1. Introduction
In machine learning, edge computing is becoming increasingly important, especially when potent devices, such as modern hybrid embedded systems, have shown a fantastic aptitude for high performance in their demanding processing requirements [
1]. Offline signature verification is one of the state-of-the-art biometric recognizable proof methodologies. Many systems of falsifiers and verifiers have emerged in recent years [
2]. Signature verification is still tough because no standard database is available for forgeries.
Though many script signature data sets, such as English, Latin, Chinese, Persian, Arabic, Hindi, and Bengali, are publicly available, no Urdu handwritten datasets are currently available in the literature. The purpose of this work is to solve the Urdu signature verification (USV) problem by utilizing cutting-edge machine learning methods. In the proposed framework, a majority voting (MV) algorithm is used to enhance accuracy. Majority voting needs an odd number of classifiers to vote accurately. The channel is split into two distinct parts—real and forged. The proposed model is evaluated using the public data set available in [
3] and the results are compared with other methods. The FAR and FRR equations are created using the MV algorithm. A 2D Gabor filter is improved as a sinusoidal signal modulated by a Gaussian function at a specific frequency and orientation. There are two directional components in the Gabor filter. A sinusoidal wave characterizes the Gabor filter’s drive reaction, which is increased by a Gaussian function [
4].
In this study, we consider Urdu, which is a mainstream South Asian dialect. “There are 250 million people who communicate in Urdu, around 130 million people live in Pakistan and India”. Urdu has 37 basic characters with a couple of enlargements to key characters, which makes a total of 41. Persian has 32 characters, and the Arabic script contains 28 characters. The main objective of the offline handwritten signature verification system is to improve the accuracy and minimize the error rate of the signature verification system. In a real-time situation, only 30% of forgeries can be identified. This means that the remaining 70% of forgeries in offline signatures still need to be cleaned up [
5]. This research is intended to propose an innovative, accurate, and efficient “offline signature verification system for Urdu handwritten signature”. The USV will confine itself to unique and manufactured signatures by relying upon some exceptional parts, such as length, pattern, and instance.
The Kaggle dataset in [
5] was used to compare and test for more public datasets. The Kaggle handwritten dataset contains the real and forged signatures of 30 people. Every person has five real signatures and five fake signatures from someone else. An image of an individual numbered 023’s signature made by user 06 is NFI-00602023. Due to potential authentication in fields such as crime prevention and forensic identification, signature verification has been a study area of interest in recent years [
6].
Recent advances in machine learning and artificial intelligence have enabled several intriguing insights into brain computation. Many scientists believe that deep neural networks will one day equip biological brains with theories of perception, cognition, and action [
7]. According to [
8], deep learning relies on the construction of multiple nonlinear functions modeling the intricate relationship between input characteristics and labels. While neural networks have been around for a while, improvements in the past several years have substantially enhanced their effectiveness in natural processing, computer vision, robotics, and decision-making [
7,
8].
A new hybrid model of two famous classifiers is presented in [
9]. SVM and CNN are used for handwritten digit recognition. The SVM and CNN are integrated by replacing the last output layer of the CNN with the support vector machine. In the experimental methodology, they use the well-known MNIST handwritten dataset to evaluate the presented model’s performance. The dataset contains 60,000 samples for the training set and 10,000 samples for the testing set. The KNN approach in [
10] is used for offline signature verification, and they implement their proposed technique using a public data set. In [
11], a strategy for directing a disconnected, manually written signature confirmation system is presented. In this paper, the creators apply a factual surface component. The conventional neural network is examined and used as an element. In [
12], the author proposes an automated method for identifying the surface condition of concrete structures using vision-based techniques, such as deep convolutional neural networks (CNNs), transfer learning, and decision-level image fusion [
12]. A comprehensive overview of recent deep-learning-based image colorization methods from several angles, such as color space, network structure, loss function, degree of automation, and application domains, is presented. Measures for gauging effectiveness are also covered [
13]. Deep learning techniques are used to determine the strength of RC beams against torsional loads. Two-dimensional CNN models are established based on the collected data. When compared to other machine learning models, building codes, and empirical formulas for predicting the torsional strength of RC beams, the proposed 2D CNN with hyperparameter optimization shows marked improvement [
14]. The handwritten verification dataset has been implemented in [
14] to compare the accuracy of our proposed solutions. In the end, CNN is also included in the proposed solution.
In [
15], the authors also use KNN for signature verification. For the training [
16] and testing of their proposed methodology, they use MCYT-75 and GPDS public databases for their result. An offline Japanese signature verification has been proposed [
16,
17]. This paper proposes a transformed example matching strategy, free of stroke widths, and a suitable determination system. The trial results demonstrate that the proposed techniques enhance the confirmation execution and the exactness of the estimation under a 0.16 FRR. S. In [
18], an Arabic signature oracle database for signature verification is presented with geometrical features for signature feature extraction, and in the verification phase, SVM is used for the results [
19].
In [
20], a system for verification and authentication is presented. This particular system differentiates between individuals and recognizes them based on their style. The second goal is to narrow the search to identify the gender in the database.
Biometric signatures based on handwriting have been the subject of debate in the scientific community. There has been a lot of work conducted on expanding the use of handwritten signature analysis and processing systems. A comprehensive literature review of offline handwritten signatures published over the past decade [
21] zeroed in on cutting-edge techniques for authenticating signatures using deep learning.
A comprehensive study on ensemble-based classifiers in [
22] is presented, and the main idea of this study was to review existing methodologies. This study can be used as a tutorial for new researchers who are working on ensemble-based systems. In the system, four blocks are introduced [
23]. The key factors are accuracy, computational cost, scalability, and flexibility. The ensemble is highly diverse, and the choice of combination also grants better performance and accuracy of the system [
24].
An approach is proposed in [
25] for the recognition of objects from datasets of images. The presented approach is a combination of two SVM and KNN [
26]. To identify and categorize potential IoT devices in the future, the DeepClassifier deep neural network has been proposed. Initial work proposes a likelihood-based approach and demonstrates that it is optimal in the asymptotic limit of the observations, despite its high computational complexity [
27]. Though feature-based classification methods claim to be simple, designing efficient features can be challenging [
28]. The proposed DeepClassifier is divided into two stages: the first processes a single observation; the second combines the results of multiple classifications [
29].
