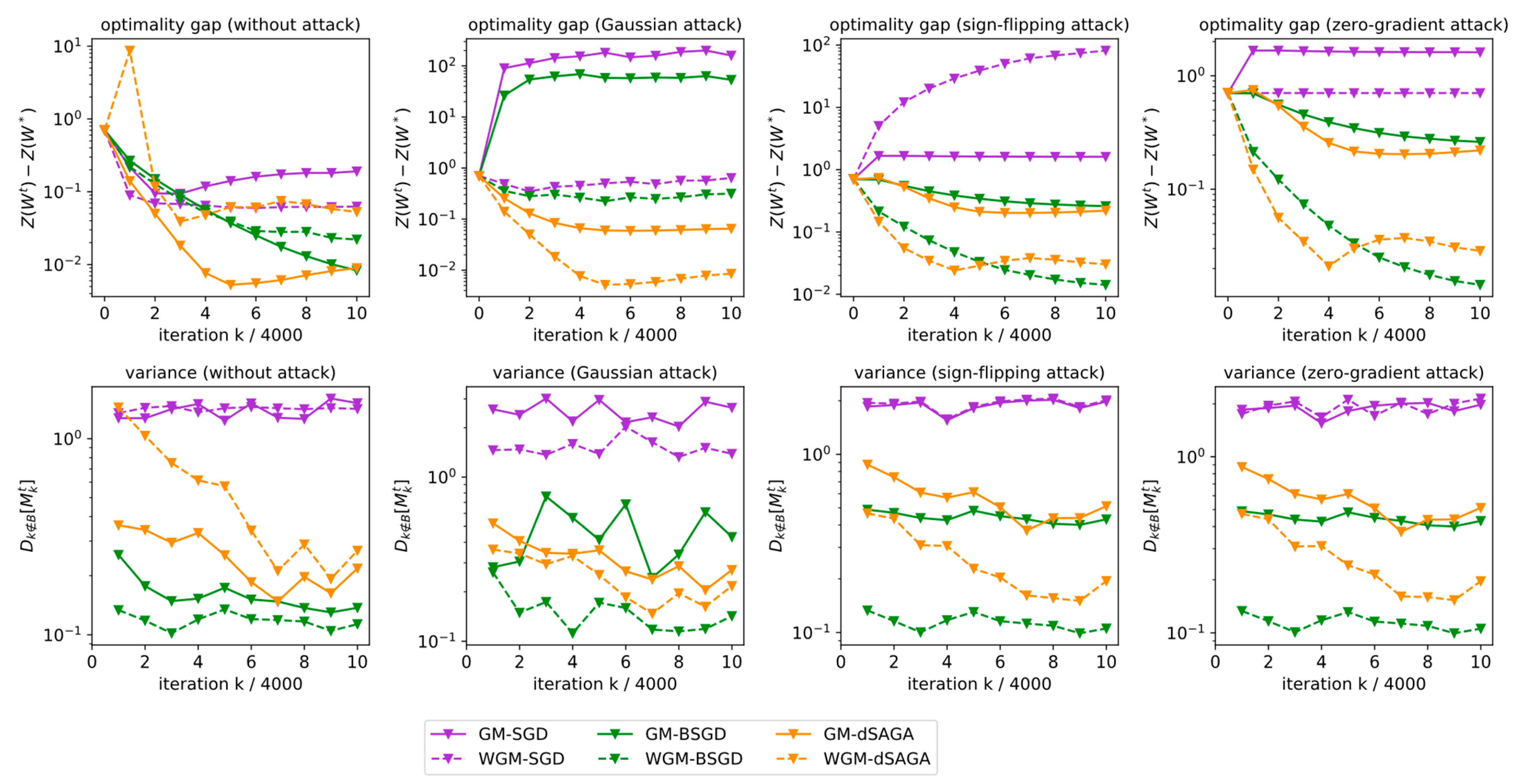
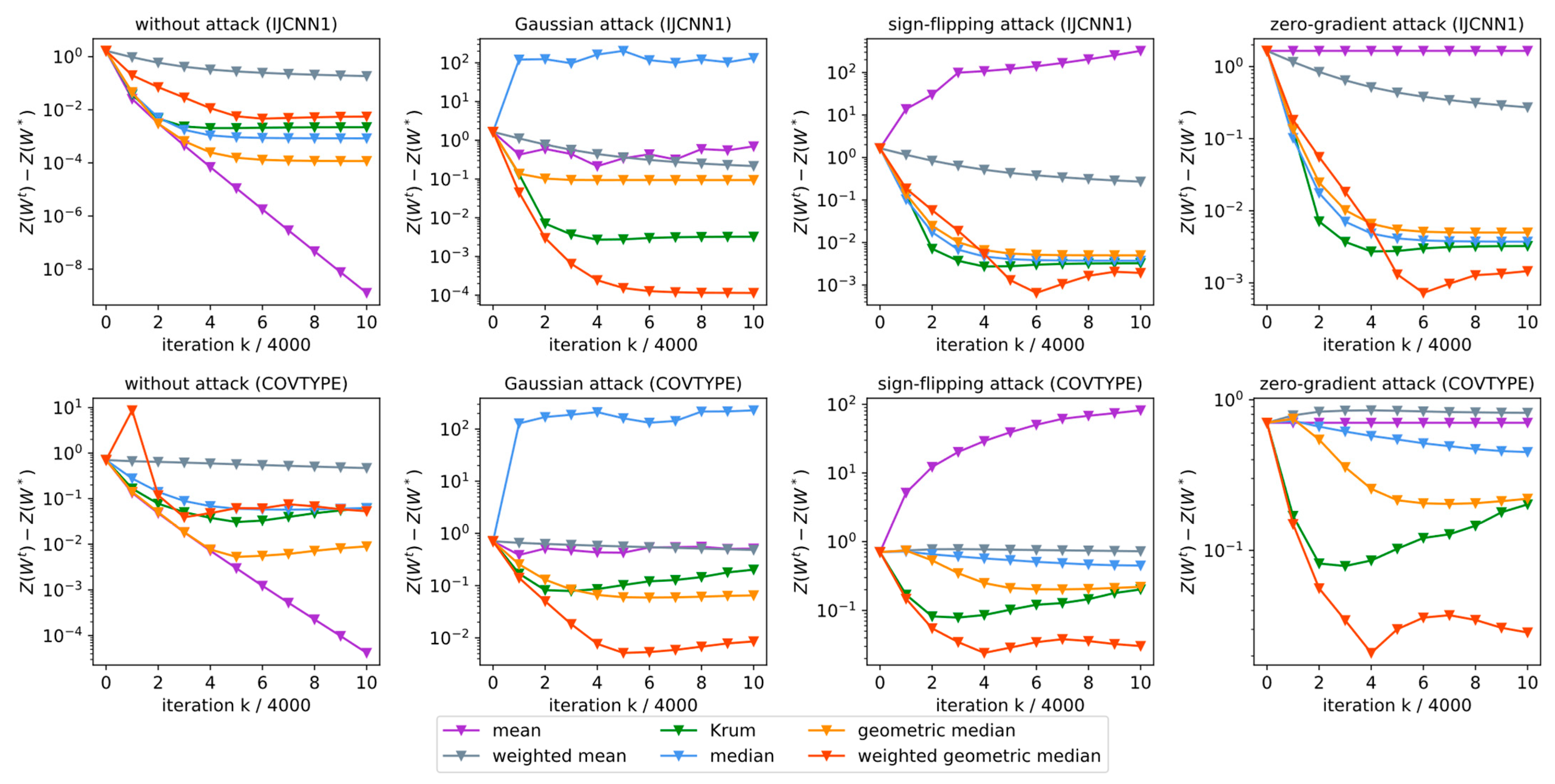
4. Numerical Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, Z.; Ling, Q.; Chen, T.; Giannakis, G.B. Federated Variance-Reduced Stochastic Gradient Descent with Robustness to Byzantine Attacks. IEEE Trans. Signal Process. 2020, 68, 4583–4596. [Google Scholar] [CrossRef]
- Yang, Z.; Gang, A.; Bajwa, W.U. Adversary-Resilient Distributed and Decentralized Statistical Inference and Machine Learning: An Overview of Recent Advances Under the Byzantine Threat Model. IEEE Signal Process. Mag. 2020, 37, 146–159. [Google Scholar] [CrossRef]
- Dolev, D.; Lamport, L.; Pease, M.C., III; Shostak, R.E. The Byzantine Generals; Van Nostrand Reinhold Co.: New York, NY, USA, 1987. [Google Scholar]
- Calauzènes, C.; Le Roux, N. Distributed SAGA: Maintaining linear convergence rate with limited communication. arXiv 2017, arXiv:1705.10405. [Google Scholar]
- Chen, Y.; Su, L.; Xu, J. Distributed Statistical Machine Learning in Adversarial Settings: Byzantine Gradient Descent. ACM SIGMETRICS Perform. Eval. Rev. 2018, 46, 96. [Google Scholar] [CrossRef]
