
Bust Portraits Matting Based on Improved U-Net


Abstract
:1. Introduction
- Aiming at the problem of the automatic matting of half-body portraits, a new contour sharpness refinement network is proposed to improve the prediction of edge details;
- Focusing on high-quality bust portrait matting improves the accuracy of predictions;
- It produces a bust-matting dataset containing high-resolution busts and their corresponding alpha images.
2. Related Work
2.1. Matting
2.2. Datasets
3. Approach
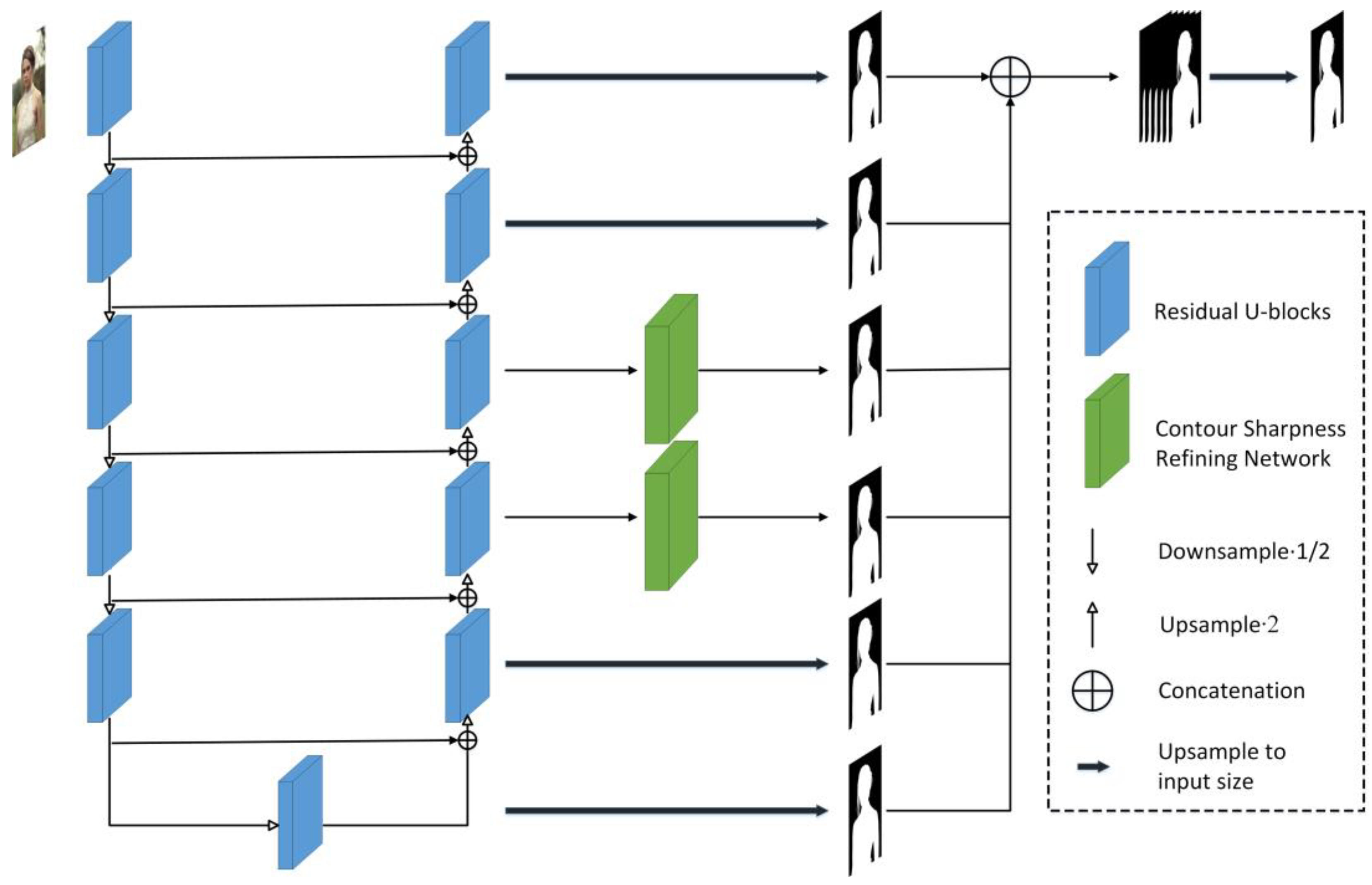
3.1. Overall Network Structure
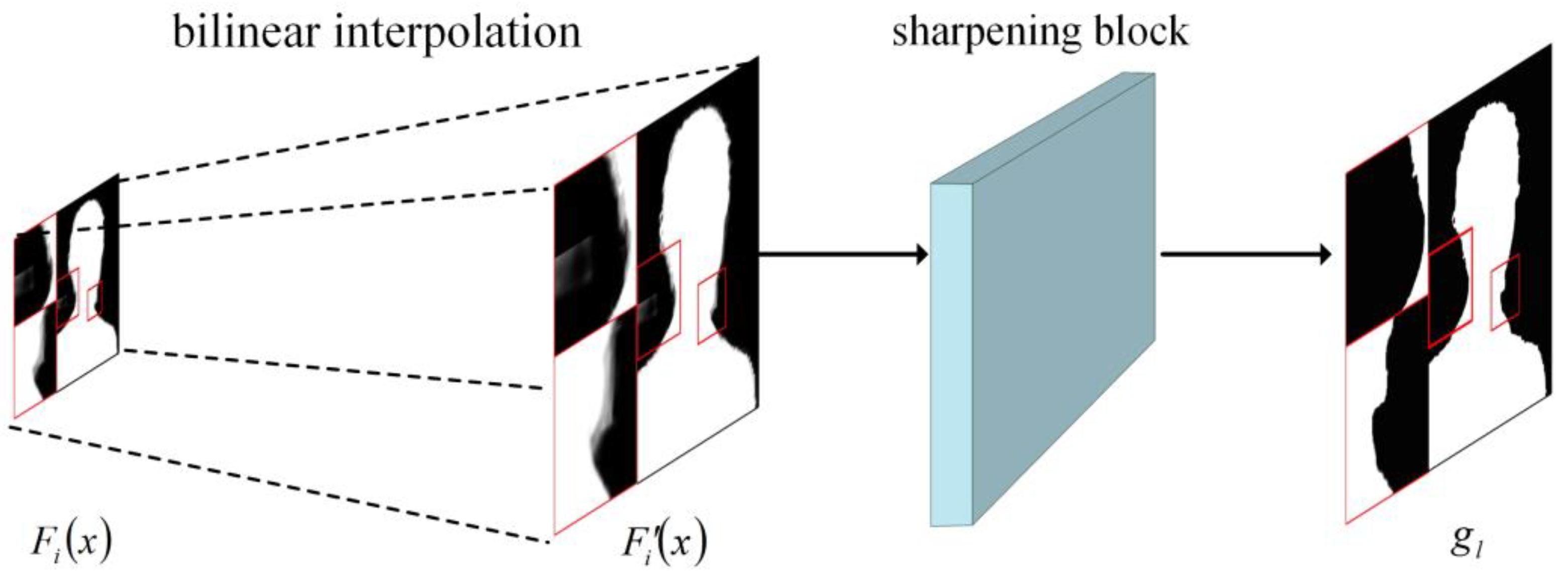
3.2. Contour Sharpness Refining Network
4. Experiments and Analysis
4.1. Experimental Environment
4.2. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ruzon, M.A.; Tomasi, C. Alpha Estimation in Natural Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2000 (Cat. No. PR00662), Hilton Head Island, SC, USA, 13–15 June 2000; IEEE: Piscataway, NJ, USA, 2000; pp. 18–25. [Google Scholar]
- Sun, J.; Jia, J.; Tang, C.-K.; Shum, H.-Y. Poisson matting. In Proceedings of the ACM SIGGRAPH 2004 Papers, Los Angeles, CA, USA, 8–12 August 2004; pp. 315–321. [Google Scholar]
- Chuang, Y.-Y.; Curless, B.; Salesin, D.H.; Szeliski, R. A Bayesian Approach to Digital Matting. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 264–271. [Google Scholar]
- Islam, M.A.; Kalash, M.; Bruce, N.D. Revisiting Salient Object Detection: Simultaneous Detection, Ranking and Subitizing of Multiple Salient Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7142–7150. [Google Scholar]
- Porter, T.; Duff, T. Compositing Digital Images. In Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques, Detroit, MI, USA, 25–29 July 1984; pp. 253–259. [Google Scholar]
- Ruan, Q.; Wu, Q.; Yao, J.; Wang, Y.; Tseng, H.-W.; Zhang, Z. An Efficient Tongue Segmentation Model Based on U-Net Framework. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2154035. [Google Scholar] [CrossRef]
- Qiao, Y.; Liu, Y.; Yang, X.; Zhou, D.; Xu, M.; Zhang, Q.; Wei, X. Attention-Guided Hierarchical Structure Aggregation for Image Matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13676–13685. [Google Scholar]