For signature verification problems, we propose a novel hybrid machine learning system for testing handwritten signature verification. A new Urdu handwritten signature database is created, and a framework is proposed for data acquisition, pre-processing, feature extraction, and hybrid classification. It achieves high accuracy for signature verification problems.
This paper is organized into four sections.
Section 1 includes the Introduction and a background study.
Section 2 includes the Material and Methods.
Section 3 comprises the proposed methodology and Results.
Section 4 describes this research’s Conclusion and future work.
2. Materials and Methods
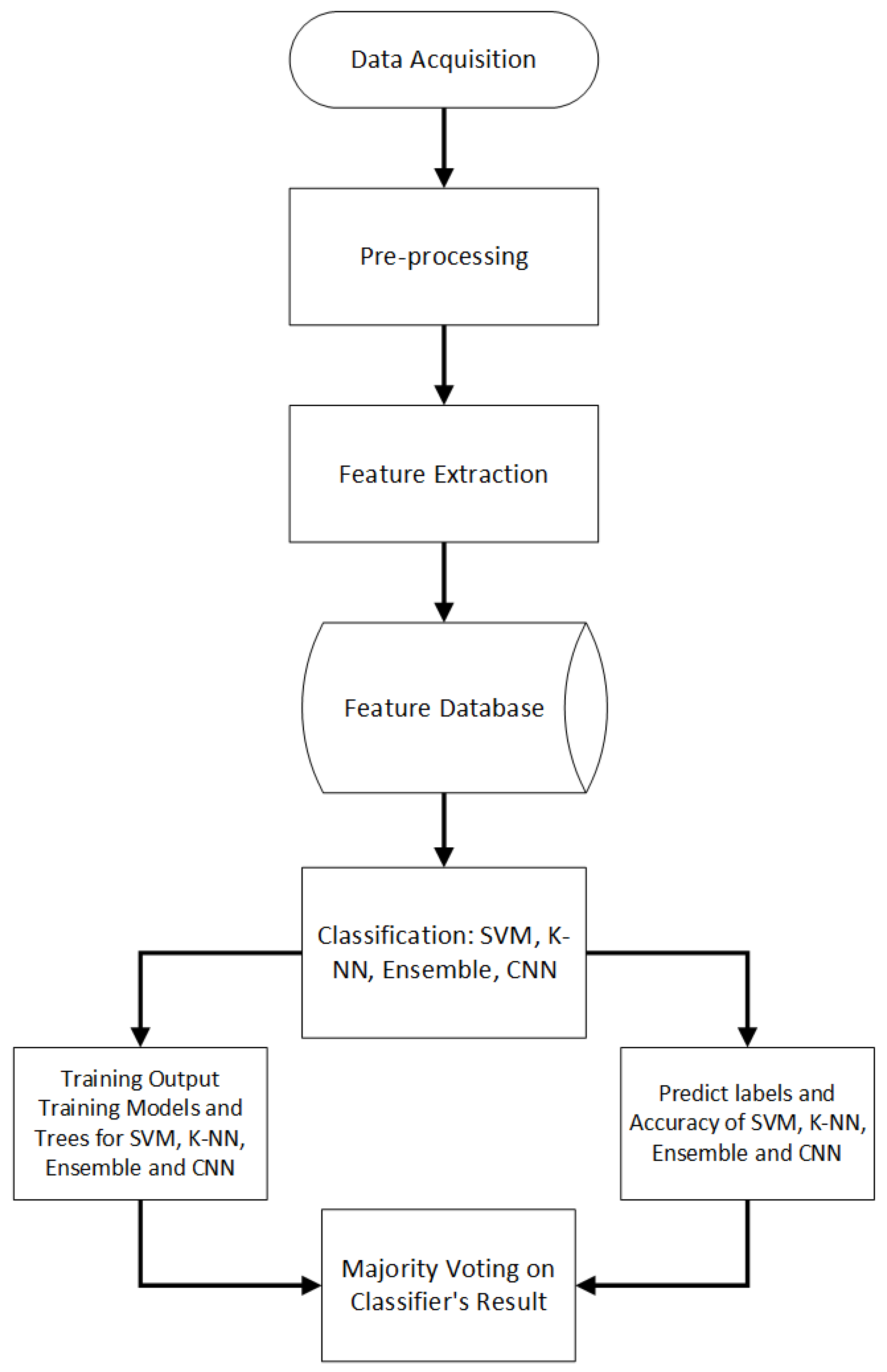
We proposed a group of classifiers for “offline Urdu handwritten signature verification” to enhance its prediction ability. This system comprises five steps: “Data Acquisition, Pre-processing, Feature Extraction, Signature Registration, and Signature Verification” [
30]. A histogram was used in data acquisition [
31]. Pre-processing includes noise removal, binarization, smoothing, and thinning. Signature verification has KNN, SVMs, and ensemble classifiers.
Figure 1 describes the proposed system for UHSV.
2.1. Classification Selection
This hybrid approach is based on the observation that when using KNN for handwritten character recognition, the correct class is almost always one of the two nearest neighbors of the KNN. An SVM is used to predict the accuracy of the class between two diverse classification assumptions. The embedded hybrid system of KNN, SVM, and ensemble classifiers results in significant changes in confirmation rates [
32].
