2.1. Mathematical Framework
Consider a
p-dimensional random vector
that comes from a multivariate distribution
F:
Let
be the marginal distribution of random variable
,
. Now, recall that, if
, then
. From here, one can conclude that
, since
It is worth pointing out that the previous result is quite known and valuable for generating synthetic data from the random variable with distribution function . It is a simple step by generating a random variable and then to consider ; here, must be known. However, to generate a sample of synthetic data of size N from observed random sample coming from the same distribution function where is unknown, one must implement some nonparametric simulation process. In this paper, we introduce a methodology to generate synthetic data that must come from the same population where the observed sample is coming.
Let
be the
r-th order statistic of a random sample
, i.e.,
Consider a partition of the interval
as
. Define
as:
where
is the indicator function. Note that
can be seen as a natural estimator for
, thus some desirable properties will be considered below. In the context of density estimation, an important parameter to consider is the bandwidth denoted by
h, which represents the radius of each element in the partition, i.e.,
. It is worth noting that the number of partitions
t in Equation
(2) depends on the bandwidth parameter as follows:
. Some methods for computing the bandwidth
h are discussed in greater detail in Wasserman ([
37], pp. 134–135).
Proposition 1. is an unbiased estimator for
Proof. However, ; then, the proof is completed. □
Previous results of Proposition 1 will be needed in the proof of the next proposition that states an asymptotic result.
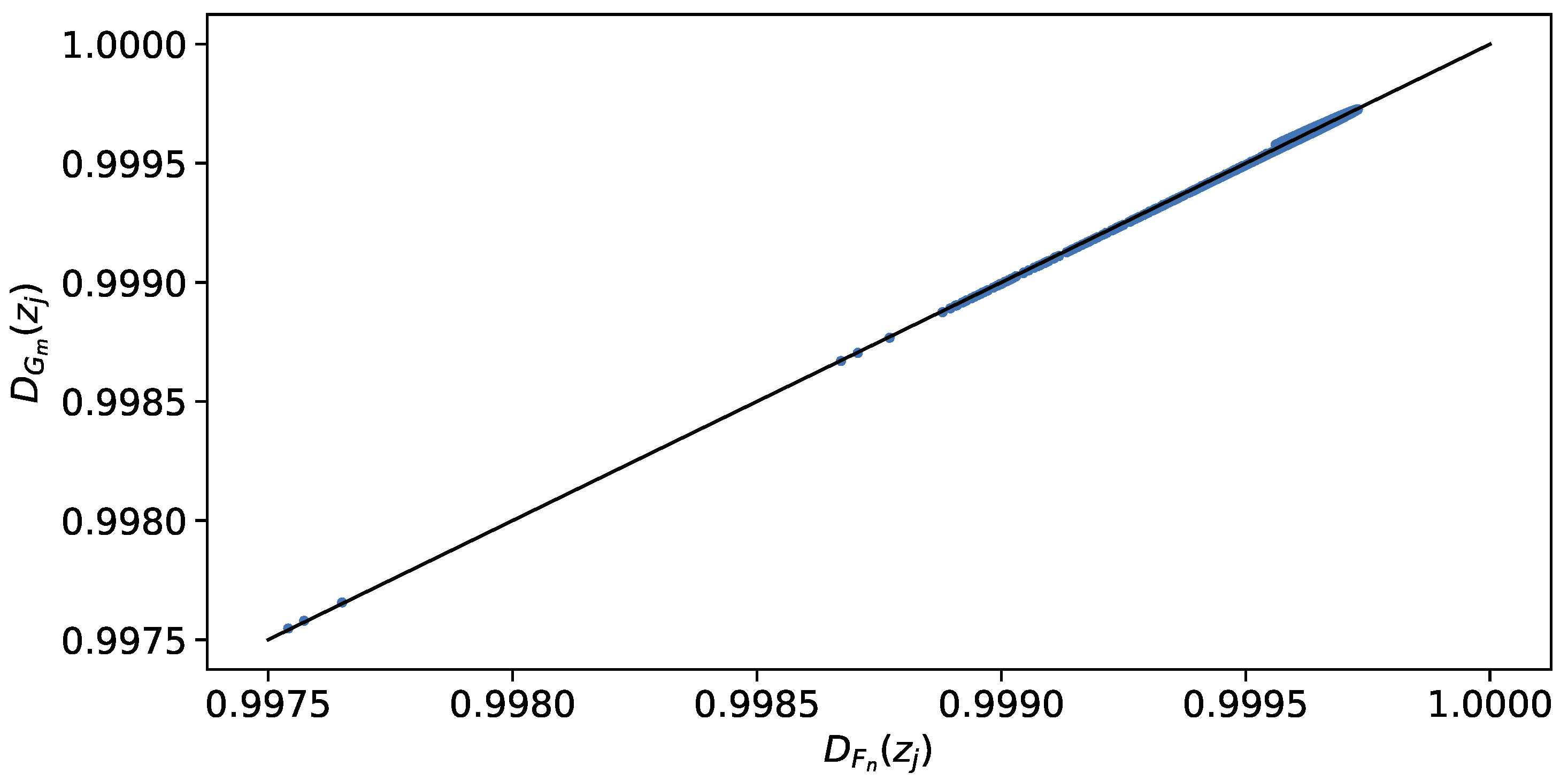
Proposition 2. converges in quadratic mean to
Proof. Therefore, converges to zero, and from Proposition 1, we have the desired conclusion. □
It is recalled that, if one wants to generate univariate synthetic data from a known distribution , a simple form is using the inverse transform, i.e., one must generate a random variable Uniform in and then . However, if is unknown but we have a sample that comes from the distribution , the generation of synthetic data is more complicated. In this paper, considering the result obtained in Proposition 2, a methodology is proposed to generate univariate synthetic data but when one has a sample that comes from the unknown distribution . Following the same idea considered in the inverse transform, one must generate a random variable U Uniform in and then calculate and so the synthetic data are generated by considering .
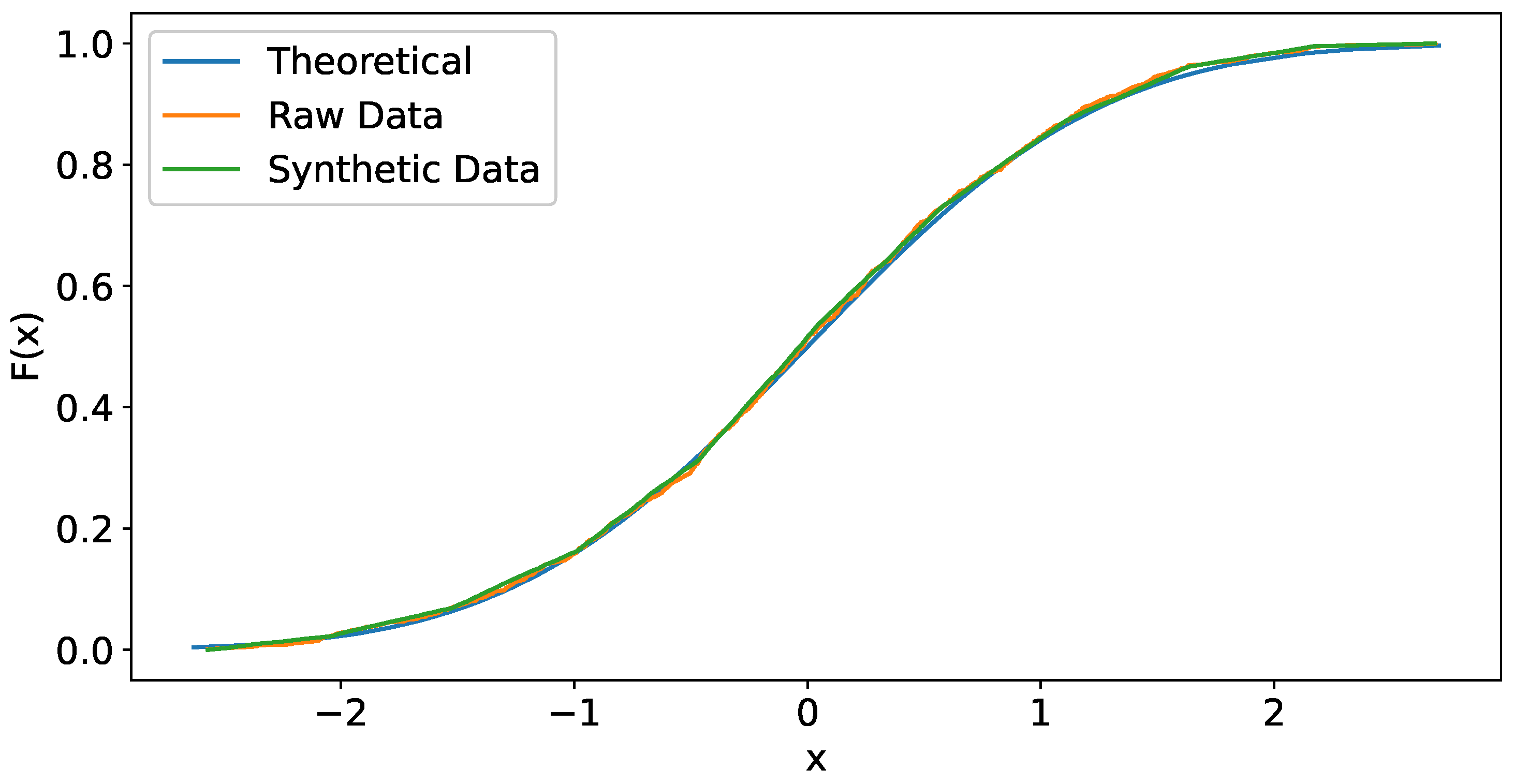
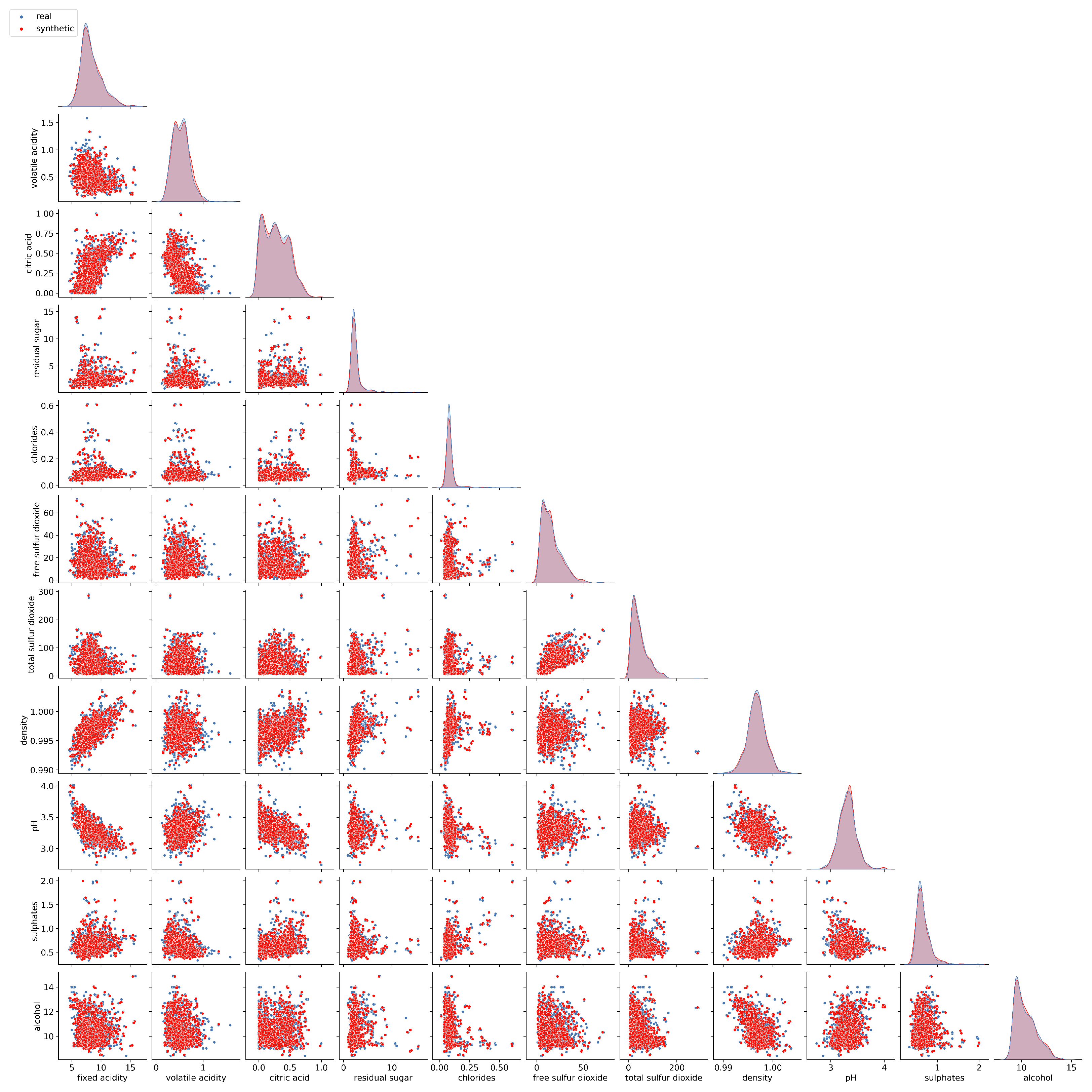
Example 1. Let us simulate 300 data points from a standard Normal distribution. These 300 data points will be considered as an observed sample, i.e., raw data. Now, from those raw data, we will generate 1000 synthetic data points through the procedure introduced in this paper. The results on some relevant parameters can be seen in Table 1. We will generate 2000 collections of synthetic data, each comprising 1000 records and based on the same raw data that were previously considered. For each data set, the same