- Yin, D.; Chen, Y.; Ramchandran, K.; Bartlett, P. Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust Aggregation for Federated Learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Fang, M.; Cao, X.; Jia, J.; Gong, N.Z. Local Model Poisoning Attacks to Byzantine-Robust Federated Learning. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- Li, Z.; Zhao, Y.; Botta, N.; Ionescu, C.; Hu, X. COPOD: Copula-Based Outlier Detection. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 1118–1123. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Yu, T.; Liu, X.-W.; Dai, Y.-H.; Sun, J. Stochastic Variance Reduced Gradient Methods Using a Trust-Region-Like Scheme. J. Sci. Comput. 2021, 87, 5. [Google Scholar] [CrossRef]
- Shang, F.; Zhou, K.; Liu, H.; Cheng, J.; Tsang, I.W.; Zhang, L.; Tao, D.; Jiao, L. VR-SGD: A Simple Stochastic Variance Reduction Method for Machine Learning. IEEE Trans. Knowl. Data Eng. 2020, 32, 188–202. [Google Scholar] [CrossRef] [Green Version]
- Defazio, A.; Bach, F.; Lacoste-Julien, S. SAGA: A Fast Incremental Gradient Method with Support for Non-Strongly Convex Composite Objectives. Adv. Neural Inf. Process. Syst. 2014, 2, 1646–1654. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. Comput. Sci. 2012. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. Int. Conf. Learn. Represent. 2014. [Google Scholar] [CrossRef]