2.2. Hyperparameters of Classifiers
The convolutional neural network (CNN) uses two Conv2D layers followed by two MaxPooling2D layers, two Dense layers, and a Dropout layer. The CNN uses the ReLU activation function for the Conv2D and Dense layers, and the Softmax activation function for the output layer. The first Conv2D layer has 64 filters with a kernel size of (3, 3), which means that the layer will learn 64 different 3 × 3 convolutional filters to extract features from the input images. The second Conv2D layer has 32 filters with the same kernel size, which means it will learn 32 different filters to extract more abstract features from the previous layer’s output. The MaxPooling2D layers reduce the dimensionality of the feature maps produced by the Conv2D layers. The first MaxPooling2D layer has a pool size of (3, 3), which means it will reduce the feature map size by a factor of 3 × 3, and the second MaxPooling2D layer has a pool size of (2, 2), which means it will reduce the feature map size by a factor of 2 × 2 [
33]. The two Dense layers consist of 128 and 1 units and are connected to the flattened output of the second MaxPooling2D layer. The first Dense layer uses the ReLU activation function, which introduces non-linearity to the model and helps it to learn more complex representations. The second Dense layer has one unit and uses the Softmax activation function to produce a probability score for each of the two classes. The input images are resized to 224 × 224 with 3 color channels, which is a common image size used in CNNs [
34].
The KNN classifier uses Models 5, 10, and 15 with seed = 7, 14, and 21, Kfold = 3, and hp-candidates = n-neighbor was (n, 2,3,4,5,6,7). The best hyperparameters for KNN were hp-candidate, (n, 3); seed, 21; and input model, 15. SVM uses 3 types of hyperparameters: learning rate = 0.2; subsample = above 7; hyperplane = 255 × 255; and SVM models = (5, 10, 15). The SVM best model hyperparameter was 15. The ensemble uses trees instead of models. A total of 200 trees were generated, such as (0, 20, 40, 60, 80, 100, 120, 140, 160, 180, 200), and an ensemble uses these trees to generate different bags. The number of bags is similar to the number of trees. The total number of bags = (0, 20, 40, 60, 80, 100, 120, 140, 160, 180, 200). The best oob-loss was 0.65, and the reuse oob-loss at 200 trees was 0.00001. The best performance of the ensemble classifiers was achieved with the reuse oob-loss at 200 trees.
To create the hyperplane, SVM picks the most extreme points and vectors possible [
35], while the parameters of SVM are kernels. The KNN method assigns an input sample to a category determined by which of the K closest samples it most closely resembles [
36]. The KNN classifier uses the minimum distance to K neighbors to determine the output class [
37] for a given input sample by performing the following steps: it finds the average distance Ti ∈ T between both the input data set and all the training samples. Euclidean distance
is used as the parameter to find the nearest distance between the two points. Ensemble learning is an effective method of machine learning that combines numerous independent models (called base models) into a single superior prediction model. KNN is also used to generate the embedding of the system. In the proposed system, we generated user embedding and found items that are most relevant to it. In the testing phase, the most similar signature image was tested. This method is a computationally expensive operation by performing O(NxK), where N is the number of items, and K is the size of each embedding.
The ensemble classifier is used to improve accuracy over a typical classifier by combining the predictions of multiple classifiers. Bagging, often called bootstrap aggregating, is the process of combining results from several iterations of a predictive model. The independent training of models is followed by an averaging step. Using bagging, one hopes to reduce variability more than would be possible using a single model. If you want to estimate a parameter of a population, you can use a technique called “bootstrapping,” which involves drawing samples at random from the population and replacing some of the data with new data. Initially, bootstrap samples are generated in bagging. Each sample is then processed by a regression or classification technique. For classification, the result is either the class with the most votes (hard voting) or the class with the highest average probability. This is where aggregation has a role in this context. Bagging mathematically can be represented as: .
2.3. Pre-Processing
For experiments, signatures were taken on white papers from signers. Every single signer signed their signature five times. Three different forged signatures were generated by professional writers: random, skilled, and straightforward. Eight signatures from one signer were collected at the end of one sheet of paper. A total of 21 people took part in the sign-up for database creation. The first task was to convert all hardcopy text signatures into softcopy images. The viability of the feature extraction stage relies on image scanning quality. Four steps of pre-processing were used in this proposed solution: (i) Noise removal—the noise removal function converts it to grayscale. The noise is removed using the wiener2 function; (ii) binarization—image binarization is the conversion of an image into two black-and-white colors; (iii) smoothing—Gaussian smoothing filters are commonly used to reduce noise; and (iv) thinning—a thinning procedure makes signatures, lines, and curves thinner and more precise. To prepare signature images from K, the image is binarized, and the noise from the signature image is removed. In the next step, the signature image is smoothed, and then, the image is thinned. These steps will also be repeated for images K and r until pre-processed image data are clear.
Pixel
p0 must be explored; when pixel
p0 is a bit of a skeleton, pixel
p0 will be deleted or not eradicated by conditions. Regardless, in a one-way handle, the estimation of pixel
p0 should be set to another concern, for instance, −1, as shown by Hilditch’s calculation [
37], set to 0 until all pixels in the photo are examined along these lines. At this point, the procedure is rehashed until no advancements are made.
Figure 2 contains the handwritten signature images of Urdu script which are used in the pre-processing phase of the proposed system.
2.4. Feature Extraction
One of the important parts of this study is feature extraction. Feature extraction is an essential part of any image processing to increase the performance of embedded systems [
38]. Many researchers use different feature extraction techniques to extract features from images. The standard feature extraction methods were already discussed above. We used the Gabor wavelet method for feature extraction [
9,
36]. The method, which is used for generating embeddings in the proposed system, is called principal component analysis (PCA), which was used in feature extraction. PCA reduces the dimensionality of an entity by compressing variables into a smaller subset. This allows the model to behave more effectively. The novelty of the feature extraction phase is that it extracts features from multiple signature images from a single signer and saves them into a single file. This will be used to compare the testing signature at the verification phase. This strategy helps reduce the verification complexity of classifiers. This research uses a feature of interest that improves the proposed system’s performance. A single image’s extracted features are 25,000. We used a feature of interest to overcome this massive number of features, making the system more reliable and accurate. The Gabor filter function drive reaction is characterized by a sinusoidal wave (a plane wave for 2D Gabor channels) increased by a Gaussian function. The channel has an imaginary and a real segment in orthogonal directions. The two parts may be framed into a complex number or be utilized separately.
