
An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLOv5


Abstract
:1. Introduction
- In this paper, the YOLOv5 feature extraction network is improved, and the feature map extraction operation is advanced. If it is a small object, the deeper the network level is, the less semantic information is retained by the small object. By extracting the feature map in advance, more abundant location information can be obtained to improve the problem of the feature loss of object information as the network level deepens;
- The network model proposed in this paper adds a selfattention mechanism. The attention mechanism can improve the object feature weight, reduce the background feature weight, let the model obtain the object area that needs to be focused on, and reconstruct the features;
- The network model proposed in this paper uses a context feature-fusion structure. The feature information with rich deep semantics but also unclear location information is fused to the feature information with clear shallow location information but not rich semantics to improve the detection difficulty caused by complex multiobject;
- The remainder of this paper is organized as follows: Section 2 discusses work related to image object detection, followed, in Section 3, by the object detection algorithms based on deep learning. In Section 4, the proposed method is addressed along with the considerations for the analysis of this paper. Section 5 presents the experimental results and analysis. Finally, in Section 6, a conclusion is drawn.
2. Related Work
3. Object Detection Algorithms Based on Deep Learning
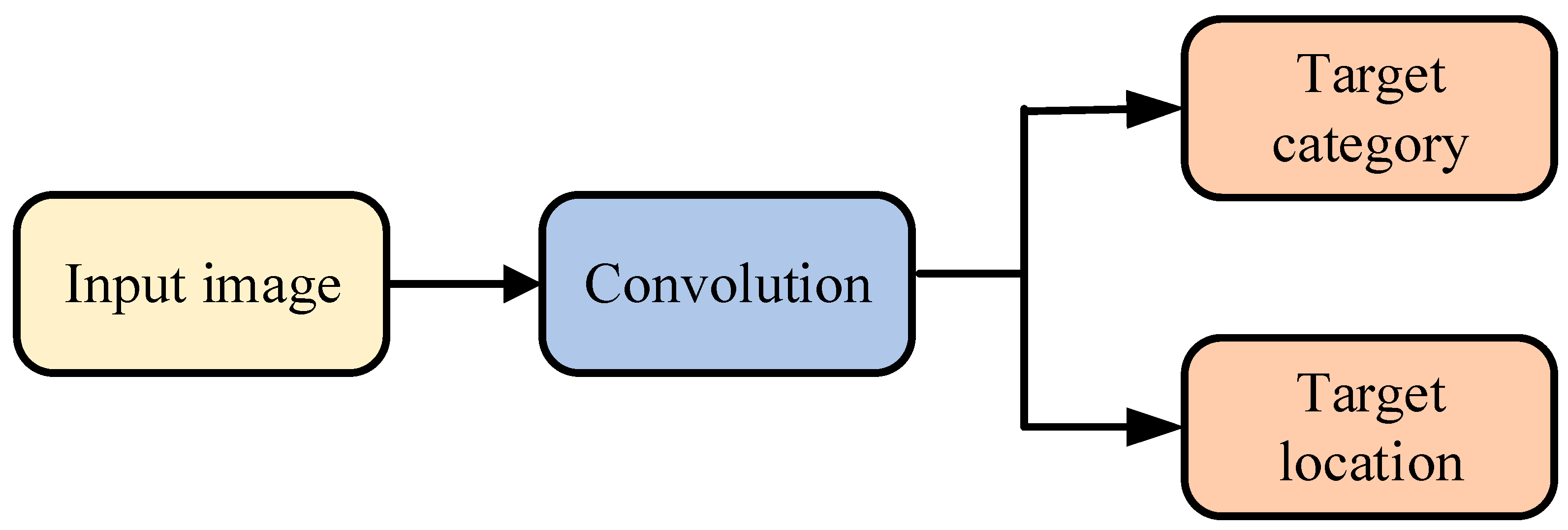
3.1. Classification of Mainstream Algorithms in Object Detection
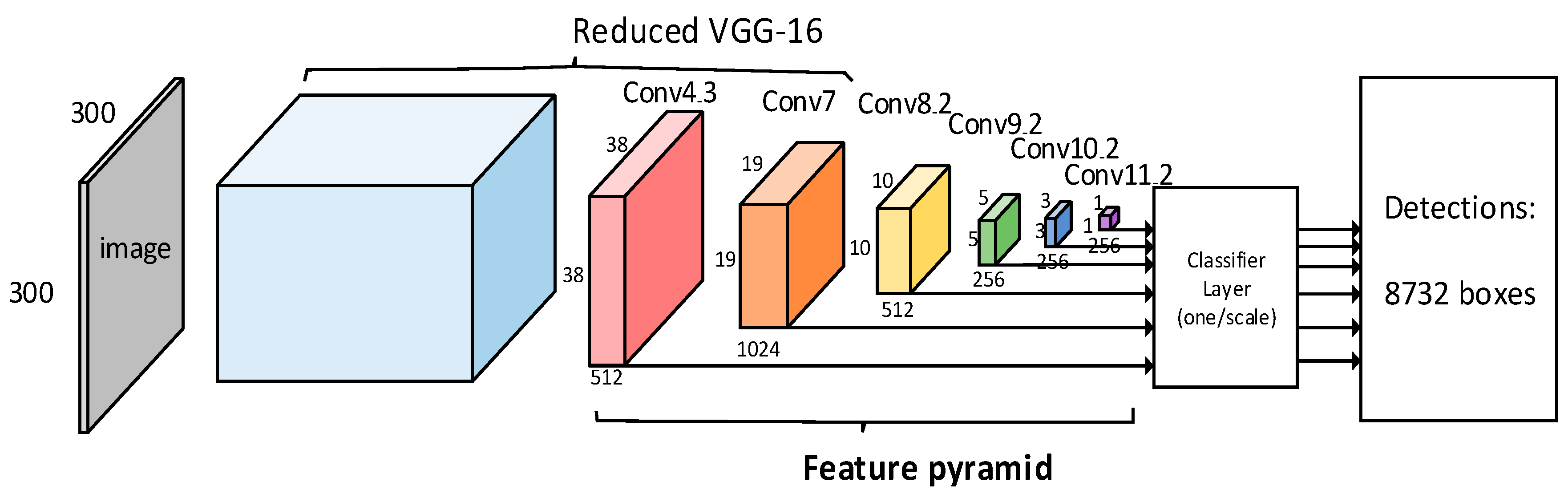
3.2. SSD Object Detection Algorithm
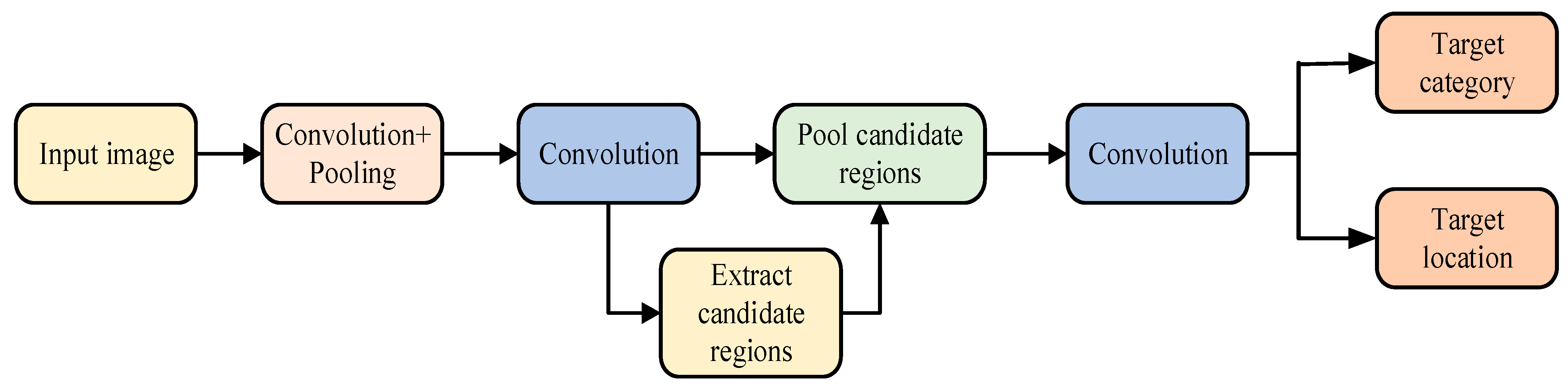
3.2.1. SSD Algorithm Model Structure
3.2.2. Prior Frame
3.2.3. Border Regression
3.2.4. Loss Function of SSD
3.3. YOLOv3 Object Detection Algorithm
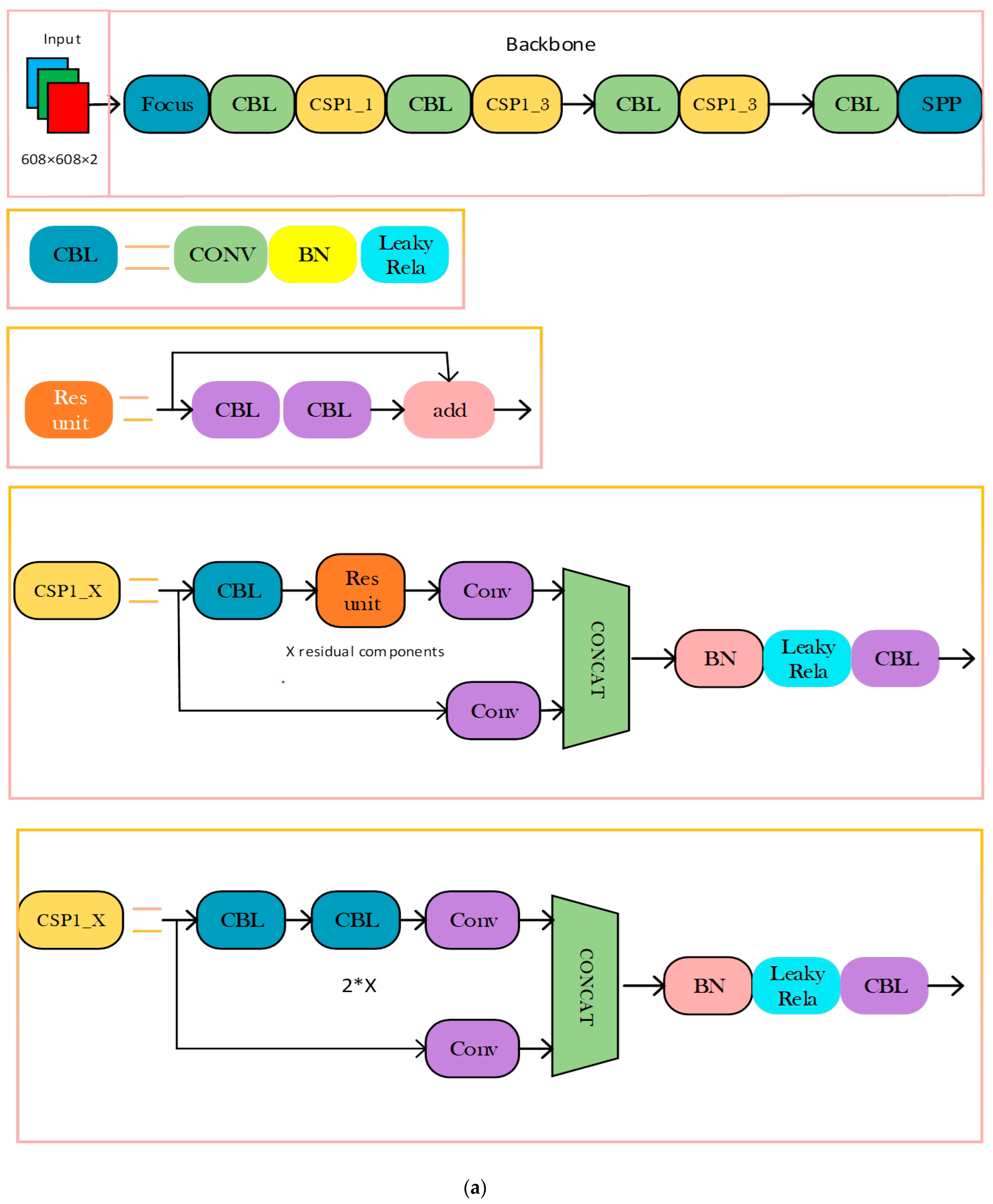
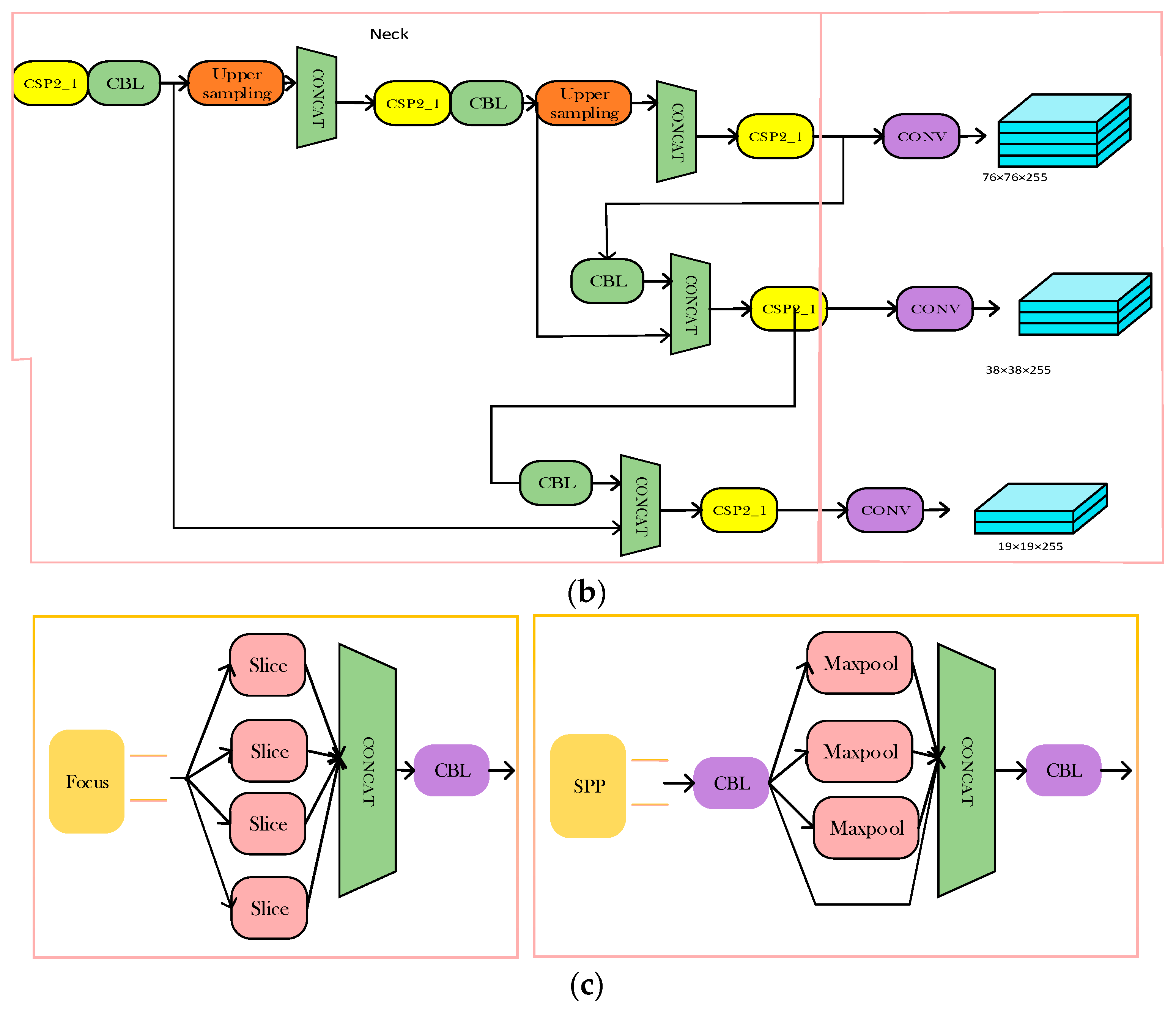
3.3.1. YOLOv3 Network Structure
3.3.2. Residual Module
3.3.3. Loss Function of YOLOv3
4. Image Object Detection Based on YOLOv5 Optimized by Mixed Attention Mechanism
4.1. Attention Mechanism
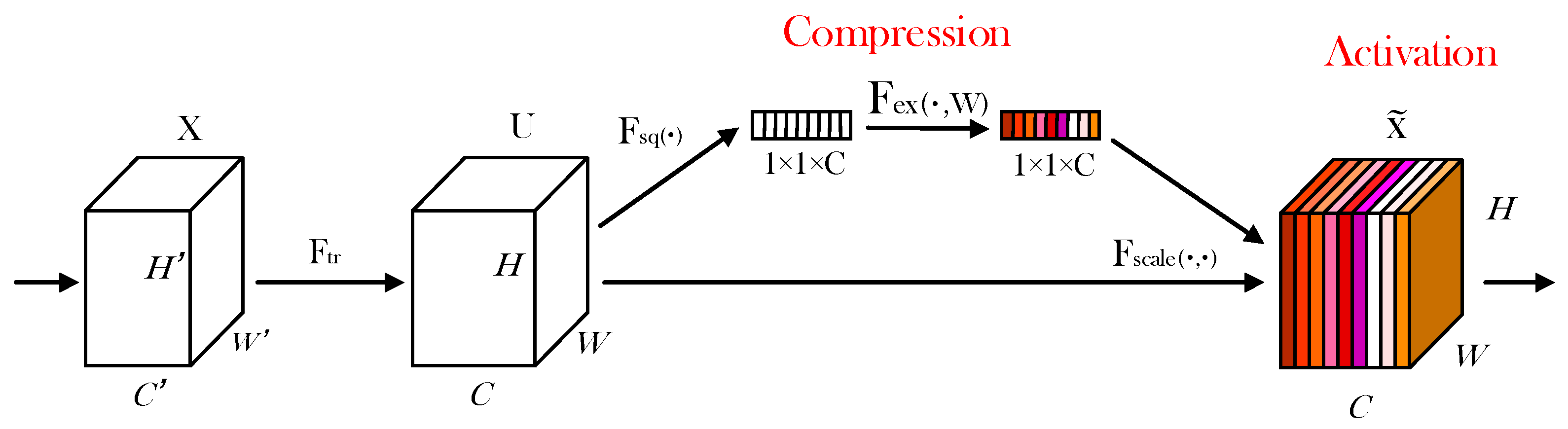
4.1.1. Channel Attention Mechanism
4.1.2. Spatial Attention Mechanism
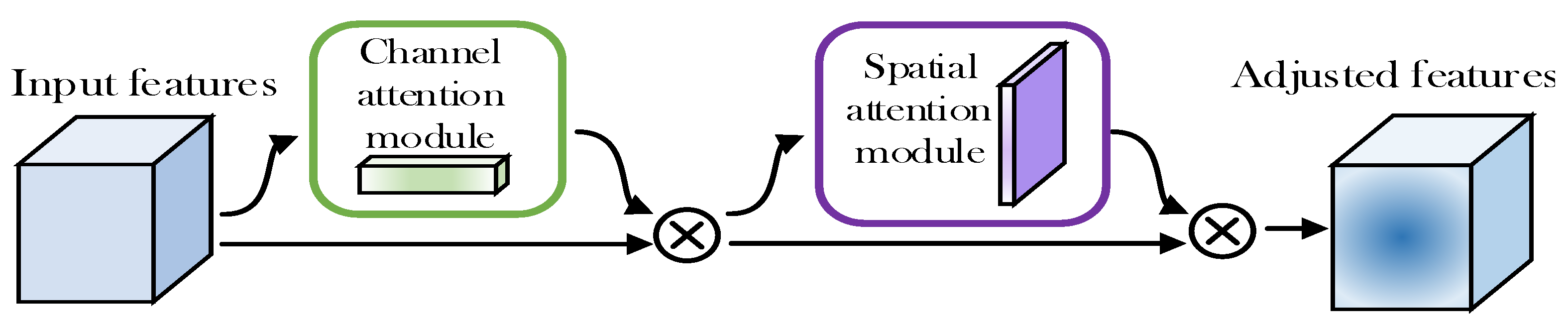
4.1.3. Mixed Attention Mechanism
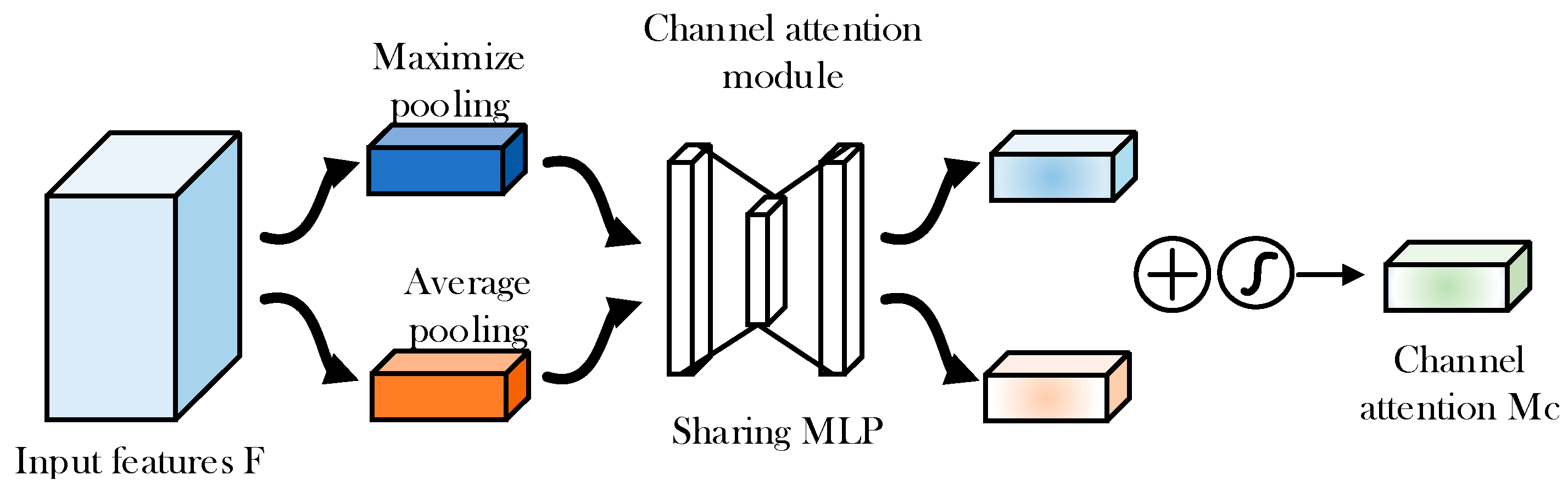