- Tran, H.; Zhang, G. AdaDGS: An adaptive black-box optimization method with a nonlocal directional Gaussian smoothing gradient. arXiv 2020, arXiv:2011.02009. [Google Scholar]
- Ilboudo, W.E.L.; Kobayashi, T.; Matsubara, T. AdaTerm: Adaptive T-Distribution Estimated Robust Moments towards Noise-Robust Stochastic Gradient Optimizer. arXiv 2022, arXiv:2201.06714. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, M.; Wu, Y.; Zheng, N. Deep Model Poisoning Attack on Federated Learning. Future Internet 2021, 13, 73. [Google Scholar] [CrossRef]
- Xie, C.; Koyejo, O.; Gupta, I. Generalized Byzantine-tolerant SGD. arXiv 2018, arXiv:1802.10116. [Google Scholar]
- Su, L.; Xu, J. Securing Distributed Machine Learning in High Dimensions. arXiv 2018, arXiv:1804.10140. [Google Scholar]
- Blanchard, P.; Mhamdi, E.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, L.; Xu, W.; Chen, T.; Giannakis, G.B.; Ling, Q. RSA: Byzantine-Robust Stochastic Aggregation Methods for Distributed Learning from Heterogeneous Datasets. arXiv 2018, arXiv:1811.03761. