
Out-of-Distribution (OOD) Detection and Generalization Improved by Augmenting Adversarial Mixup Samples


Abstract
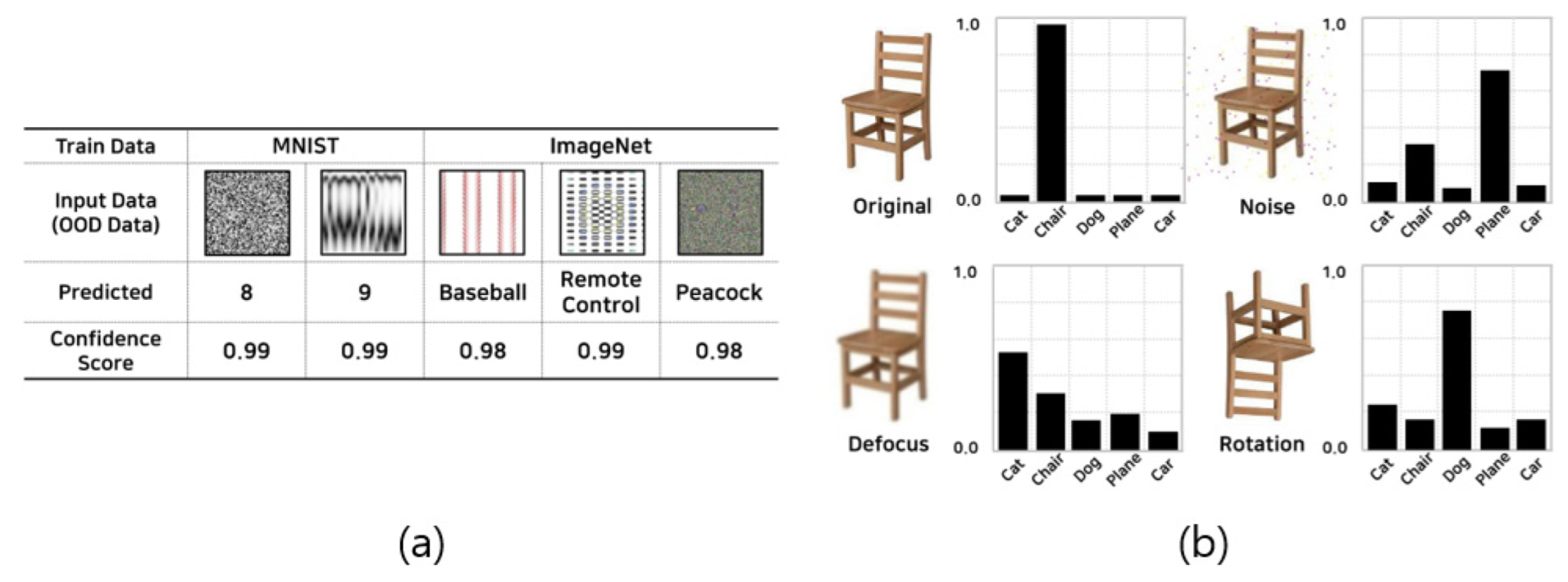
:1. Introduction
2. Related Works
2.1. OOD Detection and Generalization Methods
2.2. Data Augmentation Methods
3. Distance-Aware OOD Detection with Adversarial Mixup Training
