
Deep-Learning-Based Scalp Image Analysis Using Limited Data


Abstract
:1. Introduction
2. Literature Review
2.1. Scalp Data Preprocessing Methods
2.2. Existing Models for Scalp Datasets
3. Method Description
3.1. Dataset
3.2. Data Augmentation
3.3. Loss Function
3.4. Model Description
3.4.1. ResNet and ResNeXt
3.4.2. DenseNet
3.4.3. XceptionNet
4. Experiment and Result
4.1. Experimental Environments
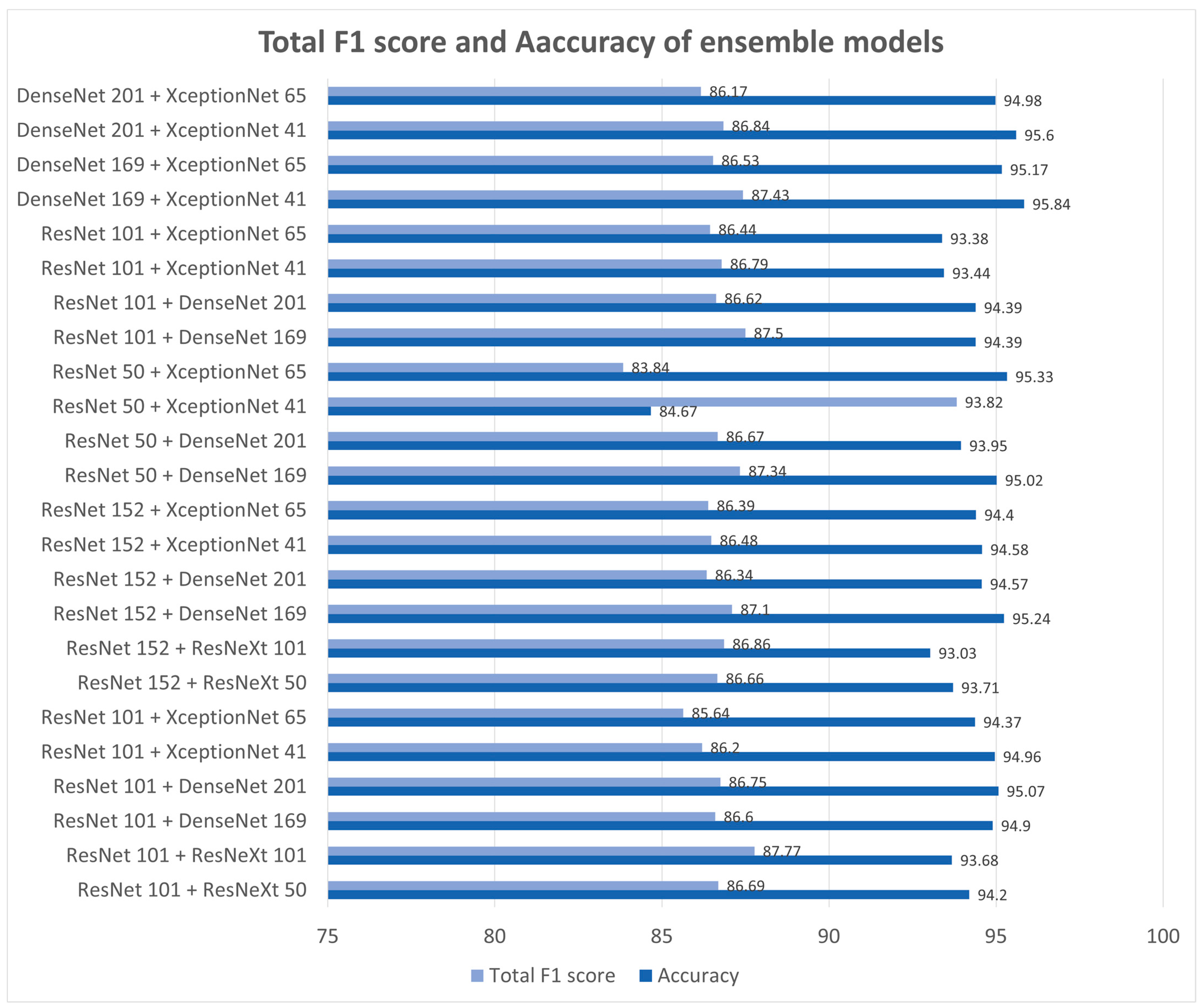
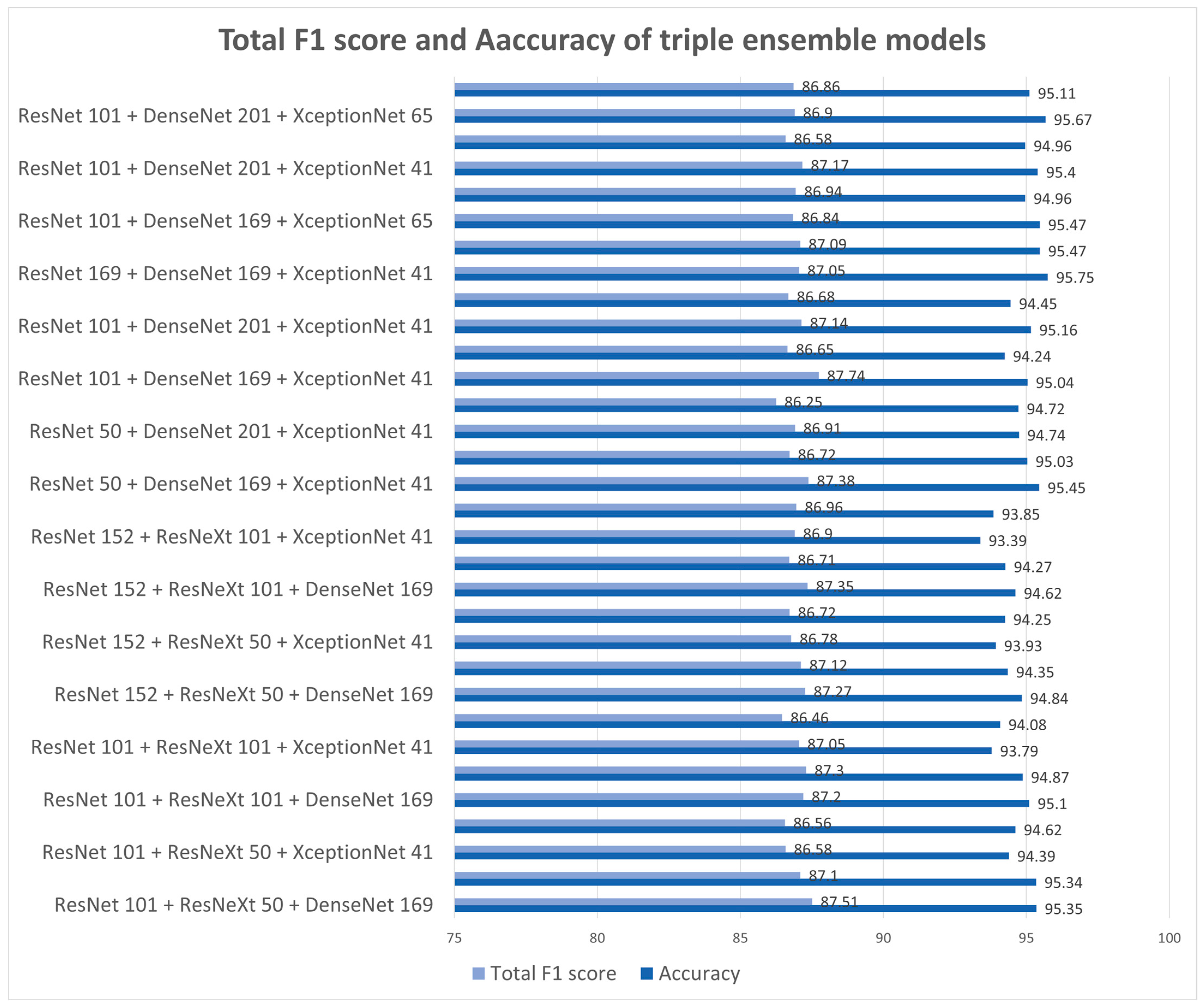
4.2. Experimental Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- 2021 Korea Health Insurance Statistical Annual Report. Available online: https://www.hira.or.kr/ (accessed on 29 December 2022).