values considered in Table 1 are calculated. Table 2 displays the mean value and the confidence interval of each of those values. Figure 2 shows the curve of theoretical distribution, the empirical distribution of raw data and the empirical distribution of synthetic data. Note that the raw data curve fits well to the theoretical distribution curve. This is not surprising because the raw data have been simulated from the theoretical distribution. However, the synthetic data generated from the raw data retain the same good-fit behavior. Note that the quality of the synthetic data depends on the quality of the observed raw data. Example 2. Let us now simulate 300 data points from an exponential distribution with mean 5. These 300 data points will be considered as an observed sample, i.e., raw data. From these raw data, we will generate 1000 synthetic data points. We followed the same steps as in the previous example. Table 3 presents relevant parameters for these data.
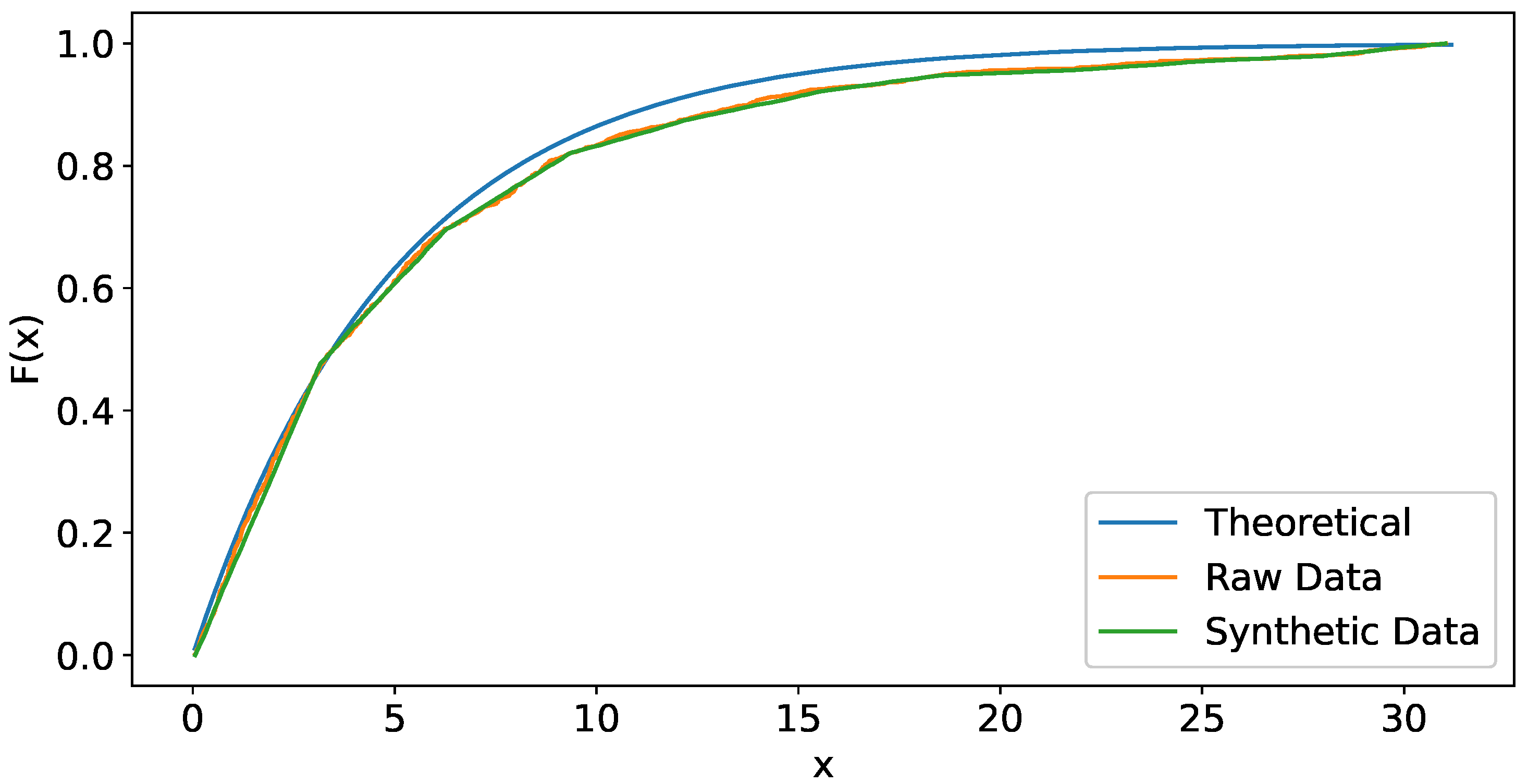
From the same raw data, we generate 2000 collections of synthetic data of same size 1000. Table 4 displays the mean value and the 95% confidence interval of values considered in Table 3. Figure 3 shows the curve of the theoretical distribution, the empirical distribution of raw data and the empirical distribution of synthetic data where a good fit can be observed. Once the methodology to generate synthetic data from a univariate raw data sample has been designed, then we propose a technique to generate multivariate synthetic data from a multivariate data sample that comes from a random vector with multivariate distribution F, with being the marginal distribution of the random variable .