3.1. Data Mixup
3.2. Adversarial Training
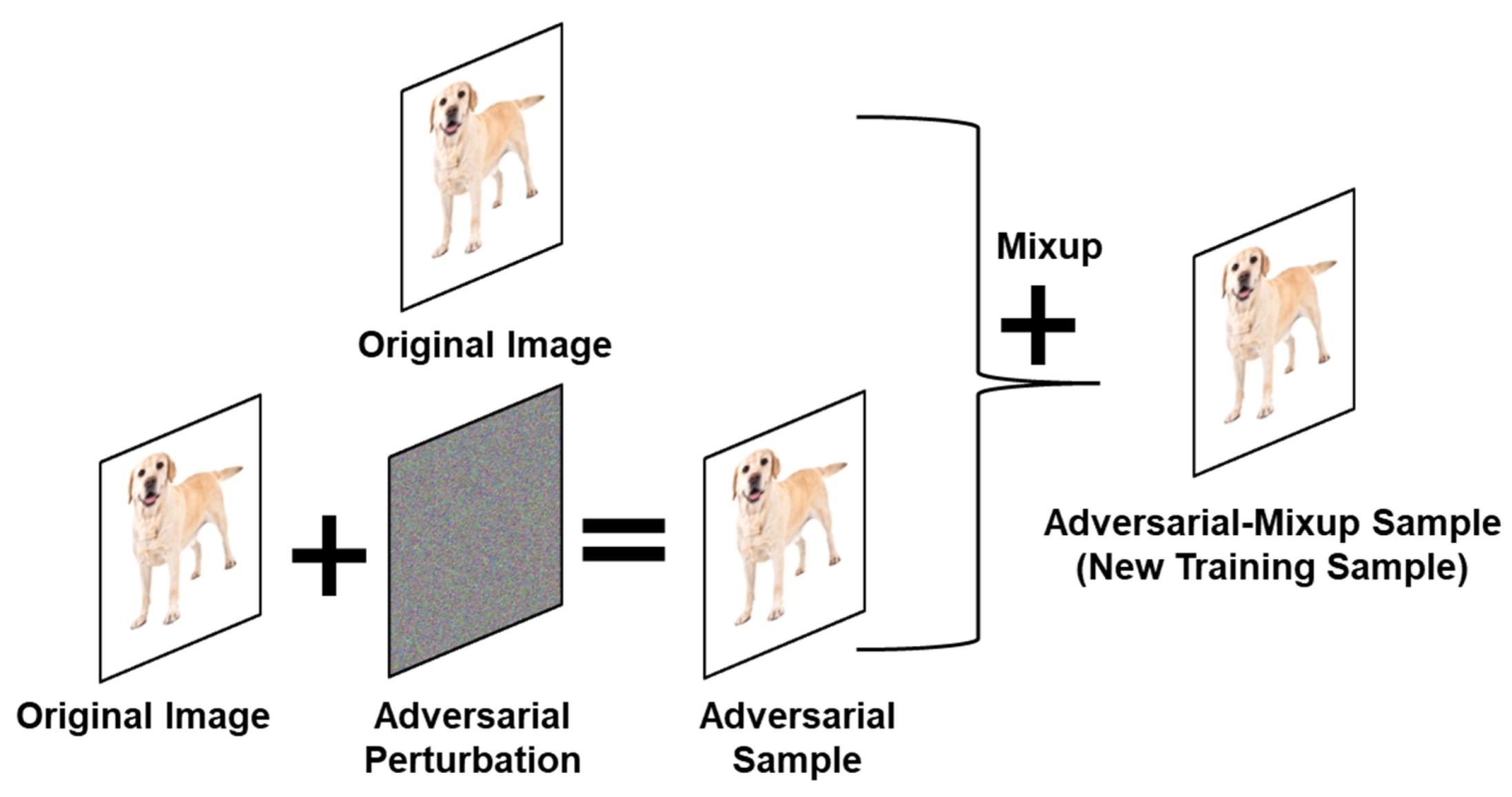
3.3. Generating Adversarial Mixup OOD Samples
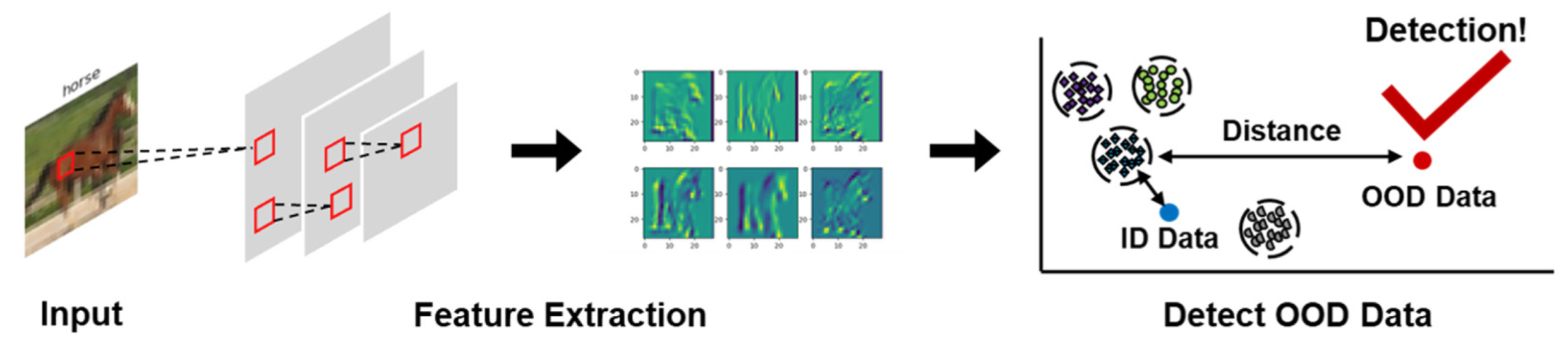
3.4. Mahalanobis-Distance-Based OOD Detector
4. Experimental Methodology
4.1. Datasets Configuration
4.2. Evaluation Metrics