- Pratt, C.H.; King, L.E.; Messenger, A.G.; Christiano, A.M.; Sundberg, J.P. Alopecia areata. Nat. Rev. Dis. Prim. 2017, 3, 17011. [Google Scholar] [CrossRef] [Green Version]
- Kim, W.; Kim, H.; Rew, J.; Hwang, E. A Hair Density Measuring Scheme Using Smartphone. In Proceedings of the Korea Information Processing Society Conference, Jeju City, Republic of Korea, 30–31 October 2015; pp. 1416–1419. [Google Scholar]
- Kim, H.; Kim, W.; Na, B.; Rew, J.; Hwang, E. Microscopy image analysis scheme for estimating scalp condition. In Proceedings of the Korea Information Processing Society Conference, Seoul, Republic of Korea, 29–30 April 2016; pp. 740–742. [Google Scholar]
- Jakubik, J. Dataset Enhancement in Hair Follicle Detection: ESENSEI Challenge. In Position Papers of the 2018 Federated Conference on Computer Science and Information Systems, Poznan, Poland, 9–12 September 2018; Polish Information Processing Society: Warsaw, Poland, 2018; pp. 19–22. [Google Scholar]
- Seo, S.; Park, J. Trichoscopy of Alopecia Areata: Hair Loss Feature Extraction and Computation Using Grid Line Selection and Eigenvalue. Comput. Math. Methods Med. 2020, 2020, 908018. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.; Kang, S.; Lee, B.-D. Evaluation of Automated Measurement of Hair Density Using Deep Neural Networks. Sensors 2022, 22, 650. [Google Scholar] [CrossRef] [PubMed]
- Gao, M.; Wang, Y.; Xu, H.; Xu, C.; Yang, X.; Nie, J.; Zhang, Z.; Li, Z.; Hou, W.; Jiang, Y. Deep Learning-based Trichoscopic Image Analysis and Quantitative Model for Predicting Basic and Specific Classification in Male Androgenetic Alopecia. Acta Derm.-Venereol. 2022, 102, adv00635. [Google Scholar] [CrossRef] [PubMed]
- Chang, W.J.; Chen, L.B.; Chen, M.C.; Chiu, Y.C.; Lin, J.Y. ScalpEye: A Deep Learning-Based Scalp Hair Inspection and Diagnosis System for Scalp Health. IEEE Access 2020, 8, 134826–134837. [Google Scholar] [CrossRef]
- Benhabiles, H.; Hammoudi, K.; Yang, Z.; Windal, F.; Melkemi, M.; Dornaika, F.; Arganda-Carreras, I. Deep Learning based Detection of Alopecia Levels from Facial Images. In Proceedings of the Ninth International Conference on Image Processing Theory, Tools and Applications, Istanbul, Turkey, 6–9 November 2019; pp. 1–6. [Google Scholar]
- Shakeel, C.S.; Khan, S.J.; Chaudhry, B.; Aijaz, S.F.; Hassan, U. Classification Framework for Healthy Hairs and Alopecia Areata: A Machine Learning (ML) Approach. Comput. Math. Methods Med. 2021, 2021, 1102083. [Google Scholar] [CrossRef] [PubMed]
- Roy, M.; Protity, A.T. Hair and Scalp Disease Detection using Machine Learning and Image Processing. arXiv 2022, arXiv:2301.00122. [Google Scholar] [CrossRef]
- Aditya, S.; Sidhu, S.; Kanchana, M. Prediction of Alopecia Areata using Machine Learning Techniques. In Proceedings of the 2022 IEEE international Conference on Data Science and Information System (ICDSIS), Hassan, India, 29–30 July 2022; p. 7. [Google Scholar]
- Jhong, S.-Y.; Yang, P.-Y.; Hsia, C.-H. An Expert Smart Scalp Inspection System Using Deep Learning. Sens. Mater. 2022, 34, 1265–1274. [Google Scholar] [CrossRef]
- Sayyad, S.; Midhunchakkaravarthy, D.; Sayyad, F. An Analysis of Alopecia Areata Classification Framework for Human Hair Loss Based on VGG-SVM Approach. J. Pharm. Negat. Results 2022, 13, 9–15. [Google Scholar]