Here, the pre-processed image from K is read, and then, the Gabor wavelet function for feature extraction with the parameter c to extract the features of interest from the extracted features is applied. The c from column to row is converted. All these processes will be repeated for images K and R until all of the features are extracted. In this mathematical statement, lambda (λ) expresses the wavelength of the sinusoidal component, theta speaks to the introduction of the ordinary to the corresponding lines of a Gabor capacity, psi is the stage balance, sigma is the sigma/average deviation in the Gaussian cover, and gamma is the 3D angle proportion, which indicates the sphericity of the backing of the Gabor filter. The Gabor filter is a process for every image to extract features. By utilizing a filter bank for analysis and a decimation process, DWT can be used to examine a picture. Each decomposition level is represented in the analysis filter bank by a pair of low- and high-pass filters. While the high-pass filter is responsible for extracting finer features such as edges, the low-pass filter is responsible for obtaining the rougher, more general information in the image. DWT has two levels: one for edge detection and one for image denoising. The Gabor filter function is used as a mother wavelet function in DWT. The use of a linear filter known as a Gabor filter makes feature extraction in image processing tasks easier. It is a bandpass filter, so it only lets through signals within a certain frequency range and mutes everything else.
2.5. Training
The extracted features are saved in the directory for classifier training and testing as calculated features. The reason for saving these features is to reduce the time required for feature extraction. All calculated features are saved with the same name as their labeled classes, A to U, which means 1 to 21 people. The training and testing algorithm read the calculated features c and labels l from k and divide the calculated features and labels into three datasets. The taring time is more than the existing methods. A challenging task is creating a system that is effective and efficient for data collection. The databases’ volume increases exponentially and quickly becomes unmanageable; therefore, the core of intelligent solutions is to reduce the raw data to sparse forms without losing crucial information. Hybrid classifiers for training are applied: SVM, KNN, and ensemble. Now, the system will read the calculated features c from r, then divide the calculated features c from r into three data sets. Handwritten classification and verification are significant and challenging problems due to two main factors. First, because signature consistency is frequently lacking, intra-personal variations in speed, pressure, and inclination can be significant. Second, there are not any forgeries, and we can only obtain a limited number of samples from a single person. Therefore, it is challenging to evaluate the dependability of retrieved features. The limitation of this framework is pre-processing computational time and cost.
2.6. Hybrid Classifier for Training and Testing
We proposed a novel hybrid classifier combining SVM, KNN, ensemble, and CNN. At the result stage, we took all the results and combined them. In addition, we implemented a new approach to obtain the actual and highly rated results. The MV algorithm was employed to achieve this task. The hybrid classifier helps achieve better performance and more accurate results. For the training phase, we labeled the target classes with every member’s signature that we had taken before. These labels with extracted features from the Gabor filter were given an arrangement of training samples generally denoted by extracted features or “vectors”. Every training set was named with a target class, an individual’s signature from a limited and typically small arrangement of labeled classes. The objective of supervised learning is to correctly predict the class labels of samples in the testing phase. This method was repeated for every classifier in the hybrid approach, and the MV method is applied to achieve the accuracy of the proposed system. All the data sets are used to make a base classifier, and the “majority voting” of these base classifiers decides the final prediction of the character.
3. Results
For experiments, we created an Urdu handwritten signature dataset for testing the performance of our proposed embedded system. The data were collected from 21 individuals. Each person was asked to sign his or her signature six times correctly, the same as he or she could. This dataset was saved as a genuine signature database. We asked some writing experts to sign these signatures as a random, skilled, and straightforward forgery of forged handwritten signatures and saved them in the forged handwritten signature database. We had six genuine and three forged handwritten signatures for each person. So, nine from one person, and 9 × 21 = 189. This dataset was divided into 70% and 30% for training and testing, respectively.
For the training of “KNN, SVM, ensemble, and CNN classifiers”, the training set consisted of 70% of the dataset and was divided into three sub-models for better training. All handwritten signatures were labeled correctly. All labeled and analyzed features had inputs for “KNN”, “SVM”, and “ensemble classifier’s training”. The training models were saved separately.
3.1. Testing
Individual testing was conducted on each classifier, 30% of the entire dataset was used as the testing set and 70% as the training set. In the KNN and SVM classifiers, the training was done in three sub-models called Model 5, Model 10, and Model 15. Model 5 used 33% of the training set, Model 10 used 66% of the training set, and Model 15 used the whole training set. The purpose was for comparison and increase of the accuracy of the verification process. The overall accuracy includes testing results from all training and testing data.
Figure 3 demonstrates the accuracy of KNN in various models. This methodology required additional time but reduced the overall computational cost. The accuracy of KNN Model 5 is the highest, at 89.23%. The overall accuracy is 86.34%.