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Ngai, E.; Voigt, T. Byzantine-Robust Aggregation in Federated Learning Empowered Industrial IoT. IEEE Trans. Ind. Inform. 2023, 19, 1165–1175. [Google Scholar] [CrossRef]
- Jadbabaie, A.; Li, H.; Qian, J.; Tian, Y. Byzantine-Robust Federated Linear Bandits. arXiv 2022, arXiv:2204.01155. [Google Scholar]
- Li, X.; Qu, Z.; Zhao, S.; Tang, B.; Lu, Z.; Liu, Y. LoMar: A Local Defense Against Poisoning Attack on Federated Learning. arXiv 2022, arXiv:2201.02873. [Google Scholar] [CrossRef]
- Weiszfeld, E.; Plastria, F. On the point for which the sum of the distances to n given points is minimum. Ann. Oper. Res. 2008, 167, 7–41. [Google Scholar] [CrossRef]
- Alkhunaizi, N.; Kamzolov, D.; Takáč, M.; Nandakumar, K. Suppressing Poisoning Attacks on Federated Learning for Medical Imaging. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2022, Singapore, 18–22 September 2022; pp. 673–683. [Google Scholar]
- Cohen, M.B.; Tat Lee, Y.; Miller, G.; Pachocki, J.; Sidford, A. Geometric Median in Nearly Linear Time. arXiv 2016, arXiv:1606.05225. [Google Scholar]
- Lin, F.; Ling, Q.; Xiong, Z. Byzantine-resilient Distributed Large-scale Matrix Completion. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8167–8171. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