4.1.4. Channel Attention Module CAM
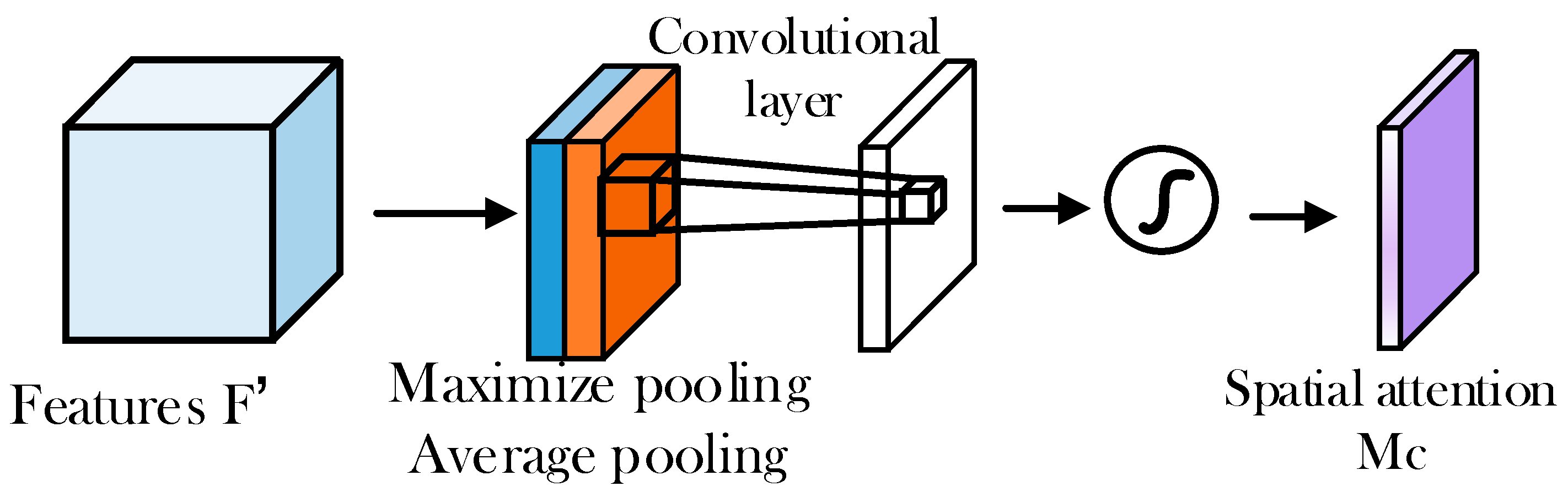
4.1.5. Spatial Attention Module SAM
4.2. Construction of MAO-YOLOv5 Model Feature Extraction Structure
4.3. Modified Loss Function
5. Experimental Process and Result Analysis
5.1. Experiment Configuration and Dataset
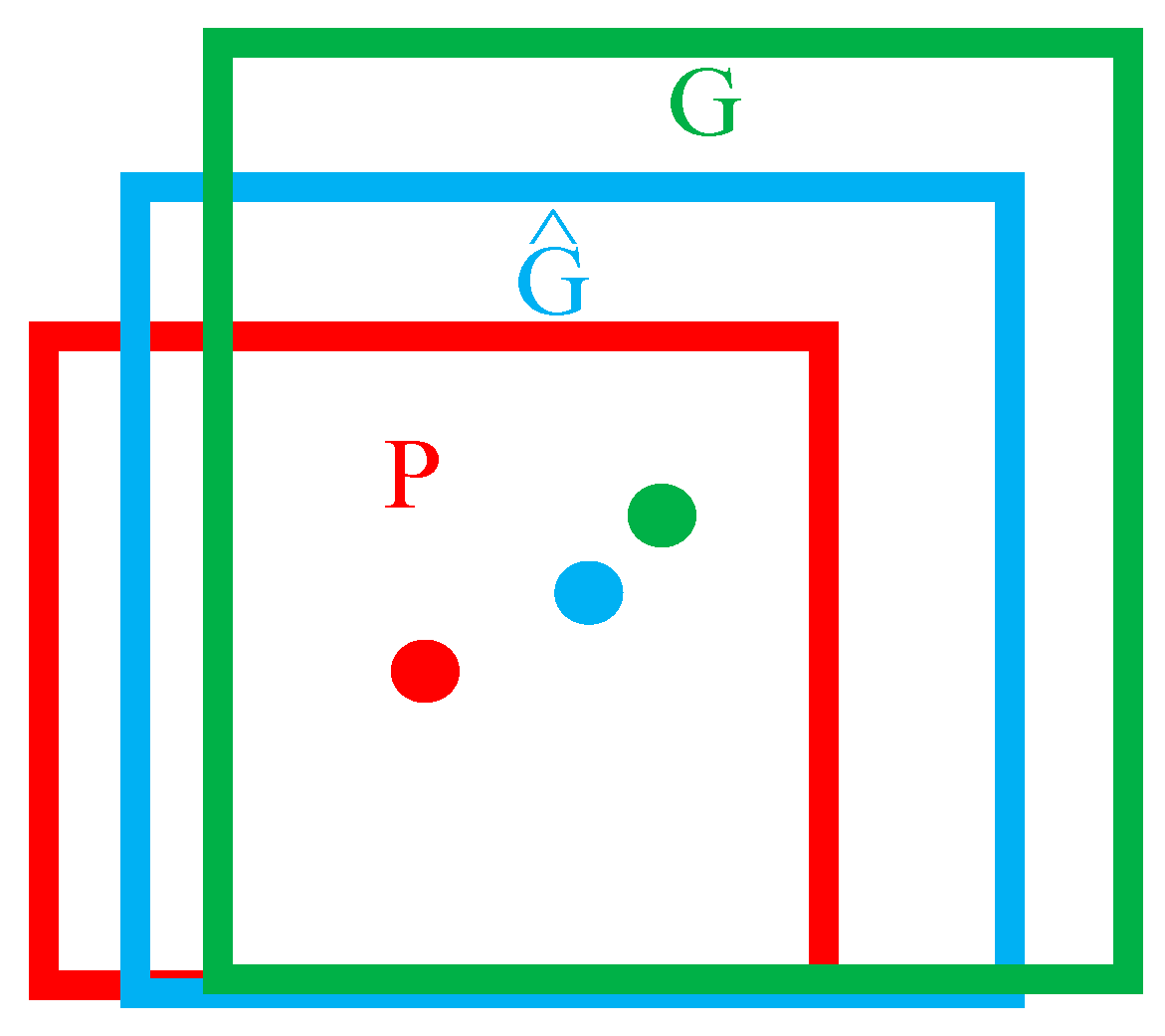
5.2. Evaluating Indicators
- (1)
- P-R curve
- (2)
- mAP
5.3. Experimental Process and Result Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, Y.; Zhang, H.; Li, Y.; Yang, Y.; Yuan, D. Video Object Detection Guided by Object Blur Evaluation. IEEE Access 2020, 8, 208554–208565. [Google Scholar] [CrossRef]
- Zhang, Q.; Wan, C.; Han, W.; Bian, S. Towards a fast and accurate road object detection algorithm based on convolutional neural networks. J. Electron. Imaging 2018, 27, 053005. [Google Scholar] [CrossRef]
- Kaur, J.; Singh, W. Tools, techniques, datasets and application areas for object detection in an image: A review. Multimed. Tools Appl. 2022, 81, 38297–38351. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, X.; Liu, F. ViT-YOLO: Transformer-based YOLO for object detection. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), OCT 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 2799–2808. [Google Scholar]