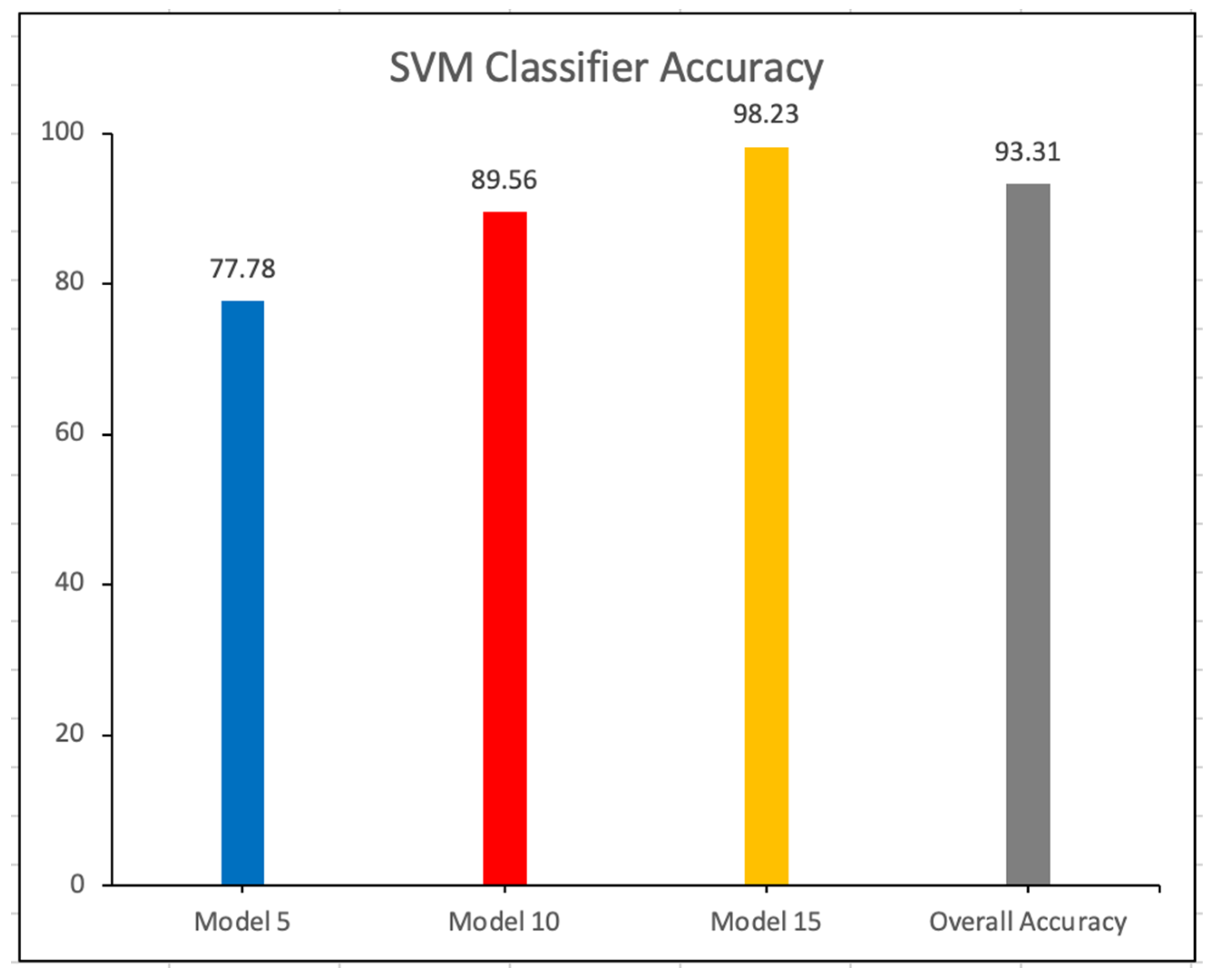
The testing was also implemented with an SVM classifier.
Figure 4 shows the accuracy of the SVM classifier in different models. The accuracy of the SVM classifier is 93.31%.
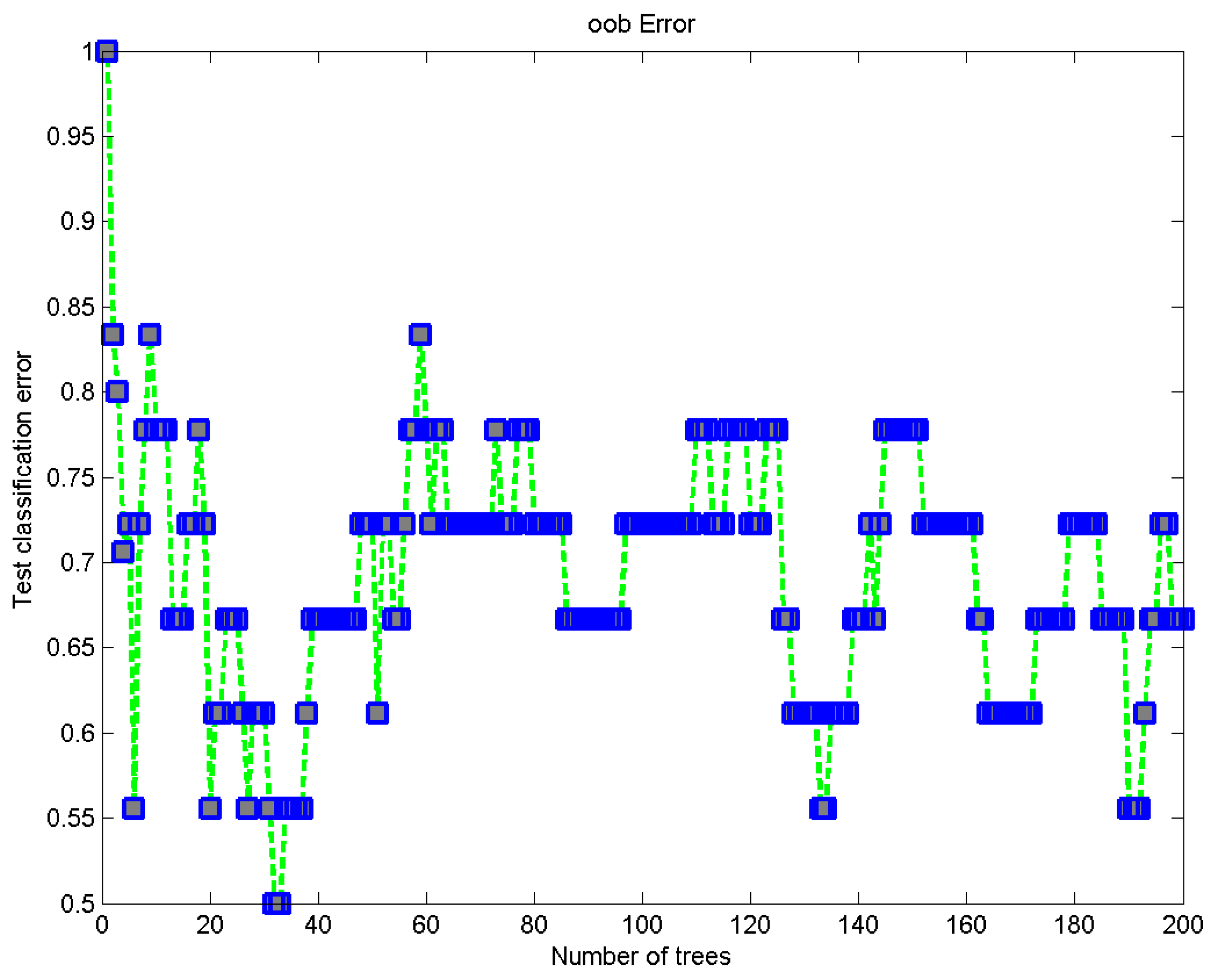
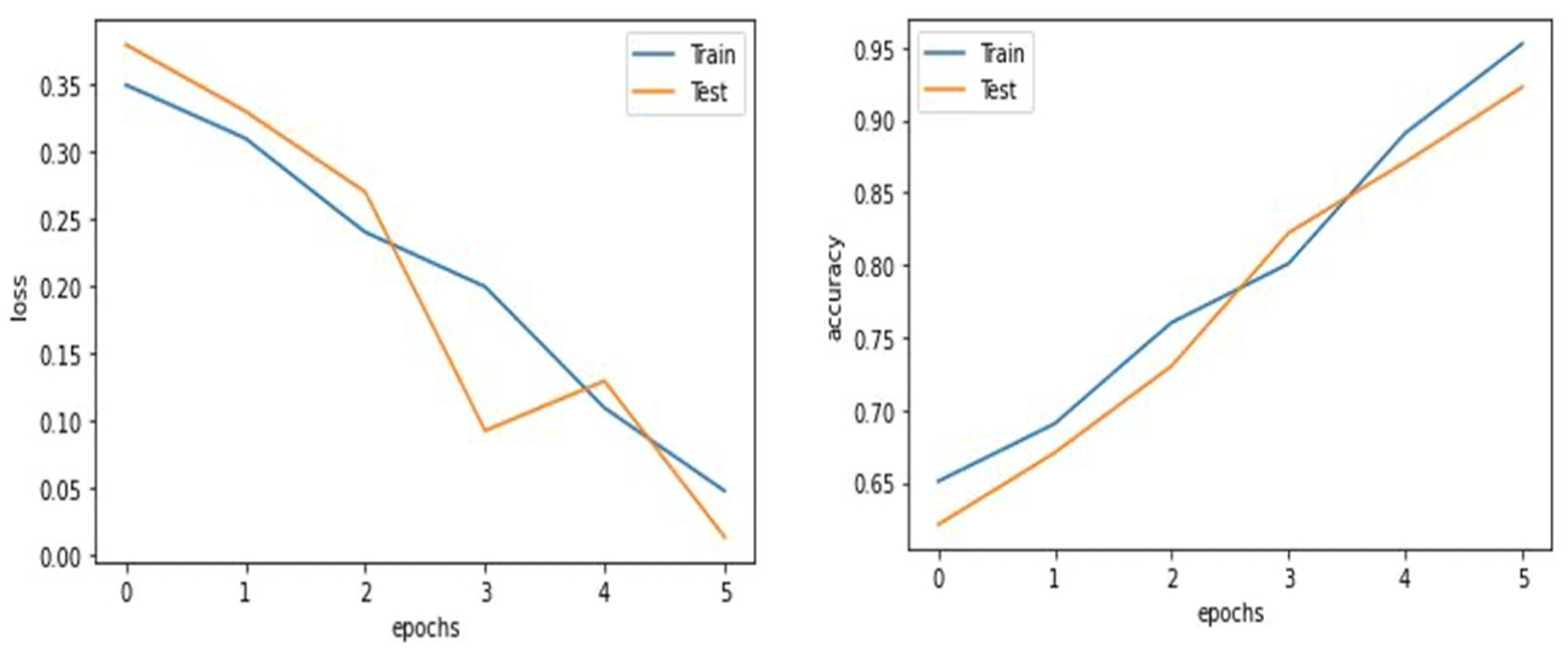
The testing was implemented with an embedded ensemble classifier, but the ensemble classifier had a different procedure. The ensemble classifier uses distinctive trees instead of models. Two further losses were calculated while testing with the embedded ensemble classifier.
Figure 5 shows the loss of ensemble training, and
Figure 6 shows the accuracy of the ensemble
3.2. CNN
The proposed model now includes a sizable dataset that can be utilized for the training and testing and the CNN model used in offline signature verification is presented in
Figure 7. CNN has been trained and tested as presented in
Figure 8. CNN achieved the accuracy of 95.05% on private dataset and 95.27% on public dataset.
3.3. Majority Voting (MV)
Many voting algorithms have been used in [
37] biometric authentication applications. It is used when we need to find the majority element (a value predicted by the classifier) from the predictions of multiple classifiers.