- Yihui, L.; Fujian, F.; Zhaoquan, C. Pyramid Matting: A resource-adaptive multi-scale pixel pair optimization framework for image matting. IEEE Access 2020, 8, 93487–93498. [Google Scholar] [CrossRef]
- Wang, Y.; Niu, Y.; Duan, P.; Lin, J.; Zheng, Y. Deep Propagation Based Image Matting. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 999–1006. [Google Scholar]
- Hou, Q.; Liu, F. Context-aware image matting for simultaneous foreground and alpha estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4130–4139. [Google Scholar]
- Liu, B.; Jing, H.; Qu, G.; Guesgen, H.W. Cascaded Segmented Matting Network for Human Matting. IEEE Access 2021, 9, 157182–157191. [Google Scholar] [CrossRef]
- Park, G.; Son, S.; Yoo, J.; Kim, S.; Kwak, N. Matteformer: Transformer-based image matting via prior-tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11696–11706. [Google Scholar]
- Cai, H.; Xue, F.; Xu, L.; Guo, L. TransMatting: Enhancing Transparent Objects Matting with Transformers. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXIX. Springer: Berlin/Heidelberg, Germany, 2022; pp. 253–269. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. Polarmask: Single Shot Instance Segmentation with Polar Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12193–12202. [Google Scholar]
- Xiao, J.; Guo, H.; Yao, Y.; Zhang, S.; Zhou, J.; Jiang, Z. Multi-Scale Object Detection with the Pixel Attention Mechanism in a Complex Background. Remote Sens. 2022, 14, 3969. [Google Scholar] [CrossRef]
- Luo, G.; Zhou, Y.; Sun, X.; Cao, L.; Wu, C.; Deng, C.; Ji, R. Multi-Task Collaborative Network for Joint Referring Expression Comprehension and Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10034–10043. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, F.; Tian, Y.; Qi, Z. Attention transfer network for nature image matting. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2192–2205. [Google Scholar] [CrossRef]
- Fang, X.; Zhang, S.-H.; Chen, T.; Wu, X.; Shamir, A.; Hu, S.-M. User-Guided Deep Human Image Matting Using Arbitrary Trimaps. IEEE Trans. Image Process. 2022, 31, 2040–2052. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Tu, A.; Bergholm, F. Improved Minimum Spanning Tree based Image Segmentation with Guided Matting. KSII Trans. Internet Inf. Syst. 2022, 16, 211–230. [Google Scholar]