- Silva, L.P.E.; Batista, J.C.; Bellon, O.R.P.; Silva, L. YOLO-FD: YOLO for face detection. In Proceedings of the 24th Iberoamerican Congress on Pattern Recognition (CIARP), OCT 2019, Havana, Cuba, 28–31 October 2019; Volume 11896, pp. 209–218. [Google Scholar]
- Yan, B.; Li, J.; Yang, Z.; Zhang, X.; Hao, X. AIE-YOLO: Auxiliary Information Enhanced YOLO for Small Object Detection. Sensors 2022, 22, 8221. [Google Scholar] [CrossRef] [PubMed]
- Ye, J.; Yuan, Z.; Qian, C.; Li, X. CAA-YOLO: Combined-Attention-Augmented YOLO for Infrared Ocean Ships Detection. Sensors 2022, 22, 3782. [Google Scholar] [CrossRef]
- Wang, K.; Liu, M. YOLO-Anti: YOLO-based counterattack model for unseen congested object detection. Pattern Recognit. 2022, 131, 108814. [Google Scholar] [CrossRef]
- Xu, P. Progress of Object detection: Methods and future directions. In Proceedings of the 2nd IYSF Academic Symposium on Artificial Intelligence and Computer Engineering, Xi’an, China, 8–10 October 2021; Volume 12079. [Google Scholar]
- Murthy, C.B.; Hashmi, M.F.; Bokde, N.D.; Geem, Z.W. Investigations of Object Detection in Images/Videos Using Various Deep Learning Techniques and Embedded Platforms—A Comprehensive Review. Appl. Sci. 2020, 10, 3280. [Google Scholar] [CrossRef]