5. Experimental Evaluation
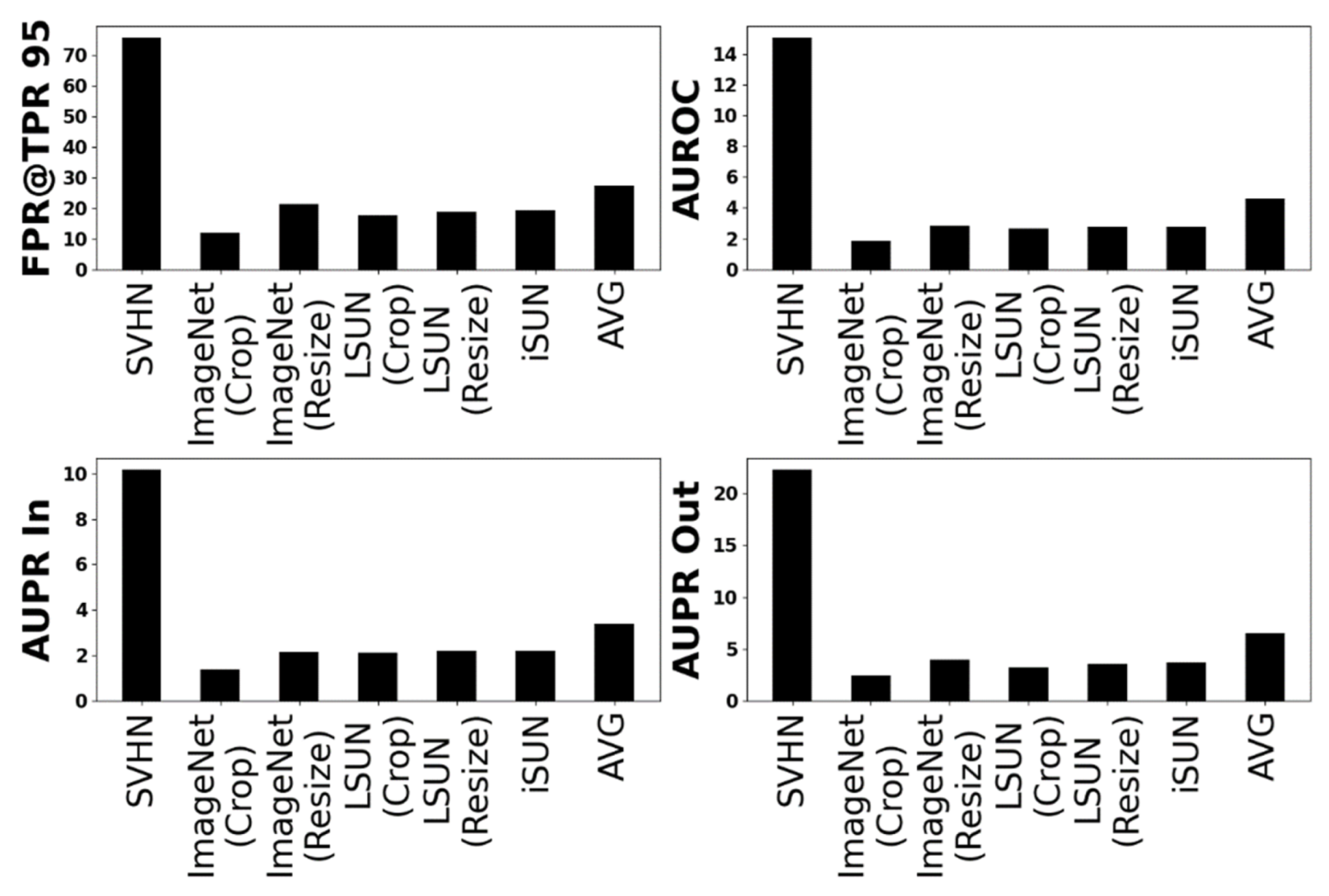
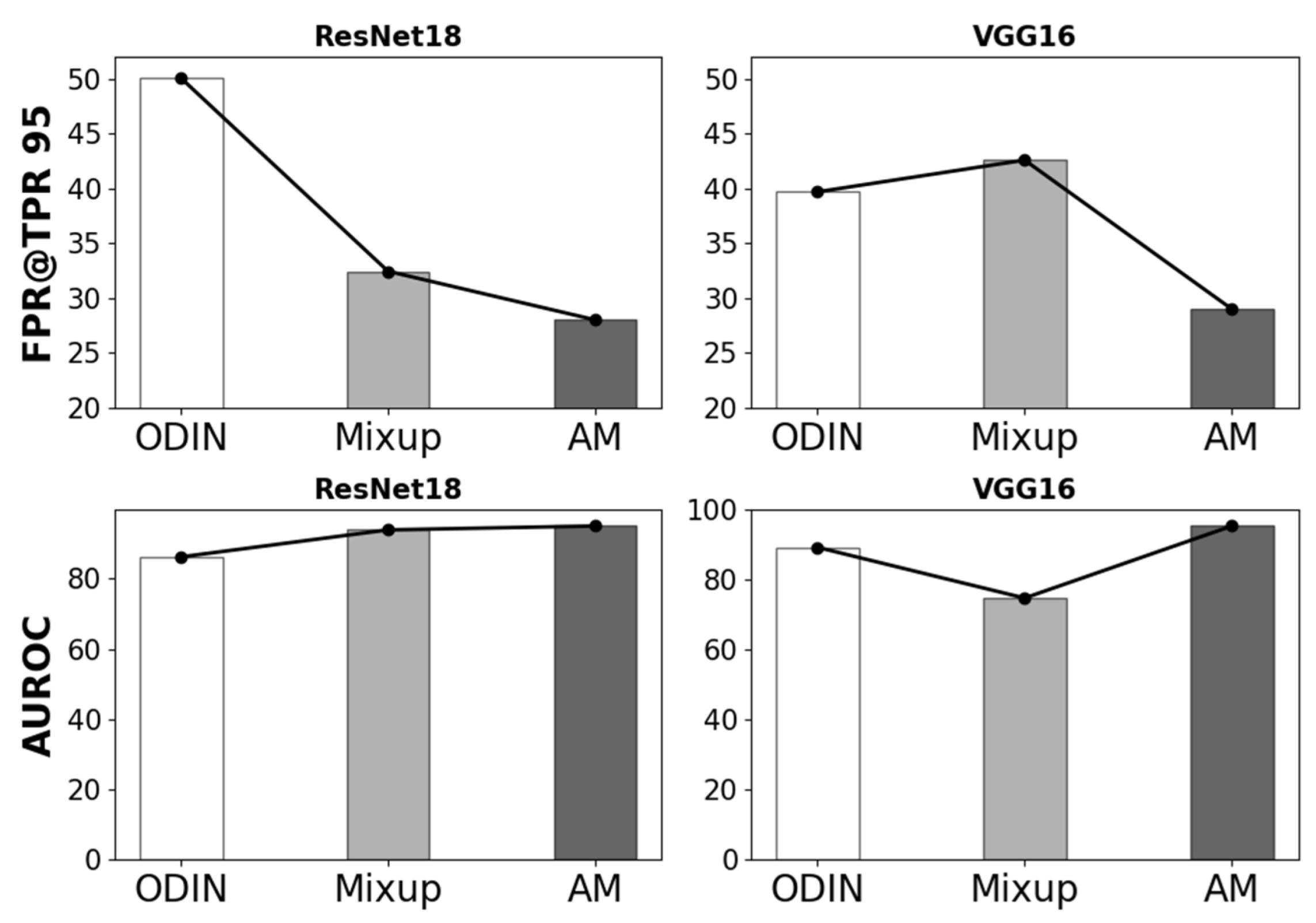
5.1. AM OOD Detection Performance
5.2. Improved OOD Detection by Combining AM with Distance Awareness
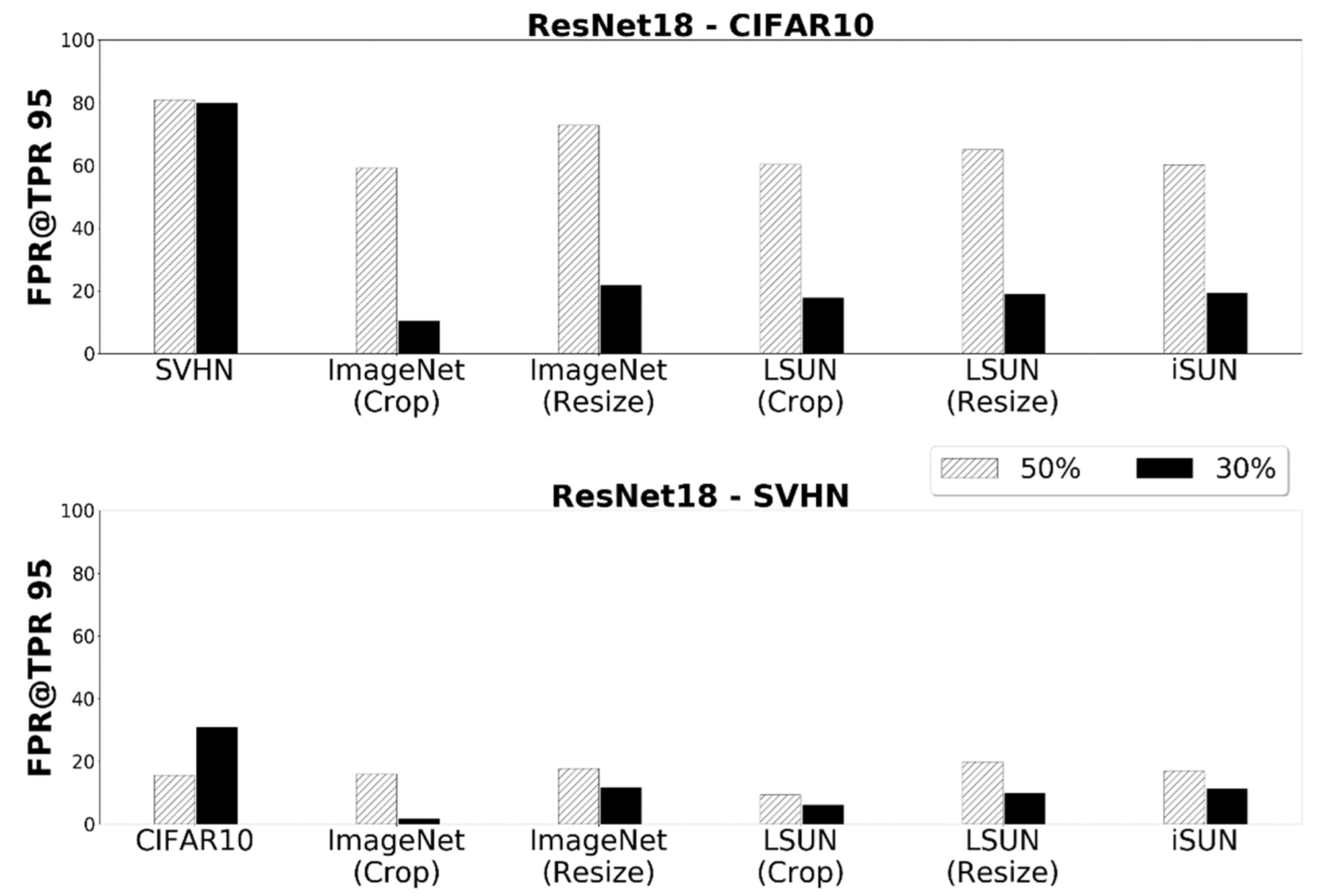
5.3. Ablation Study: Effect of Adversarial Mixup Ratio