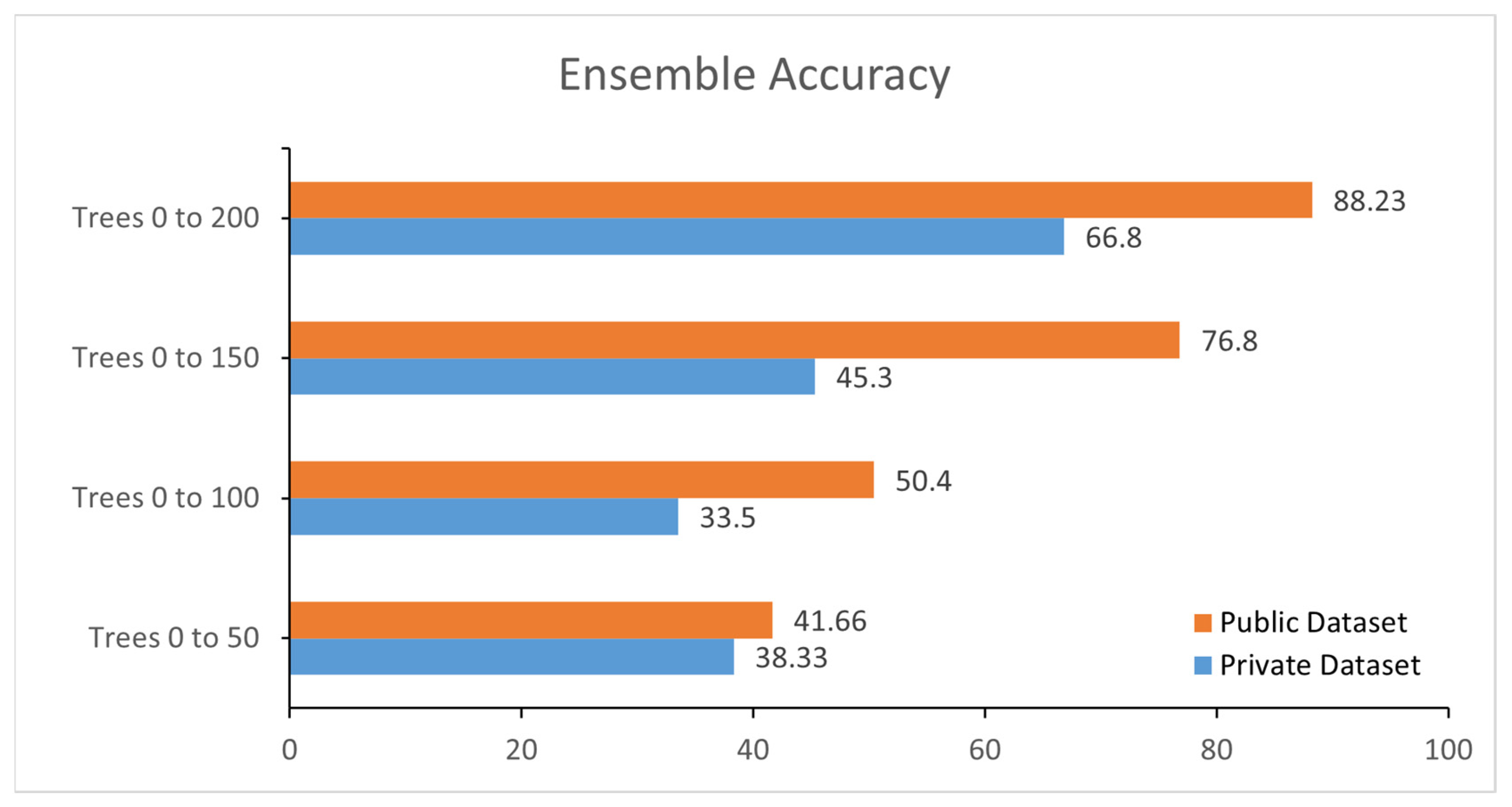
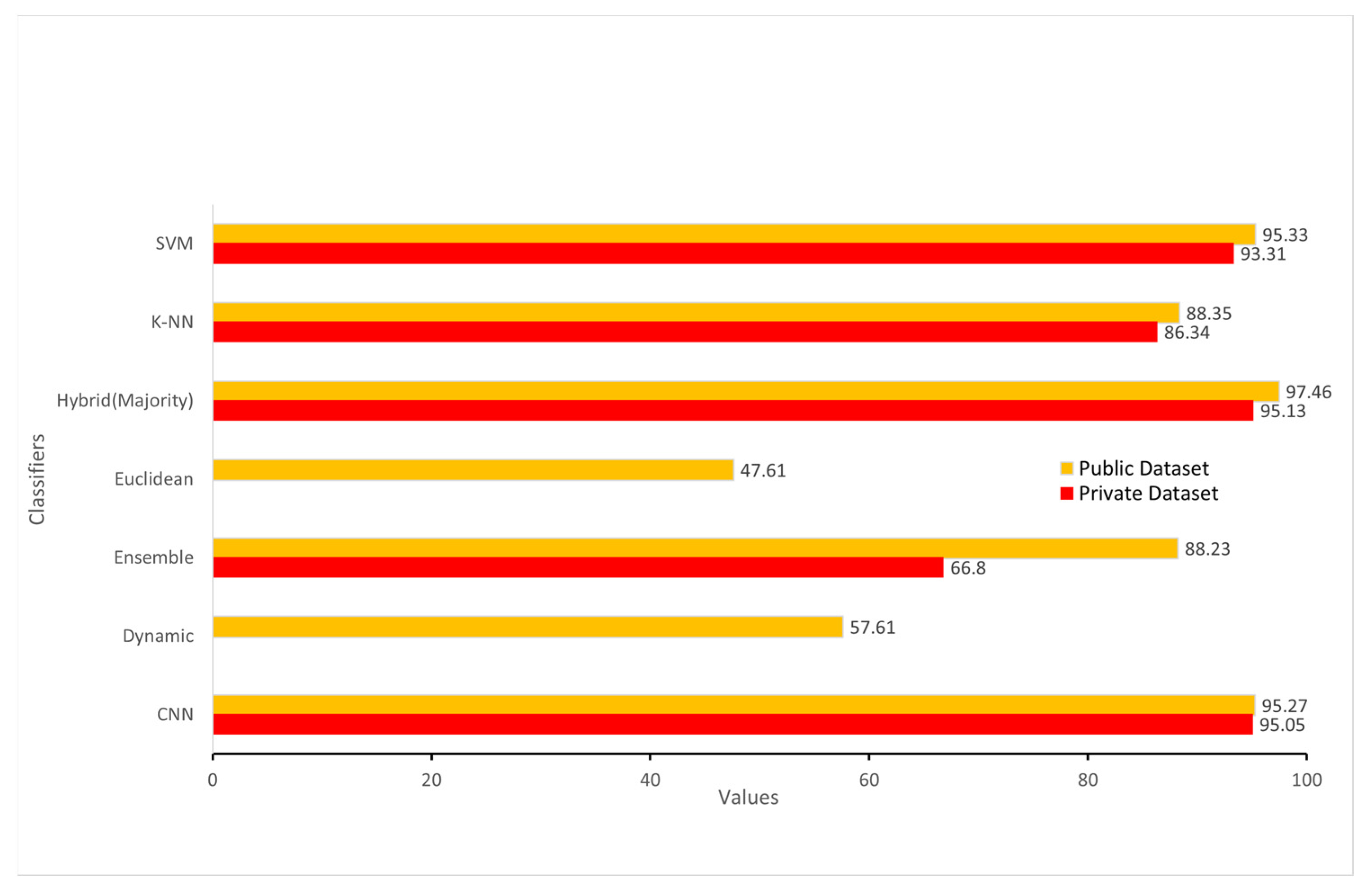
Figure 9 represents the comparison of the public dataset and private dataset. After applying majority voting on hybrid classifiers, the accuracy is increased. We used the MV algorithm in our model to ensure that the proposed embedded system has high performance. We needed an odd number of classifiers to use the MV algorithm.