- AI-Hub. Available online: https://www.aihub.or.kr/ (accessed on 29 December 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the Computer Vision and Pattern Recognition (CVPR) 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the Computer Vision and Pattern Recognition (CVPR) 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Description | Problems |
|---|---|---|
| [3] | Diagnosed alopecia based on the extent of hair growth. Preprocessed using feature extraction algorithm. | Focused only on the density of hair. |
| [4] | Used various indicators that can determine alopecia, such as hair density, thickness, and so on. | There was no preprocessing to reflect the characteristics of each person. |
| [5] | Normalized the images to lower the difference in hue between the scalp images. | The degree of enhancement is low. |
| [6] | Converted to gray tones to reduce errors arising from color differences and created an algorithm for diagnosing alopecia by extracting HLF from scalp images. | Difficult to use it to consider scalp diseases, except for the hair condition. |
| [7] | Flip images vertically and rotate +15 to −15° | Small performance improvement on models with data augmentation techniques such as YOLOv4. |
| Reference | Description | Problems |
|---|---|---|
| [7] | A model that is simply learned hair follicle images and detects hair follicles within a scalp image. | If the race, the shape of the hair follicle, and the location or distance of the picture are different, the accuracy is low. |
| [8] | An automatic hair follicle image analysis model which consists of D-Net for trichoscopy image detection, and R-Net for prediction. | |
| [9] | A system that uses Faster R-CNN with the Inception Res-Net_v2_Atrous model for examining scalp hair symptoms. | There is a limitation in that it does not directly serve the user. |
| [10] | A system that uses facial images as a dataset to detect alopecia and classify it into seven levels. | It only uses methods for general image enhancement, and not scalp-specific enhancement processes. |
| [11] | A framework that consists of a support vector machine and a K-nearest neighborhood. | It suffers from a high possibility of overfitting because only HE is used for data enhancement. |
| [12] | An image classification model, which consists of CNN structure, that extracts the characteristics of alopecia automatically. | It can only judge if the image is alopecia or non-alopecia, so it is difficult to diagnose the progress of one’s alopecia. |
| [13] | They preprocessed the dataset using image enhancement, segmentation, and data augmentation techniques. They compared the performance of various machine learning algorithms. | The accuracy is insufficient to diagnose scalp diseases, such as alopecia and scalp lesions. |
| [14] | A scalp lesion image classifier that combines cloud computing and AIoT design architecture with an algorithm that adds a convolutional block attention module (CBAM) and spinal FC to the DenseNet classic model. | |
| [15] | They proposed VGG-SVM for alopecia diagnosis, and their algorithm showed the highest accuracy at 98.31%. | They did not take into account racial difference. |
| Label | Good (0) | Mild (1) | Moderate (2) | Severe (3) |
|---|---|---|---|---|
| Image |  |  |  |  |
| Red Image | Yellow Image | Green Image | Blue Image | ||
|---|---|---|---|---|---|
(input) |  |  |  |  |  |
(result) |  |  |  |  |  |
| Red Image | Yellow Image | Green Image | Blue Image | ||
|---|---|---|---|---|---|
 |  |  |  |  | |
 |  |  |  |  | |