Let
be a
a matrix of the real data that comes from the random vector
is a raw data multivariate sample; one could think that, for generating synthetic data from
, it is enough to generate, for each variable
, univariate synthetic data through the method introduced above, but the procedure is more complex because one must consider the dependence structure among marginal variables
. This dependence structure must be studied using a special dependence functions called copulas. We consider Nelsen [
35] as the foremost general reference for an in-depth examination of copula theory.
A copula is a multivariate distribution function defined on
, where each of the
p marginal distributions is a uniform distribution in
. According to Sklar’s theorem [
17], any multivariate distribution function can be written in terms of the marginal distributions and a copula
C, i.e., given a p-dimensional random vector
with a multivariate distribution
F, then
Sklar’s theorem also states that the copula
C is unique if the marginals
are continuous. The copula
C contains the information on the dependence structure among the marginal random variables of
, and this dependence structure is an important aspect that must be considered when synthetic data are generated from the multivariate sample stated in the matrix of the real data
that comes from the random vector
. From Equation (
1),
, thus the random vector
has uniform marginals in
. Since each of
is a non decreasing function, then the random vectors
and
have the same copula because the copula is invariant under non-decreasing transformations of the marginal random variables. Therefore, if there is a procedure to generate, from a known copula
C, observations of the random vector
, then a sample from
can be obtained as
; here, the marginal distributions also must be known. However, when neither the copula
C nor the marginal distributions
are known, only a real data multivariate sample as
is known, the previous procedure can not be implemented. Therefore, we introduce a new method for the generation of a new multivariate sample just knowing the multivariate sample stated in the matrix of the real data
:
Define
where
is the indicator function. Note that
is the empirical distribution of observed value
with respect to the observed sample just of the
i-th variable. Therefore, following Equation (
4), the following matrix,
is the
p-dimensional support of the empirical copula estimated from multivariate sample
, where the columns of
are samples that come from random vector
considered in Equation (
4) and thus those samples come from the same copula
C, which is the same copula that has the random vector
, from which comes the raw data multivariate sample stated in matrix
. Since the copula
C is unknown, the new procedure introduced just considers the
p-dimensional support of the empirical copula estimated from multivariate sample
as follows.
For the
i-th column in
, consider a partition of the interval
as
. Define
as:
Note that can be seen as a natural estimator for , and from Proposition 1, the vector is an unbiased estimator of the vector .