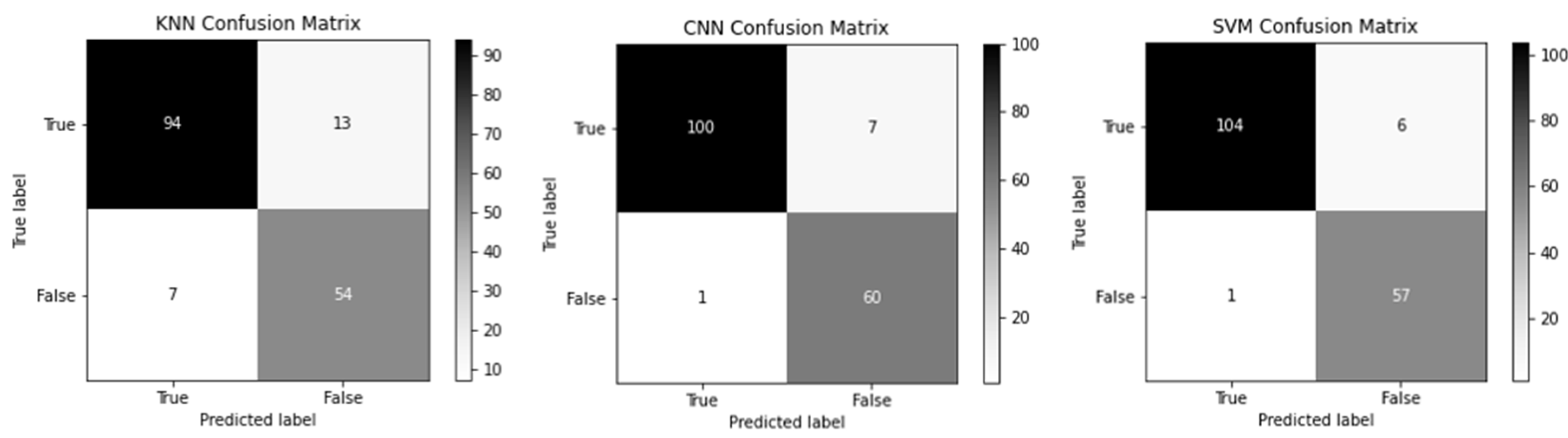
The confusion matrix in
Figure 10 represents the performance comparison of the machine learning models (KNN, CNN, and SVM) as described in [
38]. As this is a binary classification problem, the matrix was separated into true labels and false labels. Before using the MV, accuracy of the ensemble, KNN, and SVM classifier was 66.8%, 86.34% and 93.31%, respectively on private data set. We combined the results of all these classifiers and applied MV algorithm to achieve the highest accuracy of the proposed system.
Table 1 shows the actual percentage of classifiers in MV algorithms for true labels. All three SVM, KNN, and ensemble classifiers voted 88.23% for true labels, which is indicated as “3-0 voting,” where 3 indicates the number of classifiers that predicted true labels. Both SVM and KNN classifiers, voted 97.46% for true labels, which is considered 2-1 voting, and SVM alone voted 98.23% for true labels, which is 1-2 voting.
In this case, the majority of classifiers voted for 97.46%, which is considered the accuracy of our proposed model. This level of accuracy has never been achieved for Urdu signature verification.
Table 2 shows the voting percentage of classifiers that cannot vote for true labels. SVM, KNN, and ensemble classifiers could not vote for true labels with 1.76%, which is indicated as 0-3 voting, where 0 represents the number of classifiers that cannot predict true labels. KNN and ensemble were incapable of voting for true labels, which are considered 1-2 voting at 1.77% and 2-1 voting at 2.54%, respectively, whereas only ensemble classifiers could not vote for true labels. This is examined in
Figure 7. The existing Arabic and Persian signature verification methods need to be revised for Urdu signature verification. We used Arabic and Persian offline signature verification systems to test our Urdu data set. The results show that both methods could not perform better on the Urdu signature data set. In comparison, the proposed method had much better performance. For the proposed embedded system to be generally useful, we tested our method on a public dataset of handwritten signatures, which can be found on the English “Kaggle” dataset of handwritten signatures [
5]. It has 1800 signature, 860 genuine signature, and 840 forged signature datasets. The results on the public dataset are 88.23% with the ensemble, 88.35% with KNN, and 95.33% with SVM. When the MV algorithm was used, the accuracy on this public dataset after MV algorithm is 97.46%.
3.4. False Acceptance Rate (FAR) and False Rejection Rate (FRR)
An FAR (false acceptance rate) in Equation (4) indicates how often a biometric authentication system accepts a false value. In our case, it is the ratio at which our USV accepts forged signatures. FRR (false rejection rate) in Equation (5) means that the percentage of a biometric system rejecting false values in our system should reject a maximum number of forged signatures. A good biometric authentication system should have a low FAR and a high FRR.
Table 3 show the comparison of proposed method with existing published methods.
Researchers have used different methods for offline handwritten signature verification as compared to others our offline handwritten signature verification system is able to work better and have a low error rate.
Table 1 illustrates that the proposed method better, with an accuracy of 97.46%.
Table 2 show that the proposed hybrid classifier system has a very low “FAR” of 0.02% and an FRR of 43.75%.
Figure 11 shows FAR and FRR with other methods.
Table 4 shows the error rate comparison of the proposed and other published methods.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}