- Ma, D.W.; Wu, X.J.; Yang, H. Efficient Small Object Detection with an Improved Region Proposal Networks. In Proceedings of the 5th International Conference on Electrical Engineering, Control and Robotics (EECR), Guangzhou, China, 12–14 January 2019; Volume 533, p. 012062. [Google Scholar] [CrossRef]
- Fang, F.; Li, L.; Zhu, H.; Lim, J.-H. Combining Faster R-CNN and Model-Driven Clustering for Elongated Object Detection. IEEE Trans. Image Process. 2019, 29, 2052–2065. [Google Scholar] [CrossRef]
- Hu, B.; Liu, Y.; Chu, P.; Tong, M.; Kong, Q. Small Object Detection via Pixel Level Balancing With Applications to Blood Cell Detection. Front. Physiol. 2022, 13, 911297. [Google Scholar] [CrossRef]
- Afsharirad, H.; Seyedin, S.A. Salient object detection using the phase information and object model. Multimed. Tools Appl. 2019, 78, 19061–19080. [Google Scholar] [CrossRef]
- Du, L.; Sun, X.; Dong, J. One-Stage Object Detection with Graph Convolutional Networks. In Proceedings of the 12th International Conference on Graphics and Image Processing (ICGIP), Xi’an, China, 13–15 November 2020; Volume 11720. [Google Scholar]