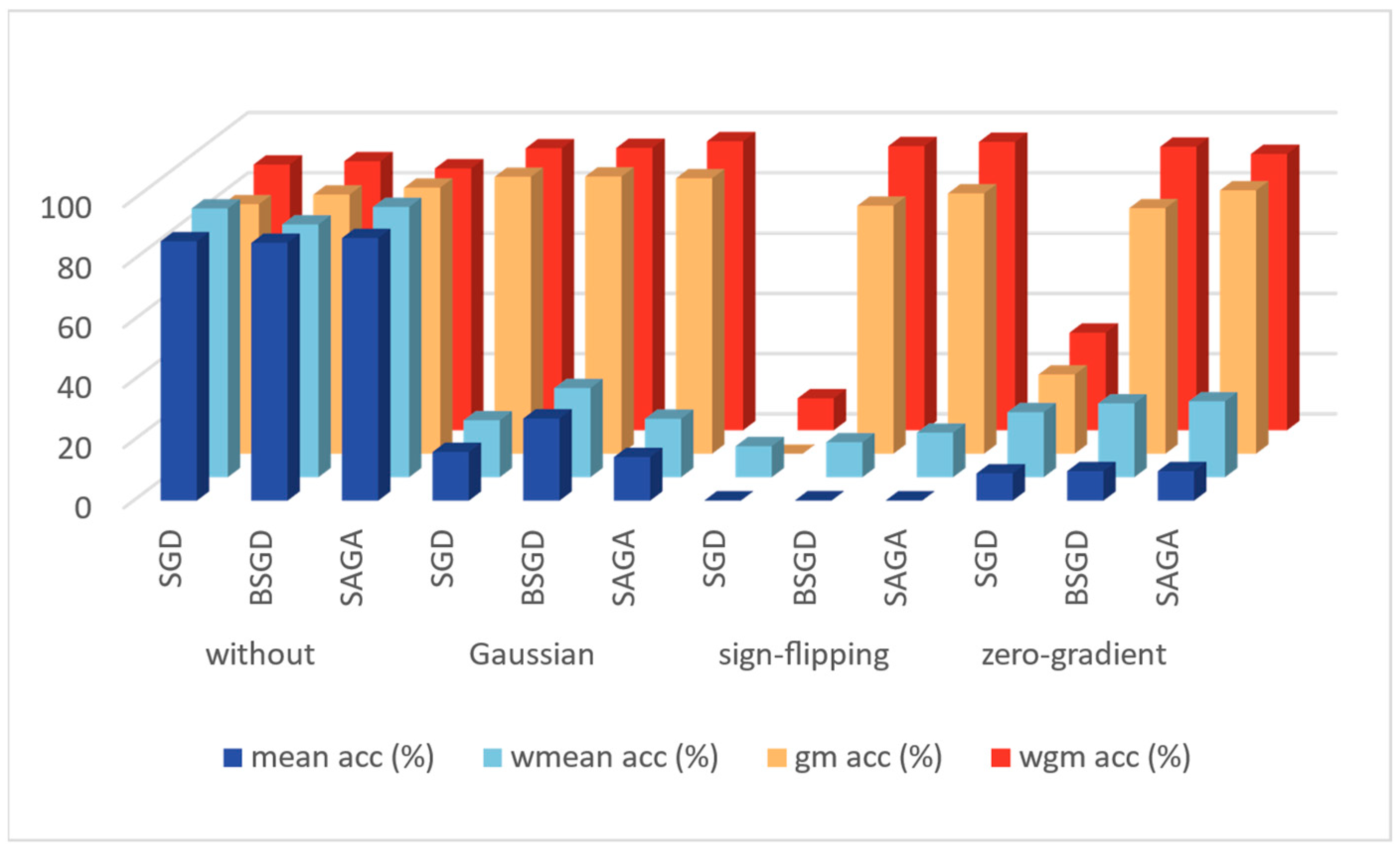
| Attack | Algorithm | Mean Acc (%) | Wmean Acc (%) | Gm Acc (%) | Wgm Acc (%) |
|---|---|---|---|---|---|
| without | SGD | 86.1 | 89.2 | 82.8 | 88.2 |
| BSGD | 85.6 | 83.9 | 86.0 | 89.3 | |
| SAGA | 87.2 | 89.7 | 88.3 | 86.9 | |
| Gaussian | SGD | 16.2 | 18.9 | 91.9 | 93.6 |
| BSGD | 27.3 | 29.6 | 92.0 | 93.7 | |
| SAGA | 14.5 | 19.4 | 91.4 | 95.9 | |
| sign-flipping | SGD | 0.12 | 10.3 | 0.02 | 10.6 |
| BSGD | 0.16 | 11.6 | 82.3 | 94.3 | |
| SAGA | 0.12 | 14.8 | 86.4 | 95.7 | |
| zero-gradient | SGD | 9.07 | 21.6 | 26.3 | 32.4 |
| BSGD | 9.83 | 24.5 | 81.5 | 94.1 | |
| SAGA | 9.82 | 25.2 | 87.4 | 91.7 |
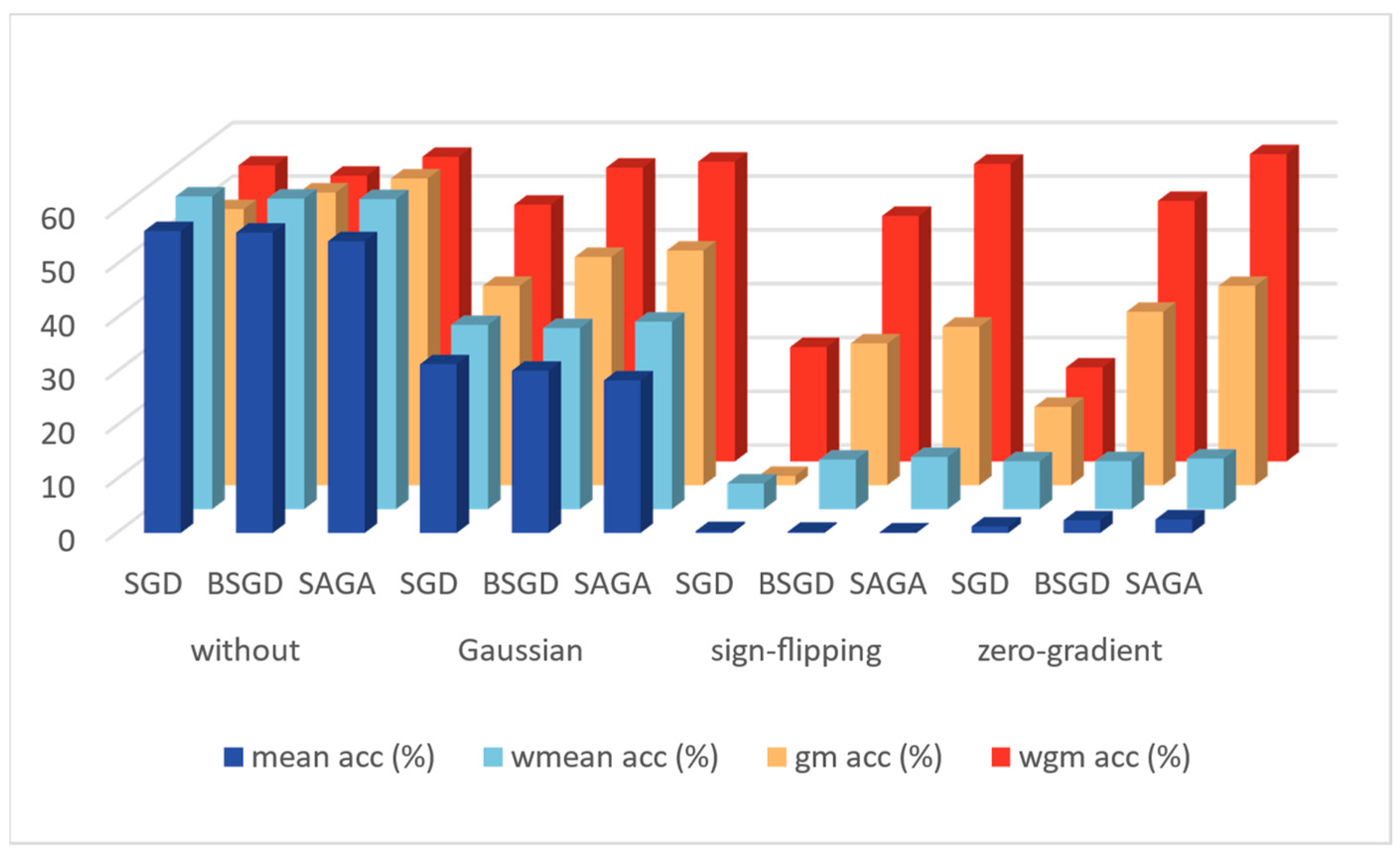
| Attack | Algorithm | Mean Acc (%) | Wmean Acc (%) | Gm Acc (%) | Wgm Acc (%) |
|---|---|---|---|---|---|
| without | SGD | 56.2 | 58.2 | 51.4 | 55.1 |
| BSGD | 55.9 | 57.8 | 54.5 | 53.2 | |
| SAGA | 54.3 | 57.7 | 57.1 | 56.7 | |
| Gaussian | SGD | 31.4 | 34.3 | 37.1 | 47.8 |
| BSGD | 30.2 | 33.7 | 42.5 | 54.7 | |
| SAGA | 28.4 | 34.9 | 43.7 | 55.8 | |
| sign-flipping | SGD | 0.35 | 4.79 | 1.75 | 21.3 |