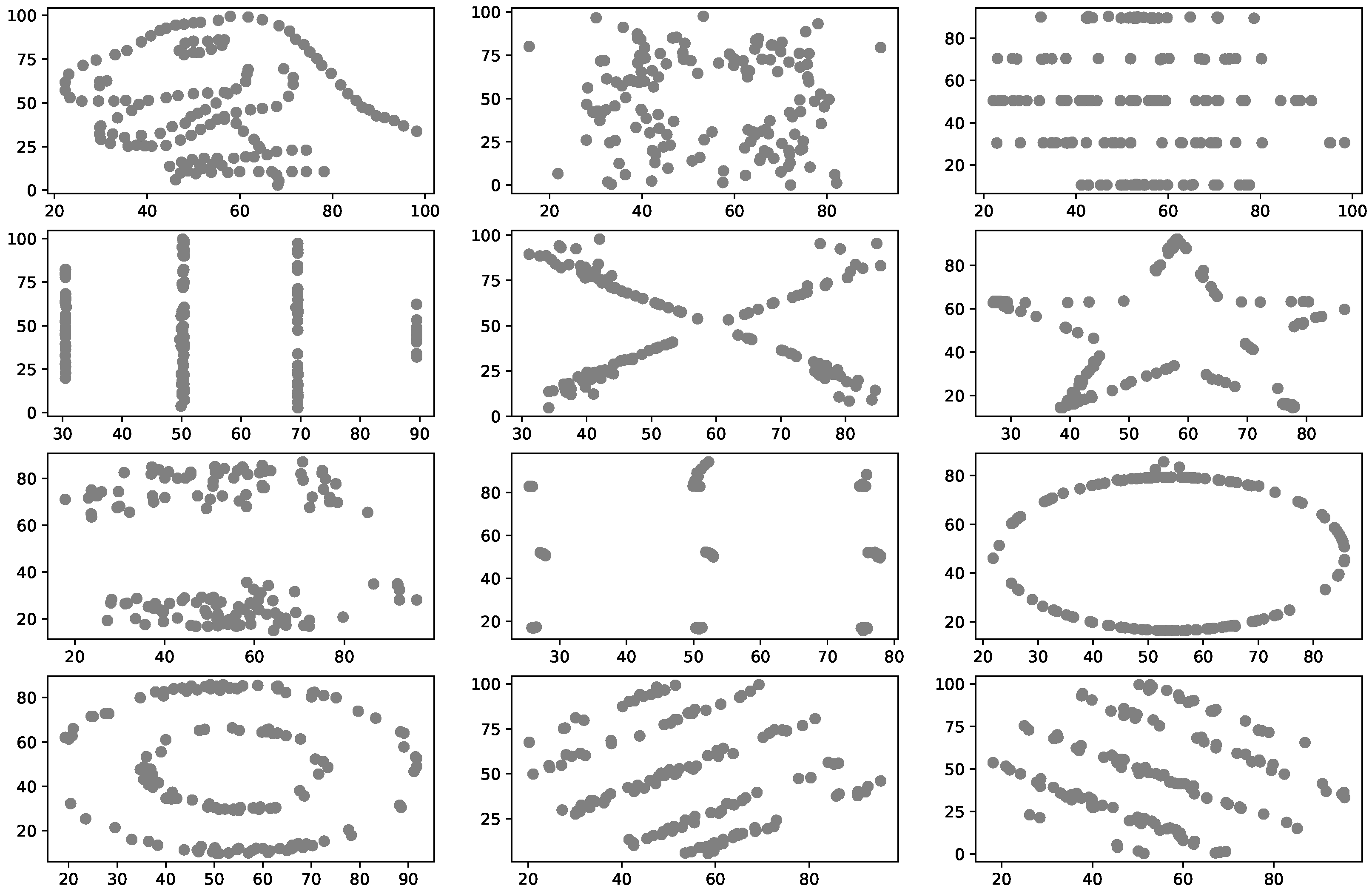
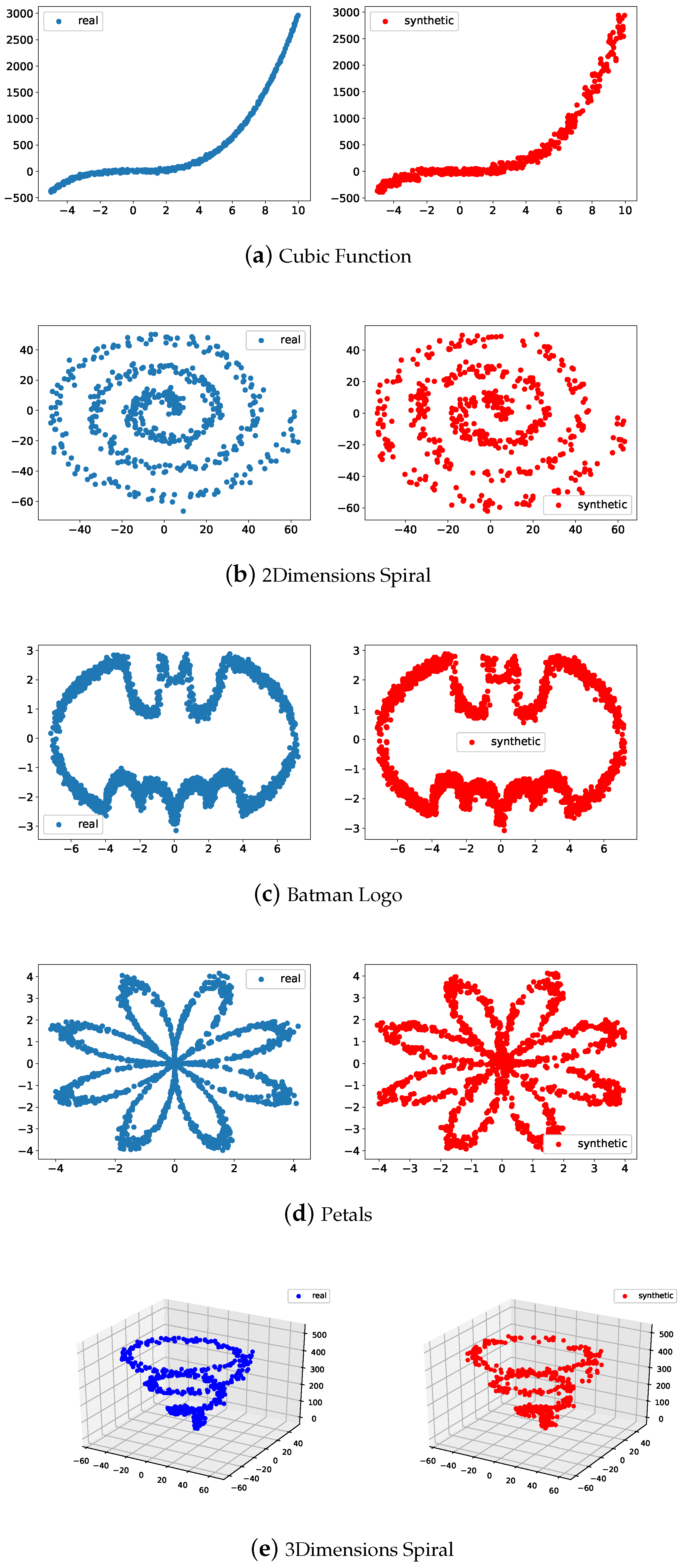
Let d be a value generated from a discrete uniform distribution in . Since the copula C is unknown, we use the the p-dimensional support of the empirical copula by selecting the d-th row of . Following the same idea considered in the inverse transform, one must generate a random variable U Uniform in ; then, for each , calculate and so a multivariate synthetic piece of data , with the same statistics structure as marginals and dependence of those data stated in the matrix of the real data , can be generated by considering for all .
| Algorithm 1: Synthetic Data Generation Algorithm |
![Electronics 12 01601 i001]() |
To understand how the performance of the algorithm scales related to the size of the parameters N, n, p and T, we analyze the complexity of Algorithm 1. First, computing the empirical distribution function along the frequency tables for all variables is time. In addition, the worst time of evaluating an empirical distribution function is , and repeated to every element in matrix is then . Let , and the creation of a datum is bounded by time. Therefore, the generation of a sample of size N is time. Thus, the worst time complexity of the Synthetic Data Generation Algorithm is and since t is bounded by n, the expression can be simplified to .













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}