- Yu, L.; Lan, J.; Zeng, Y.; Zou, J.; Niu, B. One hyperspectral object detection algorithm for solving spectral variability problems of the same object in different conditions. J. Appl. Remote Sens. 2019, 13, 026514. [Google Scholar] [CrossRef]
- Dong, Z.; Liu, Y.; Feng, Y.; Wang, Y.; Xu, W.; Chen, Y.; Tang, Q. Object Detection Method for High Resolution Remote Sensing Imagery Based on Convolutional Neural Networks with Optimal Object Anchor Scales. Int. J. Remote Sens. 2022, 43, 2677–2698. [Google Scholar] [CrossRef]
- Zhan, Y.; Yu, J.; Yu, T.; Tao, D. Multi-task Compositional Network for Visual Relationship Detection. Int. J. Comput. Vis. 2020, 128, 2146–2165. [Google Scholar] [CrossRef]
- Wang, Y.; Dong, Z.; Zhu, Y. Multiscale Block Fusion Object Detection Method for Large-Scale High-Resolution Remote Sensing Imagery. IEEE Access 2019, 7, 99530–99539. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, M.; Wang, Y.; Liu, Y.; Feng, Y.; Xu, W. Multi-Oriented Object Detection in High-Resolution Remote Sensing Imagery Based on Convolutional Neural Networks with Adaptive Object Orientation Features. Remote Sens. 2022, 14, 950. [Google Scholar] [CrossRef]
- Hou, Q.; Xing, J. KSSD: Single-stage multi-object detection algorithm with higher accuracy. IET Image Process. 2020, 14, 3651–3661. [Google Scholar] [CrossRef]