5.4. Ablation Study: Comparison of ERM-Based and VRM-Based Models
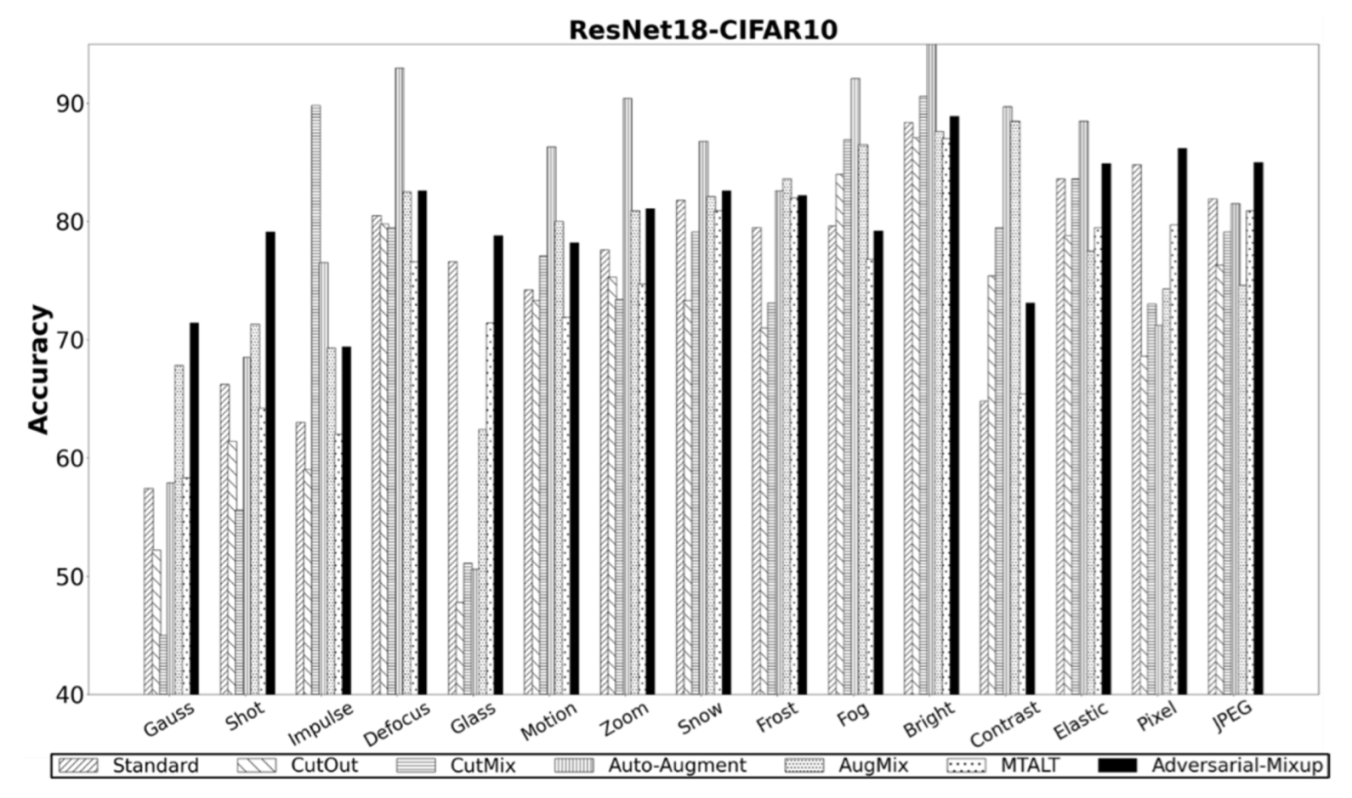
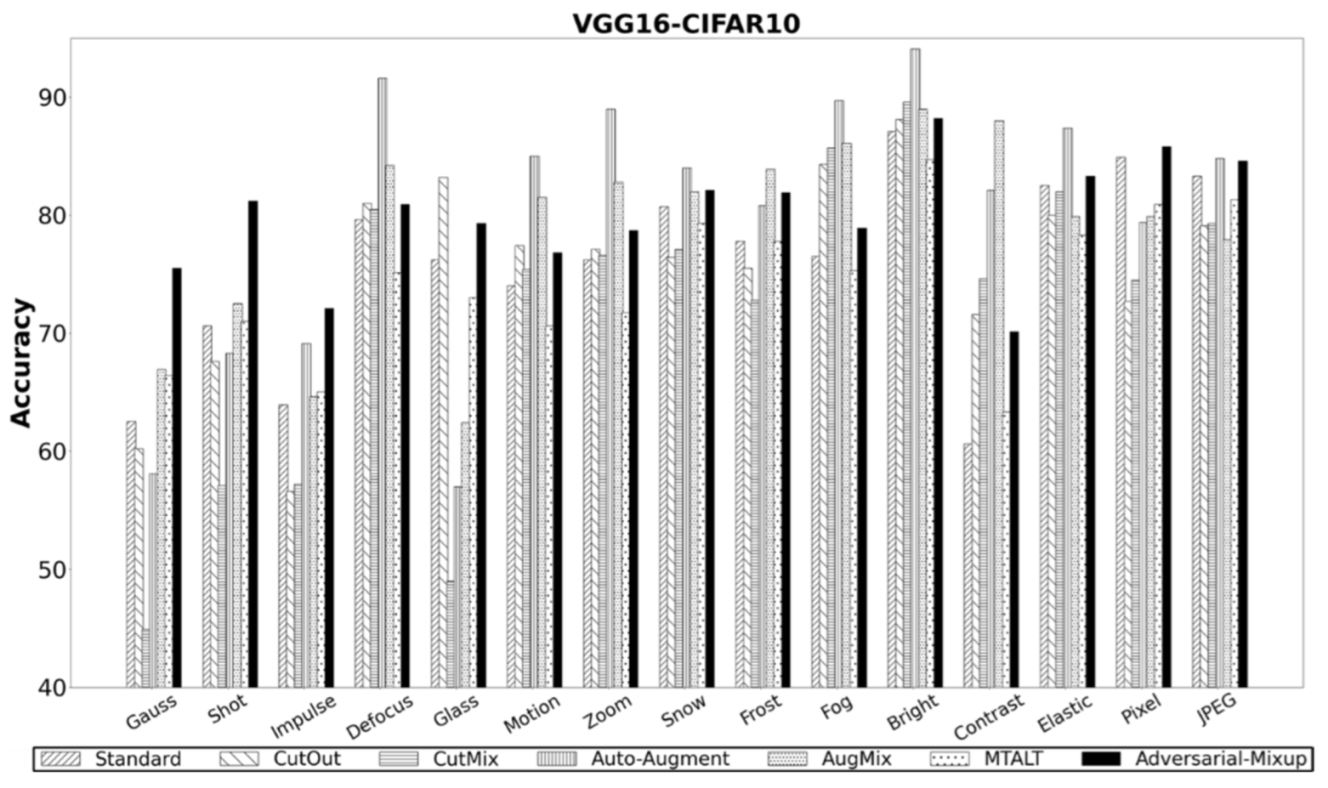
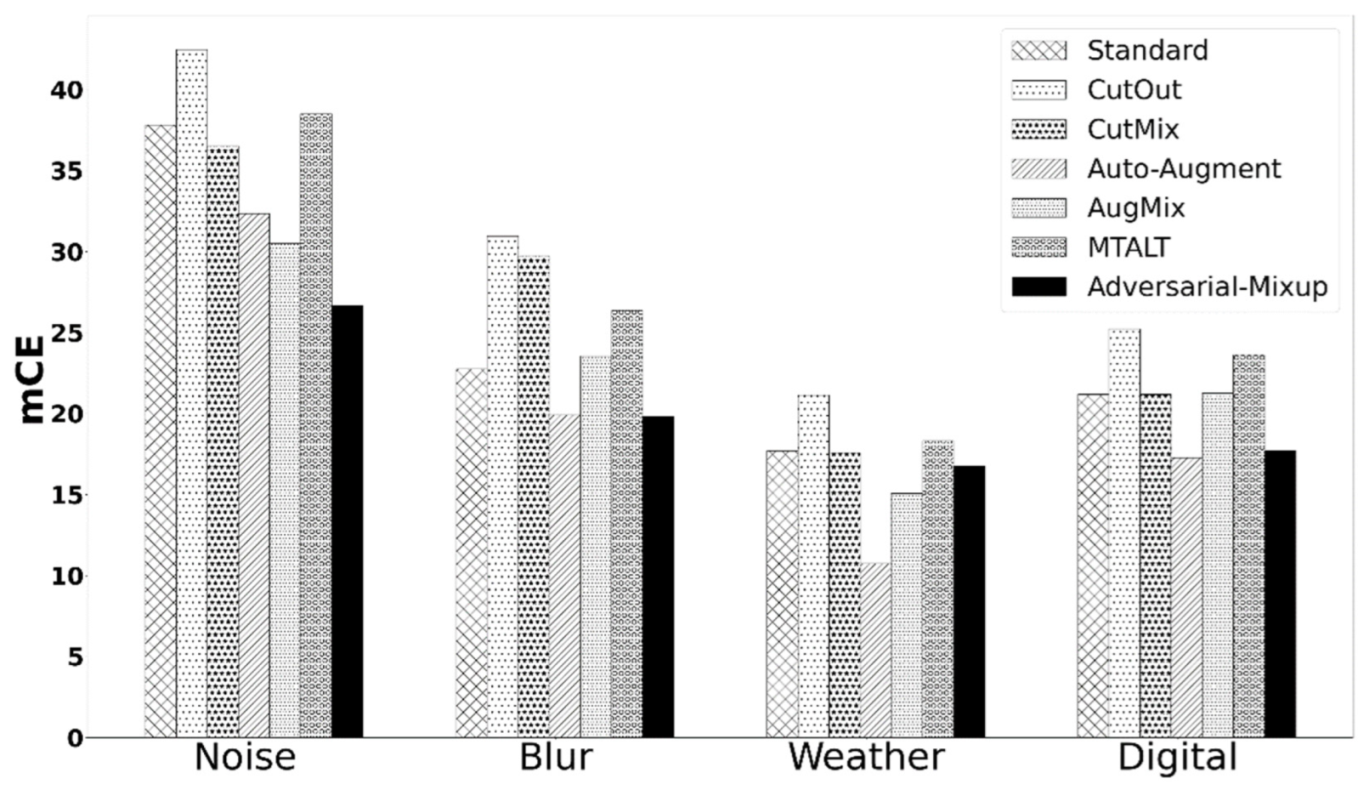
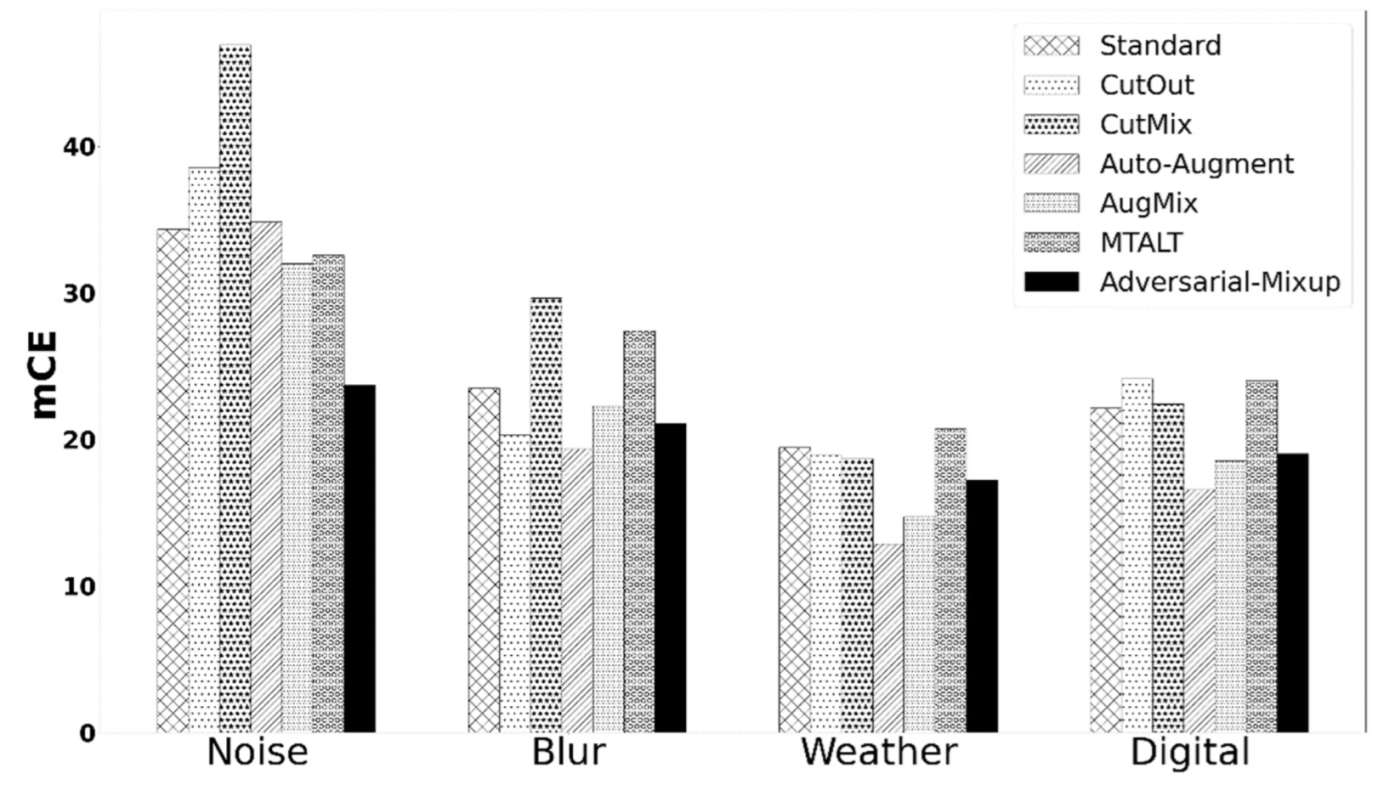
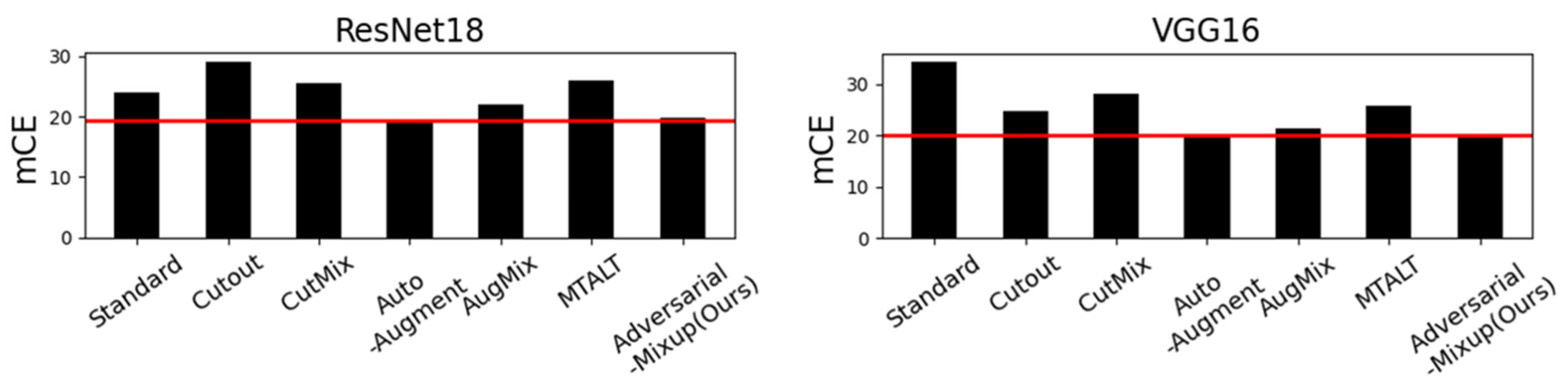
5.5. AM OOD Generalization Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of deep learning and its applications: A new paradigm to machine learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Cui, P.; Wang, J. Out-of-distribution (OOD) detection based on deep learning: A review. Electronics 2022, 11, 3500. [Google Scholar] [CrossRef]
- Yang, J.; Zhou, K.; Li, Y.; Liu, Z. Generalized out-of-distribution detection: A survey. arXiv 2022, arXiv:2110.11334v2. [Google Scholar]
- Jeong, K. The Cause of Honda’s Self-Driving Accident is Lack of AI Reliability. Meconomynews. 2020. Available online: https://www.meconomynews.com/news/articleView.html?idxno=47362 (accessed on 10 January 2022).
- Bonetti, M. Scientists Now Claim AI Can Predict a Criminal Just Checking Facial Features TrendinTech. 2016. Available online: https://trendintech.com/2016/12/02/scientists-now-claim-ai-can-predict-a-criminal-just-checking-facial-features/ (accessed on 10 January 2022).