- Xu, N.; Price, B.; Cohen, S.; Huang, T. Deep Image Matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2970–2979. [Google Scholar]
- Lin, S.; Ryabtsev, A.; Sengupta, S.; Curless, B.L.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Real-Time High-Resolution Background Matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8762–8771. [Google Scholar]
- Li, J.; Zhang, J.; Maybank, S.J.; Tao, D. Bridging composite and real: Towards end-to-end deep image matting. Int. J. Comput. Vis. 2022, 130, 246–266. [Google Scholar] [CrossRef]
- Ke, Z.; Sun, J.; Li, K.; Yan, Q.; Lau, R.W. Modnet: Real-Time Trimap-Free Portrait Matting via Objective Decomposition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virutal, 22 February–1 March 2022; pp. 1140–1147. [Google Scholar]
- Yu, Q.; Zhang, J.; Zhang, H.; Wang, Y.; Lin, Z.; Xu, N.; Bai, Y.; Yuille, A. Mask guided matting via progressive refinement network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1154–1163. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Rhemann, C.; Rother, C.; Wang, J.; Gelautz, M.; Kohli, P.; Rott, P. A perceptually motivated online benchmark for image matting. In Proceedings of the 2009 IEEE conference on computer vision and pattern recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1826–1833. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Name | SAD | MSE(10−3) | Gradient | Connectivity |
|---|---|---|---|---|
| U2-NET [13] | 114.62 | 12.26 | 103.16 | 73.87 |
| GF Matting [22] | 142.36 | 6.92 | 124.35 | 227.27 |
| MOD Net [23] | 125.85 | 11.25 | 114.96 | 87.52 |
| Ours | 66.26 | 12.18 | 97.70 | 72.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, H.; Hou, K.; Jiang, D.; Ma, W. Bust Portraits Matting Based on Improved U-Net. Electronics 2023, 12, 1378. https://doi.org/10.3390/electronics12061378
Xie H, Hou K, Jiang D, Ma W. Bust Portraits Matting Based on Improved U-Net. Electronics. 2023; 12(6):1378. https://doi.org/10.3390/electronics12061378
Chicago/Turabian StyleXie, Honggang, Kaiyuan Hou, Di Jiang, and Wanjie Ma. 2023. "Bust Portraits Matting Based on Improved U-Net" Electronics 12, no. 6: 1378. https://doi.org/10.3390/electronics12061378
APA StyleXie, H., Hou, K., Jiang, D., & Ma, W. (2023). Bust Portraits Matting Based on Improved U-Net. Electronics, 12(6), 1378. https://doi.org/10.3390/electronics12061378