- Xi, X.; Wang, J.; Li, F.; Li, D. IRSDet: Infrared Small-Object Detection Network Based on Sparse-Skip Connection and Guide Maps. Electronics 2022, 11, 2154. [Google Scholar] [CrossRef]
- Koyun, O.C.; Keser, R.K.; Akkaya, I.B.; Töreyin, B.U. Focus-and-Detect: A small object detection framework for aerial images. Signal Process. Image Commun. 2022, 104, 116675. [Google Scholar] [CrossRef]
- Kim, J.U.; Kwon, J.; Kim, H.G.; Ro, Y.M. BBC Net: Bounding-Box Critic Network for Occlusion-Robust Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1037–1050. [Google Scholar] [CrossRef]
- Lee, D.-H. CNN-based single object detection and tracking in videos and its application to drone detection. Multimed. Tools Appl. 2020, 80, 34237–34248. [Google Scholar] [CrossRef]
- Wu, T.; Liu, Z.; Zhou, X.; Li, K. Spatiotemporal salient object detection by integrating with objectness. Multimed. Tools Appl. 2017, 77, 19481–19498. [Google Scholar] [CrossRef]
- Wang, C.; Yu, C.; Song, M.; Wang, Y. Salient Object Detection Method Based on Multiple Semantic Features. In Proceedings of the 9th International Conference on Graphic and Image Processing (ICGIP), Ocean Univ China, Acad Exchange Ctr, Qingdao, China, 14–16 October 2017; Volume 10615. [Google Scholar]
- Kang, S. Research on Intelligent Video Detection of Small Objects Based on Deep Learning Intelligent Algorithm. Comput. Intell. Neurosci. 2022, 2022, 3843155. [Google Scholar] [CrossRef] [PubMed]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP | FPS |
|---|---|---|
| YOLOv3 | 82.36% | 16.74 |
| YOLOv5 | 84.75% | 34.69 |
| SSD | 86.64% | 18.99 |
| MAO-YOLOv5 | 92.30% | 23.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, G.; Wang, S.; Xie, J. An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLOv5. Electronics 2023, 12, 1515. https://doi.org/10.3390/electronics12071515
Sun G, Wang S, Xie J. An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLOv5. Electronics. 2023; 12(7):1515. https://doi.org/10.3390/electronics12071515
Chicago/Turabian StyleSun, Guangming, Shuo Wang, and Jiangjian Xie. 2023. "An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLOv5" Electronics 12, no. 7: 1515. https://doi.org/10.3390/electronics12071515
APA StyleSun, G., Wang, S., & Xie, J. (2023). An Image Object Detection Model Based on Mixed Attention Mechanism Optimized YOLOv5. Electronics, 12(7), 1515. https://doi.org/10.3390/electronics12071515