| BSGD | 0.23 | 9.23 | 26.4 | 45.7 | |
| SAGA | 0.12 | 9.71 | 29.5 | 55.4 | |
| zero-gradient | SGD | 1.22 | 8.91 | 14.6 | 17.5 |
| BSGD | 2.37 | 8.94 | 32.3 | 48.5 | |
| SAGA | 2.53 | 9.43 | 37.1 | 57.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhang, H.; Bilal, A.; Long, H.; Liu, X. WGM-dSAGA: Federated Learning Strategies with Byzantine Robustness Based on Weighted Geometric Median. Electronics 2023, 12, 1190. https://doi.org/10.3390/electronics12051190
Wang X, Zhang H, Bilal A, Long H, Liu X. WGM-dSAGA: Federated Learning Strategies with Byzantine Robustness Based on Weighted Geometric Median. Electronics. 2023; 12(5):1190. https://doi.org/10.3390/electronics12051190
Chicago/Turabian StyleWang, Xiaoxue, Hongqi Zhang, Anas Bilal, Haixia Long, and Xiaowen Liu. 2023. "WGM-dSAGA: Federated Learning Strategies with Byzantine Robustness Based on Weighted Geometric Median" Electronics 12, no. 5: 1190. https://doi.org/10.3390/electronics12051190
APA StyleWang, X., Zhang, H., Bilal, A., Long, H., & Liu, X. (2023). WGM-dSAGA: Federated Learning Strategies with Byzantine Robustness Based on Weighted Geometric Median. Electronics, 12(5), 1190. https://doi.org/10.3390/electronics12051190