 |  |  |  |  | |
 |  |  |  |  | |
 |  |  |  |  | |
 |  |  |  |  |
| Red Image | Yellow Image | White Image | Green Image | Blue Image | |
|---|---|---|---|---|---|
(input) |  |  |  |  |  |
(result) |  |  |  |  |  |
| Stage | Resolution | ResNet-50 Operator | ResNeXt-50 Operator |
|---|---|---|---|
| 1 | 112 × 112 | Conv7 × 7 | Conv7 × 7 |
| 2 | 56 × 56 | [Conv1 × 1 64, Conv3 × 3 64, Conv1 × 1 256] × 3 | [Conv1 × 1 128, Conv3 × 3 128, Conv1 × 1 256] × 3 |
| 3 | 28 × 28 | [Conv1 × 1 128, Conv3 × 3 128, Conv1 × 1 512] × 4 | [Conv1 × 1 128, Conv3 × 3 128, Conv1 × 1 512] × 4 |
| 4 | 14 × 14 | [Conv1 × 1 256, Conv3 × 3 256, Conv1 × 1 1024] × 6 | [Conv1 × 1 512, Conv3 × 3 512, Conv1 × 1 1024] × 6 |
| 5 | 7 × 7 | [Conv1 × 1 512, Conv3 × 3 512, Conv1 × 1 2048] × 3 | [Conv1 × 1 1024, Conv3 × 3 1024, Conv1 × 1 2048] × 3 |
| 6 | 1 × 1 | Average pool 7 × 7, FC | Average pool 7 × 7, FC |
| Stage | Operator | Resolution | #Layers |
|---|---|---|---|
| 1 | Conv7 × 7 | 112 × 112 | Convolution |
| 2 | Max pool 3 × 3 | 56 × 56 | Pooling |
| 3 | [Conv1 × 1, Conv3 × 3] × 6 | 56 × 56 | Dense Block |
| 4 | Average pool 2×2 | 28 × 28 | Transition Layer |
| 5 | [Conv1 × 1, Conv3 × 3] × 12 | 28 × 28 | Dense Block |
| 6 | Average pool 2 × 2 | 14 × 14 | Transition Layer |
| 7 | [Conv1 × 1, Conv3 × 3] × 24 | 14 × 14 | Dense Block |
| 8 | Average pool 2 × 2 | 7 × 7 | Transition Layer |
| 9 | [Conv1 × 1, Conv3 × 3] × 16 | 7 × 7 | Dense Block |
| 10 | Average pool 7 × 7, FC, SoftMax | 1 × 1 | Classification Layer |
| Network | Good (0) F1 Score | Mild (1) F1 Score | Moderate (2) F1 Score | Severe (3) F1 Score | Total F1 Score | |
|---|---|---|---|---|---|---|
| ResNet | 101 | 83.74 | 83.63 | 49.03 | 55.32 | 75.24 |
| 152 | 66.67 | 80.41 | 56.76 | 60.64 | 74.16 | |
| ResNeXt | 50 | 91.06 | 79.42 | 48.89 | 62.77 | 72.90 |
| 101 | 89.43 | 78.19 | 56.17 | 63.30 | 73.42 | |
| DenseNet | 169 | 89.43 | 86.97 | 38.19 | 65.96 | 76.27 |
| 201 | 69.11 | 93.36 | 21.25 | 72.87 | 77.12 | |
| XceptionNet | 41 | 84.55 | 80.70 | 42.79 | 77.66 | 73.19 |
| 65 | 76.42 | 80.08 | 49.33 | 63.30 | 72.95 | |
| Network | Good (0) F1 Score | Mild (1) F1 Score | Moderate (2) F1 Score | Severe (3) F1 Score | Total F1 Score | |
|---|---|---|---|---|---|---|
| ResNet | 101 | 92.68 | 100.0 | 87.87 | 60.43 | 86.17 |
| 152 | 90.89 | 100.0 | 85.79 | 67.45 | 86.44 | |
| ResNeXt | 50 | 90.33 | 100.0 | 91.60 | 56.91 | 86.75 |
| 101 | 86.91 | 100.0 | 89.55 | 63.78 | 86.80 | |
| DenseNet | 169 | 94.63 | 99.79 | 89.10 | 59.15 | 86.64 |
| 201 | 93.50 | 100.0 | 89.10 | 57.23 | 86.17 | |
| XceptionNet | 41 | 90.41 | 99.63 | 90.17 | 54.15 | 85.52 |
| 65 | 89.11 | 100.0 | 91.43 | 51.22 | 85.41 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Gil, Y.; Kim, Y.; Kim, J. Deep-Learning-Based Scalp Image Analysis Using Limited Data. Electronics 2023, 12, 1380. https://doi.org/10.3390/electronics12061380
Kim M, Gil Y, Kim Y, Kim J. Deep-Learning-Based Scalp Image Analysis Using Limited Data. Electronics. 2023; 12(6):1380. https://doi.org/10.3390/electronics12061380
Chicago/Turabian StyleKim, Minjeong, Yujung Gil, Yuyeon Kim, and Jihie Kim. 2023. "Deep-Learning-Based Scalp Image Analysis Using Limited Data" Electronics 12, no. 6: 1380. https://doi.org/10.3390/electronics12061380
APA StyleKim, M., Gil, Y., Kim, Y., & Kim, J. (2023). Deep-Learning-Based Scalp Image Analysis Using Limited Data. Electronics, 12(6), 1380. https://doi.org/10.3390/electronics12061380