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1528–1540. [Google Scholar]
- Shen, Z.; Liu, J.; He, Y.; Zhang, X.; Xu, R.; Yu, H.; Cui, P. Towards out-of-distribution generalization: A survey. arXiv 2021, arXiv:2108.13624v1. [Google Scholar]
- Zhou, K.; Zhang, Y.; Zang, Y.; Yang, J.; Loy, C.C.; Liu, Z. On-device domain generalization. arXiv 2022, arXiv:2209.07521. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Hendrycks, D.; Dietterich, T. Benchmarking neural network robustness to common corruptions and perturbations. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lee, K.; Lee, H.; Lee, K.; Shin, J. Training confidence-calibrated classifiers for detecting out-of-distribution samples. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April––3 May 2018. [Google Scholar]
- Hendrycks, D.; Mazeika, M.; Dietterich, T. Deep anomaly detection with outlier exposure. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Hawkins, S.; He, H.; Williams, G.; Baxter, R. Outlier detection using replicator neural networks. In Data Warehousing and Knowledge Discovery; Kambayashi, Y., Winiwarter, W., Arikawa, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 170–180. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning (ICML), Virtual Event, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Sehwag, V.; Chiang, M.; Mittal, P. SSD: A unified framework for self-supervised outlier detection. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Liang, S.; Li, Y.; Srikant, R. Enhancing the reliability of out-of-distribution image detection in neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gwon, K.; Yoo, J. Out-of-distribution data detection using mahalanobis distance for reliable deep neural networks. In Proceedings of the IeMeK Symposium on Embedded Technology (ISET 2020), Jeju-si, Republic of Korea, 23–24 July 2020. [Google Scholar]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Yang, D.; Mai Ngoc, K.; Shin, I.; Lee, K.-H.; Hwang, M. Ensemble-Based Out-of-Distribution Detection. Electronics 2021, 10, 567. [Google Scholar] [CrossRef]
- Liu, W.; Wang, X.; Owens, J.; Li, Y. Energy-based Out-of-distribution Detection. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Djurisic, A.; Bozanic, N.; Ashok, A.; Liu, R. Extremely Simple Activation Shaping for Out-of-Distribution Detection. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Devries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. In Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the 2019 International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Thulasidasan, S.; Chennupati, G.; Bilmes, J.; Bhattacharya, T.; Michalak, S. On mixup training: Improved calibration and predictive uncertainty for deep neural networks. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Hendrycks, D.; Mu, N.; Cubuk, E.D.; Zoph, B.; Gilmer, J.; Lakshminarayanan, B. AugMix: A simple data processing method to improve robustness and uncertainty. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Laugros, A.; Caplier, A.; Ospici, M. Addressing neural network robustness with mixup and targeted labeling adversarial training. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning augmentation policies from data. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Yang, J.; Zhou, K.; Liu, Z. Full-spectrum out-of-distribution detection. arXiv 2022, arXiv:2204.05306. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Szgedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| For OOD Detection Task | For OOD Generalization Task |
|---|---|
| CIFAR10 | CIFAR10-C |
| ImageNet-C | |
| SVHN | |
| ImageNet-P | |
| ImageNet (Crop) | |
| ImageNet-A | |
| ImageNet (Resize) | |
| ImageNet-V2 | |
| LSUN (Crop) | |
| ObjectNet | |
| LSUN (Resize) | |
| ImageNet-Vid-Robust | |
| iSUN | |
| YouTube-BB-Robust |
| Result | ||
|---|---|---|
| Actual | Predicted | |
| True Positive | OOD | OOD |
| False Negative | OOD | ID |
| True Negative | ID | ID |
| False Positive | ID | OOD |
| ID Data | OOD Data | FPR@TPR 95 | AUROC | AUPR In | AUPR Out |
|---|---|---|---|---|---|
| MSP [16]/MD [19]/AM (Proposed) | |||||
| CIFAR10 | SVHN | 86.7/8.8/80 | 76.9/98.0/83.7 | 73.5/94.8/87 | 70/99.2/77.1 |
| ImageNet(C) | 69/16.8/11.8 | 88.1/96.9/98.2 | 90.3/97.3/98.5 | 83.8/96.2/97.3 | |
| ImageNet(R) | 73/35.1/21.7 | 87.1/94.1/96.9 | 90.1/95.2/97.6 | 82.1/92.1/95.7 | |
| LSUN(C) | 66/6.2/17.8 | 90.3/98.5/97.3 | 92.7/98.7/97.8 | 86/98.3/96.7 | |
| LSUN(R) | 72.5/33.9/18.9 | 87.5/94.5/97 | 90.2/95.7/97.6 | 82.6/91.5/96.1 | |
| iSUN | 73.7/27.6/19.3 | 87.3/95.4/97.1 | 90.2/96.7/97.7 | 82.1/92.3/96.2 | |
| ID Data | OOD Data | FPR@TPR 95 | AUROC | AUPR In | AUPR Out |
|---|---|---|---|---|---|
| MSP [62]/MD [19]/AM (Proposed) | |||||
| CIFAR10 | SVHN | 81.1/2.4/75 | 83.3/99.4/86.4 | 86.2/98.6/89.6 | 77.1/99.8/80.6 |
| ImageNet(C) | 74.6/12.5/11 | 97.1/97.7/98.3 | 90.3/98.2/97.8 | 82.1/97.0/97.8 | |
| ImageNet(R) | 62.5/31.3/18.7 | 90.8/94.6/97.3 | 93/95.3/96.7 | 87.3/94.0/96.7 | |
| LSUN(C) | 55.8/1.0/11.5 | 92.1/99.7/98 | 94/99.7/98.6 | 89.6/99.7/97.7 | |
| LSUN(R) | 60.5/46/17.1 | 91.3/91.7/97.4 | 93.6/92.9/96.9 | 88/93.3/96.9 | |
| iSUN | 60.8/30.5/19.4 | 91.4/94.6/97.1 | 93.7/95.7/96.6 | 88/93.4/96.6 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gwon, K.; Yoo, J. Out-of-Distribution (OOD) Detection and Generalization Improved by Augmenting Adversarial Mixup Samples. Electronics 2023, 12, 1421. https://doi.org/10.3390/electronics12061421
Gwon K, Yoo J. Out-of-Distribution (OOD) Detection and Generalization Improved by Augmenting Adversarial Mixup Samples. Electronics. 2023; 12(6):1421. https://doi.org/10.3390/electronics12061421
Chicago/Turabian StyleGwon, Kyungpil, and Joonhyuk Yoo. 2023. "Out-of-Distribution (OOD) Detection and Generalization Improved by Augmenting Adversarial Mixup Samples" Electronics 12, no. 6: 1421. https://doi.org/10.3390/electronics12061421
APA StyleGwon, K., & Yoo, J. (2023). Out-of-Distribution (OOD) Detection and Generalization Improved by Augmenting Adversarial Mixup Samples. Electronics, 12(6), 1421. https://doi.org/10.3390/electronics12061421